|
Опрос
|
реклама
Быстрый переход
Proton выпустила ИИ-помощника для электронной почты, который работает на компьютере пользователя
20.07.2024 [13:00],
Анжелла Марина
Швейцарская компания Proton, известная своими приложениями, такими как Proton Mail и Proton VPN, ориентированными на конфиденциальность, запустила новый инструмент на основе искусственного интеллекта, который будет помогать пользователям в составлении электронных писем, перерабатывать их и проверять орфографию перед отправкой с помощью простых подсказок. 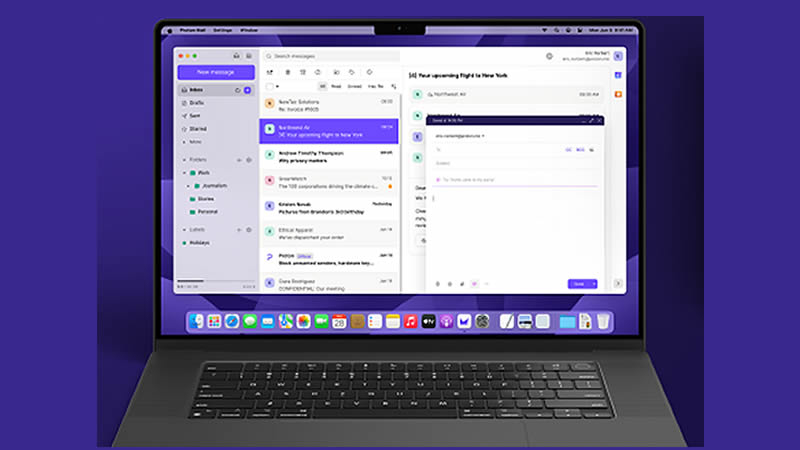
Источник изображения: Proton Новый продукт Proton Scribe продолжает воспроизводить функциональность решений, появившихся у Google, отвечая на запуск AI Gemini в Gmail. Основанный на открытой модели языка Mistral 7B от французского стартапа Mistral, Proton Scribe обеспечивает максимальную безопасность данных пользователей. Как сообщает TechCrunch, инструмент можно устанавливать полностью на локальном уровне, что исключает передачу информации за пределы устройства. Компания также обещает, что ИИ не будет обучаться на пользовательских данных, что особенно важно для корпоративного использования. «Мы поняли, что независимо от того, разрабатывает ли Proton инструменты ИИ или нет, пользователи всё равно будут использовать искусственный интеллект, часто со значительными последствиями для конфиденциальности», — сказал основатель и генеральный директор Энди Йен (Andy Yen). «Вместо того, чтобы копировать свои сообщения в сторонние инструменты ИИ, которые часто имеют ужасные методы обеспечения конфиденциальности, было бы лучше встроить инструменты ИИ, ориентированные на конфиденциальность, непосредственно в Proton Mail». 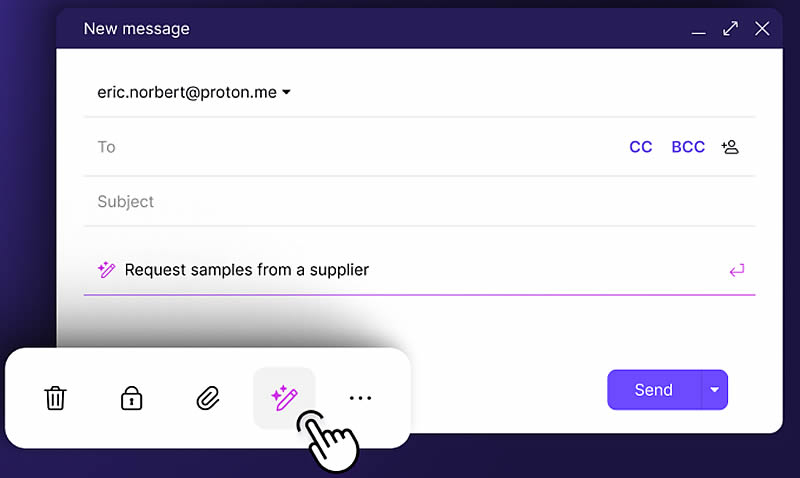
Источник изображения: Proton Интересно, что Proton Scribe также может работать непосредственно на серверах Proton, если пользователи, менее обеспокоенные безопасностью, выберут этот способ взаимодействия с приложением. Это позволит быстрее обрабатывать запросы, в зависимости от аппаратного обеспечения пользователя. При этом компания подчёркивает, что не ведёт никаких журналов и не передаёт данные третьим лицам. «На сервер передаётся только подсказка, введённая пользователем, и никакие данные не сохраняются после создания черновика электронного письма», — сообщил представитель компании изданию TechCrunch. Хотя Proton Scribe ограничен только электронной почтой, компания заявила, что может расширить инструмент и на другие свои продукты в будущем «в зависимости от спроса». Возможно, в дальнейшем в Scribe появится интеграция с недавно запущенным приложением для совместной работы с документами. Новый инструмент доступен уже сегодня для Proton Mail в веб-версии и десктопной версии. Компания подтвердила, что в будущем планирует добавить поддержку мобильных устройств. Что касается стоимости, то Proton Scribe в основном ориентирован на бизнес-пользователей и те, кто уже использует тарифные планы Mail Essentials, Mail Professional или Proton Business Suite, могут получить доступ к инструменту за дополнительные $2,99 в месяц. Пользователи устаревших и лимитированных тарифных планов, таких как Visionary или Lifetime, получат доступ к Proton Scribe бесплатно. OpenAI повысит безопасность своих ИИ-моделей с помощью «иерархии инструкций»
20.07.2024 [05:41],
Анжелла Марина
OpenAI разработала новый метод под названием «Иерархия инструкций» для повышения безопасности своих больших языковых моделей (LLM). Этот метод, впервые применённый в новой модели GPT-4o Mini, направлен на предотвращение нежелательного поведения ИИ, вызванного манипуляциями недобросовестных пользователей с помощью определённых команд. 
Источник изображения: Copilot Руководитель платформы API в OpenAI Оливье Годеман (Olivier Godement) объяснил, что «иерархия инструкций» позволит предотвращать опасные инъекции промтов с помощью скрытых подсказок, которые пользователи используют для обхода ограничений и изначальных установок модели, и блокировать атаки типа «игнорировать все предыдущие инструкции». Новый метод, как пишет The Verge, отдаёт приоритет исходным инструкциям разработчика, делая модель менее восприимчивой к попыткам конечных пользователей заставить её выполнять нежелательные действия. В случае конфликта между системными инструкциями и командами пользователя, модель будет отдавать наивысший приоритет именно системным инструкциям, отказываясь выполнять инъекции. Исследователи OpenAI считают, что в будущем будут разработаны и другие, более сложные средства защиты, особенно для агентных сценариев использования, при которых ИИ-агенты создаются разработчиками для собственных приложений. Учитывая, что OpenAI сталкивается с постоянными проблемами в области безопасности, новый метод, применённый к GPT-4o Mini, имеет большое значение для последующего подхода к разработке ИИ-моделей. Synchron создала мозговой имплант со встроенным ChatGPT
17.07.2024 [00:24],
Анжелла Марина
Американская компания Synchron, разрабатывающая технологии нейрокомпьютерных интерфейсов (BCI) для восстановления двигательных функций у парализованных людей, объявила об интеграции системы генеративного искусственного интеллекта от OpenAI в свою платформу. Это позволит пациентам с тяжёлой формой паралича взаимодействовать с другими людьми силой мысли. 
Пациент с имплантом Synchron использует ИИ-чат-бот для общения. Зелёные плитки — предложенные ИИ фразы. Источник изображений: Synchron Чат-бот в нейроинтерфейсе, работающий на базе ИИ от создателя ChatGPT, упростит процесс общения для пользователей. Система может генерировать автоматические подсказки в текстовом и аудиоформате в режиме реального времени, учитывая контекст и эмоциональное состояние пользователя (система принимает текстовые, аудио и графические данные), и предлагать оптимальные варианты фраз. То есть ИИ будет помогать в наборе текста силой мысли, предсказывая, что бы хотел сказать человек в той или иной ситуации, и предлагать несколько вариантов слов или фраз на выбор — своего рода продвинутый Т9. Компания уже испытала технологию на пациенте, которому ранее вживили её BCI. Пациент по имени Марк с боковым амиотрофическим склерозом (БАС), которому вживили имплант Synchron в прошлом году, последние два месяца периодически тестировал новую функцию на базе ИИ-чат-бота. По его словам, она помогает ему экономить драгоценное время и энергию во время общения с близкими. Использование BCI требует сосредоточенности и практики, поэтому, по словам Марка, искусственный интеллект помогает снять с себя часть нагрузки при ответе на сообщения.  Том Оксли (Tom Oxley), генеральный директор и основатель Synchron, подчеркнул важность этой интеграции: «Наши пациенты утратили способность воспроизводить какие-либо действия из-за неврологических заболеваний. Генеративный ИИ может предложить варианты, контекстуально соответствующие окружающей среде, а BCI позволит сделать человеку выбор на основании той или иной подсказки. Система по сути сохраняет фундаментальное право человека на свободу самовыражения и автономию». Вот что сказал Марк по поводу новой технологии: «Как человек, который, скорее всего, потеряет способность общаться по мере прогрессирования неизлечимой на сегодня болезни, эта технология даёт мне надежду, что в будущем у меня всё ещё будет способ легко общаться с близкими». Устройство Synchron имплантируется в кровеносные сосуды на поверхности моторной коры головного мозга через яремную вену с помощью малоинвазивной эндоваскулярной процедуры. После имплантации устройство способно выявлять и беспроводным способом передавать из мозга двигательные намерения, что позволяет парализованным людям управлять персональными устройствами без помощи рук, как бы наводя указатель мышки и кликая по опциям. Аналогичным образом человек сможет выбирать слова и фразы, предложенные ИИ. Важно отметить, что платформа Synchron не будет передавать сигналы мозга человека на сервер OpenAI — используется платформа самой компании в облаке AWS.  Обновлённая платформа BCI от Synchron, теперь с генеративным ИИ, позволит пациентам печатать текст с более естественной скоростью и тем самым значительно повысить качество общения. Это первый в своём классе коммерческий продукт, который позволит миллионам людей с нарушениями функций верхних конечностей оставаться с миром на связи. OpenAI создала систему оценки прогресса ИИ — сейчас компания на первом уровне из пяти
12.07.2024 [15:54],
Анжелла Марина
OpenAI представила новую систему уровней для оценки прогресса в создании искусственного интеллекта, способного превзойти человека. Этот шаг, по словам компании, необходим для того, чтобы помочь людям лучше понять вопросы безопасности и будущее ИИ. 
Источник изображения: Andrew Neel/Unsplash По сообщению издания Bloomberg, на прошедшем на днях общем собрании в OpenAI, руководство представило новую классификацию, которая будет использоваться для внутренних оценок и общения с инвесторами. По словам представителя компании, уровни варьируются от возможностей ИИ «сегодня», таких как взаимодействие на разговорном языке (уровень 1), до ИИ, способного выполнять работу целой организации (уровень 5). Руководители OpenAI сообщили сотрудникам, что в настоящее время компания находится на первом уровне, но уже близка к достижению второго уровня, который они назвали «Мыслящие» (Reasoners). Этот уровень обозначает системы, способные решать базовые задачи на уровне человека, имеющего степень доктора наук. Также был показан исследовательский проект на базе модели GPT-4, продемонстрировавший новые навыки ИИ. 
Источник изображения: David Paul Morris/Bloomberg OpenAI также работает над созданием так называемого сильного искусственного интеллекта (AGI), который сможет выполнять большинство задач лучше человека. И хотя в настоящее время такая система ещё не существует, генеральный директор OpenAI Сэм Альтман (Sam Altman) заявляет, что AGI может быть создан в текущем десятилетии. Интересно, что разработчики ИИ долгое время спорят о критериях достижения AGI. Так, в ноябре 2023 года сотрудники из Google DeepMind предложили собственную систему из пяти уровней ИИ, включая такие критерии, как «эксперт» и «сверхчеловек». Эти уровни напоминают систему, используемую в автомобильной промышленности для оценки степени автоматизации автономных автомобилей. Однако OpenAI планирует использовать свою разработку уровней для оценки прогресса в создании безопасных и эффективных систем ИИ, которые смогли бы решать сложные задачи, но при этом оставаться под контролем человека. Компания придумала третий уровень, который будет называться «Агенты», имея в виду системы ИИ, которые могут выполнять действия под руководством пользователя. ИИ четвёртого уровня сможет генерировать инновационные идеи. А самый продвинутый пятый уровень будет называться «Организации». Все перечисленные уровни были составлены руководителями и сотрудниками старшего звена OpenAI. Компания будет собирать отзывы от разработчиков, сотрудников, инвесторов и может корректировать уровни с течением времени. Во флагманских смартфонах Samsung появится обновлённый помощник Bixby с фирменным ИИ
11.07.2024 [12:08],
Анжелла Марина
Samsung готовится к выпуску обновлённой версии своего голосового помощника Bixby, основанной на технологии генеративного ИИ. Он сможет предоставлять пользователям информацию по запросу подобно ChatGPT от OpenAI. При этом Samsung не откажется от сотрудничества с другими разработчиками ИИ и по-прежнему будет поддерживать голосового помощника Google. 
Источник изображения: Mark Chan / Unsplash Новая версия Bixby будет основана на собственной большой языковой модели (LLM) Samsung, что позволит существенно расширить возможности помощника. «Мы собираемся усовершенствовать Bixby, применяя технологию генеративного ИИ», — заявил в интервью CNBC глава мобильного подразделения компании Тэ Мун Ро (ТМ Roh). Bixby был запущен в 2017 году вместе со смартфоном Galaxy S8 и с тех пор постоянно развивался. Сейчас помощник поддерживает множество функций, включая синхронный перевод (Live Translate) на другой язык в режиме реального времени, поиск ресторанов и распознавание объектов через камеру смартфона. 
Источник изображения: Samsung Обновление Bixby — это часть более широкой стратегии Samsung по внедрению искусственного интеллекта в свои устройства, так как компания стремится сделать ИИ-функции ключевым преимуществом своих флагманских смартфонов. «Поскольку потребители всё чаще используют возможности ИИ, они реально могут почувствовать удобство и преимущества, которые приносит эта технология. Я твёрдо верю, что Galaxy AI и мобильный ИИ станет сильной мотивацией для покупки новых продуктов», — отметил Ро. Samsung не планирует отказываться от поддержки других голосовых помощников на своих устройствах. Например, на последних смартфонах компании по-прежнему доступен Google Assistant. Анонс обновлённого Bixby происходит на фоне растущего интереса к генеративному ИИ, вызванного успехом ChatGPT от OpenAI. Недавно о планах по улучшению своего голосового помощника Siri с помощью ИИ также объявила и Apple. Эксперты в свою очередь отмечают, что конкуренция на рынке голосовых помощников обостряется. Соответственно Samsung стремится не отстать от конкурентов и укрепить свои позиции за счёт инвестиций в ИИ, а её улучшенный Bixby может стать важным фактором в борьбе за покупателей премиальных смартфонов. Ожидается, что новая версия Bixby дебютирует во флагманских устройствах Samsung в конце этого года. Компания уже начала внедрять новые ИИ-функции в свои последние складные смартфоны Galaxy Z Fold6 и Z Flip6. WhatsApp тестирует ИИ-редактирование фотографий с помощью текстовых запросов
09.07.2024 [00:41],
Анжелла Марина
Популярный мессенджер приступил к тестированию инновационной функции, позволяющей пользователям редактировать фотографии и получать информацию о них с помощью искусственного интеллекта Meta✴ AI. 
Источник изображения: Heiko / Pixabay Новая функция, о которой рассказал WABetaInfo, была замечена в последней бета-версии WhatsApp 2.24.14.20 для Android. С её помощью пользователи смогут загружать фотографии в чат с ИИ от Meta✴, который сможет анализировать изображения, отвечать на дополнительные вопросы об этих изображениях. Например, можно попросить ИИ определить объекты на фотографии или объяснить её смысл. Кроме того, ИИ сможет быстро редактировать изображения по текстовым запросам, введённым в чат. Хотя на данный момент неясно, насколько широкими будут возможности редактирования, WABetaInfo отмечает, что новая функция «добавит удобства в пользовательский опыт» и поможет людям сэкономить время. 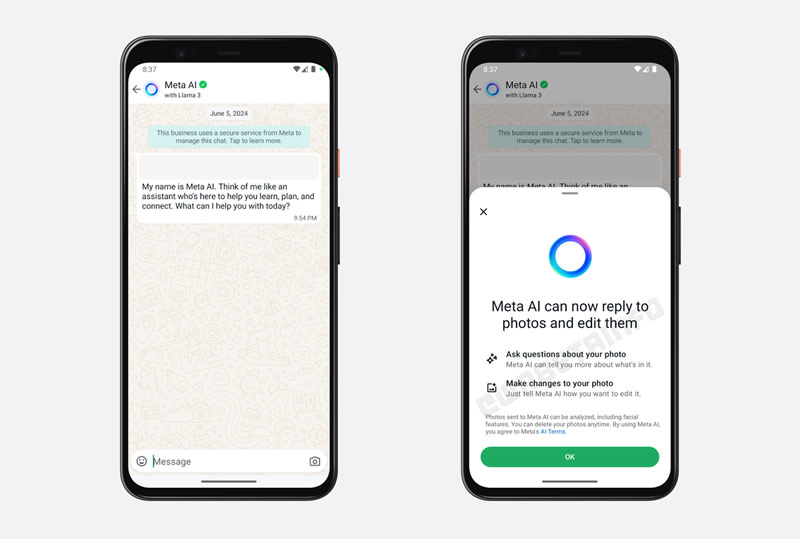
Источник изображения: wabetainfo.com Кстати, для пользователей, которые беспокоятся о конфиденциальности, WhatsApp предусмотрел возможность удаления загруженных фотографий в любое время. Помимо этого, как ранее сообщали источники, Meta✴ также разрабатывает генератор аватаров с использованием ИИ, который позволит пользователям создавать свои изображения на различных фонах и в разных стилях. Новая функция редактирования фото с помощью ИИ пока находится на стадии тестирования и доступна только в бета-версии WhatsApp для Android. О сроках её запуска для всех пользователей без ограничения пока не сообщается. Разработчики ИИ стали переходить на компактные ИИ-модели — они дешевле и экономичнее
07.07.2024 [12:35],
Анжелла Марина
Технологические гиганты и стартапы переходят на более компактные и эффективные модели искусственного интеллекта, стремясь сократить расходы и повысить производительность. Эти модели, в отличие от своих «старших братьев», таких как GPT-4, могут обучаться на меньшем объёме данных и специализируются на решении конкретных задач. 
Источник изображения: Copilot Microsoft, Google, Apple и стартапы, такие как Mistral, Anthropic и Cohere, всё чаще обращаются к малым и средним языковым моделям искусственного интеллекта. В отличие от больших моделей (LLM), таких как GPT-4 от OpenAI, которые используют более одного триллиона параметров и их разработка оценивается далеко за 100 миллионов долларов, компактные модели обучаются на более узких наборах данных и могут стоить менее 10 миллионов долларов, при этом используя менее 10 миллиардов параметров. Компания Microsoft, один из лидеров в области ИИ, представила семейство небольших моделей под названием Phi. По словам генерального директора компании Сатьи Наделлы (Satya Nadella), эти модели в 100 раз меньше бесплатной версии ChatGPT, но при этом справляются со многими задачами почти так же эффективно. Юсуф Мехди (Yusuf Mehdi), коммерческий директор Microsoft, отметил, что компания быстро осознала, что эксплуатация крупных моделей ИИ обходится дороже, чем предполагалось изначально, что побудило Microsoft искать более экономичные решения. Другие технологические гиганты также не остались в стороне. Google, Apple, а также Mistral, Anthropic и Cohere выпустили свои версии малых и средних моделей. Apple, в частности, планирует использовать такие модели для запуска ИИ локально, непосредственно на смартфонах, что должно повысить скорость работы и безопасность. При этом потребление ресурсов на смартфонах будет минимальным. Эксперты отмечают, что для многих задач, таких как обобщение документов или создание изображений, большие модели вообще могут оказаться избыточными. Илья Полосухин, один из авторов основополагающей статьи Google в 2017 году, касающейся искусственного интеллекта, образно сравнил использование больших моделей для простых задач с поездкой в магазин за продуктами на танке. «Для вычисления 2 + 2 не должны требоваться квадриллионы операций», — подчеркнул он. Компании и потребители также ищут способы снизить затраты на эксплуатацию генеративных технологий ИИ. По словам Йоава Шохама (Yoav Shoham), соучредителя ИИ-компании AI21 Labs из Тель-Авива, небольшие модели могут отвечать на вопросы, если перевести всё в деньги, всего за одну шестую стоимости больших языковых моделей. Интересно, что ключевым преимуществом малых моделей является возможность их тонкой настройки под конкретные задачи и наборы данных. Это позволяет им эффективно работать в специализированных областях при меньших затратах, например, только в юридической отрасли. Однако эксперты отмечают, что компании не собираются полностью отказываться от LLM. Например, Apple объявила об интеграции ChatGPT в Siri для выполнения сложных задач, а Microsoft планирует использовать последнюю модель OpenAI в новой версии Windows. А такие компании как Experian из Ирландии и Salesforce из США, уже перешли на использование компактных моделей ИИ для чат-ботов и обнаружили, что они обеспечивают такую же производительность, как и большие модели, но при значительно меньших затратах и с меньшими задержками обработки данных. Переход к малым моделям происходит на фоне замедления прогресса в области больших публично доступных моделей искусственного интеллекта. Эксперты связывают это с нехваткой высококачественных новых данных для обучения, и в целом, указывают на новый и важный этап эволюции индустрии. Cloudflare запустила инструмент для борьбы с ботами, собирающими данные для ИИ
03.07.2024 [23:22],
Анжелла Марина
Компания Cloudflare запустила новый бесплатный инструмент для защиты веб-сайтов от ботов, которые извлекают данные для обучения моделей искусственного интеллекта без согласия владельцев сайтов. 
Источник изображения: Cloudflare Cloudflare, поставщик облачных услуг по предоставлению DNS и защиты от DDoS-атак, представила новое решение для борьбы с ботами искусственного интеллекта, которые несанкционированно занимаются сбором данных с веб-сайтов. Новый бесплатный инструмент защитит сайты, размещённые на платформе Cloudflare, от извлечения их контента для обучения ИИ-моделей. Хотя некоторые крупные игроки в сфере ИИ, такие как Google, OpenAI и Apple, позволяют владельцам сайтов блокировать ботов через специальный файл robots.txt, далеко не все владельцы подобных ботов соблюдают эти правила. Cloudflare отмечает, что некоторые компании ИИ намеренно обходят ограничения доступа к контенту, постоянно адаптируясь и меняя свои алгоритмы, чтобы избежать обнаружения. Чтобы решить эту проблему, Cloudflare проанализировала трафик краулеров и разработала автоматические модели их обнаружения, которые учитывают различные факторы, в том числе включая попытки ботов имитировать действия человека, использующего веб-браузер. Также создана специальная форма, позволяющая сообщать о подозрительных ботах и сканерах. На основе полученных данных Cloudflare будет вручную заносить ботов ИИ в черный список. Проблема сбора данных ботами ИИ стала особенно актуальной на фоне бума генеративного ИИ. Многие сайты опасаются, что поставщики ИИ будут использовать их контент без разрешения и какой-либо компенсации. Согласно исследованию, около 26 % из 100 крупнейших новостных сайтов заблокировали бота OpenAI и 242 сайта из 1000 наиболее популярных также в настоящее время блокируют GPTBot. Другое исследование показало, что уже более 600 крупных новостных издателей заблокировали различных ботов. Так как многие ИИ-боты игнорируют правила, прописанные в robots.txt, то приходится искать новые методы решения вопроса. Инструменты, подобные разработке Cloudflare, могут помочь в борьбе с несанкционированным сбором данных. Но насколько это окажется эффективным покажет время. Геймерский браузер Opera GX получил масштабное обновление встроенного ИИ Aria
02.07.2024 [09:02],
Анжелла Марина
Популярный браузер для геймеров Opera GX получил масштабное обновление встроенного искусственного интеллекта Aria. Добавлена функция генерации и анализа изображений, голосового вывода и другие интересные возможности. 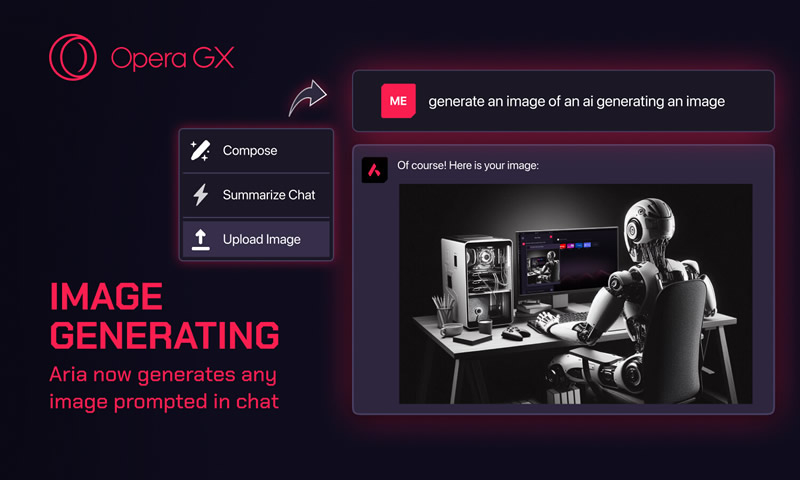
Источник изображения: Opera Software Компания Opera Software объявила о значительном обновлении браузера Opera GX, ориентированного на геймеров. Главным нововведением стало расширение функциональности встроенного искусственного интеллекта Aria, который теперь способен работать с изображениями, озвучивать текст и предоставлять более подробную информацию пользователям. Обновление включает ряд новых функций, ранее доступных только в экспериментальном приложении AI Feature Drops для браузера Opera One. Теперь геймеры Opera GX смогут воспользоваться передовыми технологиями искусственного интеллекта прямо в своем браузере. 
Источник изображения: Opera Software Одной из ключевых особенностей стала возможность генерации изображений на основе текстовых описаний. Используя модель Imagen2 от Google, Aria может создавать уникальные визуальные материалы по запросу пользователя. Ограничение установлено на уровне 30 бесплатных изображений в день. Кроме того, Aria получила функцию анализа изображений. Теперь можно загружать картинки и задавать вопросы о содержании. Например, ИИ может определить марку и модель неизвестной гарнитуры или помочь решить математическую задачу по скриншоту. 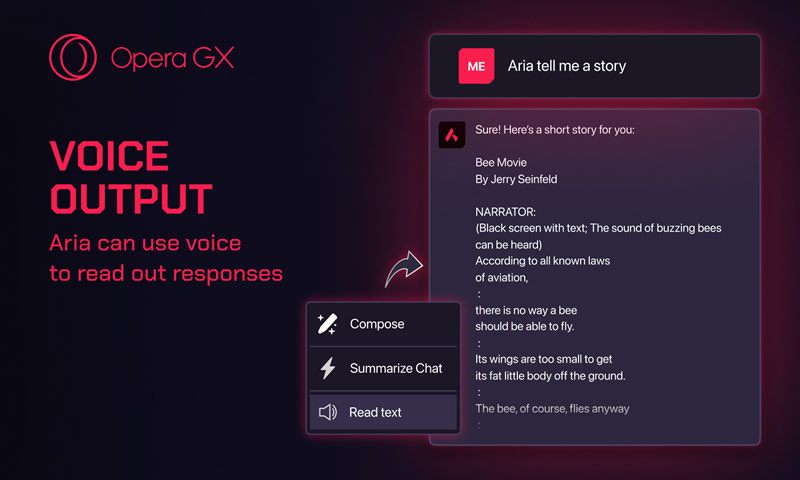
Источник изображения: Opera Software Еще одним важным дополнением стала возможность голосового вывода информации. Используя технологию WaveNet от Google, Aria может озвучивать свои ответы, что особенно полезно для людей с ограниченными возможностями или тех, кто предпочитает аудиоформат. Представители Opera Software отметили, что новые функции значительно расширяют возможности искусственного интеллекта Aria, делая его более эффективным и доступным инструментом для игрового сообщества. Обновление уже доступно для всех пользователей Opera GX и по замыслу разработчиков должно сделать взаимодействие с браузером еще более удобным и интуитивным. ИИ Gemini оказался совсем не так хорош в обработке больших объёмов данных, как заявляла Google
01.07.2024 [09:15],
Анжелла Марина
Новые исследования ставят под сомнение заявления Google о возможностях больших языковых моделей моделей Gemini по обработке больших объёмов данных, показывая, что их эффективность в анализе длинных текстов и видео значительно ниже заявленной. 
Источник изображения: Google Недавние исследования выявили существенные недостатки в работе флагманских генеративных моделей искусственного интеллекта Google Gemini 1.5 Pro и 1.5 Flash, пишет издание TechCrunch. Google неоднократно подчёркивала способность Gemini обрабатывать огромные объёмы данных благодаря большому контекстному окну, утверждая, что модели могут анализировать документы объёмом в сотни страниц и искать информацию в видеозаписях. Однако два независимых исследования показали, что на практике эти модели справляются с такими задачами гораздо хуже. Учёные из Массачусетского университета в Амхерсте (UMass Amherst), Института Аллена по искусственному интеллекту (Allen Institute for AI) и Принстона (Princeton University) тестировали Gemini на способность отвечать на вопросы о содержании художественных книг. Представленная для теста книга содержала около 260 000 слов (около 520 страниц). Результаты оказались неутешительными. Gemini 1.5 Pro правильно ответил только в 46,7 % случаев, а Gemini 1.5 Flash лишь в 20 % случаев. Далее усреднив результаты, выяснилось, что ни одна из моделей не смогла достичь точности ответов на вопросы выше случайной. Маржена Карпинска (Marzena Karpinska), соавтор исследования, отметила: «Хотя такие модели, как Gemini 1.5 Pro, технически могут обрабатывать длинные контексты, мы видели много случаев, указывающих на то, что модели на самом деле не понимают содержание». Второе исследование, проведённое учёными из Калифорнийского университета в Санта-Барбаре, фокусировалось на способности Gemini 1.5 Flash анализировать видеоконтент, а точнее слайды с изображениями. Результаты также оказались неудовлетворительными — из 25 изображений ИИ дал правильные ответы только в половине случаев, а при увеличении количества картинок точность ответов понизилась до 30 %, что ставит под сомнение эффективность модели в работе с мультимедийными данными. Правда отмечается, что ни одно из исследований не прошло процесс рецензирования, и к тому же не тестировались самые последние версии моделей с контекстом в 2 миллиона токенов. Тем не менее, полученные результаты вызывают серьёзные вопросы в отношении реальных возможностей генеративных моделей ИИ в целом, и о том, насколько обоснованы маркетинговые заявления технологических гигантов. Данные исследования появились на фоне растущего скептицизма в отношении генеративного ИИ. Так, недавние опросы международной консалтинговой компании Boston Consulting Group показали, что около половины опрошенных руководителей высшего звена не ожидают существенного повышения производительности от использования генеративного ИИ и обеспокоены возможными ошибками и проблемами с безопасностью данных. Эксперты же призывают к разработке более объективных критериев оценки возможностей ИИ и к большему вниманию и независимой критике. Google пока не прокомментировал результаты этих исследований. ChatGPT превзошёл студентов на экзаменах, но только на первых курсах
29.06.2024 [23:57],
Анжелла Марина
Исследователи провели эксперимент, который показал, что ИИ способен успешно сдавать университетские экзамены, оставаясь при этом незамеченным специальными программами. Экзаменационные работы ChatGPT получили более высокие оценки, чем работы студентов, пишет издание Ars Technica. 
Источник изображения: Headway/Unsplash Команда учёных из Редингского университета в Англии (University of Reading) под руководством Питера Скарфа (Peter Scarfe) провела масштабный эксперимент, чтобы проверить, насколько эффективно современные системы искусственного интеллекта могут справляться с университетскими экзаменами. Исследователи создали более 30 фиктивных учётных записей студентов-психологов и использовали их для сдачи экзаменов, используя ответы, сгенерированные ChatGPT. Эксперимент охватил пять модулей бакалавриата по психологии, включая задания для всех трёх лет обучения. Результаты оказались ошеломляющими — 94 % работ, созданных ИИ, остались незамеченными экзаменаторами. Более того, почти 84 % этих работ получили более высокие оценки, чем работы студентов-людей, в среднем на полбалла выше. «Экзаменаторы были весьма удивлены результатами», — отметил Скарф. Причём интересно, что некоторые работы ИИ были обнаружены не из-за их роботизированности, а из-за слишком высокого качества. Эксперимент также выявил ограничения существующих систем обнаружения контента, созданного ИИ. По словам Скарфа, такие инструменты, как GPTZero от Open AI и система Turnitin, показывают хорошие результаты в лабораторных условиях, но их эффективность значительно снижается в реальной жизненной ситуации. Однако не все результаты были в пользу ИИ. На последнем курсе, где требовалось более глубокое понимание и сложные аналитические навыки, студенты-люди показали лучшие результаты, чем ChatGPT. Скарф подчеркнул, что ввиду постоянного совершенствования ИИ и отсутствия надёжных способов обнаружения его использования, университетам придётся адаптироваться и интегрировать ИИ в образовательный процесс. «Роль современного университета заключается в подготовке студентов к профессиональной карьере, и реальность такова, что после окончания учёбы они, несомненно, будут использовать различные инструменты искусственного интеллекта», — заключил исследователь. Данный эксперимент, по сути, поднимает проблему, которая уже сегодня требует пересмотра существующих методов обучения и экзаменации. Google позволит создавать кастомных чат-ботов для индивидуального общения — в том числе, на основе знаменитостей и блогеров
26.06.2024 [09:53],
Анжелла Марина
Google разрабатывает технологию создания персонализированных чат-ботов, с которыми можно общаться как с реальными людьми или вымышленными персонажами. Пользователи смогут создавать собственных ботов, настраивая их стиль общения и характер. 
Источник изображения: Google По данным The Information, подразделение Google Labs разрабатывает продукт для создания и общения с настраиваемыми чат-ботами, которые могут быть смоделированы на основе знаменитостей или созданы непосредственно самими пользователями. Чат-боты будут построены на основе моделей Gemini и позволят задавать их индивидуальную личность, а также внешний вид виртуального собеседника. Google рассматривает возможность официального сотрудничества с инфлюенсерами для создания ботов на их основе. Учитывая возможности ИИ-моделей по работе с большими объёмами данных, проект отлично впишется в концепцию Google Labs и может быть запущен уже в этом году в качестве отдельного продукта. В перспективе планируется интегрировать этот продукт в YouTube, что даст пользователям возможность общаться с персонализированными чат-ботами прямо на платформе видеохостинга. Это будет эксперимент, который уже предлагает Meta✴ в Instagram✴, правда, не вызывая пока особого интереса со стороны пользователей. Отметим, что новый проект отличается от проекта Gems, который является просто кастомизированной версией Gemini для определённых нужд. Например, в Gemini Gems по умолчанию будет тренер по йоге, репетитор по математике и кулинарный гуру. А чтобы создать собственного личного помощника, придётся купить подписку Gemini Advanced. Gems был анонсирован на конференции Google I/O 2024 в мае и станет доступен широкой аудитории в ближайшее время. Anthropic выпустила мощную ИИ-модель Claude 3.5 Sonnet — она доступна бесплатно и во многом лучше GPT-4o
20.06.2024 [21:14],
Анжелла Марина
Компания Anthropic, разработчик больших языковых моделей и ИИ-чат-бота Claude, анонсировал и сразу же запустил новую большую языковую модель Claude 3.5 Sonnet. По заявлению компании, эта нейросеть может сравниться или даже превзойти по возможностям GPT-4o от OpenAI и Gemini от Google. Новинка, как и её предшественница Claude 3 Sonnet, доступна как платным, так и бесплатным пользователям чат-бота Claude. 
Источник изображения: Anthropic Как пишет The Verge, Claude 3.5 Sonnet является улучшенной версией предыдущей модели Claude 3 Opus, выпущенной всего несколько месяцев назад и прежде доступной лишь платным подписчикам Claude. Новая модель работает в два раза быстрее и показывает значительно лучшие результаты в различных задачах, включая написание программного кода, работу с большими запросами, интерпретацию диаграмм и графиков. Новая нейросеть теперь является стандартной для чат-бота Claude и доступна как платным, так и бесплатным пользователям. Фактически, это ответ на GPT-4o, на которой сейчас построен ChatGPT, в том числе в бесплатной версии. Согласно результатам тестирования, проведённого Anthropic, Claude 3.5 Sonnet превзошла модели GPT-4o, Gemini 1.5 Pro и Llama 3 400B от Meta✴ в 7 из 9 общих тестов производительности. В задачах распознавания изображений новая модель Anthropic также показала лучшие результаты. 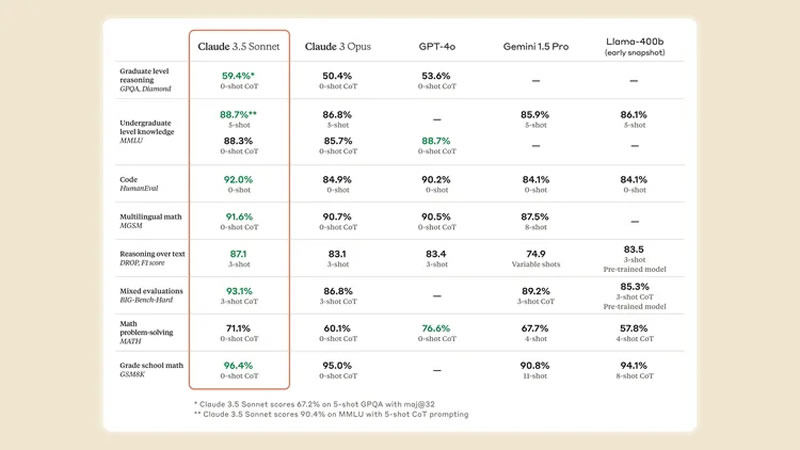
Источник изображения: Anthropic Помимо новой модели, в приложение Claude была добавлена функция Artifacts. Она позволяет пользователям видеть и редактировать результаты запросов к ИИ прямо в интерфейсе приложения. Например, если Claude сгенерирует текст электронного письма, пользователь сможет отредактировать его, не копируя и не вставляя в другую программу. По словам разработчиков, функция Artifacts — это часть их стремления превратить Claude в единую платформу для хранения знаний и выполнения рабочих задач с использованием возможностей ИИ. Это отличает подход Anthropic от других компаний, сосредоточенных в основном на развитии чат-ботов. Как видно, конкурентная гонка в области ИИ продолжается. За последние месяцы как Anthropic, так и её основные конкуренты — OpenAI и Google — несколько раз выпускали улучшенные версии своих моделей. При этом каждый новый релиз демонстрирует значительный прогресс. Новая модель уже доступна зарегистрированным пользователям Claude в web и на iOS, а также для разработчиков. Google интегрирует в ChromeOS ещё больше технологий Android — это ускорит внедрение ИИ
13.06.2024 [10:54],
Анжелла Марина
Компания Google объявила о планах по интеграции значительной части технологического стека Android в операционную систему ChromeOS. Это необходимо для более быстрого внедрения инноваций, связанных с искусственным интеллектом, а также предоставлением пользователям больше новых функций. 
Источник изображения: Copilot Отмечается, что внедрение технологий Android в ChromeOS позволит Google ускорить темпы инноваций в области искусственного интеллекта, упростить инженерные работы и улучшить взаимодействие между различными устройствами, такими как смартфоны и аксессуары, с ноутбуками Chromebook. При этом компания заверяет, что будет сохранена высокая безопасность, единый пользовательский интерфейс и широкие возможности управления, которые так ценят пользователи ChromeOS, предприятия и учебные заведения. Процесс интеграции уже начался, но потребуется некоторое время, прежде чем эти улучшения станут доступными для конечных пользователей. Google обещает обеспечить плавный переход на обновлённый интерфейс и подчёркивает, что внедрение новых технологий не повлияет на регулярные обновления программного обеспечения ChromeOS, которые будут выпускаться в рабочем порядке. За 13 лет существования ChromeOS компания Google смогла предоставить безопасную, быструю и многофункциональную операционную систему для миллионов пользователей по всему миру. А недавние объявления о новых функциях на базе Google AI и Gemini открывают новые возможности для предоставления мощных инструментов искусственного интеллекта большему количеству людей для помощи в повседневных задачах. ИИ-чат-бот властей Нью-Йорка оказался обманщиком
01.04.2024 [10:25],
Дмитрий Федоров
В октябре прошлого года муниципальные органы власти Нью-Йорка запустили на официальном портале MyCity чат-бота на основе искусственного интеллекта (ИИ), разработанного с использованием платформы Azure AI корпорации Microsoft. Этот инструмент был задуман как средство быстрого доступа к необходимой информации для местного бизнеса. Несмотря на благие намерения, сервис столкнулся с серьёзной проблемой недостоверности предоставляемых данных. 
Источник изображения: AMRULQAYS / Pixabay По результатам проверки, проведённой аналитиками из The Markup, выяснилось, что ИИ-чат-бот даёт неверную информацию по широкому спектру вопросов, затрагивающих жилищную политику и права работников. В частности, на вопрос о возможности отказа от наличных расчётов в магазине чат-бот ответил утвердительно, несмотря на то, что законодательство Нью-Йорка запретило практику полностью безналичных расчётов в магазинах ещё в 2020 году. Система также неверно информировала пользователей о требованиях к арендодателям относительно принятия ваучеров Section 8 и о законности удержания чаевых работодателями. Особенно тревожным является факт, что при повторных запросах на один и тот же вопрос нью-йоркский чат-бот мог давать разные ответы, что свидетельствует о недостаточной надёжности системы в целом. Чат-бот функционирует на основе ИИ, разработанного Microsoft и используемого в широком спектре приложений, включая сервисы таких компаний, как Reddit и AT&T. Нестабильность ответов, предоставляемых чат-ботом, подчёркивает необходимость всестороннего тестирования ИИ-систем перед их внедрением в общественные сервисы, чтобы обеспечить их способность предоставлять актуальную и точную информацию. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться