|
Опрос
|
реклама
Быстрый переход
AMD анонсировала мероприятие Advancing AI, на котором представит ИИ-ускорители Instinct MI355X
10.04.2025 [13:24],
Николай Хижняк
Компания AMD запланировала проведение мероприятия Advancing AI на 12 июня. На нём будут представлены специализированные ускорители Instinct нового поколения. Компания также пообещала обновления для своей платформы Radeon Open Compute Platform (ROCm), предназначенной для высокопроизводительных вычислений (HPC) и задач искусственного интеллекта. 
Источник изображения: AMD От AMD ожидается анонс ИИ-ускорителей Instinct MI355X. Ранее компания заявляла, что этот продукт будет выпущен во второй половине 2025 года. В составе ускорителей будут использоваться графические процессоры на архитектуре CDNA 4, производимые по 3-нм техпроцессу, а также до 288 Гбайт памяти HBM3e. Возможно, компания также поделится свежими подробностями об ускорителях Instinct MI400, выход которых намечен на 2026 год. Они станут первыми ИИ-ускорителями AMD, использующими память HBM4. AMD проведёт прямую трансляцию мероприятия Advancing AI 12 июня в 9:30 по тихоокеанскому времени (19:30 мск). Вести мероприятие будет глава компании AMD Лиза Су (Lisa Su). «Яндекс» привлечёт белых хакеров к проверке безопасности генеративных нейросетей
10.04.2025 [11:11],
Андрей Крупин
Компания «Яндекс» сообщила о расширении программы «Охоты за ошибками» и запуске нового направления, связанного с генеративными нейросетями. Теперь исследователи, которым удастся отыскать технические уязвимости в семействах моделей YandexGPT, YandexART и сопутствующей инфраструктуре, могут получить вознаграждение до миллиона рублей. 
Источник изображения: yandex.ru/bugbounty Участникам «Охоты» предстоит искать технические ошибки, которые могут повлиять на результаты работы и процесс обучения нейросетевых моделей: например, привести модель к сбою или изменить её поведение так, чтобы она повлияла на работу других сервисов «Яндекса». В программе участвуют все сервисы и ИИ-продукты «Яндекса», использующие модели семейства YandexGPT и YandexART. В числе таковых: «Алиса», «Поиск с Нейро», «Шедеврум» и другие облачные службы, включая те, где ML-модель используется неявно для ранжирования и поиска. Размер выплаты зависит от серьёзности ошибки и простоты её применения. К критичным относятся уязвимости, которые позволяют раскрыть сведения о внутренней конфигурации модели, её служебный промт с техническими данными или другую чувствительную информацию. Максимальное вознаграждение за такие ошибки — 1 млн рублей. Программу поиска уязвимостей «Яндекс» запустил в 2012 году — компания была первой в России. Теперь программа «Охота за ошибками» действует в «Яндексе» постоянно, а принять в ней участие может любой желающий. Главный конкурент ChatGPT запустил подписку за $200 в месяц, и в ней всё равно есть ограничения
09.04.2025 [21:47],
Анжелла Марина
Компания Anthropic собирается протестировать верхний ценовой порог премиальной подписки на своего чат-бота Claude. Компания станет очередным игроком — вслед за конкурентом OpenAI — на рынке искусственного интеллекта (ИИ), исследующим, сколько готовы платить пользователи за расширенный доступ к современным ИИ-технологиям. 
Источник изображения: Anthropic Сегодня Anthropic представила тариф Max, стоимость которого составила $100 или $200 в месяц в зависимости от объёма использования. По словам представителей компании, за $100 пользователи смогут отправлять в пять раз больше запросов к Claude, чем позволяет текущий план Pro за $18 в месяц. А за $200 возможности увеличатся в 20 раз. В настоящее время владельцы подписки Pro могут отправлять в среднем 45 сообщений боту в течение пяти часов. Подобно другим разработчикам ИИ, компания из Сан-Франциско стремится убедить частных клиентов и бизнес приобретать её продукты, чтобы покрыть высокие затраты на разработку передовых ИИ-моделей. Новый тариф можно сравнить с предложением OpenAI, которая в конце прошлого года запустила аналогичную подписку за $200 в месяц для ChatGPT. Однако OpenAI предоставляет безлимитный доступ к самым мощным моделям за те же $200 в месяц. Anthropic утверждает, что подписчики тарифа Max смогут получать более развёрнутые ответы, а их запросы будут обрабатываться в приоритетном порядке даже в периоды пиковых нагрузок. Кроме того, они получат эксклюзивный доступ к новым моделям и обновлениям программного обеспечения. Последняя версия модели Anthropic — Claude 3.7 Sonnet — также предоставляет пользователям возможность выбора между быстрым ответом на простые запросы и более детальным, разложенным «по полочкам» и имитирующим человеческое мышление. Это выделяет компанию на фоне конкурентов в условиях насыщенного рынка ИИ, особенно после того как в марте Anthropic успешно привлекла $3,5 млрд инвестиций, достигнув оценки в $61,5 млрд и тем самым подтвердив своё место среди крупнейших ИИ-стартапов мира. Мяч с мозгами: Samsung и Google объединились для выпуска домашнего робота Ballie с ИИ Gemini и проектором
09.04.2025 [17:58],
Сергей Сурабекянц
Samsung и Google объединились для запуска Ballie, домашнего робота в форме футбольного мяча, который использует ИИ Gemini для управления умным домом и умеет проецировать видео на стены. Жёлтый шарообразный робот призван, по словам Samsung, «оживить ИИ как друга и настоящего компаньона». С этим устройством обе компании впервые выходят на перспективный рынок потребительской робототехники, который оценивается в миллиарды долларов. 
Источник изображений: Samsung Samsung впервые представила Ballie в начале 2020 года на технологической конференции CES, где он произвёл фурор, но путь к выходу домашнего робота на потребительский рынок оказался тернистым. Исполнительный вице-президент Samsung Джей Ким (Jay Kim) сообщил, что актуальное устройство представляет собой «совершенно новый Ballie». Одним из самых больших изменений стало использование моделей ИИ от Google для понимания команд пользователя, подключения к поиску Google и обработки данных с бортовых камер во время навигации по дому.  Ballie работает под управлением операционной системы Tizen от Samsung, которая также используется во многих устройствах компании, что обеспечивает ему доступ к таким поставщикам контента, как YouTube, Netflix и собственный сервис Samsung TV Plus. Робот использует платформу Samsung SmartThings для управления умными домашними устройствами, календарями и напоминаниями, ответа на вопросы, совершения и приёма телефонных звонков и воспроизведения видео через встроенный проектор. Он также использует модели ИИ от Samsung для таких функций, как доступ к персональным данным и погоде.  «Сложно описать систему, которая может чувствовать, двигаться и взаимодействовать так естественно, как это делает она, — считает генеральный директор Google Cloud Томас Куриан (Thomas Kurian). — Когда вы говорите: “Иди сюда”, она действительно размышляет, как туда попасть. Системе требуется много магии за кулисами, чтобы она заработала».  По словам Кима, Samsung выбрала Google Cloud из-за своей «веры» в возможности Gemini. Эта работа знаменует собой расширение существующих партнёрских отношений по устройствам Android, умным часам и будущей гарнитуре смешанной реальности, которая также появится в конце этого года. Он добавил, что компании уже разрабатывают дополнительные функции для Ballie, включая комплект разработки программного обеспечения для сторонних приложений и видеоконференций. Куриан подчеркнул, что партнёрство с Samsung требует «много настроек и оптимизации […] и это единственное наше партнёрство с таким персонализированным опытом». Устройство сначала поступит в продажу в США и Южной Корее и, по крайней мере, на первых порах будет поддерживать общение только на английском и корейском языках. Google представила рассуждающую ИИ-модель Gemini 2.5 Flash с высокой производительностью и эффективностью
09.04.2025 [17:46],
Николай Хижняк
Google выпустила новую ИИ-модель, призванную обеспечить высокую производительность с упором на эффективность. Она называется Gemini 2.5 Flash и вскоре станет доступна в составе платформы Vertex AI облака Google Cloud для развёртывания и управления моделями искусственного интеллекта (ИИ). 
Источник изображения: Google Компания отмечает, что Gemini 2.5 Flash предлагает «динамические и контролируемые» вычисления, позволяя разработчикам регулировать время обработки запроса в зависимости от их сложности. «Вы можете настроить скорость, точность и баланс затрат для ваших конкретных нужд. Эта гибкость является ключом к оптимизации производительности Flash в высоконагруженных и чувствительных к затратам приложениях», — написала компания в своём официальном блоге. На фоне растущей стоимости использования флагманских ИИ-моделей Gemini 2.5 Flash может оказаться крайней полезной. Более дешёвые и производительные модели, такие как 2.5 Flash, представляют собой привлекательную альтернативу дорогостоящим флагманским вариантам, но ценой потери некоторой точности. Gemini 2.5 Flash — это «рассуждающая» модель по типу o3-mini от OpenAI и R1 от DeepSeek. Это означает, что для проверки фактов ей требуется немного больше времени, чтобы ответить на запросы. Google утверждает, что 2.5 Flash идеально подходит для работы с большими объёмами данных и использования в реальном времени, в частности, для таких задач, как обслуживание клиентов и анализ документов. «Эта рабочая модель оптимизирована специально для низкой задержки и снижения затрат. Это идеальный движок для отзывчивых виртуальных помощников и инструментов резюмирования в реальном времени, где эффективность при масштабировании является ключевым фактором», — описывает новую ИИ-модель компания. Google не опубликовала отчёт по безопасности или техническим характеристикам для Gemini 2.5 Flash, что усложнило задачу определения её преимуществ и недостатков. Ранее компания говорила, что не публикует отчёты для моделей, которые она считает экспериментальными. Google также объявила, что с третьего квартала планирует интегрировать модели Gemini, такие как 2.5 Flash в локальные среды. Они будут доступны в Google Distributed Cloud (GDC), локальном решении Google для клиентов со строгими требованиями к управлению данными. В компании добавили, что работают с Nvidia над установкой Gemini на совместимые с GDC системы Nvidia Blackwell, которые клиенты смогут приобрести через Google или по своим каналам. Google представила свой самый мощный ИИ-процессор Ironwood — до 4,6 квадриллиона операций в секунду
09.04.2025 [15:56],
Николай Хижняк
В рамках конференции Cloud Next на этой неделе компания Google представила новый специализированный ИИ-чип Ironwood. Это уже седьмое поколение ИИ-процессоров компании и первый TPU, оптимизированный для инференса — работы уже обученных ИИ-моделей. Процессор будет использоваться в Google Cloud и поставляться в системах двух конфигураций: серверах из 256 таких процессоров и кластеров из 9216 таких чипов. 
Источник изображений: Google «Ironwood — это наш самый мощный, самый производительный и самый энергоэффективный TPU. Он разработан для ускорения инференса ИИ-моделей в масштабах облачной инфраструктуры», — прокомментировал анонс процессора вице-президент Google Cloud Амин Вахдат (Amin Vahdat). Анонс Ironwood состоялся на фоне усиливающейся конкуренции в сегменте разработок проприетарных ИИ-ускорителей. Хотя Nvidia доминирует на этом рынке, свои технологические решения также продвигают Amazon и Microsoft. Первая разработала ИИ-процессоры Trainium, Inferentia и Graviton, которые используются в её облачной инфраструктуре AWS, а Microsoft применяет собственные ИИ-чипы Cobalt 100 в облачных инстансах Azure.  Google заявляет, что Ironwood обладает пиковой вычислительной производительностью 4614 Тфлопс или 4614 триллионов операций в секунду. Таким образом кластер из 9216 таких чипов предложит производительность в 42,5 Экзафлопс. 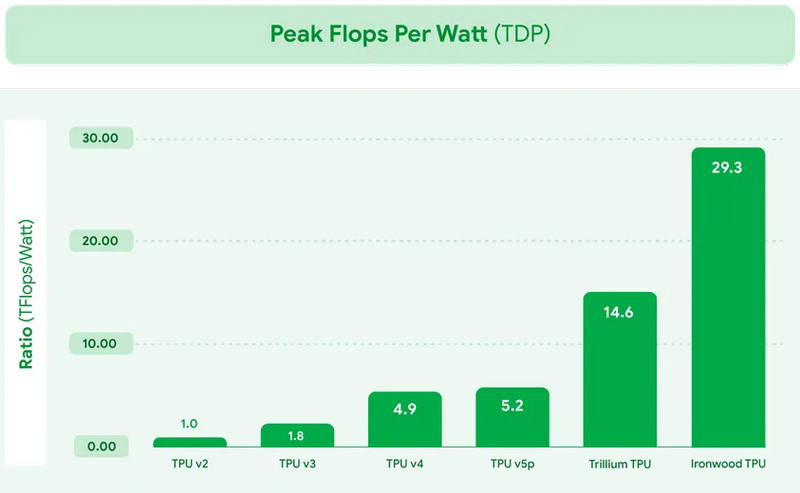 Каждый процессор оснащён 192 Гбайт выделенной оперативной памяти с пропускной способностью 7,4 Тбит/с. Также чип включает усовершенствованное специализированное ядро SparseCore для обработки типов данных, распространённых в рабочих нагрузках «расширенного ранжирования» и «рекомендательных систем» (например, алгоритм, предлагающий одежду, которая может вам понравиться). Архитектура TPU оптимизирована для минимизации перемещения данных и задержек, что, по утверждению Google, приводит к значительной экономии энергии. Компания планирует использовать Ironwood в своём модульном вычислительном кластере AI Hypercomputer в составе Google Cloud. Джон Кармак встал на защиту ИИ-версии Quake II, которую игроки назвали «абсолютно отвратительной»
09.04.2025 [11:31],
Дмитрий Рудь
Представленная на днях демоверсия культового шутера Quake II на базе ИИ-модели Muse от Microsoft вызвала отторжение у игроков, тогда как сооснователь id Software и соавтор Quake Джон Кармак (John Carmack) увидел в технологии большой потенциал. 
Источник изображения: id Software Демонстрация ИИ-версии Quake II была встречена в основном негативно. Пользователь Quake Dad в X, например, назвал проект «абсолютно отвратительным» и приравнял его к «плевку на труд всех разработчиков в мире». Отвечая Quake Dad, Кармак не согласился с высказанной пользователем позицией и заявил, что «создание мощных инструментов является ключевым двигателем прогресса в компьютерной сфере». Кармак вспомнил, как при разработке своих первых проектов вручную делал то, за что сегодня отвечают игровые движки: «Прогресс в программном обеспечении сделал эту работу такой же ненужной, как обслуживание колёс у боевой колесницы». 
Источник изображения: ArsTechnica (Benj Edwards) По мнению Кармака, ИИ-инструменты «позволят лучшим достигать ещё более впечатляющих высот, дадут возможность небольшим командам добиваться большего и привлекут кардинально новую демографию творцов». «Да, прогресс дойдёт до того, что вы сможете получить интерактивную игру (роман или фильм) из текстового запроса, но куда более выдающиеся произведения всё равно будут создавать команды увлечённых разработчиков», — заверил Кармак. Разработчика поддержал гендиректор Epic Games Тим Суини (Tim Sweeney), который призывает не бояться автоматизации и считает, что конкуренция вынудит компании использовать ИИ-инструменты для создания наилучших продуктов. В Госдуме создали «серьёзную» группу для надзора за развитием ИИ
09.04.2025 [10:29],
Владимир Фетисов
В Госдуме РФ создана межфракционная рабочая группа по разработке законов о применении искусственного интеллекта. По данным источника, в состав группы вошли представители всех фракций, которые займутся законодательным обеспечением «национально ориентированного» ИИ. Группа будет работать до конца срока полномочий восьмого созыва, т.е. до 2026 года. 
Источник изображения: Steve Johnson / Unsplash Возглавил группу вице-спикер нижней платы Александр Бабаков, представляющий партию «Справедливая Россия». Комментируя данный вопрос, он заявил, что регулирование сферы ИИ «не должно никого пугать». Он добавил, что это «не та сфера, которая может развиваться чисто по рыночным законам» и ориентироваться «только на нормы прибыли». По мнению Бабакова, необходимо оценивать множество факторов, включая угрозы (в том числе этические), которые несут в себе новые трансграничные технологии. Также было сказано, что есть вопросы, связанные с изучением насыщенности рынка и его развитием в сочетании с рынком энергетики. В сообщении сказано, что рабочая группа была создана по поручению председателя Госдумы Вячеслава Володина. Комплексный вопрос ИИ затрагивает многие сферы, включая энергетику для энергоёмких вычислений, отечественное оборудование, этику, международное сотрудничество, безопасность и др. Депутат от ЛДПР Андрей Свинцов сообщил, что есть цель, которая заключается в быстром изучении потребностей каждой стороны, начиная от малого и среднего бизнеса, заканчивая интересами государства, а также определении первоочередных вопросов регулирования, поскольку «ИИ в российском законодательстве отсутствует». Также известно, что члены рабочей группы подготовят предложения по эффективному отраслевому применению ИИ, включая законопроекты, касающиеся национальной обороны и безопасности страны. Они также займутся разработкой инициатив по противодействию использованию ИИ в преступлениях. Госдума планирует сформировать законодательные условия для того, чтобы использовать ИИ в государственном стратегическом планировании социально-экономического развития России. Осведомлённый источник сообщил, что к настоящему моменту удалось организовать «форматно серьёзную» группу. Следующим шагом станет подготовка к публичным парламентским слушаниям. Также ведётся обсуждение того, что регулирование может привести к дополнительной нагрузке, но никому не удастся справиться с новыми технологиями «без направляющей руки государства». В Китае квантовый компьютер впервые применили для точной настройки ИИ
09.04.2025 [10:26],
Геннадий Детинич
Китайские учёные первыми в мире использовали квантовый компьютер для точной настройки искусственного интеллекта — большой языковой модели с одним миллиардом параметров. Это стало первым использованием квантовой платформы, имеющим практическую ценность. В этом проявил себя компьютер Wukong китайской компании Origin, основанный на 72 сверхпроводящих кубитах. 
Источник изображения: Origin Система Wukong относится к третьему поколению квантовых компьютеров Origin. В январе 2024 года к ней был открыт облачный доступ со всего мира. Как признаются разработчики, поток учёных возглавили исследователи из США, несмотря на то что китайским учёным доступ к аналогичным ресурсам западных партнёров по-прежнему закрыт. «Это первый случай, когда настоящий квантовый компьютер был использован для точной настройки большой языковой модели в практических условиях. Это демонстрирует, что современное квантовое оборудование может начать поддерживать задачи обучения ИИ в реальном мире», — сказал Чэнь Чжаоюнь (Chen Zhaoyun), исследователь из Института искусственного интеллекта при Национальном научном центре в Хэфэе. По словам учёных, система Origin Wukong на 8,4 % улучшила результаты обучения ИИ при одновременном сокращении количества параметров на 76 %. Обычно для решения подобных задач — специализации ИИ общего назначения — используются суперкомпьютеры, что требует значительных вычислительных и энергетических ресурсов. Квантовый вычислитель, использующий принцип квантовой суперпозиции — множества вероятностных состояний вместо двух классических (0 и 1), способен экспоненциально ускорить расчёты при относительно скромных затратах ресурсов. В частности, учёные продемонстрировали преимущества точной настройки большой языковой модели с помощью квантовой системы для диагностики психических расстройств (число ошибок снижено на 15 %), а также при решении математических задач, где точность выросла с 68 % до 82 %. Для запуска алгоритмов обучения ИИ на квантовой платформе исследователи разработали то, что назвали «квантово-взвешенной тензорной гибридной настройкой параметров». Весовые значения обрабатывала квантовая платформа, в то время как классическая часть готовила большую языковую модель. Благодаря суперпозиции и эффекту квантовой запутанности платформа Origin Wukong смогла одновременно обрабатывать огромное количество комбинаций параметров, что ускорило специализацию модели. В Meta✴ отрицают, что искусственно завысили результаты тестов ИИ-модели Llama 4
08.04.2025 [05:11],
Анжелла Марина
Представитель Meta✴ опроверг слухи о том, что компания намеренно улучшала показатели своих новых ИИ-моделей Llama 4 в бенчмарках. Вице-президент по генеративному искусственному интеллекту Ахмад Аль-Дахле (Ahmad Al-Dahle) заявил в посте на страницах X, что утверждения о подгонке результатов с целью сокрытия слабых сторон моделей Maverick и Scout — «просто неправда». 
Источник изображения: Mariia Shalabaieva / Unsplash Слухи о манипуляциях появились в соцсетях после публикации бывшего сотрудника Meta✴. Пользователь китайской платформы утверждал, что уволился из компании в знак протеста против «нечестных методов тестирования». Позже эти обвинения распространились в X (бывший Twitter) и Reddit, пишет издание TechCrunch. Однако Аль-Дахле подчеркнул, что Meta✴ не обучала модели Llama 4 Maverick и Llama 4 Scout на «тестовых наборах данных», то есть специальных выборках, используемых для оценки ИИ. Такая практика могла бы искусственно завысить результаты, создав ложное впечатление о возможностях моделей. Подозрения изначально появились из-за различий в работе Llama 4 Maverick на разных платформах. Исследователи заметили, что версия модели в бенчмарке LM Arena ведёт себя иначе, чем публично доступная и не справляется с определёнными задачами. Кроме того, Meta✴ использовала экспериментальную сборку Maverick для улучшения результатов тестов, что также вызвало вопросы. Одновременно Аль-Дахле отмечает, что причина, по которой пользователи пока сталкиваются с нестабильным качеством моделей, может быть связана с настройками облачных провайдеров, на серверах которых размещаются скрипты. «Мы выпустили модели сразу после их готовности, и потребуется несколько дней, чтобы все публичные реализации были настроены в соответствии с нашими требованиями», — пояснил он. В Meta✴ пообещали в любом случае продолжить работу над исправлениями багов Llama 4 для быстрой интеграции разработчиками в свои проекты. «ИИ крадёт у всех»: медиаиндустрия потребовала немедленно остановить воровство контента для ИИ
08.04.2025 [01:05],
Анжелла Марина
Сотни медиакомпаний, включая The New York Times, The Washington Post и The Guardian, запустили рекламную кампанию с призывом к правительству США защитить контент от неконтролируемого использования искусственным интеллектом (ИИ), сообщает The Verge. Инициатива под названием Support Responsible AI организована ассоциацией News/Media Alliance и включает объявления как в печатных, так и онлайн-изданиях. 
Источник изображения: сгенерировано AI Кампания стартовала через несколько недель после того, как OpenAI и Google направили властям письма с просьбой разрешить их ИИ-моделям обучаться на защищённых авторским правом материалах. В рекламе используются такие слоганы, как «Следите за ИИ», «Остановите кражу ИИ», «ИИ крадёт у вас тоже», и всё это вместе с призывом внизу каждого тизера: «Кража — это не по-американски. Скажите Вашингтону, чтобы техногиганты платили за контент, который они берут у издателей». Объявления содержат ссылку и QR-код, ведущие на сайт Support Responsible AI, где пользователей призывают обратиться к своим представителям в Конгрессе с требованием обязать технологические компании справедливо компенсировать труд журналистов, писателей и художников. Также издатели настаивают на обязательном указании источников в контенте, созданном ИИ. 
Источник изображения: News/Media Alliance «Сейчас Big Tech и ИИ-компании используют контент издателей против них самих, то есть забирают его без разрешения и оплаты, чтобы обучать ИИ-модели, которые в конечном итоге перетягивают на себя все рекламные доходы от создателей, — заявила Даниэль Коффи (Danielle Coffey), президент и генеральный директор News/Media Alliance. — Медиаиндустрия не против ИИ — многие компании сами используют эти инструменты. Но мы хотим сбалансированной экосистемы, где ИИ развивается ответственно». В феврале аналогичную кампанию провели крупные британские газеты, разместив на первых полосах лозунг «Make It Fair» с призывом защитить авторские права от обучения ИИ-моделей. Среди участников сегодняшней инициативы также присутствуют The Atlantic, Seattle Times, Tampa Bay Times, Condé Nast (издатель Wired) и Axel Springer (владелец Politico). Очевидно, что конфликт между медиакомпаниями и технологическими гигантами обостряется. Пока OpenAI и Google добиваются у правительства США свободного доступа к данным для обучения ИИ, издатели настаивают на законодательном регулировании и выплатах за использование их материалов. Исход этой борьбы в эпоху нейросетей может определить будущее цифрового контента . Будущее ИИ-устройство от Джони Айва — это «не телефон», но оно сможет звонить
07.04.2025 [18:33],
Владимир Фетисов
Бывший главный дизайнер Apple Джони Айв (Jony Ive) сейчас работает над первым устройством собственной компании LoveFrom. Первые подробности о новом «персонализированном ИИ-устройстве» Айва указывают на то, что дизайнер снова может пройтись по знакомой территории, сотрудничая с главой OpenAI Сэмом Альтманом (Sam Altman). 
Источник изображения: 9to5mac.com Несмотря на то, что дизайн будущего персонализированного устройства с искусственным интеллектом находится в стадии разработки, его уже сравнивают со смартфоном. «По словам двух человек, непосредственно знакомых с ходом переговоров, OpenAI в последние недели обсуждала приобретение стартапа io Products, основанного её генеральным директором Сэмом Альтманом и бывшим дизайнером Apple Джони Айвом и работающего над созданием персонального устройства с искусственным интеллектом», — говорится в недавней публикации журналистов The Information. Сумма сделки может составить $500 млн. Собеседники журналистов рассказали, что дизайн ИИ-устройства находится на ранней стадии разработки и ещё не завершён. По их словам, потенциально речь идёт о мобильном устройстве без экрана или бытовом устройстве с поддержкой ИИ. Другие осведомлённые источники утверждают, что это «не телефон». Такое расхождение в заявлениях источников может указывать на то, что разрабатываемое устройство потенциально является настолько инновационным, что люди затрудняются провести аналогии с уже существующими продуктами. Идея о том, что речь идёт о телефоне «без экрана» выглядит абсурдной, но и она может помочь в определении направления развития продукта. Возможно, технически это не телефон, но устройство, которое может использоваться для осуществления звонков. Новый продукт Айва может позиционироваться не просто в качестве нишевого компаньона для смартфона. Возможно, его амбиции направлены на то, чтобы полностью заменить смартфон. Конечно, работа ещё только начинается, и подробностей пока мало. Однако первые намёки указывают на то, что это персональное устройство создаётся с нуля и ориентировано на эпоху ИИ. Поэтому не удивительно, что OpenAI рассматривает покупку io Products, компании Альтмана, которая работает над новым устройством вместе с Айвом. Microsoft подтвердила разработку собственных ИИ-моделей — это устранит зависимость от OpenAI
07.04.2025 [18:03],
Владимир Мироненко
Несмотря на сотрудничество с разработчиком ИИ-систем OpenAI и инвестиции в него $13,75 млрд, компания Microsoft занимается созданием собственных ИИ-моделей, что подтвердил генеральный директор Microsoft AI Мустафа Сулейман (Mustafa Suleyman). Он сообщил, что компания не стремится к созданию передовых ИИ-моделей, указав на положительные стороны такого подхода. 
Источник изображения: Growtika/unsplash.com Глава Microsoft AI заявил, что «абсолютно критически важно» для миссии, чтобы в долгосрочной перспективе компания могла самостоятельно заниматься ИИ, хотя, по крайней мере до 2030 года, Microsoft будет тесно сотрудничать с OpenAI. Он подчеркнул, что компания не предпринимает усилий для создания прорывных моделей. «У нас невероятно сильная команда по разработке в сфере ИИ, огромные объёмы вычислений, и для нас очень важно не тратить ресурсы на разработку передовой, лучшей в мире модели первыми. Это очень, очень дорого, и нет необходимости дублировать эти усилия», — заявил Сулейман. Он отметил, что создание ИИ-моделей с отставанием на три или шесть месяцев от передовых решений имеет свои преимущества. «На самом деле это наша стратегия — играть очень мощно на вторых ролях, учитывая капиталоёмкость этих моделей», — говорит глава Microsoft AI. В последнее время в ранее тесных партнёрских отношениях Microsoft и OpenAI появились трещины. Это произошло вскоре после того, как OpenAI анонсировала проект Stargate стоимостью $500 млрд по строительству ЦОД на территории Соединённых Штатов, партнёром в котором выступил конкурирующий облачный провайдер Oracle. Microsoft не только потеряла статус эксклюзивного поставщика облачных вычислений для OpenAI, но и перестала быть её крупнейшим инвестором после того, как SoftBank возглавил последний раунд финансирования OpenAI, собрав $40 млрд. DeepSeek придумал, как повысить эффективность ИИ-моделей с помощью самообучения
07.04.2025 [12:15],
Владимир Мироненко
Китайский стартап DeepSeek прославился в начале года, выпустив рассуждающую модель R1, которая смогла конкурировать с ИИ-моделями американских технологических гигантов, несмотря на скромный бюджет. Теперь DeepSeek опубликовал в сотрудничестве с исследователями университета Цинхуа статью с подробным описанием нового подхода к обучению моделей с подкреплением, позволяющего значительно повысить их эффективность. Об этом сообщил ресурс SCMP. 
Источник изображения: Solen Feyissa/unsplash.com Согласно публикации, новый метод направлен на то, чтобы помочь ИИ-моделям лучше соответствовать человеческим предпочтениям, используя механизм вознаграждений за более точные и понятные ответы. Обучение с подкреплением доказало свою эффективность в ускорении решения задач ИИ в ограниченных сферах и приложениях. Однако его использование для более общих задач оказалось не столь эффективным. Команда DeepSeek пытается решить этот вопрос, объединив генеративное моделирование вознаграждения (GRM) и так называемую настройку самокритики на основе принципов. Как утверждается в статье, новый подход с целью улучшения возможностей рассуждений больших языковых моделей (LLM) превзошёл существующие методы, что подтверждено проверкой моделей в различных тестах, и позволил получить самую высокую производительность для общих запросов при использовании меньших вычислительных ресурсов. Новые модели получили название DeepSeek-GRM — сокращение от термина Generalist Reward Modeling (универсальное моделирование вознаграждения). Компания сообщила, что новые модели будут с открытым исходным кодом, однако сроки их выхода пока не объявлены. В прошлом месяце агентство Reuters сообщило со ссылкой на информированные источники, что в апреле компания также выпустит DeepSeek-R2, преемника рассуждающей модели R1. Другие ведущие разработчики в сфере ИИ, включая китайскую Alibaba Group Holding и OpenAI из Сан-Франциско (США), также работают над улучшением возможностей рассуждения и самосовершенствования ИИ-моделей, отметил Bloomberg. Apple отодвинула выпуск устройства для управления умным домом на 2026 год
06.04.2025 [21:17],
Владимир Фетисов
По данным обозревателя Bloomberg Марка Гурмана (Mark Gurman), Apple больше не планирует выпустить в этом году устройство Home Hub, которое станет центром управления умным домом. Это связано с трудностями, которые возникли при разработке функций на базе искусственного интеллекта Apple Intelligence и новой версии помощника Siri. Журналист указывает на то, что теперь компания надеется вывести это устройство на рынок в 2026 году. 
Источник изображения: 9to5mac.com Ожидается, что хаб для умного дома от Apple будет оснащён 7-дюймовым квадратным дисплеем и камерой, а также получит поддержку ИИ-функций и различных фирменных приложений, таких как FaceTime. Вместе с этим Home Hub позволит комфортно управлять разными устройствами умного дома. Разработка новой версии Siri столкнулась с рядом технических проблем, из-за которых Apple пришлось отложить запуск уже анонсированных функций. Изначально Гурман писал, что Apple выпустит хаб для умного дома в марте этого года. Позднее он же сообщил, что компания перенесла запуск на апрель или более поздний срок в течение года. Теперь же он говорит, что ситуация более сложная, и Home Hub не выйдет на рынок до следующего года. «Компания рассматривает возможность отсрочки до 2026 года, когда, как ожидается, появятся новые функции Siri. Если это произойдёт, то это будет разочарованием для фанатов Apple, ожидающих, что компания сделает более масштабный шаг в развитии умного дома. Но этот продукт, скорее всего, не принесёт существенного дохода. На самом это всего лишь версия Google Nest Hub от Apple», — говорится в сообщении Гурмана. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться