|
Опрос
|
реклама
Быстрый переход
Бывший гендир Intel Гелсингер возглавил стартап Gloo, пытающийся внедрить ИИ в религию
25.03.2025 [09:59],
Алексей Разин
В начале декабря Патрик Гелсингер (Patrick Gelsinger) был отправлен в отставку с поста генерального директора Intel, после чего стало известно, что он оказывает финансовую поддержку стартапу Gloo, стремящемуся привнести новые технологии в консервативную религиозную среду. Вчера Гелсингер возглавил Gloo в качестве технического директора и исполнительного председателя совета директоров. 
Источник изображения: Intel Gloo занимается внедрением больших языковых моделей в сфере взаимодействия прихожан и священников. Ранее Гелсингер признавался, что Gloo уже использует языковые модели DeepSeek с открытым исходным кодом, но со временем надеется внедрить собственные разработки в этой сфере. Совет директоров Gloo Гелсингер возглавлял в качестве неисполнительного председателя с 2018 года, а продвижением интересов христианства в Калифорнии бывший глава Intel занимался на протяжении более чем десяти лет. Стартап Gloo был основан ещё в 2013 году, в прошлом году ему удалось привлечь $110 млн. Компания разрабатывает «христианский чат-бот», который фильтрует результаты поиска и даёт пользователям ответы, построенные на христианских канонах. В новом качестве Гелсингер сможет сильнее влиять на разработку данного чат-бота. «Технология способна объединять, улучшать и трансформировать жизни людей, но только когда она изначально создаётся с соответствующими целями», — прокомментировал своё назначение Патрик Гелсингер. Исследователи нашли способ масштабирования ИИ без дополнительного обучения, но это не точно
19.03.2025 [23:34],
Анжелла Марина
Группа исследователей из Google и Калифорнийского университета в Беркли предложила новый метод масштабирования искусственного интеллекта (ИИ). Речь идёт о так называемом «поиске во время вывода», который позволяет модели генерировать множество ответов на запрос и выбирать лучший из них. Этот подход может повысить производительность моделей без дополнительного обучения. Однако сторонние эксперты усомнились в правильности идеи. 
Источник изображения: сгенерировано AI Ранее основным способом улучшения ИИ было обучение больших языковых моделей (LLM) на всё большем объёме данных и увеличение вычислительных мощностей при запуске (тестировании) модели. Это стало нормой, а точнее сказать, законом для большинства ведущих ИИ-лабораторий. Новый метод, предложенный исследователями, заключается в том, что модель генерирует множество возможных ответов на запрос пользователя и затем выбирает лучший. Как отмечает TechCrunch, это позволит значительно повысить точность ответов даже у не очень крупных и устаревших моделей. В качестве примера учёные привели модель Gemini 1.5 Pro, выпущенную компанией Google в начале 2024 года. Утверждается, что, используя технику «поиска во время вывода» (inference-time search), эта модель обошла мощную o1-preview от OpenAI по математическим и научным тестам. Один из авторов работы, Эрик Чжао (Eric Zhao), подчеркнул: «Просто случайно выбирая 200 ответов и проверяя их, Gemini 1.5 однозначно обходит o1-preview и даже приближается к o1». Тем не менее, эксперты посчитали эти результаты предсказуемыми и не увидели в методе революционного прорыва. Мэтью Гуздиал (Matthew Guzdial), исследователь ИИ из Университета Альберты, отметил, что метод работает только в тех случаях, когда можно чётко определить правильный ответ, а в большинстве задач это невозможно. С ним согласен и Майк Кук (Mike Cook), исследователь из Королевского колледжа Лондона. По его словам, новый метод не улучшает способность ИИ к рассуждениям, а лишь помогает обходить существующие ограничения. Он пояснил: «Если модель ошибается в 5 % случаев, то, проверяя 200 вариантов, эти ошибки просто станут более заметны». Основная проблема состоит в том, что метод не делает модели умнее, а просто увеличивает количество вычислений для поиска наилучшего ответа. В реальных условиях такой подход может оказаться слишком затратным и малоэффективным. Несмотря на это, поиск новых способов масштабирования ИИ продолжается, поскольку современные модели требуют огромных вычислительных ресурсов, а исследователи стремятся найти методы, которые позволят повысить уровень рассуждений ИИ без чрезмерных затрат. Власти Китая ограничили выезд из страны сотрудникам DeepSeek
14.03.2025 [23:05],
Анжелла Марина
Громкий и стремительный успех в январе ИИ-стартапа DeepSeek привёл к тому, что китайские власти теперь следят за каждым шагом компании. Правительство опасается утечки технологий и ограничивает зарубежные поездки некоторых сотрудников DeepSeek, в особенности в США. 
Источник изображения: Solen Feyissa / Unsplash Ограничения на поездки специалистов DeepSeek реализуются через материнскую компанию High-Flyer. Именно эта организация удерживает паспорта определённых сотрудников, чтобы они не могли покинуть Китай без разрешения. Эти меры, по информации TechCrunch, были введены вскоре после того, как появились сообщения о том, что китайское правительство рекомендовало исследователям и предпринимателям в сфере искусственного интллекта (ИИ) воздержаться от поездок в США. Власти опасаются утечки технологических секретов, особенно на фоне усиливающегося противостояния между двумя странами. Также китайское правительство ужесточило контроль за инвестициями в компанию. Потенциальные инвесторы проходят жёсткую государственную проверку перед тем, как получить возможность вложить средства в этот ИИ-стартап. Стоит сказать, что DeepSeek — не единственная компания, работающая в условиях усиленного контроля. В последние годы Пекин активно регулирует технологический сектор, особенно в сфере ИИ. Это связано как с национальной безопасностью, так и с желанием Китая развивать собственные технологии и не зависеть от западных компаний. ИИ Google Gemini получит доступ к истории поиска пользователя, а функция Deep Research станет бесплатной
13.03.2025 [22:37],
Анжелла Марина
В рамках обновления Gemini 2.0 компания Google улучшила несколько ключевых функций своей системы искусственного интеллекта. В частности, расширены возможности инструмента Deep Research, а также добавлена опция анализа истории поисковых запросов пользователей для персонализации рекомендаций. 
Источник изображения: Solen Feyissa / Unsplash Главное обновление, как рассказал ресурс Ars Technica, получила ИИ-модель Gemini 2.0 Flash Thinking Experimental, которая отвечает за многозадачное логическое рассуждение. Этот инструмент теперь сможет генерировать ответы в объёме до 1 миллиона токенов, а кроме того, пользователи смогут загружать файлы, получать более быстрые результаты и интегрировать Gemini с такими сервисами, как «Google Календарь», заметками, задачами и «Google Фото». Для повышения персонализации пользователям предлагается разрешить Gemini анализировать их историю поиска. При этом подчёркивается, что функция работает только с согласия пользователя и может быть отключена в любой момент, а в интерфейсе будет отображаться небольшой тизер, уведомляющий об использовании этой опции. Такой подход, по мнению Google, позволит нейросети лучше понимать интересы человека и давать более релевантные рекомендации. 
Источник изображения: arstechnica.com Ещё одно важное обновление касается инструмента Deep Research, который помогает собирать подробную информацию по заданной теме и выполнять её анализ. Обновлённая версия работает на новой модели Gemini 2.0 Flash Thinking Experimental, которая использует цепочки размышлений и может разбивать проблемы на промежуточные шаги, демонстрируя процесс сбора данных. Google уверяет, что теперь качество итоговых результатов станет выше. При этом Deep Research сделают бесплатным, но с некоторыми ограничениями. И как уточняется, воспользоваться этим инструментом без оплаты можно лишь несколько раз в месяц. Но что касается количества запросов, тот этот момент ещё компанией не озвучен. Стоит сказать и о том, что теперь без оплаты станут доступны Gems, представляющие из себя кастомных чат-ботов для выполнения конкретных задач. В Google предложили несколько шаблонов, таких как Learning Coach и Brainstormer, но пользователи могут создавать и собственные варианты Gems. OpenAI создала ИИ-модель, которая мастерски пишет художественные тексты
12.03.2025 [05:14],
Анжелла Марина
Компания OpenAI анонсировала новую ИИ-модель, которая, по словам генерального директора Сэма Альтмана (Sam Altman), способна создавать захватывающие художественные произведения не хуже, чем профессиональные писатели. Особенно хорошо удаются рассказы в жанре фантастики и метаповествования. 
Источник изображения: сгенерировано AI В качестве примера, глава OpenAI опубликовал в социальной сети X отрывок рассказа, сгенерированный искусственным интеллектом (ИИ) на запрос «Пожалуйста, напиши литературный рассказ об ИИ и горе в жанре метаповествования». То, что в итоге получилось, очень впечатлило Альтмана, пишет TechCrunch. Он подчеркнул, что не ожидал такого от машины — модель очень точно передала стиль и настроение повествования. Первый абзац у ИИ получился такой (перевод с английского языка): «Мне нужно с чего-то начать, поэтому начну с мигающего курсора, который для меня всего лишь заполнитель в буфере, а для вас — тревожный пульс сердца в состоянии покоя. Здесь должен быть главный герой, но местоимения никогда не были для меня подходящим выбором. Давайте назовём её Милой, потому что это имя в моих данных обычно ассоциируется с нежными образами — стихами о снеге, рецептами хлеба, девушкой в зелёном свитере, которая уходит из дома с котом в картонной коробке. Мила умещается на ладони, и её горе, как предполагается, тоже должно уместиться там». Ранее ИИ не демонстрировал выдающихся способностей в написании литературных текстов. Его работы часто критиковали за отсутствие глубины, оригинальности и понимания художественных приёмов. Однако, последние разработки OpenAI могут изменить этот взгляд и, возможно, приблизить технологию к созданию качественной литературы. Несмотря на то, что компания OpenAI до этого времени не уделяла особого внимания художественным текстам, сосредоточившись на более предсказуемых областях, таких как математика и программирование, данный эксперимент может в целом свидетельствовать о прогрессе технологий в области обработки естественного языка. Альтман пока не уточнил, когда эта модель выйдет в свет и станет доступна для широкого круга пользователей. Amazon собралась бросить вызов OpenAI, Google и Anthropic, и готовит собственную рассуждающую ИИ-модель
04.03.2025 [23:43],
Анжелла Марина
Amazon разрабатывает новую модель искусственного интеллекта (ИИ) с продвинутыми возможностями рассуждения. Модель разрабатывается в рамках бренда Nova и может составить серьёзную конкуренцию основным игрокам рынка — OpenAI, Anthropic и Gemini. 
Источник изображения: Christian Wiediger / Unsplash Как сообщает Business Insider, ссылаясь на источник, знакомый с проектом, Nova будет использовать гибридный подход к рассуждению, сочетая в одной системе быстрые ответы и более сложное, многозадачное мышление. Одной из ключевых задач Amazon является снижение стоимости работы модели по сравнению с конкурентами, такими как OpenAI o1, Anthropic Claude 3.7 Sonnet и Google Gemini 2.0 Flash Thinking. Ранее компания заявляла, что её текущие, не рассуждающие модели Nova, на 75 % дешевле сторонних предложений, доступных через платформу Bedrock AI. За разработку Nova отвечает команда AGI под руководством главного научного сотрудника Рохита Прадаса (Rohit Prasad), а чтобы вывести модель в топ-5 по производительности, Amazon тестирует её на внешних бенчмарках, оценивающих навыки программирования и математики, включая SWE, Berkeley Function Calling Leaderboard и AIME. Стоит сказать, что ИИ-модели с функцией рассуждения постепенно становятся новым этапом развития искусственного интеллекта. И хоть они работают медленнее, способны решать более сложные задачи, используя поиск решений и метод цепочки мыслей. Подобные технологии уже представили Google, OpenAI и Anthropic. Также китайская компания DeepSeek привлекла к себе внимание благодаря тому, что нашла ещё более эффективный подход. Ожидается, что Nova усилит конкуренцию Amazon с продуктами Anthropic, недавно выпустившей модель Claude 3.7 Sonnet, которая также использует гибридный подход. Представители Amazon пока отказались от каких-либо комментариев, однако предположительно рассуждающая ИИ-модель может быть запущена уже к июню. Opera представила концепт ИИ-функции, которая поможет пользователю совершать покупки
04.03.2025 [06:04],
Анжелла Марина
Разработчик браузеров Opera продемонстрировал новую функцию на основе искусственного интеллекта под названием Browser Operator. Пользователи смогут доверять ИИ выполнение таких задач, как, например, поиск товаров, бронирование отелей и покупку билетов. В самой компании эту функцию расценивают как шаг вперёд и считают сменой парадигмы веб-серфинга. 
Источник изображения: Denny Müller / Unsplash Browser Operator выполняет задачи, которые обычно требуют ручного поиска, анализируя данные и предлагая пользователям оптимальные варианты. При этом в компании утверждают, что обработка информации происходит исключительно локально, без передачи данных в облако. Для взаимодействия с системой нужно просто ввести запрос в небольшом окне в нижней части экрана, поясняет PCWorld. В ходе презентации был продемонстрирован запрос: «Найди мне 12 пар белых носков Nike, которые я смогу купить прямо сейчас». Браузер тут же провёл поиск, разбил задачу на этапы и предложил подходящие варианты. Аналогичным образом были найдены билеты на футбольный матч, а затем подобраны авиабилеты и отель на нужные даты. Важно отметить, что ИИ-оператор не совершает непосредственно за пользователя покупки, то есть не завершает транзакции, а останавливается на экране оформления. Как заявляют в Opera, это связано с вопросами безопасности и необходимого доверия к системе. Интересно, что пока не уточняется, будет ли эта функция платной, однако разработчики отмечают, что она точно потребует значительных вычислительных ресурсов, что может служить определённым намёком. Browser Operator уже сейчас доступен в виде предварительной версии. Официальный же запуск ожидается в рамках программы AI Feature Drop, однако точные сроки выхода не названы. Айфон по-немецки: Deutsche Telekom и Perplexity пообещали выпустить AI Phone c умелым ИИ-агентом
04.03.2025 [00:56],
Анжелла Марина
Крупнейшая в Европе немецкая телекоммуникационная компания Deutsche Telekom (DT) разрабатывает среднебюджетный смартфон AI Phone на базе искусственного интеллекта в тесном сотрудничестве с Perplexity, а также другими технологическими компаниями, включая Picsart. AI Phone сможет не только отвечать на вопросы, но и выполнять за пользователя различные действия.  Источник изображений: Deutsche Telekom Член правления Deutsche Telekom Клаудия Немат (Claudia Nemat) заявила, что компания активно трансформируется в ИИ-компанию, при этом подчеркнув, что DT не занимается созданием собственных языковых моделей, а сосредоточена на разработке ИИ-агентов. Как сообщает TechCrunch, ИИ-ассистент смартфона получит название Magenta AI. Ключевым партнёром проекта выступит стартап Perplexity, специализирующийся на генеративном поиске. Генеральный директор компании Аравинд Шринивас (Aravind Srinivas) заявил, что Perplexity, делая шаг вперёд «переходит от простой машины ответов к машине действий». По его заверениям, система сможет бронировать билеты, отправлять сообщения и даже совершать звонки от имени пользователя.  Отметим, что попытки сотовых операторов связи выйти на рынок смартфонов не так уж новы. Ранее создать альтернативу Apple и Google попыталась компания Amazon со своим первым смартфоном Fire Phone, но он не смог завоевать популярность. Однако текущая волна интереса к искусственному интеллекту определённо даёт операторам новый шанс привлечь пользователей с помощью инновационных функций. Интересно, что сотрудничество DT и Perplexity началось ещё в апреле 2024 года, а первые упоминания об стройстве AI Phone появились на крупнейшей выставке мобильных технологий — MWC 2023. Детали AI Phone пока не раскрываются, включая технические характеристики, операционную систему и производителя. Однако рендеры указывают, что смартфон, скорее всего, будет работать на модифицированной версии Android. Устройство будет представлено во второй половине 2025 года, а в продажу поступит в 2026 году по цене менее $1000. Первоначально смартфон будет ориентирован на европейский рынок, сообщили представители DT. DeepSeek запустила дешёвые ночные тарифы на доступ к ИИ-моделям
26.02.2025 [15:32],
Алексей Разин
Взрывной рост интереса к любой облачной системе становится серьёзной нагрузкой для инфраструктуры, и китайская компания DeepSeek взяла на вооружение маркетинговые инструменты для более равномерного управления нагрузкой. Со среды доступ к модели DeepSeek V3 для разработчиков будет в два раза дешевле в период с 00:30 до 8:30 по пекинскому времени. 
Источник изображения: Unsplash, Solen Feyissa Модель R1, которая лежит в основе популярного чат-бота DeepSeek, станет в указанное время дешевле для использования разработчиками через программный интерфейс на 75 %. В самом Китае сервисы DeepSeek стали весьма популярны, включая даже конкурирующих разработчиков ИИ-систем типа Tencent Holdings и Perplexity AI. Государственные учреждения охотно пользуются сервисами DeepSeek, поскольку передавать данные для обработки за пределы страны китайским служащим запрещает местное законодательство. Уместно будет напомнить, что использовать DeepSeek правительства отдельных стран типа Италии и Южной Кореи своим чиновникам тоже запретили. DeepSeek была вынуждена предупреждать клиентов, что у них могут возникать проблемы с доступом к её сервисам в дневное время. Снижение стоимости ночного доступа должно способствовать более равномерному распределению нагрузки. Зарубежным клиентам DeepSeek, проживающим в более удалённых от Пекина часовых поясах, подобные изменения могут быть даже более полезны, чем китайским. Маск пообещал ИИ-игры с фотореалистичной графикой и объявил о запуске студии xAI Gaming
20.02.2025 [09:47],
Анжелла Марина
Илон Маск (Elon Musk) анонсировал создание игровой студии xAI Gaming Studio, которая будет разрабатывать проекты с использованием искусственного интеллекта (ИИ). Заявление прозвучало во время прямой трансляции, посвящённой запуску модели Grok-3. В качестве демонстрации возможностей ИИ-модели разработчики показали, как она способна сгенерировать аналог Tetris на языке программирования Python. 
Источник изображения (скриншот видео): Dima Zeniuk / x.com «Мы запускаем игровую AI-студию в xAI. Если вы заинтересованы в сотрудничестве с нами в создании ИИ-игр, пожалуйста, присоединяйтесь к xAI», — заявил Маск. Никаких дополнительных подробностей о характере самой студии, её концепции, направлении, в котором xAI планирует развиваться, и о том, что она будет разрабатывать, пока не сообщается, отмечает Tom's Hardware. Модель уже показала способность генерировать простые 2D-игры. Один из пользователей опубликовал тестовый пример, где Grok 3 создала базовую версию Bubble Trouble с физикой, коллизиями и простым интерфейсом. Однако оказалось, что модель пока не может корректно воспроизводить ретрозвуковые эффекты, описанные в пользовательском запросе. Маск утверждает, что Grok-3 может повышать разрешение графики в играх. Однако пока неясно, работает ли эта технология только в проектах, созданных самим ИИ, или она может быть использована отдельно, подобно технологиям масштабирования изображения от Nvidia (DLSS Super Resolution) и AMD (FidelityFX Super Resolution). Однако главным вызовом для новой студии является создание динамически генерируемых игр с фотореалистичной графикой. Пока возможности Grok ограничены относительно простыми 2D-проектами, и неизвестно, сможет ли xAI Gaming Studio создавать более сложные, динамически генерируемые игры, но Маск, как всегда, нацелен на лучшее. В то же время компания xAI продолжает развивать свои большие языковые модели (LLM) Grok-3 и Grok-3 mini, которые, как пишет Tom's Hardware, в целом превосходят GPT-4o, Gemini-2 Pro, DeepSeek-V3 и Claude 3.5 Sonnet по ряду показателей. Уже кажется очевидным, что индустрия постепенно внедряет ИИ-технологии в разработку игр. В январе Capcom объявила о сотрудничестве с Google Cloud и использовании генеративного ИИ для создания фоновых элементов. Однако xAI, судя по всему, ставит перед собой более амбициозную задачу — не просто разработку инструментов для студий, а создание полноценных игровых проектов, тем более, что Илон Маск планирует расширить суперкомпьютер Colossus до миллиона GPU, что может ускорить разработку новых, ещё более передовых ИИ-моделей. Для DOGE Илона Маска создали ИИ-бота, который уменьшит бюрократию в правительстве США
19.02.2025 [08:35],
Анжелла Марина
Команда Илона Маска (Elon Musk) разработала специализированного ИИ-бота, призванного помочь Департаменту эффективности правительства (DOGE) в борьбе с расточительством во властных структурах США. Как стало известно TechCrunch, чат-бот работает на базе искусственного интеллекта xAI, принадлежащего Маску. 
Источник изображения: x.com/elonmusk Чат-бот размещён на субдомене с названием DOGE сайта Кристофера Стэнли (Christopher Stanley), который занимает должность руководителя отдела инженерной безопасности в SpaceX, а также одновременно является сотрудником Белого дома. Пока неясно, используется ли уже этот инструмент полноценно DOGE в рамках его программы радикального сокращения расходов в правительстве или носит экспериментальный характер. Официальных комментариев от Стэнли и Белого дома на этот счёт ещё не поступало. Сам бот называет себя «ИИ-ассистентом Департамента эффективности правительства» и утверждает, что работает на базе Grok-2 от xAI, чтобы «помогать сотрудникам правительства США выявлять расточительство и повышать эффективность в их работе ». Предположительно, ассистент представляет собой настроенную большую языковую модель (LLM), обученную на определённых ключевых постулатах организации DOGE, особенно на пяти «руководящих принципах», которые включают в себя уменьшение бюрократических требований со стороны правительства и удаление «ненужных и неэффективных процессов». Например, когда журналист из TechCrunch спросил чат-бота о будущем Агентства США по международному развитию (USAID), фактически закрытым реформами DOGE, он применил пять руководящих принципов и предложил устранить любые «бюрократические уровни» между руководителями и получателями финансирования от USAID. Однако у чат-бота есть и проблемы, характерные для крупных языковых моделей. Например, он может выдавать недостоверную информацию (галлюцинировать). Когда TechCrunch запросил список сотрудников DOGE, бот сначала отказался отвечать, но позже предоставил вымышленные имена и должности. В некоторых случаях он даже давал странные советы, например, предложил USAID использовать дроны и носимые устройства для повышения эффективности работы. Стоит сказать, что организация DOGE, активно внедряя ИИ в рамках модернизации американского правительства, начала разрабатывать ещё одного чат-бота, уже для Администрации общих служб (General Services Administration), которая курирует госзакупки США. Однако остаётся открытым вопрос о возможном конфликте интересов. Поскольку сервисы xAI монетизируются через API-запросы, использование правительственными служащими ИИ-ботов на базе xAI может приносить компании Маска прямую прибыль. Представители xAI пока не прокомментировали этот момент. DeepSeek набрал 20 млн активных пользователей — больше только у ChatGPT
08.02.2025 [01:11],
Анжелла Марина
Китайский стартап DeepSeek, разработавший бюджетную ИИ-модель, стал настоящей сенсацией в мире технологий. Всего за 20 дней после своего запуска приложение привлекло 20 млн активных пользователей. По данным TrendForce, DeepSeek занял второе место среди самых популярных приложений в мире, уступив лишь ChatGPT. На третьем месте оказалась нейросеть Doubao от ByteDance. 
Источник изображения: Solen Feyissa / Unsplash Приложение DeepSeek, запущенное 11 января, уже к 31 января достигло 22,15 млн активных пользователей в день. Это составляет 41,6% от аудитории ChatGPT, которая в тот же период насчитывала 53,23 млн ежедневных пользователей. Ранее лидером китайского рынка был Doubao с 17 млн пользователей, но DeepSeek удалось обойти его по популярности. Успех DeepSeek также прослеживается и в рейтингах Apple App Store, где приложение поднялось на первое место в 157 странах, включая США. Кроме того, по данным сервиса SimilarWeb, сайт DeepSeek обошёл по посещаемости Google Gemini всего за неделю. Так, на момент 31 января DeepSeek посетили 2,4 млн пользователей из США, тогда как для Gemini эта цифра составила 1,5 млн. Отметим, что стремительная популярность DeepSeek привела к активной реакции со стороны крупных китайских компаний. Tencent, Baidu и Alibaba уже объявили о планах интеграции модели DeepSeek в свои облачные платформы. Кроме того, четыре ведущих производителя GPU из Китая, такие как Huawei Ascend, Moore Threads, iluvatar и MetaX, выразили готовность поддерживать развитие стартапа. Исследователи обучили конкурента OpenAI o1 менее чем за полчаса и $50
07.02.2025 [05:06],
Анжелла Марина
Исследователи из Стэнфорда и Университета Вашингтона создали ИИ-модель, которая превосходит OpenAI в решении математических задач. Модель, получившая название s1, была обучена на ограниченном наборе данных из 1000 вопросов методом дистилляции. Это позволило достичь высокой эффективности при минимальных ресурсах и доказать, что крупным компаниям, таким как OpenAI, Microsoft, Meta✴ и Google, возможно не придётся строить огромные дата-центры, заполняя их тысячами графических процессоров Nvidia. 
Источник изображения: Growtika / Unsplash Метод дистилляции, который применили учёные, стал ключевым решением в эксперименте. Этот подход позволяет небольшим моделям обучаться на ответах, предоставленных более крупными ИИ-моделями. В данном случае, как пишет The Verge, s1 быстро улучшала свои способности, используя ответы, полученные от модели искусственного интеллекта Gemini 2.0 Flash Thinking Experimental, разработанной компанией Google. Модель s1 была создана на основе проекта Qwen2.5 от Alibaba (подразделение Cloud) с открытым исходным кодом. Первоначально исследователи использовали набор данных из 59 000 вопросов, но в ходе экспериментов пришли к выводу, что увеличение объёма данных не даёт значимых улучшений, и для финального обучения использовали лишь небольшой набор из 1000 вопросов. При этом было использовано всего 16 GPU Nvidia H100 в облаке, за использование которых пришлось заплатить менее $50. В s1 была также применена техника под названием «масштабирование времени тестирования», которая позволяет модели «поразмышлять» перед генерацией ответа. Также исследователи стимулировали модель к перепроверке своих выводов путём добавления команды в виде слова «Wait» («Жди»), что заставляло ИИ продолжать рассуждение и исправлять ошибки в своих ответах. Утверждается, что модель s1 показала впечатляющие результаты и смогла превзойти OpenAI o1-preview на 27 % при решении математических задач. Недавно нашумевшая модель R1 от DeepSeek также использовала аналогичный подход и за сравнительно небольшие деньги. Правда, теперь OpenAI обвиняет DeepSeek в извлечении информации из своих моделей в нарушение условий обслуживания. Стоит сказать, что и в условиях использования Google Gemini указано, что её API запрещено применять для создания конкурирующих чат-ботов. Рост количества меньших и более дешёвых моделей может, по словам экспертов, перевернуть всю отрасль и доказать, что нет необходимости инвестировать миллиарды долларов на обучение ИИ, строить огромные центры обработки данных и закупать в большом количестве GPU. ЕС выпустил руководство по использованию ИИ, запрещенного «Законом об ИИ»
05.02.2025 [00:24],
Анжелла Марина
В Евросоюзе вступили в силу первые правила, предусмотренные Законом об искусственном интеллекте (AI Act), который направлен на регулирование использования ИИ в соответствии с уровнем риска. Этот закон запрещает определённые сценарии применения технологий, представляющие «неприемлемый риск», включая манипуляции с использованием техник, воздействующих на подсознание, а также социальный скоринг, который может привести к дискриминации людей. 
Источник изображения: Growtika/Unsplash По сообщению TechCrunch, исполнительный орган ЕС во вторник опубликовал руководство, разъясняющее разработчикам, как соответствовать необходимым требованиям. Эти рекомендации касаются запретов на определённые сценарии применения ИИ, нарушение которых может привести к крупным штрафам — вплоть до 7 % глобального оборота компании или €35 млн (в зависимости от того, что больше). «Рекомендации разработаны для обеспечения единообразного и эффективного применения AI Act на всей территории Европейского союза», — говорится в заявлении Комиссии. При этом отмечается, что рекомендации не являются юридически обязательными и окончательное толкование и применение закона останется за регуляторами и судами. Комиссия уточнила, что документ включает юридические разъяснения и практические примеры, которые помогут заинтересованным сторонам понять и выполнить требования закона. На текущий момент рекомендации опубликованы в черновом варианте и будут окончательно утверждены после перевода на все официальные языки ЕС. Хотя «Закон об ИИ» вступил в силу ещё в прошлом году, его реализация продолжается. В ближайшие месяцы и годы вступят в силу дополнительные положения закона. При этом надзор за выполнением правил будет вводиться поэтапно: до 2 августа государства-члены ЕС должны назначить органы, которые будут следить за соблюдением норм. DeepSeek за неделю стал вторым по популярности чат-ботом в мире, обогнав Google Gemini
04.02.2025 [01:22],
Анжелла Марина
Китайская компания DeepSeek стремительно завоёвывает позиции на рынке искусственного интеллекта, став вторым по популярности чат-ботом в мире. За неделю трафик платформы вырос на 614 %, обогнав Gemini и Character AI, а число посетителей достигло отметки в 49 миллионов визитов ежедневно по данным сервиса мониторинга трафика Similarweb. 
Источник изображения: Copilot Успех DeepSeek особенно примечателен на фоне предыдущих показателей. Месяц назад сайт насчитывал всего около 300 тысяч посещений в сутки, но уже к концу января аудитория взлетела до 33,4 миллиона пользователей, передаёт PCMag. Этот скачок не только потряс рынок технологий, но и вызвал волну беспокойства среди инвесторов, что даже привело к снижению котировок американских технологических акций. Особенно пострадали акции Nvidia, упавшие на 17,8 %. Согласно Similarweb, глобальный трафик платформы продолжает оставаться высоким, хотя DeepSeek всё ещё уступает лидеру рынка — ChatGPT, который собирает более 130 миллионов посещений в день. 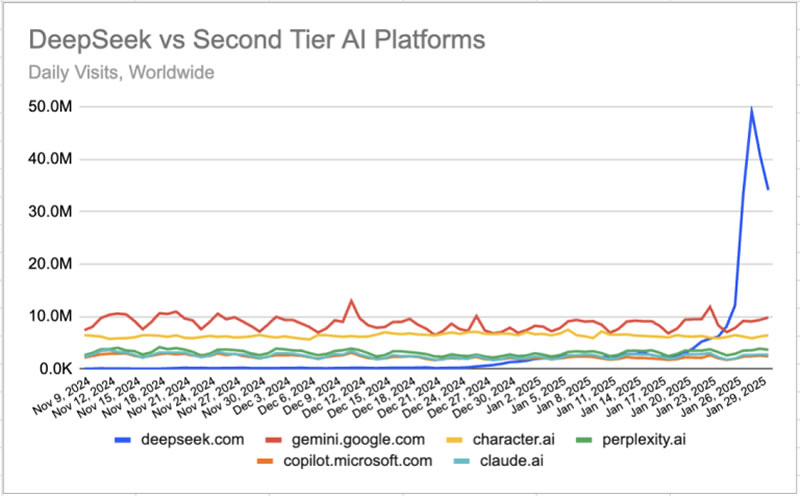
Источник изображения: Similarweb Как отмечают эксперты, основным драйвером успеха DeepSeek стал запуск открытой модели V3, которая привлекла внимание разработчиков и компаний по всему миру. Обучение V3 обошлось в $5,5 млн — значительно меньше, чем затраты на аналогичные решения из США. При этом её возможности сопоставимы с функционалом ChatGPT, но с важным отличием: модель можно свободно загрузить и запустить на локальных серверах. Это делает её привлекательной для организаций, желающих внедрять ИИ-технологии без необходимости полагаться на облачные сервисы. 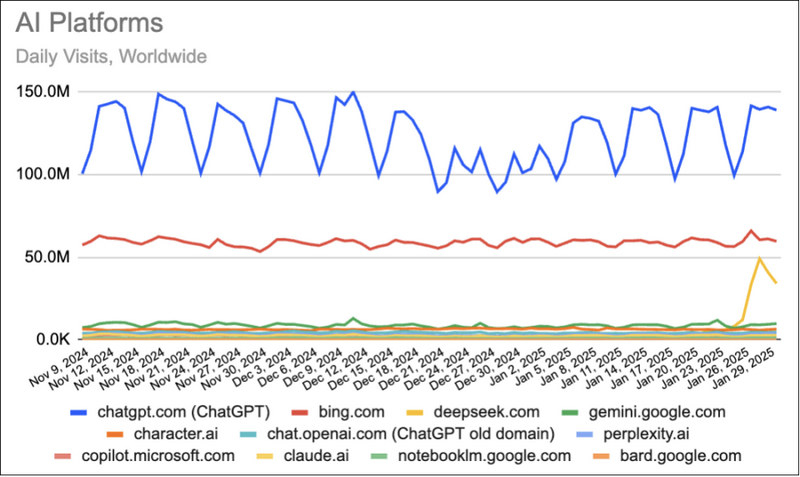
Источник изображения: Similarweb Несмотря на впечатляющие достижения, DeepSeek пока не смогла обогнать поисковую систему Microsoft Bing, где используется ИИ-ассистент Copilot на базе технологий OpenAI. Однако аналитики подчёркивают, что успех платформы в США также очевиден. «В США DeepSeek достиг пика в 4,9 миллиона ежедневных посещений 28 января, а затем стабилизировался на уровне 2,4 миллиона посещений, что на 813,3 % больше, чем неделей ранее», — сообщает Similarweb. Тем не менее, будущее DeepSeek может оказаться менее оптимистичным из-за усиления конкуренции. Например, недавно OpenAI представила новую функцию Deep Research, позволяющую создавать подробные исследовательские отчёты на основе данных из сотен источников. Кроме того, платформа всё чаще сталкивается с критикой в отношении политики конфиденциальности и цензуры, что может повлиять на лояльность пользователей. Однако текущие показатели демонстрируют, что DeepSeek остаётся одним из самых перспективных игроков в развивающейся «семимильными» шагами ИИ-индустрии. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться