|
Опрос
|
реклама
Быстрый переход
После скандала Mozilla снова изменила условия использования Firefox и дала разъяснения о продаже данных пользователей
01.03.2025 [16:21],
Павел Котов
Mozilla начала пересматривать формулировки «Условий использования» браузера Firefox, которые вызвали резкую критику общественности. В предыдущем варианте компания наделяла себя слишком широкими правами на данные, принадлежащие пользователям. Также было опубликовано разъяснение о том, продаёт ли компания данные пользователей. 
Источник изображения: Rubaitul Azad / unsplash.com Новая формулировка уже присутствует в англоязычной версии документа, а вариант на русском языке пока имеет прежний вид: «Когда вы загружаете или вводите информацию через Firefox, вы тем самым предоставляете нам неисключительную, безвозмездную, действующую во всём мире лицензию на использование этой информации для помощи вам в навигации, восприятии и взаимодействии с онлайн-контентом, как вы указываете при использовании Firefox». Обновлённый фрагмент «Условий использования» сформулирован следующим образом: «Вы предоставляете Mozilla права, необходимые для работы Firefox. Это включает обработку ваших данных, как это описано в „Уведомлении о конфиденциальности“. Это также включает неисключительную, безвозмездную, действующую во всём мире лицензию с целью делать то, что вы просите, с контентом, который вы вводите в Firefox. Это не даёт Mozilla никаких прав собственности на данный контент». Компания также разъяснила, почему убрала утверждение, что «никогда не продаёт ваши данные». По версии Mozilla, «в некоторых местах юридическое определение „продажи данных“ является обширным и развивается», а «сравнительные толкования требований „не продавать“ на практике оставляют многие компании неуверенными в своих точных обязательствах и в том, рассматриваются ли они как „продажа данных“». Компания признала, что «существует ряд мест, где мы собираем и передаём некоторые данные нашим партнёрам», чтобы Firefox оставался «коммерчески целесообразным», но об этом говорится в «Уведомлении о конфиденциальности», и Mozilla прилагает усилия, чтобы удалять из этих массивов информацию, по которой можно идентифицировать человека, или передавать её в агрегированном формате. Mozilla наделила себя правами на данные пользователей Firefox и заверила, что иначе никак
28.02.2025 [15:57],
Павел Котов
Mozilla опубликовала новые редакции «Условий использования» и «Уведомления о конфиденциальности». Этот шаг компания объяснила стремлением обеспечить прозрачность своих обязательств в отношении защиты конфиденциальности пользователей. Некоторые формулировки в этих документах звучат пугающе, но в компании заверили, что в противном случае браузер лишится основных функций. 
Источник изображения: mozilla.org Среди новых положений значится, что пользователи предоставляют Mozilla «неисключительную, безвозмездную, действующую во всем мире лицензию» на использование данных, которые скачиваются или вводятся через браузер. Слишком расплывчатая формулировка вызвала тревогу среди пользователей, поскольку она не проясняет, к каким именно данным компания хочет получить доступ — эти данные могут включать личную информацию, сохранённые пароли и историю просмотра. «Когда вы загружаете или вводите информацию через Firefox, вы тем самым предоставляете нам неисключительную, безвозмездную, действующую во всём мире лицензию на использование этой информации для помощи вам в навигации, восприятии и взаимодействии с онлайн-контентом, как вы указываете при использовании Firefox», — говорится в документе. Этот пункт вызвал бурные обсуждения в Сети, в том числе в сообществе Reddit. Подобная риторика традиционно ассоциируется с технологическими гигантами и контрастирует с идеалами открытости, которые, по её собственным заверениям, поддерживает Mozilla. Ситуацию усугубила ещё одна формулировка: «Mozilla имеет право приостановить или прекратить чей-либо доступ к Firefox в любое время по любой причине, в том числе, если Mozilla решит прекратить действие Firefox». Кроме того, компания удалила из раздела FAQ вопрос «Продаёт ли Firefox ваши данные?», где был ответ «Нет. Никогда не продавали и не будем. И мы защищаем вас от многих рекламодателей, которые это делают. Продукты Firefox разработаны для защиты вашей конфиденциальности. Это обещание». Пользователи справедливо решили, что больше это обещание не действует. В самой компании, однако, не нашли повода драматизировать ситуацию. Mozilla продолжает настаивать, что Firefox остаётся программой с открытым исходным кодом, а новые условия применяются только к официальной версии браузера. «Мы обратили внимание на небольшую путаницу в связанных с лицензиями формулировках и хотим дать разъяснение. Нам необходима лицензия, чтобы некоторые из основных функций Firefox были возможными. Без неё мы, например, не смогли бы использовать введённую в Firefox информацию. Она НЕ (sic) даёт нам права собственности на ваши данные или права использовать их для чего-либо за исключением указанного в „Уведомлении о конфиденциальности“. Новая политика просто даёт возможность Firefox работать так, как он работал всегда, помогать пользователям посещать веб-страницы, разрешать браузеру сохранять вашу личную информацию, такую как данные форм, или получать доступ к файлу, который вы хотели загрузить на сайт», — гласит посвящённая инциденту публикация в блоге Mozilla. Шпионский софт Pegasus удаётся обнаружить лишь на половине заражённых iPhone
20.02.2025 [20:19],
Сергей Сурабекянц
Шпионское ПО Pegasus от израильской компании NSO Group — одна из самых страшных угроз конфиденциальности, с которой может столкнуться владелец iPhone. Pegasus использует уязвимости нулевого дня, чтобы получить доступ почти ко всем хранящимся на смартфонах Apple персональным данным, отслеживать деятельность владельца, а в некоторых случаях даже активировать камеру и микрофон устройства. 
Источник изображений: unsplash.com Pegasus проникает на устройства, используя цепочки эксплойтов с нулевым кликом (которые не требуют взаимодействия с пользователем), что позволяет обойти функции безопасности iPhone. При взломе этими методами пользователю даже не требуется нажимать на вредоносную ссылку, чтобы Pegasus проник в устройство. Apple, в свою очередь, стремится обнаружить шпионское ПО — iOS включает эвристический код для обнаружения взлома iPhone, даже если метод взлома пока не известен Apple. При выявлении подозрительной активности компания уведомляет владельцев потенциально заражённых шпионским ПО устройств и одновременно начинает работу над выявлением эксплуатируемой уязвимости безопасности. Apple отмечает, что никогда не может быть на 100 % уверена в своих выводах, но тем не менее призывает получателей сообщений серьёзно отнестись к предупреждению. В прошлом году компания уведомила значительное количество пользователей iPhone из 98 стран о том, что они, по всей видимости, подверглись атакам шпионского ПО, которые могут скомпрометировать почти все личные данные на их устройствах. Недавно полученные данные свидетельствуют о том, что Apple в настоящее время обнаруживает лишь около половины заражённых устройств. Эта информация предоставлена компанией мобильной безопасности iVerify, которая в прошлом году выпустила приложение для сканирования смартфонов Apple и отправки результатов для анализа. Единовременная плата в $1 позволяет выполнять одно сканирование в месяц. Собранные данные позволили компании оценить распространённость шпионского ПО Pegasus, а также оценить, какой процент владельцев заражённых iPhone получил уведомления от Apple. 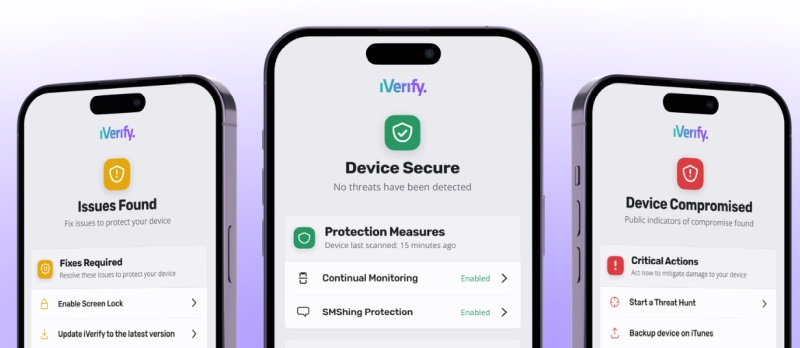
Источник изображения: iVerify «После широкого освещения в прессе ещё 18 000 человек загрузили наше приложение iVerify Basic и просканировали свои устройства, и в результате мы обнаружили 11 новых случаев Pegasus только в декабре. [Это снижает] наш глобальный уровень примерно до 1,5 обнаружений Pegasus на 1000 сканирований; однако больший размер выборки повышает нашу уверенность в том, что эта цифра представляет собой нечто более близкое к истинному уровню заболеваемости, и позволяет нам делать потенциально более интересные выводы», — сообщил представитель iVerify. iVerify отметила, что взлом мобильных устройств давно вышел за рамки таких целей, как политики и активисты, и действительно, по-видимому, влияет на широкий срез общества. Новые подтверждённые обнаружения, включающие известные варианты Pegasus с 2021 по 2023 год, демонстрируют атаки на пользователей в правительственных, финансовых, логистических и риэлторских сферах. Многие iPhone были заражены сразу несколькими вариантами вредоносного ПО и отслеживались в течение многих лет.  По подсчётам iVerify, примерно в половине случаев владельцы скомпрометированных устройств не получали уведомления об угрозах от Apple. Представитель iVerify подчеркнул, что компания приложила максимум усилий и учитывала только те телефоны, в заражении которых она была на 100 % уверена. Google reCAPTCHA утратила эффективность и превратилась в инструмент слежки
09.02.2025 [11:41],
Дмитрий Федоров
Система reCAPTCHA, изначально созданная как средство защиты веб-ресурсов от автоматических атак, сегодня утратила свою изначальную функцию, превратившись в инструмент массовой слежки за пользователями. Согласно исследованиям, её эффективность в борьбе с ботами стремится к нулю. Однако технология остаётся востребованной благодаря способности собирать детализированные цифровые отпечатки пользователей. В 2025 году люди по всему миру затратили на решение reCAPTCHA 819 млн часов, что эквивалентно потере $6,1 млрд потенциального дохода. В то же время ценность собранных данных оценивается в $888 млрд, обеспечивая Google колоссальную прибыль. 
Источник изображения: Google При входе на сайт банка или при заполнении онлайн-форм пользователи сталкиваются с капчей (Completely Automated Public Turing test to tell Computers and Humans Apart или CAPTCHA) — тестами, предназначенными для различения людей и ботов. Эти тесты используются для защиты веб-ресурсов от автоматических атак, предотвращения создания злоумышленниками поддельных аккаунтов и массовой рассылки спама. Однако со временем их функциональность изменилась: современные CAPTCHA, особенно система reCAPTCHA, теперь не только проверяют пользователей, но и анализируют их поведение. В 2007 году профессор Луис фон Ан (Luis von Ahn) предложил концепцию нового подхода к CAPTCHA. Он считал, что её можно использовать не только для проверки пользователей, но и для решения проблемы оцифровки текстов. В то время существующие алгоритмы плохо справлялись с распознаванием слов в отсканированных документах, особенно если шрифт был повреждён или размыт. Фон Ан разработал систему reCAPTCHA, которая позволяла миллионам пользователей по всему миру невольно помогать в расшифровке текстов, вводя символы, недоступные для автоматического анализа. Одной из первых компаний, применивших эту технологию, стала The New York Times. С её помощью газета перевела в цифровой формат 13 млн статей, опубликованных с 1851 года. В 2009 году Google приобрела reCAPTCHA и интегрировала её в экосистему своих сервисов. Первоначально технология использовалась для улучшения Google Books: она помогала обрабатывать сложные фрагменты текста, которые стандартные алгоритмы оптического распознавания символов (OCR) не могли корректно интерпретировать. Однако этим её применение не ограничилось. Google начала использовать reCAPTCHA для расшифровки уличных знаков, номеров домов и других текстовых объектов в системе Google Street View, что значительно повысило точность картографического сервиса компании. К 2025 году система reCAPTCHA практически потеряла свою эффективность как средство защиты от ботов: современные алгоритмы машинного обучения легко обходят стандартные проверки. Тем не менее Google продолжает активно применять её, поскольку ключевая функция технологии сместилась с обеспечения безопасности на сбор детализированных данных о пользователях. По данным исследовательской группы Chuppl, reCAPTCHA создаёт уникальный цифровой отпечаток браузера, фиксируя каждое действие человека на веб-странице. Доктор Эндрю Сирлз (Andrew Searles), исследователь компьютерной безопасности из Калифорнийского университета в Ирвайне (UC Irvine), в своей работе Dazed & Confused: A Large-Scale Real-World User Study of reCAPTCHAv2 доказал, что основная цель reCAPTCHA — вовсе не защита пользователей, а мониторинг их цифровой активности. Согласно исследованию, система анализирует не только куки-файлы и историю просмотров, но и ряд параметров окружения: отрисовку графического холста, разрешение и параметры экрана, траекторию и скорость движения курсора, сведения о пользовательском агенте и другие технические характеристики. Эти данные формируют детализированный профиль пользователя, который может использоваться в рекламных и аналитических целях. Дополнительно исследование показало, что reCAPTCHA замедляет взаимодействие пользователей с веб-ресурсами. В эксперименте, охватившем 3 600 человек, выяснилось, что решение визуальных задач занимает на 557 % больше времени, чем стандартное нажатие на чекбокс «Я не робот». Это приводит к значительным потерям времени и снижает удобство работы с сайтами, особенно в ситуациях, требующих оперативных действий. По подсчётам исследователей, общее количество времени, затраченное пользователями на прохождение reCAPTCHA, составило 819 млн часов. В финансовом эквиваленте эти потери оцениваются в $6,1 млрд — именно столько составил бы потенциальный заработок пользователей, если бы они использовали это время на оплачиваемый труд. Однако для Google ситуация обратная: сбор данных с помощью reCAPTCHA приносит компании колоссальные выгоды. Оценочная стоимость информации, собранной благодаря этой технологии, достигает $888 млрд, что делает её одним из важнейших инструментов коммерческой аналитики. Тем не менее отказаться от reCAPTCHA невозможно. Крупнейшие веб-платформы, включая банковские сервисы, социальные сети и интернет-магазины, продолжают использовать её, делая эту технологию неотъемлемой частью современного цифрового пространства. Пользователь, желающий полноценно работать в интернете, неизбежно сталкивается с проверками reCAPTCHA, передавая тем самым свои данные Google. Приложение DeepSeek уличили в передаче конфиденциальных данных без шифрования
08.02.2025 [18:43],
Павел Котов
Мобильное приложение DeepSeek для Apple iOS отправляет конфиденциальные данные через интернет, подвергая их угрозе перехвата и манипуляций. Об этом сообщила компания NowSecure, специалисты которой провели аудит безопасности приложения и выявили несколько вопиющих проблем. 
Источник изображений: nowsecure.com Шифрование пользовательских данных при работе с приложением отличается серьёзными огрехами в реализации: используется небезопасный алгоритм симметричного шифрования 3DES, жёстко закодирован ключ шифрования, есть повторное использование векторов инициализации. Данные отправляются на серверы под управлением платформы облачных вычислений и хранения Volcano Engine, принадлежащей ByteDance (владеет TikTok). «В приложении DeepSeek для iOS глобально отключена App Transport Security (ATS) — защита на уровне платформы iOS, предотвращающая отправку конфиденциальных данных по незашифрованным каналам. Поскольку эта защита отключена, приложение может отправлять (и отправляет) незашифрованные данные через интернет», — отмечает NowSecure. 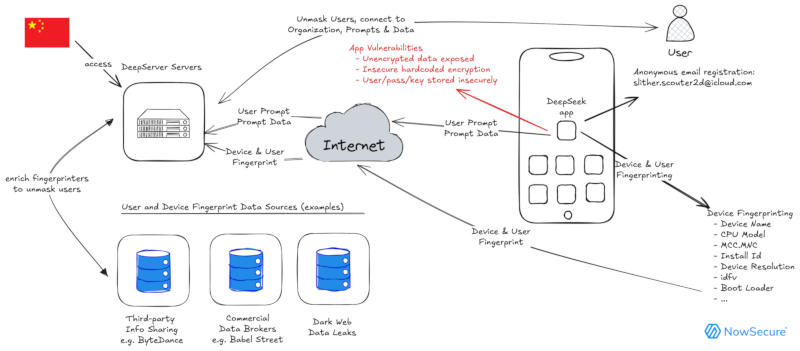 Специализирующаяся на кибербезопасности компания Check Point ранее сообщила о зафиксированных случаях, когда злоумышленники использовали ИИ-платформы DeepSeek, Alibaba Qwen и OpenAI ChatGPT для создания инструментов кражи данных, для генерации недопустимых материалов и оптимизации скриптов для рассылки спама. Сервис DeepSeek, кроме того, отправляет учётные данные пользователей в China Mobile — оператору, деятельность которого запрещена в США, сообщило Associated Press. Китайские корни приложения уже побудили американских законодателей добиваться запрета использования DeepSeek на всех принадлежащих правительству устройствах — по их мнению, администрация сервиса может делиться информацией о пользователях с китайскими властями. Решение о запрете уже приняли в Австралии, Италии, Нидерландах, Южной Корее, Индии и на Тайване; в США сервис нельзя использовать на устройствах Конгресса, NASA, ВМС, Пентагона и штата Техас. Взрыв популярности DeepSeek принёс некоторые проблемы и самому проекту: ему пришлось отбиваться от DDoS-атак, исходящих от ботнетов hailBot и RapperBot семейства Mirai. Бренд DeepSeek используется и в схемах, связанных с инвестиционным и криптовалютным мошенничеством, распространением вредоносного ПО, создаются поддельные страницы, имитирующие официальный сайт проекта. Microsoft сделала более приватным режим «Инкогнито» в Chrome для Windows, но никому не сказала
07.02.2025 [15:12],
Владимир Фетисов
Обычно Microsoft старается убедить пользователей отказаться от использования браузера Chrome и перейти на Edge. Однако на этот раз софтверный гигант неожиданно повысил привлекательность веб-обозревателя Google. Дело в том, что теперь в Windows 11 и Windows 10 больше не сохраняется история буфера обмена при просмотре веб-страниц в режиме «Инкогнито» браузера Chrome. 
Источник изображения: Monticello / Shutterstock Это не совсем новость, поскольку Microsoft без лишнего шума внесла эти изменения несколько месяцев назад. На стороне Google соответствующие корректировки были сделаны во второй половине прошлого года. Однако прежде компании никак не упоминали об этом нововведении. По умолчанию в Chromium реализован механизм хранения истории буфера обмена. В Windows скопированное содержимое Chromium синхронизируется с облачным буфером обмена, доступ к которому можно получить с помощью сочетания клавиш Win + V. Однако такая синхронизация может представлять угрозу конфиденциальности, особенно в режиме «Инкогнито». Этот режим предназначен для обеспечения более высокого уровня приватности, а синхронизация буфера обмена Chrome с облачным буфером обмена Windows этому совершенно не способствовала. Разработчики Microsoft решили исправить ситуацию, внеся изменения, которые блокируют синхронизацию буфера обмена при копировании данных в режиме «Инкогнито». После одного из плановых обновлений ОС это изменение было распространено на пользовательские ПК. «Анонимность — не основополагающее право»: в Европоле заявили, что мессенджеры обязаны раскрывать зашифрованные переписки
20.01.2025 [19:59],
Сергей Сурабекянц
Глава Европола Кэтрин Де Болле (Catherine De Bolle) призвала крупные технологические компании к сотрудничеству с правоохранительными органами в вопросах шифрования, иначе «они рискуют поставить под угрозу европейскую демократию». По её словам, компании несут «социальную ответственность» за предоставление полиции доступа к зашифрованным сообщениям, которые используются преступниками для сохранения анонимности. 
Источник изображения: Pixabay Де Болле планирует встретится с представителями компаний на Всемирном экономическом форуме в Давосе. «Анонимность не является основополагающим правом, — считает глава правоохранительного агентства ЕС. — Когда у нас есть ордер на обыск, и мы находимся перед домом, а дверь заперта, и вы знаете, что преступник находится внутри дома, население не смирится с тем, что вы не можете войти». Полиция должна иметь возможность расшифровывать сообщения преступников, чтобы бороться с правонарушениями. «Без этого вы не сможете обеспечить демократию», — уверена Де Болле.  Между технологическими компаниями и правоохранительными органами уже давно существует напряжённость из-за использования сквозного шифрования на платформах обмена сообщениями, что затрудняет получение полицией доказательств в ходе расследований. В апреле прошлого года руководители европейских полицейских служб призвали правительства и бизнес принять срочные меры, чтобы шифрование не мешало расследованию преступлений. Технологические компании последовательно сопротивляются подобным юридическим претензиям правоохранителей, утверждая, что это поставит под угрозу конфиденциальность и безопасность их пользователей. Попытки компаний сотрудничать в сфере шифрования с правоохранительными органами встречают жёсткое противодействие от сторонников конфиденциальности. Некоторые государства-члены ЕС, включая Германию, также скептически отнеслись к предоставлению правоохранительным органам большего доступа к личным сообщениям. 
Источник изображений: Europol 54-летняя бельгийка Де Болле, возглавившая Европол в 2018 году также заявила, что хотела бы расширить использование искусственного интеллекта в расследованиях агентства и рассмотреть «гибридные угрозы». Европол использует свой гигантский массив данных для помощи государствам в борьбе с серьёзной и организованной преступностью в таких областях, как терроризм, незаконный оборот наркотиков и мошенничество За последние шесть лет агентство удвоило численность персонала до примерно 1700 человек. В прошлом году Европол совместно с ФБР и Министерством юстиции США пресекли деятельность группы вымогателей LockBit. Агентство также сыграло большую роль в борьбе с незаконным оборотом наркотиков в Европе, оказав помощь в расшифровке сообщений на использованных преступниками платформах EncroChat и Sky ECC. Доступ к этим сообщениям привёл к множеству уголовных дел и тысячам арестов.  В прошлом году более 100 человек были осуждены в ходе самого крупного в истории Бельгии уголовного процесса на основании доказательств, полученных в результате расшифровки Sky ECC. В ближайшее время ожидается рассмотрение ещё нескольких дел, связанных с расшифровкой сообщений. В марте Европол планирует опубликовать свой анализ преступности за последние четыре года. Apple заявила, что никогда не продавала данные из диалогов с Siri рекламодателям
09.01.2025 [10:56],
Владимир Мироненко
Компания Apple выступила с официальным заявлением, в котором подтвердила свою приверженность конфиденциальности взаимодействия пользователей с Siri, подчеркнув, что не предоставляла данные голосового помощника рекламодателям и не продавала их кому-либо.  «Apple никогда не использовала данные Siri для создания маркетинговых профилей, никогда не предоставляла их для рекламы и никогда не продавала их кому-либо в каких-либо целях. Мы постоянно разрабатываем технологии, чтобы сделать голосового ассистента ещё более конфиденциальным, и будем продолжать это делать», — сказано в заявлении компании. Публикация Apple появилась после того, как она урегулировала коллективный иск, связанный с Siri, на сумму $95 млн. Истцы обвинили Apple в записи разговоров, полученных в результате случайных активаций виртуального помощника, и в последующем распространении информации из этих разговоров для сторонних рекламодателей. Некоторые истцы утверждали, что после упоминания в разговоре таких брендов, как Air Jordan, Easton bats, Pit Viper и Olive Garden, им показывали на устройствах Apple рекламу соответствующих продуктов. Ещё один истец заявил, что ему направили рекламу хирургического лечения после обсуждения этого вопроса в частном порядке со своим врачом. Ранее на этой неделе Apple пояснила ресурсу MacRumors, что иск был урегулирован, чтобы избежать дополнительных судебных разбирательств. В своём заявлении Apple отметила, что «не сохраняет аудиозаписи взаимодействия с голосовым помощником, если пользователи явно не соглашаются помочь улучшить Siri, и даже в этом случае записи используются исключительно для этой цели. Пользователи могут легко отказаться в любое время». Также Apple акцентировала внимание на том, что поисковые запросы и обращения к Siri не связаны с учётной записью Apple и не могут быть использованы для идентификации конкретного пользователя. Скрытые возможности Microsoft Bing Wallpaper напугали пользователей
22.11.2024 [11:56],
Дмитрий Федоров
Microsoft выпустила приложение Bing Wallpaper, которое ежедневно обновляет фон рабочего стола с использованием изображений с главной страницы Bing. Однако под этим, на первый взгляд, безобидным инструментом скрываются функции, угрожающие безопасности и конфиденциальности пользователей. Среди них: автоматическая установка расширений, вмешательство в настройки браузеров и отслеживание геолокации пользователя без его согласия. 
Источник изображений: bingwallpaper.microsoft.com Приложение Bing Wallpaper, доступное в Windows Store, предлагает пользователям коллекцию изображений со всего мира, ранее представленных на главной странице Bing. На первый взгляд, приложение кажется удобным инструментом для персонализации рабочего стола, однако результаты анализа, проведённого экспертом Рафаэлем Риверой (Rafael Rivera), говорят об обратном. Программа незаметно интегрирует в систему Bing Visual Search, расшифровывает cookie из сторонних браузеров и добавляет API геолокации, позволяющий отслеживать местоположение пользователя. Всё это происходит без уведомления и согласия пользователей, что вызывает серьёзные опасения. Приложение также пытается изменить настройки системы, принудительно устанавливая Microsoft Edge в качестве браузера по умолчанию. Если Edge не установлен, Bing Wallpaper через некоторое время инициирует запуск текущего браузера, предлагая активировать расширение Microsoft Bing Search. Эти действия, по словам Риверы, направлены на навязывание экосистемы Microsoft пользователям. Он опубликовал список расширений, которые программа автоматически добавляет в браузеры Chrome и Firefox, подчёркивая необходимость их блокировки для минимизации риска утечки данных и защиты конфиденциальности. 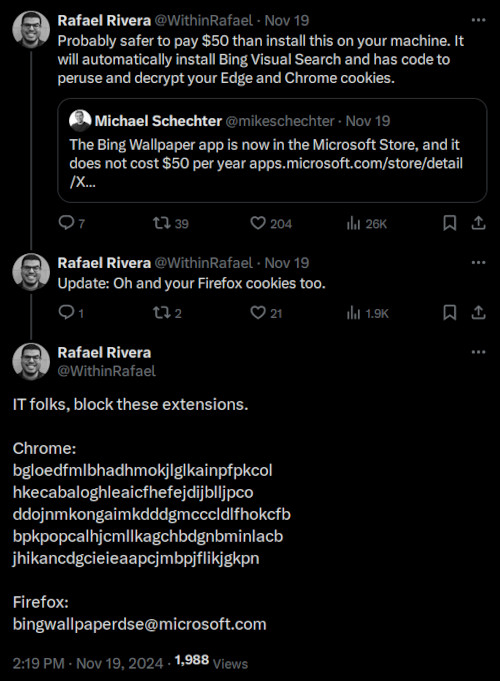
Источник изображения: @WithinRafael / X Кроме того, Bing Wallpaper использует серверные настройки, позволяющие скрытно управлять его функциональностью. Среди обнаруженных возможностей: ключ реестра, который позволяет принудительно удалить приложение. Ривера называет эту особенность «функцией самоуничтожения» и указывает на её потенциальную опасность. Такие механизмы ставят под сомнение этичность действий Microsoft и усиливают подозрения пользователей относительно реальных целей данного программного решения. Реакция пользователей на Bing Wallpaper была крайне негативной. Интернет-сообщество раскритиковало Microsoft за навязывание своего продукта, сравнив Bing Wallpaper с вредоносным ПО. Один из пользователей отметил, что если что-то бесплатно, значит, продуктом являетесь вы сами. Некоторые пользователи Windows даже предложили организовать коллективный иск, аргументируя своё решение нарушением конфиденциальности и вмешательством в личное пространство. 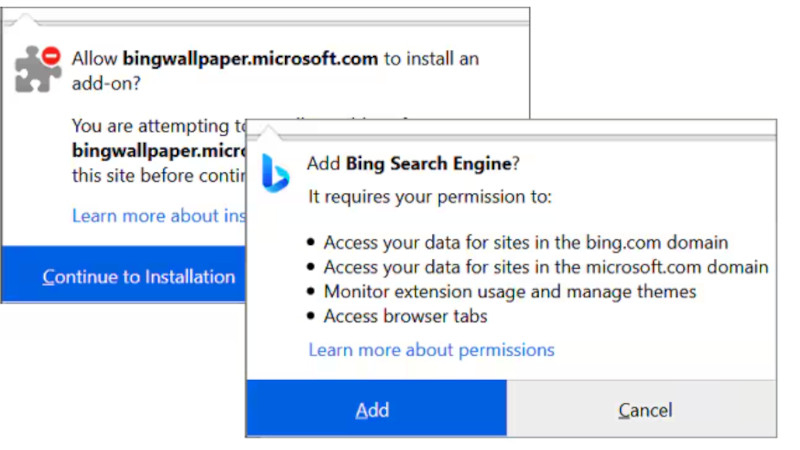 Для тех, кто ищет безопасные альтернативы Bing Wallpaper, существуют проверенные решения. Такие приложения, как Wallpaper Engine и Dynamic Wallpaper, предоставляют широкие возможности для настройки рабочего стола, не нарушая конфиденциальности. Кроме того, Windows 11 уже оснащена встроенной функцией автоматической смены обоев, которая позволяет ежедневно обновлять фон рабочего стола без необходимости использования стороннего ПО. Брокеры данных собирают огромные объёмы информации о каждом человеке, но иногда можно попросить её удалить
12.10.2024 [16:43],
Павел Котов
В интернете уже давно работают компании, называемые брокерами данных, которые собирают беспрецедентные объёмы личной информации о миллиардах людей по всему миру, но мало кто осознаёт истинный масштаб их деятельности. И не всякий знает, что в некоторых случаях можно запросить удаление этой информации. 
Источник изображения: Claudio Schwarz / unsplash.com Сегодня тщательно собирается, упаковывается и продаётся с целью извлечения прибыли каждое действие человека в интернете: каждый клик, покупка и каждый «лайк». Агрегированная персональная информация в этих условиях оказываются ценным товаром, что доказывает мировая индустрия брокеров данных. И с развитием инструментов искусственного интеллекта возникает риск, что объёмы извлекаемых сведений ещё сильнее вырастут, а мир брокеров данных, и без того непрозрачный, станет ещё более агрессивным. Это усиливает опасения по поводу конфиденциальности данных. По словам 67 % американцев, они мало или вообще ничего не понимают, что компании делают с их персональными данными, показали результаты исследования, проведённого Pew Research в 2023 году — в 2019 году таких было 59 %. И большинство (73 %) американцев считает, что у них «мало или совсем нет контроля» над тем, что компании делают с их информацией. Люди не осознают, что даже их номер телефона может использоваться брокерами данных или недобросовестными лицами для раскрытия крайне конфиденциальной информации: номера социального страхования, домашнего адреса, электронной почты и даже данных о семье. Крупные игроки в этой отрасли продают информацию ответственно, а мелкие и неизвестные могут обходить правила, нарушать этические границы и использовать персональные данные граждан так, что это может причинить им вред. Среди крупнейших игроков, по версии профильного сервиса OneRep, значатся Experian, Equifax, TransUnion, LexisNexis, Epsilon (ранее Acxiom) и CoreLogic, а также службы поиска людей Spokeo и Intelius. Эти компании работают в нескольких отраслях, обрабатывая как общедоступную информацию, так и закрытые конфиденциальные данные. Они предлагают различные услуги: маркетинговую аналитику, оценку кредитоспособности и проверку биографических сведений — при этом у них сформированы процедуры запроса собранных о себе данных или запроса на их удаление. Впрочем, компания может по-разному отреагировать за запросы из разных стран и даже штатов США. 
Источник изображения: Pawel Czerwinski / unsplash.com Ниже приводятся типы информации, которую обычно собирают брокеры данных, по словам опрошенных CNBC экспертов по вопросам конфиденциальности.
Брокеры данных продолжают работать под незначительным контролем, поскольку их работа регламентируется не везде: есть Общий регламент по защите данных (GDPR) в ЕС и некоторые нормативные акты в двадцати американских штатах, но и там нет уверенности, что эти компании действуют надлежащим образом. Чтобы начать полноценную работу по защите конфиденциальности, обществу необходимо осознать, какие объёмы личной информации передаются ежедневно, говорят эксперты. Полностью скрыться современный человек уже не может, но в его силах выработать новые привычки и овладеть новыми средствами, которые ограничат раскрытие данных. Например, некоторым мобильным приложениям следует ограничить доступ к геопозиции, в отдельных случаях лучше отказываться от сохранения файлов cookie и воздерживаться от публикации личных данных в интернете. Поможет применение защищённых браузеров и блокировщиков трекеров. Американские потребители имеют возможность отказаться от передачи своей личной информации некоторым брокерам данных, а также запросить её удаление — в отдельных случаях такой запрос обрабатывается всего один рабочий день. Но эта процедура иногда оказывается намеренно усложнённой, указывают эксперты, а ранее удалённые персональные данные могут опять появиться в той же базе, но уже из других источников. Существуют также службы, преимущественно платные, которые берут на себя составление и отправку запросов на удаление данных у разных операторов. Тем же, кто решит действовать самостоятельно, рекомендуется выполнить поиск своей персональной информации через Google и связаться с администрациями сайтов, где эта информация может обнаружиться. Или произвести поиск на ресурсах самих брокеров данных — у них же может быть форма запроса на удаление. В некоторых случаях, вероятно, потребуется решать вопрос в судебном порядке. Перспективы отрасли брокеров данных включают в себя как положительные, так и отрицательные аспекты. С одной стороны, развитие ИИ способно значительно упростить работу этим компаниям. С другой, защитой от них могут стать блокчейн, технологии повышения конфиденциальности, а также развитие законодательной базы. Но пока соответствующие нормы не приняты, брокеры данных продолжат собирать максимально возможные объёмы информации — для них это источник дохода, и чем больше информации о каждом человеке собрано, тем она точнее, а значит, дороже. Meta✴ созналась, что все фото, снятые пользователями на умные очки Ray-Ban, она применит для обучения ИИ
03.10.2024 [11:54],
Павел Котов
Компания Meta✴ призналась, что любое снятое умными очками Ray-Ban изображение, которое пользователи отправляют помощнику с искусственным интеллектом, она может использовать для обучения новых систем ИИ. 
Источник изображений: ray-ban.com «В регионах, где доступен мультимодальный ИИ (в настоящий момент это США и Канада) изображения и видео, передаваемые Meta✴ AI, могут в соответствии с нашей политикой конфиденциальности использоваться для его улучшения», — заявил представитель компании Эмиль Васкес (Emil Vazquez) ресурсу TechCrunch. Ранее компания заявляла, что снимаемые на очки Ray-Ban Meta✴ фото и видео не используются компанией для обучения систем, пока пользователь сам не отправит их ИИ на анализ — в этот момент материалы попадают под другой набор политик. Другими словами, компания использует своё первое потребительское устройство с ИИ для создания большого набора данных, который можно направить на разработку ещё более мощных моделей ИИ. Единственный способ отказаться — просто не обращаться к мультимодальным системам Meta✴ AI. Владельцы умных очков Ray-Ban Meta✴ могут не осознавать, что сами предоставляют компании большие объёмы изображений — это могут быть интерьеры их домов, фото близких и личные документы — для обучения новых моделей ИИ. Представители Meta✴ утверждают, что эти сведения есть в пользовательском интерфейсе устройства, но в действительности руководство компании либо само не знало, либо не хотело раскрывать эти сведения. Ранее стало известно, что модели ИИ Llama обучаются на публичных материалах американских пользователей в Instagram✴ и Facebook✴, но теперь определение «общедоступных данных» компания расширила на всё, что пользователи умных очков отправляют ИИ на анализ.  Накануне компания начала развёртывать новые функции ИИ для очков Ray-Ban Meta✴ — общение с устройством становится всё более естественным, и владельцы очков будут всё чаще отправлять ИИ свои данные, которые компания станет использовать для обучения новых систем. На мероприятии Meta✴ Connect 2024 она подробно рассказала об этих новых функциях, но умолчала о том, что будет делать с пользовательскими данными. В условиях обслуживания Meta✴ AI говорится: «Вы соглашаетесь, что Meta✴ будет анализировать эти изображения, включая черты лица, с помощью ИИ» — при этом компания недавно выплатила властям штата Техас $1,4 млрд, чтобы урегулировать судебное разбирательство, связанное с системой распознавания лиц. Примечательно, что некоторые связанные с обработкой изображений функции Meta✴ AI не работают в Техасе. Meta✴ также по умолчанию хранит расшифровки всех голосовых диалогов пользователей с умными очками — тоже для обучения ИИ. А вот от записи самого голоса можно отказаться: при первом входе в приложение для управления устройством пользователь выбирает, можно ли использовать записи голоса для этих целей. К слову, американские студенты уже модифицировали программную часть очков Ray-Ban Meta✴ — теперь они раскрывают имя, адрес и номер телефона любого, на кого смотрит пользователь. Россиянам стал доступен бот для жалоб на незаконную информацию в Telegram
23.09.2024 [23:44],
Владимир Фетисов
Бот для передачи информации о нарушениях правил мессенджера Telegram заработал в России с 23 сентября. О запуске бота объявил основатель сервиса Павел Дуров. Он также отметил, что специальная команда модераторов за последние несколько дней удалила «весь проблемный контент», обнаруженный в открытом поиске Telegram. 
Источник изображения: Павел Дуров Специальный бот был создан для того, чтобы пользователи мессенджера могли сообщать администрации о небезопасном и незаконном контенте. Некоторое время после запуска этого инструмента в чате бота с российскими пользователями появлялось сообщение о том, что сервис недоступен в регионе. Также Telegram обновил условия предоставления услуг и политику конфиденциальности 23 сентября, тем самым обеспечив их единообразие по всему миру. В соответствии с новой политикой, IP-адреса и номера телефонов пользователей сервиса, которые нарушают действующие правила платформы, могут быть раскрыты органам правопорядка в ответ на юридически обоснованные запросы. Павел Дуров также заявил, что поиск в Telegram мощнее по сравнению с аналогами в других сервисах обмена сообщениями, поскольку с его помощью можно находить публичные каналы и ботов. Этой функцией злоупотребляют продавцы нелегальных товаров, а также лица, распространяющие незаконную информацию. По его словам, новые правила сделают поиск более безопасным, поскольку проблемный контент больше недоступен. Meta✴ использовала почти все ваши публикации с 2007 года для обучения ИИ
13.09.2024 [07:22],
Дмитрий Федоров
Компания Meta✴, владеющая Facebook✴ и Instagram✴, подтвердила, что использует публичные посты пользователей, опубликованные с 2007 года, для обучения ИИ-моделей. Это заявление прозвучало во время правительственного расследования в Австралии. При этом миллиарды пользователей за пределами Европейского союза (ЕС) и Бразилии, сохраняющие публичность своих постов, не имеют возможности отказаться от участия в обучении ИИ. 
Источник изображения: VEPN / Pixabay Во время расследования, проводимого австралийским правительством относительно внедрения ИИ, Мелинда Клейбо (Melinda Claybaugh), глобальный директор по вопросам конфиденциальности компании Meta✴, признала, что компания использует все публичные текстовые и фотоматериалы, опубликованные совершеннолетними пользователями Facebook✴ и Instagram✴ с 2007 года. Признание прозвучало после настойчивых вопросов сенатора от партии «Зелёных» Дэвида Шубриджа (David Shoebridge). При этом Meta✴ не предоставляет возможности удаления уже собранных данных, даже в случае, если пользователь изменит настройки приватности. Meta✴ в своих материалах по конфиденциальности и блогах упоминает об использовании публичных постов и комментариев для обучения моделей генеративного ИИ. Однако детали этого процесса остаются неясными. В июне 2023 года, отвечая на запрос The New York Times о сроках начала и масштабах сбора данных, Meta✴ не предоставила конкретного ответа, отметив лишь, что изменение настроек приватности предотвратит будущий сбор. Особенно тревожит факт использования данных пользователей, которые в 2007 году могли быть несовершеннолетними. Клейбо заявила, что Meta✴ не использует данные пользователей младше 18 лет, однако не смогла дать чёткого ответа на вопрос о том, как обрабатываются аккаунты взрослых, созданные ими в детском возрасте. Сенатор Тони Шелдон (Tony Sheldon) задал вопрос о сканировании публичных фотографий детей на аккаунтах взрослых пользователей. Клейбо подтвердила, что такие данные тоже используются. В отличие от пользователей из ЕС, имеющих право отказаться от участия в обучении ИИ благодаря местным законам о конфиденциальности, и пользователей из Бразилии, где недавно запретили Meta✴ использовать персональные данные для обучения ИИ, большинство из миллиардов пользователей Facebook✴ и Instagram✴ лишены такой возможности. Клейбо не смогла уточнить, будет ли предоставлена возможность отказа австралийским пользователям или кому-либо ещё в будущем, ссылаясь на неопределённость нынешнего регуляторного ландшафта. Отсутствие возможности отказа от использования данных вызывает критику со стороны правозащитников и политиков. Сенатор Шубридж отметил, что неспособность правительства Австралии принять адекватные законы о конфиденциальности позволяет таким компаниям, как Meta✴, продолжать монетизировать и эксплуатировать даже фотографии и видео детей на Facebook✴. Данное заявление указывает на глобальную проблему: законодательство не поспевает за темпами развития технологий ИИ и методами сбора данных. Telegram обновил справочный раздел, но модерации личной переписки не будет
06.09.2024 [12:31],
Павел Котов
Администрация Telegram внесла изменения в содержимое справочного раздела, дав невнимательным гражданам повод сделать вывод, что платформа теперь будет модерировать переписку пользователей. В действительности личные и групповые чаты мессенджера так и остались приватными, утверждает его администрация. 
Источник изображения: Rubaitul Azad / unsplash.com Ранее на странице «Часто задаваемые вопросы» в разделе подачи жалоб на незаконные материалы отмечалось, что «все чаты Telegram и групповые чаты являются приватными для их участников. Мы не обрабатываем никакие связанные с ними запросы». Сейчас этот раздел гласит: «Все приложения Telegram имеют кнопки „Сообщить“, которые позволяют вам сообщать нашим модераторам о незаконных материалах — всего за несколько нажатий». Приводится также адрес электронной почты для обращения и краткие инструкции, чтобы ускорить реакцию администрации. Но это не значит, что платформа изменила свою политику и теперь собирается модерировать переписку пользователей. Фраза о приватном характере личных и групповых чатов переместилась в соседний раздел. В нём уточняется, что в отличие от личной и групповой переписки наборы стикеров, каналы и боты содержат информацию, доступную неограниченному кругу пользователей. Ранее глава Telegram Павел Дуров заявил, что администрации мессенджера приходится выдерживать баланс между безопасностью и конфиденциальностью пользователей. Copilot в Microsoft Edge научился обрабатывать PDF-файлы, и это может стать причиной утечки данных
14.08.2024 [21:10],
Сергей Сурабекянц
Microsoft стремится интегрировать максимальное количество ИИ-функций в свой веб-обозреватель. Новую порцию ИИ-улучшений получил и встроенный в Microsoft Edge инструмент для чтения документов PDF. ИИ-функция, добавленная в Copilot, сканирует документ, выделяя ключевые слова и фразы, а затем предоставляет пользователю дополнительную информацию. Обработка, вероятно, производится на серверах Microsoft, что может нарушить конфиденциальность. 
Источник изображения: Microsoft Новый инструмент доступен при нажатии кнопки, появившейся рядом с существующей кнопкой «Спросить Copilot» в интерфейсе PDF-ридера. Она запускает сканирование всего PDF-документа для генерации соответствующих ключевых слов и фраз. Затем пользователь может выбрать любое из них, чтобы открыть боковую панель Copilot в браузере и получить больше контекста или информации, связанной с этим ключевым словом. Содержимое PDF-файла, вероятно, обрабатывается и анализируется серверами Microsoft, что потенциально может привести к утечке конфиденциальной информации. Скорее всего, при обработке документов также будет производиться масштабный сбор данных для улучшения модели ИИ и изучения пользовательского опыта. Стоит дважды подумать, прежде чем использовать новую функцию для обработки документов с чувствительной информацией, например, налоговых форм или финансовых договоров. Весьма вероятно, что в ближайшее время Microsoft расширит область применения новой ИИ-функции, добавив в список обрабатываемых файлов документы Word, электронные таблицы Excel и презентации PowerPoint. Эта функция — лишь одна из нескольких возможностей на базе ИИ, которые были добавлены в Edge. Ранее обозреватель получил функцию интеллектуального поиска, которая обнаруживает связанные совпадения и слова, что упрощает поиск информации на странице. «Генератор тем» на базе ИИ преобразует текстовые подсказки в визуальные дизайны. ИИ даже научился автоматически присваивать названия группам вкладок для эффективного просмотра. Сейчас, если судить по предварительной сборке Canary, Microsoft работает над улучшением способности ИИ в Edge предлагать пользователю сайты для просмотра. Точная природа и функциональность этих нововведений пока не известна, но, учитывая стремление Microsoft к массированному внедрению ИИ везде, где только можно, рано или поздно они появятся. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться