







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Зачем нужны чиплеты, или Как вдохнуть новую жизнь в «закон Мура» за пределами 3 нм
Для современных чипов характерная плотность размещения базовых элементов интегральных схем (транзисторов) уже перевалила за 200 млн на 1 мм2. Само по себе это чрезвычайно много — и не совсем понятно, как эту плотность наращивать дальше, не вступая в противоречие с законами физики. Мало того, неуклонный рост числа транзисторов — более или менее равномерный в соответствии с «законом» (на самом деле самосбывающимся пророчеством) Гордона Мура — ведёт к непропорционально стремительному увеличению непрямых производственных затрат. Ещё немного — и индустрия попросту не сможет себе это позволить. Надо что-то делать, причём срочно! 
Составные чипы проектируются сегодня не только в двух, но уже и в трёх измерениях (источник: Intel) ⇡#Дорогое удовольствиеВо времена торжества «28-нм» техпроцесса — как наиболее на тот момент передового и миниатюрного — полная стоимость разработки СБИС по этим производственным нормам (именно полная, от лицензирования микроархитектуры до валидации готового предсерийного образца) составляла, по данным IBS, чуть более 51 млн долл. США. Понятно, что это средняя по рынку величина: спроектировать и поставить на поток какой-нибудь сетевой контроллер обходилось заметно дешевле; серверный ЦП или графический процессор — заметно дороже. 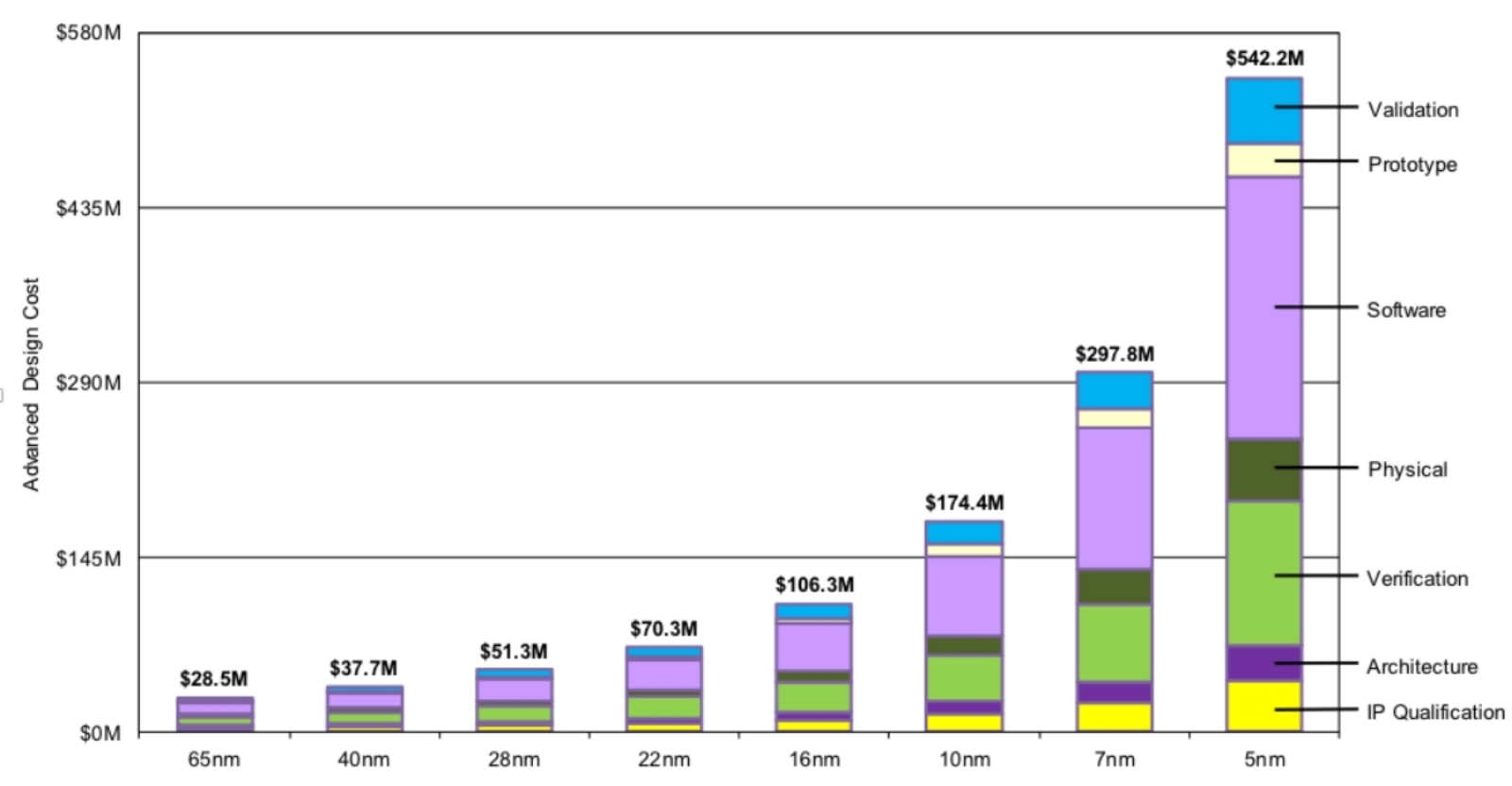
Себестоимость полной разработки новой СБИС, млн долл. США, в зависимости от выбранной для её изготовления производственной нормы. В каждом столбце выделены цветом составляющие затрат, снизу вверх: сверка прав на владение интеллектуальной собственностью (включая приобретение необходимых лицензий), разработка архитектуры, проверка её работоспособности, аппаратное обеспечение для разработки, плата за используемое в её ходе ПО, собственно прототипирование, валидация готового прототипа (источник: IBS) С переходом на «7-нм» техпроцесс те же самые процедуры в сумме подорожали почти до 300 млн долл., а в случае «5-нм» они уже требуют инвестиций в размере около 550 млн. Для условной средней, напомним, микросхемы. Если же говорить о наиболее актуальных на сегодня «3 нм», то ставка на эти производственные нормы влечёт за собой, по оценке всё тех же аналитиков IBS, совершенно умопомрачительные затраты на полный цикл разработки — вплоть до 1,5 млрд долл. в случае ГП. Растущая сложность СБИС проявляется, например, в том, что вручную спроектировать размещение миллиардов транзисторов оказывается попросту невозможно. Для этого давно используется специализированное ПО, чрезвычайно сложное в алгоритмическом плане. Кроме того, оно должно быть с гарантией готово к работе «из коробки», сразу после развёртывания на рабочих станциях инженерных дизайнеров. Цена ошибки здесь слишком высока: получить от разработчика исправляющий досадную оплошность патч уже после того, как на основе ошибочного проекта была изготовлена дорогущая фотомаска, — утешение сомнительное. Вот почему ПО для разработки микросхем с каждым новым шагом миниатюризации техпроцесса (и, соответственно, роста плотности транзисторов на поверхности микросхемы) становится всё дороже. 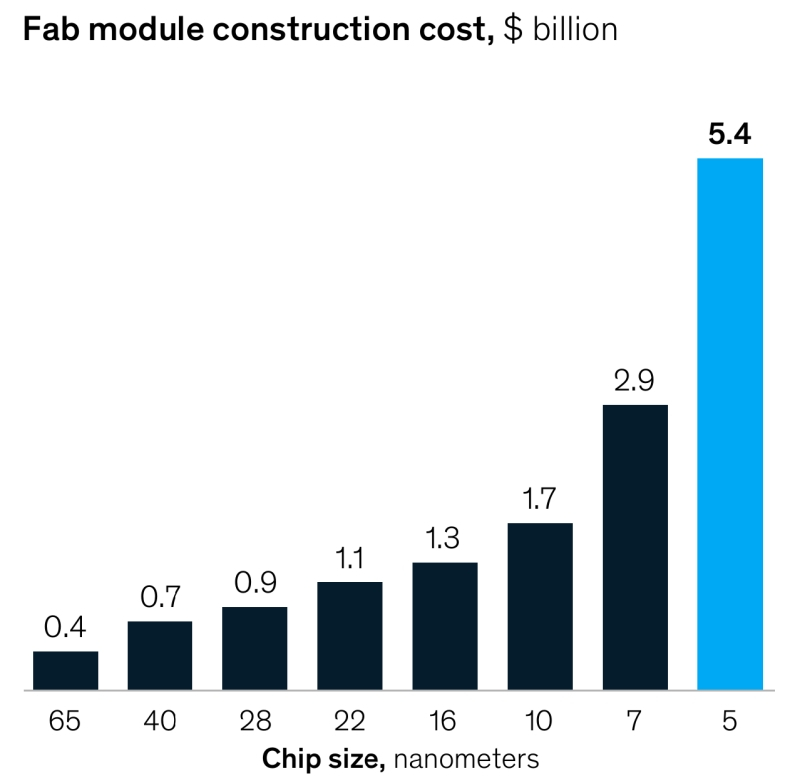
Рост инвестиций в постройку микропроцессорных фабрик, работающих по всё более миниатюрным производственным нормам, хотя и не так динамичен, как увеличение стоимости дизайна чипов, однако исчисляется уже не сотнями миллионов, а миллиардами долларов (источник: McKinsey) Аналогично растут — вместе с переходом к всё более компактным технологическим нормам — расходы и на верификацию созданного таким ПО дизайна, и на валидацию прототипов будущих серийных СБИС, т. е. на проверку соответствия их фактических функциональных характеристик расчётным. Кстати, и на этапе коммерческого производства приходится тратить немало времени и средств, чтобы выявлять на только что подвергнутой литографированию пластине-заготовке дефектные узлы вплоть до единичных нерабочих штрихов Шеффера. Задача эта по трудоёмкости вполне сопоставима с самим процессом изготовления такой пластины. Словом, мало того, что далеко не каждый чипмейкер планеты может позволить себе оборудование для изготовления микросхем по «5-нм» и более миниатюрным технологическим нормам, так ещё и не всякий fabless-разработчик располагает достаточными средствами для функционального проектирования — от эскизного наброска до формирования полного пакета документации, передаваемой чипмейкеру для выполнения заказа, — такого рода чипов. С экономической точки зрения слишком стремительный рост издержек разработчиков и изготовителей микросхем крайне невыгоден для рынка. Если у молодой амбициозной компании нет возможности вложить полтора миллиарда долларов в дизайн нового чипа, она не составит конкуренции де-факто образующим олигополию микропроцессорным монстрам — и у тех, в свою очередь, не появится стимулов к снижению себестоимости своих ставших чересчур громоздкими наработок. 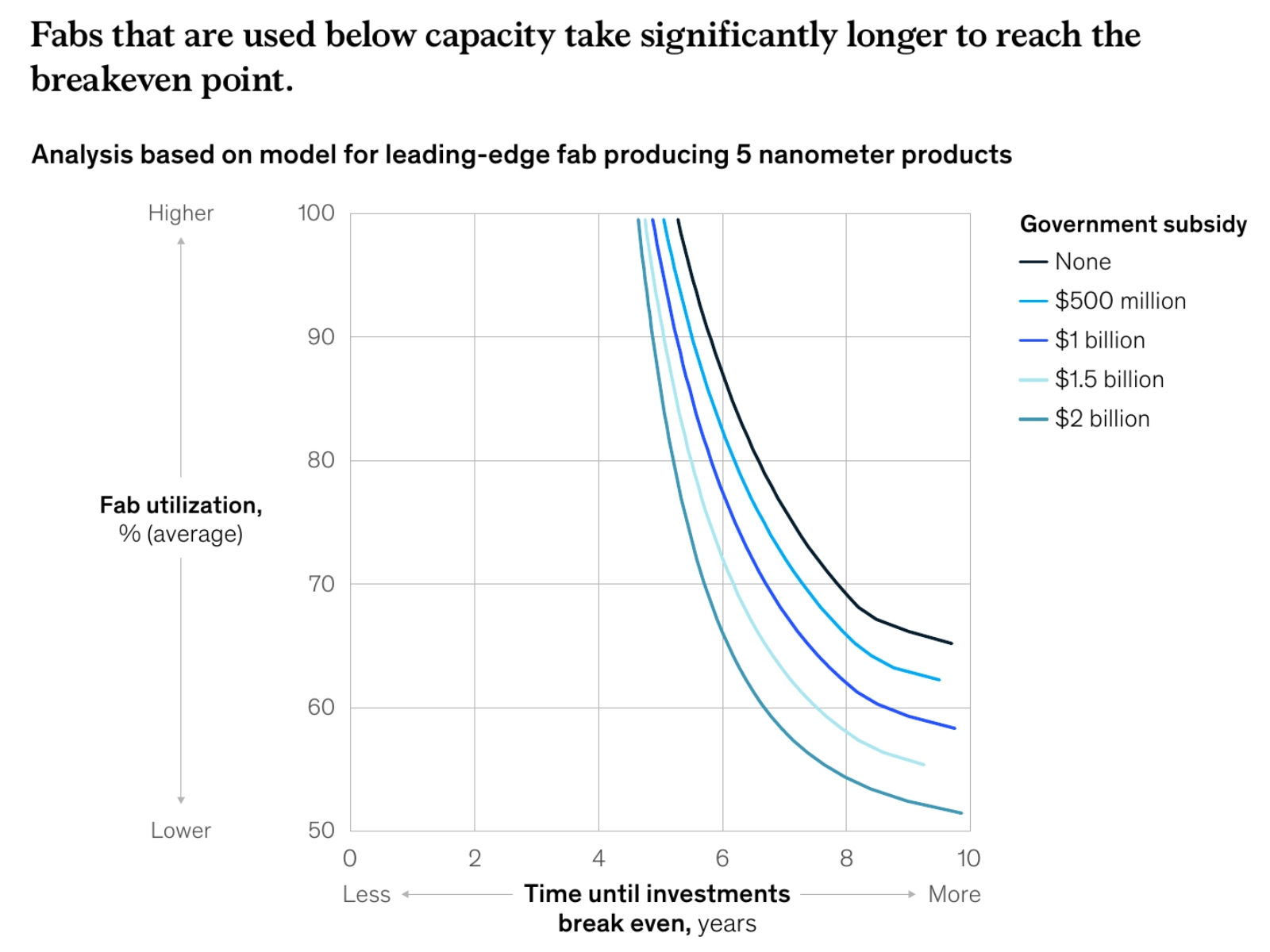
Исследование McKinsey свидетельствует, что чем выше средний уровень загрузки микропроцессорных фабрик заказами, тем быстрее достигается точка безубыточности (break-even point, когда расходы на организацию производства в точности компенсируются доходами) даже в отсутствие государственных субсидий (источник: McKinsey) В результате сохранения высоких цен на готовую продукцию (а в отсутствие конкуренции — зачем им снижаться?) поток заказов на СБИС по новейшим производственным нормам будет снижаться, сокращая доходы разработчиков и изготовителей микросхем. Это, в свою очередь, притормозит возврат капитальных инвестиций, сделанных как чипмейкерами в новое оборудование, так и fabless-проектировщиками в разработку передовых чипов. Тем самым непозволительно удлинятся циклы миниатюризации техпроцессов, и «закону Мура» будет грозить очередное переиздание в новой редакции. На сей раз вместо прежнего «удвоения числа транзисторов на наиболее передовом актуальном процессоре раз в 18 месяцев», а позже и «…раз в 24-36 месяцев», он будет самосбываться с темпом вроде «…раз в 48-60 месяцев», если не больше. 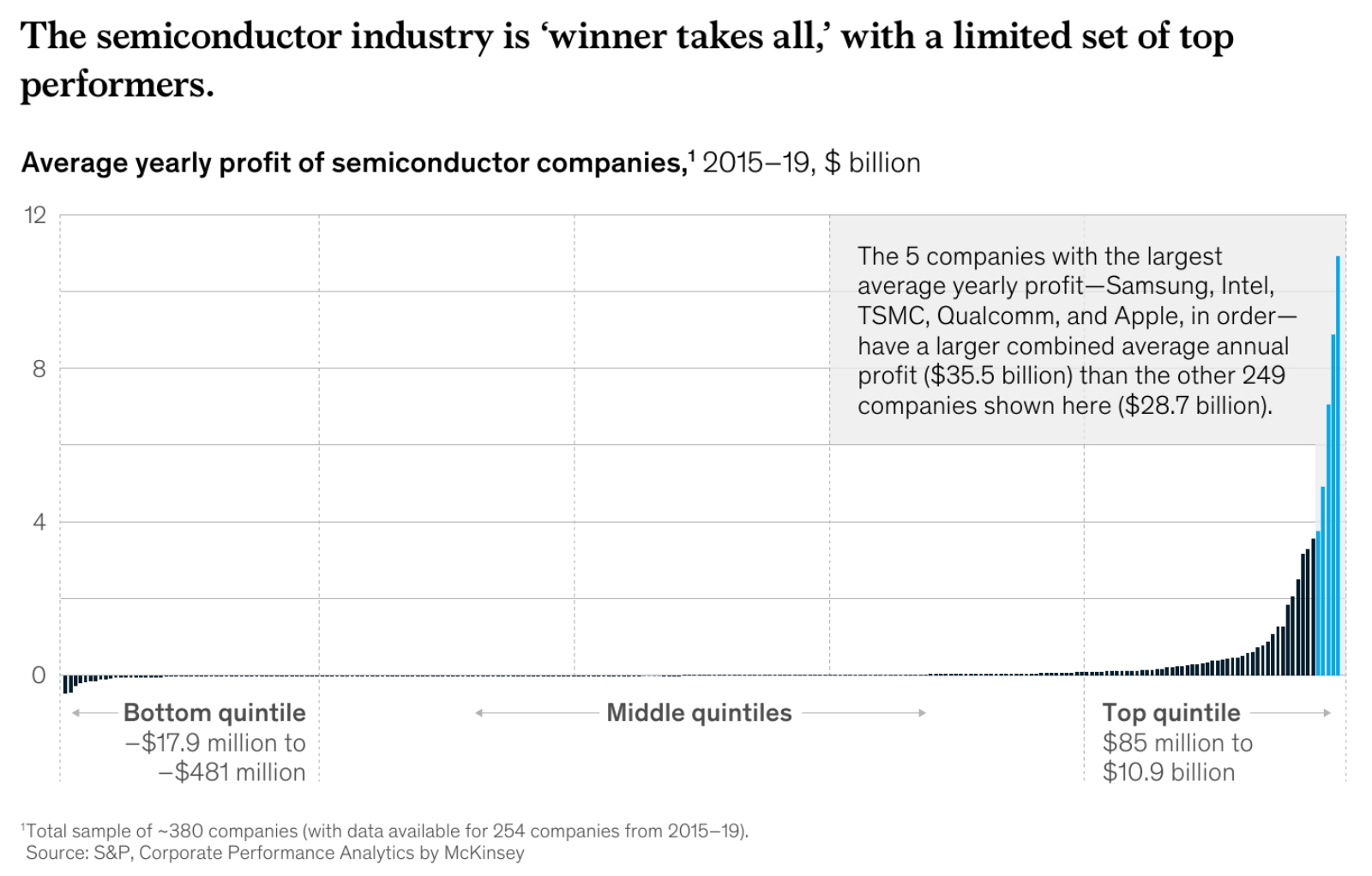
Мировая полупроводниковая индустрия сегодня сверхцентрализована — почти до состояния олигополии: первые пять компаний в этой отрасли по объёму среднегодовой выручки за 2015-2019 гг. превосходили оставшиеся 249 (всего их на планете около 380, но не по всем есть доступные данные) в сумме (источник: McKinsey) Указанная проблема носит системный характер: дальнейшее сокращение производственных норм остается возможным (на 2027 г. Samsung Electronics уже наметила начало серийного производства «1,4-нм» СБИС, например), — однако оно становится всё более и более экономически невыгодным. Вместе с тем потребность в неуклонном наращивании производительности микросхем при приблизительном сохранении их физических габаритов никуда не делась: её активно формируют такие перспективные направления высокотехнологичной индустрии, как смешанная реальность, 6G, высокоавтономный промышленный Интернет вещей. Уже появились рабочие прототипы сетевых контроллеров для оптоволоконных сетей, способных коммутировать потоки данных с плотностью более 1,8 Пбит/с — и нет сомнения, что процессоры, готовые подобные потоки генерировать, тоже вскоре начнут выпускаться серийно. 
Планарно-унитарный подход к разработке новых СБИС, при котором отдельные области единого полупроводникового кристалла выполняют различные задачи, уходит в историю (источник: NVIDIA) Вот только привычными нам сегодня, планарно-унитарными (в смысле размещения всех их базовых элементов, транзисторов, на плоскости единого полупроводникового кристалла), такого рода чипы, скорее всего, не будут. А будут с большой вероятностью либо составными (несколько отдельных планарных чипов с высокоскоростными шинами межсоединений внутри единого корпуса — такие и называют «чиплетами»), либо многоэтажными (несколько электрически сопряжённых транзисторных слоёв один над другим), либо некими комбинациями двух этих подходов (речь идёт о DSA — domain specific architecture; определяемой задачей архитектуре). Каждая из этих опций заслуживает отдельного вдумчивого рассмотрения, и начнём мы как раз с чиплетных СБИС — благо на сегодня это направление уже достаточно хорошо развито. ⇡#Микроэлектроника кусочкамиНа первый взгляд, экономический смысл перехода от унитарного чипа к собранному под крышкой общего корпуса набору менее функциональных, электрически и логически связанных мини-чипов (чиплетов) не представляется очевидным. Напротив: история развития, к примеру, смартфонов свидетельствует, что как раз замена разрозненными СБИС (отдельно процессор, отдельно контроллер памяти, дисплея и т. п.) на системы-на-кристалле обеспечила удешевление сборочного производства, снижение требований к занимаемому логическими устройствами объёму — и в целом немало способствовала прогрессу в данном секторе ИТ-рынка. 
Унитарные системы-на-кристалле особенно удобны для изготовления сверхкомпактных гаджетов, таких как эти подкожные биодатчики сантиметрового размера, разработанные в швейцарской EFPL — Федеральной политехнической школе Лозанны (источник: EFPL) Всё так: унитарный многофункциональный полупроводниковый кристалл действительно всем хорош — в конечном итоге, когда уже изготовлен, протестирован, признан годным и размещён внутри некоего гаджета. Вот только получить такой кристалл — задача нетривиальная, и она становится тем сложнее, чем миниатюрнее применяемый для изготовления СБИС техпроцесс. Один только пример: ведущий американский чипмейкер, осваивая техпроцесс «Intel 7» (в девичестве известный как «10 нм»), по данным TrendForce, до сих пор — по состоянию на конец октября 2022 г. — не продвинулся в увеличении доли выхода годных СБИС с литографированной пластины выше 55-60%. В результате массовый старт отгрузок чипов архитектуры Sapphire Rapids уже де-факто сдвинут с запланированного прежде IV кв. текущего года «на первую половину» (даже не первый квартал!) 2023-го. 
Фотомаска (reticle) на квадратной подложке кварцевого стекла со стороной 6 дюймов, применяемая при литографировании пластин по разработанным Intel техпроцессам «14 нм» и «10 нм» (источник: Intel) Если оставаться в рамках планарно-унитарной парадигмы, избежать чудовищных капитальных затрат на освоение всё более миниатюрных техпроцессов никак не удастся. Экстенсивный и, казалось бы, самый очевидный путь — увеличивать площадь кристалла, размещая на нём больше полупроводниковых элементов, изготовленных по прежним технологическим нормам, — чипмейкерам более недоступен, поскольку те и так уже работают с предельно крупноформатными фотомасками (reticles) площадью чуть более 800 мм2. Стандартная заготовка, на которой формируется фотомаска, представляет собой квадратную кварцевую пластину со стороной 6 дюймов — примерно 152 × 152 мм, — правда, фактически используемая для формирования изображения площадь на ней несколько меньше. Но после маски излучение внутри оптического тракта литографа проходит через систему многократно уменьшающих изображение линз (или зеркал — в случае EUV-процесса), в результате чего проекция исходного изображения на заготовку значительно сокращается — до прямоугольника со сторонами всего лишь 26 × 33 мм (858 мм2). 
Отражательная фотомаска для EUV-литографии внутри чипмейкерской установки (источник: TNO) Точные размеры итоговой проекции диктуются оптическими свойствами системы линз или зеркал, по которым распространяется экспонирующий заготовку свет: если маска чересчур велика, на её границах возникнут уже слишком сильные искажения. Новейшие EUV-аппараты с увеличенной численной апертурой (high-NA) вынуждены иметь дело с ещё более миниатюрными проекциями фотомасок — 26 × 16,5 мм — из-за особенностей гораздо более изощрённой, чем для агрегатов первого поколения, оптической системы с анаморфическими (неосесимметричными) линзами. Вот почему инженеры-микроэлектронщики вынуждены искать неэкстенсивные способы наращивания количества транзисторов внутри отдельно взятого микропроцессора. И превращение такого процессора, прежде цельного, в составной оказывается едва ли не наименьшим из зол. 
Мультимикросхемный модуль — multi-chip module, MCM — мейнфрейма IBM System z10, выпускавшегося в 2008-2011 гг. (источник: IBM) Да, при этом возникает острая необходимость организовать между образующими единую систему чиплетами высокоскоростную и сверхнадёжную шину — иначе ощутимо снизится эффективность их взаимной работы по сравнению с размещением тех же элементов на поверхности монолитного кристалла. Зато с экономической и технологической точек зрения — сплошные выгоды. Более миниатюрные и высокоспециализированные чиплеты проще изготавливать (в том числе на разных предприятиях, что может способствовать их дополнительному удешевлению) и легче тестировать. Вдобавок из соответствующих некоему единому стандарту чиплетов, словно из кубиков конструктора, несложно компоновать составные СБИС различной производительности и функциональности, экономя средства ещё и на разработке нишевых микропроцессорных решений. 
Наглядная иллюстрация того, насколько выгоден переход от монолитной СБИС к чиплетной сборке: по горизонтали — площадь микросхемы в квадратных миллиметрах, по вертикали — выход (yield) годных микросхем в % от общего их числа, размеченного на пластине-заготовке. Видно, что чем меньше площадь отдельного чипа, тем выше выход годных: если для одной СБИС площадью 360 кв. мм этот показатель около 15%, то для четырёх эквивалентных ей (с учётом технического допуска на разрез) чиплетов примерно по 100 кв. мм выход годных при прочих равных уже будет на уровне 37% (источник: WikiChip) Не случайно небезызвестное американское агентство DARPA ещё в 2017 г. инициировало программу CHIPS — не путать с CHIPS Act, законодательной инициативой, одобренной Конгрессом США в середине 2022 г. и призванной способствовать возвращению на американскую землю чипмейкерских производств. К участию в программе CHIPS привлечены такие разнородные учреждения, как производители классических микросхем (Intel, Northrop, Micross, UCLA), разработчики собственно чиплетов (Ferric, Jariet, Micron, Synopsys, Университет Мичигана) и создатели ПО для проектировки СБИС (Cadence и Технологический институт Джорджии). Акроним CHIPS раскрывается как Common Heterogeneous Integration and IP Reuse Strategies — «стратегии общей гетерогенной интеграции и повторного использования интеллектуальной собственности» (IP как раз и значит intellectual property в данном случае — имеется в виду раздельное лицензирование чиплетов их разработчиками). Главная задача здесь — преодолеть достигнутый на литографических машинах предел площади проекции фотомаски на заготовку (reticle limit) за счёт процесса, по сути обратного тому, что привёл к появлению систем-на-кристалле. А именно — разборки продолжающего функционировать как единое целое чипа на физически раздельные элементы, каждый из которых проектируется, изготавливается и проходит верификацию по отдельности. ⇡#Лики дезагрегацииГлобальная микропроцессорная индустрия вплотную приблизилась к осознанию необходимости скорейшего перехода на чиплеты, пожалуй, не ранее приснопамятного 2020 года — однако связано это было не со спровоцированным коронавирусом спадом в мировой экономике, а с достижением чипмейкерами вполне определённого технологического предела. «Когда люди начали работать над техпроцессами за рубежом 3 нм, это породило множество дискуссий, итогом которых стало деятельное инвестирование во множество чиплетов, или по сути в деагрегацию системы-на-кристалле», — так описывал зарождение индустриального консенсуса главный директор по управлению продуктами в компании Cadence Винай Патвардан (Vinay Patwardhan). 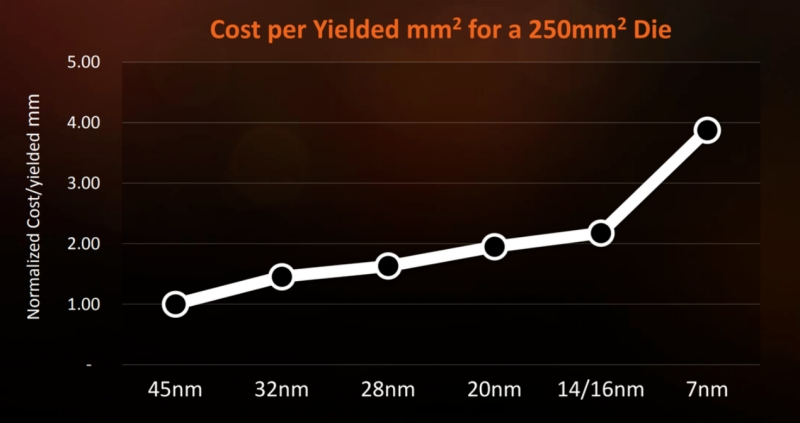
Себестоимость изготовления чипов в пересчёте на 1 кв. мм полученных на выходе годных (только годных!) СБИС для условного полупроводникового кристалла в 250 кв. мм, литографируемого по неуклонно сокращающимся производственным нормам, обходится всё дороже. За единицу принята такая себестоимость для «45-нм» техпроцесса (источник: AMD) Известны разные способы разделить исходно цельную микросхему на логические блоки, более компактные по размерам и простые в изготовлении. Предложенная разработчиками из Synopsys классификация разделяет подходы к проектированию составных чипов на четыре крупные группы:
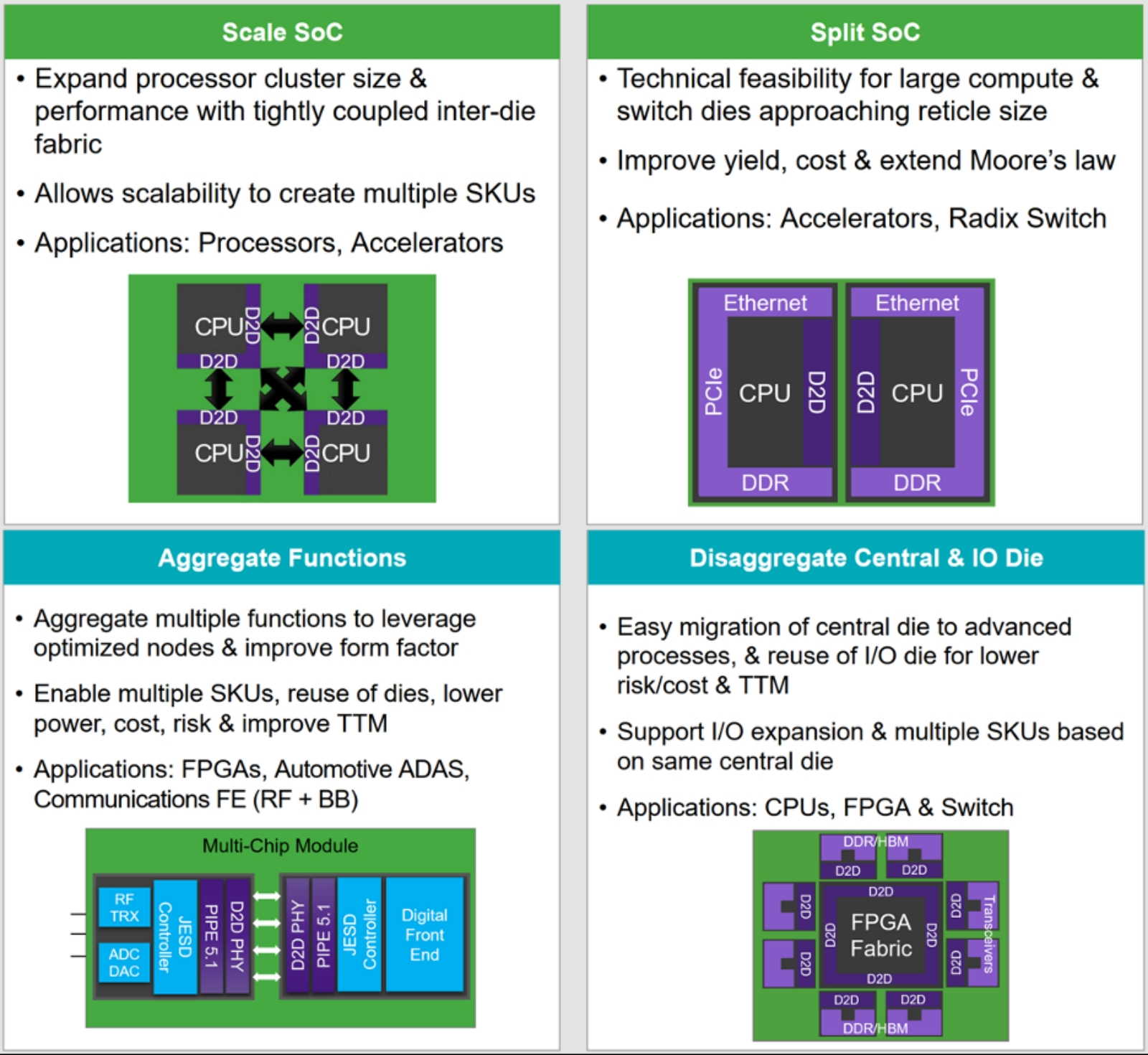
Наглядная классификация составных микросхем по типам (источник: Synopsys) По сути, концепция разведения внутренних и периферийных функций полупроводниковой системы была реализована задолго до появления самой идеи чиплетов. Ведь памятный многим «северный мост» в составе чипсетов на системных платах ПК не такого уж давнего прошлого как раз и принимал на себя сопряжение ЦП с подсистемой памяти и периферией, и при этом был выполнен по куда менее прогрессивным технологическим нормам, чем взаимодействующие с ними центральные процессоры. Безусловно, решение одной проблемы (reticle limit), как это обычно и бывает в инженерном деле, моментально порождает другую, а именно — необходимость обеспечить надёжные и высокоскоростные межсоединения (D2D) внутри составного чипа. По счастью, задача эта на сегодня вполне решаема — по крайней мере, цена её решения существенно ниже предполагаемого объёма инвестиций в значительное увеличение площади проекции фотомаски на полупроводниковую заготовку. 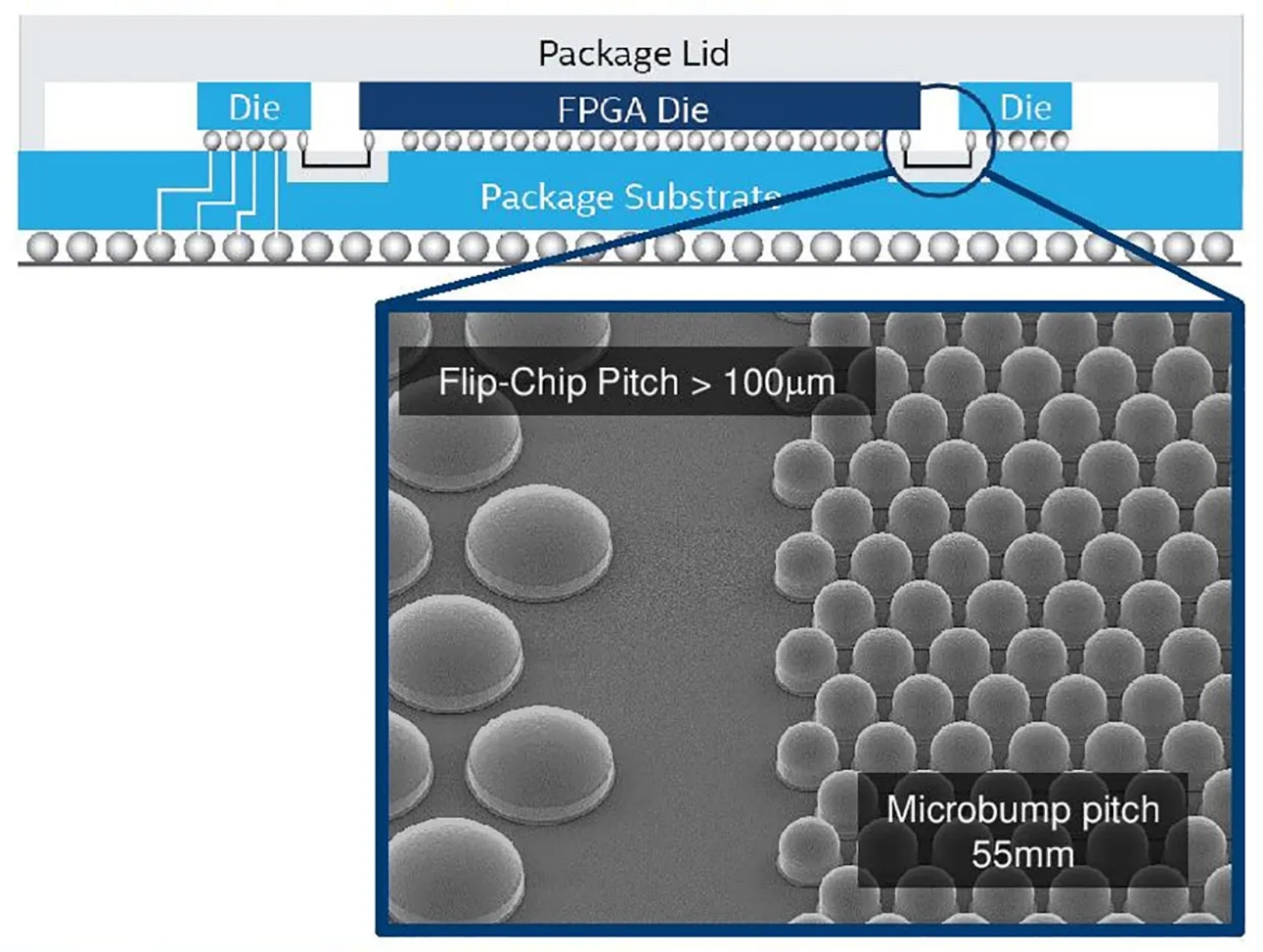
Межчиплетный «мост» EMIB представляет собой крохотную кремниевую прослойку между соединяемыми микросхемами и/или внешними шинами, густо усеянную контактами-микропупырышками, microbumps (источник: Intel) Более того, разработка эффективных D2D оказалась делом настолько перспективным и сравнительно легкодостижимым, что ею параллельно занялись — и с успехом достигли цели — сразу несколько ведущих полупроводниковых компаний планеты. И это уже само по себе становится проблемой: реализуемые сегодня на практике интерфейсы чиплетных межсоединений по большей части проприетарные, что делает их заведомо несовместимыми. У Intel есть EMIB (embedded multi-die interconnect bridge), у AMD — Infinity Fabric, у NVIDIA — NVLink, у Qualcomm — Qlink, и, судя по всему, это только начало. К примеру, разработчики из материкового Китая, последовательно отрезаемые всё новыми санкциями Минторга США от магистрального пути развития микропроцессорных технологий, почти наверняка возьмутся (если уже не принялись) за разработку собственного D2D-интерфейса. Впрочем, даже если бы в мире существовал общепризнанный стандарт межсоединений внутри планарных составных микросхем, сама упаковка чиплетов в общий корпус — включая точные габариты гребёнок контактов (точнее, почти полусферических контактных «пупырышков», bumps) и размеры отдельных чиплетов — не стандартизована на индустриальном уровне. Что, в свою очередь, до крайности затрудняет гипотетическую сборку составного чипа из компонентов, независимо изготовленных на различных предприятиях. 
Разработанная французским исследовательским центром CEA-Leti в 2020 г. сборка 96-ядерного процессора из 6 чиплетов, для которой обеспечена пропускная способность межчиплетных соединений на уровне 3 Тбит/с на каждый квадратный миллиметр. D2D-«моста» при задержке сигнала не более 0,6 нс на 1 погонный миллиметр (источник: CEA-Leti) С точки зрения отдельных разработчиков и/или чипмейкеров это вполне оправданно: с какой стати они должны делиться с конкурентами интеллектуальной собственностью? Но, напомним снова, для микропроцессорной отрасли в целом переход к очередной технологической ступени раз за разом обходится всё дороже — по вполне объективным техническим причинам. И чем больше средств на этом пути удастся сэкономить (в том числе за счёт реализации единых открытых стандартов), тем скорее выйдет вернуть вложенные в новое оборудование инвестиции. А ведь без их возврата и получения прибыли сделать следующий шаг, подтвердив в очередной раз «закон Мура» со всеми полагающимися оговорками, коммерческим предприятиям — чипмейкерам и fabless-разработчикам — не удастся, насколько значимой ни была бы оказываемая им на государственном уровне поддержка. Значит, единый — или хотя бы признаваемый всеми лидерами индустрии — чиплетный стандарт просто-таки обречён на появление. ⇡#Привет из мира кубиковСтандартизация внутрикомпьютерной шины коммуникаций, PCIe, обеспечивает значительную свободу в плане выбора отдельных компонентов для решения различных задач — это может подтвердить каждый, кто хоть раз собственноручно менял в настольном ПК графический адаптер или добавлял М.2-накопитель в свободное гнездо на системной плате ноутбука. Аналогичную свободу для разработчиков чипов на основе чиплетов призван обеспечить стандарт UCIe — Universal Chiplet Interconnect Express — на данный момент существующий в версии 1.0. В число организаций, занятых разработкой этой спецификации и готовых придерживаться её в своих перспективных продуктах, входят AMD, Arm, Intel, Qualcomm, Samsung Electronics и TSMC. 
Стандарт UCIe необходим для разработки и продвижения подлинно гетерогенных составных микросхем, базирующихся на открытой чиплетной экосистеме (источник: UCIe Consortium) Главной целью стандартизации D2D-шины для обеспечения взаимодействия между чиплетами прямо указано создание обширной экосистемы — с прицелом даже на нечто вроде B2B-маркетплейса, — которая позволяла бы под любую задачу заказчика, сколь угодно узкую, собирать из доступных унифицированных компонентов заведомо работоспособный составной чип. Принцип ровно тот же самый, что и для любого детского конструктора из кубиков (и деталей более сложной формы), только роль гарантированно совместимых штырьков и впадин здесь играет интерфейс UCIe. Полоса пропускания, предоставляемая данным интерфейсом, зависит от решаемых конкретными чиплетами задач. Для базового подстандарта UCIe 1.0 она может составлять от 28 до 224 Гбайт/с на 1 мм длины физической шины, для более скоростного варианта (advanced) — от 165 до 1317 в тех же единицах. Напомним, что стандарт PCIe версии 4.0 обеспечивает 16 Гт/с (гигатрансферов в секунду — имеется в виду передача информации «брутто», со всеми служебными и контрольными битами) для одиночного канала, что эквивалентно предельной пропускной способности полезных данных чуть меньше 2 Гбайт/с. 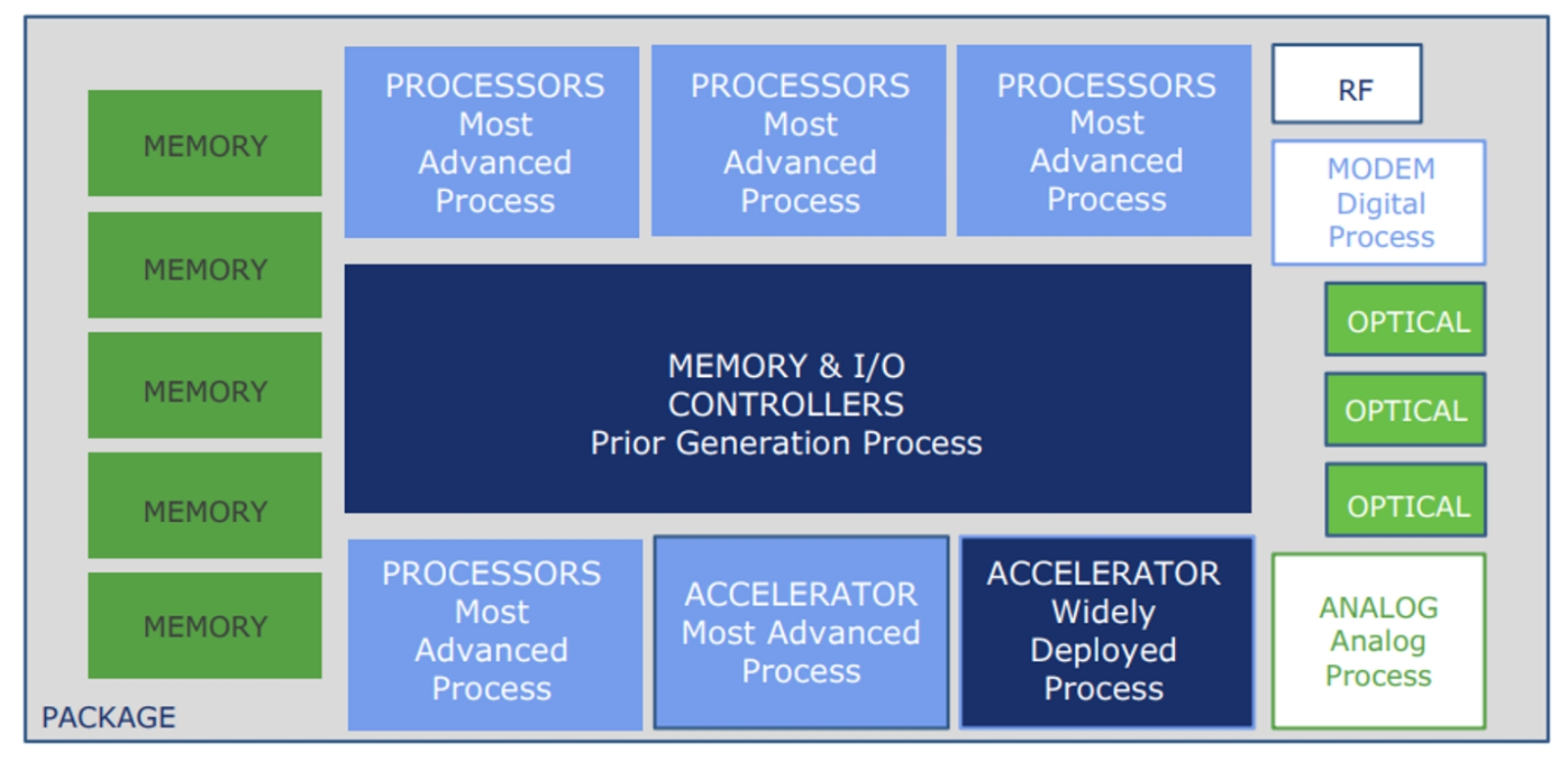
Одно из важнейших преимуществ UCIe — сопряжение независимых (но соответствующих этому стандарту, разумеется) функциональных блоков самого различного назначения в виде чиплетов (источник: UCIe Consortium) Типичная латентность для PCIe на характерных для межчиплетных расстояний дистанциях достигает 20 нс, тогда как для UCIe 1.0 она на порядок меньше. Эффективность передачи данных — затрачиваемая на перенос одного бита энергия — в случае базового подстандарта UCIe 1.0 заявлена на уровне 0,5 пДж (пикоджолулей), advanced-варианта — и вовсе 0,25 пДж/бит, что также более чем на десятичный порядок лучше, чем для PCIe. Идеал, к которому стремятся поддерживающие UCIe чипмейкеры и fabless-разработчики, предполагает как раз функциональную кластеризацию исполняемых чиплетами функций — причём в достаточно мелкой, если можно так выразиться, нарезке. Смысл в том, чтобы заведомо минимизировать себестоимость каждого отдельного блока, позволяя разработчикам подбирать подходящую комбинацию чиплетов, функционально соответствующую практически любой сколь угодно сложной монолитной СБИС. 
Составной 64-ядерный процессор EPYC (источник: AMD) На уровне логики работы практически не будет разницы между цельной и составной микросхемами — благодаря высокой пропускной способности и малой латентности UCIe, — а обходиться инженерный дизайн и производство микросхем на основе чиплетов станут заведомо дешевле. По свидетельству представителей AMD, которая фактически ещё в первом поколении процессоров Zen реализовала чиплетную технологию (устанавливая от 4 до 8 ядер Zeppelin в десктопные ЦП, до 32 — в серверные), каждый монолитный 32-ядерный процессор обходился бы ей на 70% дороже составного. Впрочем, точно так же и экономическая эффективность изготовления чиплетов в литографических машинах выходит ощутимо выше таковой для монолитных СБИС (если речь идёт о конечных продуктах с сопоставимым числом транзисторов). Взять хотя бы такой крайне неприятный, но неизбежный момент, как образование в ходе литографического процесса дефектных транзисторов и/или соединяющих их в логические контуры проводников. 
Продемонстрированный в ходе Computex 2021 прототип процессора Ryzen 9 5900 включал даже вертикально интегрированные чиплеты кеш-памяти третьего уровня 3D V-Cache (источник: AMD) В ходе инспекции по завершении производственного процесса дефектные участки выявляются и блокируются: если полностью неработоспособным оказывается, к примеру, одно или несколько процессорных ядер, такой ЦП обычно квалифицируется как менее производительный и реализуется, соответственно, дешевле. Но в этом случае вендор получает хоть какую-то прибыль, тогда как критически высокая плотность дефектов на несдублированном участке полупроводниковой схемы (скажем, в области, отведённой под кеш-память) может привести к полной выбраковке такой СБИС. Сплошной убыток! Чиплетная же технология благодаря полной взаимозаменяемости функциональных кластеров если не полностью снимает проблему нестопроцентного выхода годных чипов с каждой пластины, то в значительной мере её нивелирует. Для изготовления каждого составного процессора или иной схемы исходно отбираются заведомо работоспособные чиплеты, причём ровно в том ассортименте, который необходим именно в данном конкретном случае. А поскольку число транзисторов в каждом чиплете по современным меркам не слишком велико, и доля выхода годных СБИС такого рода с пластины-заготовки окажется выше, чем для планарно-унитарных огромных чипов, и валидация каждого чиплета будет требовать меньше времени. 
Микрофотографии фрагментов D2D-«моста» EMIB (на схеме в верхней части рисунка — узкая серая полоска в толще подложки под чиплетами Die1 и Die2): дистанция между соседними контактами-пупырышками (bumps), соединяющими чиплеты и подложку, — 55 мкм, между более крупными контактами, при помощи которых составной процессор взаимодействует с гнездом (сокетом), — 130 мкм (источник: Intel) Более того, вышедший из строя чиплет в принципе возможно заменить. Да, это будет несколько сложнее, чем переустановить видеокарту в настольном ПК; потребуется специальное оборудование и, возможно, прямое участие чипмейкера либо авторизованного им сервисного центра, располагающего кадрами соответствующей квалификации. Но это выводит рынок СБИС на совершенно новый уровень, производя на нём революцию, подобную той, что когда-то вознесла «IBM-совместимые» ПК на высоту, недосягаемую для прочих соперничавших с ними — закрытых — архитектур. Притом, что важно, проприетарным разработкам ведущих fabless-дизайнеров планеты по-прежнему ничто не угрожает: никто не отнимет у них права создавать собственные действительно уникальные, защищённые патентами логические узлы. Просто сегодня какая-нибудь Apple или Qualcomm вынуждена, проектируя свои системы-на-кристалле, снова и снова интегрировать в них (помимо собственно инновационных разработок) давно отлаженные, доведённые практически до совершенства универсальные узлы: контроллеры памяти, ввода-вывода и т. п. Чиплетная же технология позволит разработчикам сосредоточиться на создании действительно прогрессивных СБИС, привлекая для реализации стандартной функциональности созданные на стороне другими компаниями, но заведомо совместимые блоки. ⇡#Гетерогенность — это выгодноПроектируя свои составные чипы Zen первого поколения, разработчики AMD впервые в истории компании применяли «14-нм» производственные нормы. Переход к Zen 2 логично сопровождался переориентацией на «7-нм» технологию, наиболее на тот момент передовую из освоенных нынешним лидером чипмейкерской индустрии — тайваньской компанией TSMC. Однако в процессе масштабирования системы-на-кристалле Zeppelin, так удачно исполнявшей свою роль в микросхемах Zen первого поколения, выяснилось, что формальное сокращение производственной нормы вдвое вовсе не приводит к двукратному же уменьшению площади готового чиплета. Вместо этого «7-нм» микросхема окажется всего лишь примерно на 28% меньше «14-нм». 
3D-рендер составного чипа, который может содержать в том числе и разнородные по производственным нормам изготовления чиплеты (источник: Intel) Причина этого кажущегося парадокса довольно проста: логические элементы СБИС, те самые штрихи Шеффера и составленные из них схемы, исправно сокращаются в размерах вдвое при двукратной миниатюризации техпроцесса. Но эти элементы занимают не более 56% общей площади ядра Zeppelin. Всё остальное приходится на упоминавшиеся уже выше SerDes, DDR PHY и прочие физические интерфейсы, связывающие чиплет с периферийными для него устройствами. Вот здесь-то и кроется главная неприятность: поскольку внешние габариты таких интерфейсов жёстко заданы линейными размерами гребёнок соответствующих контактов, нет никакого смысла сокращать физические размеры транзисторов, обеспечивающих их работу на уровне процессорной логики. То есть сократить-то можно, но тогда придётся оставить между ними огромные (по меркам уменьшенного вдвое техпроцесса) зазоры, что в итоге почти сводит на нет выгоды от перехода к новой, более прогрессивной производственной норме. 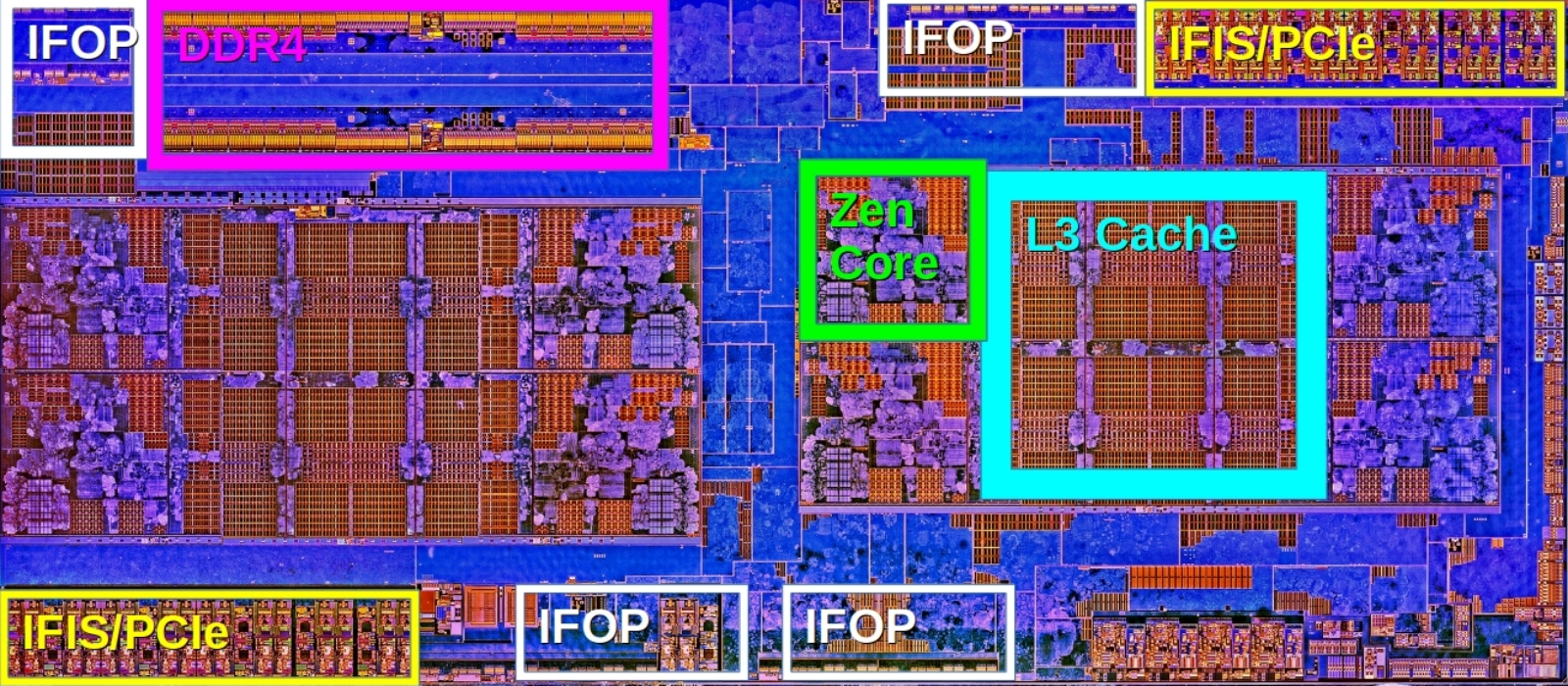
Система-на-кристалле Zeppelin содержит два вычислительных кластера с четырьмя ядрами Zen и кеш-памятью L3 в каждом, которые масштабируются с «14 нм» на «7 нм» очень хорошо, тогда как прочие элементы — интерфейсы SerDes Infinity Fabric On-Package (IFOP), Infinity Fabric InterSocket (IFIS), Server Controller Hub (SCH) и пр. — уже не очень (источник: AMD) Дальше — больше: при переходе к «5-нм» и более миниатюрным техпроцессам, как показывает практика, ячейки памяти SRAM (формирующие процессорный кеш) масштабируются не так хорошо, как штрихи Шеффера, из которых собраны логические вентили и более крупные вычислительные структуры самого ЦП. По оценке самой TSMC, смена технологической нормы N7 («7 нм») на N5 («5 нм») ведёт к сокращению площади, занимаемой логическими элементами на поверхности кремниевой подложки, примерно в 1,8 раза, занимаемой ячейками SRAM — в 1,35 раза, а аналоговыми структурами — и вовсе всего лишь в 1,2 раза. Имеется в виду, что дистанция между активными полупроводниковыми элементами в двух последних случаях масштабируется значительно хуже, чем габариты самих этих элементов. Может показаться, что не слишком внушительное сокращение площади чипа при переходе к более миниатюрному техпроцессу — не самая серьёзная проблема: СБИС ведь всё равно становится меньше прежнего, пусть лишь на 30%, а не вдвое, — значит, таких микросхем на пластине-заготовке в любом случае окажется больше, чем было на предыдущем технологическом этапе. Но здесь опять невозможно не принимать в расчёт экономические соображения, поскольку чипмейкерское производство — предприятие коммерческое. 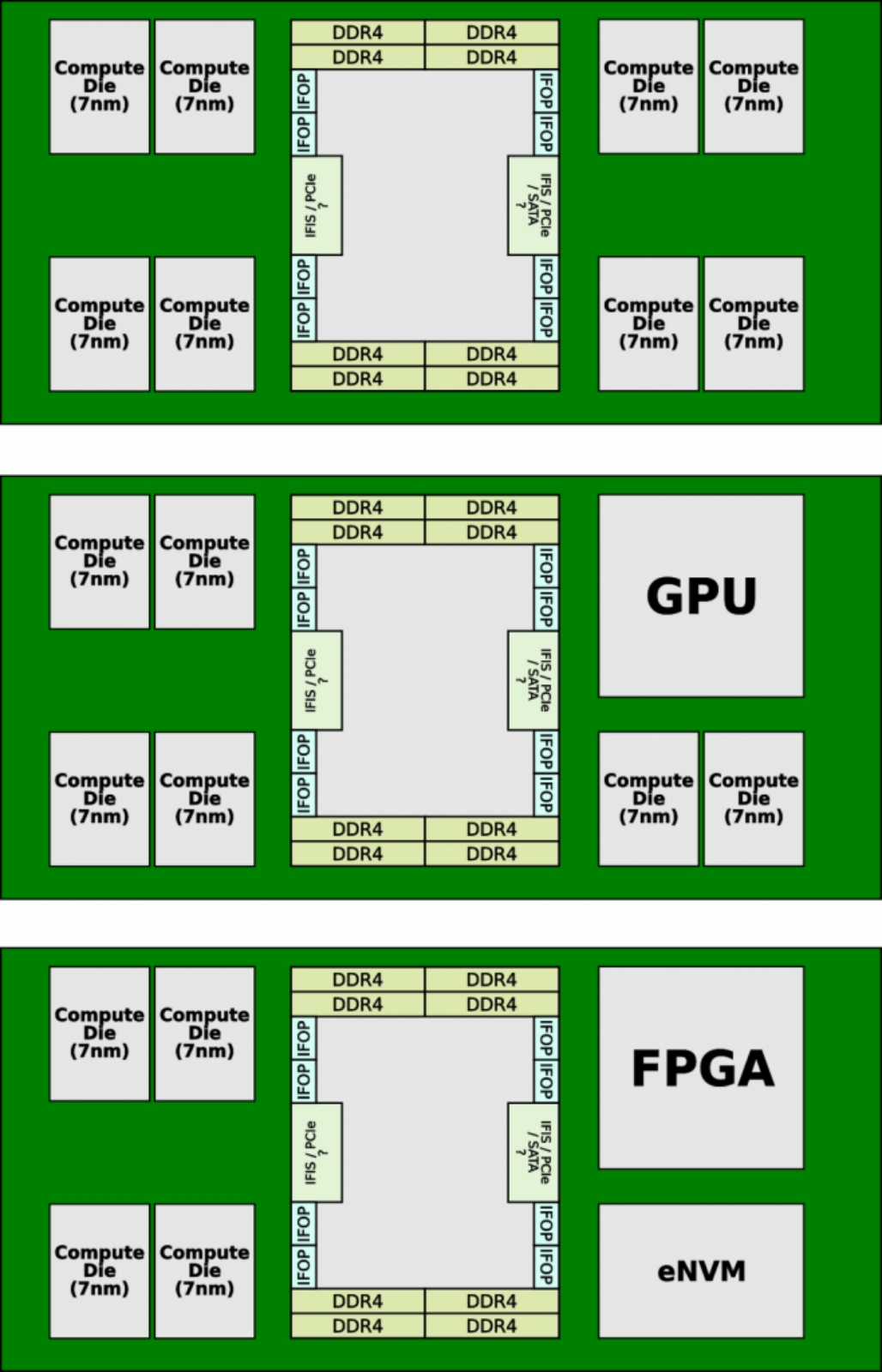
Чиплетная технология позволяет свободно комбинировать гетерогенные функциональные блоки внутри составной микросхемы в зависимости от её предназначения (источник: AMD) Себестоимость организации серийного выпуска микропроцессоров по всё более миниатюрным производственным нормам ощутимо растёт на каждой стадии. Судить об этом можно хотя бы по впечатляющему росту цен на соответствующие литографические машины, а ведь помимо них чипмейкерам требуются на каждом этапе и более дорогостоящие дефектоскопы, например, — и ими одними дело также не ограничивается. В итоге, если смена технологической нормы обеспечит двукратное сокращение площади СБИС (и, соответственно, вдвое больший выход годных чипов с пластины), это ещё более или менее приемлемо с точки зрения компенсации издержек. Когда же выросший в цене по меньшей мере вдвое производственный процесс позволяет получать лишь на треть больше микросхем с каждой заготовки, это неизбежно ввергнет чипмейкера в прямые убытки. Кстати, до сих пор молчаливо подразумевалось, что не связанные непосредственно со сменой техпроцесса затраты на полупроводниковое производство остаются неизменными по себестоимости на длительных интервалах времени, — однако это далеко не так. EUV-фотолитография значительно более энергоёмка, чем DUV, а цены на энергию в мире сегодня демонстрируют явную тенденцию к росту. 
Метаморфозы (слева направо) грубой кремниевой отливки в цилиндр, из которого затем нарезаются пластины для литографирования в чипмейкерских машинах (источник: Sil'tronix Silicon Technologies) Кроме того, неуклонно дорожают сами кремниевые пластины-заготовки: по оценке экспертов China Times, сделанной весной 2022 г., к 2024-му цена 12-дюймовой пластины в оптовых поставках впервые в истории преодолеет рубеж 200 долл. США за единицу, увеличившись с ныне актуальных значений на 20-25%. И это, обратим внимание, мартовский прогноз, не учитывавший ещё резкий всплеск промышленной инфляции в наиболее развитых экономиках мира, игнорировать который осенью текущего года уже невозможно. С техпроцессом «3 нм» ситуация ещё сложнее: если на TSMC переход от N7 к N5 обеспечивал сокращение площади логических участков микросхем максимум в 1,87 раза, то смена N5 на N3, как ожидалось уже в 2020 г. (ещё до фактического запуска новых линий), приведёт к менее масштабному уменьшению этого параметра — в 1,7 раза. На деле же в конце 2021 г., когда работа серийных линий N3 начала налаживаться, стало понятно, что сократить площадь логической части чипа при масштабировании с производственной нормы N5 удаётся не более чем в 1,6 раза. 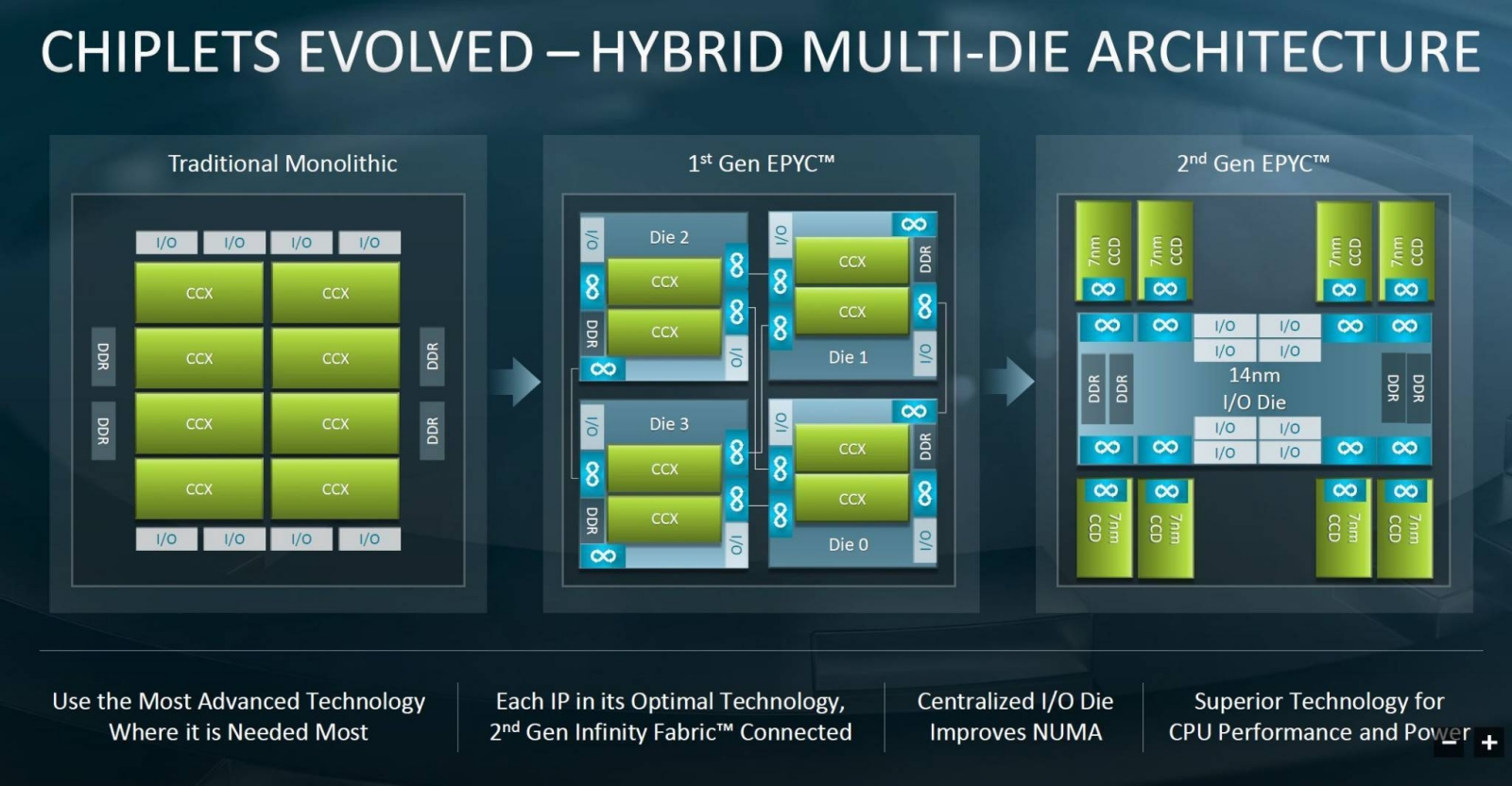
Эволюция подходов AMD к разработке процессорных чипов: от монолитных к составным гетерогенным (источник: AMD) Собственно, именно по этой причине второе поколение процессоров AMD EPYC представлено не просто составными чипами, но гетерогенными чиплетными сборками — комбинациями изготовленных по «7-нм» производственным нормам процессорных ядер и «14-нм» коммуникационных блоков, включающих контроллеры памяти и ввода-вывода. Да, отказ от перевода части элементов микросхемы на более миниатюрный техпроцесс ведет к повышенным энергетическим аппетитам составного чипа. Однако выигрыш в себестоимости — полученный за счёт того, что миниатюризации подвергаются по сути лишь хорошо масштабируемые элементы полупроводниковой логики, — позволяет удерживать цену готового изделия в разумных пределах. Благодаря чему, в свою очередь, и разработчик СБИС, и её изготовитель остаются в прибыли — и имеют возможность производить новые инвестиции в ещё более перспективные разработки. ⇡#Разделить, чтобы собратьСоставные микросхемы, таким образом, имеет смысл компоновать из чиплетов, оптимизированных (в плане применяемого для их выпуска техпроцесса) для выполнения тех или иных функций. Однако помещённые в единый корпус чиплеты необходимо между собой соединять, и само по себе это представляет определённую технологическую проблему — даже если оставить пока в стороне вопрос стандартизации D2D-интерфейсов, речь о котором шла чуть ранее. 
Составные серверные ЦП семейства Sapphire Rapids-SP из IV поколения Xeon Scalable сложены из «плиток» (tiles — термин, используемый Intel для собственных разработок вместо chiplets), соединённых «мостами» EMIB (источник: Intel) Дело в том, что внутренние контакты, соединяющие отдельные транзисторы, штрихи Шеффера и более крупные логические узлы внутри отдельной СБИС, слишком малы по габаритам, чтобы возможно было просто вывести их на край элемента составной микросхемы для соединения с другими подобными элементами. А значит, необходимо образовать на этом самом краю дополнительные полупроводниковые структуры, которые служили бы мостиками между внутренней логикой чиплета и гребёнкой контактов — существенно макроскопических, если сопоставлять их с габаритами внутренних проводников, — предназначенной для формирования межчиплетных соединений. Уже одна только эта процедура и усложняет проектирование составных СБИС (а следовательно — удорожает его; опять-таки, безотносительно к тому, стандартизованы используемые D2D-соединения или нет), и требует некоторого увеличения площади каждого отдельного чиплета — в среднем примерно на 10%, если сравнивать с аналогичным по функциональности фрагментом монолитной планарно-унитарной СБИС. Важно также, что выбор конкретного способа реализации межсоединений напрямую влияет на пропускную способность D2D и, следовательно, на производительность составного чипа в целом. 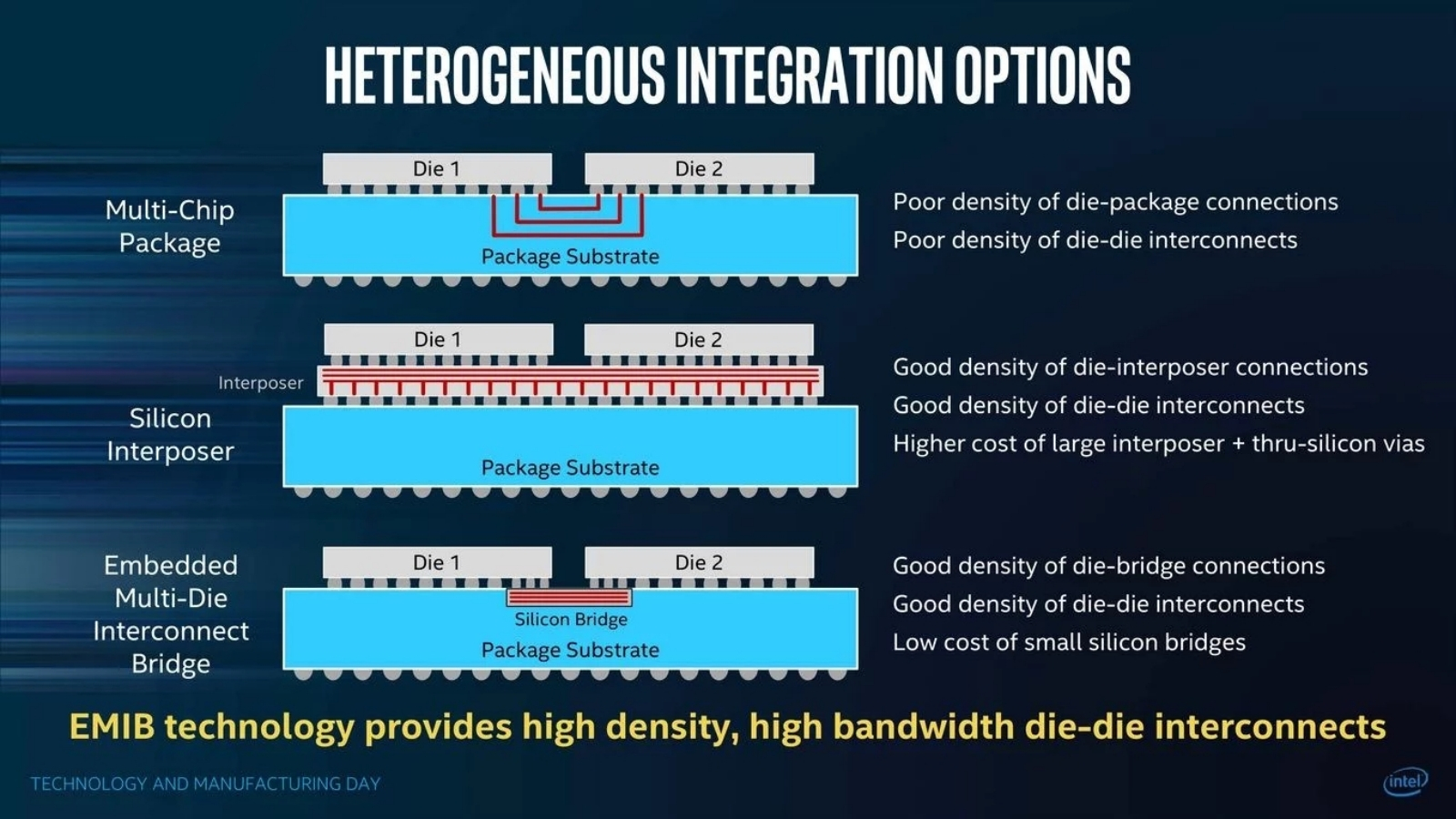
Различные способы интеграции гетерогенных чиплетов и их особенности (источник: Intel) Наиболее прямолинейно межсоединения внутри чиплета организуются по тому же принципу, как и внутри многослойной системной платы: этот способ описывается как 2D-interconnect или multi-chip package (MCP). Токоведущие дорожки внутри субстрата, на котором размещены чиплеты, тянутся на единицы и десятки миллиметров, причём никаких особенных технологических ухищрений от разработчиков в данном случае не требуется: малая длина проводников сама по себе гарантирует невысокие задержки и минимальное рассеяние передаваемых по ним сигналов. AMD Infinity Fabric, основа чиплетных архитектур Zen 2 и Zen 3 для настольных, так и для серверных процессоров, представляет собой именно 2D-межсоединение — и свою задачу выполняет, как можно судить по показателям производительности этих ЦП на современных задачах, вполне достойно. Впрочем, задержки при обращении к памяти (латентность) составных процессоров, организованных по принципу MCP, всё-таки достаточно велики, если сравнивать с монолитными чипами. Плюс, едва ли не самое главное, плотность контактов чиплета с подложкой в случае 2D D2D относительно невысока — примерно соответствует плотности поневоле макроскопических «ножек» привычных всем процессорных упаковок. Решить эти проблемы призвано кремниевое межсоединение (silicon interposer), относящееся уже к категории 2.5D. 
Принцип объёмной интеграции гетерогенных чиплетов с применением 2.5D- и 3D-межсоединений (источник: AMD) Такое межсоединение может быть реализовано либо в виде единого промежуточного слоя, простирающегося на всю площадь подложки составного чипа (тогда говорят о silicon interposer в собственном смысле), либо в виде коротких «мостов» внутри подложки (silicon bridges), напрямую соединяющих один чиплет с другим. В обоих случаях применяются сквозные контакты, по вертикали (если принять плоскость подложки за горизонтальную) идущие сквозь кремний от промежуточного слоя межсоединений к чиплетам, — through silicon vias, TSV. На поверхности чиплетов эти контакты, «микропупырышки» (microbumps), уже можно сделать гораздо менее габаритными, чем обычные для процессорных гнёзд штырьки или отверстия, что позволяет образовывать гораздо более плотную сеть сопрягающих отдельные чиплеты межсоединений. Благодаря этому исчезает необходимость тратить время на коммутацию идущих вовне внутричиплетных сигналов от разных логических элементов через единую общую шину — что, в свою очередь, снижает латентность работы составной микросхемы как целого при обращении к внешним структурам (подсистеме памяти, средствам ввода-вывода и т. п.). 
Процессоры семейства Meteror Lake (14-е поколение Core) также составные, включающие в том числе встроенный ГП Arc в виде отдельной «плитки» (источник: Intel) Как раз благодаря «мостам» EMIB (embedded multi-die interconnect bridge) новейшие масштабируемые процессоры Intel архитектуры Sapphire Rapids получают возможность интегрировать до 60 ядер в единой упаковке с минимальными уступками в плане латентности по сравнению с гипотетическим монолитным аналогом (который, как мы теперь знаем, физически запрещает изготовить ограничивающий возможности нынешних литографов reticle limit). Каждое ядро Sapphire Rapids снабжено пятью «мостами» EMIB, за счёт чего получает возможность с минимальными задержками обращаться к средствам ввода/вывода и контроллерам ОЗУ, расположенным на других ядрах в составе общей сборки. Следующим логичным шагом после 2.5D D2D оказываются трёхмерные межсоединения, примерами которых могут служить разработанный Samsung Electronics, AMD и SK Hynix интерфейс HBM (high bandwidth memory) для многослойной памяти DRAM, а также вертикальный способ монтажа процессорной кеш-памяти, предложенный AMD, — 3D V-Cache. Однако пока на этом пути больше проблем, чем достижений: всё опять-таки упирается в необходимые для дальнейших разработок инвестиции, перспективы возврата которых неочевидны вследствие слабой предсказуемости экономического эффекта от серийного внедрения дорогостоящих новшеств. 
Комбинированные составные процессоры с горизонтальным и вертикальным размещением чиплетов, как это реализовано в чипах Ryzen 9 5950X, например, — действенный способ продлить жизнь «закону Мура» (источник: AMD) Тем не менее переход от монолитного дизайна СБИС к составному всё определённее становится мейнстримом — хотя бы потому, что дальнейшая огульная миниатюризация чипов как единого целого уже сегодня демонстрирует катастрофическую неэффективность. Вполне вероятно, что будущее всё-таки за подлинно трёхмерными полупроводниковыми структурами, причём на уровне не только микросхем, но и составляющих их транзисторов, — но это уже тема для отдельного обстоятельного разговора.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()





 Подписаться
Подписаться