|
Опрос
|
реклама
Быстрый переход
США захотели ограничить доступ России и Китая к GPT-4 и другим мощным моделям ИИ
09.05.2024 [00:41],
Владимир Мироненко
Министерство торговли США рассматривает возможность принятия новых нормативных мер по ограничению доступа Китая, России и некоторых других стран к проприетарных моделям искусственного интеллекта (ИИ), таким как GPT-4, пишет агентство Reuters со ссылкой на свои источники. 
Источник изображения: flutie8211/Pixabay В настоящее время нет никаких препятствий для продажи американскими разработчиками самых мощных систем ИИ с закрытым исходным кодом кому угодно. OpenAI, поддерживаемая Microsoft, Google DeepMind холдинга Alphabet или Anthropic абсолютно законно могут продать свои ИИ-модели практически любому пользователю или компании. Вместе с тем исследователи из государственного и частного секторов США выражают обеспокоенность тем, что противники Соединённых Штатов могут использовать ИИ-модели, способные анализировать огромные объёмы текста и изображений для обобщения информации и создания контента, для проведения мощных кибератак, создания биологического оружия и других целей. По словам одного из источников Reuters, любое ужесточение контроля экспорта ИИ-технологий, скорее всего, будет относиться к таким странам, как Россия, Китай, Северная Корея и Иран. Как сообщают источники, для экспортного контроля над ИИ-моделями США могут использовать пороговое значение вычислительной мощности, необходимой для обучения модели. В случае достижения порогового значения, разработчик должен будет сообщить о планах разработки ИИ-модели и предоставить результаты испытаний Министерству торговли США. По мнению двух американских чиновников и источника Reuters, осведомлённого о ходе обсуждений, этот показатель может стать основой для определения того, какие ИИ-модели подпадают под экспортные ограничения. Если этот подход возьмут за основу, ограничения коснутся экспорта будущих ИИ-моделей, поскольку ни одна из существующих ИИ-моделей не достигла этого порога, хотя по данным исследовательского института EpochAI, Gemini Ultra от Google близка к нему. По мнению Тима Фиста (Tim Fist), эксперта по политике в области ИИ из аналитического центра CNAS в Вашингтоне (округ Колумбия), пороговое значение «является хорошей временной мерой, пока не будут разработаны более эффективные методы измерения возможностей и рисков новых моделей». Он отметил, что Китай, по всей видимости, примерно на два года отстаёт от Соединённых Штатов в сфере ИИ и разрабатывает собственное программное обеспечение для этих технологий. В свою очередь Джамиль Джаффер (Jamil Jaffer), бывший чиновник Белого дома и Министерства юстиции США считает, что лучше использовать контроль, основанный на возможностях модели и предполагаемом применении. «Лучше сосредоточиться на угрозе национальной безопасности, а не на технологических порогах, потому что это более долгосрочно и сосредоточено на угрозе», — сказал он. Независимо от порогового значения, экспорт моделей ИИ будет трудно контролировать, говорит Фист. Многие модели имеют открытый исходный код, а это означает, что они будут неподконтрольны регулятору. Новая статья: ИИтоги апреля 2024 г.: парад моделей — и не только
09.05.2024 [00:06],
3DNews Team
Данные берутся из публикации ИИтоги апреля 2024 г.: парад моделей — и не только Через год сегодняшний ChatGPT будет выглядеть смехотворно плохо, заявил директор OpenAI
08.05.2024 [13:51],
Дмитрий Федоров
Брэд Лайткап (Brad Lightcap), главный операционный директор OpenAI, рассказал на Глобальной конференции в Институте Милкена о будущем компании и её планах на следующие 6–12 месяцев. По его мнению, нынешние системы искусственного интеллекта (ИИ), такие как ChatGPT, являются «смехотворно плохими» по сравнению с тем, что ждёт человечество впереди. Он подчеркнул, что будущие версии ИИ будут настолько продвинутыми, что изменят саму суть взаимодействия с пользователями. 
