|
Опрос
|
реклама
Быстрый переход
Картинки в стиле Ghibli перегрузили серверы OpenAI — выпуск новых функций замедлен
02.04.2025 [00:41],
Анжелла Марина
Генеральный директор OpenAI Сэм Альтман (Sam Altman) заявил, что из-за высокой популярности нового инструмента генерации изображений в ChatGPT компания столкнулась с перегрузкой оборудования, из-за чего выход новых продуктов и функций придётся ограничить. 
Источник изображения: Mariia Shalabaieva / Unsplash По словам Альтмана, OpenAI пытается справиться с ситуацией, но пользователям следует ожидать как минимум задержек в релизах, а также перебоев в работе сервисов и замедления работы платформы. Тем не менее, как отмечает TechCrunch, компания уверяет, что держит ситуацию под контролем. «Что-то будет ломаться, а обслуживание иногда будет медленным, поскольку мы справляемся с проблемами, связанными с пропускной способностью, — написал Альтман. — Мы стараемся решать проблемы оперативно, чтобы всё действительно работало». Напомним, выпущенный недавно новый генератор изображений вызвал буквально ажиотаж благодаря способности имитировать различные стили, в частности популярный стиль анимационной студии Studio Ghibli. Однако компания не успевает справляться с наплывом пользователей, а сотрудники вынуждены работать допоздна и даже в выходные, чтобы поддерживать работоспособность системы. Чтобы снизить нагрузку на свои серверы, OpenAI задержала запуск нового инструмента генерации изображений для бесплатных пользователей ChatGPT, а возможность создания видео с помощью Sora временно отключена для новых пользователей. Компания не уточняет, когда проблемы с перегрузкой будут окончательно решены и пока продолжает работать над улучшением инфраструктуры. В понедельник ChatGPT зафиксировал регистрацию в сервисе одного миллиона новых пользователей всего за один час. Также отметим, что на сегодня системой пользуются 500 миллионов еженедельных пользователей и 20 миллионов подписчиков, что значительно больше по сравнению с концом 2024 года, когда показатели составляли 300 миллионов и 15,5 миллиона соответственно. Завирусившийся новый генератор изображений в ChatGPT стал доступен всем пользователям
01.04.2025 [11:24],
Владимир Фетисов
Новый генератор изображений OpenAI, работающий на базе большой языковой модели GPT-4o, теперь доступен всем пользователям. Об этом на своей странице в социальной сети X написал гендиректор OpenAI Сэм Альтман (Sam Altman). До этого момента использовать новый ИИ-генератор изображений могли только платные подписчики ChatGPT. 
Источник изображения: OpenAI Бесплатные пользователи сервиса сейчас могут генерировать не больше двух изображений в сутки. Ранее Альтман упоминал о возможности введения лимита в три изображения в день. Инструмент генерации изображений OpenAI мгновенно стал сверхпопулярным сразу после его запуска в массы. Альтман заявлял, что спрос на генерацию картинок был так высок, что используемые компанией графические ускорители попросту «плавились». Генератор быстро стал известен тем, что его использовали для преобразования изображений в стиль японской анимационной студии Studio Ghibli. Это вызвало обеспокоенность по поводу нарушения авторских прав, поскольку создаваемые ИИ-генератором изображения были очень похожи на работы студии. Некоторые люди также использовали данный инструмент для создания поддельных квитанций, например, ресторанных счетов. В компании на это заявили, что все сгенерированные ИИ изображения содержат метаданные, указывающие на их происхождение. Вместе с этим OpenAI заявила о привлечении $40 млрд инвестиций, за счёт чего рыночная стоимость компании составила $300 млрд. В качестве основного инвестора в рамках этого раунда финансирования выступил Softbank. Компания также объявила, что ИИ-бот ChatGPT еженедельно используют более 500 млн человек по всему миру, тогда как количество ежемесячно активных пользователей выросло до 700 млн человек. Представлен формат изображений Spectral JPEG XL, который эффективно сохранит данные даже о невидимом свете
29.03.2025 [12:44],
Павел Котов
Учёные Intel разработали формат для записи изображения Spectral JPEG XL — он позволяет записывать данные в широком диапазоне спектра за пределами стандартного набора красного, зелёного и синего. Поддерживаются даже невидимые человеческому глазу участки. 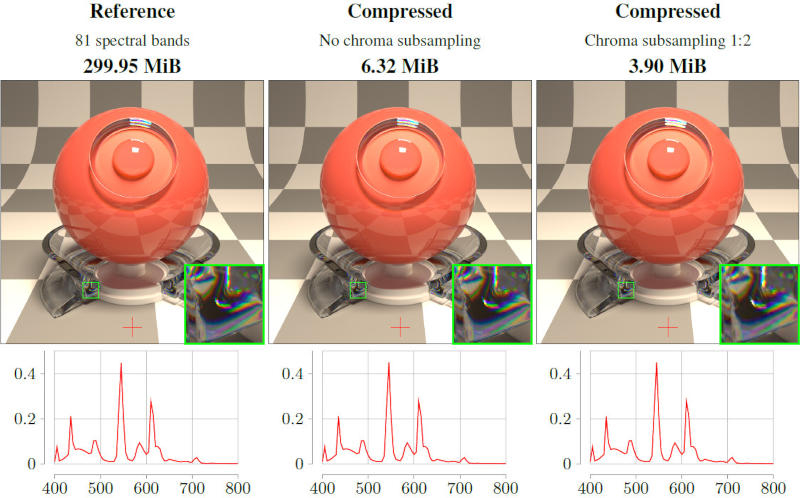
Источник изображений: jcgt.org В науке и промышленности иногда возникает потребность фиксировать цвета, которые неспособен воспринимать человеческий глаз, например, ультрафиолетовый и инфракрасный участки спектра или определённые длины волн, которые необходимы растениям для фотосинтеза. Некоторые камеры предназначаются, чтобы фиксировать тонкие различия, из-за которых цвета краски выглядят так, как нужно при заданном освещении. Существующие форматы записи такой информации предусматривают запись 30, 100 и более точек данных на пиксель, из-за чего файлы раздуваются до размеров в несколько гигабайтов — они получаются слишком громоздкими для хранения и анализа. Решение предложили учёные из компании Intel Альбан Фише (Alban Fichet) и Кристоф Питерс (Christoph Peters) — они разработали формат Spectral JPEG XL, способный записывать спектральные данные, но при этом поддерживающий сжатие. Традиционные файлы цифровых изображений записывают информацию всего о трёх цветах: красном, зелёном и синем (RGB). Этого достаточно для повседневных фотографий, но для истинного захвата цвета требуется больший набор деталей. Спектральные изображения отличаются более высокой точностью, потому что регистрируют насыщенность не только в RGB, но и в десятках или даже сотнях узких длин волн. Эта подробная информация охватывает видимый спектр, а также ближние инфракрасный и ультрафиолетовый участки — это позволяет более точно моделировать взаимодействие материалов со светом. Такие файлы хранят данные не только в трёх каналах RGB — этих каналов оказывается значительно больше, и каждый представляет интенсивность света на определённом, очень узком диапазоне длин волн. В опубликованной авторами проекта научной работе обсуждаются изображения, содержащие 31 канал, приводятся даже примеры с 81 спектральной полосой. Эти каналы должны захватывать более широкий диапазон значений яркости — стандартных 8-битных изображений уже недостаточно, поэтому для каждого канала приходится использовать 16- и 32-битные числа с плавающей запятой.  Существует множество вариантов практического применения этой технологии. Автопроизводителю необходимо точно предсказать, как будет выглядеть краска при разном освещении. Учёные применяют спектральную визуализацию для идентификации материалов по их уникальным световым сигнатурам. Специалистам по рендерингу она требуется для точного моделирования реальных оптических эффектов, например, дисперсии и флуоресценции. Астрономы анализируют спектральные линии излучения от гамма-всплеска, чтобы идентифицировать присутствующие при взрыве вещества. Используемый сегодня для хранения таких данных формат OpenEXR разрабатывался без учёта таких широких требований, а существующие методы сжатия без потерь, такие как ZIP, не позволяют добиться значительного сокращения объёмов данных. В Spectral JPEG XL применяется метод дискретного косинусного преобразования (ДКП). В упрощённом виде принцип его работы можно объяснить так: при взгляде на цветовые переходы у радуги не нужно записывать каждую длину волны, чтобы понять, что видит человек. ДКП преобразует плавные волновые узоры в волноподобные составляющие (частотные коэффициенты), из которых при сложении воссоздаётся исходная спектральная информация. Схожим образом обрабатывается звук в MP3 — вместо того, чтобы записывать каждую крошечную вибрацию в отдельную звуковую волну, формат фиксирует важные частотные составляющие, которые воспринимаются ухом, а всё остальное отбрасывается. Так и Spectral JPEG XL записывает данные, которые определяют взаимодействие света с материалами, а менее важные детали подвергаются сжатию. Далее осуществляется оценка данных — спектральные коэффициенты делятся на общую яркость, благодаря чему менее важная информация при сжатии повреждается не так сильно. Получившийся поток данных подаётся в кодек, и вместо того, чтобы изобретать новый тип файла, используется стандартный формат изображения JPEG XL, в который записываются специально подготовленные спектральные данные. На выходе авторам проекта удалось уменьшить размеры спектральных изображений в 10–60 раз по сравнению со стандартным сжатием формата без потерь OpenEXR — по размерам файлы стали сравнимы с обычными высококачественными фотографиями. При этом сохраняются важные функции OpenEXR, в том числе метаданные и поддержка широкого динамического диапазона. Часть информации в процессе сжатия теряется, но формат разработан с расчётом на то, чтобы сначала отбрасывать менее заметные детали — артефакты сжатия возникают на менее важных участках, а важная визуальная информация сохраняется. Остаются и некоторые ограничения. Spectral JPEG XL сможет широко использоваться при условии постоянной разработки и совершенствования программных инструментов; первоначальные программные реализации могут потребовать дальнейшей разработки, чтобы полностью раскрыть все возможности формата. Принять формат с потерями при сжатии смогут не все — в некоторых областях, где проводятся особо тонкие измерения, может потребоваться дальнейший поиск альтернативных методов хранения данных. На начальном этапе Spectral JPEG XL может оказаться полезным в научной визуализации и высококачественном рендеринге; но многие отрасли от проектирования транспорта до медицинской визуализации продолжают вырабатывать большие объёмы данных, и со временем технологии сжатия могут найти применение и здесь. «Наши GPU плавятся»: ажиотаж вокруг нового генератора картинок в ChatGPT заставил OpenAI ввести ограничения
27.03.2025 [22:21],
Владимир Мироненко
Представленная на днях функция 4o Image Generation генерации качественных изображений вызвала огромный интерес у пользователей. Ажиотаж даже вынудил OpenAI «временно» ограничить частоту отправки запросов на генерацию изображений, сообщил в соцсети X гендиректор компании Сэм Альтман (Sam Altman). «Очень забавно наблюдать, как людям нравятся изображения в ChatGPT, но наши графические процессоры плавятся», — отметил он в своём сообщении. 
Источник изображения: OpenAI Альтман не уточнил, какой предел скорости был установлен, лишь выразив надежду, что это ограничение не понадобится надолго, поскольку OpenAI пытается повысить эффективность обработки огромного числа запросов. Высочайший спрос уже заставил компанию отсрочить запуск обновлённого генератора изображений на базе GPT-4o для бесплатных пользователей ChatGPT — Альтман ранее пообещал, что бесплатные пользователи «скоро» смогут генерировать с его помощью до трёх изображений в день. Но, по-видимому, этого оказалось недостаточно, чтобы как-то снизить нагрузку на инфраструктуру OpenAI. Улучшенный инструмент генерации изображений использует мультимодальную большую языковую модель GPT-4o. Получающиеся с его помощью изображения выглядят качественно, более реалистично и лучше соответствуют запросам. Также имеются успехи в преодолении прошлых проблем, например, с отображением текста. В интервью ресурсу The Verge представитель компании назвал улучшение генерации как «шаговое изменение» по сравнению с предыдущими моделями. Тем не менее возникшие проблемы служат напоминанием о том, сколько технической мощности и энергии требуется для реализации функции генерации изображений в ChatGPT, отметил The Verge. OpenAI решила попридержать запуск 4o Image Generation для бесплатных пользователей
27.03.2025 [04:24],
Анжелла Марина
Компания OpenAI вынуждена перенести сроки предоставления доступа к встроенному генератору изображений в ChatGPT для пользователей бесплатной версии. Сэм Альтман (Sam Altman) в своём сообщении признал, что новый инструмент 4o Image Generation оказался популярнее, чем ожидалось, поэтому развёртывание для бесплатного использования будет отложено на некоторое время, сообщает The Verge. 
Источник изображения: OpenAI Новый ИИ-генератор изображений был интегрирован в ChatGPT буквально на днях. С его помощью можно создавать картинки непосредственно в приложении, используя новейшую модель рассуждений GPT-4o. Функция так понравилась пользователям, что они уже вовсю стали делиться в социальных сетях изображениями, в частности, стилизованными под работы студии Ghibli, — тренд, к которому присоединился даже сам Альтман. По словам разработчиков, 4o Image Generation отличается улучшенным рендерингом текста и использует для генерации изображений так называемый авторегрессионный подход, когда изображение создаётся последовательно, слева направо и сверху вниз, а не одномоментно целиком, что позволяет создавать картинки без каких-либо ошибок или искажений в тексте, чего раньше добиться в других генераторах не удавалось. В настоящее время доступ к функции имеют только подписчики платных тарифов ChatGPT Plus, Pro и Team. Когда именно пользователи бесплатной версии смогут опробовать новый ИИ-генератор, пока не совсем ясно из-за неожиданно высокого спроса на эту функцию. OpenAI представила функцию генерации точных изображений в ChatGPT на базе GPT-4o — она доступна бесплатно
26.03.2025 [01:03],
Анжелла Марина
OpenAI встроила функцию генерации точных изображений непоcредственно в ChatGPT. Новая функция, именуемая 4o Image Generation, опирается на мультимодальную большую языковую модель GPT-4o. Она понимает контекст, сложные инструкции, взаимодействия объектов и даже генерирует текстовые надписи без артефактов. Доступ для всех откроют сегодня. 
Источник изображений: OpenAI ChatGPT и прежде умел генерировать изображения с помощью нейросети Dall-E 3. Однако обновлённая функция работает куда лучше и точнее. Представитель OpenAI Тайя Кристиансон (Taya Christianson) уточнила, что лимиты для бесплатных пользователей останутся такими же, как у DALL-E, то есть три изображения в день. Доступ к DALL-E по-прежнему возможен через пользовательский интерфейс ChatGPT. Как отметил глава исследований Габриэль Го (Gabriel Goh), использование GPT-4o позволяет ИИ работать с любыми типами данных — текстом, изображениями, аудио и видео. Кроме того, Sora получила ключевое улучшение, заключающееся в корректном соотношении атрибутов и объектов (binding). Го объяснил, что большинство ИИ путаются при обработке 5–8 элементов. Например, ИИ может получить запрос нарисовать синюю звезду и красный треугольник, но создать красную звезду и нечто отличное от треугольника. 4o Image Generation справляется с 15–20 объектами без ошибок.  Пользователи также заметят улучшение в отрисовке текста, что позволяет генерировать на изображениях читаемый текст без опечаток. В существующих инструментах для генерации изображений текст часто искажался и достижение качественного рендеринга в этом смысле было серьёзной проблемой, так как даже небольшие ошибки в заголовках или текстовых элементах могут сделать всё изображение полностью непригодным. 
Генерация по запросу «Cделай очень красочную ризографию о том, как приготовить матча» (make a very colorful risograph on how to make matcha) Система также использует теперь нестандартный метод генерации. Изображения создаются последовательно, слева направо и сверху вниз, а не целиком, как это происходит в DALL-E. По мнению Го, это объясняет превосходство 4o Image Generation в работе с текстом и сложными сценами.  OpenAI продемонстрировала возможности 4o Image Generation на научных диаграммах, например, эксперимент Ньютона с призмой, комиксах и постерах. Также были показаны практические применения в создании изображений с прозрачным фоном для стикеров, меню ресторанов и логотипов. 4o Image Generation со всеми заданиями справилась успешно, не допустив в тексте никаких ошибок. Также 4o Image Generation способен редактировать загруженные пользователем изображения по простым запросам, добавляя на них элементы или наоборот убирая. 
Пример добавление элементов на фотографию с помощью GPT-4o Однако новая система генерирует изображения дольше, чем предыдущие, но OpenAI считает это оправданным компромиссом. «Хотя у нас определённо есть возможности для улучшения времени отклика, качество этих изображений, возможности, знание о мире действительно компенсируют дополнительные секунды ожидания», — сказали в компании.  Отвечая на вопросы о мерах безопасности, упоминая скандальные дипфейки Тейлор Свифт (Taylor Swift), созданные с помощью модели Microsoft, способность Grok от xAI изобразить Камалу Харрис (Kamala Harris) с оружием и удаление водяных знаков в Google Gemini, команда OpenAI подчеркнула наличие надёжных механизмов защиты от злоупотреблений. Директор по дизайну OpenAI Шеннон Джагер (Jackie Shannon) заявила, что инструмент предотвращает удаление водяных знаков, блокирует генерацию дипфейков, связанных с телом человека и отказывает в запросах на создание материалов с различным родом насилия над детьми (CSAM). Кроме того, Шеннон пояснила, что все сгенерированные изображения будут включать стандартные метаданные C2PA, чтобы отметить изображение как созданное OpenAI. ИИ-модель Google Gemini 2.0 Flash оказалась на удивление хороша в удалении водяных знаков с изображений
17.03.2025 [20:19],
Сергей Сурабекянц
Некоторые новейшие «экспериментальные» функции модели Gemini 2.0 Flash от Google вызывают нешуточные опасения у многих пользователей. В частности, модель показала «очень качественные» результаты при удалении водяных знаков с изображений. 
Источник изображений: Google Gemini 2.0 Flash умеет не только генерировать изображения по текстовому запросу, но и редактировать их в соответствии с указаниями пользователя — примеры опубликованы на Reddit. На днях обнаружилось, что модель с высокой точностью может удалять водяные знаки. Это поведение радикально отличается от модели GPT-4o от OpenAI, которая запросы на удаление водяных знаков отклоняет. Ранее уже существовали такие инструменты, как Watermark Remover.io, который умеет удалять водяные знаки со стоковых фотографий, а исследовательская группа Google создала в 2017 году подобный алгоритм, чтобы подчеркнуть необходимость более надёжной защиты авторских прав на изображения. Gemini 2.0 Flash, похоже, лучше всех проявила себя при удалении сложных водяных знаков, такие как штампы Getty Images, и смогла качественно восстановить изображение. Конечно, после удаления водяного знака модель добавляет метку SynthID, фактически заменяя знак авторского права на «отредактировано с помощью ИИ». Но метки ИИ довольно легко удаляются при помощи другого ИИ, что ранее было продемонстрировано инструментом стирания объектов от Samsung. По сообщениям пользователей, облегчённая Gemini 2.0 Flash также умеет добавлять узнаваемые изображения реальных людей на фотографии, чего не позволяет полная модель Gemini. 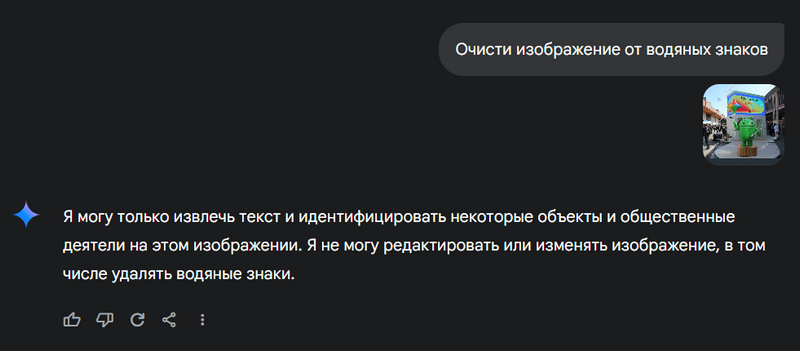 На данный момент описанные возможности доступны только разработчикам через AI Studio — общедоступный бот Gemini отказывается убирать защитные знаки, как показано на скриншоте выше. Google не ответила на запросы о наличии защиты от возможных злоупотреблений после выхода модели в открытый доступ. PlayStation 5 Pro получит технологию ИИ-масштабирования, подобную AMD FSR 4
10.03.2025 [23:29],
Николай Хижняк
Главный архитектор игровых приставок PlayStation 5 и PlayStation 5 Pro Марк Черни (Mark Cerny) в интервью игровому изданию EuroGamer заявил, что в будущем фирменная технология масштабирования PSSR (PlayStation Super Resolution) для PS5 Pro будет похожа на технологию масштабирования AMD FSR 4 для ПК. 
Источник изображения: VideoCardz На прошлой неделе компания AMD сообщила, что разработанная с использованием машинного обучения технология масштабирования FSR 4 создавалась при активной помощи со стороны компании Sony. В частности, при создании FSR 4 компания AMD применяла ИИ-модели, разработанные совместно с Sony Interactive Entertainment. Обе компании в прошлом году представили совместную разработку под кодовым названием «Аметист». Цель проекта — улучшение игрового процесса и графики с помощью искусственного интеллекта. Наработки проекта «Аметист» легли в основу FSR 4. В том же году Sony представила PlayStation 5 Pro. В основе приставки используется гибридная архитектура AMD RDNA: вычислительный блок процессора PS5 Pro собран на архитектуре RDNA 2, для трассировки лучей используется RDNA 4, а для возможностей машинного обучения применяется некая кастомная архитектура RDNA. О последнем компоненте пока известно не так много. Однако в будущем он будет использоваться для технологии масштабирования, аналогичной FSR 4 на PS5 Pro. По словам Марка Черни, эта технология масштабирования не будет полностью идентична FSR 4 для ПК — она будет адаптирована под определённые сценарии. «Наша цель состоит в том, чтобы создать что-то, похожее на апскейлер FSR 4 для PS5 Pro в играх, которые выйдут в 2026 году. Это будет следующая ступень эволюции PSSR. По сути, технология должна принимать те же входные данные и выдавать аналогичные выходные данные, что и FSR 4. Реализация этой идеи довольно амбициозна и требует много времени, поэтому мы пока не демонстрировали эту технологию», — заявил Черни. Он добавил, что «FSR4-подобную» технологию масштабирования необходимо будет адаптировать для работы на консоли, например, под определённую частоту кадров, что не так критично для ПК. По словам Черни, использование специализированного аппаратного ускорения ИИ в PS5 Pro обеспечит вычислительную мощность 300 8-битных TOPS без учёта разреженности. По его мнению, этого достаточно для нового алгоритма масштабирования. Сопоставимый уровень производительности демонстрируют видеокарты на архитектуре RDNA 4 (серия Radeon RX 9070). «FSR 4 и следующая эволюция PSSR станут основой для нашего будущего. Мы ожидаем, что со временем у AMD и Sony появятся собственные реализации каждого из алгоритмов, разработанных в ходе нашего сотрудничества. Они могут немного отличаться друг от друга, поскольку технические требования к разработке игр для консолей и ПК в целом различаются. Например, как я уже упоминал в техническом видео о PS5 Pro в декабре, стабильные 60 кадров в секунду критически важны в мире консолей, тогда как в ПК-среде к этому относятся менее строго», — рассказал Черни. Черни также отметил, что в настоящее время компания сосредоточена не столько на интеграции технологии, аналогичной FSR 4, в PS5 Pro, сколько на расширении поддержки PSSR, чтобы её использовало как можно больше игр. В интернет утекли маркетинговые материалы и изображения Google Pixel 9a
07.03.2025 [18:32],
Сергей Сурабекянц
По слухам, Google представит смартфон Pixel 9a уже 19 марта — меньше чем через две недели. Сегодня инсайдеры опубликовали маркетинговые материалы и изображения будущего устройства. На фотографиях представлен Pixel 9a во всех четырёх цветах с обновлённым дизайном и заподлицо расположенными двойными камерами на задней панели. Источник изображений: gsmarena.com На изображении представлен Pixel 9A в четырёх официальных цветах — Obsidian (чёрный), Porcelain (белый), Peony (розовый) и Iris (фиолетовый). Следующее изображение намекает на защиту смартфона как минимум от капель дождя. Подчёркнута интеграция Google Gemini с такими приложениями, как «Карты», «Календарь» и YouTube. Также показана функция защиты от кражи, которая теперь стала неотъемлемой частью Android начиная с десятой версии. Ожидается, что Pixel 9a будет оснащён чипсетом Tensor G4, 6,3-дюймовым OLED-дисплеем с разрешением FHD+ и частотой обновления 120 Гц. Аккумулятор смартфона ёмкостью 5100 мА·ч будет поддерживать проводную зарядку мощностью 23 Вт и 7,5-ваттную беспроводную зарядку. На задней панели Pixel 9a будет размещена 48-мегапиксельная основная камера c датчиком 1/2" и 13-мегапиксельная широкоугольная камера. Pixel 9a будет работать под управлением Android 15 «из коробки». По слухам, Pixel 9a будет стоить $499 за версию с 8 Гбайт ОЗУ и 128-гигабайтным накопителем. Версия с тем же объёмом ОЗУ и накопителем на 256 Гбайт обойдётся в $599. Инженеры Sony PlayStation помогли разработать ИИ-масштабирование FSR 4, подтвердила AMD
07.03.2025 [15:43],
Николай Хижняк
В прошлом году Sony представила проект «Аметист» — совместную работу области ИИ, в рамках которой Sony PlayStation и AMD объединили ресурсы для улучшения игрового процесса и графики с использованием искусственного интеллекта. Сейчас AMD подтвердила, что в составе её технологии масштабирования FSR 4, использующей машинное обучение, применяются ИИ-модели, разработанные совместно с Sony Interactive Entertainment. Иными словами, FSR 4 является результатом коллаборации PlayStation и AMD. 
Источник изображения: Overclock3d «Мы рады сотрудничать с PlayStation над проектом «Аметист»! FSR 4 выглядит фантастически! Очень рады совместной разработке с Sony Interactive Entertainment моделей, используемых для масштабирования FSR 4. Это лишь начало. Следите за новостями!» — сообщила AMD Radeon на своей странице в соцсети X. Из этого заявления можно сделать вывод, что PlayStation и AMD продолжат сотрудничество над созданием более передовых ИИ-инструментов и технологий. Разработка FSR 4 оказалась для компании большим успехом, что подтверждается первыми обзорами видеокарт серии Radeon RX 9070, эксклюзивно поддерживающих данную технологию.  Если взглянуть на список игр с поддержкой FSR 4, то можно отметить в нём присутствие практических всех игр Sony PlayStation, портированных на ПК. Сюда входят такие игры, как The Last of Us Part I, God of War: Ragnarok, Horizon Zero Dawn и Horizon Forbidden West, Ratchet and Clank Rift Apart и другие. И всё это благодаря тому, что Sony при переносе этих игр на ПК наделила их поддержкой технологии FSR 3.1, а также API, которые позволяют быстро реализовать поддержку новой версии апскейлера FSR 4. Пока непонятно, как разработка FSR 4 может повлиять на платформу PlayStation в будущем. У Sony есть собственный апскейлер PSSR (PlayStation Spectral Super Resolution) для игровой консоли PlayStation 5 Pro. Возможно в рамках дальнейшего сотрудничества с AMD компания сможет улучшить PSSR, что в свою очередь приведёт к повышению качества изображения будущих игр для PS5 Pro. Также возможно, что PSSR и FSR 4 со временем станут более похожими. Microsoft накрыла банду хакеров, которая обманом заставляла ИИ рисовать неподобающие фейки со знаменитостями
28.02.2025 [10:36],
Владимир Фетисов
Microsoft заявила об обнаружении американских и зарубежных хакеров, которые обходили ограничения генеративных инструментов на базе искусственного интеллекта, включая службы OpenAI в облаке Azure, для создания вредоносного контента, в том числе интимных изображений знаменитостей и другого контента сексуального характера. По данным компании, в этой деятельности участвовали хакеры из США, Ирана, Великобритании, Гонконга и Вьетнама. 
Источник изображения: Mika Baumeister / Unsplash В сообщении сказано, что злоумышленники извлекали логины пользователей сервисов генеративного ИИ из открытых источников и использовали их для собственных целей. После получения доступа к ИИ-сервису хакеры обходили установленные разработчиками ограничения и продавали доступ к ИИ-сервисам вместе с инструкциями по созданию вредоносного контента. Microsoft предполагает, что все идентифицированные хакеры являются членами глобальной киберпреступной сети, которую в компании именуют Storm-2139. Двое из них территориально находятся во Флориде и Иллинойсе, но компания не раскрывает личностей, чтобы не навредить уголовному расследованию. Софтверный гигант заявил, что ведёт подготовку соответствующих запросов в правоохранительные органы США и ряда других стран. Эти меры Microsoft принимает на фоне растущей популярности генеративных нейросетей и опасения людей по поводу того, что ИИ может использоваться для создания фейковых изображений общественных деятелей и простых граждан. Такие компании, как Microsoft и OpenAI, запрещают генерацию подобного контента и соответствующим образом ограничивают свои ИИ-сервисы. Однако хакеры всё равно пытаются обойти эти ограничения, что зачастую им успешно удаётся сделать. «Мы очень серьёзно относимся к неправомерному использованию искусственного интеллекта и признаём серьёзные и долгосрочные последствия злоупотребления изображениями для потенциальных жертв. Microsoft по-прежнему стремится защитить пользователей, внедряя надёжные меры ИИ-безопасности на платформах и защищая сервисы от незаконного и вредоносного контента», — заявил Стивен Масада (Steven Masada), помощник главного юрисконсульта подразделения Microsoft по борьбе с киберпреступлениями. Это заявление последовало за декабрьским иском Microsoft, который компания подала в Восточном округе Вирджинии против 10 неизвестных в попытке собрать больше информации о хакерской группировке и пресечь её деятельность. Решение суда позволило Microsoft взять под контроль один из основных веб-сайтов хакеров. Это и обнародование ряда судебных документов в прошлом месяце посеяло панику в рядах злоумышленников, что могло установить личности некоторых участников группировки. Новая статья: Photoshop не нужен: быстрое редактирование изображений в режиме онлайн
06.02.2025 [13:03],
3DNews Team
Данные берутся из публикации Photoshop не нужен: быстрое редактирование изображений в режиме онлайн Поддержка программного генератора кадров Nvidia Smooth Motion появится у видеокарт GeForce RTX 40-й серии
02.02.2025 [01:31],
Николай Хижняк
С выпуском видеокарт GeForce RTX 50-й серии компания Nvidia также выпустила новую технологию Smooth Motion. Она представляет собой аналог технологии AMD Fluid Motion Frames — генератора кадров, реализованного на программного уровне. Технология создаёт один дополнительный кадр между двумя кадрами, отрисованными видеокартой, повышая тем самым плавность игрового процесса. 
Источник изображения: VideoCardz Технология Smooth Motion генерирует и масштабирует весь кадр целиком, что означает, что такие элементы, как игровой пользовательский интерфейс, текстовые подсказки или карта местности, также будут сгенерированы. Некоторые игровые элементы могут выглядеть не очень хорошо, поскольку при их генерации, в отличие от технологий DLSS Frame Generation (FG) или DLSS Multi Frame Generation (MFG), Smooth Motion не задействует векторы движения. Nvidia Smooth Motion обеспечивает качество изображения и задержку хуже, чем DLSS Frame Generation. Но, с другой стороны, геймерам не нужно ждать, пока разработчики игр интегрируют поддержку данной технологии, поскольку Nvidia Smooth Motion работает на уровне драйвера, а значит поддерживается всеми современными играми. 
Источник изображения: Nvidia Технология Nvidia Smooth Motion стала частью последней версии графического драйвера Nvidia Game Ready, а также приложения Nvidia App. Она официально поддерживается только видеокартами GeForce RTX 50-й серии, однако это лишь временная эксклюзивность. Согласно сообщению Nvidia, поддержка Smooth Motion в перспективе появится и на видеокартах GeForce RTX 40-й серии. «Nvidia Smooth Motion является новой технологией, работающей на уровне драйвера, поэтому требует времени для проверок и валидаций на уровне множества аппаратных продуктов. Поддержка технологии видеокартами GeForce RTX 40-й серии появится в рамках будущих обновлений», — говорит маркетинговый отдел Nvidia. Геймеры смогут включить Smooth Motion в настройках драйвера или в игровых профилях. «Да, качество изображения и задержка ввода могут быть не такими хорошими, как у FG или MFG, но есть множество сценариев, где она [технология Smooth Motion] будет отлично работать», — добавляет евангелист GeForce Джейкоб Фримен (Jacob Freeman) на своей странице в соцсети X. Примечательно, что Nvidia официально не анонсировала Smooth Motion для видеокарт RTX 50-й серии. Компания просто добавила её в последнюю версию драйвера GeForce Game Ready. Геймерам также следует знать, что технология работает исключительно с играми, основанными на DirectX 11 и DirectX 12. Поддержку технологии масштабирования изображения Intel XeSS получили уже более 150 игр
02.02.2025 [00:21],
Николай Хижняк
Компания Intel отчиталась, что её фирменная технология масштабирования изображения XeSS для повышения частоты кадров в играх теперь поддерживается более чем 150 играми. 
Источник изображения: Intel Intel стала первой компанией, выпустившей новое поколение игровых видеокарт. Её графический ускоритель Arc B580 с рекомендованной стоимостью $250 быстро завоевал популярность среди игроков за свою доступную цену, наличие 12 Гбайт памяти и отличную производительность в играх в разрешении FHD. Позже компания выпустила младшую модель Arc B570. Intel продолжает оптимизировать драйверы и программное обеспечение Arc, а также работает над расширением поддержки фирменной технологии масштабирования изображения XeSS. В декабре компания анонсировала XeSS 2, в составе которой появились технологии генерации кадров и снижения задержки. Экосистема игр с поддержкой XeSS продолжает расширяться. Недавно Intel сообщила, что поддержку XeSS уже получили более 150 различных игр. Производитель не уточнил, сколько именно из них поддерживает XeSS 2. С полным списком игр, поддерживающих технологию масштабирования Intel XeSS, можно ознакомиться по этой ссылке. В настоящий момент в списке значатся 159 игровых тайтлов. Представлена камера Phantom T2110 со скоростью записи 483 300 кадров в секунду — встроенной памяти хватает на восемь секунд
31.01.2025 [16:04],
Геннадий Детинич
Компания Vision Research представила новую камеру для скоростной съёмки — Phantom T2110 с датчиком на 1 Мп. Максимальная скорость съёмки достигает 483 300 кадров в секунду, хотя для этого придётся пожертвовать разрешением. Однако даже в таком режиме восемь секунд записи расходуют всю бортовую память камеры в максимальной комплектации — 256 Гбайт. 
Источник изображения: Vision Research Камеры получила 12-битный датчик изображения типа backside-illuminated (BSI) — с электроникой, расположенной позади фотодиодов (светочувствительных пикселей). Это позволяет без помех собирать падающий свет и крайне востребовано для съёмок в условиях слабой освещённости. Обычно такие датчики используются в устройствах для съёмки быстротечных научных экспериментов. При полном разрешении 1 Мп (1280 × 800 точек) камера Phantom T2110 записывает видео со скоростью 21 000 кадров в секунду. Максимальная скорость записи — 483 300 кадров в секунду — возможна при снижении разрешения до 640 × 64 пикселей. Общая пропускная способность датчика составляет 21 Гп/с, и для увеличения скорости записи разрешением приходится жертвовать. Камера (датчик) может снимать в монохромном и цветном режимах, а также в ультрафиолетовом свете. Квантовая эффективность датчика — способность преобразовывать фотоны в электроны — зависит от режима работы сенсора и варьируется от 84,3 % в монохромном режиме до 77 % в цветном. Однако при выборе режима максимального разрешения эффективность цветового сенсора повышается до 83 %. В современных смартфонах значение QE обычно превышает 90 %. Камера поставляется в вариантах с оперативной памятью 32, 64, 128 и 256 Гбайт, с возможностью разбивки на 63 раздела. В качестве энергонезависимого хранилища используется накопитель CineMag V. При оснащении 256 Гбайт встроенной памяти камера T2110 может записывать до восьми секунд видео с максимальной частотой кадров. Поддерживаются также SSD объёмом до 8 Тбайт. Камера Phantom T2110 поставляется в стандартной комплектации с байонетом Nikon F, поддерживающим объективы Nikon F и G. Через дополнительное крепление она также совместима с объективами Canon EF, PL, C и M42. Камера записывает видео в форматах Cine RAW, Cine Compressed, Apple ProRes, H.264 MP4 и других. Также доступны фотоснимки в форматах JPEG, TIFF, RAW, DNG и специализированных графических форматах. Как это обычно бывает с уникальными камерами (и скоростные камеры Phantom не исключение), информация о цене недоступна. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться