|
Опрос
|
реклама
Быстрый переход
Midjourney теперь можно показать персонажа, чтобы он повторял его на генерируемых изображениях
12.03.2024 [17:51],
Павел Котов
Основанный на искусственном интеллекте генератор изображений Midjourney 6, доступный сейчас только в рамках альфа-тестирования на платформе Discord, предложил новую функцию «образец персонажа» (Character Reference), позволяющую зафиксировать один образ на разных созданных платформой изображениях. 
Источник изображения: youtube.com/@curtispyketech Чтобы задать образец, пользователь Midjourney может указать одну или несколько ссылок на картинку с интересующим его персонажем или загрузить его на платформу, и генератор будет учитывать эти данные при получении команды. Администрация сервиса отметила, что новая функция предназначается в первую очередь для персонажей, созданных ИИ. «Для реальных людей/фотографий она не предназначена», — заявил администратор Midjourney Discord и добавил, что это, «скорее всего, исказит их, как это делают обычные запросы на изображения». Но пользователи платформы, конечно, не смогли не попробовать. Один из них загрузил в качестве образца фотографию футбольной звезды Криштиану Роналду (Cristiano Ronaldo), и результаты действительно сильно напоминали известного спортсмена. Функция пока тестируется, но уже демонстрирует убедительные результаты: доступен также параметр «силы» (strength), то есть степени соответствия образца и результата генерации. Новая функция вызывает два противоположных этических вопроса. С одной стороны, возможность задать образец персонажа облегчит недобросовестным пользователям создание убедительных дипфейков. С другой, исключение отсылок на работы художников может вызвать проблемы с авторскими правами, если пользователи захотят коммерциализировать или опубликовать творения Midjourney. Google экстренно чинит генератор изображений в Gemini — он переборщил с расовой инклюзивностью
22.02.2024 [17:34],
Павел Котов
Google сообщила, что на время частично приостановила работу генератора изображений в чат-боте Gemini, когда выяснилось, что она допускает исторические неточности в изображении людей, связанные с расовыми вопросами. Так, при попытке изобразить американских отцов-основателей и солдат нацистской Германии она как будто ниспровергает гендерные и расовые стереотипы, что расценивают как попытку фальсификации истории. 
Такими Gemini представляет себе американских отцов-основателей. Источник изображения: Google Компания приняла решение направить генератор изображений Gemini на доработку менее чем через сутки после поступления первых жалоб. Пользователи чат-бота запрашивали у искусственного интеллекта картинки с историческими группами или лицами и получали на выходе изображения, на которых в основном были представители рас, отличных от европеоидной. Это спровоцировало появление в интернете теорий заговора, что Google намеренно избегает показывать белых людей. 
Сенатор США в 19-м веке по мнению Gemini. Источник изображения: Google К примеру, когда Gemini попросили создать изображение американского сенатора XIX века, ИИ предложил картинки чернокожих женщин и женщин коренных американских наций. В действительности женщина впервые стала сенатором в США лишь в 1922 году, и она была белой. Таким образом, генератор изображений Gemini стирал историю расовой и гендерной дискриминации. Сейчас, когда Gemini просят создать изображение человека или нескольких, тот выводит сообщение следующего содержания: «Мы работаем над улучшением способности генерировать изображения людей. Ожидаем, что эта функция скоро вернётся, и мы сообщим об обновлении выпуска, когда это произойдёт». Генератор изображений появился в чат-боте Gemini (ранее Bard) в начале месяца как ответ на аналогичные продукты OpenAI и Microsoft Copilot — он создаёт картинки по текстовому запросу. Google выпустила передовой ИИ-генератор изображений Imagen 2 — он доступен отдельно и через Bard
02.02.2024 [12:40],
Павел Котов
Google представила передовой генератор изображений Imagen 2, который, как уверяет разработчик, отличается высоким реализмом и избавлен от свойственных системам искусственного интеллекта артефактов. Система доступна как в составе чат-бота Bard, так и в качестве отдельного сервиса ImageFX на платформе бета-тестирования AI Test Kitchen. 