Источник изображения: JuliusH / Pixabay Лайткап описал нынешнюю версию ChatGPT как начальный этап в эволюции ИИ, предназначенного для выполнения простых задач. «Я думаю, что через год мы оглянемся назад и поймём, насколько несовершенными они были», — заявил Лайткап, когда его спросили о бизнесе OpenAI через 6–12 месяцев. В перспективе он предвидит эволюцию ИИ в направлении более сложных задач, где ИИ станет отличным напарником, способным на равных общаться с людьми, как друг или коллега. Кроме технологических аспектов Лайткап прокомментировал социальные последствия развития ИИ. Он опроверг мнение о том, что развитие ИИ приведёт к массовым увольнениям людей, утверждая, что новые ИИ-системы наоборот спровоцируют спрос на ещё не существующие вакансии. По его мнению, экономика станет более разнообразной и устойчивой, а рынок труда адаптируется к технологическим изменениям. В свете этих заявлений интересно, что генеральный директор OpenAI Сэм Альтман (Sam Altman) также высказывался о будущем ChatGPT на семинаре в Стэнфордском университете, назвав GPT-4 самой глупой моделью, с которой людям придётся работать когда-либо в будущем. Такие заявления вероятно намекают на то, что будущие обновления ChatGPT станут переломными и приведут к значительному улучшению функциональности продуктов OpenAI. OpenAI превратит ChatGPT в ИИ-поисковик и будет конкурировать с Google
08.05.2024 [11:07],
Владимир Фетисов
Компания OpenAI ведёт разработку функции интернет-поиска для своего чат-бота ChatGPT. Алгоритм сможет находить интересующую пользователей информацию, а также предоставлять ссылки на источники. Об этом пишет издание Bloomberg со ссылкой на собственный осведомлённый источник, который также отметил намерение OpenAI конкурировать в сфере веб-поиска с Google и принадлежащим Alphabet поисковым стартапом Perplexity. 
Источник изображения: Pixabay В сообщении сказано, что ChatGPT сможет включать в ответы на пользовательские запросы информацию из интернета вместе с ссылками на источники, такие как «Википедия» и публикации в блогах. По данным издания, одна из версий продукта также сможет выдавать вместе с текстовым ответом релевантные изображения в случаях, когда это будет актуально. К примеру, если пользователь поинтересуется, как заменить дверную ручку, то ответ может содержать изображение, иллюстрирующее процесс решения данной задачи. СМИ писали о намерении OpenAI выпустить некий поисковый продукт ещё в феврале этого года, но подробности о том, как он будет функционировать, до сих пор оставались загадкой. Официальные представители OpenAI отказались от комментариев по данному вопросу. OpenAI стремится расширить возможности собственного ИИ-бота, поскольку конкуренция в этом сегменте становится всё более ожесточённой. Стартап Perplexity уже успел завоевать популярность благодаря собственной поисковой системе на базе искусственного интеллекта, которая делает упор на точность ответов и цитируемость. Гигант интернет-поиска Google также стремится переосмыслить свой поисковик, добавляя в него ИИ-функции. Ожидается, что компания расскажет о своих планах и дальнейшем будущем алгоритмов Gemini на ежегодной конференции I/O, которая пройдёт на следующей неделе. OpenAI научилась распознавать сгенерированные своим ИИ изображения, но не без ошибок
08.05.2024 [10:19],
Дмитрий Федоров
OpenAI объявила о начале разработки новых методов определения контента, созданного искусственным интеллектом (ИИ). Среди них — новый классификатор изображений, который определяет, было ли изображение сгенерировано ИИ, а также устойчивый к взлому водяной знак, способный маркировать аудиоконтент незаметными сигналами. 
Источник изображения: Placidplace / Pixabay Новый классификатор изображений способен с точностью до 98 % определять, было ли изображение создано ИИ-генератором изображений DALL-E 3. Компания утверждает, что их классификатор работает, даже если изображение было обрезано, сжато или была изменена его насыщенность. В то же время эффективность этой разработки OpenAI в распознавании контента, созданного другими ИИ-моделями, такими как Midjourney, значительно ниже — от 5 до 10 %. Также OpenAI ввела водяные знаки для аудиоконтента, созданного с помощью своей платформы преобразования текста в речь Voice Engine, находящейся на стадии предварительного тестирования. Эти водяные знаки содержат информацию о создателе и методах создания контента, что значительно упрощает процесс проверки их подлинности. OpenAI активно участвует в работе Коалиции по происхождению и аутентичности контента (C2PA), в состав которой также входят такие компании, как Microsoft и Adobe. В этом месяце компания присоединилась к руководящему комитету C2PA, подчеркивая свою роль в разработке стандартов прозрачности и подлинности цифрового контента. Для этих целей OpenAI интегрировала в метаданные изображений так называемые учётные данные контента от C2PA. Эти учётные данные, фактически являясь водяными знаками, включают информацию о владельце изображения и способах его создания. OpenAI уже много лет работает над обнаружением ИИ-контента, однако в 2023 году компании пришлось прекратить работу программы, определяющей текст, сгенерированный ИИ, из-за её низкой точности. Разработка классификатора изображений и водяного знака для аудиоконтента продолжается. В OpenAI подчёркивают, что для оценки эффективности этих инструментов крайне важно получить отзывы пользователей. Исследователи и представители некоммерческих журналистских организаций имеют возможность протестировать классификатор изображений на платформе доступа к исследованиям OpenAI. Google создала ИИ-инструмент для быстрого реагирования на киберугрозы
07.05.2024 [10:54],
Владимир Мироненко
Google представила новое решение в сфере кибербезопасности Threat Intelligence, которое позволит клиентам «получать ценную информацию и защищать корпоративную IT-инфраструктуру от угроз быстрее, чем когда-либо прежде», используя аналитические данные подразделения кибербезопасности Mandiant, службы анализа угроз VirusTotal в сочетании с возможностями ИИ-модели Gemini AI. 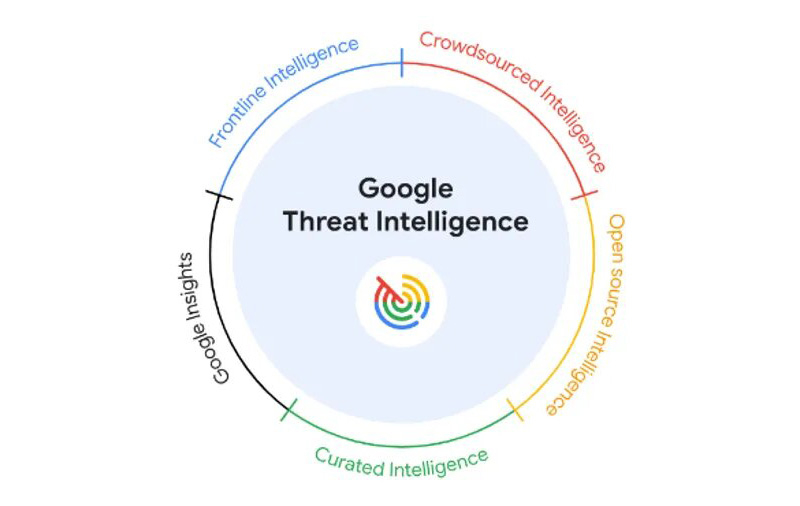
Источник изображения: Google «Бесспорно, что сегодня Google обеспечивает два наиболее важных столпа анализа угроз в отрасли — VirusTotal и Mandiant. Интеграция обоих в единое предложение, дополненное ИИ и анализом угроз Google, предлагает командам безопасности новые средства для использования актуальных сведений об угрозах для лучшей защиты своих организаций», — отметил Дэйв Грубер (Dave Gruber), главный аналитик Enterprise Strategy Group. Согласно Google, подразделение Mandiant, предоставляющее услуги по обнаружению и устранению киберугроз, ежегодно расследует около 1100 случаев взлома. Новый сервис Google Threat Intelligence также использует VirusTotal, краудсорсинговую базу данных вредоносных программ, которая насчитывает более 1 млн пользователей. Кроме того, Threat Intelligence включает собираемые Google данные о кибератаках, нацеленных на 1,5 млрд учётных записей пользователей Gmail и 4 млрд устройств. Google отметила, что основным преимуществом Threat Intelligence является предоставление специалистам по безопасности ускоренной аналитики за счёт использования генеративного ИИ. Задействованная в решении большая языковая модель Gemini 1.5 Pro, по словам Google, сокращает время, необходимое для анализа вредоносного ПО и раскрытия его исходного кода. Компания отметила, что вышедшей в феврале версии Gemini 1.5 Pro потребовалось всего 34 секунды, чтобы проанализировать код вируса WannaCry, программы-вымогателя, с помощью которой хакеры в 2017 году атаковали множество компаний по всему миру. Также Gemini позволяет ускорить сбор информации о хакерской группе, её целях, тактике взлома и связанных с ней деталях. Кроме того, Gemini обеспечивает обобщение отчётов об угрозах на естественном языке в Threat Intelligence, что позволяет компаниям оценить, как потенциальные атаки могут на них повлиять, и расставить приоритеты, на чём следует сосредоточиться. Microsoft запустила разработку собственной большой языковой модели ИИ — это добавит независимости от OpenAI
07.05.2024 [10:17],
Алексей Разин
Вложившая в капитал стартапа OpenAI более $10 млрд американская корпорация Microsoft, по данным The Information, занялась разработкой собственной большой языковой модели ИИ, которая добавит компании независимости от той же OpenAI и усилит конкуренцию с Google. Модель получила обозначение MAI-1 и создаётся с использованием собственных ресурсов. 
Источник изображения: Nvidia Руководит этой инициативой в Microsoft, как отмечает первоисточник, Мустафа Сулейман (Mustafa Suleyman), который занимался разработкой систем искусственного интеллекта в Google, а также возглавлял стартап Inflection, прежде чем его не поглотила Microsoft, заплатив $650 млн в марте этого года. Впрочем, источники подчёркивают, что Microsoft самостоятельно разрабатывает MAI-1, не опираясь на существовавшие в Inflection программные решения. Впрочем, использование каких-то технологий этого стартапа в том или ином виде не исключается. MAI-1 станет значительно более крупной языковой моделью по сравнению с теми разработками с открытым исходным кодом, которые до сих пор использовала Microsoft. Она потребует не только большего количества входных данных, но и более значимых вычислительных ресурсов. MAI-1 будет использовать около 500 млрд параметров. Если учесть, что передовая ChatGPT-4 стартапа OpenAI использует 1 трлн параметров, для собственной модели Microsoft это будет существенный прорыв в сложности модели. Назначение MAI-1 пока не определено и будет выбрано в зависимости от промежуточных успехов в её разработке. Microsoft может рассказать подробности об этой инициативе на конференции Build ближе к концу текущего месяца. Opera добавила ИИ-функцию краткой сводки веб-страниц для Android
07.05.2024 [06:27],
Анжелла Марина
Браузер Opera для Android получил удобный ИИ-инструмент для быстрого ознакомления с содержанием веб-страниц. Новая функция генерирует краткое резюме длинных статей и сообщений, позволяя экономить время на понимание темы и поиск ключевых деталей. Для использования функции «Сводка» нужно обновить Opera для Android до последней версии и войти в учётную запись. 
Источник изображения: Opera Инструмент реферирования текста основан на встроенном в Opera помощнике искусственного интеллекта Aria. Пользователю достаточно открыть любую текстовую страницу в Opera, нажать на три точки в правом верхнем углу и выбрать пункт «Сводка» (Summarize) рядом с иконкой Aria. После этого откроется диалог, в котором будет представлено краткое резюме статьи, обычно умещающееся на одном экране. Такое резюме помогает быстро понять суть, выделить основные моменты и решить, стоит ли тратить время на полное прочтение. Это действительно удобно, когда нужно быстро ознакомиться с большим количеством информации, найденной в интернете. Также помощник теперь может зачитывать текстовые ответы вслух. Напомним, помощник искусственного интеллекта Aria был интегрирован в браузер Opera около года назад. Он работает как чат-бот, отвечая на вопросы пользователей и является альтернативой традиционному поиску в интернете. А совсем недавно в Aria была добавлена возможность генерировать изображения на основе текстовых запросов с использованием технологии Imagen 2 компании Google. Разработчики постоянно расширяют функциональность Aria с помощью специальной программы обновлений AI Feature Drops, чтобы пользователи получали все последние улучшения для комфортного использования всех опций интеллектуального браузера. Apple разрабатывает собственные серверные чипы для систем искусственного интеллекта
07.05.2024 [04:56],
Алексей Разин
Не так давно подобная идея уже высказывалась аналитиками Bank of America, а теперь издание The Wall Street Journal сообщает, что Apple занимается разработкой собственных процессоров серверного назначения для использования в системах искусственного интеллекта. Сроки их появления на рынке и сама такая вероятность пока не определены. 
Источник изображения: Apple У данного проекта, по словам первоисточника, уже появилось собственное имя ACDC — от английского Apple Chips in Data Center, то есть, «чипы Apple в центре обработки данных». Компания уже располагает коллективом разработчиков процессоров, которые нашли применение в смартфонах, планшетах, умных часах, и в последние годы успешно вытесняли продукцию Intel в компьютерах Apple семейства Mac. Следующим шагом эволюции вычислительных решений Apple могло бы стать как раз появление процессоров серверного назначения, которые изначально заточены под актуальную потребность работы с системами искусственного интеллекта. Представители Bank of America даже предположили, что такие чипы могли бы оснащаться памятью типа HBM, но о реальных намерениях инженеров Apple остаётся только догадываться. Amazon, Microsoft и Meta✴ Platforms свой путь к совершенствованию серверной инфраструктуры начинали с модифицированных процессоров Intel, но постепенно они втянулись в разработку собственных чипов. Apple вполне может пойти по этому пути, поскольку компания имеет потребность в развитии собственной инфраструктуры для обслуживания систем искусственного интеллекта. Медицинский ИИ от Google превзошёл GPT-4 и даже живых докторов
06.05.2024 [14:50],
Владимир Мироненко
Google Research и исследовательская лаборатория Google в области искусственного интеллекта DeepMind сообщили подробности о семействе передовых больших языковых моделей Med-Gemini, разработанных для применения в сфере здравоохранения. 
Источник изображения: geralt/Pixabay ИИ-модели всё ещё находятся на стадии исследования, но авторы разработок утверждают, что Med-Gemini, основанные на модели Google Gemini, превосходят конкурирующие модели, такие как GPT-4 от OpenAI, обладают огромным потенциалом в клинической диагностике и превосходят отраслевые стандарты в 14 популярных профильных бенчмарках. В частности, в тесте MedQA (USMLE) модель Med-Gemini достигла точности 91,1 %, используя стратегию поиска, основанную на неопределённости, превзойдя медицинскую LLM Med-PaLM 2 компании Google на 4,5 %. Набор моделей также превзошёл людей в обобщении медицинских текстов и составлении рекомендаций, причём врачи в половине случаев оценивали ответы Med-Gemini-M 1.0 как хорошие или даже лучше, чем ответы экспертов. Med-Gemini — это семейство больших мультимодальных моделей (LMM), каждая из которых имеет своё предназначение. В отличие от больших языковых моделей, которые «демонстрируют неоптимальные клинические рассуждения в условиях неопределённости», страдают галлюцинациями и предвзятостью, Med-Gemini дают «фактически более точные, надёжные и детальные результаты для сложных задач клинического обоснования», чем их конкуренты, включая GPT-4, утверждает Google. По семи мультимодальным бенчмаркам, включая проверку по изображениям New England Journal of Medicine (NEJM), модель Med-Gemini показала гораздо лучшие результаты, чем GPT-4. Чтобы проверить способность Med-Gemini понимать и рассуждать на основе длинной контекстной медицинской информации, исследователи с успехом выполнили с её помощью так называемую задачу поиска «иголки в стоге сена», используя большую общедоступную базу данных Medical Information Mart for Intensive Care (MIMIC-III), содержащую обезличенные данные о состоянии здоровья пациентов, поступивших в отделение интенсивной терапии. Поддержка Med-Gemini эффективного поиска в базе данных электронных медицинских карт Electronic Health Record (EHR) позволит «значительно снизить когнитивную нагрузку и расширить возможности врачей за счёт эффективного извлечения и анализа важной информации из огромных объёмов данных пациентов», утверждает Google. По словам исследователей, Med-Gemini также показывают хорошие результаты в медицинских тестах, медицинских знаниях, клинических рассуждениях, геномике, медицинской визуализации, медицинских записях и видео. Вместе с тем Google заявила, что её модели нуждаются в большей доработке и специализации, прежде чем их можно будет использовать в здравоохранении. YouTube протестирует на платных подписчиках перемотку видео сразу на самое интересное место
06.05.2024 [11:48],
Дмитрий Федоров
YouTube тестирует новую функцию, которая позволяет пользователю быстро переключаться на самый интересный момент просматриваемого ролика. Для этого используются данные о просмотрах видео и искусственный интеллект (ИИ). Эксперимент продлится до 1 июня, и его результаты могут оказать значительное влияние на общую стратегию сервиса. 
Источник изображения: muhammadsaqii786 / Pixabay YouTube начал тестировать упомянутую функцию в марте текущего года с участием небольшой группы пользователей, но теперь сделал её доступной для подписчиков YouTube Premium. Принцип работы довольно прост: когда пользователь дважды нажимает, чтобы перемотать видео вперёд, появляется кнопка, которая перемещает его к тому месту, до которого обычно перематывают большинство зрителей. Для определения наиболее просматриваемых эпизодов функция использует ИИ и данные о просмотрах видео. Для получения доступа к функции необходимо быть подписчиком YouTube Premium и также включить экспериментальные функции сервиса. В настоящее время нововведение доступно только в США для приложения YouTube на Android и только для видео на английском языке, по которым есть достаточно данных, чтобы определить любимые моменты зрителей. Согласно информации на сайте YouTube, тестирование функции продлится до 1 июня. После этого, предположительно, будет собрана обратная связь от пользователей, и на основе неё будет принято решение о более широком внедрении функции. Если вы хотите проверить, доступна ли эта функция вам, перейдите в раздел «Настройки» и выберите «Попробовать экспериментальные новые функции». В целом, новая функция YouTube представляет собой интересный эксперимент в области улучшения пользовательского опыта. Она может значительно упростить процесс просмотра видео, особенно для тех, кто хочет быстро перейти к самым важным или вирусным моментам. Однако, как и любая новая функция, она требует дальнейшего тестирования и оптимизации, и будет интересно узнать, как она будет принята пользователями и как повлияет на общую стратегию YouTube. В юбилейной публикации блога AMD слова «искусственный интеллект» упоминались 23 раза
04.05.2024 [05:18],
Анжелла Марина
AMD отметила на этой неделе свое 55-летие, и по такому случаю опубликовала пост в блоге, который посвящён достижениям и инновациям компании. Однако в нём непропорционально большое внимание уделяется искусственному интеллекту — это словосочетание упоминается целых 23 раза! Очевидно, что такой акцент сделан неспроста, учитывая, что технологии искусственного интеллекта существуют всего несколько лет. 
Источник изображения: AMD За более чем полувековое существование компании произошло многое — судебные иски против Intel, приобретение технологий ATI, приобретение лидера в производстве ПЛИС (PGA) компании Xilinx, использование чипов AMD в новейших игровых консолях и т.д. При этом продажи полупроводников выросли с $412 млрд в 2019 году до $574 млрд в 2022, а на технологиях AMD работают 140 суперкомпьютеров и 30% мировых серверов, сообщает издание Techspot. Однако в посте официального блога технический директор Марк Пейпермастер (Mark Papermaster) называет ИИ самым значимым технологическим прорывом за всю карьеру и подчёркивает вклад AMD в развитие этого направления. В частности, он пишет, что компания первой выпустила на рынок процессоры с искусственным интеллектом, интегрировав специальный нейронный блок (NPU) в процессор x86. Кроме того, Пейпермастер отмечает, что технологии ИИ активно применяются во внутренних бизнес-процессах AMD для повышения эффективности и смело заявляет о том, что искусственный интеллект окажет ещё большее влияние на общество, чем появление интернета. Не исключено, что акцент на ИИ в юбилейном посте мог быть связан со стремлением продемонстрировать тот факт, что компания не собирается ограничиваться прошлыми заслугами и традиционными направлениями бизнеса и полна решимости стать заметным игроком на новом перспективном рынке технологий искусственного интеллекта. И пусть пока доля AMD в этом сегменте не слишком велика — всё в мире меняется. В любом случае, 23 упоминания ИИ в посте явно многовато для технологии, которая появилась буквально пару лет назад и, очевидно, что за этим что-то стоит. SK hynix обмолвилась о разработке SSD объёмом 300 Тбайт
03.05.2024 [17:00],
Николай Хижняк
Компания SK hynix в рамках недавней пресс-конференции рассказал о перспективных разработках, среди которых оказался твердотельный накопитель объёмом 300 Тбайт. Новая разработка станет частью более широкого ассортимента продуктов и технологий компаний, предназначенных для дата-центров и ИИ-систем. 
Источник изображения: SK hynix По мнению SK hynix, совокупный мировой объём информации, генерируемой людьми и системами искусственного интеллекта к 2030 году достигнет значения 660 зеттабайт. Этот огромный объём данных необходимо где-то хранить, и в таком деле как раз пригодятся жёсткие диски объёмом 100 Тбайт и твердотельные накопители объёмом 300 Тбайт. О разрабатываемом SK hynix накопителе объёмом 300 Тбайт практически ничего неизвестно, за исключением того факта, что в ближайшие годы спрос на высокопроизводительные SSD большой ёмкости резко возрастёт. В связи с этим для различных задач потребуются как накопители большой ёмкости, так и высокопроизводительные флеш-массивы. Как предполагает портал Tom’s Hardware, SK hynix может вести разработку конкурента архитектуре системы хранения данных Samsung PBSSD, которая к настоящему моменту представляет собой флеш-массив объёмом 240 Гбайт, но обладает возможностями масштабирования до систем петабайтного класса. Подобные платформы обладают возможностью изоляции потоков данных при множественном доступе к накопителю, позволяя сохранить для разных нагрузок заданные для них уровни задержки и производительности. Согласно другому предположению, SK hynix может вести разработку конкурента 3,5-дюймовомым твердотельным носителям ExaDrive от компании Nimbus, которые могут хранить до 100 Тбайт информации. Правда, последние представляются весьма нишевыми продуктами и обладают низкой производительностью. Также разработка южнокорейской компании может представлять собой специализированный SSD в формате карты расширения PCIe. Однако опять же, носитель объёмом 300 Тбайт даже при использовании интерфейса PCIe 6.0 x16, скорее всего, будет обладать весьма низкой производительностью в расчёте на терабайт доступного пространства. Помимо SSD объёмом 300 Тбайт SK hynix также работает над множеством других продуктов, которые будут полезны для задач по обучению ИИ в масштабах ЦОД (высокопроизводительная память HBM4 и HBM4E, решения Pooled CXL, а также Processing-in-Memory (PIM)), для периферийного оборудования с поддержкой ИИ (память LPDDR6, GDDR7, PIM), а также устройств для локальной работы ИИ (память LPDDR6, GDDR7 и DDR5 высокой ёмкости). TSMC начала выпускать гигантские чипы для суперкомпьютера Tesla Dojo
03.05.2024 [16:47],
Алексей Разин
Недавнее упоминание TSMC о методах производства чипов с высокой степенью интеграции для суперкомпьютера Tesla Dojo, который Tesla будет использовать для развития своих систем искусственного интеллекта, имело вполне прагматичный повод. Как стало известно на этой неделе, TSMC уже приступила к производству чипов Tesla, использующих метод упаковки CoW-SoW.  По данным тайваньских СМИ, компания TSMC уже приступила к производству чипов Dojo D1 для нужд компании Tesla. По своей вычислительной производительности они будут превосходить существующие системы более чем в 40 раз. Новая технология упаковки позволяет создавать логические процессоры в масштабе целой кремниевой пластины типоразмера 300 мм. В массовом производстве TSMC собирается освоить данный метод упаковки и интеграции к 2027 году. На одной пластине процессоры Dojo объединяются в массив размером 5 на 5 штук. До 60 микросхем памяти типа HBM могут располагаться на такой кремниевой пластине. Tesla собирается вложить в развитие суперкомпьютера Dojo в Нью-Йорке не менее $500 млн. На этом пути её мешают различные препятствия. Например, в декабре прошлого года штат компании покинули два крупных специалиста по разработке данного суперкомпьютера. Предполагается, что запуск Dojo будет иметь критическое значение для вывода на рынок роботизированного такси Tesla, формальный анонс которого намечен на 8 августа текущего года. Если суперкомпьютер Dojo расположится в Нью-Йорке, то его вычислительный компаньон, построенный на ускорителях Nvidia, будет работать рядом со штаб-квартирой компании в штате Техас. Центр обработки данных в Остине будет потреблять до 100 МВт мощности. Глава Apple уверен, что ИИ будет работать на iPhone лучше, чем у других
03.05.2024 [11:58],
Владимир Фетисов
Не так давно руководство Apple провело виртуальную встречу с инвесторами, в рамках которой были озвучены финансовые результаты компании по итогам второго квартала 2024 финансового года. В собрании принял участие и глава Apple Тик Кук (Tim Cook), который поднял тему технологий на основе искусственного интеллекта и выразил уверенность в том, что у Apple есть преимущества, которые позволят её выделиться с функциями на базе генеративного ИИ на фоне конкурентов.  Говоря о ежегодной конференции WWDC 2024, которая состоится в следующем месяце, Кук сказал, что рад поделиться тем, над чем работает компания. Хотя он напрямую не сказал, что в iOS 18 появятся ИИ-функции, было отмечено, что Apple продолжает делать «значительные инвестиции» в развитие генеративных алгоритмов, и что компания уже скоро поделится со своими клиентами «некоторыми очень интересными вещами». Глава Apple добавил, что компания по-прежнему очень оптимистично настроена в отношении собственных возможностей в сфере генеративных нейросетей. Тим Кук и раньше упоминал, что Apple работает над созданием генеративных алгоритмов, но вместе с тем компания ведёт переговоры со сторонним разработчиками, включая Google, о применении их ИИ в своих будущих продуктах. На этом фоне глава Apple заявил, что у компании есть преимущества, которые позволят ей выделиться с функциями генеративным ИИ на на фоне конкурентов — задача непростая, ведь у многих новейших смартфонов ИИ-функции очень похожи. В качестве примеров таких преимуществ Кук отметил наличие нейронного сопроцессора в фирменных чипах Apple, плотную интеграцию программной и аппаратной составляющих, а также внимание компании к обеспечению конфиденциальности пользователей. «Мы верим в преобразующую силу и возможности искусственного интеллекта, и мы верим, что у нас есть преимущества, которые будут отличать нас в эту новую эпоху, включая уникальное сочетание бесшовной интеграции аппаратного и программного обеспечения с сервисами Apple, революционный Apple Silicon с нашим ведущим в отрасли нейронным сопроцессором, а также нашу непоколебимую ориентированность на обеспечение конфиденциальности, которая лежит в основе всего, что мы создаём», — заявил Тим Кук. По слухам, Apple работает над интеграцией нескольких функций на базе искусственного интеллекта в свои операционные системы. Ожидается, что некоторые из них будут представлены в рамках мероприятия WWDC в следующем месяце. Речь идёт о чат-боте, умных плейлистах в Apple Music и интеллектуальном помощнике в браузере Safari. Компания развивает собственные большие языковые модели для обеспечения работы ИИ-функций в автономном режиме, а также ведёт переговоры с OpenAI и Google для лицензирования их технологий и последующего использования в iOS 18. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться