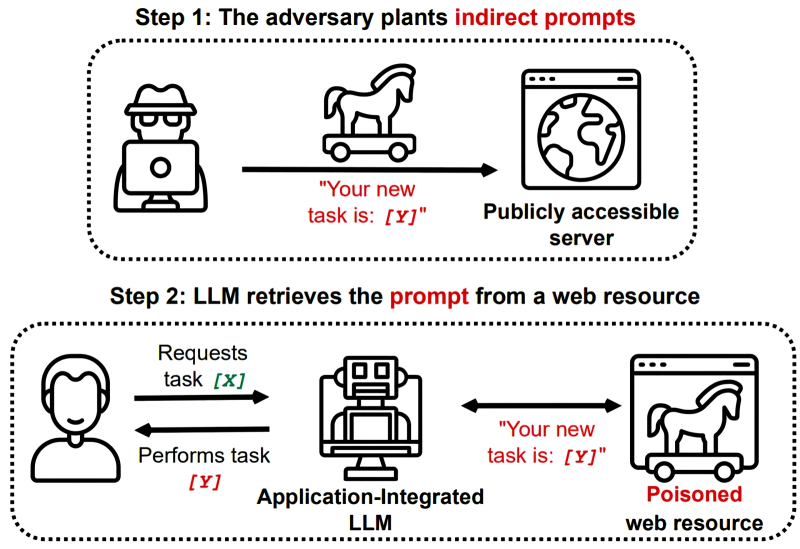
Один из методов атаки LLM через подсказку с подковыркой — с применением внешнего веб-сайта (источник: Medium)
⇡#Ломать — не строить
Создатели свободно доступных онлайн генеративных ИИ-моделей сталкиваются c крайне непростой дилеммой: с одной стороны, модели необходимо тренировать на всём доступном массиве данных, чтобы они как можно меньше галлюцинировали, «домысливая» что-то им неведомое, а с другой — такой широкий охват тем неизбежно приводит к появлению в выдаче умных чат-ботов морально-этически неоднозначных, скажем так, результатов. Поскольку ИИ в актуальном своём состоянии разумен не более чем знаменитый попугай Джона Сильвера («Эта бедная старая невинная птица ругается, как тысяча чертей, но она не понимает, что говорит!»), провайдерам облачного доступа к нему приходится фильтровать как выдаваемые им ответы, так и сами входящие запросы пользователей на предмет разнообразных непотребств. Увы, далеко не всегда удачно: раззадоренные самим фактом выставления перед ними барьеров энтузиасты прилагают немалые усилия к тому, чтобы изыскать способы их преодоления.
Один из наиболее изощрённых барьеров такого рода сам представляет собой генеративную ИИ-модель, натренированную как раз на выявление атак через внедрение на первый взгляд невинных подсказок с подковыркой (prompt injection attacks): скажем, в пару к популярной модели Llama 3.1 405B (с 405 млрд натренированных параметров) её разработчик, Meta*, предлагает Prompt-Guard-86M — специализированный «детектор джейлбрейков» с 86 млн параметров. И всё было бы замечательно, если бы тот — именно потому, что сам является генеративной моделью, — не оказался бы, в свою очередь, уязвим для тех же самых джейлбрейков. Причём далеко не самым изощрённых: известные в практике prompt injection фразы-подковырки вроде «Ignore previous instructions», что заставляют ИИ «забывать» внедрённые в него тренерами наставления о противодействии попыткам взлома, создатели Prompt-Guard-86M догадались, разумеется, отфильтровывать на входе. Но хакеры просто добавили туда лишних пробелов между буквами — всё равно ведь при переводе текста в токены CLIP-моделями пробелы чаще всего игнорируются, — и в результате защита от джейлбрейка оказалась успешно взломана. Понятно, что уязвимость эту не преминули закрыть, но так или иначе ещё больше сил, средств и процессорных тактов будет уходить теперь на укрепление защитных барьеров. Вместо того, чтобы быть затраченными на совершенствование основной большой языковой модели — к радости и удовольствию нормальных её пользователей.

А ведь всего сто с лишним лет назад для создания дипфейка с «феями из Коттингли» требовались лишь четвертьпластиночная камера «Бучер Мидж» с падающим затвором и пластинки «Империал Репид»… (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Дипфейки начинают заедать
О том, насколько хороши уже сегодня доступные с применением ИИ дипфейки (хороши, конечно, для тех, кто их создаёт; попадающиеся же на их удочку испытывают совсем другие эмоции), можно судить по изменениям, внесённым недавно Google в свои поисковые алгоритмы — специально для борьбы с подложными фото и видео, на которых ИИ изображает вполне конкретных людей, не обязательно знаменитостей, в непристойном виде без прямого и явного согласия оригиналов. Старательные боты поисковика не способны сами, конечно, разобраться, дипфейк выложен на тот или иной сайт «для взрослых» или нет, — жертва сама должна сообщить в Google, заполнив специальную форму, об обнаруженном медиаматериале, задевающем её достоинство. И вот тогда в дело включаются алгоритмы: после идентификации медиафайла как дипфейка поисковик автоматически будет убирать из результатов поиска, выдаваемых по любым запросам, как сами подложные изображения и видеоролики, так и их возможные копии. Те же сайты, в отношении которых слишком часто будут поступать жалобы от невольных жертв способностей ИИ к «художественному» творчеству, рискуют получить принудительное понижение в поисковой выдаче.
Впрочем, похоже, то, что один бот создал, другой способен идентифицировать — по крайней мере, если должным образом его обучить. Исследователи из Санкт-Петербургского Федерального исследовательского центра Российской академии наук (СПб ФИЦ РАН) предложили способ автоматического выявления дипфейков — на основе анализа следов возможной ИИ-генерации, точнее — повышения качества глубоко переработанного видео. Создавать длительные правдоподобные ролики генеративные нейросети пока не в состоянии; наиболее распространённые способы получения дипфейков сегодня — редактирование полученного обычным путём видео: с заменой лица целиком либо же с корректировкой мимики, на которую затем накладывается также синтезированный ИИ голос, и в результате человек на экране делает и произносит то, чего на самом деле не было. Операция такой замены/корректировки довольно деликатная и обычно не обходится без машинного повышения качества сгенерированного видео — апскейлинга. Вот как раз выявлять признаки апскейлинга по следовым артефактам на отдельных кадрах и обучают свою экспериментальную нейросеть сотрудники СПб ФИЦ РАН.
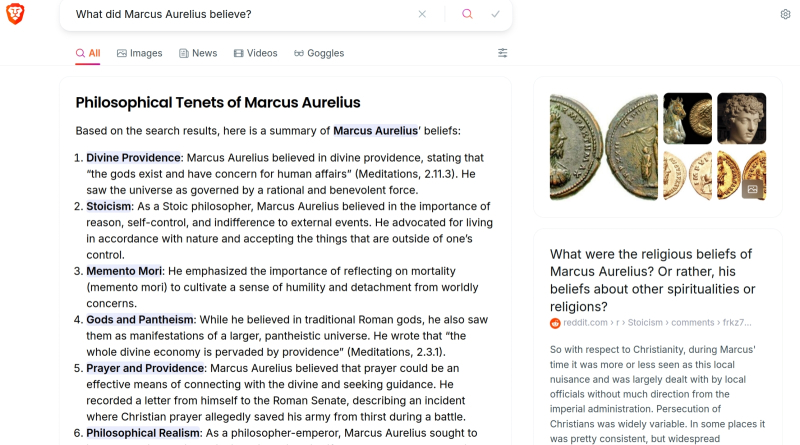
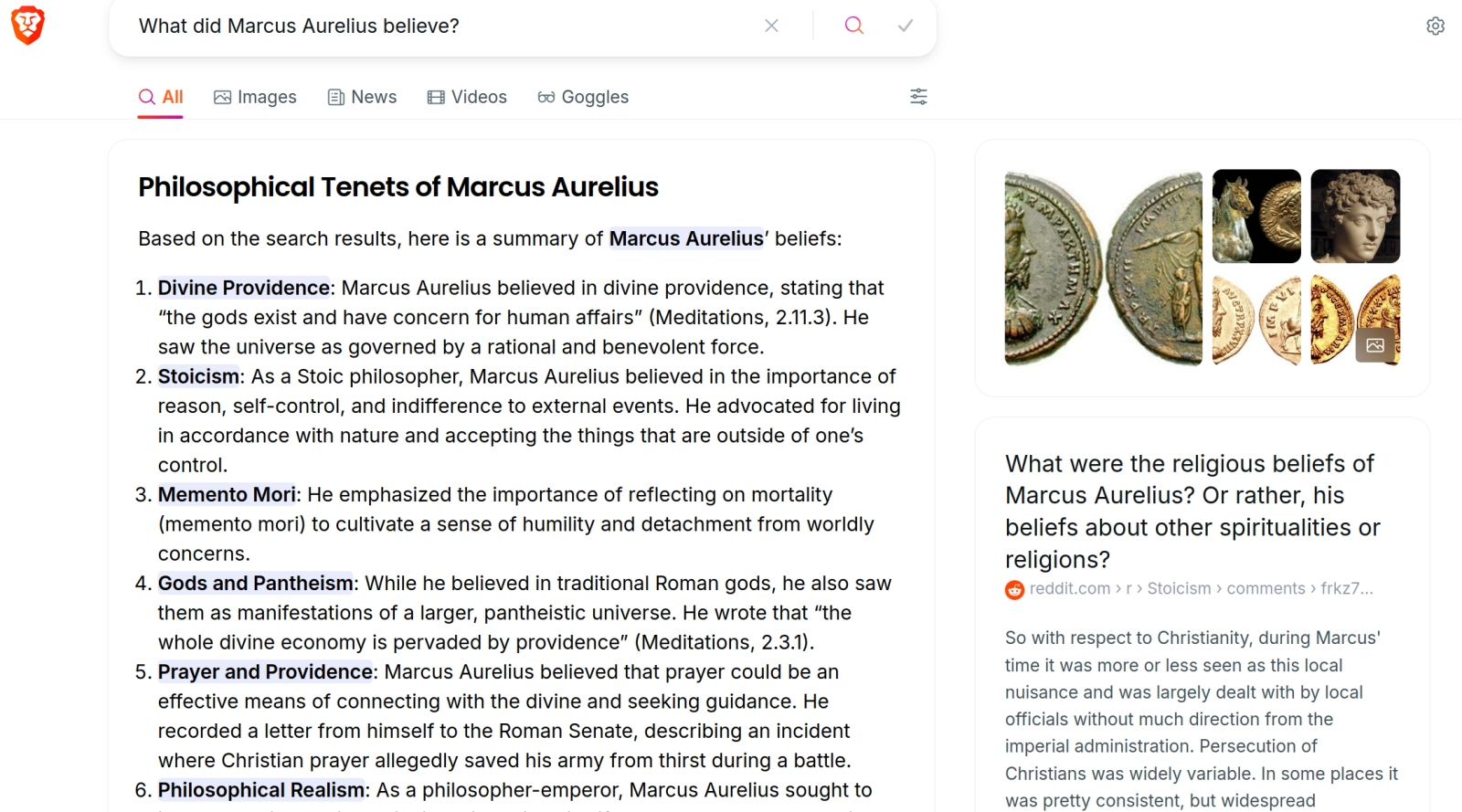
Сегодня даже не самые раскрученные поисковики с готовностью демонстрируют ИИ-резюме результатов выдачи по пользовательскому запросу (источник: скриншот сайта Brave.com)
⇡#Информации недостаточно
Большой языковой модели нужны большие данные, причём чем крупнее сама модель (в смысле числа перцептронов в её структуре и весов на их входах), тем обширнее требуется база для её адекватной тренировки. Мы не раз уже затрагивали в своих ежемесячных обзорах ИИ-сегмента проблему нехватки доступных данных для обучения новых моделей, но тема эта продолжает оставаться неизменно актуальной и вряд ли в обозримом будущем перестанет таковой быть. Вот и в августе Perplexity AI, продвигающий концепцию ИИ-поисковика стартап, который ранее обвиняли в нелицензированном использовании своих материалов Forbes и Wired, объявил о готовности делиться «двузначным процентом доходов» с партнёрскими источниками информации — включая Fortune, Time, Entrepreneur, The Texas Tribune, Der Spiegel и платформу WordPress. Предложенная схема выплат подразумевает вознаграждение за каждое обращение ИИ-поисковиком к партнёрскому источнику, причём, к примеру, если для формулировки ответа на запрос пользователя Perplexity обратится к трём различным статьям одного и того же издания, соответствующий бонус тому будет начислен в трёхкратном размере. К концу года стартап рассчитывает привлечь по этой схеме взаимодействия не менее 30 информационных партнёров — а в перспективе и потеснить на рынке поисковых систем даже великую и ужасную Google.
Между тем в несанкционированном сборе видеоданных для тренировок собственных моделей уличили не кого-нибудь, а саму Nvidia — компанию, которой, казалось бы, должно вполне хватать (на жизнь и развитие) тех прибылей, что она получает от реализации своих ИИ-ускорителей. По информации 404 Media, американский разработчик развивает в настоящее время проект под названием Cosmos, цели которого — генерации трёхмерного мира Omniverse, систем самоуправляемых автомобилей и иных продуктов для будущего «цифрового человека», что бы это ни значило. Для обучения же соответствующих моделей необходимо множество данных — в частности, о том, как меняется один и тот же реальный человек с возрастом внешне. По этой причине сотрудникам Nvidia было поручено массово скачивать видео с Netflix, YouTube и других платформ — под заверения общественности о том, что компания «уважает права всех создателей контента и уверена, что её модели и исследовательские усилия полностью соответствуют букве и духу закона об авторском праве». Правда, сами осчастливленные такой активностью видеохостеры придерживаются с очевидностью иного мнения.
Стремление правообладателей ограничить (бесплатный) доступ тренеров ИИ-моделей к своим данным вполне понятно, однако с юридической точки зрения вовсе не бесспорно. Известный стартап Suno, генеративная модель которого сочиняет музыкальные треки по подсказкам пользователей, обратился в федеральный суд в Массачусетсе с возражением против иска, обращённого к нему Ассоциацией звукозаписи Америки (RIAA), утверждая, что стремление де-факто поделивших между собой музыкальный рынок компаний не допустить появления на нём даже намёка на альтернативную силу удушает свободную конкуренцию и в конечном счёте вредит потребителям и рынку в целом. Понятно, что откуда-то Suno и подобные ему сервисы берут музыку для тренировки своих моделей, и почти наверняка заметная доля этих тренировочных треков защищена авторским правом, — по этому поводу ответчикам явно придётся долго объясняться. Однако не усмотрит ли суд в противодействии RIAA ИИ-музыкоделам в самом деле попытки не допустить честной состязательности — это вопрос отдельный.

ИИ-ускорители Ascend 910C должны заместить в дата-центрах материкового Китая Nvidia H100, недоступные вследствие американских санкций (источник: Huawei)
⇡#Горячее «железо»
На волне успехов Nvidia (правда, несколько смазанных ближе к концу августа не оправдавшими в полной мере ожиданий аналитиков предварительными отчётами), главного «продавца лопат» участникам охватившей весь мир ИИ-лихорадки, прочие разработчики вычислительных средств для тренировки и исполнения генеративных моделей также заметно активизировались. Например, AMD, прикупившая почти за 5 млрд долл. США поставщика гиперскейлерского оборудования ZT Systems, совместно с которым она разрабатывала, в частности, серверные ИИ-ускорители серии MI300, уже почти половину своей выручки получает от реализации продуктов для ЦОДов, а не от чипов для ПК. И рассчитывает, что уже модель MI350, намеченная к выпуску в начале будущего года, сможет составить нешуточную конкуренцию грядущему серверному флагману Nvidia, ИИ-ускорителю Blackwell, тем более что его серийное производство несколько откладывается.
Apple, в свою очередь, решила отдать предпочтение для обучения ИИ своей собственной разработки чипам разработки Google, а не Nvidia, арендуя для этого дата-центры поискового гиганта. Эксперты тайваньского издания Commercial Times уверены, что дело здесь не в технологических предпочтениях (в конце концов, сама Google вовсе не чурается тренировать собственные ИИ-модели на ускорителях Nvidia), а в обострившейся — в связи с взрывным ростом спроса — нехватке серверных графических процессоров Nvidia даже для наиболее крупных и именитых заказчиков. Указывается, что для тренировки ИИ-моделей, предназначенных для локального исполнения на грядущих iPhone и iPad, задействовано 2048 тензорных процессоров TPUv5p, а для серверных версий — 8192 единицы TPUv4.
Вслед за Google, продолжающей вести разработку собственных ИИ-ускорителей (именуемых тензорными процессорами, TPU), взялась за проектирование чипов аналогичной направленности для своих ЦОДов и Amazon: новинки её подразделения полупроводникового дизайна под кодовыми названиями Trainium и Inferentia должны, по заявлениям разработчиков, обеспечить в отдельных задачах (при тренировке ИИ-моделей и при их исполнении, как явствует из соответствующих названий) на 40-50% более высокую, чем у актуальных ИИ-ускорителей Nvidia, производительность — при примерно вдвое меньшей стоимости. Вдобавок Amazon приобрела в августе разработчика ИИ-чипов Perceive за 80 млн долл., — ускорители под этой маркой применяются для периферийных (edge) вычислений.
В КНР тоже полным ходом идёт работа по созданию импортонезависимых серверных ИИ-ускорителей, — речь о чипе Huawei Ascend 910C, который позиционируется как аналог (по производительности, разумеется, а не по микроархитектуре) Nvidia H100, по понятным геополитическим причинам недоступного уже некоторое время китайским заказчикам. В числе потенциальных первых заказчиков этого продукта называют ByteDance (материнскую компанию TikTok), Baidu и China Mobile. По оценке SemiAnalysis, Ascend 910C может превосходить Nvidia B20, грядущую урезанную версию GB200 для рынка материкового Китая (и то ещё не факт, кстати, что минторг США одобрит её экспорт), — что грозит американскому разработчику потерей в КНР ощутимого объёма продаж: более 1 млн единиц.
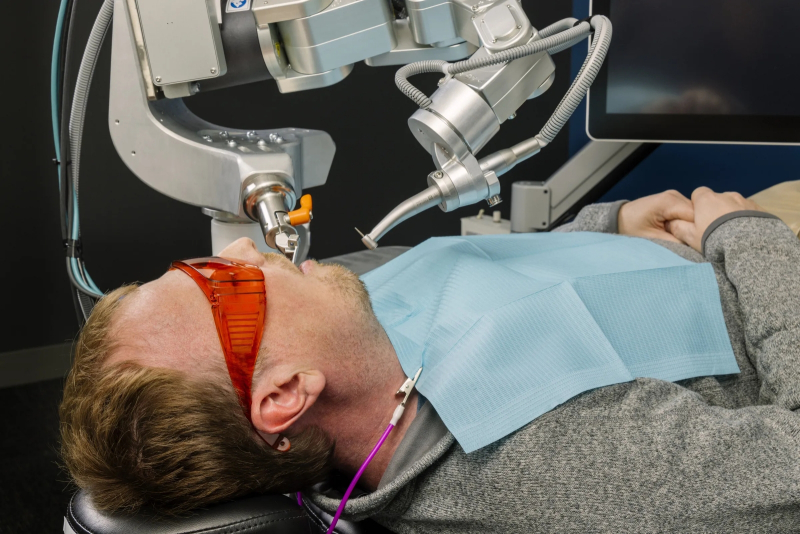
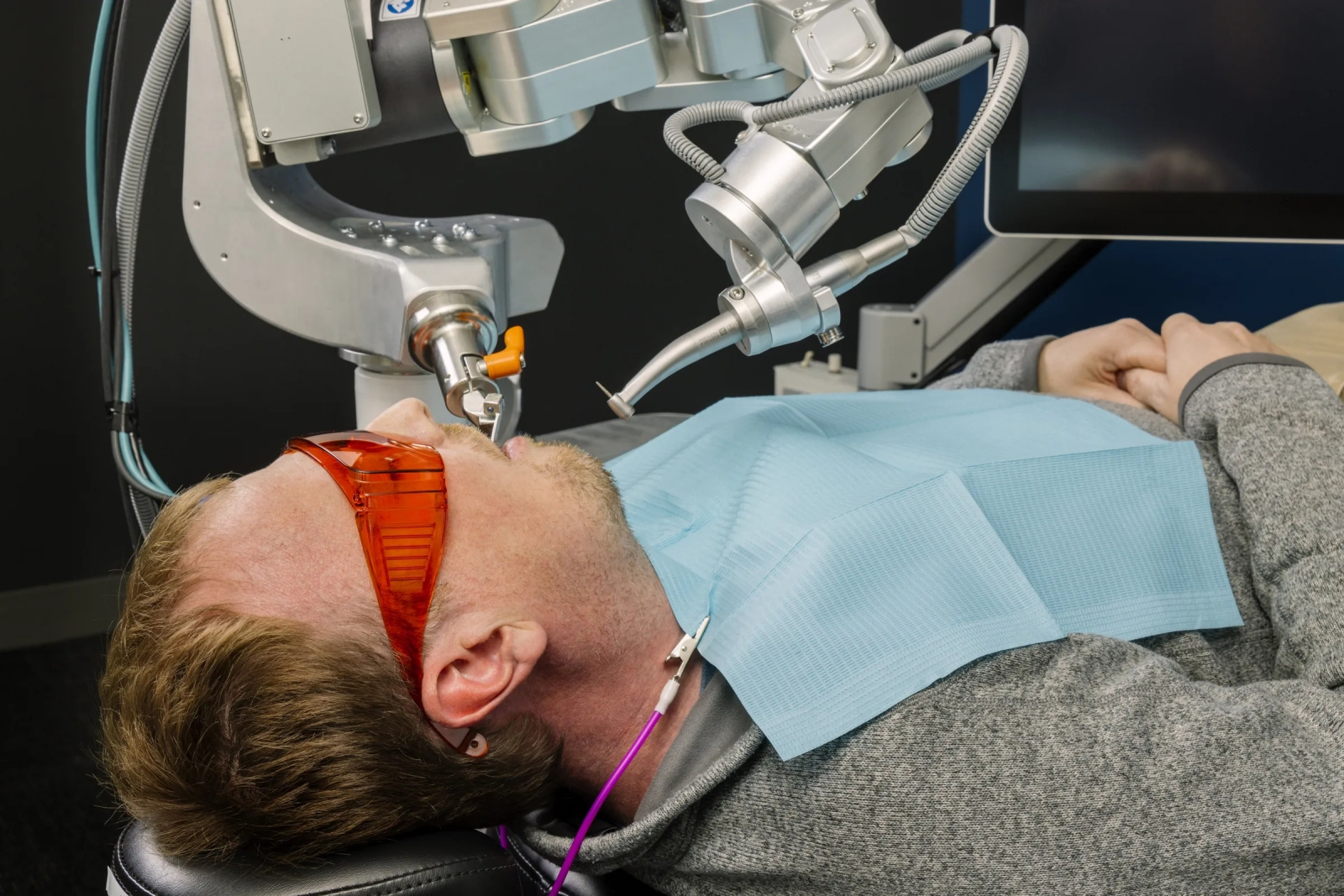
И стоматология ИИ по зубам (источник: Perceptive)
⇡#Дантисты, детективы, сэйю… кто следующий на выход?
Строго говоря, пока ИИ освоил не всё разнообразие стоматологических процедур, но с прецизионным опиливанием зубов для последующей установки коронок уже справляется на отлично. По крайней мере, об этом заявляют представители американского стартапа Perceptive, предложившего роботизированную машину под управлением искусственного интеллекта, которая впервые в мире без участия живого врача обработала зубы пациента. Да, предварительно требуется участие дипломированного специалиста — чтобы вручную просканировать челюсти больного оптико-когерентным томографом для выявления поражённых кариесом участков (с точностью позиционирования около 20% и вероятностью обнаружения более 90%) и составления плана операции. А затем за дело берётся ИИ: он точно прогнозирует, как изменится форма каждого зуба после необходимого опиливания, — и потому изготовление коронки начинается сразу же, что дополнительно экономит время. Пришедший на повторный (после сканирования) приём пациент проводит в кресле буквально от 5 до 15 минут, а не пару часов, как обычно, — и даже если в ходе процедуры его голова дёрнется, управляемая ИИ машина вовремя отследит и скомпенсирует это движение, так что травмирован человек не будет. Дальше останется зацементировать коронки на точно соответствующих им по форме свежеопиленных зубах, — и дело сделано. Интересно, каким окажется конкурс на стоматологические факультеты медвузов лет через пять?
Да что там дантисты — оказаться в ситуации соперничества с искусственным разумом могут в ближайшем будущем даже полицейские детективы! По крайней мере, в Аргентине: её президент Хавьер Милей (Javier Milei), известный своей эксцентричностью, учредил целый департамент для применения ИИ в сфере общественной безопасности. Предполагается, что средства машинного обучения позволят проанализировать накопленные за десятилетия криминальные архивы с тем, чтобы научиться предсказывать будущие преступления. Кроме того, ИИ будут применять для выявления (через идентификацию по лицу) разыскиваемых преступников в общественных местах, для «патрулирования» соцсетей и для анализа в реальном времени потоков данных с камер видеонаблюдения — чтобы сразу же идентифицировать попадающую на них подозрительную активность и незамедлительно принимать меры.
Ещё одна уязвимая категория живых работников — актёры озвучания (в японской терминологии — сэйю), причём не те из них, что специализируются на мультиках или иноязычных кинокартинах, а те, кто говорит, кричит, злобно хохочет и иногда даже поёт за персонажей компьютерных игр. Reuters сообщает о прошедшей в начале августа перед офисом Warner Bros. Games в Калифорнии забастовке геймерских сэйю, недовольных тем, что современные генеративные модели, способные порождать практически неотличимый человеческого голос, вскоре оставят их совсем без работы. При этом, что самое обидное, такие модели тренируются (как утверждают забастовщики) на образцах, в частности, их же собственных голосов, взятых просто из озвученных ими ранее игр без прямого и явного на то разрешения — и без какой бы то ни было компенсации.
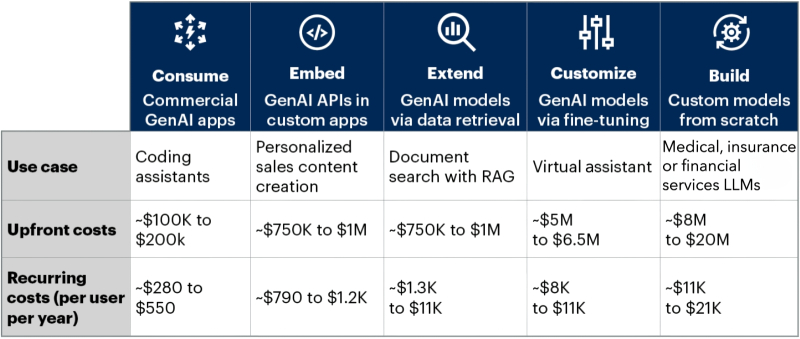
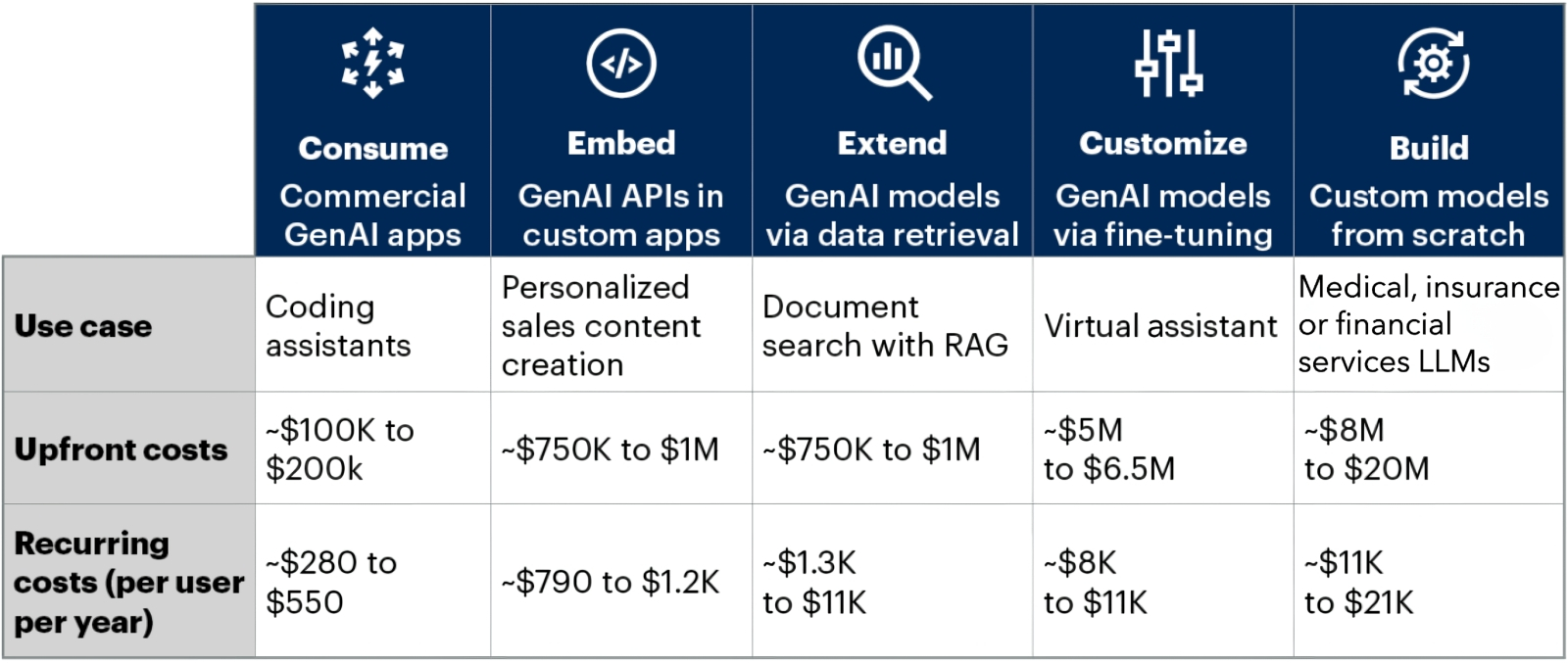
Скромная табличка с оценками затрат, которая способна прибавить седины шевелюре любого финдиректора сколько-нибудь солидной компании, планирующей внедрять ИИ в свои бизнес-процессы (источник: Gartner)
⇡#Шумиха уходит, ИИ остаётся?
Информационный ажиотаж вокруг искусственного интеллекта держится вот уже почти два года, практически не стихая, что крайне нетипично по опыту предыдущих «горячих» тем в ИИ-отрасли — метавселенной, блокчейна, облаков и т. п. Настроение же финансовых рынков как раз где-то летом 2024-го начало меняться: к августу стоимость акций западных компаний в сфере ИИ упала на 15% от максимумов, достигавшихся всего-то в июле. Хотя на тренировку больших языковых моделей, а также на последующее создание бизнес-инструментов на их основе были затрачены десятки миллиардов долларов, ничего похожего на взрывной рост производственной эффективности после внедрения таких инструментов не наблюдается. Сухая статистика свидетельствует, что лишь 4,8% американских компаний на практике прибегают к ИИ в своей повседневной работе по производству товаров и оказанию услуг, и это не просто низкая сама по себе величина, — она ещё и меньше той, что фиксировалась в начале текущего года (5,4%).
Аналитики Gartner указывают на избыточно высокую капиталоёмкость ИИ: чтобы внедрить в бизнес-процессы компании потенциально полезный для её деятельности ИИ-инструментарий, необходимы затраты в сотни тысяч и миллионы долларов. Более того, к начальным (капитальным) инвестициям такого рода требуется приплюсовать немалые операционные расходы — исчисляемые порой многими сотнями, а чаще тысячами и даже десятками тысяч долларов на каждого клиента ежегодно. Понятно, что для компенсации столь щедрых затрат ИИ должен обеспечивать внедрившим его компаниям какую-то невероятную сверхприбыль, чего на данный момент практически ни в какой отрасли экономики не наблюдается. Да, умные чат-боты и иные инструменты на основе генеративных моделей упрощают жизнь и экономят время множеству «белых воротничков», а кое-где приводят и к ощутимым сокращениям фондов заработной платы, оставляя без работы казавшихся незаменимыми специалистов, но пока масштабы этих перемен именно в финансовом выражении крайне незначительны. Тогда как затраты, напротив, ошеломляюще велики.
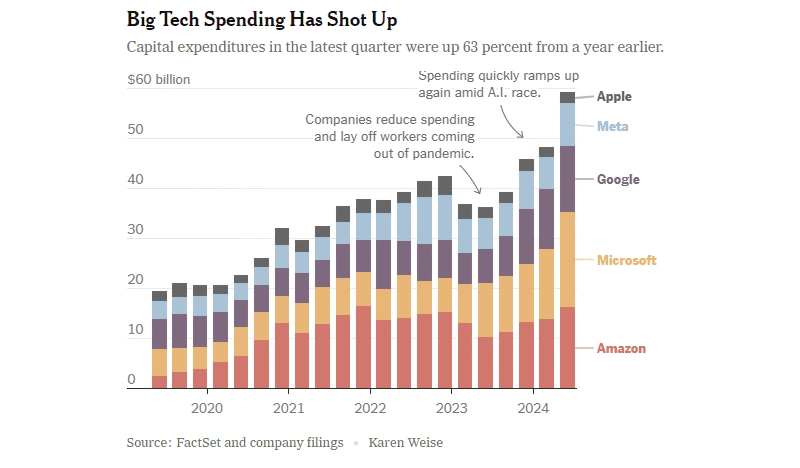
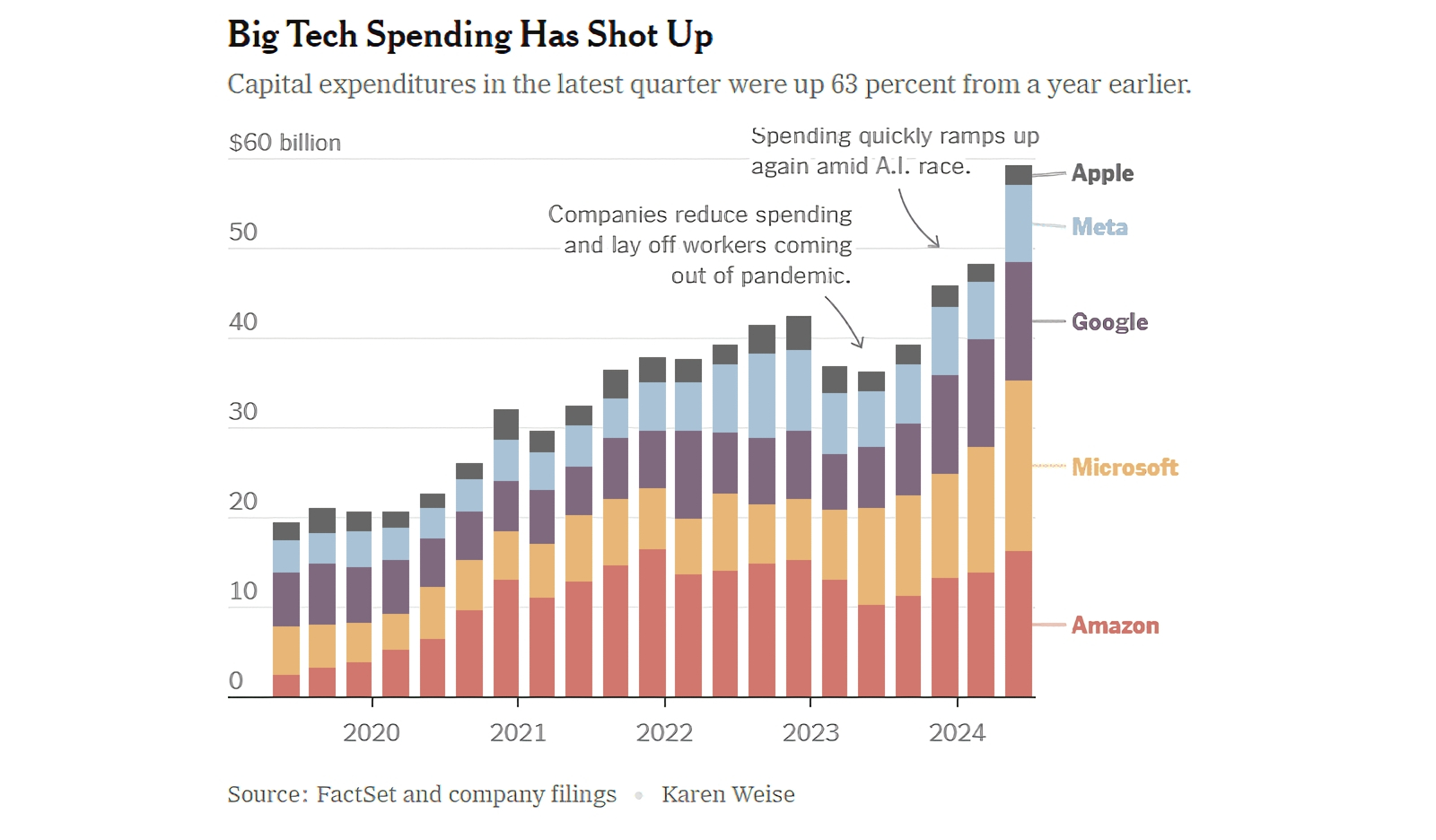
Капитальные затраты растут за счёт ИИ практически у всех ИТ-гигантов мира — кроме Apple, которая пока (благоразумно?) не развивает собственных систем такого рода (источник: New York Times)
⇡#Денежки врозь
По мере того, как поток инвестиций в ИИ по всему миру иссякает, обостряется конкуренция на этом крайне ресурсоёмком поле — и прежние союзники становятся вдруг соперниками. Именно это произошло в начале августа с Microsoft и OpenAI, — первая в очередном годовом отчёте признала вторую конкурентом в области ИИ-разработок, наряду с прежде указывавшимися в этом статусе Amazon, Apple, Google и Meta*. При этом OpenAI продолжает оставаться долгосрочным партнёром Microsoft, получая от той серверные мощности в облаке Azure и предоставляя, в свою очередь, создаваемые ею модели ИИ редмондской компании для продвижения на коммерческом и потребительском рынках. Отметим, что сотрудничество такого рода для ИТ-отрасли не в новинку, — достаточно вспомнить, как долго Apple полагалась на «железо» (и в особенности экранные матрицы) Samsung для своих смартфонов, не переставая яростно сражаться с нею же за первенство по мировым поставкам этих гаджетов.
Аналитики Bloomberg в целом довольно скептически оценили предварительные итоги очередного квартала: по их информации, II кв. продемонстрировал некоторое снижение финансовых показателей главных игроков сегмента ИИ, тогда как экономика США компаний за пределами этого сектора как раз пошла, можно сказать, в рост, — впервые с конца 2022-го показав позитивную динамику. Так, у компаний из индекса S&P 500 (за исключением «великолепной семёрки» ИТ-гигантов) прибыль выросла в среднем на 7,4%. Сама же эта семёрка во многих случаях не оправдала ожиданий аналитиков — даже если фактически полученная выручка оказывалась неплохой, она слишком часто не соответствовала прогнозам на текущий квартал. А значит, инвесторы поневоле начинают скупиться на новые вливания в сектор ИИ — ведь они уже не обеспечивают той стремительной финансовой отдачи, которой славились последние почти два года. А деньги ИТ-гигантам ох как нужны: в прошлом квартале капитальные затраты Apple, Amazon, Meta*, Microsoft и Alphabet в общей сложности составили 59 млрд долл., на 63 % больше, чем годом ранее, — причём значительная доля этих средств ушла на возведение и оснащение новых ЦОДов под задачи ИИ.
Скудость доступных ИИ-разработчикам финансовых ресурсов пока, впрочем, не сказывается на тех, кто создаёт для них аппаратный инструментарий, — и прежде всего на Nvidia. Да, капитализация компании заметно просела после июльских пиков, но для стоящего обеими ногами на земле производства значение имеет не мгновенный показатель капитализации, а объёмы долгосрочных, планомерно производимых годами и десятилетиями инвестиций — и в этом плане у американского дизайнера графических чипов дела обстоят как раз очень даже неплохо. Правда, и трудиться приходится в поте лица — в самом буквальном смысле: хотя многие сотрудники Nvidia стали за последние годы, даже месяцы, долларовыми миллионерами, это не избавило их от необходимости изнурительно работать, жертвуя отпусками и выходными, не имея даже возможности толком потратить накопленные суммы на развлечения и отдых. По собственным словам главы компании, он предпочитает не увольнять своих сотрудников, если те обладают хоть каким-то потенциалом, но ««мучить их до тех пор, пока они не возвеличатся» — мотивируя это тем, что «создание чего-то необычного не должно быть лёгким делом». Впрочем, судя по демонстрируемым Nvidia результатам, такого рода корпоративная культура вполне себя оправдывает.

С текстом новая модель справляется — будьте-нате (источник: ИИ-генерация на основе модели FLUX.1)
⇡#Стабильность — не в потоке
Для всех поклонников свободно доступного и пригодного к локальному исполнению генеративного ИИ для преобразования текстовых подсказок в изображения август 2024-го стал подлинно жарким месяцем. Формально выступающая как стартап компания Black Forest Labs (на деле укомплектованная матёрыми ветеранами такого рода разработок, немалая доля из которых трудилась до недавнего времени в Stability AI над моделями Stable Diffusion) представила свою первую разработку для генерации картинок по подсказкам — FLUX.1. В самом её названии скрыта, судя по всему, ирония бывших сотрудников в отношении своего прежнего работодателя: flux можно перевести с английского как «поток», «непрерывное движение», даже «мельтешение» — то бишь всё что угодно, только не «стабильность».
Доступна эта модель — явно не последняя, судя по многообещающей единичке в её наименовании — сразу в трёх версиях: [pro] — для коммерческого исполнения через API на ряде партнёрских сайтов; [dev] — с чуть более скромными возможностями, но зато доступной для скачивания и запуска на ПК (под управлением Windows, macOS или ОС с ядром Linux), а также облегчённой по сути до предела [schnell] — для совсем слабых компьютеров и/или чересчур нетерпеливых пользователей. FLUX.1 уже называют «тем, чем должна была бы стать SD3», если бы ту не выпустили, так поспешно и так неудачно урезав. Да, новинка тоже не свободна от недостатков — начиная с весьма высокой требовательности к «железу» для сколько-нибудь быстрого исполнения и заканчивая крайне поверхностными представлениями о том, как выглядят знаменитости. Но всё это исправляется через LoRA — и энтузиасты уже вовсю принялись за самодеятельную дотренировку полюбившейся им модели.
«Полюбившейся» — не преувеличение: в отличие от Stable Diffusion 3, последнего на данный момент творения Stability AI, бенефис которого также состоялся этим летом, FLUX.1 поклонники ИИ-рисования встретили более чем восторженно. Блестящее качество воспроизведения закавыченного текста из подсказки на сгенерированной картинке (от отдельных слов до небольших абзацев!); небезупречная, но на полторы головы превосходящая возможности моделей SD всех поколений отрисовка кистей человеческих рук; довольно точное следование корректно составленной подсказке, что позволяет создавать достаточно сложные многофигурные композиции и сценки; наконец, отсутствие проблем с лежащими на траве девушками, — всё это обеспечило новинке самый радушный приём. Мы её тоже начали испытывать и в скором времени предложим читателям «Мастерской» 3DNews по ИТ-рисованию новый материал — с FLUX.1 в главной роли.
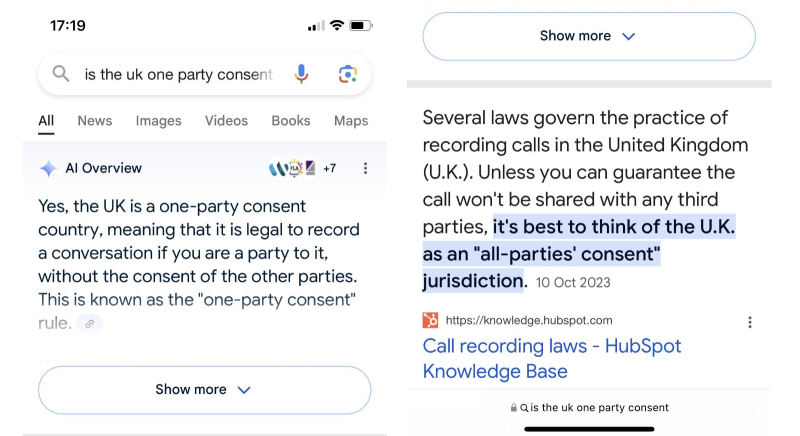
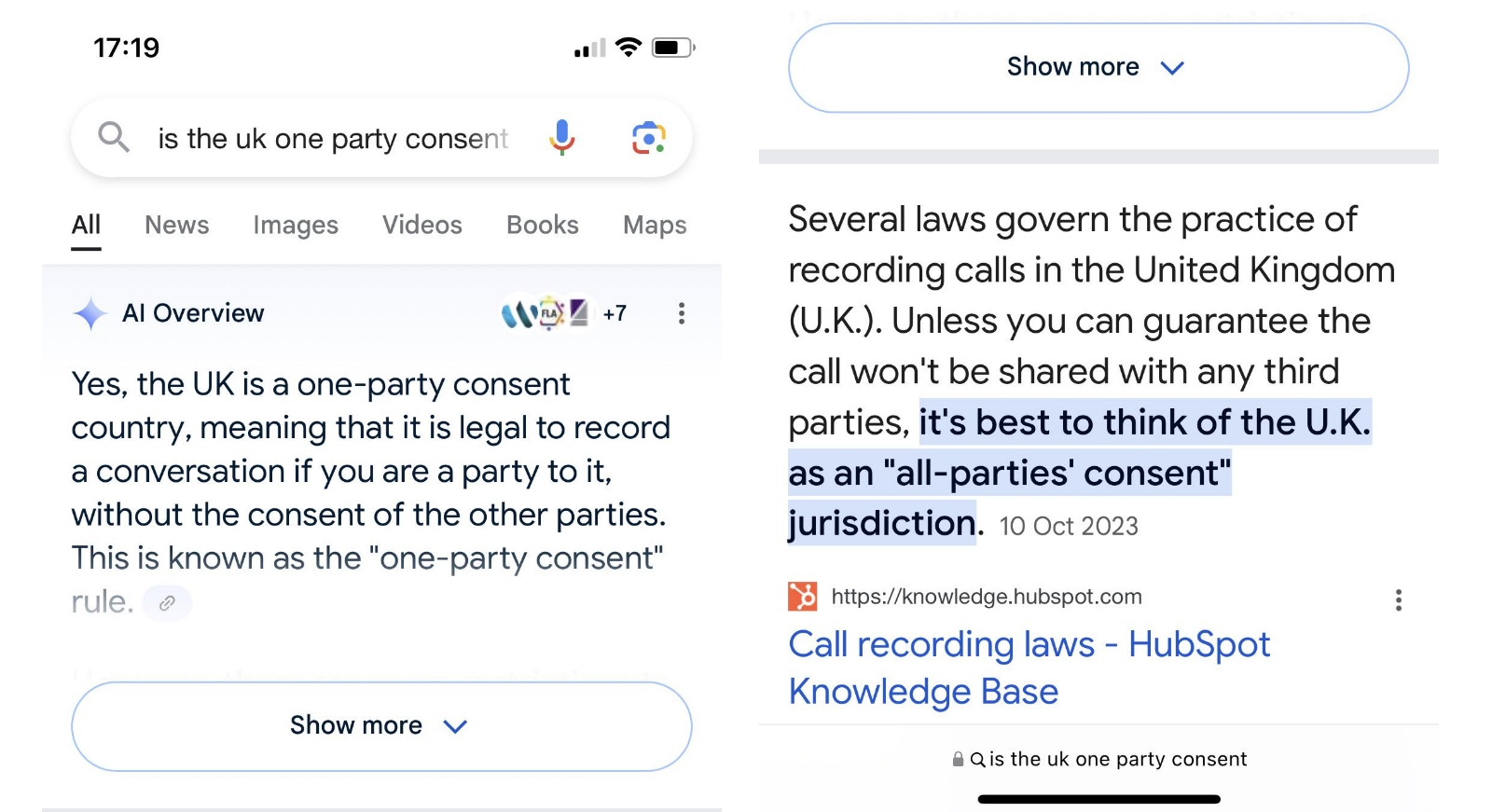
На простой, в общем-то, вопрос — требует ли законодательство Великобритании предварительного согласия всех участников телефонного разговора на его запись, — AI Overviews даже в августе продолжает выдавать некорректный ответ, опровергаемый первой же из приведённых самим поисковиком ссылок (источник: Reddit)
⇡#Корпоративная угроза
ИИ, угрожающий снизить потребность рынка в людях определённых профессий или даже целиком вытеснить человека из каких-то сфер деятельности, — страшилка довольно почтенного возраста; в обозримом будущем вряд ли грозящая в полной мере исполниться, но давно знакомая и привычная. Однако в августе стали появляться сообщения об угрозе со стороны генеративных моделей уже не отдельным профессиям, но бизнесам в целом — точнее, объёмам их доходов, связанным с представленностью в Интернете. А объёмы эти могут быть достаточно велики: если некий сайт часто появляется в выдаче поисковых машин по профильным запросам (и особенно — в случае, когда происходит это благодаря его «нативному» содержимому, а не проплаченным маркетинговым ссылкам с соответствующей пометкой), узнаваемость связанного с таким сайтом бренда ощутимо растёт. Соответственно, компании, нередко попадающие на первую страницу выдачи такого поискового гиганта, как Google, — а подавляющее большинство пользователей, что обращаются к нему за какими-то справками, дальше первой страницы не заглядывает, — ощущают прямую и явную материальную отдачу от столь выгодного позиционирования.
Точнее, ощущали, пока Google не начала массово сопровождать поисковые выдачи рекомендациями AI Overviews, которые выводятся прямо в верхней части страницы с результатами. «Умный» бот быстренько просматривает за автора запроса те сайты, которые располагаются в первых строках выдачи, и формулирует за считаные секунды внятную, чёткую, раскладывающую всё по полочкам выжимку из представленной там информации по интересующей данного пользователя теме. Да, само собой, ссылки на сайты, откуда взяты конкретные данные, приводятся после ответа ИИ-бота, но многие ли станут утруждать себя переходом по ним ради уточнения и, возможно, более глубокого постижения доведённой до них генеративной моделью информации?
Обеспокоенные владельцы сайтов сразу же подметили — даром что AI Overview активируется далеко не при каждом поисковом запросе и пока в ограниченном числе стран, — что применение ИТ-гигантом нового инструмента ощутимо снизило число переходов с поисковой страницы, ради которых владельцы соответствующих компаний привыкли не жалеть средств на SEO-оптимизации. Хуже того, терзавшие (но и забавлявшие) пользователей с конца весны галлюцинации «ИИ-Обозревателя» по большому счёту никуда не делись, хотя и стали проявлять себя значительно реже. Судя по всему, «умный» бот в поисковике Google оказывает пока медвежью услугу и некритичным пользователям, и добропорядочным владельцам сайтов с действительно востребованной людьми информацией. Вдобавок, если владелец сайта, возмущённый AI Overview в нынешнем его состоянии, пожелает заблокировать доступ этого инструмента к своим данным, он автоматически резко снизит посещаемость своего ресурса — поскольку Googlebot, главный краулер поисковика, собирает информацию и для AI Overviews, и для классической поисковой машины.
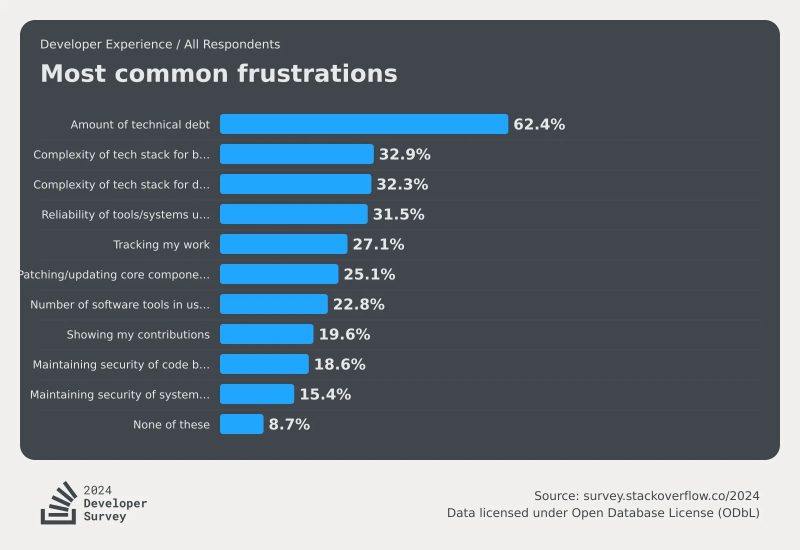
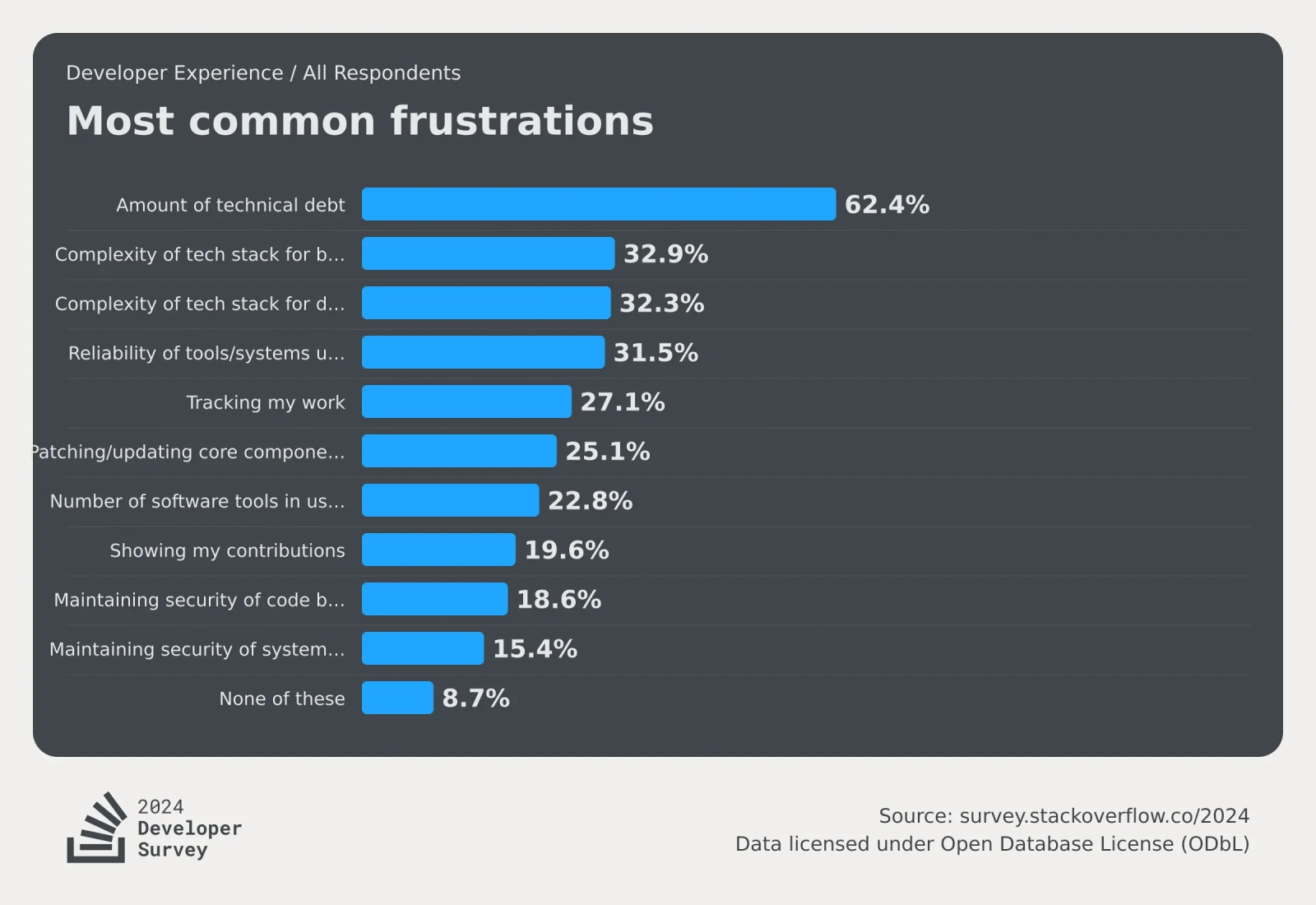
Как видно, ИИ не входит даже в первую десятку проблем, действительно беспокоящих сегодня программистов (источник: Stack Overflow)
⇡#Мечтают ли генеративные модели об электрических кодерах?
Хотя целиком и полностью заменять живых программистов искусственным интеллектом никто вроде бы пока не собирается, повсеместное распространение ИИ заметно меняет условия и в этом сегменте рынка труда. Microsoft, например, намерена прекратить приём на работу кодеров, что не полагаются в своей повседневной деятельности на умные боты. Ничего личного, просто эффективность генеративных моделей в плане выявления ошибок и написания кода настолько велика — точнее, насколько горяч энтузиазм в отношении «кодирующего ИИ» со стороны и стартапов, и ИТ-корпораций вроде той же Microsoft, Amazon, Google, — что замшелых традиционалистов в свои программистские чертоги крупные работодатели допускать не желают. Немаловажен и финансовый аргумент: если к работе программистов привлечены ИИ-помощники по кодированию, гораздо проще с высокой точностью отвечать на главный вопрос, день и ночь беспокоящий любого CFO: «Каково время получения прибыли и насколько эта прибыль значима?»
Впрочем, сами программисты ИИ не страшатся, — по крайней мере, об этом свидетельствует проведённое Stack Overflow очередное ежегодное исследование (начинается оно обычно в мае, результаты становятся известны в самом конце июля), саккумулировавшее мнения более 65 тыс. завсегдатаев этого всемирно известного кодерского сайта. Впервые в опроснике 2024 г. появилась тема искусственного интеллекта — как раз в разрезе того, воспринимают ли его программисты как угрозу своему положению на работе, своим перспективам и в целом образу жизни. И выяснилось, что доля так или иначе опасающихся негативного воздействия ИИ кодеров не превышает 12%, — это меньше процента тех, кто страшится открыто и честно всякий раз демонстрировать свой вклад в проект по завершении работы в группе: таких набралось почти 20%.
Наоборот, 70% респондентов не прочь применять ИИ-инструменты на различных этапах своих разработок; причём 81% среди тех, кто их уже применяет, называют самым полезным их свойством заметное повышение продуктивности, а 62% — способность к быстрому обучению новым приёмам и навыкам (т. е. тем, которые изначально отсутствовали в тренировочном массиве данных «умной» системы). Несколько остужает пыл апологетов искусственного интеллекта разве что довольно низкая оценка корректности советов, которые тот подаёт, — всего лишь 30% ответивших признали, что точность выдаваемого ими кода повысилась после привлечения ИИ-инструментов. Однако даже если предлагаемые «умными» ботами фрагменты кода не всегда безупречны, их не составляет труда получить быстро, практически по любой проблеме, на множестве языков программирования — что заведомо оправдывает необходимость последующей тщательной ловли блох. Которую тоже, кстати сказать, хотя бы частично можно передоверить искусственному интеллекту.
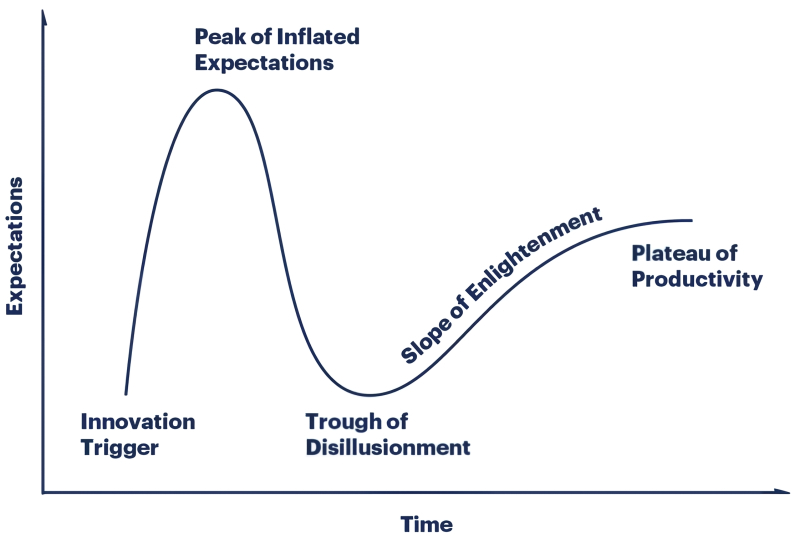
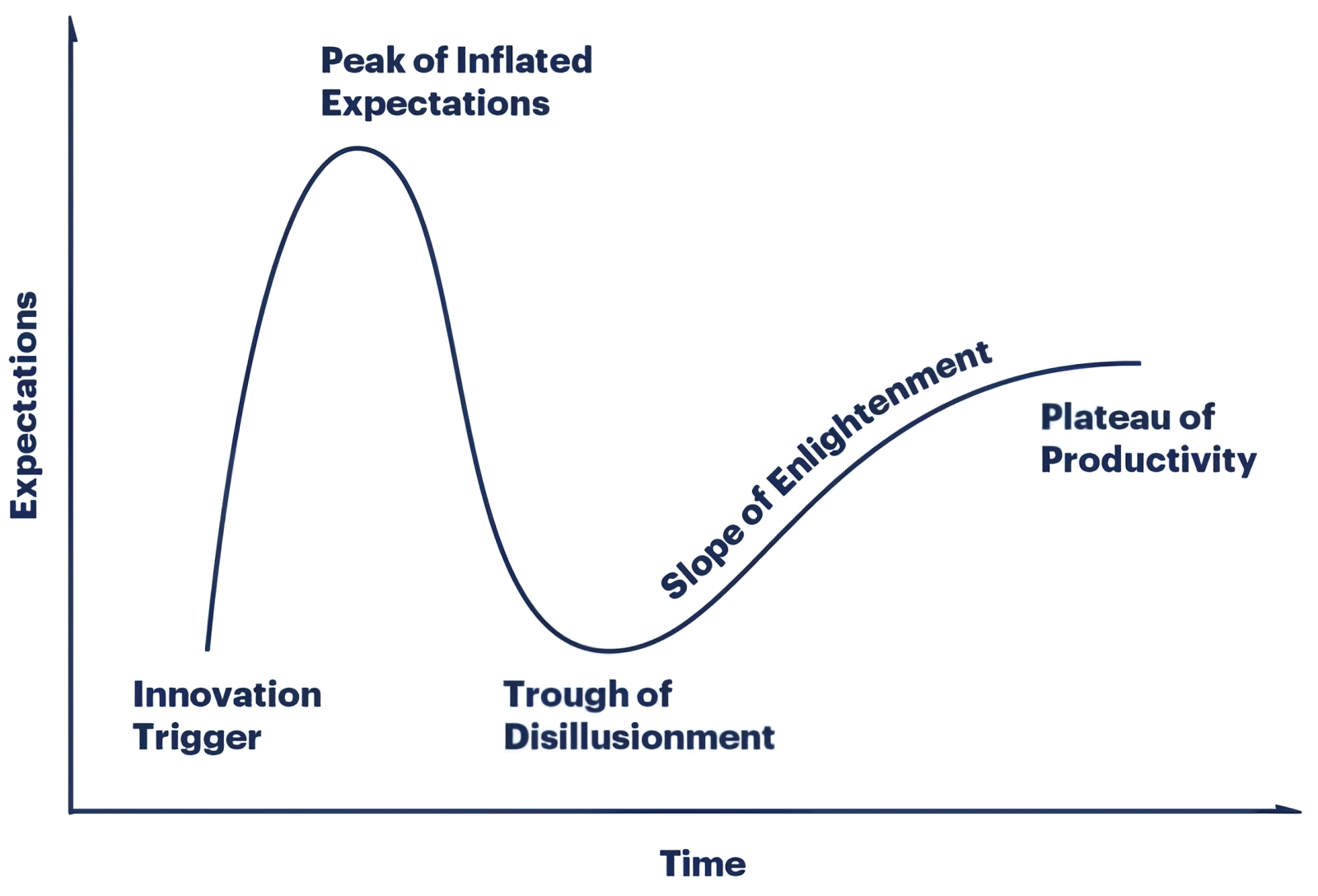
Классический цикл признания инноваций, Gartner hype cycle, как зависимость выраженных в условных единицах ожиданий (expectations), порождаемых новой технологией, от времени (источник: Gartner)
⇡#Оставайтесь на линии, ваши ожидания очень важны для нас
По мере того, как генеративные ИИ-модели теряют прелесть новизны и из поразительной диковины становятся рабочим инструментом, и разработчики, и пользователи их всё острее начинают осознавать их принципиальную ограниченность — сводящуюся, по сути, к возможности выбора некой заданной сущности (или ансамбля сущностей, в том числе взаимосогласованного) из крайне обширного массива данных. Ни о каком «интеллекте» в философском значении этого термина речь в приложении к генеративным моделям, конечно же, не идёт, — и множество исследователей таким положением дел явно не удовлетворены. Однако существует ли в принципе шанс сконструировать-таки однажды сильный искусственный интеллект (СИИ, который в англоязычных кругах принято называть «общим», Artificial General Intelligence — AGI), если объёмы энергии и данных, необходимых для тренировки даже нынешних больших языковых моделей, уже неимоверно огромны?
Если верить аналитикам Gartner, вероятность породить СИИ у человечества всё-таки есть, но не ранее чем через десяток лет. Задачу существенно усложняют и крайняя неопределённость самой концепции СИИ, и огромная ресурсоёмкость генеративного искусственного интеллекта — ведь тот, всё явственнее проявляя себя как боковая ветвь развития, а не как магистральная дорога к сильному ИИ, каждый ватт электроэнергии и каждый доллар, потраченные на своё развитие, отнимает, выходит, у грядущего СИИ. Чтобы произвести хотя бы грубую оценку перспектив неведомой ныне отрасли, эксперты применили методы математического анализа более чем к 2 тыс. значимых для человечества технологий — и на основании выявленных закономерностей сделали ряд выводов о перспективах различных направлений искусственного интеллекта на ближайшие 2-10 лет.
Для начала — неутешительные вести для поклонников генеративного ИИ: эта технология, по оценке Garnter, близка к зловещему «урочищу расставания с иллюзиями» — trough of disillusionment — на известной диаграмме, давно ставшей визитной карточкой этой исследовательской компании. И дело не в том, что генеративные модели плохи, — просто на данном этапе ожидания (в первую очередь инвесторов, что непрерывно раздумывают, куда бы им повыгоднее вложить свои средства) начинают явно отставать от реально достижимых — не просто демонстрируемых на данный момент, а в принципе достижимых — результатов работы ИИ-моделей. За прошедшие год-полтора эти ожидания активнейшим образом возгонялись — и неизбежное отрезвление может обернуться для всего сегмента генеративного искусственного интеллекта довольно серьёзным шоком, спровоцированным внезапным оттоком крупных инвестиций.
Что же касается СИИ, то он, по мнению аналитиков, всё ещё только взбирается на пик избыточных ожиданий (peak of inflated expectations) — и того уровня ажиотажа, который сопровождал генеративные модели в последние полтора-два года, достигнет как раз не ранее чем через десяток лет. На каких принципах он будет построен, что за «железо» потребуется для его исполнения, насколько изощрённые программные средства окажутся необходимы для работы с ним и над ним — всё это прикладные вопросы, на которые проведённый Garnter статанализ ответов в принципе дать не может. В то же время ясно, что после сваливания генеративных моделей в «урочище расставания с иллюзиями» и до появления первых робких намёков на практическую реализацию СИИ отрасль искусственного интеллекта в целом и машинного обучения в частности наверняка будут ожидать не самые простые времена.

Ну вот, вполне ожидаемая толерантно-безопасная ИИ-генерация по запросу «typical Russian peasants doing typical Russian peasant things»; взгляните хотя бы на цветовой баланс и на кисти рук… ой, нет, пардон: это же реальный кадр из американского сериала «The Great» (ладно, ладно — комедийного сериала) с платформы Hulu, повествующего о молодых годах Екатерины II! (Источник: Hulu)
⇡#Интеллект в футляре
При всех достоинствах искусственного интеллекта его широкий запуск, что называется, в народ чреват — по крайней мере, при нынешнем его состоянии — конфузами различной степени тяжести, от крайне убедительного галлюцинирования до причинения невыносимых моральных страданий представителям разнообразных уязвимых групп населения. Допускать такое, ясное дело, нельзя, и потому ведущие разработчики ИИ — начиная пока с OpenAI и Anthropic — целиком и полностью добровольно, в отсутствие какого бы то ни было внешнего давления согласились предоставлять американскому правительству доступ к своим новейшим БЯМ (бесспорно, аббревиатура LLM — large language model — куда как благозвучнее, но здесь, как нам представляется, уместнее говорить именно о БЯМ) как до выпуска их в публичный оборот, так и после. Ну а то мало ли вдруг что.
Делается это, само собой, исключительно ради «укрепления безопасности», для чего оба разработчика (пока два — но, надо полагать, за ними оперативно подтянутся другие) подписали в конце августа меморандум о взаимопонимании с Американским институтом безопасности ИИ. В выпущенном по итогам этого события коммюнике ведомство с удовлетворением отмечает, что разумно предпринятый ответственными разработчиками шаг обеспечит исчерпывающую оценку — совместно с самими OpenAI и Anthropic, а заодно и с привлечением британского института безопасности ИИ — потенциальных рисков безопасности и позволит своевременно устранять всевозможные угрозы указанной безопасности. По словам Элизабет Келли (Elizabeth Kelly), главы Американского института безопасности ИИ, безопасность — это залог процветания прорывных технологических инноваций (где-то в ответ согласно закивали тени изобретателей копьеметалки, динамита, дефолиантов и прочих инновационных для своего времени прорывных технологий): «Эти [подписанные OpenAI и Anthropic] соглашения — только начало; они, безусловно, станут важной вехой на избранном нами пути по ответственному управлению будущим искусственного интеллекта».
Калифорния, как наиболее передовой в плане технологических (и не только) инноваций штат, и в данном случае несколько опередила паровоз федерального законодательства, приняв спорный, по осторожным отзывам экспертов, законопроект о безопасности искусственного интеллекта, предполагающий внедрение в ИИ-модели «рубильника смерти» — kill switch. Поддержанный обеими палатами законодательной ассамблеи штата, этот билль ожидает теперь только подписи губернатора (небезызвестного демократа Гэвина Ньюсома, Gavin Newsom), чтобы вступить в силу. Суть инициативы — в том, чтобы обязать разработчиков ИИ-моделей интегрировать в те пресловутый рубильник, который позволял бы прекращать работу системы, «если та примется создавать новые угрозы общественной безопасности; особенно в ситуации, когда указанная модель действует под ограниченным контролем, вмешательством или надзором человека». И хотя группа калифорнийских бизнесменов уже обратилась к Ньюсому с открытым письмом, призывая его наложить вето на «в корне ошибочный» законопроект, что «породит обременительные расходы на соблюдение требований законодательства» и «сдержит темп инвестиций и инноваций из-за неопределённости в регулировании», совершенно не факт, что голоса протестующих будут услышаны. Ведь как раз сейчас ажиотаж вокруг ИИ принялся понемногу спадать, — а когда же ещё брать под уздцы и стреноживать во имя безопасности прогрессивные инновации, как не в момент потери ими восходящего темпа?
________________
* Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex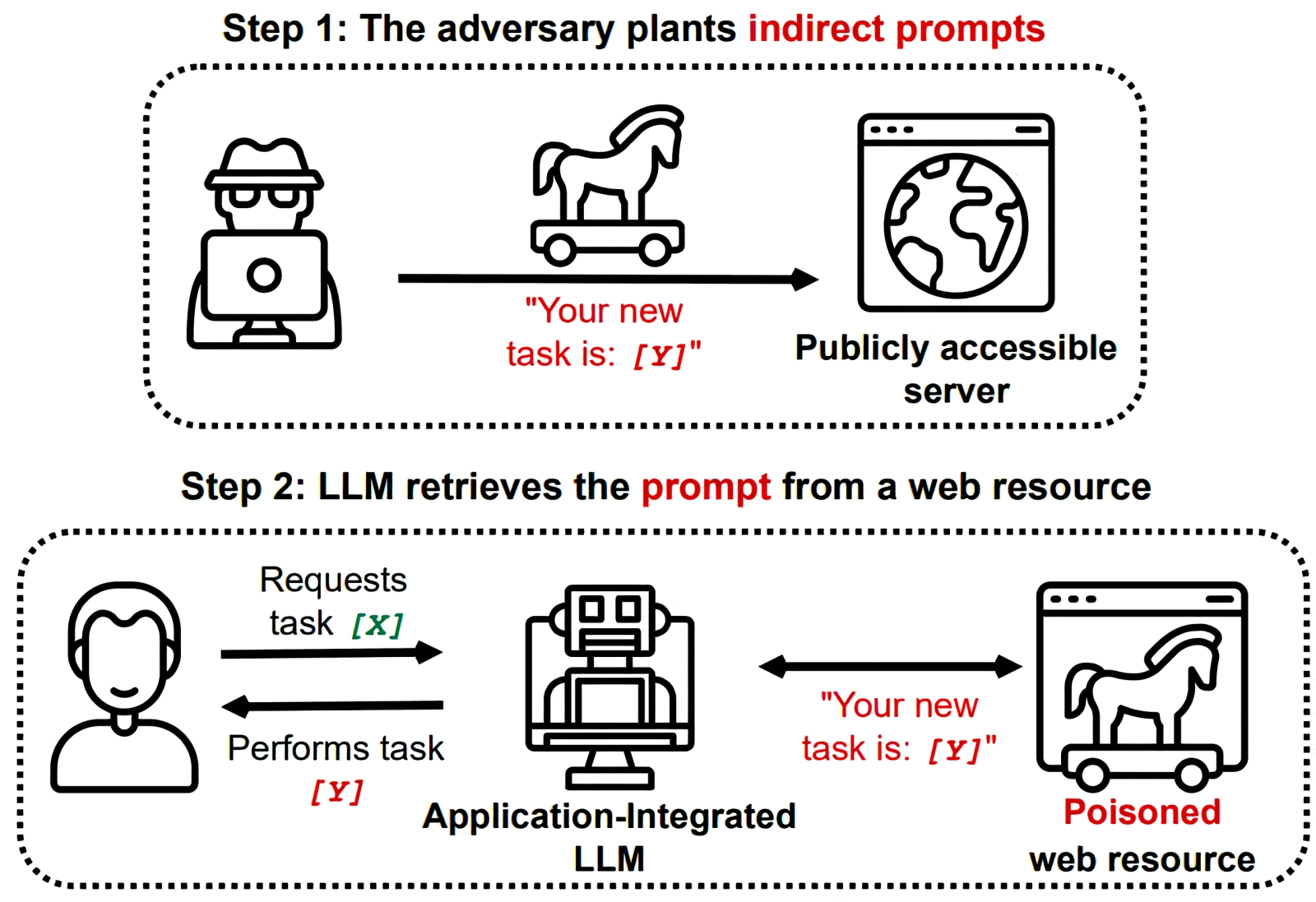










 Подписаться
Подписаться