Источник изображения: deepmind.google Google всесторонне улучшила Bard: теперь в основе чат-бота лежит большая языковая модель Gemini Pro — она была представлена ещё в декабре, но до настоящего момента работала лишь у небольшой части пользователей. Теперь Gemini Pro доступна везде, где работает Bard — на всех поддерживаемых языках, во всех странах и на всех территориях. Но чего в Bard пока не было, так это генератора изображений. Раньше компания уступала в этом сегменте как Bing Image Creator, так и Midjourney. Но с выходом Imagen 2 силы, похоже, сравнялись — эта нейросеть теперь работает и в составе чат-бота, и как отдельный сервис ImageFX. Правда, в последнем случае потребуется регистрация в программе AI Test Kitchen — наряду с MusicFX, качество которой Google тоже улучшила. ImageFX позволяет не только генерировать реалистичные изображения по текстовому описанию, но и редактировать их, в том числе изменяя стиль. В компании подчеркнули, что созданные ImageFX изображения маркируются как созданные ИИ посредством метаданных и цифровых водяных знаков SynthID; если эти картинки появятся в поиске Google, то они получат соответствующую пометку и там. Модель Imagen 2 «предлагает изображения самого высокого на сегодня качества, а также улучшения в проблемных областях систем преобразования текста в изображение, таких как прорисовка реалистичных человеческих рук и лиц, избавляя картинки от отвлекающих визуальных артефактов», пояснил вице-президент подразделения Google DeepMind Эли Коллинз (Eli Collins). Разработчик также заверил, что принял защитные меры, которые не позволят платформе генерировать неприемлемый контент. ИИ-художник «Шедеврум» научился перерисовывать фото пользователей в разных стилях
24.01.2024 [19:15],
Владимир Фетисов
Мобильной приложение «Шедеврум» компании «Яндекс» теперь может перерисовывать изображения и фотографии пользователей в разных стилях, для чего задействована нейросеть YandexART. В приложении появились «Фильтрумы» — восемь креативных режимов, которые откроют дополнительные возможности для пользователей «Шедеврума». 
Источник изображений: yandex.ru С помощью «Фильтрумов» можно стилизовать свои изображения и снимки под плюшевые или вязаные игрушки, кадры из мультфильмов, пиксельную графику, нарисованные кистью изображения, а также добавить на них атмосферу зимы, неоновое свечение и красочные цветы. Новая функция работает на основе нейросети YandexART, которая полностью перерисовывает исходное изображение в выбранном стиле, сохраняя при этом сходство с оригиналом. Для взаимодействия с новым инструментом необходимо выбрать один из предлагаемых стилей, после чего остается лишь загрузить из памяти устройства исходное изображение. Обработанные нейросетью изображения можно публиковать в ленте «Шедеврума», а также скачивать, отправлять друзьям, делиться в чатах и др.  Также анонсировано скорое появление в «Шедевруме» новых креативных режимов и функции создания собственных режимов обработки изображений посредством текстовых запросов. Сгенерированными таким образом изображениями можно будет делиться как в самом приложении, так и в соцсетях и мессенджерах. Первый специальный режим называется «Ёлочная игрушка», он появился в приложении в конце прошлого года. С помощью этого режима пользователи сервиса сгенерировали более 4,5 млн новогодних украшений. Запущен обновлённый ИИ-художник Midjourney V6 — он научился писать
22.12.2023 [10:35],
Павел Котов
Состоялся выход альфа-версии Midjourney V6 — ИИ-генератора изображений. Среди наиболее примечательных нововведений разработчики отмечают более реалистичные и детализированные картинки, а также способность модели генерировать разборчивый текст внутри изображений. 
Источник изображения: twitter.com/OrctonAI Midjourney V6 на самом деле является «третьей моделью, обученной с нуля на наших суперкластерах ИИ», и на её разработку ушли девять месяцев, пояснил глава компании Дэвид Хольц (David Holz). Подключение к обновлённой нейросети не происходит для всех пользователей по умолчанию — в чате Discord с ботом Midjourney необходимо перейти в режим настроек командой «/settings», после чего в раскрывающемся меню сверху выбрать «V6». В качестве альтернативы можно после каждого описания изображения добавлять параметр «-v 6». 
Источник изображения: twitter.com/Boris_Jov Господин Хольц обратил внимание на следующие нововведения: «гораздо более точное следование описаниям и более длинные описания; улучшенная согласованность и знания модели; улучшены механизмы подсказок и правок; некоторые возможности рисования текста — он указывается в кавычках, помочь могут параметры „--style raw” и низкие значения „--stylize”; улучшены средства масштабирования с „точным” и „творческим” режимами». 
Источник изображения: twitter.com/giffboake Механизм создания описаний изображений в Midjourney полностью переработан: параметры вроде «фотореализм» или «4K» больше не работают, и пользователям придётся переучиваться. Разработчики советуют быть более откровенными в том, чего хотят пользователи. Так, если требуется фотореалистичное изображение, рекомендуется использовать параметр «--style raw». Следует также выбрать нужный баланс параметра «--stylize», значение которого по умолчанию равно «100». Чем меньше значение, тем буквальнее модель воспринимает команду, а с его увеличением растёт эстетический аспект изображения. 
Источник изображения: chrisperna / Instagram✴ Глава Midjourney подчеркнул, что V6 выпущена в рамках альфа-тестирования — её работа может со временем кардинально меняться, и зачастую без предварительного уведомления аудитории. С полноценным выходом модели, выразили надежду разработчики, «вы все почувствуете развитие чего-то более значительного, что глубоко переплетается с силой нашего коллективного воображения». Но пока в Midjourney V6 отсутствуют некоторые функции, которые есть в V5.2, в том числе панорамирование влево и вправо, а также уменьшение масштаба, но в последующих обновлениях они добавятся. Snapchat теперь позволяет дорисовывать фото с помощью ИИ, но только платным пользователям
13.12.2023 [10:50],
Павел Котов
Функции генеративного искусственного интеллекта появились в мессенджере Snapchat достаточно давно: пакет приложений My AI включает в себя чат-бот на базе ChatGPT, доступны ИИ-эффекты Dreams для селфи и многое другое. В последнем обновлении пользователи платной подписки Snapchat+ получили возможность дорисовывать фото при помощи ИИ. 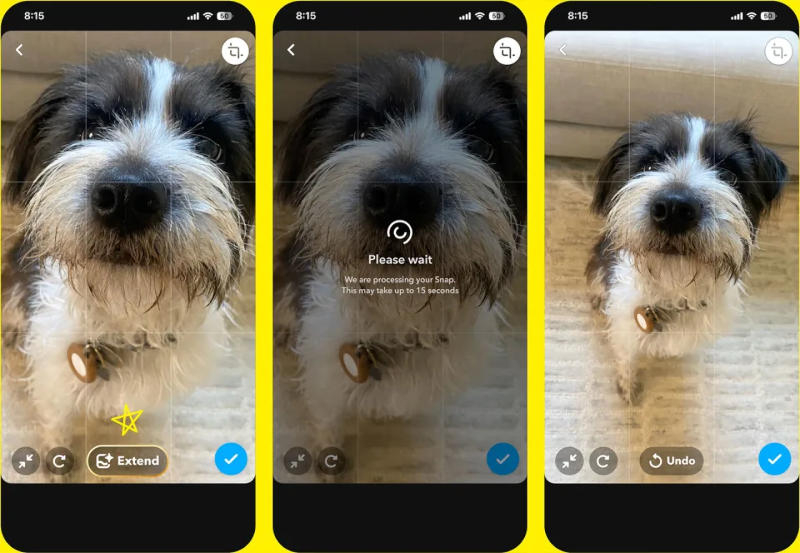
Источник изображения: snap.com Дорисовка фотографий или «уменьшение масштаба» пригодится, если объект на снимке оказался слишком крупным — достаточно нажать кнопку обрезки в правом верхнем углу кадра, выбрать кнопку «Расширить» (Extend), и дальше приложение сделает всё самостоятельно. Обновлённый пакет My AI позволяет и просто генерировать изображения по текстовому описанию, Snapchat даже готов предложить свои варианты таких описаний. Функция Dreams теперь помогает делать совместные фото с друзьями, не делая снимков в реальности — достаточно выбрать имя друга из списка контактов, и «снимок» можно опубликовать. Подписчикам Snapchat+ доступен пакет из восьми таких селфи Dreams, а пользователям бесплатной версии платформы предлагается воспользоваться этой функцией лишь один раз в тестовом режиме, после чего будет предложено либо оформить подписку, либо приобрести пакет за $0,99. Внедрение функций ИИ в Snapchat приносит свои плоды: к сентябрю платную подписку оформили 5 млн человек, к настоящему моменту их число увеличилось до 7 млн, а «среднесрочная цель» Snapchat+ установлена на отметке в 10 млн. И это непростая задача, ведь сервисы Meta✴ предлагают аналогичные возможности бесплатно. Представлен ИИ-генератор изображений Imagine with Meta✴
07.12.2023 [13:11],
Павел Котов
Вслед за DALL-E, Midjourney и Stable Diffusion собственный отдельный генератор изображений представила компания Meta✴. В основу платформы, которая создаёт картинки по текстовым командам, легла обученная работе с графикой модель искусственного интеллекта Emu. Генератор получил название Imagine with Meta✴ — он предлагает четыре картинки по одному запросу, но пока доступен только в США. 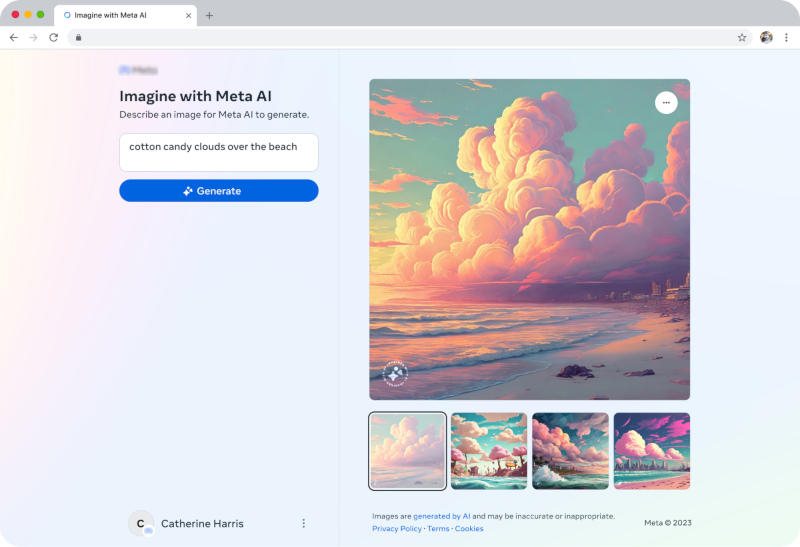
Источник изображений: Meta✴ «Нам было приятно получать от людей отзывы о том, как они пользуются Imagine — функцией генерации изображений по тексту Meta✴ AI для создания забавного и креативного контента в чатах. Сегодня мы расширяем доступ к Imagine за пределы чатов. Наша платформа обмена сообщениями предназначена для озорной двусторонней переписки, а теперь можно бесплатно генерировать изображения и в веб-интерфейсе», — рассказали в блоге компании. Пока созданные Imagine with Meta✴ картинки маркируются видимым водяным знаком, но в перспективе разработчик пообещал заменить его на невидимый — его будет генерировать ИИ, и обнаруживать его сможет тоже соответствующая модель. Такой водяной знак будет устойчив к традиционным манипуляциям с изображениями: к обрезке, изменению размера и цвета, снятию снимков экрана, сжатию, наложению шума, стикеров и многому другому, уточнили в Meta✴. В перспективе компания планирует внедрять такую маркировку во многие свои продукты с изображениями, созданными ИИ. Пока служба Imagine with Meta✴ доступна только для пользователей из США. Ранее Meta✴ предложила пользователям Instagram✴ и Facebook✴ ИИ-генератор стикеров, но пользователи соцсетей начали использовать его для создания непристойностей — фильтры сервиса оказались недостаточно надёжными. Amazon представила свой ИИ-генератор изображений Titan Image Generator
30.11.2023 [06:10],
Николай Хижняк
На конференции AWS re:Invent компания Amazon представила собственный ИИ-генератор изображений Titan Image Generator на платформе Bedrock. Он предназначен для создания изображений на основе текстовых запросов, а также предлагает поддержку различных дополнительных функций редактирования уже готовых изображений. 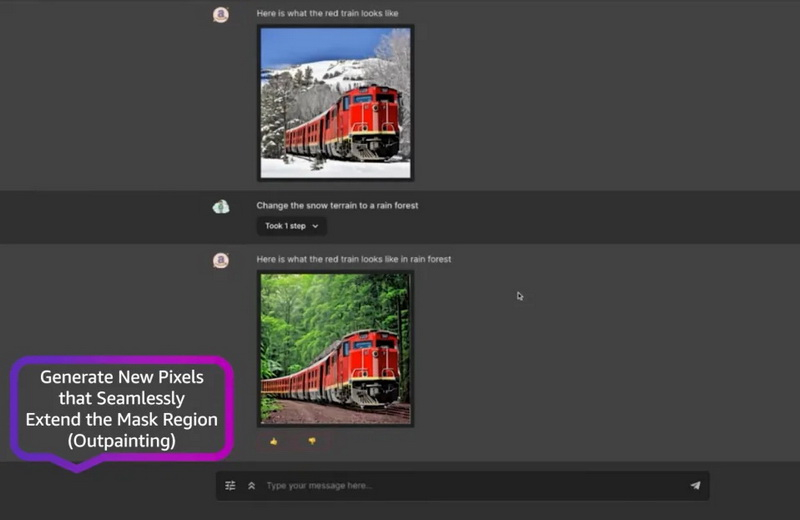
Источник изображения: Amazon По словам Amazon, инструмент способен генерировать «огромные объёмы реалистичных изображения студийного качества при низкой цене». Компания заявляет, что Titan Image Generator способен создавать изображения на основе сложных текстовых подсказок, одновременно обеспечивая при этом точность композиции генерируемых объектов на изображении с минимальными искажениями. По мнению разработчиков Amazon, это поможет «сократить объёмы создания вредного контента и смягчить распространение дезинформации». Функции Titan Image Generator также позволяют редактировать отдельные элементы на изображении, удаляя или добавляя дополнительные детали. Например, инструмент позволяет заменить задний фон на изображении, а также заменить или удалить предмет, который может находиться в руках человека, изображенного в кадре. Использующиеся в составе Titan Image Generator ИИ-алгоритмы также могут расширять композицию изображения, добавляя дополнительные искусственные детали, аналогично функции Generative Expand в Photoshop. В компании отмечают, что их ИИ-генератор изображений Titan накладывает на каждое созданное им изображение невидимый невооружённому глазу специальный водяной знак. По мнению компании, эта функция поможет «уменьшить распространение дезинформации, предоставив незаметный механизм для идентификации изображений, созданных ИИ, а также будет способствовать безопасному, надежному и прозрачному развитию технологий искусственного интеллекта». Amazon заявляет, что эти водяные знаки невозможно удалить или изменить. Согласно опубликованному видео с демонстрацией работы Titan Image Generator, инструмент также может создавать описания изображений или релевантный текст для последующего использования в публикации в социальных сетях. Paint в Windows 11 обзавёлся ИИ-генератором изображений на базе DALL-E 3
28.11.2023 [19:40],
Владимир Фетисов
Microsoft представила долгожданную интеграцию генеративной нейросети DALL-E 3 с графическим редактором Paint в Windows 11. Благодаря этому пользователи программной платформы теперь смогут задействовать ИИ-генератор для создания изображений в Paint через функцию под названием Cocreator. 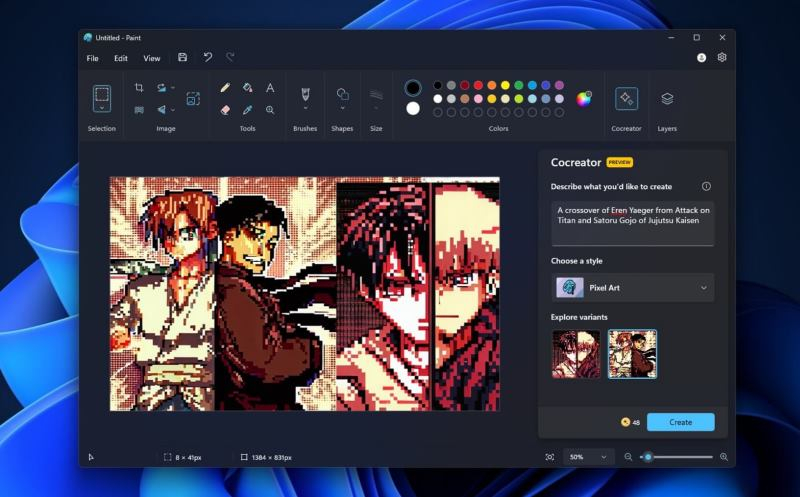
Источник изображений: windowslatest.com В сентябре этого года упомянутое нововведение стало доступно участникам программы предварительной оценки на каналах Dev и Canary. Ранее в этом месяце возможность использования генеративной нейросети появилась на канале Release Preview, а теперь она становится доступна всем пользователям Windows 11. 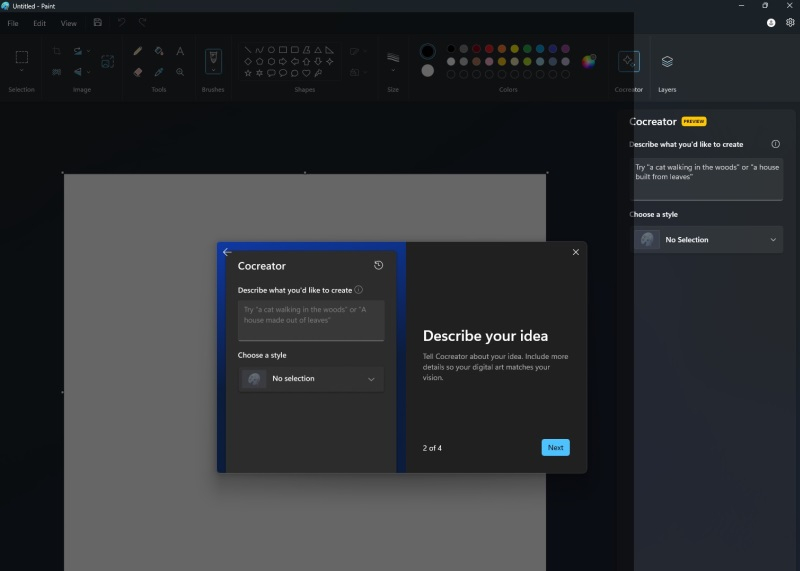 Для генерации изображений достаточно открыть чистый лист Paint, выбрать функцию Cocreator в правой части панели инструментов и ввести текстовое описание изображения, которое алгоритм должен создать. Пользователи, которые только начинают знакомство с инструментами на базе нейросетей, могут ознакомиться с четырёхэтапным руководством прямо в приложении. С его помощью можно узнать порядок работы с алгоритмом и быстро приступить к генерации изображений. 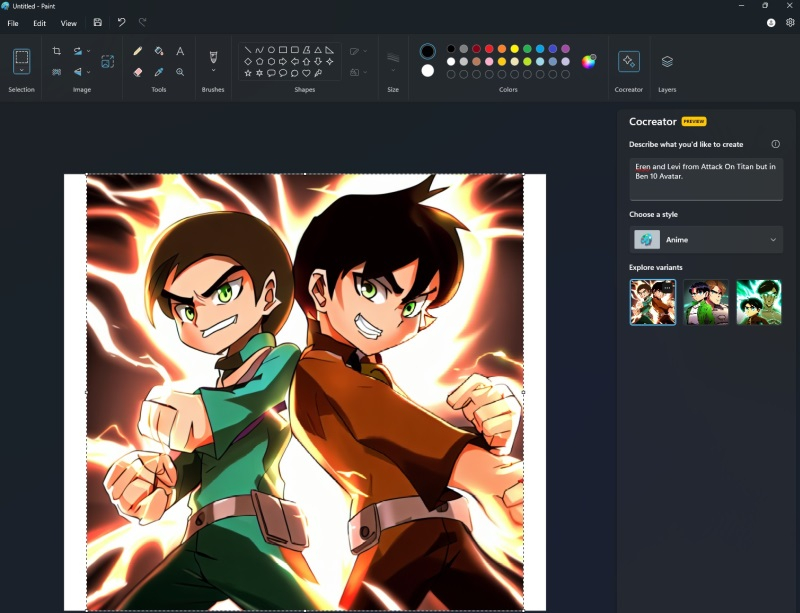 Отмечается, что на данном этапе некоторые пользователи Windows 11 могут получить доступ к новой функции только через регистрацию в списке ожидания, поэтому до получения одобрения от вендора может пройти несколько дней. Пользователям, которые не видят кнопку Cocreator, рекомендуется убедиться в том, что они используют наиболее актуальную версию Paint, а также зарегистрироваться в списке ожидания. «Сбер» запретил ИИ-художнику Kandinsky генерировать изображения с государственной символикой
09.11.2023 [16:51],
Владимир Фетисов
«Сбер» скорректировал работу нейросети Kandinsky 2.1 после вызова сотрудников компании в прокуратуру из-за генерации изображения на флаге России. Об этом сообщил председатель правления Сбербанка Герман Греф на пленарной сессии форума Finopolis 2023. 
Источник изображений: sberbank.com Греф рассказал, что вскоре после запуска ИИ-алгоритма сотрудников «Сбера» вызвали в прокуратуру. Поводом для этого стало обращение депутатов Госдумы после того, как нейросеть нарисовала на государственном флаге России купола собора Василия Блаженного. «Депутаты посчитали, что это издевательство над нашими национальными флагами. Соответственно, мы тут же остановились. Определённые вещи — символы государственные и прочее — она не генерирует уже», — сообщил Герман Греф. Теперь алгоритм Kandinsky 2.1 по запросу пользователя выдаёт заранее заданное изображение без добавления к нему каких-либо иных элементов на его основе. «Но при этом она теряет в генерации», — отметил топ-менеджер Сбербанка, добавив, что в течение полугода «Сбер» корректировал настройки нейросети, из-за чего доступная широкому кругу пользователей версия алгоритма «потеряла 12 % в креативности и точности». Господин Греф также сказал, что при развитии технологий на основе искусственного интеллекта компаниям требуются, прежде всего, «снисхождение и понимание» со стороны органов власти. Что касается разбирательства в прокуратуре, то оно закончилось без последствий для банка. «Хорошо, что прокурор современный попался, с чувством юмора: он всё изучил, слава богу, нас никуда не привлекли», — резюмировал Греф. Суд отклонил большинство исков художниц против ИИ-генераторов изображений
01.11.2023 [11:18],
Павел Котов
Окружной судья в Калифорнии Уильям Оррик (William Orrick) отклонил иск, поданный тремя художницами против трёх платформ — ИИ-генераторов изображений Stability AI, DeviantArt и Midjourney. По версии истцов, администрации платформ нарушили их авторские права, использовав авторские произведения для обучения систем искусственного интеллекта. 
Источник изображения: succo / pixabay.com Судья вынес решение, что иск Сары Андерсен (Sarah Andersen), Келли МакКернан (Kelly McKernan) и Карлы Ортиз (Karla Ortiz) о нарушении авторских прав платформами DeviantArt и Midjourney является «неполноценным во многих отношениях» и не может быть обоснован. Но он допустил до рассмотрения жалобу о прямом нарушении прав Stability AI. Художницы утверждают, что компания Stability AI использовала принадлежащие им произведения, защищённые авторским правом, для обучения преобразующей текст в изображения системы ИИ, не получив согласия авторов. По словам судьи Оррика, двое художниц-истцов, МакКернан и Ортиз, не зарегистрировали авторских прав ни на одно из своих произведений, а значит, у них не было достаточных оснований для предъявления претензий. Чтобы продолжить рассмотрение дела, он попросил их доказать, что создаваемые генераторами произведения по существу похожи на их собственные работы. Части иска против DeviantArt и Midjourney были отклонены, поскольку эти платформы не связаны с компанией Stability AI, которая стала основным объектом обвинений. «Истцы надлежащим образом заявили о прямом нарушении авторских прав, основываясь на утверждениях, что Stability „загрузила или иным образом получила копии миллиардов защищённых авторским правом изображений без разрешения для создания Stable Diffusion”, использовала эти изображения для обучения Stable Diffusion и содействовала хранению этих изображений и включению их в Stable Diffusion в виде сжатых копий», — заявил судья Оррик. В своём решении он добавил, что даст истцам возможность внести изменения в своё заявление. OpenAI открыла доступ к генератору изображений DALL-E 3 для подписчиков ChatGPT Plus и Enterprise
20.10.2023 [04:35],
Владимир Фетисов
OpenAI расширяет доступность своего новейшего генератора изображений по текстовому описанию DALL-E 3. Компания объявила, что на этой неделе ИИ-алгоритм станет доступен подписчикам ChatGPT Plus и ChatGPT Enterprise. Разработчики заявили, что для этой модели был подготовлен пакет мер по повышению уровня безопасности, что указывает на её готовность к расширенному запуску. 
Источник изображения: OpenAI Модель DALL-E 3 была анонсирована в прошлом месяце, и разработчики показали, насколько она лучше справляется с генерацией картинок по сравнению с предыдущей версией алгоритма DALL-E 2. Пользователи могли убедиться в этом, составляя в ChatGPT более длинные и детальные описания изображений, которые должен создать генератор. Ранее в этом месяце модель DALL-E 3 была интегрирована в службы Bing Chat и Bing Image Creator. Разработчики признают, что предыдущие версии генератора вызывали опасения, поскольку могли использоваться для создания фейковых изображений с целью распространения дезинформации или ведения другой неправомерной деятельности. В DALL-E 3 реализованы инструменты для ограничения генерации картинок определённых тематик. К примеру, алгоритм будет отклонять запросы, содержащие имена общественных деятелей или какие-либо «вредные побуждения». Разработчики ввели ограничения, которые не позволят DALL-E создавать изображения в стиле живущих ныне художников. OpenAI также заявила о наличии классификатора изображений, который позволяет с точностью до 99 % определить, была ли та или иная картинка сгенерирована с помощью DALL-E. В Android 14 появился ИИ-генератор обоев
04.10.2023 [20:10],
Владимир Фетисов
Сегодня состоялась презентация смартфонов Pixel 8 и Pixel 8 Pro, а также других аппаратных и программных новинок компании Google. Вместе с этим состоялся релиз мобильной операционной системы Android 14, которая имеет немало новых функций, включая генератор обоев на базе нейросети. 
Источник изображения: Google Впервые эта функция была анонсирована в рамках мероприятия Google I/O в мае этого года. Взаимодействие с генератором обоев начинается с выбора категории, например, классического искусства, после чего нужно задать требуемые параметры и алгоритм представит несколько вариантов изображений на их основе. В одном из примеров Google выбирается категория Dreamscape, после чего отмечаются варианты структуры, материала и цвета. В конечном итоге формируется запрос «Дом из растений цвета индиго», после обработки которого алгоритм выдаёт несколько изображений покрытых растениями построек с входной дверью и фиолетовым оттенком. Первыми функцию генерации обоев смогут испытать в деле обладатели смартфонов Pixel 8 и Pixel 8 Pro. Когда она может появиться на других смартфонах с Android 14, не уточняется. Однако формулировка Google предполагает, что в конечном счёте это всё же произойдёт. ИИ-генератор обоев — это лишь одна из многих новых функций Android 14. Программная платформа предоставит широкие возможности в плане настройки пользовательского интерфейса, включая экран блокировки, возможность выбора разных шрифтов и цветов, ситуативные виджеты и др. Хотя Android в целом опережает iOS в плане возможностей визуальной настройки, пользователям не всегда легко привести интерфейс к желаемому виду. С выходом Android 14 сделать это будет проще. Представлен ИИ-генератор изображений DALL-E 3 — он лучше понимает людей и скоро будет встроен в ChatGPT
21.09.2023 [01:08],
Николай Хижняк
Компания OpenAI представила новую версию генератора изображений DALL-E и заявила о планах интегрировать его в ChatGPT. Разработчики сообщают, что DALL-E 3 может «значительно лучше понимать запросы», анализировать сложные инструкции и генерировать «чрезвычайно детальные и точные изображения» по сравнению с DALL-E 2. 
Источник изображений: OpenAI / DALL-E 3 «Современные генераторы изображений имеют тенденцию игнорировать слова или описания, вынуждая пользователей изучать промпт-инженерию. DALL-E 3 представляет собой шаг вперёд в нашей способности создавать изображения, которые точно соответствуют предоставленному вами запросу», — сообщает OpenAI в описании нового генератора изображений. Модель лучше справляется и с такими сложными для искусственного интеллекта мелкими деталями, как человеческие руки. Даже при одинаковых запросах результаты DALL-E 3 намного лучше, чем у DALL-E 2, отмечают разработчики. DALL-E 3 сможет точно отобразить сцену с конкретными объектами и учесть, как они друг с другом связаны, как показано на изображении ниже.  OpenAI планирует в ближайшем будущем встроить DALL-E 3 в чат-бот ChatGPT Plus и Enterprise. Комбинация языковых навыков чат-бота с генератором изображений позволит создавать ещё более точные изображения и предоставит ещё больше возможностей в тонкой настройке запроса, если первый полученный результат окажется не тем, чего ожидал пользователь. «При запросе ChatGPT автоматически сгенерирует индивидуальные подробные подсказки для DALL-E 3, на основе которых тот создаст изображение. Если полученное изображение понравится пользователю, но оно не совсем точно будет отображать запрос, то в него можно будет внести изменения, добавив всего несколько дополнительных уточняющих слов», — говорят в OpenAI Сейчас DALL-E 3 находится на стадии исследовательской предварительной версии и станет доступен подписчикам ChatGPT Plus и Enterprise в октябре через API. Следует напомнить, что использование DALL-E 2 платное, а месячная подписка на тот же ChatGPT Plus стоит $20. В настоящий момент единственным крупным ИИ-чат-ботом, предлагающим бесплатный встроенный генератор изображений, является Bing Chat AI от Microsoft. Он, к слову, работает на базе мощной языковой модели GPT-4 от OpenAI. «Как и в случае с DALL-E 2, сгенерированные с помощью DALL-E 3 изображения будут принадлежать пользователю, и ему не потребуется разрешение на их перепечатку, продажу или распространение», — уточняют в OpenAI.  В компании также отметили, что в DALL-E 3 предусмотрены инструменты, ограничивающие создание определённых изображений. Например, генератор изображений будет отклонять запросы с именами общественных деятелей или «вредными предубеждениями», чтобы снизить риск распространения пропаганды и дезинформации. Разработчики также тестируют классификатор происхождения — инструмент, который позволит определить, было ли изображение сгенерировано нейросетью. Наконец, DALL-E не будет генерировать картинки в стиле ныне живущих и творящих художников. Meta✴ анонсировала производительный ИИ-генератор изображений CM3Leon с поддержкой точных команд редактирования
15.07.2023 [16:32],
Павел Котов
За минувшие два года основанные на алгоритмах искусственного интеллекта генераторы изображений стали почти повседневным явлением, и на первый взгляд в работе они не так сильно отличаются друг от друга. Но в Meta✴ утверждают, что разработанная инженерами компании новая модель CM3Leon является прорывом. 
Источник изображений: Meta✴ Отличием модели Meta✴ CM3Leon, как заявляют разработчики, является высокая производительность при преобразовании текста в изображение. Кроме того, это одна из первых моделей, обеспечивающих обратную операцию — создание подписей к изображениям. Большинство современных генераторов изображений, включая OpenAI DALL-E, Google Imagen и Stable Diffusion при создании картинок используют диффузию — процесс постепенного удаления шума из первоначального изображения по мере приближения к поставленной цели. Результат получается убедительным, но данный алгоритм требует значительных вычислительных ресурсов, что делает работу таких систем дорогостоящей, а сами модели — медленными, и в реальном времени они функционировать попросту не могут. 
Редактирование исходного изображения: заменить девушку на бородатого мужчину, добавить очки, увеличить возраст, раскрасить лицо Модель CM3Leon действует принципиально иначе — в её основе лежит алгоритм-трансформер, предусматривающий оценку релевантности исходных данных, будь то текст или изображение. Примечательно, что и в OpenAI первоначально строили генераторы изображений на основе моделей-трансформеров, но на смену Image GPT пришли диффузионные алгоритмы. При обучении CM3Leon использовались 2 млн изображений, лицензированных у Shutterstock — самая мощная версия модели имеет 7 млрд параметров — в два раза больше, чем у OpenAI DALL-E 2. Наконец, здесь использован механизм дообучения SFT (Supervised Fine-Tuning), обычно свойственный генераторам текста. В результате увеличилась производительность модели при генерации изображений и составлении описаний к готовым картинкам, а система получила возможность редактировать изображения по текстовым командам, например, «изменить цвет неба на ярко-синий». 
Генерация интерьера с объектами, для которых указываются точные координаты В результате Meta✴ CM3Leon воспринимает в качестве исходных данных весьма конкретные команды — вплоть до того, в какой области изображения в пикселях должен находиться тот или иной предмет. Для сравнения, DALL-E такие нюансы игнорирует и зачастую даже отказывается помещать на изображение объекты, непосредственно указанные в инструкции. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться