|
Опрос
|
реклама
Быстрый переход
Завирусившийся новый генератор изображений в ChatGPT стал доступен всем пользователям
01.04.2025 [11:24],
Владимир Фетисов
Новый генератор изображений OpenAI, работающий на базе большой языковой модели GPT-4o, теперь доступен всем пользователям. Об этом на своей странице в социальной сети X написал гендиректор OpenAI Сэм Альтман (Sam Altman). До этого момента использовать новый ИИ-генератор изображений могли только платные подписчики ChatGPT. 
Источник изображения: OpenAI Бесплатные пользователи сервиса сейчас могут генерировать не больше двух изображений в сутки. Ранее Альтман упоминал о возможности введения лимита в три изображения в день. Инструмент генерации изображений OpenAI мгновенно стал сверхпопулярным сразу после его запуска в массы. Альтман заявлял, что спрос на генерацию картинок был так высок, что используемые компанией графические ускорители попросту «плавились». Генератор быстро стал известен тем, что его использовали для преобразования изображений в стиль японской анимационной студии Studio Ghibli. Это вызвало обеспокоенность по поводу нарушения авторских прав, поскольку создаваемые ИИ-генератором изображения были очень похожи на работы студии. Некоторые люди также использовали данный инструмент для создания поддельных квитанций, например, ресторанных счетов. В компании на это заявили, что все сгенерированные ИИ изображения содержат метаданные, указывающие на их происхождение. Вместе с этим OpenAI заявила о привлечении $40 млрд инвестиций, за счёт чего рыночная стоимость компании составила $300 млрд. В качестве основного инвестора в рамках этого раунда финансирования выступил Softbank. Компания также объявила, что ИИ-бот ChatGPT еженедельно используют более 500 млн человек по всему миру, тогда как количество ежемесячно активных пользователей выросло до 700 млн человек. Microsoft накрыла банду хакеров, которая обманом заставляла ИИ рисовать неподобающие фейки со знаменитостями
28.02.2025 [10:36],
Владимир Фетисов
Microsoft заявила об обнаружении американских и зарубежных хакеров, которые обходили ограничения генеративных инструментов на базе искусственного интеллекта, включая службы OpenAI в облаке Azure, для создания вредоносного контента, в том числе интимных изображений знаменитостей и другого контента сексуального характера. По данным компании, в этой деятельности участвовали хакеры из США, Ирана, Великобритании, Гонконга и Вьетнама. 
Источник изображения: Mika Baumeister / Unsplash В сообщении сказано, что злоумышленники извлекали логины пользователей сервисов генеративного ИИ из открытых источников и использовали их для собственных целей. После получения доступа к ИИ-сервису хакеры обходили установленные разработчиками ограничения и продавали доступ к ИИ-сервисам вместе с инструкциями по созданию вредоносного контента. Microsoft предполагает, что все идентифицированные хакеры являются членами глобальной киберпреступной сети, которую в компании именуют Storm-2139. Двое из них территориально находятся во Флориде и Иллинойсе, но компания не раскрывает личностей, чтобы не навредить уголовному расследованию. Софтверный гигант заявил, что ведёт подготовку соответствующих запросов в правоохранительные органы США и ряда других стран. Эти меры Microsoft принимает на фоне растущей популярности генеративных нейросетей и опасения людей по поводу того, что ИИ может использоваться для создания фейковых изображений общественных деятелей и простых граждан. Такие компании, как Microsoft и OpenAI, запрещают генерацию подобного контента и соответствующим образом ограничивают свои ИИ-сервисы. Однако хакеры всё равно пытаются обойти эти ограничения, что зачастую им успешно удаётся сделать. «Мы очень серьёзно относимся к неправомерному использованию искусственного интеллекта и признаём серьёзные и долгосрочные последствия злоупотребления изображениями для потенциальных жертв. Microsoft по-прежнему стремится защитить пользователей, внедряя надёжные меры ИИ-безопасности на платформах и защищая сервисы от незаконного и вредоносного контента», — заявил Стивен Масада (Steven Masada), помощник главного юрисконсульта подразделения Microsoft по борьбе с киберпреступлениями. Это заявление последовало за декабрьским иском Microsoft, который компания подала в Восточном округе Вирджинии против 10 неизвестных в попытке собрать больше информации о хакерской группировке и пресечь её деятельность. Решение суда позволило Microsoft взять под контроль один из основных веб-сайтов хакеров. Это и обнародование ряда судебных документов в прошлом месяце посеяло панику в рядах злоумышленников, что могло установить личности некоторых участников группировки. Google раскрыла цену генерации видео в Veo 2 — в 64 000 раз дешевле «Мстителей»
24.02.2025 [14:44],
Владимир Фетисов
Компания Google без лишнего шума раскрыла стоимость использования своей новой генеративной нейросети Veo 2, которая предназначена для создания видео и была впервые анонсирована в декабре. Стоимость генерации видео с помощью ИИ-алгоритма составит $0,5 за секунду. 
Источник изображения: Google Это означает, что минута сгенерированного с помощью Veo 2 видео будет стоить $30, а за час придётся заплатить $1800. В подразделении Google DeepMind, занимающемся разработками в сфере искусственного интеллекта, эти цифры сравнили с блокбастером Marvel «Мстители: Финал», производственный бюджет которого составил $356 млн, т.е. примерно $32 000 за секунду видео. Конечно, пользователи Veo 2 не обязательно будут использовать каждую секунду сгенерированного алгоритмом видео, за которую они заплатят. Кроме того, в обозримом будущем нейросеть вряд ли сможет создать что-то подобное блокбастерам Marvel. В сообщении Google сказано, что алгоритм может генерировать видео продолжительностью более двух минут. Отметим, что OpenAI недавно сделала доступным свой ИИ-генератор видео Sora для подписчиков ChatGPT Pro, которые платят $200 в месяц. В YouTube появился ИИ-генератор полноценных роликов по текстовому описанию — их можно будет публиковать в Shorts
13.02.2025 [22:57],
Владимир Фетисов
На платформе YouTube появилась новая функция на основе искусственного интеллекта. Она предназначена для генерации небольших роликов, которые пользователи могут публиковать в Shorts. Речь идёт об инструменте YouTube Dream Screen, который построен на базе Google Veo 2. Эта функция и раньше позволяла генерировать ролики на основе текстового описания, но прежде пользователи могли лишь задействовать их в качестве фона. 
Источник изображения: Copilot Теперь же созданные с помощью Dream Screen видео можно публиковать в своём аккаунте в Shorts. Чтобы опробовать новые возможности пользователю нужно активировать камеру в Shorts, запустить функцию Dream Screen, открыть панель выбора медиафайлов и нажать на кнопку «Создать». После этого можно ввести текстовое описание будущего ролика, а также выбрать один из доступных стилей, объективов, кинематографических эффектов и указать продолжительность видео. По словам представителей YouTube, возможность публиковать сгенерированные ИИ ролики в Shorts на этой неделе появится у пользователей платформы из США, Канады, Австралии и Новой Зеландии. Позднее она также станет доступна в других странах, но более точные сроки озвучены не были. Это обновление стало несколько неожиданным, учитывая, что последняя версия нейросети Google Veo всё ещё находится в раннем доступе. По данным YouTube, интеграция нейросети с функцией Dream Screen позволит быстрее генерировать более «детальные и реалистичные» видео с учётом физики реального мира и естественных движений людей. При этом созданные с помощью ИИ видео будут помечаться, как видимыми визуальными метками, так и невидимыми водяными знаками Google SynthID, указывающими на то, что ролик создан или изменён с помощью нейросети. Европа установила рекорд по отрицательным и нулевым ценам на электричество в 2024 году
21.01.2025 [23:16],
Геннадий Детинич
В Европе рост генерации из возобновляемых источников в совокупности с другими факторами привёл к тому, что в 2024 году количество периодов с предложением нулевой и даже отрицательной стоимости электроэнергии за год удвоилось. Но успех праздновать рано. Цены на энергию обвалило увядание промышленности в ЕС и отсутствие линий электропередач между странами с зелёной генерацией. 
Источник изображения: ИИ-генерация Кандинский 3.1/3DNews Статистику по ценам на электрическую энергию в Европе собрало агентство Montel Analytics. Оно отмечает, что в 2024 году в разных странах Европы было зафиксировано 4838 случаев падения цен на электроэнергию до нуля или ниже на сутки вперед, что является рекордно высоким показателем, обусловленным ростом мощностей возобновляемой генерации, вялым спросом и ограниченной гибкостью электросетей. Тем самым общее количество случаев падения цен до нуля и ниже почти вдвое превысило 2442 случаев, которые были зарегистрированы в 2023 году. Финляндия лидировала по отрицательным ценам в течение 721 часа, в основном из-за высокой генерации ветровыми электростанциями и невозможности поделиться излишками со Швецией и Эстонией, с которыми имеет кое-какие общие линии электропередачи, но недостаточные по пропускной способности. В это же время в Нидерландах был переизбыток солнечной электроэнергии, в Швеции — ветряной и, впервые, переизбыток был зафиксирован на Пиренейском полуострове. В совокупности в 2024 году на возобновляемые источники энергии пришлось 50,4 % от общего энергобаланса Европы, что стало рекордно высоким показателем. Тем временем ископаемое топливо упало до доли менее чем 25 % от общего объёма генерации на континенте, а атомная энергетика выросла до 24,7 %, чему способствовало восстановление парка АЭС Франции. «Доступность атомной энергии во Франции постепенно восстановилась в течение 2023 года и в начале 2024 года после исторического минимума в 2022 году, — сказал директор Montel Analytics Жан-Поль Харреман (Jean-Paul Harreman) в своём комментарии к публикации. Более того, Франция экспортировала самый большой за 22 года объём электроэнергии в 2024 году, за что, похоже, надо благодарить власти Германии, которые остановили все свои АЭС. Снижение цен на электроэнергию не привело к снижению цен на газ. Цена газовой генерации выросла за год на 5,6 % (до 43 евро за 1 МВт·ч). К началу года хранилища были заполнены на 76 %, что при средних условиях зимы считается достаточным. При всей кажущейся дешевизне и обилии солнечной генерации в Европе ещё сильнее увеличился разрыв между дешёвой энергией в часы пика выработки и дорогой в вечернее время, когда электричество необходимо гражданам в максимальном объёме. Возобновляемая энергетика вытесняет традиционную и в вечернее и ночное время дешёвого электричества больше нет. Промышленный спрос в Европе на электричество в 2024 году оставался ниже «доковидного» уровня, а солнечные панели на крышах продолжали компенсировать потребление электроэнергии в домашних хозяйствах. Сообщается, что общий спрос на электроэнергию в Европе упал на 7,7 % в годовом исчислении до 2678 ТВт·ч, что подчёркивает ослабление промышленности, особенно в Германии. Intel показала работу генерации кадров в XeSS2 на встроенной графике — это «меняет правила игры»
13.01.2025 [18:43],
Сергей Сурабекянц
Одновременно с выпуском графических процессоров Battlemage компания Intel представила технологию XeSS второго поколения, которая включает в себя функцию генерации кадров (XeSS FG). Данная технология поддерживается в том числе встроенной графикой Intel последнего поколения. На CES 2025 эксперты протестировали XeSS2 в игре F1 24 с высокими настройками качества графики на ноутбуке MSI Prestige с чипом Core Ultra 9 285H (Arrow Lake) со встроенной графикой Xe-LPG+. 
Источник изображений: hothardware.com В отличие от масштабирования, генерация кадров доступна далеко не для всех графических продуктов Intel — она требует специализированного графического процессора Intel Arc. Графический движок в процессорах Core Ultra 200H в основе своей похож на движок в процессорах Core Ultra 100H под кодовым названием Meteor Lake. Он имеет то же количество ядер Xe и построен на той же архитектуре Alchemist. Однако обновление ядер XMX до Xe-LPG+ обеспечило улучшенный уровень производительности под рабочими нагрузками ИИ, включая XeSS. Эксперты утверждают, что технология XeSS FG в сочетании с процессором Core Ultra 9 285H продемонстрировала «значительный прирост производительности» — с 57 FPS до более чем 100 FPS в игре F1 24. Перевод системы в режим с низким энергопотреблением ограничил чипсет 15 ваттами, при этом ноутбук благодаря XeSS FG смог поддерживать частоту кадров выше 60 FPS по сравнению с базовыми 30 FPS при отключённой генерации кадров.  Исследователи отмечают, что повышение частоты с 30 FPS до 60 FPS через генерацию кадров — «не самый приятный опыт, и, вероятно, не то, что мы хотели бы делать в гоночной игре, такой как F1». Однако, по их мнению, для таких игр, как Civilization VI или Marvel's Midnight Suns, это может быть отличным решением. Эксперты полагают, что XeSS FG работает довольно хорошо, если не считать «некоторых странностей ранней реализации, в основном в меню». Генерация кадров, как практически любая технология, имеет как реальные достоинства, так и реальные ограничения. По мнению экспертов, «это отличный способ довести игру, которая выдаёт 50 или 60 FPS, до 100+ кадров в секунду для улучшения визуальной плавности, и это реальное преимущество новых процессоров Intel Core Ultra». США столкнутся с дефицитом электроэнергии из-за ИИ уже в 2025 году, предупредил отраслевой регулятор
18.12.2024 [17:46],
Сергей Сурабекянц
Североамериканская электросеть сталкивается с «критическими проблемами надёжности», поскольку производство электроэнергии не успевает за растущим спросом со стороны систем искусственного интеллекта. Рост потребления электроэнергии в следующем десятилетии в сочетании с закрытием угольных электростанций создаст огромную нагрузку на сети США и Канады и может превысить генерирующие мощности, сообщает North American Electric Reliability Corporation (NERC). 
Источник изображения: pexels.com NERC — некоммерческая организация, подконтрольная Федеральной комиссии по регулированию энергетики. По данным NERC, дефицит может привести к веерным отключениям электроэнергии в периоды пикового спроса в обеих странах. Проблема может потенциально усугубится из-за задержек с вводом в эксплуатацию мощностей солнечной генерации, ветряных электростанций, аккумулирующих мощностей и гибридных ресурсов. Некоторые районы США могут столкнуться с дефицитом уже в следующем году. Отчёт NERC за 2024 год свидетельствует о том, что растущие потребности ИИ в энергии могут перегрузить и нарушить баланс всей энергосистемы. «Мы переживаем период глубоких изменений, — заявил директор по оценке надёжности NERC Джон Моура (John Moura). — Мы наблюдаем рост спроса, которого не видели десятилетиями и видим, что темпы [роста спроса] только ускоряются». Предполагаемый всплеск спроса совпадёт со сворачиванием генерации на ископаемом топливе, при этом в течение следующих 10 лет планируется закрыть мощности на 115 ГВт. По данным NERC, спрос на электроэнергию за последний год рос быстрее, чем когда-либо за последние два десятилетия на фоне массового строительства центров обработки данных ИИ и майнинга криптовалют, а также по мере роста популярности электромобилей и тепловых насосов. Вместо прогнозируемых 80 ГВт пиковый летний спрос в течение следующего десятилетия вырастет на 132 ГВт, или на 15 процентов. Пиковый зимний спрос вырастет на 18 процентов до 149 ГВт, что в полтора раза превышает прошлый прогноз в 92 ГВт. По прогнозам международного энергетического агентства, глобальный спрос на электроэнергию только от центров обработки данных может превысить 1000 тераватт-часов к 2026 году, что вдвое больше уровня 2022 года и эквивалентно общим потребностям Германии в электроэнергии. Крупные технологические компании изо всех сил пытаются найти способы удовлетворить растущие потребности в электроэнергии, в том числе заключая сделки о строительстве новых атомных электростанций и малых модульных ядерных реакторов. Intel представила технологию XeSS2 с генерацией кадров — FPS вырастет до четырёх раз
03.12.2024 [18:45],
Сергей Сурабекянц
Технология масштабирования изображения Intel XeSS обновилась до второй версии и получила долгожданную функцию генерации кадров. С её помощью графические ускорители Intel, такие как новый Arc B580, смогут обеспечить прирост производительности до 3,9 раза. Intel также анонсировала режим низкой задержки XeLL (Xe Low Latency), который существенно снижает задержку в играх, особенно при включённой генерации кадров. 
Источник изображений: Intel Технология масштабирования изображения Intel XeSS продемонстрировала огромный прогресс. Последнее обновление стека XeSS включает поддержку API DirectX 11 и Vulkan, что существенно расширяет список поддерживаемых игр. По утверждению Intel, XeSS теперь обеспечивает более высокую производительность и сравнялась с DLSS от Nvidia с точки зрения визуального качества. На сегодняшний день XeSS поддерживается более чем 150 играми. Intel утверждает, что генерация кадров в XeSS2 позволит графическим процессорам Intel обеспечить до 3,9-кратного прироста производительности в режиме Ultra Performance («Ультра производительность») в разрешении 1440p и максимальных настройках качества графики. Производительность масштабируется в зависимости от используемых настроек, но даже при выборе пресета Quality («Качество») прирост производительности составит до 2,8 раз. 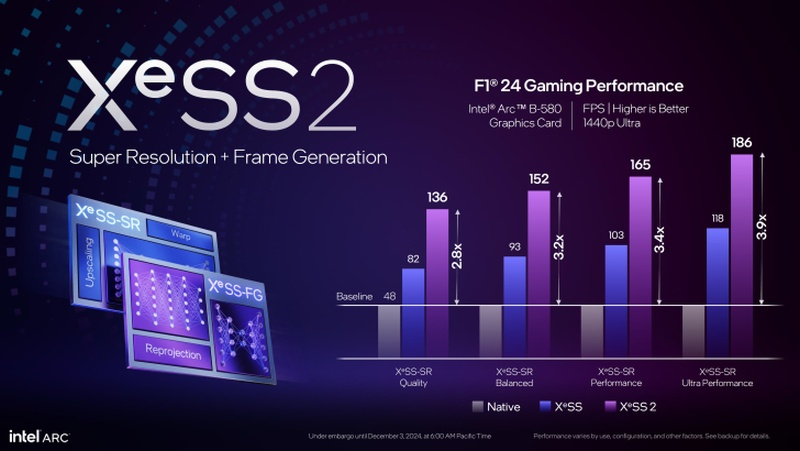 По мнению экспертов, Intel в XeSS2 отказалась от прежних попыток использования метода экстраполяции и прибегла к интерполяции, которую используют при генерации кадров Nvidia и AMD. Режим низкой задержки XeLL (Xe Low Latency) аналогичен технологиям Nvidia Reflex и AMD Anti-Lag 2. Поддержка XeLL реализована на уровне драйвера. Функция снижает задержку в играх, особенно при включённой генерации кадров. Intel заявляет об улучшении отзывчивости игр на 45 % при разрешении 1440p.  На сегодняшний день Intel сообщила о десяти играх с поддержкой XeSS2:
 С появлением XeSS2 Intel в какой-то степени достигает паритета с технологиями Nvidia DLSS3 и AMD FSR3, которые, скорее всего, будут обновлены в следующем поколении их графических процессоров, вновь оторвавшись от Intel. YouTube добавил в Shorts функцию Dream Screen — ИИ-генератор фонов для роликов
22.11.2024 [16:25],
Павел Котов
Администрация YouTube объявила, что в разделе коротких вертикальных роликов Shorts теперь доступна обновлённая функция Dream Screen — генерация динамических фоновых изображений с использованием искусственного интеллекта. Ранее функция Dream Screen позволяла генерировать в качестве фонов не видео, а неподвижные картинки. 
Источник изображения: YouTube Новая возможность появилась благодаря интеграции модели для генерации видео Google DeepMind Veo — она позволяет создавать ролики с разрешением 1080p в разных кинематографических стилях. Чтобы запустить новую функцию, необходимо перейти в камеру Shorts, выбрать значок «Зелёный экран» и опцию Dream Screen — здесь можно ввести текстовый запрос, например, «пейзаж из конфет» или «волшебный лес и ручей»; после чего останется выбрать стиль анимации и нажать кнопку «Создать». Dream Screen создаст несколько видеофонов, из которых нужно выбрать один, после чего можно записывать видео с этим изображением позади себя. Новая функция пригодится, например, чтобы погрузить зрителя в атмосферу любимой книги или подготовить анимированное вступление к основному ролику. В перспективе YouTube планирует предоставить авторам возможность создавать 6-секундные видеоролики, полностью сгенерированные Dream Screen. Крупнейшая в мире платформа коротких видео TikTok также поддерживает создание фоновых изображений с помощью ИИ, но эти картинки пока статические. Воспользоваться обновлённым вариантом Dream Screen могут пользователи YouTube из США, Канады, Австралии и Новой Зеландии. StabilityAI представила улучшенную ИИ-модель для генерации изображений Stable Diffusion 3.5
23.10.2024 [05:06],
Анжелла Марина
Компания StabilityAI представила новую версию ИИ-модели для генерации изображений Stable Diffusion 3.5 с улучшенным реализмом, точностью и стилизацией. По сообщению Tom's Guide, модель бесплатна для некоммерческого использования, включая научные исследования, а также для малых и средних предприятий с доходом до $1 млн. 
Источник изображения: StabilityAI Как и предыдущая версия SD3, Stable Diffusion 3.5 доступен в трёх конфигурациях: Large (8B), Large Turbo (8B) и Medium (2,6B). Все конфигурации оптимизированы для работы на обычном пользовательском оборудовании и их можно настраивать. В своём пресс-релизе StabilityAI признала, что модель Stable Diffusion 3 Medium, выпущенная в июне, не полностью соответствовала стандартам и ожиданиям сообщества. «После того как мы выслушали ценные отзывы, вместо быстрого исправления мы решили уделить время разработке версии, которая продвигает нашу миссию по трансформации визуальных медиа», — сказали в компании. Новые модели ориентированы на возможность гибкой настройки, высокую производительность и разнообразие результатов. Поддерживаются стилистические настройки, включая фотографию и живопись. Для указания определённого стиля можно также использовать хештеги, например, boho, impressionism или modern. Ещё можно выделять ключевые слова в запросе для получения более реалистичных изображений. Модель Stable Diffusion 3.5 Large лидирует на рынке по лучшему соответствию запросам и качеству изображений. Модель Turbo имеет минимальное время вывода результатов. Medium превосходит другие модели в плане баланса между качеством изображений и соответствия запросам, что делает её, по утверждению компании, самым эффективным выбором для создания контента. Все три конфигурации свободно доступны по лицензии Stability AI Community License. Для использования в коммерческих целях потребуется лицензия Enterprise License. Adobe интегрировала ИИ-генератор видео Firefly Video Model в редактор Premiere Pro
15.10.2024 [00:37],
Владимир Фетисов
Компания Adobe официально представила новую генеративную нейросеть Firefly Video Model, которая предназначена для работы с видео и стала частью приложения Premiere Pro. С помощью этого инструмента пользователи смогут дополнять отснятый материал, а также создавать ролики на основе статичных изображений и текстовых подсказок. 
Источник изображений: Adobe Функция Generative Extend на базе упомянутой нейросети в рамках бета-тестирования становится доступной пользователям Premiere Pro. Она позволит продлить видео на несколько секунд в начале, конце или каком-то другом отрезке ролика. Это может оказаться полезным, если в процессе монтажа нужно скорректировать мелкие недочёты, такие как смещение взгляда человека в кадре или лишние движения.  С помощью Generative Extend можно продлить ролик лишь на две секунды, поэтому он подходит только для внесения небольших изменений. Данный инструмент работает с разрешением 720p или 1080p с частотой 24 кадра в секунду. Функция также подходит для увеличения продолжительности аудио, но есть ограничения. Например, пользователь может продлить какой-либо звуковой эффект или окружающий шум до 10 секунд, но сделать это же с записями разговором или музыкальными композициями не удастся. 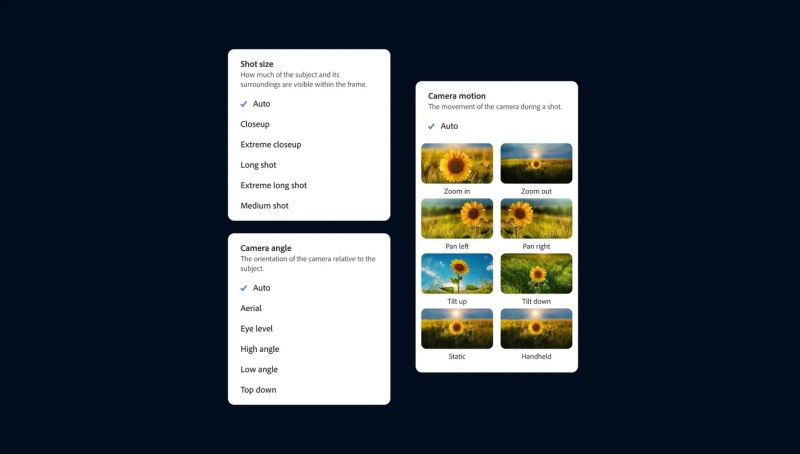 В веб-версии Firefly появились два новых инструмента генерации видео. Речь идёт о функциях Text-to-Video и Image-to-Video, которые, как можно понять из названия, позволяют создавать видео на основе текстовых подсказок и статических изображений. На данном этапе обе функции находятся на этапе ограниченного бета-тестирования, поэтому могут быть доступны не всем пользователям веб-версии Firefly. Text-to-Video работает аналогично другим ИИ-генераторам видео, таким как Sora от OpenAI. Пользователю нужно ввести текстовое описание желаемого результата и запустить процесс генерации ролика. Поддерживается имитация разных стилей, а сгенерированные ролики можно доработать с помощью набора «элементов управления камерой», которые позволяют имитировать такие вещи, как угол наклона камеры, движение и менять расстояние съёмки. Image-to-Video позволяет добавить к текстовому описанию статическое изображение, чтобы генерируемые ролики более точно соответствовали требованиям пользователя. Adobe предлагает использовать этот инструмент, в том числе, для пересъёмки отдельных фрагментов, генерируя новые видео на основе отдельных кадров из существующих роликов. Однако опубликованные примеры дают понять, что этот инструмент, по крайней мере на данном этапе, не позволит отказаться от пересъёмки, поскольку он не совсем точно воспроизводит все имеющиеся на изображении объекты. Ниже пример оригинального видео и ролика, сгенерированного на основе кадра из оригинала. Снимать длинные ролики с помощью этих инструментов не получится, по крайней мере на данном этапе. Функции Text-to-Video и Image-to-Video позволяют создавать видео продолжительностью 5 секунд в качестве 720p с частотой 24 кадра в секунду. Для сравнения, OpenAI утверждает, что её ИИ-генератор Sora может создавать видео длиной до минуты «при сохранении визуального качества и соблюдении подсказок пользователя». Однако этот алгоритм всё ещё недоступен широкому кругу пользователей, несмотря на то, что с момента его анонса прошло несколько месяцев. Для создания видео с помощью Text-to-Video, Image-to-Video и Generative Extend требуется около 90 секунд, но в Adobe сообщили о работе над «турборежимом» для сокращения времени генерации. В компании отметили, что созданные на основе Firefly Video Model инструменты «коммерчески безопасны», поскольку нейросеть обучается на контенте, который Adobe разрешено использовать. «Яндекс» создал ИИ-помощника для генерации программного кода
12.09.2024 [14:03],
Владимир Фетисов
Компания «Яндекс» подала в Роспатент заявку на регистрацию товарного знака Yandex Code Assistant, в числе регистрируемых классов и услуг — программное обеспечение и средства совместной работы над программным кодом. В «Яндексе» подтвердили разработку сервиса для генерации кода на базе искусственного интеллекта, добавив, что он будет доступен «бесплатно в режиме тестирования» на облачной платформе Yandex Cloud. 
Источник изображения: geralt/Pixabay «Яндекс» и «Сбер», у которых есть собственные большие языковые модели (LLM), больше года работают над созданием инструментов автоматического дополнения программного кода. Разработка таких продуктов началась вскоре после появления сервиса GitHub Copilot, который в 2021 году создала Microsoft на основе технологий компании OpenAI. Этот сервис недоступен в России, а взаимодействие с ним осуществляется в рамках платной подписки. Осенью прошлого года «Сбер» запустил сервис GigaCode, а летом этого года собственную интегрированную среду разработки GigaIDE. По данным источника, за несколько месяцев с момента запуска ИИ-помощника GigaCode его установили более 20 тыс. пользователей. Что касается Yandex Code Assistant, то он будет совместим с популярными редакторами программного кода, сообщил директор по продукту Yandex Cloud Григорий Атрепьев. Он также добавил, что этот и другие инструменты станут частью «платформы для создания, развёртывания и сопровождения цифровых продуктов». В компании не уточнили, планируется ли создание собственной интегрированной среды разработки, а также, какие именно сервисы станут частью платформы. По данным источника, «Яндекс», помимо Code Assistant, работает над созданием инструментов Code Review для проверки и анализа кода, а также Auto Documentation для автоматической аннотации кода. MiniMax представила бесплатный ИИ-генератор video-1, который превращает текст в видео за 2 минуты
02.09.2024 [19:03],
Владимир Фетисов
Китайский стартап MiniMax, работающий в сфере искусственного интеллекта, представил алгоритм video-1, который генерирует небольшие видеоклипы на основе текстовых подсказок. Генератор video-1 был представлен широкой публике на прошедшей несколько дней назад в Шанхае первой конференции разработчиков компании, а позднее стал доступен всем желающим на веб-сайте MiniMax. 
Источник изображения: scmp.com С помощью video-1 пользователь может на основе текстового описания создавать видеоролики продолжительностью до 6 секунд. Процесс создания такого ролика занимает около 2 минут. Основатель MiniMax Ян Цзюньцзе (Yan Junjie) рассказал на презентации, что video-1 является первой версией алгоритма генерации видео по текстовым подсказкам, отметив, что в будущем нейросеть сможет создавать ролики на основе статических изображений, а также позволит редактировать уже созданные клипы. Появление video-1 отражает стремление китайских технологических компаний продвинуться в зарождающемся сегменте рынка ИИ. Генератор видео был представлен всего через несколько месяцев после анонса нейросети Sora компании OpenAI, которая также позволяет создавать видео по текстовым подсказкам. Что касается MiniMax, то компания была основана в декабре 2021 года и с тех пор она проделала немалую работу. Новый инструмент video-1 предлагается в рамках платформы MiniMax под названием Hailuo AI, которая ориентирована на потребительский рынок и уже предоставляет доступ к функциям генерации текстов и музыки с помощью нейросетей. Помимо MiniMax, разработкой ИИ-алгоритмов для генерации видео из текста занимаются и другие китайские компании. Пекинский стартап Shengshu AI в июле запустил собственный генератор видео из текста на китайском или английском языках под названием Vidu. Стартап Zhipu AI стоимостью более $1 млрд в том же месяце представил свой аналог Sora, который может создавать небольшие видео на основе текстовых подсказок или статических изображений. Владелец TikTok и Douyin, компания ByteDance, в прошлом месяце опубликовала в китайском App Store приложение Jimeng text-to-video для генерации видео из текста, а ещё ранее оно появилось в местных магазинах Android-приложений. Jimeng позволяет создать бесплатно 80 изображений или 26 видео, а для более активного взаимодействия с нейросетью предлагается оформить подписку за 69 юаней (около $10). В прошлом месяце компания Alibaba Group Holding объявила о разработке алгоритма для генерации видео под названием Tora, основанного на модели OpenSora. Отметим, что среди инвесторов MiniMax есть крупные IT-компании, такие как Alibaba, Tencent Holdings и miHoYo (создатель Genshin Impact). Очередной раунд финансирования прошёл весной и после его завершения рыночная стоимость MiniMax оценивалась более чем в $2 млрд. AMD представила Amuse 2.0 — ПО для ИИ-генерации изображений для Ryzen и Radeon
29.07.2024 [00:20],
Николай Хижняк
AMD представила Amuse 2.0 — программный инструмент для ИИ-генерации изображений. Программа доступна в бета-версии. В перспективе её функциональность будет расширяться. Amuse 2.0 является своего рода аналогом инструмента AI Playground от Intel, использующего мощности видеокарт Intel Arc. Решение от AMD для генерации контента в свою очередь полагается на мощности процессоров Ryzen и видеокарт Radeon. 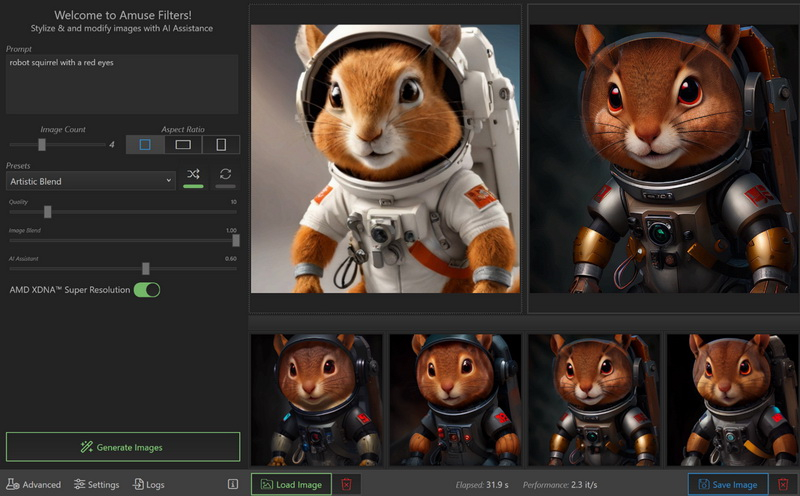
Источник изображений: AMD Приложение Amuse 2.0, разработанное с помощью TensorStack, отличается простотой использования, без необходимости загружать множество внешних компонентов, задействовать командные строки или запускать что-либо ещё. Для использования приложения достаточно лишь запустить исполняемый файл. 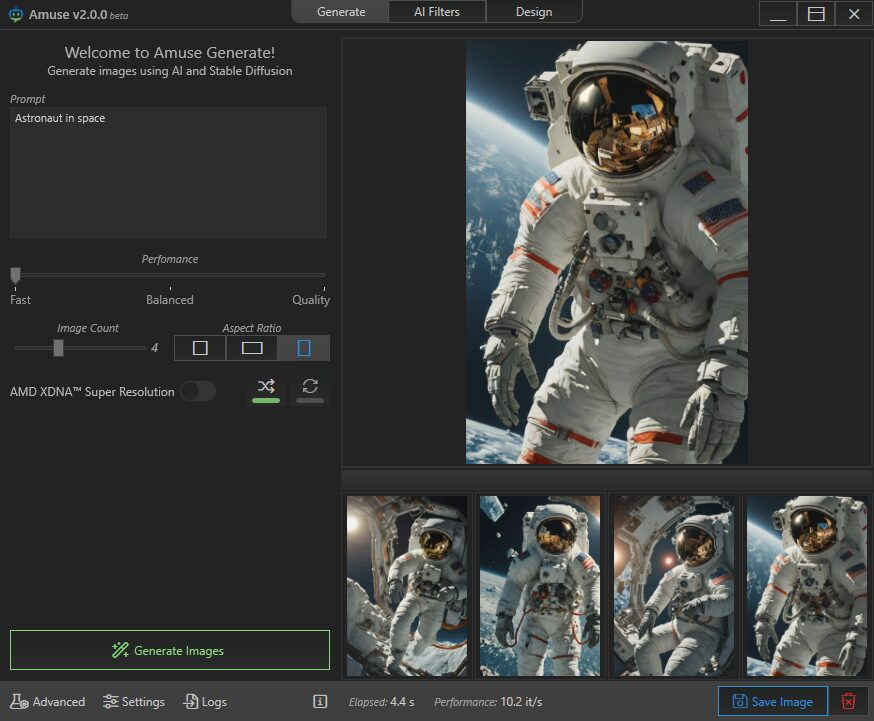 По сравнению с Intel AI Playground, Amuse 2.0 не поддерживает запуск чат-ботов на основе больших языковых моделей. В настоящее время приложение предназначено только для генерации изображений с помощью ИИ. Amuse 2.0 использует модели Stable Diffusion и поддерживает процессоры Ryzen AI 300 (Strix Point), Ryzen 8040 (Hawk Point) и серию видеокарт Radeon RX 7000. Почему компания не добавила поддержку видеокарт Radeon RX 6000 и более ранних моделей, а также процессоров Ryzen 7040 (Phoenix), обладающих практически идентичными характеристиками с Hawk Point, неизвестно. Возможно, это изменится в будущем. 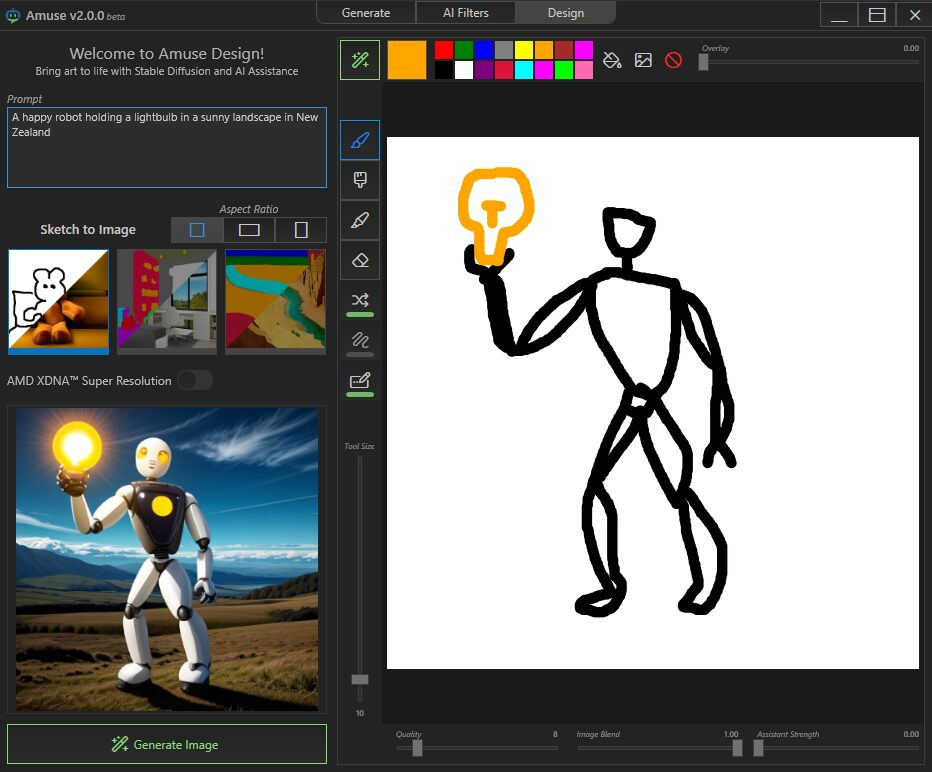 Для работы Amuse 2.0 AMD рекомендует использовать 24 Гбайт ОЗУ или больше для систем на базе процессоров Ryzen AI 300 и 32 Гбайт оперативной памяти для систем на базе Ryzen 8040. Для видеокарт Radeon RX 7000 требования к необходимому объёму памяти не указаны. 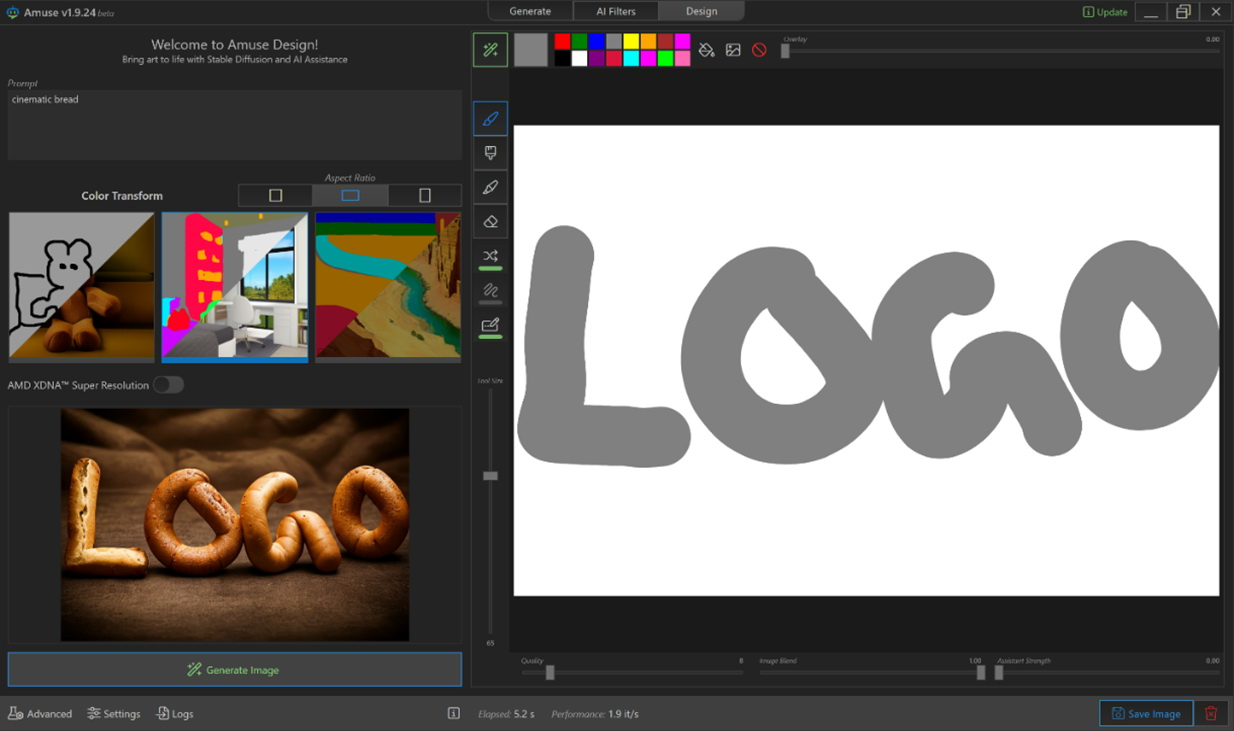 Возможности Amuse 2.0:
Стоит отметить, что инструмент поддерживает XDNA Super Resolution — технологию, позволяющую увеличивать масштаб изображений вдвое. Более подробно об Amuse 2.0 можно узнать по этой ссылке. Stability AI представила генератор 4D-видео Stable Video 4D
25.07.2024 [01:21],
Владимир Фетисов
На фоне популярности генеративных нейросетей уже доступно множество ИИ-алгоритмов для создания видео, таких как Sora, Haiper и Luma AI. Разработчики из Stability AI представили нечто совершенно новое. Речь идёт о нейросети Stable Video 4D, которая опирается на существующую модель Stable Video Diffusion, позволяющую преобразовывать изображения в видео. Новый инструмент развивает эту концепцию, создавая из получаемых видеоданных несколько роликов с 8 разными перспективами. 
Stable Diffusion 3 «Мы считаем, что Stable Video 4D будет использоваться в кинопроизводстве, играх, AR/VR и других сферах, где присутствует необходимость просмотра динамически движущихся 3D-объектов с произвольных ракурсов», — считает глава подразделения по 3D-исследованиям в Stability AI Варун Джампани (Varun Jampani). Это не первый случай, когда Stability AI выходит за пределы генерации двумерного видео. В марте компания анонсировала алгоритм Stable Video 3D, с помощью которого пользователи могут создавать короткие 3D-ролики на основе изображения или текстового описания. С запуском Stable Video 4D компания делает значительный шаг вперёд. Если понятие 3D или три измерения обычно понимается как тип изображения или видео с глубиной, то 4D, не добавляет ещё одно измерение. На самом деле 4D включает в себя ширину (x), высоту (y), глубину (z) и время (t). Это означает, что Stable Video 4D позволяет смотреть на движущиеся 3D-объекты с разных точек обзора и в разные моменты времени. «Ключевые аспекты, которые позволили создать Stable Video 4D, заключаются в том, что мы объединили сильные стороны наших ранее выпущенных моделей Stable Video Diffusion и Stable Video 3D, а также доработали их с помощью тщательно подобранного набора данных динамически движущихся 3D-объектов», — пояснил Джампани. Он также добавил, что Stable Video 4D является первым в своём роде алгоритмом, в котором одна нейросеть выполняет синтез изображения и генерацию видео. В уже существующих аналогах для решения этих задач используются отдельные нейросети. «Stable Video 4D полностью синтезирует восемь новых видео с нуля, используя для этого входное видео в качестве руководства. Нет никакой явной передачи информации о пикселях с входа на выход, вся эта передача информации осуществляется нейросетью неявно», — добавил Джампани. Он добавил, что на данный момент Stable Video 4D может обрабатывать видео с одним объектом длительностью несколько секунд с простым фоном. В дальнейшем разработчики планируют улучшить алгоритм, чтобы он мог использоваться для обработки более сложных видео. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться