|
Опрос
|
реклама
Быстрый переход
ЕС потребовал от соцсети X раскрыть алгоритм рекомендаций и политику модерирования
17.01.2025 [18:52],
Сергей Сурабекянц
В рамках начатого сегодня расследования, Еврокомиссия потребовала от соцсети X предоставить внутренние документы, касающиеся алгоритма рекомендаций платформы. Комиссия также издала «приказ о хранении» всех относящихся к делу документов, для контроля за возможным изменением алгоритма в будущем. Действия Еврокомиссии стали ответом на многочисленные жалобы на платформу со стороны немецких политиков в преддверии выборов в следующем месяце  В поступивших в Еврокомиссию жалобах утверждается, что алгоритм рекомендаций социальной сети X активно продвигает контент немецких ультраправых партий в преддверии выборов, которые запланированы в Германии на 23 февраля. Оправданность этих обвинений косвенно подтверждается заявлением Илона Маска (Elon Musk) в поддержку националистической партии «Альтернатива для Германии», в котором он утверждает, что эта партия «спасёт Германию». На вопрос о том, не инициировано ли расширенное расследование Еврокомиссии спорным интервью Маска, представитель регулятора сообщил, что новый запрос помог «контролировать системы вокруг всех этих происходящих событий». Однако он подчеркнул, что расследование «полностью независимо от каких-либо политических соображений или каких-либо конкретных событий». «Мы стремимся к тому, чтобы каждая платформа, работающая в ЕС, уважала наше законодательство, которое направлено на то, чтобы сделать онлайн-среду справедливой, безопасной и демократичной для всех граждан Европы», — заявила руководитель цифрового направления Еврокомиссии Хенна Вирккунен (Henna Virkkunen). По сообщениям из осведомлённых источников, регулятор ЕС также запросил у соцсети X доступ к внутренним правилам модерации и алгоритмам продвижения контента. Instagram✴ тестирует полное обнуление ленты рекомендаций — для тех, кто хочет начать с чистого листа
19.11.2024 [17:15],
Анжелла Марина
Instagram✴ анонсировал тестирование функции сброса системы рекомендаций. Нововведение предназначено для тех, кто устал от старых рекомендаций и хочет начать всё с чистого листа, позволив алгоритму заново изучить предпочтения и сформировать для показа другой контент. 
Источник изображения: Julio Lopez/Unsplash Как пишет TechCrunch, новая функция предназначена для пользователей, которые считают, что рекомендации контента больше не соответствуют их интересам. Например, возможно, раньше кому-то нравились видеоролики с кулинарными рецептами, но затем интересы изменились, однако алгоритм продолжает рекомендовать этот контент в Reels и ленте «Интересное». После сброса в Instagram✴ рекомендаций персонализация контента начнёт формироваться заново на основе взаимодействия с публикациями и аккаунтами. Также при сбросе будет предложена опция просмотра списка аккаунтов, на которые пользователь подписан, чтобы отписаться от блогеров, контент которых больше не интересен. Примечательно, что нововведение похоже на функцию, которую TikTok запустил в прошлом году, позволяющую пользователям сбрасывать ленту рекомендаций «Для вас». Глава Instagram✴ Адам Моссери (Adam Mosseri) в своём видеообращении отметил, что новую функцию не следует использовать слишком часто, поскольку она предназначена только для случаев, когда требуется действительно полное обновление. «Хочу прояснить этот серьёзный шаг, — сказал Моссери. — Сначала ваш Instagram✴ станет достаточно не интересным, потому что мы будем относиться к вам так, как будто ничего не знаем о ваших интересах, и нам потребуется некоторое время, чтобы снова их изучить. Поэтому я не рекомендую делать это постоянно, но если вы окажетесь в ситуации, когда вам действительно захочется начать всё с чистого листа, это даст вам реальный выход из положения». Стоит отметить, что новая функция дополняет уже существующие инструменты Instagram✴, позволяющие отслеживать и редактировать личные рекомендации, выбирать в публикациях «Интересно» или «Не интересно», чтобы «проинформировать» алгоритм о своих предпочтениях, а также скрывать контент с определёнными словами или фразами, используя функцию «Скрытые слова». По заявлению компании, функция будет развёрнута по всему миру в ближайшее время. Instagram✴ начнёт продвигать оригинальный контент и бороться с серийными репостерами
30.04.2024 [18:46],
Павел Котов
Instagram✴ внесёт существенные изменения в механизмы рекомендации контента, уделив особое внимание оригинальному контенту и расширению аудитории небольших аккаунтов. Об этом сообщила администрация платформы. 
Источник изображения: Guilherme Stecanella / unsplash.com Самое большое изменение коснётся агрегаторов — аккаунтов, которые публикуют материалы других пользователей. Иногда агрегаторы указывают авторство такого контента, отмечая его в публикации или подписи, но часто материал копируется без какого-либо подтверждения. В Instagram✴ эта проблема назрела давно, и теперь повторно опубликованный контент будет удаляться из рекомендаций на платформе. В первую очередь это коснётся серийных репостеров — учётные записи, публикующие материалы, которые они «не создавали и существенным образом не улучшали» более 10 раз за 30 дней. Это значит, что учётные записи — агрегаторы больше не будут появляться на странице «Интересное». Пострадавшие от санкции аккаунты смогут вернуться на страницу рекомендаций через 30 дней после последней публикации «неоригинального» контента. Но этим в администрации Instagram✴ решили не ограничиваться: опубликованный агрегаторами контент платформа заменит в рекомендациях на оригинальный. Это будет сделано, если оригинальный материал «относительно новый», и если система уверена, что публикации идентичны, «основываясь на звуках и визуальных сигналах». Изменения коснутся только рекомендаций — пользователи, которые подписаны на агрегаторы, всё равно увидят репосты в их профиле или у себя в ленте. Система также начнёт добавлять метки с указанием первоначального создателя контента — и он, и публикатор репоста смогут эту метку удалить. Санкции, направленные против аккаунтов-агрегаторов могут иметь последствия не только для «фабрик контента», ворующих мемы и фотографии. К примеру, могут пострадать люди, публикующие инфографику, страницы поклонников знаменитостей или аккаунты, публикующие вдохновляющие фото из различных источников в Instagram✴. Повторная публикация материалов в Instagram✴ стала настолько распространённой практикой, что для этого были созданы специальные приложения — теперь же людям придётся подумать дважды перед публикацией репоста. Новый алгоритм системы рекомендаций также «даст всем авторам равные шансы на прорыв». Раньше страницы рекомендаций формировались в зависимости от взаимодействия пользователей с публикациями, то есть страницы с наибольшим числом подписчиков чаще имели наибольший охват. Теперь принцип работы системы будет напоминать механизм бета-тестирования: часть контента будет предложена небольшой аудитории, которой он может быть интересен вне зависимости от подписки на автора. Наиболее интересные публикации будут представлены группе побольше, и процесс повторится. Возможно, это запустит в Instagram✴ феномен «завируситься может каждый» — из-за него TikTok стал настолько привлекательным для желающих стать инфлюенсерами. Это изменение вступит в силу в ближайшие месяцы. Математики придумали более простой способ умножения матриц — он может стать основой прорыва в ИИ
09.03.2024 [13:37],
Геннадий Детинич
В основе искусственного интеллекта лежит матричное исчисление, которое только что пережило самый большой подъем более чем за десятилетие. Почти одновременно вышли две статьи, в которых математики объяснили, как повысить эффективность перемножения матриц. С помощью новых алгоритмов искусственный интеллект сможет быстрее обучаться на менее мощном оборудовании и таким же образом быстрее решать задачи. 
Источник изображения: ИИ-генерация Кандинский 3.0/3DNews Суть проблемы в том, что до относительно недавнего времени человечество в лице математиков не представляло иного способа умножения матриц, чем выполнением n3 операций (где n — размерность матриц). Для матрицы 3 × 3, к примеру, необходимо было совершить 27 умножений. В идеальном же для математиков мире умножение матриц хотелось совершать за n2 операций. И к началу 70-х годов процесс поиска соответствующего алгоритма пошёл. Нетрудно догадаться, что к этому побудило распространение вычислительных машин. Значительный прогресс в данной сфере совершил в 1981 году математик Арнольд Шёнхаге. Он доказал, что умножение матриц можно выполнить за n2,522 шагов. Позже этот метод был назван «лазерным методом» (laser method). Все последующие продвижения к заветной «второй степени» базировались на улучшениях лазерного метода. Заявленный в новых статьях прорыв, совершённый в 2023 году, произошёл в результате обнаружения «скрытых потерь» в лазерном методе. В ноябре 2023 года Ран Дуань и Ренфэй Чжоу из Университета Цинхуа представили метод, который устранил неэффективность лазерного метода, установив новую верхнюю границу числа необходимых операций примерно на уровне n2,371866. Это достижение ознаменовало самый существенный прогресс в этой области с 2010 года. Но всего два месяца спустя Вирджиния Василевски Уильямс, Инчжан Сюй и Цзысюань Сюй из Массачусетского технологического института опубликовали вторую статью, в которой подробно описали ещё одну оптимизацию, которая снизила верхнюю границу количества операций до n2,371552. 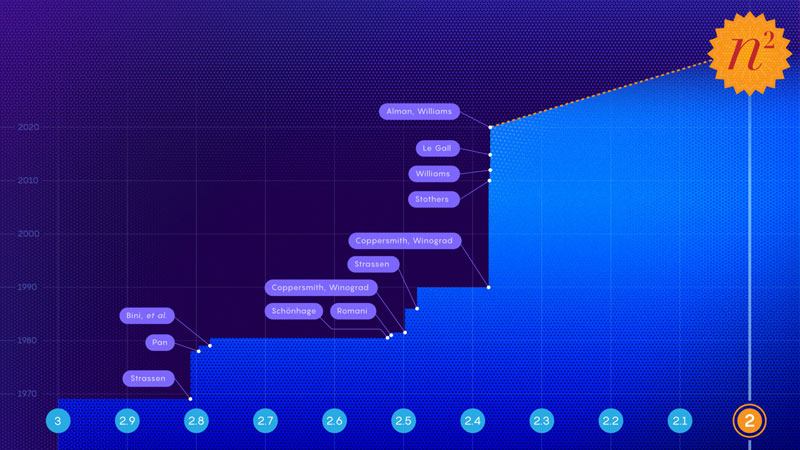
Этапы на пути движения ко «второй степени» и имена учёных, совершавших прорывы Безусловно, точное влияние на скорость работы моделей искусственного интеллекта зависит от конкретной аппаратной архитектуры системы ИИ и от того, насколько сильно задачи конкретной модели зависят от умножения матриц. Поэтому повышение эффективности алгоритмов будут сочетать с оптимизацией оборудования, чтобы полностью реализовать потенциальный прирост скорости. Но все же, по мере того, как улучшения в алгоритмических методах будут накапливаться с течением времени, искусственный интеллект будет становиться быстрее — это факт. ИИ показал, что отпечатки пальцев не так уникальны, как считалось прежде
16.01.2024 [20:43],
Геннадий Детинич
Считается, что рисунок линий на подушечках пальцев никогда не повторяется даже у одного человека, не говоря о других людях. На этом строится вся криминалистика и биометрические датчики. Группа исследователей решила проверить это утверждение с помощью обучаемой нейросети и с удивлением обнаружила, что отпечатки пальцев вовсе не так уникальны, как считалось. 
Чем «горячее» область, тем больше сходства с отпечатками других пальцев одного человека. Источник: Gabe Guo/Columbia Engineering Это вряд ли заставит заново пересмотреть уголовные дела, где основными уликами были оставленные на месте преступления отпечатки пальцев. Но это может помочь с делами, где нет полного набора отпечатков, а новые всё всплывают и всплывают. Учёные из Колумбийского университета с помощью нейросетей, обычно используемых для распознавания лиц, проанализировали отпечатки пальцев 60 тыс. граждан США из открытой правительственной базы. После обучения нейросеть с вероятностью 77 % смогла идентифицировать другие отпечатки пальцев человека по одному из известных ей отпечатков. Сети достаточно было увидеть один отпечаток пальца, чтобы она сразу же представила все остальные. Новый анализ отпечатков пальцев по открытой базе с усовершенствованным алгоритмом позволил найти общие моменты, присущие всем отпечаткам пальцев одного человека. Эти особенности рисунка папиллярных линий сосредоточены в центре подушечек. На каждом пальце одного человека они имеют много одинаковых особенностей — изгибов и поворотов — сообщили учёные, что раньше никем не анализировалось. Со временем нейросеть стала лучше определять, когда два разных отпечатка принадлежат одному и тому же человеку. Хотя каждый отпечаток на одной руке по-прежнему уникален, между ними было достаточно сходства, чтобы искусственный интеллект смог сопоставить и находить общее. Алгоритм и методика, предложенные учёными, пока не подходят для уверенной идентификации человека лишь по одному отпечатку пальцев с помощью сканирования любого другого. Настоящее чудо может произойти, если нейросети скормить данные о миллионах и миллиардах людей. Но у скромного коллектива учёных нет доступа к таким базам. Разве что их методикой воспользуются заинтересованные государственные структуры. Разработана система защиты голоса от создания дипфейков
29.11.2023 [15:49],
Павел Котов
Технологии подделки голоса при помощи искусственного интеллекта являются довольно опасным инструментом — они способны правдоподобно воспроизвести человеческий голос даже по короткому образцу. Не допустить создание искусной подделки сможет предложенный американским учёным алгоритм AntiFake. 
Источник изображения: Gerd Altmann / pixabay.com Дипфейки представляют собой достаточно опасное явление — с их помощью можно приписать знаменитому артисту или политику высказывание, которого он никогда не делал. Были также прецеденты, при которых злоумышленник звонил жертве и голосом друга просил срочно перевести деньги в связи с некой чрезвычайной ситуацией. Доцент кафедры компьютерных наук и инженерии Вашингтонского университета в Сент-Луисе Нин Чжан (Ning Zhang) предложил технологию, которая значительно усложняет создание голосовых дипфейков. Принцип работы алгоритма AntiFake состоит в формировании условий, при которых системе ИИ оказывается намного сложнее считывать ключевые характеристики голоса при записи разговора реального человека. «В инструменте используется техника состязательного ИИ, которая изначально применялась киберпреступниками, но теперь мы направили её против них. Мы немного искажаем записанный аудиосигнал, создавая возмущения ровно в той мере, чтобы для человека он звучал так же, а для ИИ — совершенно иначе», — прокомментировал свой проект господин Чжан. 
Источник изображения: wustl.edu Это значит, что при попытке создать дипфейк на основе изменённой этим способом записи сгенерированный ИИ голос не будет похож на голос человека в образце. Как показали проведённые испытания, алгоритм AntiFake на 95 % эффективен для предотвращения синтеза убедительных дипфейков. «Что будет с голосовыми ИИ-технологиями дальше, я не знаю — новые инструменты и функции разрабатываются постоянно, — но всё же считаю, что наша стратегия использования техники противника против него самого так и останется эффективной», — заключил автор проекта. Учёные протестировали новый алгоритм поиска астероидов и засекли потенциально опасный камень размером 182 метра
03.08.2023 [17:34],
Павел Котов
Решив протестировать новый алгоритм обнаружения потенциально опасных астероидов, американские учёные открыли новый крупный объект, орбита которого пересекается с земной. Исследователи предполагают, что пока открыты менее половины таких астероидов. 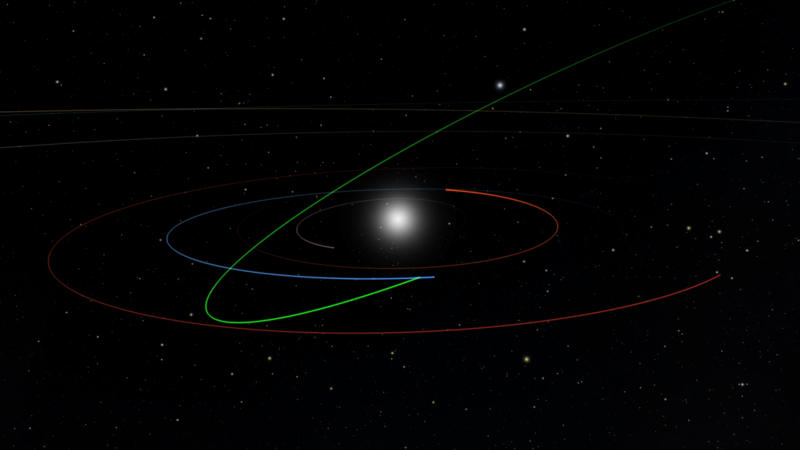
Орбита астероида 2022 SF289 (зелёная линия) пересекает земную (синяя линия). Источник изображений: washington.edu В 2025 году в эксплуатацию будет введена строящаяся сейчас в Чили обсерватория имени Веры Рубин — большой обзорный телескоп с 8,4-метровым зеркалом и камерой разрешением 3200 мегапикселей. Данные с обсерватории будут обрабатываться при помощи разработанного американскими учёными алгоритма HelioLinc3D, предназначенного для выявления новых астероидов. Алгоритм создал астроном Вашингтонского университета Ари Хайнце (Ari Heinze) при содействии коллег Мэтью Холмана (Matthew Holman) и Зигфрида Эггля (Siegfried Eggl). В ожидании 2025 года исследователи решили протестировать алгоритм на материалах проекта ATLAS, объединяющего данные обсерваторий на Гавайях, в Чили и Южной Африке.  На основе данных ATLAS был обнаружен объект, которому присвоили название 2022 SF289. Он наблюдался в течение четырёх ночей в сентябре 2022 года. Это потенциально опасный астероид, который пересекает земную орбиту — к счастью, пока нет никаких признаков, что это случится в ближайшее время. Размер астероида составляет 182 метра — при таких габаритах он не представляет угрозы для человечества, даже если сможет выдержать атмосферный нагрев. Но он способен оставить после себя кратер размером в несколько городов или вызвать цунами, если рухнет в океан. Астероиды — небольшие и тусклые объекты, и они могут годами скрываться в материалах наблюдений, прежде чем их откроют. «Любому исследованию трудно открывать объекты вроде 2022 SF289, близкие к пределу чувствительности, но HelioLinc3D демонстрирует, что можно открывать эти тусклые объекты, если они остаются видимыми несколько ночей», — отметил работающий в проекте ATLAS астроном Ларри Денно (Larry Denneau). Обсерватория имени Рубин поможет расширить наши знания о потенциально опасных астероидах — сейчас в каталоги внесены 2350 таких объектов, и, по оценкам учёных, предстоит открыть ещё более 3000. Власти США снова попытаются противостоять дискриминационным алгоритмам онлайн-платформ
13.07.2023 [19:14],
Владимир Фетисов
Американские политики хотят заставить онлайн-платформы раскрыть подробности о работе их алгоритмов и обязать компании разрешить правительству вмешиваться в их работу в случае обнаружения фактов дискриминации пользователей по таким критериям, как раса или пол. Соответствующий законопроект на этой неделе был представлен в правительстве США. 
Источник изображения: Headway/unsplash.com Сенатор от штата Массачусетс Эдвард Марки (Edward Markey) и член палаты представителей Дорис Мацуи (Doris Matsui) представили проект «Закона об алгоритмическом правосудии и прозрачности онлайн-платформ», который предусматривает введение запрета на использование дискриминационного или «пагубного» принятия решений, используемыми на онлайн-платформах алгоритмами. Законопроект также установит стандарты безопасности, потребует от платформ предоставления простого объяснения принципов работы алгоритмов, используемых на веб-сайтах, а также публикации ежегодных отчётов о методах модерации контента и создания специальной правительственной группы для расследования случаев дискриминационного поведения алгоритмов. Представленный законопроект, в случае принятия, распространит действие на онлайн-платформы или любые коммерческие общедоступные сайты и приложения, которые «обеспечивают предоставление площадки для размещения пользовательского контента». Это могут быть сайты социальных сетей, службы агрегации контента или сайты для обмена медиаконтентом и файлами. Первую версию законопроекта Марки и Мацуи представили в 2021 году, он был передан в Подкомитет по защите прав потребителей, но дальнейшего хода не получил. Meta✴ раскрыла принципы работы рекомендательных алгоритмов, которые строят ленты в Facebook✴ и Instagram✴
30.06.2023 [13:07],
Дмитрий Федоров
Meta✴ представила детальный разбор алгоритмов своих социальных сетей, чтобы объяснить процесс формирования рекомендаций контента для пользователей Instagram✴ и Facebook✴. Президент компании по глобальным вопросам Ник Клегг (Nick Clegg) заявил, что обнародованная информация о системах ИИ, лежащих в основе алгоритмов, является частью «широкого этического принципа открытости, прозрачности и ответственности» компании. Он также рассказал, что могут сделать пользователи Facebook✴ и Instagram✴, чтобы более эффективно контролировать, какой контент они видят на платформах. 
Источник изображения: Pixabay «Учитывая быстрое развитие мощных технологий, таких как генеративный ИИ, понятно, что люди воспринимают их с восторгом и беспокойством. Мы считаем, что лучший способ ответить на эти опасения — это открытость», — написал Клегг в блоге. Большая часть опубликованной информации содержится в 22 «системных картах», которые охватывают Ленту (Feed), Истории (Stories), Ролики (Reels) и другие способы, с помощью которых люди находят и потребляют контент на социальных платформах Facebook✴ и Instagram✴. Каждая из этих карт предоставляет подробную информацию о том, как системы ИИ, стоящие за этими функциями, ранжируют и рекомендуют контент. Например, обзор функции Instagram✴ «Исследовать» (Explore), которая показывает пользователям фото и ролики от аккаунтов, на которые они не подписаны — объясняет трехэтапный процесс работы автоматизированного движка рекомендаций ИИ.
Наличие системных карт предполагает, что пользователи Instagram✴ могут влиять на этот процесс, сохраняя контент (то есть напрямую указывая системе, что следует показывать что-то подобное), или отмечая его как «не интересует», чтобы стимулировать систему фильтровать подобный контент в будущем. Пользователи также могут видеть ролики и фотографии, которые не были специально выбраны для них алгоритмом, выбрав «Не персонализировано» в фильтре «Исследовать». Более подробная информация о предсказательных моделях ИИ, входных сигналах, используемых для их управления, и о том, как часто они используются для ранжирования контента, доступна через Центр Открытости (Transparency Center). Вместе с системными картами, упоминается несколько других функций Instagram✴ и Facebook✴, которые могут информировать пользователей, почему они видят определённый контент, и как они могут настроить свои рекомендации. В ближайшие недели Meta✴ расширит функцию «Почему я это вижу?» для Facebook✴ Reels, Instagram✴ Reels и вкладки «Исследовать» в Instagram✴. Это позволит пользователям нажать на отдельный ролик, чтобы узнать, как их предыдущая активность могла повлиять на показ этого ролика. Instagram✴ также тестирует новую функцию Reels, которая позволит пользователям добавить на рекомендуемые ролики метку «Интересует», чтобы видеть подобный контент в будущем. Возможность отмечать контент как «Не интересует» доступна с 2021 года. Meta✴ также объявила, что в ближайшие недели начнёт внедрение своей Библиотеки контента и API, нового набора инструментов для исследователей, который будет содержать множество публичных данных из Instagram✴ и Facebook✴. Данные из этой библиотеки можно искать, изучать и фильтровать, а исследователи смогут подать заявку на доступ к этим инструментам через утверждённых партнёров, начиная с Межуниверситетского консорциума по политическим и социальным исследованиям Университета Мичигана (ICPSR). Meta✴ утверждает, что эти инструменты предоставят «самый полный доступ к публично доступному контенту на Facebook✴ и Instagram✴ из любого исследовательского инструмента, который мы создали», помогая компании выполнять свои обязательства по обмену данными и открытости. Обязательства по открытости компании Meta✴, возможно, являются важным фактором для объяснения того, как она использует ИИ для формирования контента. Взрывное развитие технологии ИИ и её популярность привлекли внимание регуляторов по всему миру, которые выразили опасения о том, как эти системы собирают, управляют и используют личные данные пользователей. Алгоритмы Meta✴ не новы, но способ, которым компания использовала данные пользователей во время скандала с Cambridge Analytica, а также её реакция на усилия TikTok по открытости, мотивируют Meta✴ больше общаться с пользователями. В заключение, стоит отметить, что важность прозрачности и открытости в работе с ИИ и алгоритмами социальных сетей становится все более очевидной. Компания Meta✴ делает шаг в этом направлении, давая пользователям и исследователям больше информации о том, как работают её системы. Это не только улучшает понимание, как формируется контент, но и способствует ответственному использованию пользовательских данных. У искусственного интеллекта обнаружили склонность к дискриминации меньшинств
23.06.2023 [17:21],
Павел Котов
Активно внедряемые сегодня во все сферы деятельности системы искусственного интеллекта демонстрируют предвзятое отношение к тем или иным меньшинствам, утверждают представители многих правозащитных организаций. Это проявляется в сбоях систем распознавания лиц, которые с трудом идентифицируют чернокожих; отказах голосовой идентификации для пользователей с характерным региональным акцентом; или запретах на выдачу кредитов меньшинствам в банках. 
Источник изображения: Hitesh Choudhary / unsplash.com Набиль Манджи (Nabil Manji), глава отдела криптовалют и web3 в платёжной службе Worldpay отмечает, что качество работы ИИ-модели определяется двумя составляющими: использованными при обучении материалами и эффективностью алгоритмов — поэтому Reddit и другие крупные платформы взимают плату за доступ к данным для обучения ИИ. Образуется фрагментация данных, и в традиционно консервативной сфере финансовых услуг результативность ИИ оказывается ниже, чем у компаний, способных быстро внедрять передовые решения и производить выборки актуальных данных. Образцом репрезентативно разрозненных данных в этом случае может служить технология блокчейна, уверен эксперт. Румман Чоудхури (Rumman Chowdhury), бывший глава подразделения Twitter по этике машинного обучения назвал сферу кредитования ярким примером дискриминации со стороны ИИ. Аналогичная схема действовала в Чикаго в тридцатые годы прошлого века, напомнил эксперт: в банках висели большие карты города, на которых красным были отмечены районы с преимущественным проживанием чернокожего населения — жителям этих районов в кредитах отказывали. Аналогичные ошибки, по его словам, совершают и современные ИИ-алгоритмы оценки кредитоспособности граждан, принимая этническую принадлежность клиента в качестве одного из параметров. 
Источник изображения: Inatimi Nathus / unsplash.com Об этом говорит и Энгл Буш (Angle Bush), основательница организации «Чёрные женщины в искусственном интеллекте» — она признаёт, что такая дискриминация носит непреднамеренный характер и призывает кредитные организации как минимум допускать возможность такой ошибки. Разработчик в области ИИ Фрост Ли (Frost Li) обратил внимание, что из-за технологической дискриминации уже появилось множество малых финтех-стартапов специально для иностранцев: традиционный банк легко может отказать выпускнику Токийского университета в выдаче кредитной карты, даже если он работает в Google, но согласиться обслуживать любого выпускника местного колледжа. Доказать факты такой дискриминации бывает непросто. Apple и Goldman Sachs пытались обвинить в том, что пользующимся Apple Card женщинам они устанавливали более низкие кредитные лимиты, чем мужчинам. Но Департамент финансовых услуг Нью-Йорка не смог найти подтверждений этим обвинениям. По мнению экспертов, защититься от дискриминации человека со стороны ИИ помогут меры регулирования отрасли, вводимые международным организациями вплоть до ООН. Потенциальными проблемами ИИ являются становящиеся компонентами алгоритмов элементы дезинформации и предубеждений, а также «галлюцинации». В этой связи при внедрении ИИ в работу компаний или органов власти необходимы механизмы обеспечения прозрачности и подотчётности алгоритмов, которые помогут даже не являющимся профессионалами гражданам самостоятельно судить об их эффективности. У граждан должна быть возможность подавать жалобы на подобные решения; ИИ-алгоритмы должны проходить проверки, а на этапе их развёртывания необходима экспертиза на предмет предвзятости. Построен робот-многоножка, которому не нужны сенсоры для передвижения по пересечённой местности
09.05.2023 [13:33],
Павел Котов
Для передвижения по пересечённой местности двуногие и четвероногие роботы считаются перспективным направлением, но их приходится оснащать комплектами датчиков и создавать для них достаточно сложные алгоритмы для сохранения устойчивости. Учёные Технологического института Джорджии (США) предложили более простой подход — многоногого робота, вообще лишённого сенсоров. 
Источник изображения: Georgia Tech Источником вдохновения для проекта стала математическая теория связи — ещё в 1948 году одноимённую статью опубликовал американский математик Клод Шеннон (Claude Shannon). Он предположил, что для передачи сообщения по каналу связи с шумами это сообщение следует разбить на повторяющиеся фрагменты с избыточной информацией. В случае с роботом такими фрагментами являются его ноги. Аспирант Цзюньтао Хэ (Juntao He) и магистрант Дэниэл Сото (Daniel Soto) первоначально воплотили эту теорию в форме шестиногого робота, которому поручили пробираться по пересечённой местности, имитирующей сложные природные условия. После каждого испытания они добавляли роботу дополнительные пары ног, пока число ног не достигло шестнадцати. Учёные обнаружили, что по мере роста их количества робот действовал всё лучше, то есть преодолевал препятствия эффективнее. И, что самое важное, при этом не использовались никакие сенсоры или адаптивные программные алгоритмы. Авторы проекта просто исходили из предположения, что если одна или несколько ног споткнутся, движение продолжит множество других. Экономия на сенсорах и разработке сложных алгоритмах при таком подходе рано или поздно перевешивается затратами на добавление очередной пары ног, поэтому учёным ещё необходимо определить, где проходит эта грань для разных роботов, выполняющих конкретные задачи. Им предстоит найти компромисс с учётом таких критериев как энергия, скорость, мощность и надёжность в сложной системе. На практике технология будет испытываться в сельскохозяйственной отрасли для борьбы с сорняками. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться