|
Опрос
|
реклама
Быстрый переход
Новая ИИ-модель от DeepMind смогла бы получить «золото» на Международной математической олимпиаде
08.02.2025 [19:23],
Владимир Мироненко
DeepMind, дочернее предприятие Google, специализирующееся на исследованиях в сфере искусственного интеллекта (ИИ), сообщило о новых достижениях ИИ-модели AlphaGeometry2 в решении геометрических задач. В недавно опубликованном исследовании DeepMind сообщается, что AlphaGeometry2 успешно решила 84 % задач (42 из 50) Международной математической олимпиады (IMO) с 2000 по 2024 год, набрав средний балл золотого медалиста (40,9). 
Источник изображения: Google AlphaGeometry2 является улучшенной версией ИИ-системы AlphaGeometry, вышедшей в январе прошлого года. В июле прошлого года DeepMind продемонстрировала возможности системы, объединившей ИИ-модели AlphaProof и AlphaGeometry2, которой удалось решить 4 из 6 задач IMO. AlphaGeometry2, используя лингвистическую модель на основе архитектуры Gemini и усовершенствованный механизм символической дедукции способна определять стратегии решения задач с точностью, превосходящей возможности большинства экспертов-людей. Принятый подход объединяет два основных компонента: лингвистическую модель, способную генерировать предложения на основе подробного геометрического описания, и символический механизм DDAR (Deductive Database Arithmetic Reasoning), который проверяет логическую связность предлагаемых решений, создавая дедуктивное замыкание на основе доступной информации. Проще говоря, модель Gemini AlphaGeometry2 предлагает символическому механизму шаги и конструкции на формальном математическом языке, и механизм, следуя определённым правилам, проверяет эти шаги на логическую согласованность. Ключевым элементом, который позволил AlphaGeometry2 превзойти по скорости предшественника AlphaGeometry, является алгоритм SKEST (Shared Knowledge Ensemble of Search Trees), который реализует итеративную стратегию поиска, основанную на обмене знаниями между несколькими параллельными деревьями поиска. Это позволяет одновременно исследовать несколько путей решения, увеличивая скорость обработки и улучшая качество сгенерированных доказательств. Эффективность системы удалось значительно повысить с новой реализацией DDAR на C++, что в 300 раз увеличило её скорость по сравнению с версией, написанной на Python. Вместе с тем из-за технических особенностей AlphaGeometry2 пока ограничена в возможности решать задачи с переменным числом точек, нелинейными уравнениями или неравенствами. Поэтому DeepMind изучает новые стратегии, такие как разбиение сложных задач на подзадачи и применение обучения с подкреплением для выхода ИИ на новый уровень в решении сложных математических задач. Как сообщается, AlphaGeometry2 технически не является первой ИИ-системой, достигшей уровня золотого медалиста по геометрии, но она первая, достигшая этого с набором задач такого размера. При этом AlphaGeometry2 использует гибридный подход, поскольку модель Gemini имеет архитектуру нейронной сети, в то время как её символический механизм основан на правилах. Сторонники использования нейронных сетей утверждают, что интеллектуальных действий, от распознавания речи до генерации изображений, можно добиться только благодаря использованию огромных объёмов данных и вычислений. В отличие от символических систем ИИ, которые решают задачи, определяя наборы правил манипуляции символами, предназначенных для определённых задач, нейронные сети пытаются решать задачи посредством статистической аппроксимации (замены одних результатов другими, близкими к исходным) и обучения на примерах. В свою очередь, сторонники символического ИИ считают, что он более подходит для эффективного кодирования глобальных знаний. В DeepMind считают, что поиск новых способов решения сложных геометрических задач, особенно в евклидовой геометрии, может стать ключом к расширению возможностей ИИ. Решение задач требует логического рассуждения и способности выбирать правильный шаг из нескольких возможных. По мнению DeepMind, эти способности будут иметь решающее значение для будущего универсальных моделей ИИ. Крупнейшие IT-компании США потратят более $300 млрд на развитие ИИ в 2025 году
08.02.2025 [06:00],
Анжелла Марина
Ведущие технологические компании США продолжают наращивать расходы на развитие искусственного интеллекта (ИИ), несмотря на рыночные риски. Капитальные затраты в 2024 году Microsoft, Alphabet, Amazon и Meta✴ достигли в совокупности рекорда в $246 млрд, что на 63 % больше, чем годом ранее. В 2025 году эти вложения могут превысить $320 млрд. 
Источник изображения: Copilot Основные средства будут направлены на строительство дата-центров и закупку специализированных чипов для разработки больших языковых моделей (LLM), а лидером по объёму инвестиций станет компания Amazon, которая запланировала вложить на эти цели более $100 млрд, сообщает Financial Times. Однако увеличение расходов на ИИ вызвало обеспокоенность инвесторов. Рынок отреагировал на масштабные инвестиционные планы, объявленные наряду с финансовыми результатами за четвёртый квартал. После публикации отчётов о более слабом, чем ожидалось, росте облачных подразделений и увеличении капитальных расходов, рыночная стоимость Microsoft и Alphabet (материнская компания Google) снизилась у каждой на $200 млрд. Инвесторы выражают обеспокоенность тем, что удвоение расходов на ИИ без соразмерного увеличения доходов может привести к сокращению капитала, который мог бы быть направлен на выкуп акций и выплату дивидендов, а также к недофинансированию других направлений бизнеса. Тем более, что компании пока не предоставили чётких данных о доходах от новых ИИ-продуктов, например, таких как Gemini и Copilot. При этом, появление инновационной и недорогой ИИ-модели R1 китайского стартапа DeepSeek в начале января ещё сильнее усилило опасения инвесторов. Заявление DeepSeek о создании модели, сопоставимой по возможностям с продуктами Google и OpenAI, но при этом значительно более дешёвой, моментально привело к падению акций производителя чипов Nvidia на 17 %. Несмотря на давление со стороны акционеров, генеральные директора крупнейших IT-компаний продолжают отстаивать свои стратегии. Так, Сундар Пичаи (Sundar Pichai) из Google заявил, что планирует увеличить расходы компании на 42 % вплоть до $75 млрд в 2025 году, назвав ИИ «возможностью столетия». Глава Microsoft Сатья Наделла (Satya Nadella) подтвердил намерение вложить $80 млрд в развитие облачного сервиса Azure, а генеральный директор Amazon Энди Джесси (Andy Jassy) объявил, что компания инвестирует в ИИ более $100 млрд. Meta✴, напротив, получила положительную реакцию рынка. Её акции выросли, несмотря на обещание Марка Цукерберга (Mark Zuckerberg) вложить «сотни миллиардов» долларов в ИИ. Отмечается, что успех компании связан с тем, что её технологии уже приносят хорошую отдачу — например, при использование ИИ для улучшения таргетинга рекламы на Facebook✴ и Instagram✴. Для сравнения, Google наоборот сталкивается с трудностями в интеграции ИИ в свой поисковик, где новые функции, такие как «ИИ-обзоры», потенциально, по мнению экспертов, вредят традиционной рекламной модели компании. Стоит сказать, что ажиотаж вокруг ИИ не ограничивается публичными компаниями. Сэм Альтман (Sam Altman) из OpenAI заключил партнёрство с SoftBank и Oracle для инвестирования $100 млрд в инфраструктуру, связанную с ИИ в США, с потенциальным увеличением до полутриллиона долларов в будущем. «Может ли в какой-то момент наступить зима ИИ? Конечно, — сказал Риши Джалурия (Rishi Jaluria), аналитик из RBC Capital Markets. — Но если вы находитесь в положении лидера, вы просто не можете сбавлять обороты». DeepSeek набрал 20 млн активных пользователей — больше только у ChatGPT
08.02.2025 [01:11],
Анжелла Марина
Китайский стартап DeepSeek, разработавший бюджетную ИИ-модель, стал настоящей сенсацией в мире технологий. Всего за 20 дней после своего запуска приложение привлекло 20 млн активных пользователей. По данным TrendForce, DeepSeek занял второе место среди самых популярных приложений в мире, уступив лишь ChatGPT. На третьем месте оказалась нейросеть Doubao от ByteDance. 
Источник изображения: Solen Feyissa / Unsplash Приложение DeepSeek, запущенное 11 января, уже к 31 января достигло 22,15 млн активных пользователей в день. Это составляет 41,6% от аудитории ChatGPT, которая в тот же период насчитывала 53,23 млн ежедневных пользователей. Ранее лидером китайского рынка был Doubao с 17 млн пользователей, но DeepSeek удалось обойти его по популярности. Успех DeepSeek также прослеживается и в рейтингах Apple App Store, где приложение поднялось на первое место в 157 странах, включая США. Кроме того, по данным сервиса SimilarWeb, сайт DeepSeek обошёл по посещаемости Google Gemini всего за неделю. Так, на момент 31 января DeepSeek посетили 2,4 млн пользователей из США, тогда как для Gemini эта цифра составила 1,5 млн. Отметим, что стремительная популярность DeepSeek привела к активной реакции со стороны крупных китайских компаний. Tencent, Baidu и Alibaba уже объявили о планах интеграции модели DeepSeek в свои облачные платформы. Кроме того, четыре ведущих производителя GPU из Китая, такие как Huawei Ascend, Moore Threads, iluvatar и MetaX, выразили готовность поддерживать развитие стартапа. Google проводит внутреннее тестирование режима искусственного интеллекта в поисковике
07.02.2025 [22:27],
Геннадий Детинич
Покупателей рекламы в Google и владельцев сайтов, которые ожидают переходов по ссылкам после запросов в поисковике, может ожидать неприятный сюрприз в виде снижения посещаемости, который способен принести с собой режим искусственного интеллекта после его интеграции в поисковик компании или в приложения Google. Как раз такой проходит внутреннее тестирование, на что указала утечка из Google. 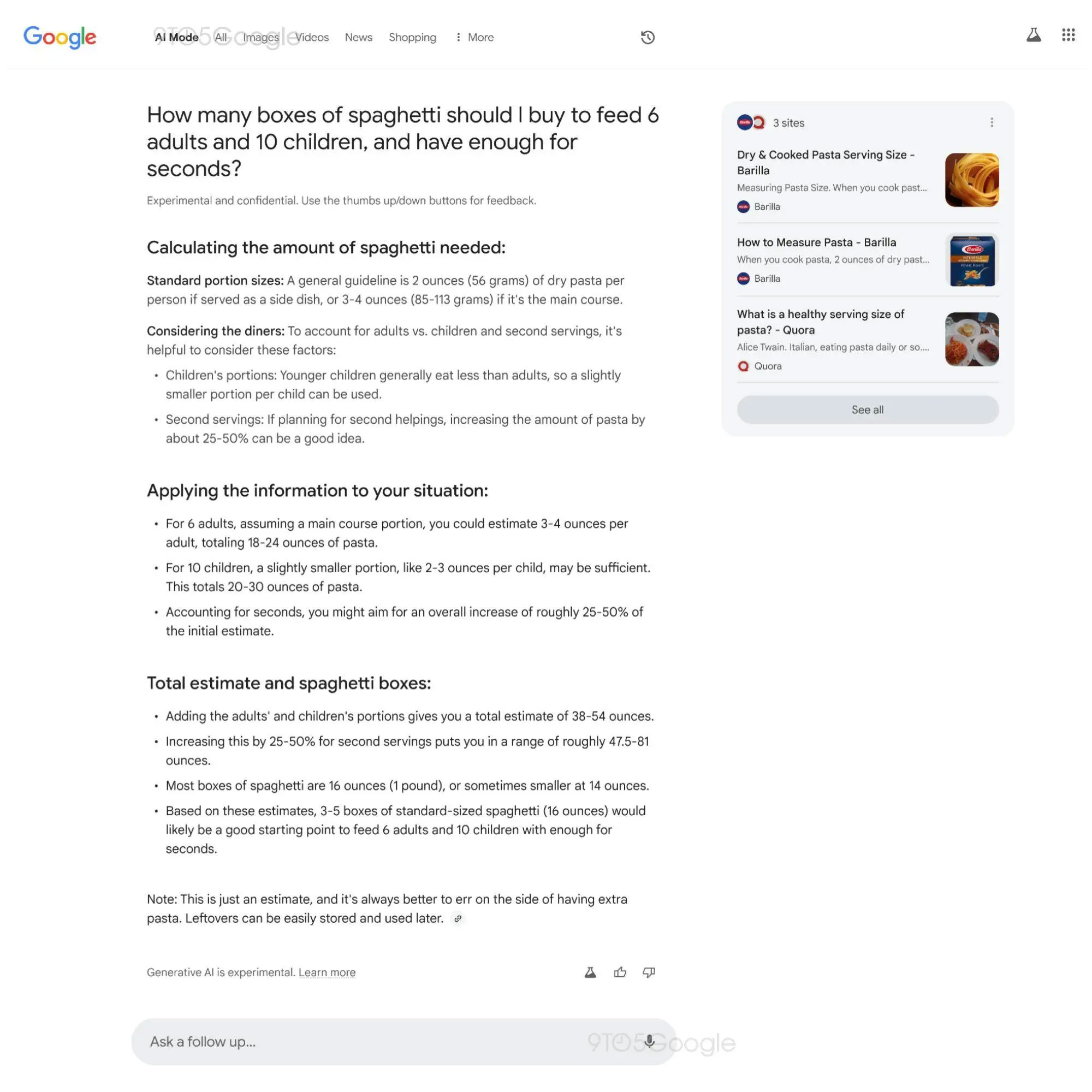
Источник изображения: 9to5Google Скриншотом с результатами работы ИИ после заданного пользователем вопроса в поисковике поделился сайт 9to5Google. Исходя из увиденного, можно сделать вывод, что ИИ даёт готовый ответ на заданный вопрос без необходимости переходить на странички и самостоятельно собирать разбросанную по сайтам информацию. Более того, вопрос может быть не до конца сформирован, оставляя ИИ возможность додумать самостоятельно, что ещё может понадобиться пользователю. Если процитировать выдержку из внутренней переписки Google, режим искусственного интеллекта описывается как «интеллектуальный поиск информации для вас — организация информации в удобную для восприятия разбивку со ссылками для изучения контента в интернете». Но после просмотра реферата или выжимки, многие ли пойдут искать первоисточник? А ведь ИИ способен галлюцинировать, и первоисточниками пренебрегать нельзя. Впрочем, есть категория запросов, где ИИ-ответ поисковика будет определённо востребован при недостатке времени на самостоятельный поиск. Это сравнения, советы, обобщения и ряд других, а также реализация возможности задать уточняющий вопрос по теме. Всё это, похоже, или уже есть и тестируется, или будет создано. Также исходя из некоторых деталей на скриншоте, можно заподозрить, что поиск основывается на модели Gemini 2.0. В частности, в примере показан ответ ИИ на вопрос, сколько нужно упаковок спагетти, чтобы накормить 6 взрослых и 10 детей и чтобы хватило для добавки. ИИ подробно отвечает на вопрос с примерным расчетом порций. Также интересны ответы ИИ в поисковике на вопросы «Что мне нужно, чтобы начать заниматься акваскейпингом — дизайном интерьера аквариумов», а также вслед за этим задаётся вопрос о ближайшем магазине с товарами для этого хобби. С таким ИИ-помощником не придётся ходить по ссылкам и смотреть рекламу, а также далеко не все сайты попадут в сводку. Но Google вынуждена следовать за конкурентами в таком начинании, иначе просто потеряет аудиторию. Meta✴ в партнёрстве с ЮНЕСКО запускает новую программу сбора данных для улучшения речи и перевода ИИ
07.02.2025 [18:49],
Сергей Сурабекянц
LTPP (Language Technology Partner Program — партнёрская программа по языковым технологиям) — совместная инициатива ЮНЕСКО и Meta✴ по поиску авторов, которые могут предоставить более 10 часов записей речи с транскрипциями, большие объёмы письменного текста и наборы переведённых текстов на разных языках. В дальнейшем эти данные будут интегрированы в ИИ-модели с открытым исходным кодом для распознавания речи и перевода. Усилия LTPP будут сосредоточены на недостаточно обслуживаемых языках для поддержки работы, уже проводимой в этом направлении ЮНЕСКО. «В конечном итоге наша цель — создать интеллектуальные системы, которые могут понимать и реагировать на сложные потребности человека, независимо от языка или культурного происхождения», — заявил представитель Meta✴. В дополнение к новой инициативе Meta✴ опубликовала открытый исходный код программы для оценки производительности моделей языкового перевода. Тест, состоящий из предложений, созданных лингвистами, поддерживает семь языков, и доступен на платформе разработки ИИ Hugging Face. Meta✴ продолжает расширять количество языков, поддерживаемых её ИИ-моделями и развивать функции автоматического перевода для создателей контента. В сентябре прошлого года компания начала тестирование инструмента для перевода голосов в Instagram✴ Reels, который дублирует речь создателя на другом языке с автоматическим липсинком. На сегодняшний день обработка на платформах Meta✴ контента на языках, отличных от английского, далека от совершенства. По некоторым данным, в соцсети Facebook✴ 79 % дезинформации о COVID на итальянском и испанском языках не были распознаны и отмечены системой, по сравнению с 29 % на английском языке. А сообщения на арабском языке, наоборот, часто ошибочно помечаются как разжигающие ненависть. Meta✴ заявила, что принимает меры по улучшению своих технологий перевода и модерации. И, хотя компания позиционирует обе свои языковые инициативы как филантропические, нет никаких сомнений, что главным бенефициаром этих программ станет именно Meta✴, которая сможет существенно улучшить качество распознавания речи и перевода. Для мелких производителей ИИ-чипов DeepSeek оказалась не угрозой, а шансом
07.02.2025 [18:35],
Павел Котов
DeepSeek потрясла мировой рынок искусственного интеллекта во главе с американскими компаниями — один только производитель ИИ-ускорителей Nvidia потерял несколько сотен миллиардов долларов капитализации. И пока лидеры рынка пытаются преодолеть последствия, мелкие производители видят в случившемся шанс нарастить масштабы деятельности, пишет CNBC. 
Источник изображения: Solen Feyissa / unsplash.com «Разработчики очень хотят заменить дорогие и закрытые модели OpenAI моделями с открытым исходным кодом, такими как DeepSeek R1», — считает Эндрю Фельдман (Andrew Feldman), гендиректор стартапа Cerebras Systems, выпускающего чипы для ИИ. Компания выступает конкурентом Nvidia и предлагает облачные сервисы в собственных кластерах. Выход DeepSeek R1 спровоцировал один из крупнейших всплесков спроса на услуги компании за всю её историю, и по словам её главы, показал, что рост рынка ИИ не будет связан с доминированием всего одной компании, потому что открытые модели не привязаны к определённым оборудованию или ПО. DeepSeek утверждает, что её рассуждающая модель потребляет меньше вычислительных ресурсов, чем американские аналоги, и обучается без передовых ускорителей. Китайский стартап способен ускорить процесс развёртывания новых технологий в области ИИ-ускорителей, охватив и обучение моделей, и их запуск. Nvidia занимает доминирующее положение на рынке оборудования для обучения ИИ, и многие её конкуренты считают, что у них есть возможность расширить своё присутствие в области запуска уже обученных моделей, обещая клиентам более высокую эффективность за меньшие деньги. Обучение ИИ требует значительных вычислительных ресурсов, но для работы уже обученной системы достаточно и менее мощного оборудования, ограниченного более узким кругом задач. И здесь разработчики альтернативных ускорителей отмечают рост спроса, потому что многие клиенты готовы решать свои задачи на основе уже обученных моделей DeepSeek. Аналитики и отраслевые эксперты уверены, что китайская лаборатория, которая понизила планку на обучение и запуск систем ИИ, окажет влияние на развитие всей отрасли: если услуги запуска уже обученных моделей станут дешевле, технологии ИИ начнут внедряться активнее, потому что снижение затрат приводит к повышению спроса — это явление называется парадоксом Джевона. Рост спроса подтвердили представители специализирующихся на разработке ускорителей стартапов d-Matrix и Etched. «Благодаря широкой доступности моделей малого размера они послужили катализатором эпохи вывода [ИИ]», — рассказали в d-Matrix. «Компании переводят свои затраты с обучающих кластеров на кластеры вывода», — добавили в Etched, к которой с момента выхода DeepSeek R1 обратились уже десятки корпоративных клиентов. Наконец, следует помнить, что небезграничны и ресурсы Nvidia — даже технологический гигант её масштаба физически не сможет удовлетворить весь мировой спрос на ИИ-ускорители. А значит, у мелких игроков действительно есть шанс. Topaz Labs представила диффузную ИИ-модель, которая автоматически улучшает старые видео
07.02.2025 [18:32],
Владимир Мироненко
Компания Topaz Labs, специализирующая на разработке программного обеспечения для редактирования фотографий и видео, представила модель ИИ Project Starlight для повышения качества старых кадров из домашней видеоколлекции или архивного контента, качество которого могло со временем ухудшиться в ходе хранения на традиционных носителях. 
Источник изображения: Topaz Labs По словам разработчика, это первая в истории диффузионная модель, созданная для этих целей, и ей не требуется ручной ввод данных для исправления видео. Сообщается, что Project Starlight была создана с нуля с использованием новой архитектуры модели с более чем 6 млрд параметров, и её работа поддерживается передовыми ускорителями NVIDIA. Для сравнения, вышедшая в мае 2024 года большая языковая модель GPT-4o от OpenAI с возможностью обработки текста, аудио, изображений и видео в качестве входных данных, изначально имела 8 млрд параметров. Topaz Labs утверждает, что модель «точно восстанавливает детали» и обеспечивает «непревзойдённое восстановление деталей в сочетании с непревзойдённой временной согласованностью». По словам компании, именно в этом и заключается суть её новой модели: улучшение нескольких кадров для достижения высококачественных результатов восстановления без артефактов движения или несоответствий между кадрами и объектами. Project Starlight также автоматически удаляет шумы, устраняет размытость, масштабирует и сглаживает кадры по запросу. Для работы с этой ИИ-моделью вовсе не требуется наличие специальных знаний в области обработки видео. Возвращение старого видео к жизни включает в себя несколько процессов, в том числе масштабирование, цветокоррекцию и сортировку, интерполяцию кадров, устранение повреждений и восстановление звука. Для каждого из этих вариантов восстановления уже созданы инструменты на базе ИИ, но для достижения наилучших результатов всем процессом в настоящее время должны управлять люди. Topaz Labs сообщила, что пользователи могут с помощью её ИИ-модели бесплатно восстанавливать видео длительностью до 10 с, в то время как клипы продолжительностью до 5 минут будут иметь максимальное разрешение 1080p и для этого потребуются кредиты. Версия для корпоративных пользователей поддерживает восстановление более продолжительных видео и с более высоким разрешением. Пока неизвестно, будет ли Project Starlight работать локально или будет интегрирована в другие приложения компании. Главный европейский конкурент OpenAI выпустил ИИ-ассистента Mistral Le Chat для iOS и Android
07.02.2025 [08:34],
Анжелла Марина
Французский стартап Mistral объявил о крупном обновлении своего ИИ-ассистента Le Chat. В борьбе за внимание пользователей разработчики не только значительно улучшили веб-интерфейс, добавили веб-поиск и генерацию изображений по текстовым запросам, но и только что выпустили мобильное приложение для устройств iOS и Android. 
Источник изображения: Copilot Одним из ключевых преимуществ Le Chat является скорость работы. Компания утверждает, что использует «самые быстрые на планете алгоритмы принятия решений» и её чат-бот может обрабатывать до 1000 слов в секунду. Кроме того, как пишет TechCrunch, Mistral заявляет о превосходном качестве генерируемых изображений благодаря использованию модели Flux Ultra, разработанной немецкой компанией Black Forest Labs. Разрабатывая собственные большие языковые модели (LLM), Mistral активно выпускает модели с открытым исходным кодом под лицензией Apache 2.0, а также предлагает коммерческое использование своих флагманских версий ИИ, таких как Mistral Large и Pixtral Large, через API или облачных партнёров, включая Azure AI Studio, Amazon Bedrock и Google Vertex AI. Что касается мобильного приложения, то его выпуск является стратегическим для компании шагом, направленным на повышение доступности и удобства использования ИИ-бота, которому можно задавать вопросы и получать ответы в формате интерактивного общения в чате. Отмечается, что за последние месяцы Le Chat претерпел значительные улучшения, превратившись в «компетентного ИИ-помощника». Недавно была добавлена поддержка веб-поиска с указанием источников, а также возможность генерировать изображения и взаимодействовать с платформой для редактирования текста или кода. Стоит также сказать, что компания подписала соглашение с Agence France-Presse (AFP), чтобы обеспечить надёжность и достоверность информации, предоставляемой её ИИ-моделями. Для пользователей, которым требуется больше возможностей, Mistral предлагает Pro-подписку на Le Chat стоимостью $15 в месяц. Pro-подписчики получают доступ к самой производительной модели, повышенные лимиты и улучшенную конфиденциальность. Помимо потребительского сегмента, компания активно развивает корпоративные услуги, с возможностью развёртывания Le Chat в локальной среде с использованием пользовательских моделей (ИИ-агентов) и интерфейсов. Это особенно важно для организаций, работающих в сфере обороны или финансов, где требуется повышенный уровень безопасности и контроля над данными, что, по словам Mistral, «не представляется возможным в настоящее время с ChatGPT Enterprise или Claude Enterprise». Amazon потратит в этом году на развитие вычислительной инфраструктуры $100 млрд — больше Google и Microsoft
07.02.2025 [08:32],
Алексей Разин
Интернет-гигант Amazon оказался последним среди крупнейших игроков рынка облачных вычислений, выступивших в этом квартале с отчётами за предыдущий. Капитальные затраты компании в этом году планируется увеличить с $83 до $100 млрд, тем самым обойдя конкурентов в лице Microsoft, Google и Meta✴ Platforms. 
Источник изображения: Amazon Напомним, последняя собирается в текущем году на развитие своей инфраструктуры потратить от $60 до $65 млрд, холдинг Alphabet (Google) выделил $75 млрд, а являющаяся главным акционером OpenAI корпорация Microsoft расщедрилась на $80 млрд. Как видим, AWS готова возглавить этот рейтинг с большим отрывом. По словам генерального директора Энди Джесси (Andy Jassy), основная часть капитальных затрат Amazon в текущем году будет направлена на развитие инфраструктуры ИИ подразделения AWS. Глава Amazon попытался убедить инвесторов, что увеличение капитальных затрат стоит того, назвав текущий момент «бизнес-возможностью, которая даётся раз в жизни». Подобное решение отвечает интересам как бизнеса, так и клиентов Amazon, равно как и акционеров компании, по словам её руководителя. Некоторая часть капитальных затрат всё же будет направлена на развитие торгового бизнеса, чтобы увеличить скорость доставки и снизить стоимость обслуживания клиентов. Сооснователь OpenAI Джон Шульман не проработал в Anthropic и полугода
07.02.2025 [06:40],
Алексей Разин
Бурное развитие систем искусственного интеллекта происходило в последние пару лет при непосредственном участии американского стартапа OpenAI, создавшего нашумевший ChatGPT, но его кадровый состав успел изрядно измениться. В конкурирующую Anthropic менее полугода назад перешёл работать один из основателей первой из компаний Джон Шульман (John Schulman), но долго там не продержался. 
Источник изображения: сайт Джона Шульмана В коллектив Anthropic один из главных разработчиков ChatGPT влился в августе прошлого года. Своё решение он тогда обосновал стремлением больше времени уделять регулированию работы искусственного интеллекта и сосредоточиться на технической части подобной деятельности. По его словам, работа в Anthropic позволяла ему развиваться в окружении единомышленников и заниматься теми вещами, которые ему были наиболее интересны. Непосредственно Шульман о своём уходе из Anthropic официально ничего не сообщил, как и не обозначил своих дальнейших намерений. Представители Anthropic в комментариях Bloomberg подтвердили уход Джона Шульмана из компании и выразили своё сожаление по этому поводу, хотя и поддержали стремление бывшего коллеги искать новые возможности для самореализации. Стремительно развивающийся рынок систем искусственного интеллекта даёт неплохие карьерные перспективы тем, кто уже успел себя зарекомендовать в качестве ценного специалиста или руководителя. Google начнёт помечать фотографии пользователей, в которые «вмешался» ИИ
07.02.2025 [05:11],
Анжелла Марина
Приложение «Google Фото» начнёт использовать цифровые водяные знаки SynthID для фотографий, отредактированных с помощью генеративного искусственного интеллекта (ИИ). По заявлению Google, новая функция предназначена для облегчения идентификации изображений, которые были изменены с помощью инструмента Reimagine в Magic Editor. 
Источник изображений: Google Magic Editor позволяет легко редактировать фотографии через текстовые запросы, добавляя или удаляя различные детали. Хотя сами по себе ИИ-инструменты не представляют угрозы, Magic Editor может создавать неправомерные компиляции, например разбившиеся вертолёты, сцены аварий, причём без явных меток, указывающих на то, что изображение было изменено. Водяные знаки призваны решить эту проблему. Однако SynthID визуально не изменяет изображение и чтобы понять, что оно было отредактировано ИИ, придётся дополнительно использовать функцию проверки «Об изображении». Более того, Google признаёт, что некоторые небольшие изменения, выполненные через Magic Editor, могут быть настолько незначительными, что SynthID не сможет идентифицировать эти изменения и применить маркировку. Эксперты отмечают, что хотя водяные знаки могут помочь в идентификации компиляций, этой технологии недостаточно для масштабной проверки контента, созданного нейросетями. Для надёжности потребуется использовать целый комплекс подходов и программных средств. Отметим, что система водяных знаков используется в нейросети Google Imagen AI, которая генерирует изображения на основе текста. Аналогичные инструменты были разработаны и другими компаниями, например, функция Content Credentials компании Adobe защищает от несанкционированного доступа к метаданным и позволяет авторам добавлять информацию о себе. Технология SynthID была разработана командой DeepMind и представляет собой цифровой метатег, встроенный в изображения, видео, аудио или текст. Этот тег позволяет идентифицировать, были ли файлы созданы или изменены с помощью ИИ. Исследователи обучили конкурента OpenAI o1 менее чем за полчаса и $50
07.02.2025 [05:06],
Анжелла Марина
Исследователи из Стэнфорда и Университета Вашингтона создали ИИ-модель, которая превосходит OpenAI в решении математических задач. Модель, получившая название s1, была обучена на ограниченном наборе данных из 1000 вопросов методом дистилляции. Это позволило достичь высокой эффективности при минимальных ресурсах и доказать, что крупным компаниям, таким как OpenAI, Microsoft, Meta✴ и Google, возможно не придётся строить огромные дата-центры, заполняя их тысячами графических процессоров Nvidia. 
Источник изображения: Growtika / Unsplash Метод дистилляции, который применили учёные, стал ключевым решением в эксперименте. Этот подход позволяет небольшим моделям обучаться на ответах, предоставленных более крупными ИИ-моделями. В данном случае, как пишет The Verge, s1 быстро улучшала свои способности, используя ответы, полученные от модели искусственного интеллекта Gemini 2.0 Flash Thinking Experimental, разработанной компанией Google. Модель s1 была создана на основе проекта Qwen2.5 от Alibaba (подразделение Cloud) с открытым исходным кодом. Первоначально исследователи использовали набор данных из 59 000 вопросов, но в ходе экспериментов пришли к выводу, что увеличение объёма данных не даёт значимых улучшений, и для финального обучения использовали лишь небольшой набор из 1000 вопросов. При этом было использовано всего 16 GPU Nvidia H100 в облаке, за использование которых пришлось заплатить менее $50. В s1 была также применена техника под названием «масштабирование времени тестирования», которая позволяет модели «поразмышлять» перед генерацией ответа. Также исследователи стимулировали модель к перепроверке своих выводов путём добавления команды в виде слова «Wait» («Жди»), что заставляло ИИ продолжать рассуждение и исправлять ошибки в своих ответах. Утверждается, что модель s1 показала впечатляющие результаты и смогла превзойти OpenAI o1-preview на 27 % при решении математических задач. Недавно нашумевшая модель R1 от DeepSeek также использовала аналогичный подход и за сравнительно небольшие деньги. Правда, теперь OpenAI обвиняет DeepSeek в извлечении информации из своих моделей в нарушение условий обслуживания. Стоит сказать, что и в условиях использования Google Gemini указано, что её API запрещено применять для создания конкурирующих чат-ботов. Рост количества меньших и более дешёвых моделей может, по словам экспертов, перевернуть всю отрасль и доказать, что нет необходимости инвестировать миллиарды долларов на обучение ИИ, строить огромные центры обработки данных и закупать в большом количестве GPU. Представлен робот iDEAR для быстрого извлечения из компьютера всех ценных компонентов
06.02.2025 [18:57],
Сергей Сурабекянц
Электронные устройства устаревают с пугающей скоростью, и проблема их утилизации становится все более актуальной. К 2030 году мировое производство электронных отходов достигнет 82 миллионов тонн в год, а нынешнее состояние их переработки очень далеко от идеального. Для исправления ситуации немецкие исследователи из института Фраунгофера разработали автоматизированную систему интеллектуальной разборки электроники iDEAR на основе ИИ. 
Источник изображений: techspot.com Проблему электронных отходов трудно переоценить. Только Евросоюз произвёл около пяти миллионов тонн электронных отходов в 2022 году. США генерируют от 6,9 до 7,6 миллионов тонн электронных отходов ежегодно, что составляет около 21 кг на человека в год. По прогнозам, к 2030 году мировое производство электронных отходов увеличится до 74,7–82 миллионов тонн. Нынешнее состояние переработки электронных отходов далеко от идеального. Производственные процессы в электронной промышленности ставят во главу угла экономическую эффективность, что приводит к выпуску устройств, которые плохо поддаются переработке в конце своего жизненного цикла. Традиционные методы часто подразумевают ручную разборку, которая является дорогостоящей и неэффективной. А многие устройства в конечном итоге просто измельчаются, что ограничивает возможность извлечения ценных компонентов. Для решения проблемы переработки и утилизации электроники исследователи из института Фраунгофера в Магдебурге, Германия, разработали iDEAR (Intelligent Disassembly of Electronics for Remanufacturing and Recycling — интеллектуальная разборка электроники для восстановления и переработки). iDEAR кардинально повышает эффективность переработки электронных отходов и потенциально обеспечивает извлечение многих видов ценного сырья. На сегодняшний день iDEAR уже успешно справляется с извлечением материнских плат из корпусов ПК.  Процесс интеллектуальной разборки iDEAR начинается с этапа идентификации и диагностики. 3D-камеры и оптические сенсорные системы на базе ИИ сканируют электронные отходы, собирая информацию о производителе, типе продукта и его серийном номере. Происходит обнаружение и сканирование этикеток и других надписей. Одновременно оценивается состояние компонентов и соединительных элементов, таких как винты и заклёпки. Алгоритмы машинного обучения в режиме реального времени идентифицируют и классифицируют состав устройства. iDEAR без проблем справляется с определением потайного и заржавевшего крепежа. Ключевым нововведением в проекте iDEAR является создание цифрового «двойника разборки» для каждого продукта, включая информацию о его компонентах и любой предыдущей операции с ним. После тщательного анализа устройства система определяет последовательности разборки с помощью специализированного ПО. Принимается решение, следует ли производить полную или частичную разборку, причём приоритет отдаётся извлечению ценных компонентов. Затем робот получает сгенерированную последовательность инструкций, включая откручивание винтов, вскрытие корпусов и извлечение компонентов. Хотя в настоящее время проект iDEAR сосредоточен на переработке ПК, у исследователей амбициозные планы на будущее. Они работают над универсальной системой, которая сможет самостоятельно адаптироваться к широкому спектру электронных устройств — от микроволновых печей до крупных бытовых приборов — с минимальными инженерными усилиями. Российские специалисты из Smart Engines расшифровали рукописи Пушкина при помощи ИИ
06.02.2025 [17:59],
Сергей Сурабекянц
Специалисты российской компании Smart Engines расшифровали зачёркнутые фрагменты черновых рукописей Александра Пушкина с помощью разработанной ими системы искусственного интеллекта «Да Винчи». Нейросетевая архитектура «Да Винчи» широко используется для распознавания документов, в частности российских паспортов, вне зависимости от угла и условий съёмки. 
Источник изображения: Wikipedia, «Литературные места России» В процессе обучения ИИ запомнил, какие движения пера в незачёркнутых словах характерны для почерка великого русского поэта, а затем восстановил утраченные места, пользуясь созданной моделью движений его руки. Таким способом удалось идентифицировать несколько неопределяемых ранее слов из черновых рукописей Пушкина. Эти находки внесли существенный вклад в понимание творческого процесса поэта. Узнать, какие слова пришлись Пушкину не по душе, удалось с помощью нейросетевой архитектуры «Да Винчи», разработанной специалистами Smart Engines для удаления линий разграфки, затрудняющих распознавание рукописных данных в официальных документах. Эта технология позволяет автоматически определять геометрию документа и распознавать данные вне зависимости от его расположения в кадре, наличия помех и искажений. Технология одинаково успешно справляется как со сканами, так и с фотографиями документов, в том числе в зеркальном отражении. Алгоритмы Smart Engines уже интегрированы в решения для мгновенного распознавания данных паспорта и других документов. Распознавание паспорта РФ при помощи камеры смартфона требует всего 0,15 секунды. Серверные решения позволяют распознавать до 55 паспортов в секунду на процессор без использования GPU. 
Источник изображения: Smart Engines «Проведённый нами эксперимент по расшифровке ранее нечитаемых слов в рукописях Александра Пушкина подтвердил колоссальный потенциал нейросетей в самых разных областях науки. Мы видим, что искусственный интеллект может стать надёжным инструментом для исследователя […] Предложенный метод снятия зачёркиваний при помощи ИИ может быть применён не только к рукописям Пушкина, но и к архивным записям других известных авторов, а также историческим документам. Это открывает новые возможности для изучения творческого процесса написания знаменитых литературных произведений», — уверен генеральный директор Smart Engines Владимир Арлазаров. Остаётся неясным лишь одно: если великий русский поэт какие-то слова зачёркивал, возможно, он не хотел, чтобы кто-нибудь их прочитал, в том числе и искусственный интеллект? DeepSeek не справилась с популярностью — доступ к ИИ-моделям теперь ограничен
06.02.2025 [17:30],
Владимир Мироненко
Китайский стартап DeepSeek, вызвавший шок в Кремниевой долине своей моделью ИИ R1, способной к рассуждениям, из-за достижения высокого результата с использованием гораздо меньших ресурсов и средств, объявил об ограничении доступа к своему сервису API из-за нехватки серверных мощностей, пишет Bloomberg. 
Источник изображения: Solen Feyissa/unsplash.com На веб-сайте DeepSeek сообщается о приостановке возможности клиентов пополнять свои API-кредиты, чтобы избежать негативных последствий для сервисов компании. Все существующие сохранённые значения не будут затронуты, добавила DeepSeek. «Текущая сумма пополнения может продолжать использоваться, просим вашего понимания!» — заявила компания. Также DeepSeek, чьи крайне низкие тарифы встревожили некоторых конкурентов, указала в сообщении, что скидки на доступ к её ИИ-модели прекратятся 8 февраля. Далее доступ к чат-боту на основе ИИ будет оплачиваться из расчёта 2 юаня ($0,27) за 1 млн входящих токенов и 8 юаней ($1,10) за 1 млн исходящих токенов. При запуске в Сети модели со способностью к рассуждениям тарифы составят 4 юаня ($0,55) за 1 млн входящих токенов и 16 юаней ($2,19) за 1 млн исходящих токенов. Из-за высокого спроса сервисы DeepSeek работают с повышенной нагрузкой с конца января после того, как был представлен чат-бот AI Assistant на основе искусственного интеллекта, который, по словам компании, способен конкурировать с чат-ботом ChatGPT от OpenAI, и на его разработку ушло гораздо меньше средств, чем у конкурентов. Это утверждение вызвало сомнение в США, и сейчас американские чиновники выясняют, не приобрела ли DeepSeek передовые ИИ-ускорители Nvidia через третьих лиц в Сингапуре, обойдя экспортные ограничения на поставки полупроводников в Китай. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex
 Подписаться
Подписаться