|
Опрос
|
реклама
Быстрый переход
Meta✴ собралась купить чипмейкера FuriosaAI для выпуска своих ИИ-чипов
13.02.2025 [00:18],
Анжелла Марина
Компания Meta✴, стремясь укрепить свою серверную инфраструктуру для систем искусственного интеллекта (ИИ), ведёт переговоры о покупке южнокорейского чипмейкера FuriosaAI, специализирующегося на разработке ускорителей искусственного интеллекта. Об этом сообщает TechCrunch. 
Источник изображения: Igor Omilaev / Unsplash FuriosaAI, основанная бывшими сотрудниками Samsung и AMD, разрабатывает чипы, которые значительно ускоряют работу и обслуживание ИИ-моделей, включая модели генерации текста, такие как Llama 2 и Llama 3 от Meta✴. Ожидается, что Meta✴ может объявить о своих намерениях приобрести FuriosaAI уже в этом месяце. Согласно данным, FuriosaAI привлекла около 90 миллиардов корейских вон (примерно $61,94 млн) от инвесторов, включая южнокорейскую технологическую компанию Naver. Также ранее FuriosaAI заявляла о взаимодействии с потенциальными клиентами в США, Японии и Индии, не раскрывая их имён. По мнению экспертов, этот шаг, очевидно, направлен на снижение зависимости от доминирующей в области производства чипов компании Nvidia и является дополнением к собственным усилиям Meta✴ по созданию производительных и эффективных ИИ-ускорителей. Meta✴ заявила, что планирует потратить до $65 млрд в этом году на поддержку своих целей в области искусственного интеллекта. При этом приобретение FuriosaAI может значительно ускорить разработку и внедрение новых ИИ-технологий в собственные продукты Meta✴. Еврокомиссия раскритиковала новые правила США по поставкам ИИ-чипов — ограничения затронули большую часть ЕС
14.01.2025 [23:35],
Николай Хижняк
США, введя новые правила по контролю распространения ИИ, не только заблокировали поставки ИИ-чипов своим противникам, но также ограничили их экспорт в большинство стран мира. Такой радикальный подход администрации президента США Джо Байдена вызвал возмущение со стороны компании Nvidia, Ассоциации полупроводниковой промышленности (SIA), а теперь и Европейской комиссии (ЕК). 
Источник изображения: Nebius Новые правила экспортного контроля вступят в силу через 120 дней после их публикации — уже во время второго президентского срока Дональда Трампа. Это даст странам Евросоюза и другим заинтересованным сторонам время для консультаций с новой администрацией США, внесения возможных изменений в правила, их отсрочки или даже отмены. Согласно новым правилам, только 18 стран мира получат статус доверенных (Tier 1), из которых 10 являются членами ЕС: Бельгия, Дания, Финляндия, Франция, Германия, Ирландия, Италия, Нидерланды, Норвегия и Швеция. Это означает, что у них будет «практически неограниченный доступ» к передовым американским чипам для ИИ. Однако такие страны должны будут соблюдать требования безопасности США и размещать не менее 75 % своих вычислительных мощностей у себя или в других странах того же доверенного круга. Остальную часть мощностей разрешается размещать в странах, на которые не распространяется контроль над поставками вооружений со стороны США (Tier 2), при этом не более 7 % от общего объёма квоты может быть размещено в одной стране Tier 2. Для стран Tier 2, включая остальных 17 членов ЕС, вводится квота в 50 000 ИИ-чипов на страну. Возможны также сделки между правительствами, в результате которых квота может быть увеличена до 100 000 чипов, если цели стран в области возобновляемых источников энергии и технологической безопасности совпадают с целями США. Учреждения из некоторых стран могут подать заявку на получение особого статуса, который позволит им приобрести до 320 000 передовых ускорителей в течение двух лет. В ЕС резко раскритиковали такие экспортные ограничения. «Мы [ЕС] тесно сотрудничаем, в частности, в области безопасности, и представляем экономическую возможность для США, а не риск безопасности [...] Мы с нетерпением ждём конструктивного взаимодействия со следующей администрацией США. Мы уверены, что сможем найти способ сохранить безопасную трансатлантическую цепочку поставок технологий ИИ и суперкомпьютеров на благо наших компаний и граждан по обе стороны Атлантики», — говорится в совместном заявлении, опубликованном на сайте Еврокомиссии. Администрация президента Джо Байдена объявила о новых радикальных и противоречивых правилах экспортного контроля после сообщений о том, что предыдущие экспортные ограничения и санкции США в отношении противников оказались недостаточно эффективными. Новые меры в виде квот на поставки передовых чипов направлены на то, чтобы ещё больше затруднить доступ к ИИ-чипам для стран, находящихся под санкциями США, в частности Китая и России, даже через посредников. Стоит отметить, что с новыми экспортными ограничениями согласны не все даже в текущем составе руководства США. Так, министр торговли Джина Раймондо (Gina Raimondo) считает такие шаги пустой тратой времени. По её мнению, инвестиции в производство и исследования полупроводников гораздо важнее, так как именно они позволят США сохранить своё глобальное технологическое превосходство. США перекрыли параллельный импорт ИИ-чипов и закрыли России доступ к мощным ИИ-моделям
13.01.2025 [15:36],
Андрей Созинов
Администрация президента США объявила сегодня о новых радикальных и противоречивых правилах экспортного контроля, которые призваны предотвратить попадание передовых чипов и моделей искусственного интеллекта в руки противников США, таких как Россия, Китай и некоторые другие страны. 
Источник изображения: Nvidia Новое «правило распространения ИИ», разработанное администрацией Байдена, делит мир на страны, которым разрешен относительно свободный доступ к самым передовым американским микросхемам и алгоритмам ИИ, и страны, которым потребуются специальные лицензии для доступа к этим технологиям. Правило, которое будет введено в действие Бюро промышленности и безопасности Министерства торговли США, впервые ограничит перемещение самых мощных моделей ИИ. «США сейчас лидируют в мире в области ИИ — как в разработке ИИ, так и в создании ИИ-чипов, — и очень важно, чтобы мы сохранили это положение», — заявила министр торговли США Джина Раймондо (Gina Raimondo) в преддверии сегодняшнего объявления. В список доверенных стран вошли основные союзники США: Великобритания, Канада, Австралия, Япония, Франция, Германия, Бельгия, Дания, Финляндия, Ирландия, Италия, Нидерланды, Новая Зеландия, Норвегия, Республика Корея, Испания, Швеция и Тайвань. Компании из этих стран смогут беспрепятственно приобретать любые ИИ-чипы и алгоритмы у компаний из США. Поставки ИИ-чипов в другие страны будут ограничены. Для стран, на которые не распространяется контроль над поставками вооружений со стороны США, вводится квота в 50 000 ИИ-чипов на страну. Также возможны сделки между правительствами, в результате которых лимит может быть увеличен до 100 000, если их цели в области возобновляемых источников энергии и технологической безопасности совпадают с целями Соединенных Штатов. Учреждения в некоторых странах также могут подать заявку на получение особого статуса, который позволит им приобрести до 320 000 передовых ускорителей в течение двух лет. Тем не менее, будет установлен лимит на общий объём вычислительных мощностей ИИ, которые компании и другие учреждения могут размещать за рубежом. Также компании из стран, на которые не распространяется контроль над поставками вооружений со стороны США, смогут получить до 1700 новейших чипов искусственного интеллекта без специального разрешения. Если же им понадобится больше чипов или доступ к наиболее мощным ИИ-моделям, они смогут обратиться в Минторг США за специальной лицензией. Чтобы получить лицензию, компании должны будут доказать, что способны обеспечить надлежащий уровень физической и кибербезопасности. Лимит в 1700 ускорителей позволит удовлетворить потребности многих университетов и учреждений здравоохранения, но его явно не хватит операторам дата-цетров. Заметим, что новое правило распространяется только на готовые чипы: американские компании по-прежнему смогут вести разработку и производство чипов, в странах, которые не присутствуют в списке, но на которые не наложены ограничения по поставкам вооружений. По словам администрации, правило также не будет ограничивать модели ИИ с открытым исходным кодом, такие как Llama от Meta✴. 
Источник изображения: AMD Что касается России и других стран, на которые наложено эмбарго на поставки оружия и технологий военного назначения, таких как Китай, Иран и Северная Корея. В эти страны уже запрещено поставлять передовые чипы для ИИ, а новые санкции впервые ограничит их доступ к передовым моделям искусственного интеллекта. Однако тут важно отметить, что прежде ИИ-чипы всё равно вполне успешно поставлялись в Россию с помощью механизмов параллельного импорта, то есть через третьи страны, которые не вводили санкции против РФ. Теперь же появление квот для этих самых третьих стран создаёт серьёзнейшее препятствие для параллельного импорта ИИ-чипов в Россию — компании не смогут просто так закупать ИИ-ускорители в больших объёмах и перепродавать их. Кроме того, раньше компании из России, Китая и других подсанкционных юрисдикций могли создавать нейросети с использованием компьютерных кластеров, расположенных заграницей. Согласно новым ограничениям, Россия, Китай и другие соперники США больше не смогут создавать передовые модели ИИ в других странах, на которые распространяется действие правила. «Полупроводники, которые питают [ИИ] и тяжёлые модели, как мы все знаем, являются технологией двойного назначения, — добавила Раймондо в преддверии объявления. — Они используются во многих коммерческих приложениях, но также могут использоваться нашими противниками для ядерного моделирования, разработки биологического оружия и продвижения своих вооруженных сил». Новые правила наверняка вызовут споры, поскольку они могут ограничить международные продажи ИИ в критический для отрасли момент. Также важно отметить, что правило представили всего за неделю до инаугурации Трампа. Постановление вводит 120-дневный период консультаций, что означает, что администрация Дональда Трампа (Donald Trump) должна будет выслушать мнения, возможно, изменить правило, а затем ввести его в действие. 
Источник изображения: Nvidia Компания Nvidia, ведущий мировой производитель чипов для искусственного интеллекта, в своем блоге назвала новое правило «беспрецедентным и ошибочным». «Прикрываясь "антикитайскими" мерами, эти правила ничего не сделают для укрепления безопасности США. Вместо того чтобы смягчить какую-либо угрозу, новые правила Байдена лишь ослабят глобальную конкурентоспособность Америки, подорвав инновации, благодаря которым США находятся впереди», — написала компания. Представители Байдена считают новые ограничения необходимыми, поскольку в ближайшие годы ИИ может развиваться стремительно и непредсказуемо. «США должны быть готовы к быстрому росту возможностей ИИ в ближайшие годы, что может оказать преобразующее воздействие на экономику и национальную безопасность», — заявил Джейк Салливан (Jake Sullivan), советник администрации Байдена по национальной безопасности. По словам высокопоставленного сотрудника администрации президента США, попросившего Wired не называть его имени, администрация Байдена также считала оправданным принять новые правила поскорее, поскольку, по мнению администрации, китайские разработки в области ИИ отстают от американских всего на 6–18 месяцев. «Время действительно имеет большое значение, — сказал чиновник. — Мы считаем, что сейчас мы находимся в критической точке». Байден напоследок полностью заблокирует поставки любых ИИ-чипов в Россию
10.01.2025 [04:31],
Анжелла Марина
Джо Байден (Joe Biden) перед уходом с поста намерен ввести дополнительные ограничения на экспорт чипов искусственного интеллекта (ИИ), производимых, в частности, компанией Nvidia. Эти меры направлены на усиление контроля над передовыми технологиями и предотвращение их попадания в руки Китая и ряд других стран, включая Россию. Экспорт обученных ИИ-моделей также будет прекращён. 
Источник изображения: Nvidia Как передаёт Bloomberg, новые правила будут направлены на ограничение продаж ИИ-чипов для дата-центров как для отдельных стран, так и на уровне отдельных компаний. США тем самым хотят сосредоточить развитие ИИ в дружественных странах и заставить международный бизнес соответствовать американским стандартам. Ожидается, что новые ограничения будут разделять страны на три группы, каждая из которых получит свой уровень доступа к американским технологиям. В первую группу войдут США и их ближайшие 18 союзников, включая Германию, Японию, Южную Корею, Нидерланды и Тайвань. Для этих стран доступ к американским чипам останется практически неограниченным. Вторая группа охватит большинство стран мира, где будут установлены строгие лимиты на объём вычислительных мощностей, доступных для импорта. Однако компании из этих стран смогут получить более высокие квоты, если согласятся на соблюдение стандартов США, включая требования по безопасности и правам человека. Третья группа будет включать Китай, Россию, Макао и ещё около двух десятков стран, которым доступ к американским технологиям будет практически полностью закрыт, включая обученные большие языковые модели. Новые правила затруднят поставки ускорителей в Россию методом параллельного импорта. Все страны, через которые поставки осуществляются сейчас и в принципе возможны, будут иметь ограничения на получения чипов. В таких условиях затруднительно заниматься реэкспортом, поскольку лимитов может хватить лишь на собственные нужды. При этом компания Nvidia, крупнейший производитель ИИ-чипов, выступила с жёсткой критикой инициативы. «Правило, ограничивающее экспорт для большей части мира, станет значительным изменением политики, которое не только не снизит риски неправильного использования технологий, но и нанесёт ущерб экономическому росту и лидерству США», — заявили в компании. Аналогичную позицию выразила Ассоциация полупроводниковой промышленности, назвав меры поспешными и требующими более тщательного обсуждения. Акции Nvidia после закрытия торгов в США успели снизиться в цене на процент с небольшим. Отмечается, что эти ограничения являются продолжением многолетних усилий США по ограничению доступа Китая и России к передовым технологиям. Ранее американские чипмейкеры, такие как Nvidia и AMD, уже столкнулись с запретами на продажу своих передовых процессоров в этих странах. Кроме того, США пытаются предотвратить обход санкций через третьи страны, такие как государства Ближнего Востока и Юго-Восточной Азии. Новые правила также затронут экспорт определённых ИИ-моделей. Компании не смогут размещать мощные модели с закрытыми параметрами в странах третьей группы и будут обязаны соблюдать строгие стандарты безопасности для работы в странах второй группы. При этом открытые модели, доступные для общественного использования, и менее мощные закрытые модели искусственного интеллекта не подпадают под ограничения. Дженсен Хуанг похвалился, что Nvidia обогнала закон Мура
08.01.2025 [22:30],
Анжелла Марина
Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) заявил, что за последние 10 лет производительность чипов Nvidia увеличилась в 1000 раз, вступив в противоречие с законом Мура. И этот прогресс не замедлится в ближайшем будущем, а чипы компании обеспечат дальнейшее снижение стоимости и ускорение развития искусственного интеллекта (ИИ), рассказал Хуанг в интервью TechCrunch после выступления на CES 2025. 
Источник изображения: Nvidia Закон Мура, сформулированный в 1965 году соучредителем Intel Гордоном Муром, предсказывал удвоение числа транзисторов на кристалле каждые два года, что приводило к удвоению производительности чипов. Стоимость вычислений соответственно снижалась. В течение десятилетий это правило определяло развитие вычислительной техники. Однако в последние годы действие закона Мура начало замедляться. Однако Дженсен Хуанг с этим категорически не согласен, о чём неоднократно заявлял прежде. В ноябре Хуанг заявил, что мир ИИ находится на пороге «гиперзакона Мура». На этот раз основатель Nvidia отметил, что ИИ-чипы Nvidia развиваются с опережением и новый суперчип для дата-центров в 30 раз быстрее предыдущего поколения чипов при выполнении задач, связанных с искусственным интеллектом. «Наши системы прогрессируют гораздо быстрее, чем закон Мура», — сказал Хуанг в интервью TechCrunch во вторник. Заявление Хуанга прозвучало в момент, когда в индустрии стали появляться вопросы, касающиеся замедления прогресса в области искусственного интеллекта. Однако Nvidia, оставаясь ключевым игроком на рынке, который поставляет чипы таким ведущим ИИ-лабораториям, как Google, OpenAI и Anthropic, заявляет, что может двигаться быстрее закона Мура, потому что инновации происходят на всех уровнях — от архитектуры чипа до программных алгоритмов. «Мы можем создавать архитектуру, чип, систему, библиотеки и алгоритмы одновременно, — отметил Хуанг. — Если вы это сделаете, то сможете двигаться быстрее, чем по закону Мура, потому что вы сможете внедрять инновации по всему стеку». Глава Nvidia продемонстрировал на CES суперчип для центров обработки данных, лежащий в основе системы GB200 NVL72, который, по его словам, в 30–40 раз быстрее справляется с ИИ-вычислениями, чем предыдущий флагманский чип H100. Это значительное увеличение производительности, по мнению Хуанга, позволит снизить стоимость использования ИИ-моделей, требующих больших вычислительных мощностей, например, таких как модель o3 от OpenAI. Также подчёркивается, что в долгосрочной перспективе дорогостоящие модели рассуждения смогут использоваться для создания более качественных данных для последующего обучения ИИ-агентов, что приведёт к снижению затрат. Хуанг отвергает идею о замедлении прогресса ИИ и утверждает, что достижения в области аппаратного обеспечения могут непосредственно повлиять на дальнейшее развитие возможностей искусственного интеллекта. «Закон Мура был так важен в истории вычислительной техники, потому что он привел к снижению стоимости вычислений, — сказал Хуанг в интервью TechCrunch. — То же самое произойдет и с инференсом [запуском обученных нейросетей]: мы увеличим производительность, и в результате стоимость инференса станет меньше». Amazon вкладывает миллиарды в разработку ИИ-чипов, чтобы снизить зависимость от Nvidia
12.11.2024 [11:39],
Алексей Разин
Подразделение AWS американского интернет-гиганта Amazon давно входит в число крупнейших игроков рынка облачных услуг. Оно сильно зависит от компонентов и программного обеспечения Nvidia, но параллельно развивает и собственную инфраструктуру, используя наработки компании Annapurna Labs, купленной в 2015 году за $350 млн. 
Источник изображения: Amazon В следующем месяце, как сообщает Financial Times, компания должна продемонстрировать публике ускорители Trainium 2, которые способны справляться с обучением больших языковых моделей. Образцы этих ускорителей уже эксплуатируются стартапом Anthropic, в капитал которого Amazon вложила $4 млрд. Клиентами Amazon на этом направлении также являются компании Databricks, Deutsche Telekom, Ricoh и Stockmark. Вице-президент AWS по вычислительным и сетевым сервисам Дейв Браун (Dave Brown) заявил следующее: «Мы хотим быть абсолютно лучшим местом для эксплуатации Nvidia, но в то же время мы считаем нормой возможность иметь альтернативу». Уже сейчас ускорители семейства Inferentia обходятся при генерировании ответов ИИ-моделей на 40 % дешевле решений Nvidia. Когда речь идёт о расходах в десятки миллионов долларов, подобная экономия может иметь решающее значение при выборе вычислительной платформы. По итогам текущего года капитальные расходы Amazon могут достичь $75 млрд, а в следующем окажутся ещё выше. В прошлом году они ограничились $48,4 млрд, и величина прироста показывает, насколько важным компания считает финансирование своей инфраструктуры в условиях бурного развития рынка систем ИИ. Эксперты Futurum Group поясняют, что крупные провайдеры облачных услуг стремятся формировать собственную вертикально интегрированную и однородную по своему составу структуру используемых чипов. Большинство из них стремится разрабатывать собственные чипы для ускорителей вычислений, это позволяет снизить расходы, поднять прибыль, усилить контроль за доступностью чипов и развитием бизнеса в целом. «Дело не столько в чипе, сколько в системе в целом», — поясняет Рами Синно (Rami Sinno), директор Annapurna Labs по разработкам. По его словам, мало кто из компаний может повторить в больших масштабах то, что делает Amazon. Чипы собственной разработки позволяют Amazon потреблять меньше электроэнергии и повышать КПД собственных центров обработки данных. Представители TechInsights сравнивают чипы Nvidia с автомобилями с кузовом типа «универсал», тогда как решения Amazon собственной разработки напоминают более компактные хэтчбеки, заточенные под выполнение узкого спектра задач. Amazon не спешит делиться данными о тестировании быстродействия своих ускорителей, но чипы Trainium 2 должны по уровню быстродействия превзойти своих предшественников в четыре раза, по имеющимся данным. Само по себе появление альтернатив решениям Nvidia уже может быть высоко оценено клиентами AWS. Энергопотребление ИИ удалось снизить на 95 % без потерь, но Nvidia новый алгоритм вряд ли одобрит
10.10.2024 [08:55],
Анжелла Марина
В условиях растущей популярности искусственного интеллекта высокое энергопотребление ИИ-моделей становится всё более актуальной проблемой. Несмотря на то, что такие техногиганты, как Nvidia, Microsoft и OpenAI, пока не говорят об этой проблеме громко, явно преуменьшая её значение, специалисты из BitEnergy AI разработали технологию, способную значительно снизить энергопотребление без существенных потерь в качестве и скорости работы ИИ. 
Источник изображения: Copilot Согласно исследованию, новый метод может сократить использование энергии вплоть до 95 %. Команда называет своё открытие «Умножением линейной сложности» (Linear-Complexity Multiplication) или сокращённо L-Mul. Как пишет TechSpot, этот вычислительный процесс основан на сложении целых чисел и требует значительно меньше энергии и операций по сравнению с умножением чисел с плавающей запятой, которое широко применяется в задачах, связанных с ИИ. На сегодняшний день числа с плавающей запятой активно используются в ИИ для обработки очень больших или очень малых чисел. Они напоминают запись в бинарной форме, что позволяет алгоритмам точно выполнять сложные вычисления. Однако такая точность требует крайне больших ресурсов и уже вызывает определённые опасения, так как некоторым ИИ-моделям нужны огромные объёмы электроэнергии. Например, для работы ChatGPT требуется столько электроэнергии, сколько потребляют 18 000 домохозяйств в США — 564 МВт·ч ежедневно. По оценкам аналитиков из Кембриджского центра альтернативных финансов, к 2027 году ИИ-индустрия может потреблять от 85 до 134 ТВт·ч ежегодно. Алгоритм L-Mul решает эту проблему за счёт замены сложных операций умножения с плавающей запятой на более простые сложения целых чисел. В ходе тестирования ИИ-модели сохранили точность, при этом энергопотребление для операций с тензорами сократилось на 95 %, а для скалярных операций на 80 %. L-Mul также улучшает и производительность. Оказалось, что алгоритм превосходит текущие стандарты вычислений с 8-битной точностью, обеспечивая более высокую точность с меньшим количеством операций на уровне битов. В ходе тестов, охватывающих различные задачи ИИ, включая обработку естественного языка и машинное зрение, снижение производительности составило всего 0,07 %, что специалисты сочли незначительной потерей на фоне огромной экономии энергии. При этом модели на основе трансформеров, такие как GPT, могут получить наибольшую выгоду от использования L-Mul, поскольку алгоритм легко интегрируется во все ключевые компоненты этих систем. А тесты на популярных моделях ИИ, таких как Llama и Mistral, показали даже улучшение точности в некоторых задачах. Плохая новость заключается в том, что L-Mul требует специализированного оборудования и современные ускорители для ИИ не оптимизированы для использования этого метода. Хорошая новость заключается в том, что уже ведутся работы по созданию такого оборудования и программных интерфейсов (API). Одной из возможных преград может стать сопротивление со стороны крупных производителей чипов вроде Nvidia, которые могут замедлить внедрение новой технологии. Так как, например, Nvidia является лидером в производстве оборудования для искусственного интеллекта и маловероятно, что она так просто уступит позиции более энергоэффективным решениям. SK hynix приступила к массовому производству 12-слойной памяти HBM3E ёмкостью 36 Гбайт
26.09.2024 [04:51],
Алексей Разин
Накануне южнокорейская компания SK hynix в официальном пресс-релизе сообщила, что приступила к массовому производству памяти типа HBM3E с 12-слойных стеках ёмкостью по 36 Гбайт. Это не только самая современная память такого типа, но и самая ёмкая из ныне выпускаемых. Клиенты SK hynix получат эту память к концу текущего года. 
Источник изображения: SK hynix Нетрудно догадаться, что среди этих клиентов будет Nvidia, поскольку SK hynix остаётся главным поставщиком HBM различных поколений для этого разработчика графических процессоров и ускорителей вычислений. До сих пор, как отмечается в пресс-релизе южнокорейской компании, предельный объём в 24 Гбайта обеспечивался 8-слойным стеком HBM3E. Чипы DRAM, формирующие стек, компании удалось сделать на 40 % более тонкими, что в итоге позволило увеличить ёмкость стека на 50 % по сравнению с 8-слойным вариантом. SK hynix приступила к поставкам 8-слойных стеков HBM3E в марте этого года, поэтому соответствующий прогресс был ею достигнут всего за шесть месяцев. С 2013 года SK hynix поставляет полный спектр микросхем семейства HBM. Скорость передачи информации в 12-слойном стеке HBM3E достигает 9,6 Гбит/с. Увеличение количества слоёв в стеке при одновременном уменьшении толщины каждого слоя сочетается с улучшением свойств теплопроводности на 10 % по сравнению с памятью предыдущего поколения. На утренних торгах в Сеуле котировки акций SK hynix выросли на 8,3 % после заявления о начале производства самой современной памяти семейства HBM. Всего с начала года акции компании укрепились в цене более чем на 25 %. Такой динамике способствовал и благоприятный прогноз по выручке на текущий квартал от конкурирующего производителя памяти Micron Technology. Intel объявила о выделении производства чипов в независимую компанию и других шагах по выходу из кризиса
17.09.2024 [02:00],
Анжелла Марина
Компания Intel объявила о стратегических изменениях, направленных на укрепление своего финансового положения и технологического потенциала, включая выделение бизнеса по производству чипов в самостоятельную компанию и сделку с Amazon по производству ИИ-чипов. Компания нацелена на сокращение расходов и пересмотр инвестиций в производство, а также повышении эффективности капитальных вложений. Intel объявила о масштабной реструктуризации бизнеса, которая затронет практически все аспекты деятельности компании, начиная от производства и заканчивая продуктовым портфелем. Генеральный директор Intel Пэт Гелсингер (Pat Gelsinger) в своём обращении к сотрудникам 16 сентября 2024 года подчеркнул, что целью преобразований является повышение эффективности, оптимизация расходов и усиление фокуса на ключевых направлениях, таких как разработка x86-совместимых процессоров и бизнес по производству чипов (Intel Foundry). «Мы должны действовать быстро, чтобы создать более конкурентоспособную структуру затрат и достичь целевого показателя экономии в $10 млрд», — заявил Гелсингер. Одним из ключевых шагов станет превращение Intel Foundry в независимую дочернюю компанию внутри Intel. «Такая структура обеспечит нашим клиентам и поставщикам Foundry большую прозрачность и независимость от остального Intel, — пояснил Гелсингер. — Это также позволит Intel Foundry активнее привлекать внешнее финансирование и оптимизировать свою капитальную структуру для ускорения роста ». Компания также пересматривает свои инвестиции в производство, стремясь к большей эффективности капитальных вложений, в том числе приостанавливает проекты по строительству новых фабрик в Польше и Германии на два года, ориентируясь на текущий рыночный спрос. Что касается запуска производственного центра в Малайзии, то он будет достроен, но его ввод в эксплуатацию будет синхронизирован с рыночными условиями и загрузкой существующих мощностей. При этом Intel подтверждает свою приверженность инвестициям в производство в США и продолжает реализацию проектов в Аризоне, Орегоне, Нью-Мексико и Огайо. Вместе с тем, компания намерена сместить акцент с агрессивного наращивания производственных мощностей на более гибкое и эффективное планирование, соответствующее темпам развития технологий. 
Источник изображения: Intel Одновременно с этим объявлено о расширении стратегического партнёрства с Amazon Web Services (AWS). AWS выбрала Intel Foundry для производства нового ИИ-чипа на базе передовой технологии Intel 18A, а также специализированного процессора Xeon 6 на базе Intel 3. В рамках реструктуризации Intel также оптимизирует свой портфель продуктов, стремясь к большей интеграции и фокусировке на ключевых направлениях. «Наш главный приоритет — максимизировать ценность франшизы x86 на рынках клиентских устройств, периферийных вычислений и центров обработки данных, — подчеркнул генеральный директор. — Компания продолжит инвестировать в развитие ИИ-технологий, включая лидерство в категории ПК с искусственным интеллектом и укрепление позиций в центрах обработки данных». При этом для повышения эффективности ряд подразделений будут реорганизованы. В частности, Edge и Automotive будут объединены с CCG, а Integrated Photonics Solutions перейдёт в DCAI. Гелсингер в своём обращении также отметил, что для достижения намеченного целевого показателя экономии в $10 млрд Intel продолжит сокращать расходы. Для этого уже предприняты определённые действия: сокращено по программе добровольного увольнения более половины штата сотрудников (примерно 15 000), планируется отказаться от примерно двух третей недвижимости по всему миру к концу года, а также продать часть доли в Altera для получения дополнительных средств. «Нам предстоит принять ещё ряд сложных решений, — признал Гелсингер. — Но все эти меры направлены на то, чтобы превратить Intel в более гибкую, простую и эффективную систему, способную успешно конкурировать на рынке и обеспечивать долгосрочный рост». Стоит отметить, что недавно Intel получила около $3 млрд прямого финансирования в рамках федерального «Закона о чипах и науке» (CHIPS and Science Act) подписанного президентом Джо Байденом (Joe Biden) США в 2022 году. ИИ будет главным двигателем полупроводниковой отрасли в ближайшие несколько лет
05.09.2024 [10:36],
Алексей Разин
По мере роста котировок акций многих компаний, так или иначе связанных со сферой искусственного интеллекта, растёт и некоторый скептицизм в среде инвесторов, которые считают, что высокие вложения в эту область экономики не смогут себя оправдать в сжатые сроки. Один из поставщиков TSMC выражает уверенность, что многолетний цикл роста в полупроводниковой отрасли сейчас находится в самом начале. 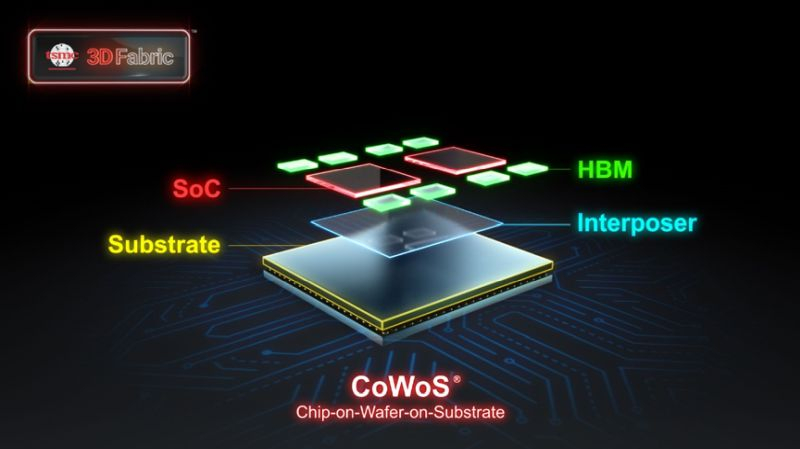
Источник изображения: TSMC В интервью телеканалу Bloomberg Сюй Мин Чи (Hsu Ming-chi), генеральный директор компании Scientech, которая снабжает своей продукцией крупнейшего контрактного производителя TSMC, назвал спрос на компоненты для систем искусственного интеллекта главной движущей силой в развитии полупроводниковой отрасли на ближайшие несколько лет. По его словам, за предыдущие 20 лет рынок полупроводниковой продукции рос буквально на 8 % в год, но в сфере компонентов для систем ИИ темпы роста в дальнейшем будут гораздо выше. «Этот бум в отрасли ИИ только начался», — пояснил Сюй Мин Чи. Крупнейший получатель выпускаемого Scientech оборудования, как он добавил, нарастил объёмы закупок за год почти в два или три раза. Во втором полугодии выручка данной компании должна последовательно увеличиться, как считает руководитель. В дальнейшем стабильность роста спроса в сегменте будет обеспечиваться появлением новых приложений, использующих искусственный интеллект. Scientech поставляет TSMC оборудование, которое компания использует при упаковке чипов по методу CoWoS. Он сейчас весьма востребован в связи с ажиотажным спросом на ускорители вычислений Nvidia, при производстве которых также применяется. По оценкам самой TSMC, тайваньская компания принимает участие в выпуске 99 % ускорителей вычислений для сферы ИИ, производимых во всём мире. В случае с Scientech причастность к этим процессам способствовала росту котировок акций на 80 % с начала текущего года. OpenAI забронировала 1,6-нм мощности TSMC для выпуска передовых ИИ-чипов
03.09.2024 [10:11],
Алексей Разин
Многие источники не раз упоминали о наличии у стартапа OpenAI амбиций по организации если не производства чипов для ускорителей вычислений, то хотя бы их разработки. По данным тайваньских СМИ, среди клиентов TSMC на передовой 1,6-нм техпроцесс A16 как раз может оказаться компания OpenAI, которая к моменту его освоения надеется располагать готовым проектом собственного чипа. 
Источник изображения: Intel Во всяком случае, об этом сообщает издание Economic Daily News. Основным заказчиком выпускаемых TSMC по технологии A16 чипов должна оказаться всё же Apple, по уже сложившейся практике и благодаря наличию у последней потребности в совершенствовании собственных мобильных процессоров. Освоить техпроцесс A16 компания TSMC рассчитывает в 2026 году, но обсуждать свои взаимоотношения с заказчиками публично она традиционно отказывается. По данным тайваньских источников, OpenAI активно обсуждала с TSMC возможность создания специализированной фабрики исключительно под её нужды. Однако после оценки потенциальных преимуществ план создания специализированного предприятия был отложен. Разработку чипов для OpenAI ведут такие американские компании, как Broadcom и Marvell Technology, в случае с первой из них OpenAI даже может оказаться в числе её четырёх крупнейших клиентов. К слову, первые чипы OpenAI могут выпускаться TSMC по более зрелому 3-нм техпроцессу, а выбор технологии A16 уже сделан для последующих поколений. Как отмечала TSMC ранее, 1,6-нм техпроцесс A16 по сравнению с ближайшим предшественником 2-нм N2P обеспечивает увеличение скорости переключения транзисторов на 8–10 % при неизменном напряжении, либо снижает энергопотребление на 15–20 % при том же уровне быстродействия. Плотность размещения транзисторов при этом удаётся увеличить на 10 %. Южнокорейский ускоритель вычислений Rebellions получит четыре 12-ярусных стека памяти HBM3E общим объёмом 144 Гбайт
25.08.2024 [06:36],
Алексей Разин
На этой неделе, как сообщает Business Korea, технический директор южнокорейского стартапа Rebellions О Чжин Ук (Oh Jin-wook) признался в намерениях ускорить вывод на рынок ускорителя вычислений Rebel Quad, который будет сочетать четыре стека памяти Samsung HBM3E с 12 ярусами в каждом. Ускоритель выйдет на рынок до конца года и будет почти полностью производиться Samsung Electronics. 
Источник изображения: Rebellions Корейская компания пытается составить конкуренцию ускорителям Nvidia и AMD, её решения также могут использоваться в системах искусственного интеллекта. Примечательно, что первое поколение ускорителей Atom компании Rebellions использовало микросхемы памяти типа GDDR6 совокупным объёмом 16 Гбайт, и новинка Rebel Quad будет первенцем марки с памятью типа HBM. Четыре стека HBM3E в 12-ярусном исполнении обеспечат совокупный объём памяти 144 Гбайт, и это позволяет изделию южнокорейского стартапа сравниться с ускорителями Nvidia семейства Blackwell. Непосредственно чип ускорителя Rebel Quad будет выпускаться компанией Samsung по 4-нм технологии, она же займётся и упаковкой, поэтому в этом отношении подрядчик предложит Rebellions комплексные услуги. Представители стартапа подчеркнули, что сейчас не рассматривают возможность сотрудничества с TSMC. Примечательно, что недавно Rebellions поглотила конкурирующую южнокорейскую компанию Sapeon, которая использует в своих ускорителях память типа SK hynix. Впрочем, схема сотрудничества с Samsung вряд ли оставляет Rebellions возможность присматриваться к другим поставщикам памяти. Китай обходит санкции США на ИИ-ускорители с помощью облака Amazon
23.08.2024 [17:46],
Анжелла Марина
Китайские компании нашли «дыру» в законодательстве США, получая доступ к передовым американским технологиям ИИ через облачные сервисы, такие как Amazon Web Services (AWS). Расследование Reuters показало, что минимум 11 китайских компаний, связанных с государственными структурами, обходят санкции, покупая доступ к запрещённым чипам и моделям ИИ через AWS. 
Источник изображения: Copilot Согласно недавно опубликованным тендерным документам, китайские организации используют облачные сервисы Amazon и сервисы других компаний для доступа к передовым американским чипам и возможностям искусственного интеллекта, которые они не могут приобрести иным способом. Известно, что правительство США ограничило экспорт передовых ИИ-чипов в Китай. Однако предоставление доступа к таким чипам или продвинутым ИИ-моделям через облако не является нарушением американских правил. Выяснилось, что по меньшей мере 11 китайских организаций, включая Шэньчжэньский университет и исследовательский институт Zhejiang Lab, стремились получить доступ к облачным сервисам, предоставляющим запрещённые чипы Nvidia. В одном из тендеров указано, что Шэньчжэньский университет потратил 200 000 юаней ($27 996) за аккаунт AWS для получения доступа к облачным серверам на базе чипов Nvidia A100 и H100 для неуточнённого проекта, получив эту услугу через посредника, компанию Yunda Technology. Институт Zhejiang Lab, разрабатывающий собственную модель ИИ GeoGPT, заявил в тендере в апреле о намерении потратить 184 000 юаней ($25 782) на услуги облачных вычислений AWS, так как его ИИ-модель не получала достаточной вычислительной мощности от местного поставщика услуг Alibaba. 
Источник изображения: aboutamazon.com Правительство США в настоящее время пытается ужесточить правила, чтобы ограничить доступ через облако. «Эта лазейка беспокоит меня уже много лет, и нам давно пора её устранить», — заявил Майкл Маккол (Michael McCaul), председатель Комитета по иностранным делам Палаты представителей США. При этом, в настоящий момент AWS не нарушает правил, установленных правительством США. «AWS соблюдает все применимые законы США, включая торговые законы, в отношении предоставления услуг AWS внутри и за пределами Китая», — заявил представитель облачного подразделения Amazon. Расследование Reuters также выявило, что Китай обходит ограничения США, закупая доступ к облачным сервисам Microsoft и OpenAI. В частности, Сычуаньский университет приобрёл 40 миллионов токенов Azure OpenAI, а Сучжоуский институт передовых исследований при Научно-техническом университете Китая (USTC) арендовал 500 облачных серверов, оснащённых чипами Nvidia A100. Несмотря на то, что Microsoft и OpenAI официально не поддерживают свои сервисы в Китае, а USTC находится в чёрном списке Минторга США, китайские компании получают доступ к технологиям через их облако. Также выяснилось, что Amazon не только предоставляет организациям из Поднебесной доступ к передовым чипам для ИИ, но и открывает возможность использования ИИ-моделей, таких как Claude от Anthropic. Для этого компания активно продвигает свои облачные сервисы на китайском рынке, подчёркивая доступность «лучших в мире моделей ИИ» для клиентов в регионе. В Индии анонсирован первый ИИ-чип, разработанный местной компанией
19.08.2024 [06:17],
Анжелла Марина
Компания Ola Electric, один из крупнейших производителей электрических двухколёсных транспортных средств в Индии, объявила о запуске своих собственных ИИ-чипов. Ожидается, что первые три чипа появятся на рынке в 2026 году, а четвёртый — Bodhi 2, будет запущен в 2028 году. Эти чипы станут первыми чипами для моделей искусственного интеллекта, разработанными в Индии, и на них уже наблюдается спрос на местном рынке. 
Источник изображения: Ola Electric/YouTube Как сообщает издание Tom's Hardware, первоначально Ola Electric представила три чипа — Bodhi 1, Ojas и Sarv 1. Чип Bodhi 1 предназначен для ИИ и подходит для работы с большими языковыми моделями (LLM) и визуальными моделями. Компания утверждает, что Bodhi 1 обеспечивает «лучшую в своём классе производительность», что является одним из важнейших факторов обработки данных в области искусственного интеллекта. Sarv 1 и Ojas предназначен для работы в дата-центрах. Также разработан чип Ojas Edge для специфических приложений, который может быть адаптирован под различные сферы, включая автомобильную, мобильную и IoT-технологии (Интернет вещей). Ola планирует внедрить Ojas Edge в свои новые электрические транспортные средства для управления системой зарядки и помощи водителю (ADAS). На презентации компания показала, что все прототипы этих чипов обеспечивают более высокую производительность и энергоэффективность по сравнению с GPU от Nvidia. Однако какой именно графический процессор использовался и точные параметры сравнения не раскрываются. Эксперты отмечают, что этот шаг отражает стремление Индии включиться в глобальную гонку ИИ-технологий, в которой сейчас лидируют США и Китай. С учётом того, что Индия, как самая густонаселённая страна в мире, обладает огромным потенциалом талантов и технических специалистов, которых она может использовать для развития своих ИИ-технологий, её участие в мировом процессе в этом направлении вряд ли может вызвать сомнения. Intel и Softbank обсуждали проект ИИ-ускорителя для конкуренции с Nvidia, но так и не договорились
15.08.2024 [12:02],
Алексей Разин
Как выясняется, среди вероятных партнёров Intel то и дело находились инициативные компании, готовые поручить ей выпуск передовых ускорителей для систем искусственного интеллекта. Помимо упущенной возможности сотрудничать с OpenAI в этой сфере, Intel также не стала сближаться с японской корпорацией SoftBank, которой принадлежит британский разработчик процессорных архитектур Arm. 
Источник изображения: Intel Издание Financial Times выяснило, что в течение нескольких предыдущих месяцев SoftBank пыталась договориться с Intel о выпуске специализированных ИИ-чипов, разработанных выходцами из купленной ею компании Graphcore. В данной ситуации Intel должна была выступать в роли контрактного производителя чипов. После того, как переговоры с Intel привели к неудовлетворительному результату, SoftBank решила сосредоточиться на переговорах с TSMC. Если бы сотрудничество с Intel состоялось, как продолжают источники, SoftBank смогла бы претендовать на часть американских субсидий по так называемому «Закону о чипах», поскольку выпуск соответствующих компонентов для её нужд осуществлялся бы на территории США. Как утверждает источник, переговоры SoftBank с Intel развалились по вине последней из сторон. По крайней мере, на этом настаивает первая из них. Заказчика не устраивали возможности Intel в части скорости выпуска чипов и объёма их производства. Тем не менее, учитывая высокую загруженность TSMC подобными заказами, Intel с точки зрения SoftBank всё ещё не списывается со счетов. Руководство SoftBank рассчитывало привлечь к финансированию данной инициативы потенциальных покупателей подобных ускорителей, созданных с использованием разработок Graphcore. Выход SoftBank в этот сегмент рынка мог бы навредить отношениям Arm и Nvidia, поскольку последняя является крупным клиентом этого британского холдинга. Впрочем, сейчас рынок компонентов для ИИ является лакомым кусочком для многих компаний, и потенциальная выгода могла бы компенсировать подобный риск. SoftBank не теряет надежды создать прототипы собственного ускорителя в ближайшие месяцы, но рассчитывать на возможности TSMC в этой сфере затруднительно из-за высокой нагрузки на эту тайваньскую компанию. Intel была бы полезна SoftBank в этом случае и своими компетенциями в разработке чипов, а не только как контрактный производитель. Проект, финансирование которого потребовало бы многих десятков миллиардов долларов США, планировалось реализовать с участием арабских инвесторов. Недавно стало известно, что Intel избавилась от купленных в прошлом году акций Arm, чтобы максимально мобилизовать собственные финансовые ресурсы. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться