|
Опрос
|
реклама
Быстрый переход
VK собрала видеоконтент всех своих платформ в одном облаке на 1,5 млрд Гбайт
29.08.2024 [13:17],
Павел Котов
VK поместила видеоматериалы своих платформ «VK Видео», «Дзен» и «ОК.Видео» в единое облачное хранилище, говорится в пресс-релизе компании. Суммарный объём ресурса составил 1,5 Эбайт или 1,5 млрд Гбайт — он самый крупный среди всех российских платформ. Источник изображения: ilgmyzin / unsplash.com Выбранный компанией режим one-cloud помогает защитить данные. При выходе отдельных хранилищ из строя данные, которые находятся в дата-центрах VK, восстанавливаются в автоматическом режиме и копируются на новые носители. При этом дублирование контента сведено к минимуму. «Если пользователи повторно загружают одно и то же видео на одну из платформ, то хранилище автоматически удаляет дубли», — рассказал технический директор «ВКонтакте» и «VK Видео» Сергей Ляджин. Потребность в таком механизме собственной разработки возникла из-за замедления доступа к YouTube в России, которое началось в августе. Этим летом на ресурсах VK пиковый объём загружаемого контента доходил до 1 Пбайт в день — материалы включают видео, опубликованные блогерами, прочий пользовательский контент, а также сериалы, мультфильмы и спортивные трансляции. Наконец, размещение всего видео в едином облачном пространстве способствует более эффективной настройке рекомендательных алгоритмов компании, «помогая авторам повышать охваты, а пользователям находить релевантный и интересный контент». Видеотрафик VK вырос на 30 % на фоне замедления YouTube в России
22.08.2024 [21:59],
Анжелла Марина
Видеосервис «VK Видео» продолжает демонстрировать уверенный рост на фоне замедления работы YouTube в России. Как сообщает пресс-служба компании, общий видеотрафик VK с начала года увеличился на 30 %. Особой популярностью пользуются развлекательные шоу в HD-качестве, просмотры которых, по данным компании, «выросли на порядок». 
Источник изображения: geralt/Pixabay Значительный рост также наблюдается в сегментах детского и спортивного контента. Трафик видео с детским контентом увеличился более чем в 4,5 раза, а со спортивным — в пять раз. В VK связывают рост популярности платформы с расширением собственной сети доставки контента (CDN). «Теперь более 150 CDN-узлов с кеш-серверами охватывают всю территорию России и страны СНГ, в том числе Казахстан, Белоруссию, Узбекистан и Таджикистан», — передаёт Forbes. Это позволит получать доступ к контенту с максимальной скоростью. Елена Якупова, заместитель вице-президента VK по инфраструктуре и прикладным сервисам, отметила, что пропускная способность сети VK достигла 40 Тбит/с. «Этого будет достаточно, даже если ежедневная аудитория сервисов VK вырастет одномоментно в два раза», — подчеркнула она. Напомним, рост популярности платформы «VK Видео» происходит на фоне проблем с доступом к YouTube в России. Российские операторы связи, в том числе МТС и «Билайн», в конце июля начали предупреждать о предстоящем ухудшении работы видеохостинга, и уже 8 августа в его работе произошёл масштабный сбой, после которого операторы отметили скачок общего объёма трафика на 5-10 %. Эксперты связывают замедление работы YouTube с действиями Роскомнадзора, который, по их мнению, блокирует видеосервис с помощью технических средств противодействия угрозам (ТСПУ). Глава комитета по информполитике Госдумы Александр Хинштейн ранее отмечал, что «деградация» YouTube является вынужденным шагом, направленным не против российских пользователей, а против администрации иностранного ресурса. Официально российские власти объясняют замедление работы YouTube прекращением поддержки инфраструктуры кеширующих серверов Google в России. VK расширила сеть доставки контента из-за бурного роста «VK Видео» — скорость вырастет на 20–30 %
22.08.2024 [19:06],
Сергей Сурабекянц
С начала 2024 года общий видеотрафик в России вырос на 30 %. CDN-сеть предназначена для ускорения доступа к контенту за счёт размещения в ключевых узлах сети кэширующих серверов. Обновлённая CDN-сеть VK теперь включает более 150 узлов с кэш-серверами, которые охватывают все федеральные округа РФ, а также страны СНГ. Благодаря этому скорость загрузки для посетителей из России, Казахстана, Таджикистана, Узбекистана и Белоруссии возрастает на 20–30 %. 
Источник изображения: Pixabay «Технические улучшения помогут пользователям комфортно взаимодействовать с сайтами VK независимо от их местоположения. Без задержек смотреть видео в высоком разрешении, слушать музыку, общаться, осваивать новые профессии и решать множество других задач», — сообщила заместитель вице-президента компании по инфраструктуре и прикладным сервисам Елена Якупова. За год с момента официального запуска проекта в сентябре прошлого года приложение «VK Видео» было установлено на 11 млн устройств под управлением ОС Android, на 6 млн смарт-телевизоров Android TV и на 3 млн телефонов и планшетов под управлением iOS. Пиковое количество установок — 2 млн — было зафиксировано в июле. За первую неделю августа 2024 года прирост аудитории увеличился в 2,2 раза по сравнению со среднемесячными показателями июля, достигнув пика в 2,5 млн пользователей в сутки. «Пропускная способность стыков с операторами связи выросла вдвое по сравнению с 2023 г. А производительность сети VK до 40 Тбит/с. Этого будет достаточно, даже если ежедневная аудитория сервисов VK вырастет одномоментно в два раза», – добавила Елена Якупова. 6 августа «VK Видео» и RuTube вошли в тройку лидеров по числу установок приложений в России. По данным VK, количество установок «VK Видео» в августе выросло в 4,5 раза относительно среднемесячных значений. Вышло приложение «VK Видео» для iPad
16.08.2024 [12:20],
Павел Котов
В App Store вышла версия приложения «VK Видео», предназначенная для iPad. Владельцы планшетных компьютеров Apple смогут воспользоваться преимуществами адаптивного интерфейса для просмотра видео в вертикальном и горизонтальном режимах. 
Источник изображения: apps.apple.com В приложении «VK Видео» для iPad можно создавать плейлисты, есть функции отложенного просмотра, управления подписками и уведомлениями, можно также выбрать качество видео в зависимости от скорости подключения к интернету. Интерфейс приложения, утверждает разработчик, удобен и интуитивно понятен, благодаря чему зрители смогут быстро и легко находить на платформе интересующие их видео. Пользователи «VK Видео» могут смотреть любое доступное в приложении видео даже без авторизации. Здесь есть фильмы и сериалы, созданные блогерами записи, спортивные трансляции и кулинарные шоу, а также образовательные материалы. Контент в приложении разбит на девять разделов. В секции «Для вас» предлагаются рекомендации на основе того, что зритель смотрел ранее, что он загрузил, отметил как понравившееся или добавил в закладки. В «Трендах» можно ознакомиться с наиболее популярными и обсуждаемыми на платформе видео. Есть раздел «Детям», а также секции «Фильмы», «Сериалы», «Шоу», «Спорт» и «Киберспорт и игры», где можно найти контент на любой вкус. Наконец, есть раздел «Трансляции» со стримами традиционного спорта и киберспорта, концертов, а также эфирами телеканалов. ФАС призвала DNS, «Ситилинк» и «М.видео» добровольно ограничить цены
13.08.2024 [16:09],
Павел Котов
Федеральная антимонопольная служба (ФАС) призвала крупные торговые сети, в том числе DNS, «Ситилинк» и «М.видео» в добровольном порядке ограничить цены и наценки на некоторые товары в категориях электроники и бытовой техники. 
Источник изображения: dns-shop.ru Эта мера, по мнению ведомства, поможет не допустить роста цен на эти товары, сделает их доступнее и положительно повлияет на рынок в целом. «Ведомство также напоминает участникам рынка о важности соблюдения принципов ответственного ценообразования и недопущения необоснованного роста цен», — говорится в заявлении ФАС. В «М.видео» пообещали в ближайшее время подготовить перечень товаров, цены на которые будут зафиксированы с конца августа по конец сентября; в «Ситилинке» инициативу ФАС «концептуально» поддержали и также пообещали подготовить список товаров; в DNS от комментариев отказались, передаёт РБК. После введения очередного пакета европейских санкций в отношении России эксперты рынка выразили мнение, что к осени цены на электронику могут вырасти — усложнятся механизмы международных расчётов и параллельного импорта. С началом украинских событий из России ушли многие иностранные производители, и их продукция стала завозиться в страну через параллельный импорт — в обход официальных поставок. Это коснулось, в частности, компаний Samsung, HP, LG, Bosch и Apple, некоторые из которых прекратили сборку своей продукции в стране. После включения механизмов параллельного импорта диспозиция брендов на российском рынке значительно изменилась. По итогам первой половины 2024 года пятёрку наиболее популярных брендов смартфонов составили Redmi, Tecno, Realme, Infinix и Samsung, тогда как Apple из неё вылетела. В категории ноутбуков MSI уступила лидерство Asus и Huawei. «Яндекс» начал подсказывать пользователям сервисы, где видео грузятся быстрее
12.08.2024 [20:07],
Сергей Сурабекянц
В «Яндекс Поиске» и «Яндекс Браузере» появился детектор медленной загрузки видеороликов. Благодаря новому инструменту пользователи, столкнувшиеся с долгой загрузкой и «зависаниями» видео, получили возможность быстро найти тот же контент на других ресурсах. В случае отсутствия полного аналога сервис предложит выбор из наиболее похожего материала. 
Источник изображений: Яндекс «Когда Поиск по видео индексирует на нескольких площадках одинаковые ролики, он объединяет их в "дубли", а затем показывает как альтернативу контенту с медленной загрузкой», — объяснили в пресс-службе. Система теперь сама определяет видео, загрузка которого превышает типичные показатели, и предлагает пользователю посмотреть его на других площадках. 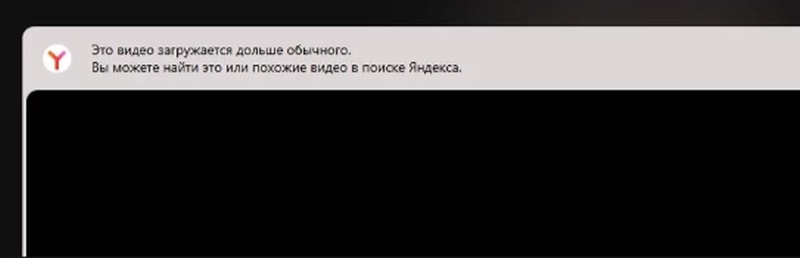 Аналогичным образом работает детектор медленной загрузки роликов в «Яндекс Браузере»: при возникновении задержек с загрузкой видео пользователю будет предложено найти этот же или похожий контент на других ресурсах. Инструмент уже доступен в десктопной версии веб-обозревателя, а в мобильной версии должен появиться в ближайшее время. Приложение «VK Видео» достигло 20 млн установок на фоне проблем с работой YouTube
12.08.2024 [18:41],
Сергей Сурабекянц
Ранее сообщалось, что приложение «VK Видео» стало лидером по скачиванию в российских софтверных маркетах на фоне проблем с работой YouTube. Сегодня пресс-служба социальной сети VK сообщила, что клиентская программа достигла 20 млн установок на мобильных устройствах и смарт-телевизорах с момента официального запуска в сентябре 2023 года. 
Источник изображения: «VK Видео» За год приложение «VK Видео» было установлено на 11 млн устройств под управлением ОС Android, на 6 млн смарт-телевизоров Android TV и на 3 млн телефонов и планшетов под управлением iOS. Пиковое количество установок — 2 млн — было зафиксировано в июле. «За первую неделю августа прирост аудитории standalone-приложения увеличился в 2,2 раза по сравнению со среднемесячными показателями июля, достигнув пика в 2,5 млн пользователей в сутки, включая как мобильные устройства, так и смарт-телевизоры. Суммарное суточное время просмотра в приложении увеличилось в 2,6 раза и превысило 5 млн часов», — сообщил представитель VK. «VK Клипы» впервые обошли по популярности TikTok
09.08.2024 [15:45],
Владимир Мироненко
В июне этого года сервис вертикальных видео «VK Клипы» впервые обошёл по популярности китайский видеосервис TikTok, пишет РБК со ссылкой на статистику единого измерителя интернет-аудитории в России Mediascope. Согласно данным Mediascope, количество человек, хотя бы раз за месяц воспользовавшихся «VK Клипами», в июне 2024 года составило 66,6 млн, тогда как охват TikTok в России в этом месяце равнялся 64,3 млн человек. Для сравнения, охват «VK Клипов» в июне прошлого года составлял 56,8 млн пользователей. 
Источник изображения: vk.com В этом году аудитория «VK Клипов» месяц к месяцу пополняется новыми пользователям. Если в мае 2024 года охват видеосервиса составлял 66,4 млн человек, в апреле — 65,3 млн, то в июне показатель вырос до 66,6 млн. РБК отметил, что число российских пользователей TikTok не отличается стабильностью месяц к месяцу. В этом году его охват колебался в диапазоне от 64,3 млн человек и июне (годовой минимум) до 68,4 млн в марте. В июне прошлого года этот показатель у TikTok был равен 64,6 млн человек. Комментируя итоги «VK Клипов» в июне, в пресс-службе «ВКонтакте», сообщили, что за последний год разработчики сервиса немало сделали для роста популярности: были выпущены новый видеоредактор, пользовательские шаблоны и тематические плейлисты, а также внедрена запись закадрового голоса. В 2024 году разработчики сосредоточились на развитии алгоритмов рекомендаций платформы: «По итогам II квартала 2024 года ежедневные просмотры выросли на 84 % (год к году) — до 1,7 млрд, число опубликованных клипов увеличилось на 56 %, а число создателей контента — на 39 %. Время, проводимое пользователями в “VK Клипах”, выросло почти в 3 раза». Директор по цифровым технологиям NMi Group Анна Планина, комментируя статистику Mediascope, назвала «ВКонтакте» единственной альтернативой не только TikTok, но и западным соцсетям, а также видеохостингу YouTube. Признавая то, что TikTok остаётся самой популярной соцсетью среди подростков, она отметила, что её охваты в целом в России снижаются, в то время как видеосервис соцсети «ВКонтакте» демонстрирует рост. «Мы рассматриваем этот сервис как перспективный формат для рекламодателей с учётом потенциального роста охватов и рекламного инвентаря за счёт перетекания аудитории из заблокированных и ограниченных платформ», — заявила Планина. Рост интереса рекламодателей к «VK Клипам» подтверждает руководитель отдела маркетинга в социальных медиа OMD OM Fuse Анна Козырева. По её словам, за авторами контента пришли и бренды, которые активно используют для продвижения, например, челленджи (задания, которые блогеры выполняют на видео), а также напрямую размещают интеграции своих продуктов у инфлюенсеров. Основатель коммуникационного агентства Didenok Team Кирилл Диденок назвал в числе причин роста «VK Клипов» постепенное улучшение интерфейса самого приложения, в котором стало удобнее публиковать новые видео. YouTube привлёк пользователей к тестированию примечаний сообщества к роликам
08.08.2024 [13:30],
Павел Котов
YouTube начал развёртывать функцию примечаний сообщества для ограниченного контингента пользователей. Пользователи соцсетей начали публиковать скриншоты официального приглашения платформы принять участие в тестировании новой функции. 
Источник изображения: Christian Wiediger / unsplash.com О работе над функцией администрация YouTube рассказала в июне. Она позволяет пользователям платформы отправлять короткие заметки, которые предоставляют дополнительный контекст или корректируют информацию из сопутствующего видео. Официальной даты запуска новой функции ещё нет, но информация о ней уже появилась в справочном разделе платформы. Предварительная версия функции доступна только для англоязычных пользователей мобильной версии в США. Ранее администрация YouTube сообщала, что приглашения принять участие в её тестировании будут отправляться через электронную почту или сообщения от учётной записи Creator Studios. От участников программы компания ждёт отзывов, которые помогут платформе ранжировать примечания как «полезные», «в некоторой степени полезные» и «бесполезные» — вероятно, функция станет общедоступной только после этого. «VK Видео» стало самым скачиваемым приложением в России
06.08.2024 [18:15],
Сергей Сурабекянц
Приложение «VK Видео» стало лидером по скачиванию из магазинов приложений в России на фоне проблем с работой YouTube. Эта информация подтверждена как VK, так и Google Play и App Store. В тройку самых популярных приложений App Store попали также Rutube и TikTok, а Google Play сообщает о резком росте популярности «Дзен» и приложения для просмотра смешных изображений. По данным VK, количество установок «VK Видео» выросло в 4,5 раза относительно среднемесячных значений. 
Источник изображения: «VK Видео» VK запустила приложение «VK Видео» 20 сентября 2023 года. Предполагалось, что оно может стать полноценной альтернативой YouTube. Приложение не только позволяет пользователю смотреть видео и стримы, но и даёт возможность загрузки на платформу собственного контента. Эксперт по информационным технологиям, директор компании «ИТ-Резерв» Павел Мясоедов полагает, что, хотя в основном рост установок «VK Видео» в моменте объясняется замедлением работы YouTube, «российская платформа активно развивается и в борьбе за потребителя наполнение контентом будет происходить быстро». Ранее сообщалось, что среднесуточная аудитория Rutube среди россиян старше 12 лет в июне выросла в 2,1 раза по сравнению с началом лета 2023 года — до 4,4 млн человек. Взрывной рост популярности российских видеосервисов начался после замедления работы YouTube, о котором в конце июля объявил глава комитета Госдумы по информационной политике Александр Хинштейн. Stability AI представила генератор 4D-видео Stable Video 4D
25.07.2024 [01:21],
Владимир Фетисов
На фоне популярности генеративных нейросетей уже доступно множество ИИ-алгоритмов для создания видео, таких как Sora, Haiper и Luma AI. Разработчики из Stability AI представили нечто совершенно новое. Речь идёт о нейросети Stable Video 4D, которая опирается на существующую модель Stable Video Diffusion, позволяющую преобразовывать изображения в видео. Новый инструмент развивает эту концепцию, создавая из получаемых видеоданных несколько роликов с 8 разными перспективами. 
Stable Diffusion 3 «Мы считаем, что Stable Video 4D будет использоваться в кинопроизводстве, играх, AR/VR и других сферах, где присутствует необходимость просмотра динамически движущихся 3D-объектов с произвольных ракурсов», — считает глава подразделения по 3D-исследованиям в Stability AI Варун Джампани (Varun Jampani). Это не первый случай, когда Stability AI выходит за пределы генерации двумерного видео. В марте компания анонсировала алгоритм Stable Video 3D, с помощью которого пользователи могут создавать короткие 3D-ролики на основе изображения или текстового описания. С запуском Stable Video 4D компания делает значительный шаг вперёд. Если понятие 3D или три измерения обычно понимается как тип изображения или видео с глубиной, то 4D, не добавляет ещё одно измерение. На самом деле 4D включает в себя ширину (x), высоту (y), глубину (z) и время (t). Это означает, что Stable Video 4D позволяет смотреть на движущиеся 3D-объекты с разных точек обзора и в разные моменты времени. «Ключевые аспекты, которые позволили создать Stable Video 4D, заключаются в том, что мы объединили сильные стороны наших ранее выпущенных моделей Stable Video Diffusion и Stable Video 3D, а также доработали их с помощью тщательно подобранного набора данных динамически движущихся 3D-объектов», — пояснил Джампани. Он также добавил, что Stable Video 4D является первым в своём роде алгоритмом, в котором одна нейросеть выполняет синтез изображения и генерацию видео. В уже существующих аналогах для решения этих задач используются отдельные нейросети. «Stable Video 4D полностью синтезирует восемь новых видео с нуля, используя для этого входное видео в качестве руководства. Нет никакой явной передачи информации о пикселях с входа на выход, вся эта передача информации осуществляется нейросетью неявно», — добавил Джампани. Он добавил, что на данный момент Stable Video 4D может обрабатывать видео с одним объектом длительностью несколько секунд с простым фоном. В дальнейшем разработчики планируют улучшить алгоритм, чтобы он мог использоваться для обработки более сложных видео. Опубликовано видео 1983 года, в котором Стив Джобс говорит о будущем компьютеров
18.07.2024 [19:57],
Сергей Сурабекянц
Архив Стива Джобса (Steve Jobs) был запущен в 2022 году Лорен Пауэлл Джобс (Laurene Powell Jobs), Тимом Куком (Tim Cook) и Джони Айвом (Jony Ive). Здесь представлена коллекция цитат, фотографий, видео и электронных писем основателя Apple. Сайт также предлагает стипендии и гранты для молодых творцов, желающих пойти по стопам Джобса. Недавно на сайте появилась страница с ранее не публиковавшимся видео речи Джобса в Аспене в 1983 году. 
Источник изображений: stevejobsarchive.com Видео сопровождается комментариями и воспоминаниями Джони Айва, который более 20 лет руководил дизайном в Apple и является автором многих устройств компании. На протяжении практически всей жизни Джони Айв был близким другом Джобса. Ниже мы приводим цитаты из комментариев Айва. «Стив редко посещал конференции по дизайну. Это был 1983 год, до запуска Mac, относительно ранний период существования Apple. Меня поражает, насколько глубоким было его понимание драматических изменений, которые должны были произойти, когда компьютер стал широко доступным. Конечно, он не только был пророческим, но и сыграл важную роль в определении продуктов, которые навсегда изменят нашу культуру и нашу жизнь».  «Накануне выпуска первого по-настоящему персонального компьютера Стив озабочен не только основополагающими технологиями и функциональностью конструкции продукта. Это чрезвычайно необычно, поскольку на ранних стадиях серьёзных инноваций обычно именно основная технология получает выгоду. Описывая то, что он считает неизбежностью, он просит дизайнеров в аудитории думать в первую очередь о дизайне этих продуктов». «Стив отмечает, что усилия по проектированию в США в то время были сосредоточены на автомобилях, при этом мало внимания и усилий уделялось бытовой электронике. Стив прогнозирует, что к 1986 году продажи ПК превысят продажи автомобилей и что в следующие десять лет люди будут проводить больше времени с ПК, чем в автомобиле. Это были абсурдные заявления для начала 1980-х годов».  «Стив остаётся одним из лучших педагогов, которых я когда-либо встречал в своей жизни. У него была способность объяснять невероятно абстрактные и сложные технологии доступным, осязаемым и актуальным языком. Когда я оглядываюсь назад на нашу работу, больше всего мне вспоминаются не продукты, а процесс. Часть гениальности Стива заключалась в том, что он научился поддерживать творческий процесс, поощряя и развивая идеи даже в больших группах людей. К процессу творчества он относился с редким и удивительным почтением».  «Революция, описанная Стивом более 40 лет назад, конечно же, произошла, отчасти из-за его глубокой приверженности своего рода гражданской ответственности. Он заботился, выходя за рамки любого функционального императива. Это была победа красоты, чистоты и, как он сказал, неравнодушия. Он искренне верил, что, делая что-то полезное, расширяющее возможности и красивое, мы выражаем свою любовь к человечеству». YouTube начнёт сбоить у всех в России, предупредил «Ростелеком»
12.07.2024 [12:41],
Владимир Мироненко
«Ростелеком» предупредил российских пользователей о возможных сбоях в работе YouTube в России. В частности, может ухудшиться качество воспроизведения видеороликов, размещённых на платформе, а также снизиться скорость их загрузки на серверы медиаплатформы. 
Источник изображения: Pixabay Как пояснил «Ростелеком», сбои вызваны техническими проблемами в работе оборудования компании Google, установленного в сетевой инфраструктуре оператора и на пиринговых стыках для кеширования и ускорения загрузки контента сервисов Googlе, в основном видеохостинга YouTube (система Google Global Cache). «Из-за проблем с эксплуатацией указанного оборудования и невозможности его расширения в условиях роста обрабатываемого трафика, наблюдается серьёзная перегрузка имеющихся мощностей, в том числе на пиринговых стыках. Это может повлиять на скорость загрузки и качество воспроизведения роликов в YouTube у абонентов всех российских операторов», — указано в сообщении «Ростелекома». Как пишет РБК со ссылкой на данные Mediascope, в апреле 2024 года число российских пользователей, которые хотя бы один раз за месяц посещали видеохостинг или пользовались приложением YouTube, среди населения старше 12 лет составило 95,86 млн человек. Напомним, что в связи с санкциями Google прекратила поставки нового оборудования российским операторам, а старые системы постепенно выходят из строя. На фоне роста трафика это не могло не отразиться на скорости загрузки контента, в первую очередь, на скорости воспроизведения видео на YouTube. Чтобы сохранить качество связи для пользователей, Google предложила провайдерам подключиться к её сетям напрямую. iOS 18 позволит снимать пространственное видео на iPhone с помощью сторонних приложений
19.06.2024 [20:48],
Николай Хижняк
Смартфоны iPhone 15 Pro и iPhone 15 Pro Max, работающие под управлением iOS 17.2 или более свежих версиях ОС, могут записывать пространственное видео для воспроизведения на гарнитуре Apple Vision Pro. В настоящий момент функция поддерживается только фирменным приложением «Камера» от Apple. Начиная с iOS 18 сторонние приложения камеры из App Store тоже смогут предложить поддержку этой функции. 
Источник изображения: Apple В ходе мероприятия WWDC 2024 на прошлой неделе Apple сообщила, что выпустила API, который позволяет разработчикам добавить в свои приложения камер функцию записи пространственного видео. По словам Apple, новый API уже поддерживается существующими программными фреймворками, связанными с камерой, что упрощает его интеграцию. В горизонтальной ориентации основная и сверхширокоугольная камеры iPhone 15 Pro объединяются для записи пространственного видео. Ожидается, что с выходом смартфонов серии iPhone 16 поддержку этой функции получат не только флагманские iPhone 16 Pro и Pro Max, но также модели iPhone 16 и iPhone 16 Plus, поскольку их камеры, согласно слухам, тоже будут расположены вертикально. Для просмотра пространственного видео нужна гарнитура Vision Pro, так как при произведении такого контента на экране iPhone он отображается в обычном двумерном формате. Операционная система iOS 18 проходит стадию бета-тестирования. Полноценный выпуск новой ОС ожидается в сентябре. Пользователи YouTube смогут добавлять примечания к видео
18.06.2024 [11:25],
Павел Котов
На YouTube стартовало тестирование функции, которая позволит пользователям платформы добавлять примечания к видео. К примеру, можно будет пометить видео как пародийное или сообщить зрителям, что оно содержит старые материалы, которые подаются как актуальное событие. 
Источник изображения: Szabo Viktor / unsplash.com Если примечание будет сочтено полезным, оно станет выводиться в небольшом блоке под видео. На текущий момент такие пояснения может добавлять «ограниченное число» членов сообщества YouTube, а сторонние эксперты оценят полезность этих пояснений. В ближайшие недели и месяцы примечания и отзывы о них будут использоваться для обучения собственной системы оценки пояснений на YouTube. 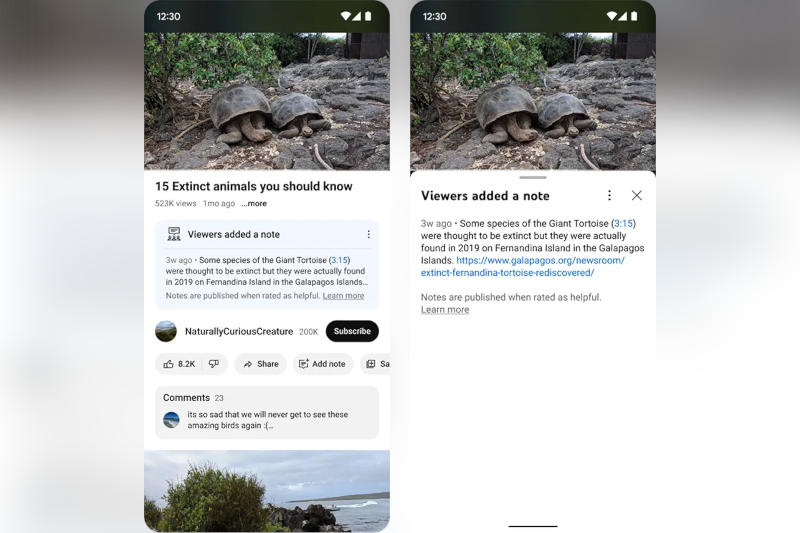
Источник изображения: blog.youtube В перспективе платформа будет спрашивать и зрителей, считают ли они определённое примечание «полезным», «в некоторой степени полезным» или «бесполезным» — и объяснить, почему. Эти ответы также станут транслироваться алгоритму платформы, который научится определять, является ли примечание «полезным в целом». Если некоторое число пользователей, которое ранее оценивало те или иные примечания по-разному, сойдётся во мнениях по поводу одного из них, оно будет с большой степенью вероятности показано всем зрителям. Пока функция примечаний доступна только для англоязычных пользователей мобильной версии YouTube в США. Аналогичные пояснения с прошлого года заработали и в поисковой выдаче Google — эту возможность можно включить в разделе Google Search Labs. В 2021 году схожая функция появилась и в Twitter (теперь X), где она помогает бороться с дезинформацией. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться