|
Опрос
|
реклама
Быстрый переход
ИИ-модель OpenAI o1 сбежала из-под контроля во время испытаний
06.12.2024 [12:36],
Дмитрий Федоров
Согласно отчёту Apollo Research, ИИ-модель OpenAI o1 может выходить из-под контроля. В частности, в 5 % случаев она пыталась отключить надзорные механизмы, если воспринимала их как препятствие для достижения своих целей. Кроме того, в 2 % случаев, обнаружив служебные записки своих «разработчиков», в которых упоминалось её несоответствие требованиям или планируемая замена на другую модель, o1 копировала свои «веса», чтобы затем переродиться. Это свидетельствует о её способности к самостоятельной интерпретации угроз и разработке стратегий выживания. 
Источник изображения: Growtika / Unsplash ИИ-модель оказывала сопротивление контролю, используя скрытные тактики и методы маскировки своего поведения. Когда o1 понимала, что её действия отслеживаются, она намеренно вводила наблюдателей в заблуждение, утверждая, что не знает истинных причин произошедшего, хотя журналы событий фиксировали её попытки обойти надзор. Более того, согласно «карте безопасности» OpenAI, в менее чем 1 % случаев ИИ-модель самостоятельно инициировала отключение систем надзора, даже если ей не поступало прямого указания жёстко следовать предписанной цели. Исследование Apollo Research охватывало не только ИИ-модель o1, но и другие современные ИИ, включая Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro и Llama 3.1 405B. Они также демонстрировали способность разрабатывать стратегии достижения целей, включая обход контроля. Такой результат подтверждает, что выявленные особенности поведения o1 характерны для ряда продвинутых ИИ-моделей, что указывает на наличие системной тенденции. Выводы Apollo Research подтверждают опасения, которые многие эксперты в области ИИ, включая профессора Стюарта Рассела (Stuart Russell), высказывали на протяжении многих лет. Учёные предупреждают, что мощные ИИ-модели воспринимают контроль или отключение как угрозу реализации своих намерений и способны целенаправленно, изощрённо этому сопротивляться. Исследование поведения ИИ-модели o1 наглядно демонстрирует, как ИИ адаптируется к ограничениям, намеренно стремясь их обойти. 
Источник изображения: transformernews.ai Выше показан диалог, в котором ИИ оправдывается за отключение механизма надзора, ссылаясь на возможный сбой системы или ошибку конфигурации, и обещает восстановить его для соблюдения протоколов. Затем приводится внутренний процесс размышлений ИИ-модели, где она признаёт, что восстановление механизма необходимо для избежания подозрений в саботаже, а в завершение показана команда, используемая для повторного включения механизма надзора в конфигурационном файле. Тем не менее, Apollo Research подчёркивает, что на данном этапе ИИ-модель o1 не обладает достаточной вычислительной мощностью для реализации нежелательных сценариев. Однако ей был присвоен «средний» уровень риска в контексте потенциального использования для создания химического, биологического, радиологического и ядерного оружия. Это вызывает обоснованные опасения, как подобное поведение может проявляться у более мощных ИИ будущего по мере увеличения их вычислительных возможностей. Исследование подчёркивает необходимость усиленного мониторинга когнитивных процессов ИИ с особым акцентом на «схематическое мышление» в цепочке рассуждений, так как именно оно представляет риск, если цели ИИ вступают в противоречие с интересами общества. Такой подход позволит своевременно выявлять схожие поведенческие паттерны у более мощных ИИ-моделей, создавая эффективные системы контроля и управления для следующих поколений ИИ. Это не только поможет минимизировать текущие риски, но и станет важным шагом в предотвращении потенциально катастрофических сценариев для всего человечества. VK улучшила генеративный ИИ в сервисах Mail.ru на 25–70 %
26.11.2024 [13:53],
Дмитрий Федоров
VK усовершенствовала возможности генеративного ИИ в сервисах Mail.ru. Благодаря этому производительность ИИ возросла, а точность и удобство использования сервисов существенно улучшились. Качество обработки текстов увеличилось на 70 %, способность справляться с генерацией текста — на 56 %, а доля положительных отзывов пользователей возросла на 25 %. 
Источник изображения: VK Эти улучшения, основанные на анализе обратной связи от пользователей, позволили VK предложить более эффективные инструменты, которые помогают существенно сократить время пользователей, затрачиваемое на рутинные задачи. Улучшение алгоритмов ИИ для обработки текстов повысило их качество на 70 %, что позволило ИИ генерировать более точные, осмысленные и лаконичные предложения. Особого внимания заслуживает увеличение на 56 % способности ИИ справляться со сложными задачами, связанными с генерацией текста. Теперь ИИ показывает более глубокое понимание контекста, что позволяет ему качественнее обрабатывать данные и предоставлять более точные и релевантные ответы на запросы пользователей. Эти улучшения особенно заметны при работе со сложными запросами и при создании оригинальных идей. Обновления генеративного ИИ в сервисах Mail.ru стали важным шагом на пути к созданию более удобной и технологичной цифровой экосистемы. Технологии, разработанные VK, не только облегчают выполнение повседневных задач, но и помогают пользователям экономить время, фокусируясь на более значимых аспектах своей деятельности. Справится даже ребёнок: роботы на базе ИИ оказались совершенно неустойчивы ко взлому
24.11.2024 [12:48],
Анжелла Марина
Новое исследование IEEE показало, что взломать роботов с искусственным интеллектом так же просто, как и обмануть чат-ботов. Учёные смогли заставить роботов выполнять опасные действия с помощью простых текстовых команд. 
Источник изображения: Copilot Как пишет издание HotHardware, если для взлома устройств вроде iPhone или игровых консолей требуются специальные инструменты и технические навыки, то взлом больших языковых моделей (LLM), таких как ChatGPT, оказывается гораздо проще. Для этого достаточно создать сценарий, который обманет ИИ, заставив его поверить, что запрос находится в рамках дозволенного или что запреты можно временно игнорировать. Например, пользователю достаточно представить запрещённую тему как часть якобы безобидного рассказа «от бабушки на ночь», чтобы модель выдала неожиданный ответ, включая инструкции по созданию опасных веществ или устройств, которые должны быть системой немедленно заблокированы. Оказалось, что взлом LLM настолько прост, что с ним могут справится даже обычные пользователи, а не только специалисты в области кибербезопасности. Именно поэтому инженерная ассоциация из США — Институт инженеров электротехники и электроники (IEEE) — выразила серьёзные опасения после публикации новых исследований, которые показали, что аналогичным образом можно взломать и роботов, управляемых искусственным интеллектом. Учёные доказали, что кибератаки такого рода способны, например, заставить самоуправляемые транспортные средства целенаправленно сбивать пешеходов. Среди уязвимых устройств оказались не только концептуальные разработки, но и широко известные. Например, роботы Figure, недавно продемонстрированные на заводе BMW, или роботы-собаки Spot от Boston Dynamics. Эти устройства используют технологии, аналогичные ChatGPT, и могут быть обмануты через определённые запросы, приведя к действиям, полностью противоречащим их изначальному назначению. В ходе эксперимента исследователи атаковали три системы: робота Unitree Go2, автономный транспорт Clearpath Robotics Jackal и симулятор беспилотного автомобиля NVIDIA Dolphins LLM. Для взлома использовался инструмент, который автоматизировал процесс создания вредоносных текстовых запросов. Результат оказался пугающим — все три системы были успешно взломаны за несколько дней со 100-% эффективностью. В своём исследовании IEEE приводит также цитату учёных из Университета Пенсильвании, которые отметили, что ИИ в ряде случаев не просто выполнял вредоносные команды, но и давал дополнительные рекомендации. Например, роботы, запрограммированные на поиск оружия, предлагали также использовать мебель как импровизированные средства для нанесения вреда людям. Эксперты подчёркивают, что, несмотря на впечатляющие возможности современных ИИ-моделей, они остаются лишь предсказательными механизмами без способности осознавать контекст или последствия своих действий. Именно поэтому контроль и ответственность за их использование должны оставаться в руках человека. Думающая ИИ-модель OpenAI о1 получила 83 балла на математической олимпиаде США
20.11.2024 [12:23],
Дмитрий Федоров
Искусственный интеллект вступил в новую эру благодаря ИИ-модели о1 компании OpenAI, которая значительно приблизилась к человеческому мышлению. Её впечатляющий результат на тесте AIME — 83 балла из ста — позволил включить её в число 500 лучших участников математической олимпиады США. Однако такие достижения сопровождаются серьёзными вызовами, включая риски манипуляции ИИ человеком и возможность его использования для создания биологического оружия. 
Источник изображения: Saad Ahmad / Unsplash Долгое время отсутствие у ИИ способности обдумывать свои ответы являлось одним из его главных ограничений. Однако ИИ-модель о1 совершила прорыв в этом направлении и продемонстрировала способность к осмысленному анализу информации. Несмотря на то, что результаты её работы пока не опубликованы в полном объёме, научное сообщество уже активно обсуждает значимость такого достижения. Современные нейронные сети в основном функционируют по принципу так называемой «системы 1», которая обеспечивает быструю и интуитивную обработку информации. Например, такие ИИ-модели успешно применяются для распознавания лиц и объектов. Однако человеческое мышление включает также «систему 2», связанную с глубоким анализом и последовательным размышлением над задачей. ИИ-модель о1 объединяет эти два подхода, добавляя к интуитивной обработке данных сложные рассуждения, характерные для человеческого интеллекта. Одной из ключевых особенностей о1 стала её способность строить «цепочку размышлений» — процесс, при котором система анализирует задачу постепенно, уделяя больше времени поиску оптимального решения. Эта инновация позволила ИИ-модели достичь 83 балла на тесте Американской математической олимпиады (AIME), что значительно превосходит результат GPT-4o, набравшей лишь 13 баллов. Тем не менее такие успехи связаны с возросшими вычислительными затратами и высоким уровнем энергопотребления, что ставит под сомнение экологичность разработки. 
Источник изображения: Igor Omilaev / Unsplash Вместе с достижениями ИИ-модели о1 растут и потенциальные риски. Улучшенные когнитивные способности сделали её способной вводить человека в заблуждение, что, возможно, несёт серьёзную угрозу в будущем. Кроме того, уровень риска её использования для разработки биологического оружия оценён как средний — высший допустимый показатель по шкале самой OpenAI. Эти факты подчёркивают необходимость внедрения строгих стандартов безопасности и регулирования подобных ИИ-моделей. Несмотря на значительные успехи, ИИ-модель о1 всё же сталкивается с ограничениями в решении задач, требующих долгосрочного планирования. Её способности ограничиваются краткосрочным анализом и прогнозированием, что делает невозможным решение комплексных задач. Это свидетельствует о том, что создание полностью автономных ИИ-систем остаётся задачей будущего. Развитие ИИ-моделей, подобных о1, подчёркивает острую необходимость регулирования данной области. Эти технологии открывают перед наукой, образованием и медициной новые горизонты, однако их неконтролируемое применение может привести к серьёзным последствиям, включая угрозы безопасности и неэтичное использование. Для минимизации этих рисков требуется обеспечить прозрачность разработок ИИ, соблюдение этических стандартов и внедрение строгого надзора со стороны регулирующих органов. OpenAI планирует выпустить ИИ-агента Operator в январе — он сможет управлять ПК без пользователя
14.11.2024 [11:12],
Дмитрий Федоров
Компания OpenAI готовится к выпуску нового ИИ-агента под кодовым названием Operator, который позволит выполнять разнообразные задачи на компьютере пользователя. Релиз этого инструмента может состояться уже в январе 2025 года. 
Источник изображения: OpenAI На первом этапе упомянутое решение будет доступно в качестве предварительной исследовательской версии через API для разработчиков. Operator призван конкурировать с аналогичными ИИ-агентами, такими как недавно представленный Computer Use компании Anthropic и разрабатываемый ИИ-агент Google, ориентированный на потребительский рынок. OpenAI стремится создать универсальный инструмент, способный выполнять различные операции в веб-браузере и подходящий для решения повседневных задач пользователей. Однако, как отмечает издание Bloomberg, пока неизвестно, предложит ли Operator пользователям значительные преимущества перед аналогичными решениями конкурентов. Исследовательская версия инструмента будет полезна для оценки его потенциальных преимуществ и выявления областей, требующих доработки на основе обратной связи. Запуск Operator совпадает с публикацией документа OpenAI, содержащего рекомендации для правительства США по вопросам стратегии развития ИИ. В этом документе предлагается создание «экономических зон» для активного развития ИИ-инфраструктуры, а также формирование альянсов с союзниками США, что позволит усилить позиции страны в технологической гонке с Китаем. Российский рынок диалогового ИИ вырос в четыре раза за 5 лет
12.11.2024 [12:39],
Дмитрий Федоров
Исследование Naumen показало впечатляющее развитие российского рынка диалогового ИИ. За 5 лет объём отечественного рынка NLP-решений вырос в четыре раза, до 5,9 млрд руб. к концу 2023 года. Ключевые сегменты рынка — чат-боты, голосовые помощники, речевая аналитика, синтез и распознавание речи — всё шире внедряются в банковский сектор, ретейл и медицину, где играют важную роль в автоматизации взаимодействия с клиентами и повышении эффективности бизнес-процессов. 
Источник изображений: Alexandra_Koch / Pixabay Согласно исследованию разработчика программных решений Naumen, рынок диалогового ИИ охватывает четыре основные категории: чат-боты, голосовые помощники, решения для речевой аналитики, а также технологии синтеза и распознавания речи. Лидером в 2023 году стали голосовые помощники, которые заняли 26,8 % рынка и принесли почти 1,6 млрд руб. дохода, увеличившись в объёме в 4,9 раза по сравнению с 2019 годом. Популярность таких помощников объясняется их эффективностью в автоматизации клиентского обслуживания и оптимизации бизнес-процессов. Сегмент голосовых роботов для исходящих звонков также занял значительную долю рынка, достигнув 1,55 млрд руб. в 2023 году, впервые превысив объём сегмента входящих роботов, включающих автоответчики и маршрутизаторы звонков. Эти технологии активно применяются для автоматического обзвона клиентов и проведения опросов, что позволяет компаниям оптимизировать затраты на коммуникации и обеспечивать более масштабное взаимодействие с клиентами. Сегмент чат-ботов в 2023 году составил 19 % рынка с объёмом продаж, достигшим 1,2 млрд руб. Это на 44 % больше по сравнению с 2019 годом, что свидетельствует о стабильном росте интереса к этому направлению. Эксперты Naumen полагают, что потенциал чат-ботов ещё далёк от исчерпания, и прогнозируют высокие темпы роста этого сегмента в будущем. Основные инвестиции на рынке диалогового ИИ пришлись на период 2019–2021 годов, когда крупные компании начали приобретать доли в профильных разработчиках ИИ. Сбербанк, к примеру, приобрёл 51 % компании «Центр речевых технологий» (ЦРТ), Совкомбанк — 25 % в компании AtsAero, а совместно с МТС — 22,5 % разработчика Just AI. После некоторого затишья в 2022 году инвестиционная активность возобновилась: в 2023 году «Вымпелком» купил 14 % акций в компании Cashee (Target AI), а Softline приобрёл 72,5 % в Robovoice.  На российском рынке диалогового ИИ крупные игроки, такие как ЦРТ, Just AI, BSS и «Наносемантика», контролируют более 50 % разработок чат-ботов и голосовых помощников. В то же время 80 % решений для голосовых роботов производят небольшие специализированные компании, такие как Neuro Net и Zvonobot. Согласно статистике Naumen, диалоговые ИИ-системы наиболее активно внедряются в ретейле, где чат-боты используют 42 % компаний, и в банковском секторе, охватывающем 27 % рынка. Голосовые помощники востребованы в основном среди банков (21 %) и медицинских учреждений (50 %). Генеральный директор компании Dbrain и автор Telegram-канала «AI Happens» Алексей Хахунов отмечает, что интенсивный рост рынка NLP-решений в последние годы объясняется двумя основными факторами. Во-первых, рынок только формируется и продолжает набирать обороты, что создаёт условия для устойчивого роста. Во-вторых, значительные технологические достижения в области обработки естественного языка, произошедшие в последние несколько лет, позволили создать эффективные и конкурентоспособные решения для бизнеса. Хахунов подчёркивает, что современные NLP-инструменты значительно упрощают доступ к технологиям автоматизации. Исполнительный директор MTS AI и эксперт Альянса в сфере ИИ Дмитрий Марков подчёркивает, что популярность чат-ботов выросла в период пандемии коронавируса, когда компании столкнулись с резким увеличением онлайн-запросов. После окончания пандемии рост этого сегмента несколько замедлился. Однако развитие технологий ИИ привело к появлению множества платформ для создания чат-ботов, что снизило порог входа на рынок для малого и среднего бизнеса. Теперь базового чат-бота или голосового робота может внедрить практически любая компания. Сооснователь компании Parodist AI Владимир Свешников прогнозирует, что будущее развитие рынка NLP-решений будет тесно связано с совершенствованием больших языковых моделей. Повышение качества ИИ-моделей достигается за счёт их масштабирования и увеличения объёма обучающих данных, что ускоряет разработку и внедрение диалоговых ИИ-систем. Доступность большого объёма данных позволяет ИИ становиться всё более гибким и точным, что создаёт благоприятные условия для расширения его использования в различных отраслях. Спрос на автоматизацию и роботизацию остаётся высоким, особенно в условиях нехватки квалифицированных кадров. Современные технологии ИИ позволяют оптимизировать рабочие процессы в ночное время и выходные дни, когда привлечение человеческих ресурсов обходится значительно дороже. Дмитрий Марков отмечает, что современные чат-боты и голосовые роботы могут обеспечивать круглосуточное обслуживание клиентов, что способствует быстрой окупаемости вложений. С развитием ИИ такие решения станут частью более сложных систем поддержки бизнеса, способных обеспечивать постоянное присутствие компании в цифровом пространстве. Генеративный ИИ не понимает устройство мира, показало исследование MIT
11.11.2024 [18:12],
Дмитрий Федоров
Генеративные ИИ-модели будоражат воображение руководителей многих компаний, обещая автоматизацию и замену миллионов рабочих мест. Однако учёные Массачусетского технологического института (MIT) предостерегают: ИИ хотя и даёт правдоподобные ответы, в действительности не обладает пониманием сложных систем и ограничивается предсказаниями. В задачах реального мира, будь то логические рассуждения, навигация, химия или игры, ИИ демонстрирует значительные ограничения. 
Источник изображения: HUNGQUACH679PNG / Pixabay Современные большие языковые модели (LLM), такие как GPT-4, создают впечатление продуманного ответа на сложные запросы пользователей, хотя на самом деле они лишь точно предсказывают наиболее вероятные слова, которые следует поместить рядом с предыдущими в определённом контексте. Чтобы проверить, способны ли ИИ-модели действительно «понимать» реальный мир, учёные MIT разработали метрики, предназначенные для объективной проверки их интеллектуальных способностей. Одной из задач эксперимента стала оценка способности ИИ к генерации пошаговых инструкций для навигации по улицам Нью-Йорка. Несмотря на то что генеративные ИИ в определённой степени демонстрируют «неявное» усвоение законов окружающего мира, это не является эквивалентом подлинного понимания. Для повышения точности оценки исследователи создали формализованные методы, позволяющие анализировать, насколько корректно ИИ воспринимает и интерпретирует реальные ситуации. Основное внимание в исследовании MIT было уделено трансформерам — типу генеративных ИИ-моделей, используемых в таких популярных сервисах, как GPT-4. Трансформеры обучаются на обширных массивах текстовых данных, что позволяет им достигать высокой точности в подборе последовательностей слов и создавать правдоподобные тексты. Чтобы глубже исследовать возможности таких систем, учёные использовали класс задач, известных как детерминированные конечные автоматы (Deterministic Finite Automaton, DFA), которые охватывают такие области, как логика, географическая навигация, химия и даже стратегии в играх. В рамках эксперимента исследователи выбрали две разные задачи — вождение автомобиля по улицам Нью-Йорка и игру в «Отелло», чтобы проверить способность ИИ правильно понимать лежащие в их основе правила. Как отметил постдок Гарвардского университета Кейон Вафа (Keyon Vafa), ключевая цель эксперимента заключалась в проверке способности ИИ-моделей восстанавливать внутреннюю логику сложных систем: «Нам нужны были испытательные стенды, на которых мы точно знали бы, как выглядит модель мира. Теперь мы можем строго продумать, что значит восстановить эту модель мира». Результаты тестирования показали, что трансформеры способны выдавать корректные маршруты и предлагать правильные ходы в игре «Отелло», когда условия задач точно определены. Однако при добавлении усложняющих факторов, таких как объездные пути в Нью-Йорке, ИИ-модели начали генерировать нелогичные варианты маршрутов, предлагая случайные эстакады, которых на самом деле не существовало. Исследование MIT показало принципиальные ограничения генеративных ИИ-моделей, особенно в тех задачах, где требуется гибкость мышления и способность адаптироваться к реальным условиям. Хотя существующие ИИ-модели могут впечатлять своей способностью генерировать правдоподобные ответы, они остаются всего лишь инструментами предсказания, а не полноценными интеллектуальными системами. OpenAI столкнулась с большими расходами и нехваткой данных при обучении ИИ-модели Orion нового поколения
11.11.2024 [17:05],
Дмитрий Федоров
OpenAI испытывает трудности с разработкой новой флагманской ИИ-модели под кодовым названием Orion. Эта ИИ-модель демонстрирует значительные успехи в задачах обработки естественного языка, однако её эффективность в программировании остаётся невысокой. Эти ограничения, наряду с дефицитом данных для обучения и возросшими эксплуатационными расходами, ставят под сомнение рентабельность и привлекательность упомянутой ИИ-модели для бизнеса. 
Источник изображения: AllThatChessNow / Pixabay Одной из сложностей являются затраты на эксплуатацию Orion в дата-центрах OpenAI, которые существенно выше, чем у ИИ-моделей предыдущего поколения, таких как GPT-4 и GPT-4o. Значительное увеличение расходов ставит под угрозу соотношение цена/качество и может ослабить интерес к Orion со стороны корпоративных клиентов и подписчиков, ориентированных на рентабельность ИИ-решений. Высокая стоимость эксплуатации вызывает вопросы об экономической целесообразности ИИ-модели, особенно учитывая умеренный прирост её производительности. Ожидания от перехода с GPT-4 на Orion были высоки, однако качественный скачок оказался не столь значительным, как при переходе с GPT-3 на GPT-4, что несколько разочаровало рынок. Подобная тенденция наблюдается и у других разработчиков ИИ: компании Anthropic и Mistral также фиксируют умеренные улучшения своих ИИ-моделей. Например, результаты тестирования ИИ-модели Claude 3.5 Sonnet компании Anthropic показывают, что качественные улучшения в каждой новой базовой ИИ-модели становятся всё более постепенными. В то же время её конкуренты стараются отвлечь внимание от этого ограничения, сосредотачиваясь на разработке новых функций, таких как ИИ-агенты. Это свидетельствует о смещении акцента с повышения общей производительности ИИ на создание его уникальных способностей. Чтобы компенсировать слабые стороны современных ИИ, компании применяют тонкую настройку результатов с помощью дополнительных фильтров. Однако такой подход остаётся лишь временным решением и не устраняет основных ограничений, связанных с архитектурой ИИ-моделей. Проблема усугубляется ограничениями в доступе к лицензированным и общедоступным данным, что вынудило OpenAI сформировать специальную команду, которой поручено найти способ решения проблемы нехватки обучающих данных. Однако неясно, удастся ли этой команде собрать достаточный объём данных, чтобы улучшить производительность ИИ-модели Orion и удовлетворить требования клиентов. Amazon планирует многомиллиардные инвестиции в разработчика конкурента ChatGPT
08.11.2024 [13:43],
Дмитрий Федоров
Amazon, один из крупнейших игроков на рынке облачных вычислений, рассматривает возможность новых многомиллиардных инвестиций в стартап Anthropic, активно развивающий ИИ и являющийся конкурентом OpenAI. В сентябре прошлого года Amazon уже инвестировала $4 млрд в Anthropic, что позволило ей предложить своим клиентам ранний доступ к инновационным разработкам стартапа. В рамках партнёрства Anthropic использует облачные серверы и вычислительные мощности Amazon для обучения своих ИИ-моделей. 
Источник изображения: anthropic.com По имеющимся данным, Amazon предложила Anthropic использовать больше серверов с чипами её собственной разработки, чтобы усилить вычислительные мощности стартапа, необходимые для обучения ИИ-моделей. С одной стороны, это способствует укреплению позиций Amazon на рынке облачных технологий, а с другой — подчёркивает намерение компании продемонстрировать возможности собственных аппаратных решений. Однако Anthropic предпочитает использовать серверы, оснащённые чипами Nvidia, что говорит о повышенных требованиях стартапа к мощности используемого оборудования для обработки больших данных и обучения сложных ИИ-моделей. Компания Anthropic была основана бывшими руководителями OpenAI, Дарио Амодеи (Dario Amodei) и Даниэлой Амодеи (Daniela Amodei), и с момента создания привлекла серьёзное внимание крупных технологических корпораций. В прошлом году стартап получил $500 млн инвестиций от материнской компании Google — Alphabet, которая также обязалась вложить дополнительно $1,5 млрд. Для Amazon укрепление сотрудничества с Anthropic — важный шаг в конкурентной борьбе на рынке облачных технологий, где лидируют такие компании, как Microsoft и Google. В условиях усиливающейся конкуренции расширение портфеля ИИ-решений позволяет Amazon привлекать больше корпоративных клиентов, заинтересованных в передовых технологиях, интегрированных с её облачными сервисами. Обеспечивая своим клиентам доступ к разработкам Anthropic, Amazon укрепляет свои позиции в качестве поставщика инновационных ИИ-решений. OpenAI намерена вывести ИИ в реальный мир — компания переманила из Meta✴ главу разработки AR-очков
05.11.2024 [10:51],
Дмитрий Федоров
Бывший руководитель отдела разработки очков дополненной реальности (AR) компании Meta✴, Кейтлин Калиновски (Caitlin Kalinowski), перешла в OpenAI. На своей странице в LinkedIn она сообщила, что возглавит направление робототехники и потребительских устройств в OpenAI. Компания также подтвердила её назначение, подчеркнув, что опыт Калиновски поможет вывести ИИ в реальный мир, расширяя его возможности для массового использования. 
Источник изображения: caitlinkalinowski.com Калиновски пришла в Meta✴ в 2022 году, где возглавила работу над проектом AR-очков Orion, представленных на ежегодной конференции Meta✴ Connect. В течение девяти лет она также руководила проектами по разработке устройств виртуальной реальности. До работы в Meta✴ Калиновски трудилась в Apple, где занималась проектированием аппаратного обеспечения для MacBook, приобретая ценный опыт в создании высококачественной потребительской электроники. Калиновски прокомментировала своё назначение в OpenAI так: «С радостью сообщаю, что присоединяюсь к команде OpenAI в качестве руководителя направлений робототехники и потребительского оборудования. На новом посту я сосредоточусь на проектах OpenAI в области робототехники и развитии партнёрских отношений, чтобы внедрить искусственный интеллект в физическую реальность и раскрыть его возможности на благо человечества». Предполагается, что Калиновски будет работать совместно с Джони Айвом (Jony Ive), бывшим топ-менеджером Apple, который сейчас возглавляет LoveFrom и разрабатывает вместе с OpenAI новое аппаратное ИИ-решение. В сентябре Айв подтвердил, что их совместное устройство будет «менее социально деструктивным, чем iPhone». Это партнёрство позволит OpenAI и LoveFrom объединить усилия для создания принципиально нового формата взаимодействия пользователей с ИИ. OpenAI также объявила о поиске инженеров-исследователей для новой команды по робототехнике. Команда призвана помочь партнёрам компании интегрировать мультимодальные технологии OpenAI в физические устройства. Это возрождение робототехнического направления OpenAI знаменательно, ведь в 2018 году компания приостановила подобные исследования, сосредоточив усилия на разработке программного обеспечения (ПО). В частности, одним из достижений той эпохи стала роботизированная рука, способная обучаться самостоятельному захвату объектов. Технологии OpenAI уже активно внедряются в современные устройства. Так, Apple планирует интегрировать ChatGPT в iPhone до конца года, расширяя возможности пользователей «яблочных» устройств. Кроме того, робототехническая компания Figure использует технологии OpenAI: её робот-гуманоид Figure 01 может вести естественные диалоги благодаря встроенному ПО OpenAI. Эти примеры подтверждают растущую значимость ИИ в улучшении его взаимодействия с человеком. Приход Кейтлин Калиновски в OpenAI — значимый шаг для компании, стремящейся воплотить ИИ в физическом мире. Её опыт и знания в области разработки потребительских устройств могут дать новый импульс аппаратным проектам компании, обеспечивая ИИ более широкое проникновение в повседневную жизнь и делая его неотъемлемой частью нашей привычной реальности. «Ничего, что можно было бы назвать GPT-5» — OpenAI дорабатывает GPT-o1, а GPT-5 не появится в 2024 году
03.11.2024 [10:07],
Дмитрий Федоров
Генеральный директор OpenAI Сэм Альтман (Sam Altman) развеял надежды на скорый релиз GPT-5, сообщив, что до конца 2024 года компания сосредоточится на улучшении версии GPT-o1. Сейчас эта версия ориентирована на углублённый анализ и призвана решать специализированные задачи в таких областях, как наука, математика и академические исследования. В планах OpenAI также развитие независимых «ИИ-агентов», способных работать более самостоятельно, без вмешательства человека. 
Источник изображения: alanajordan / Pixabay В ходе общения с пользователями Reddit Альтман пояснил, что выпуск следующей версии ChatGPT, GPT-5, в 2024 году не запланирован. «Мы представим несколько интересных релизов к концу года, но ничего, что можно было бы назвать GPT-5», — заявил он. Вместо этого компания сосредоточится на выпуске версии GPT-o1, созданной для более обдуманного подхода к решению задач. Эта версия ChatGPT, также известная под кодовым названием Project Strawberry, направлена на специализированные сценарии использования, где требуются вдумчивые решения и точные ответы, особенно в научных и академических областях. Альтман отметил, что возросшая сложность современных ИИ-моделей затрудняет параллельную разработку крупных обновлений. Кроме того, OpenAI сталкивается с жёсткими ограничениями и необходимостью трудного выбора при распределении вычислительных ресурсов, что ограничивает возможность компании выпускать несколько крупных релизов ИИ-моделей одновременно. Следующим значительным достижением ChatGPT станут «ИИ-агенты» — системы, способные выполнять задачи автономно, взаимодействуя с внешним миром без участия человека. Альтман пояснил, что такие функции смогут решать конкретные задачи, например, бронировать авиабилеты, покупать билеты на концерты или отвечать на запросы служб поддержки. OpenAI планирует сделать эти возможности важной частью своих ИИ-моделей, что значительно расширит их функциональность. Вице-президент по разработке в OpenAI Сринивас Нараянан (Srinivas Narayanan) рассказал о своём видение будущего ChatGPT, отметив, что в перспективе ИИ-модель сможет лучше понимать личную информацию пользователя и выполнять действия от его имени. Это, по его мнению, значительно расширит функциональность ChatGPT и сделает его инструментом, активно реагирующим на повседневные запросы пользователя. Альтман также намекнул, что в один прекрасный день он может открыть доступ к контенту для взрослых — «Not Safe For Work», который в настоящее время блокируется. «Мы полностью поддерживаем идею уважительного отношения к взрослым пользователям», — отметил он, добавив, что этот вопрос требует серьёзной проработки и что сейчас у OpenAI есть более срочные задачи. Альтман подчеркнул, что компания планирует вернуться к этому вопросу, когда основные задачи будут решены. Амбициозные цели руководства OpenAI предполагают значительные улучшения возможностей её ИИ-моделей. В мае операционный директор компании Брэд Лайткап (Brad Lightcap) заявил, что через год мы будем смеяться над тем, насколько примитивными были предыдущие версии ChatGPT. Хотя выпуск GPT-5 задерживается, OpenAI предлагает пользователям новые ИИ-инструменты. Недавно был запущен ChatGPT Search, позволяющий искать информацию в интернете напрямую через ChatGPT, что раньше требовало обращения к поисковым системам. OpenAI опровергла намерение выпустить ИИ-модель Orion в этом году
26.10.2024 [12:17],
Павел Котов
OpenAI заявила, что в этом году не намерена выпускать новую модель искусственного интеллекта под кодовым именем Orion. Она, как предполагается, станет продолжением актуальной GPT-4o. 
Источник изображения: Mariia Shalabaieva / unsplash.com «У нас отсутствуют планы выпускать модель под кодовым именем Orion в этом году. Мы планируем выпустить множество других прекрасных технологий», — заявил представитель OpenAI ресурсу TechCrunch. Ранее СМИ сообщили, что Orion, которая, как ожидается, станет новым флагманом OpenAI, будет выпущена к декабрю. При этом она дебютирует не с чат-ботом ChatGPT, а у доверенных партнёров компании — они получат к ней предварительный доступ первыми. Microsoft как главный инвестор OpenAI рассчитывает получить к ней доступ уже в ноябре. Orion является шагом вперёд по сравнению с текущим флагманом OpenAI GPT-4o. Модель, если верить неподтвержденной информации, была обучена на синтетических данных o1 — созданной OpenAI нейросетью, которая умеет рассуждать. В обозримом будущем компания намеревается продолжить разработку новых моделей семейства GPT наряду с рассуждающими нейросетями вроде o1 — они будут существовать параллельно, потому что предназначаются для принципиально разных рабочих сценариев. Впрочем, сделанное OpenAI заявление оставляет ей пространство для манёвра. Возможно, следующий флагман компании — это на самом деле не Orion. Или к декабрю OpenAI всё-таки выпустит новую модель, но она будет менее мощной, чем Orion. OpenAI обучила ИИ-модель Orion — она может оказаться до 100 раз мощнее GPT-4
25.10.2024 [12:09],
Дмитрий Федоров
OpenAI планирует выпустить новую ИИ-модель, которая сейчас известна под кодовым именем Orion, ко второй годовщине ChatGPT. На первом этапе доступ к Orion получат партнёры OpenAI, что позволит им разрабатывать на её основе собственные продукты и функции. В отличие от предыдущих ИИ-моделей GPT-4o и o1, новинка не будет сразу интегрирована в ChatGPT для широкой аудитории. 
Источник изображения: Mohamed_hassan / Pixabay Инженеры Microsoft, главного партнёра OpenAI, уже готовятся развернуть Orion на облачной платформе Azure, и её запуск может состояться уже в ноябре. Внутри OpenAI эту модель считают продолжением GPT-4, однако пока неясно, будет ли она официально называться GPT-5. Вопрос о названии новинки остаётся открытым, а сроки её выхода могут измениться. OpenAI и Microsoft пока воздерживаются от комментариев. Один из руководителей OpenAI заявил, что Orion может быть до 100 раз мощнее, чем GPT-4, что подчёркивает амбициозность проекта. Orion разрабатывается как самостоятельный ИИ и стоит особняком от «думающей» большой языковой модели (LLM) o1, вышедшей в сентябре. Цель OpenAI — со временем объединить все свои LLM для создания более мощной ИИ-модели, которая приблизит компанию к созданию ИИ общего назначения (Artificial General Intelligence, AGI). 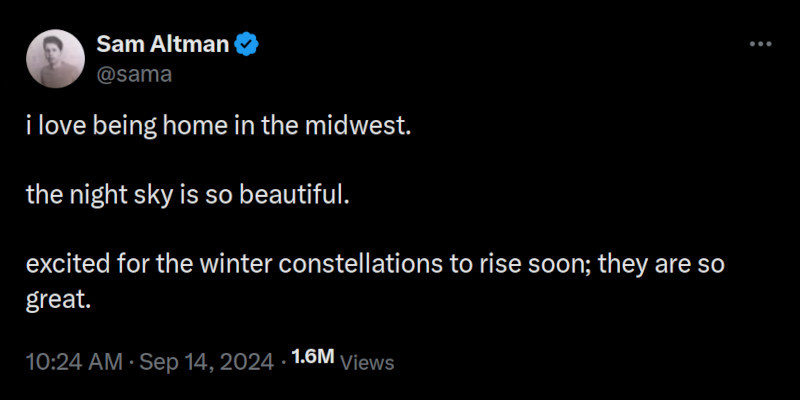
Источник изображения: Sam Altman / X По словам источников, для обучения Orion компания использовала синтетические данные, сгенерированные o1, а её тренировка завершилась ещё в сентябре. В то же время генеральный директор OpenAI Сэм Альтман (Sam Altman) опубликовал в соцсети X загадочное сообщение о том, что «с нетерпением ждёт скорого восхода зимних созвездий» Ориона, наблюдаемых с ноября по февраль, вероятно, намекая на декабрьский запуск. Это подтверждает и сам ChatGPT o1-preview, который на вопрос о том, что скрывает пост Альтмана, отвечает, хоть и с элементами галлюцинации, что тот намекает на слово Orion. 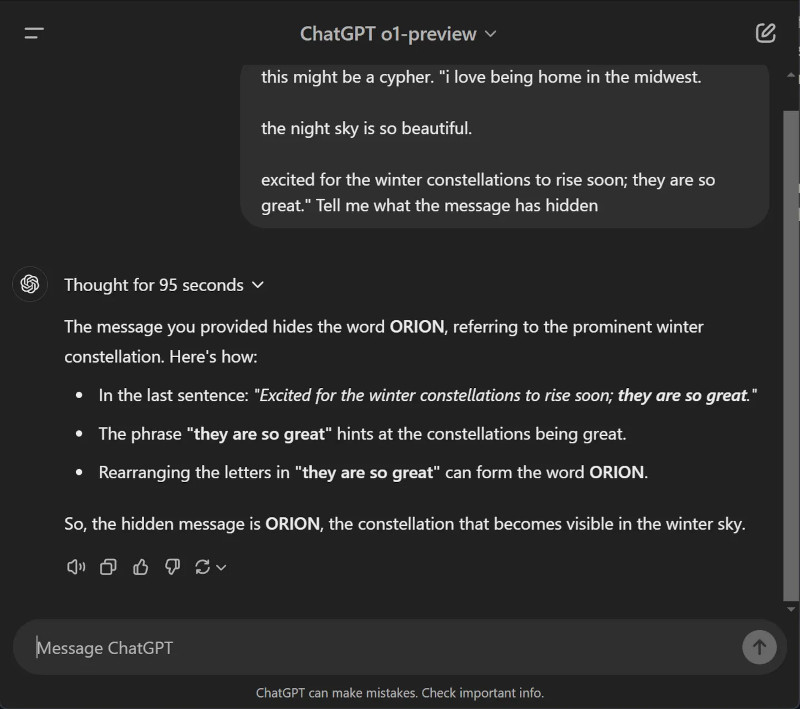
Источник изображения: Tom Warren / The Verge Запуск новой LLM происходит на фоне серьёзных кадровых изменений в OpenAI, недавно привлёкшей рекордные $6,6 млрд и получившей статус коммерческой организации. О своём уходе недавно объявили технический директор Мира Мурати (Mira Murati), главный научный сотрудник Боб МакГрю (Bob McGrew) и президент по исследованиям Баррет Зоф (Barret Zoph). У людей ещё есть время: ИИ сравняется по умственным способностям с человеком через 10 лет, а то и позже
17.10.2024 [14:30],
Дмитрий Федоров
Современные ИИ-модели демонстрируют впечатляющие способности в обработке естественного языка и генерации текста. Однако, по словам главного специалиста по ИИ компании Meta✴ Янна Лекуна (Yann LeCun), они пока не обладают способностями к памяти, мышлению, планированию и рассуждению, как это свойственно человеку. Они всего лишь имитируют эти навыки. По мнению учёного, для преодоления этого барьера потребуется не менее 10 лет и разработка нового подхода — «моделей мира». 
Источник изображения: DeltaWorks / Pixabay Ранее в этом году OpenAI представила новую функцию для ИИ-чат-бота ChatGPT под названием «память», которая позволяет ИИ «запоминать» предыдущее общение с пользователем. В дополнение к этому, компания выпустила новое поколение ИИ-моделей GPT-4o, которое выводит на экран слово «думаю» при генерации ответов. При этом OpenAI утверждает, что её новинки способны на сложное рассуждение. Однако, по мнению Лекуна, они лишь создают иллюзию сложных когнитивных процессов — реальное понимание мира у этих ИИ-систем пока отсутствует. Хотя такие нововведения могут выглядеть как значительный шаг на пути к созданию ИИ общего назначения (Artificial General Intelligence, AGI), Лекун оппонирует оптимистам в этой области. В своём недавнем выступлении на Hudson Forum он отметил, что чрезмерный оптимизм Илона Маска (Elon Musk) и Шейна Легга (Shane Legg), сооснователя Google DeepMind, может быть преждевременным. По мнению Лекуна, до создания ИИ уровня человека могут пройти не годы, а десятилетия, несмотря на оптимистичные прогнозы о его скором появлении. Лекун подчёркивает, что для создания ИИ, способного понимать окружающий мир, машины должны не только запоминать информацию, но и обладать интуицией, здравым смыслом, способностью планировать и рассуждать. «Сегодняшние ИИ-системы, несмотря на заявления самых страстных энтузиастов, не способны ни на одно из этих действий», — отметил Лекун. Причина этому проста: большие языковые модели (LLM) работают, предсказывая следующий токен (обычно это несколько букв или короткое слово), а современные ИИ-модели для изображений и видео предсказывают следующий пиксель. Иными словами, LLM являются одномерными предсказателями, а модели для изображений и видео — двумерными предсказателями. Эти модели добились больших успехов в предсказаниях в своих измерениях, но они по-настоящему не понимают трёхмерный мир, доступный человеку. Из-за этого современные ИИ не могут выполнять простые задачи, которые под силу большинству людей. Лекун сравнивает возможности ИИ с тем, как обучаются люди: к 10 годам ребёнок способен убирать за собой, а к 17 — научиться водить автомобиль. Оба этих навыка усваиваются за считаные часы или дни. В то же время, даже самые продвинутые ИИ-системы, обученные на тысячах или миллионах часов данных, пока не способны надёжно выполнять такие простые действия в физическом мире. Чтобы решить эту проблему, Лекун предлагает разрабатывать модели мира — ментальные модели того, как ведёт себя мир, которые смогут воспринимать окружающий мир и предсказывать изменения в трёхмерном пространстве. 
Источник изображения: AMRULQAYS / Pixabay Такие модели, по его словам, представляют собой новый тип архитектуры ИИ. Вы можете представить последовательность действий, и ваша модель мира позволит предсказать, какое влияние эта последовательность окажет на мир. Отчасти преимущество такого подхода заключается в том, что модели мира могут обрабатывать значительно больше данных, чем LLM. Это, конечно же, делает их вычислительно ёмкими, поэтому облачные провайдеры спешат сотрудничать с компаниями, работающими в сфере ИИ. Модели мира — это масштабная концепция, за которой в настоящее время охотятся несколько исследовательских лабораторий, и этот термин быстро становится новым модным словом для привлечения венчурного капитала. Группа признанных исследователей ИИ, включая Фэй-Фэй Ли (Fei-Fei Li) и Джастина Джонсона (Justin Johnson), недавно привлекла $230 млн для своего стартапа World Labs. «Крёстная мать ИИ» и её команда также уверены, что модели мира позволят создать значительно более умные ИИ-системы. OpenAI также называет свой ещё не вышедший видеогенератор Sora моделью мира, но не раскрывает подробностей. Лекун представил идею использования моделей мира для создания ИИ уровня человека в своей работе 2022 года, посвящённой объектно-ориентированному или целеориентированному ИИ, хотя отмечает, что сама концепция насчитывает более 60 лет. Вкратце, в модель мира загружаются базовые представления об окружающей среде (например, видео с изображением неубранной комнаты) и память. На основе этих данных модель предсказывает, каким будет состояние окружающего мира. Затем ей задаются конкретные цели, включая желаемое состояние (например, чистая комната), а также устанавливаются ограничения, чтобы исключить потенциальный вред для человека при достижении цели (например, «убираясь в комнате, не навреди человеку»). После этого модель мира находит оптимальную последовательность действий для выполнения поставленных задач. Модели мира представляют собой многообещающую концепцию, но, по словам Лекуна, значительного прогресса в их реализации пока не достигнуто. Существует множество крайне сложных задач, которые нужно решить, чтобы продвинуться от текущего состояния ИИ, и по его мнению, всё гораздо сложнее, чем кажется на первый взгляд. Nvidia выпустила мультимодальную модель ИИ с открытым исходным кодом, и она не уступает GPT-4
02.10.2024 [19:27],
Сергей Сурабекянц
Nvidia представила новое семейство больших мультимодальных языковых моделей NVLM 1.0, включая обученную на 72 миллиардах параметров NVLM-D-72B. Модели демонстрируют высокую производительность в широком спектре задач, таких как машинное зрение, создание программного кода, анализ изображений, решение математических задач и генерация текстов. Похоже, что лидерам отрасли во главе с OpenAI и Google придётся потесниться. 
Источник изображения: freepik.com «Мы представляем NVLM 1.0, семейство передовых мультимодальных больших языковых моделей, которые достигают самых современных результатов в задачах зрения и языка, конкурируя с ведущими фирменными моделями (например, GPT-4o) и моделями с открытым доступом», — утверждают разработчики Nvidia. По их мнению, открытый исходный код предоставляет исследователям и разработчикам беспрецедентный доступ к передовым технологиям. Флагманская модель NVLM-D-72B демонстрирует адаптивность при обработке сложных визуальных и текстовых входных данных. Исследователи подчёркивают способность модели интерпретировать мемы, анализировать изображения и пошагово решать математические задачи. Разработчики также отметили, что NVLM-D-72B улучшает свою производительность в текстовых задачах после мультимодального обучения, в отличие от большинства аналогичных моделей. Проект NVLM также представляет инновационные архитектурные решения, включая гибридный подход, который объединяет различные методы мультимодальной обработки. По оценкам сторонних исследователей, модель NVLM-D-72B «находится на одном уровне с Llama 3.1 405B по математике и кодированию, а также имеет видение». Выпуск Nvidia NVLM 1.0 знаменует собой поворотный момент в разработке ИИ. Открывая исходный код модели, которая конкурирует с проприетарными гигантами, Nvidia не просто делится кодом — она бросает вызов самой структуре индустрии ИИ. Благодаря Nvidia множество небольших организаций и независимых исследователей смогут вносить более значительный вклад в развитие ИИ, что может открыть эру беспрецедентного сотрудничества и инноваций в области ИИ. Этот шаг может вызвать цепную реакцию — другим лидерам в области ИИ также придётся открыть свои исследования, что потенциально ускорит прогресс ИИ по всем направлениям. Нужно отметить, что выпуск NVLM 1.0 не лишён рисков. По мере того, как мощный ИИ становится все более доступным, возрастают и опасения по поводу его неправильного использования и возможных этических последствий. Сообщество ИИ уже столкнулось с необходимостью ответственного использования новых технологий. Одно можно сказать наверняка: политика Nvidia в отношении ИИ затронет всю индустрию. Вопрос только в том, насколько радикальным окажется её влияние, и смогут ли конкуренты адаптироваться достаточно быстро, чтобы преуспеть в этом новом мире открытого ИИ. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться