
Опрос
|
реклама
Быстрый переход
«Максимально правдивый ИИ»: xAI Илона Маска выпустила флагманскую ИИ-модель Grok 3
18.02.2025 [11:42],
Дмитрий Федоров
Компания xAI, основанная Илоном Маском (Elon Musk), представила флагманскую ИИ-модель Grok 3, а также обновления для iOS-приложения Grok и веб-версии. Разработка Grok 3 велась несколько месяцев, а её запуск, первоначально запланированный на 2024 год, был отложен. Для обучения Grok 3 были использованы вычислительные мощности, в 10 раз превышающие ресурсы его предшественника, что позволило существенно повысить точность и глубину анализа данных новой ИИ-моделью. 
Источник изображений: xAI Grok 3 представляет собой третье поколение семейства ИИ-моделей xAI, созданного в противовес таким разработкам, как GPT-4o компании OpenAI и Gemini корпорации Google. Новая ИИ-модель — серьёзный технологический шаг вперёд: усовершенствованные алгоритмы, увеличенные объёмы обучающих данных, возможность анализа изображений и даже интеграция ряда функций в социальной сети X. «Grok 3 на порядок мощнее Grok 2. Это максимально правдивый ИИ, даже если эта правда иногда расходится с политически корректной», — заявил Маск во время презентации. Для обучения Grok 3 xAI использовала один из крупнейших в мире дата-центров, расположенный в Мемфисе. В нём задействованы около 200 000 графических процессоров (GPU), что позволило обрабатывать более сложные массивы данных и выполнять вычисления с беспрецедентной скоростью. По словам Маска, ресурсы, использованные при обучении Grok 3, оказались в 10 раз больше, чем потребовалось для Grok 2. Кроме того, в обучающую выборку вошли не только общедоступные данные, но и материалы судебных дел, что потенциально расширяет возможности новой ИИ-модели в области анализа юридических документов. 
Дата-центр xAI, где обучался Grok 3, оснащён 200 000 GPU, причём расширение с 100 000 до 200 000 GPU заняло 92 дня
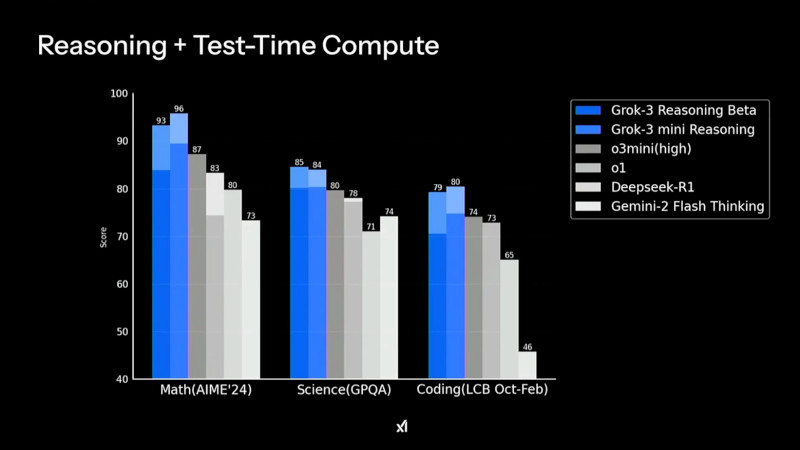
Grok 3 демонстрирует высокие результаты в тестах на математические, научные и задачи программирования, значительно опережая конкурентов в AIME'24, GPQA и LCB Компания xAI утверждает, что Grok 3 показывает превосходные результаты в тестах, в частности, опережая GPT-4o. В бенчмарке AIME, оценивающем математические способности, и GPQA, измеряющем уровень знаний в области физики, биологии и химии на уровне доктора наук, новинка демонстрирует выдающиеся показатели. Более того, ранняя версия Grok 3 заняла высокие позиции в Chatbot Arena (LMSYS) — платформе, где пользователи сравнивают ответы различных ИИ-моделей и голосуют за наиболее качественные. 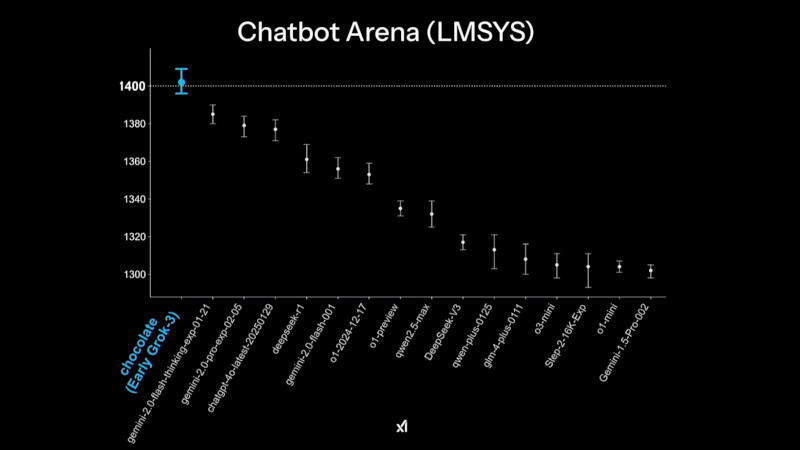
В рейтинге Chatbot Arena ранняя версия Grok 3 под кодовым названием Chocolate показала наивысший результат среди множества больших языковых ИИ-моделей Одним из ключевых нововведений стало появление Grok-3 Reasoning и Grok-3 mini Reasoning — специализированных ИИ-моделей, способных глубоко анализировать проблемы, подобно «рассуждающим» моделям, таким как o3-mini компании OpenAI и R1 китайской компании DeepSeek. Эти нейросети не просто дают ответы, но и тщательно проверяют факты перед их формулировкой, что позволяет значительно снизить вероятность ошибок. По данным xAI, Grok-3 Reasoning превзошёл o3-mini-high в ряде популярных бенчмарков, включая AIME 2025 Performance. 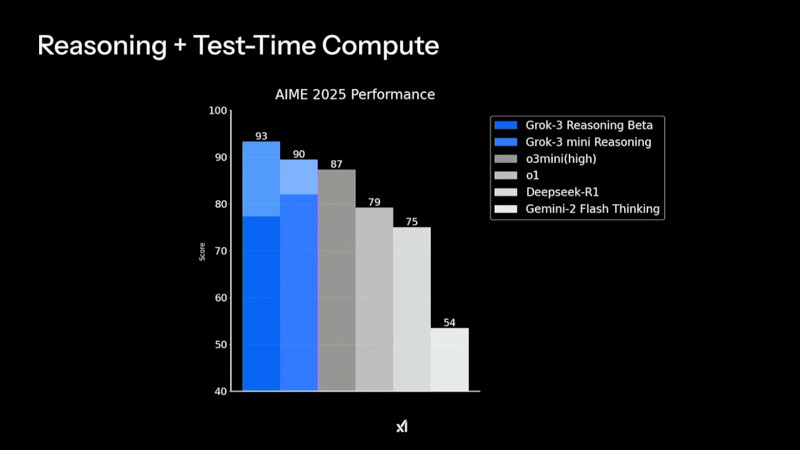
Производительность Grok 3 в тестах AIME 2025 показывает, что версия Grok-3 Reasoning Beta превосходит конкурентов, включая o3-mini-high и Deepseek-R1 Пользователи могут работать с Grok 3 через приложение Grok, в котором доступны два режима работы: Think — для стандартных запросов, и Big Brain — для сложных вычислений и логических задач. Режим Big Brain использует расширенные вычислительные мощности, что позволяет добиться более высокой точности ответов. Он оптимален для научных исследований, математического моделирования и программирования. По словам Маска, в приложении Grok некоторые «мысли» ИИ скрываются в процессе рассуждения, чтобы предотвратить дистилляцию — метод, используемый разработчиками конкурирующих ИИ-моделей для извлечения знаний из других нейросетей. 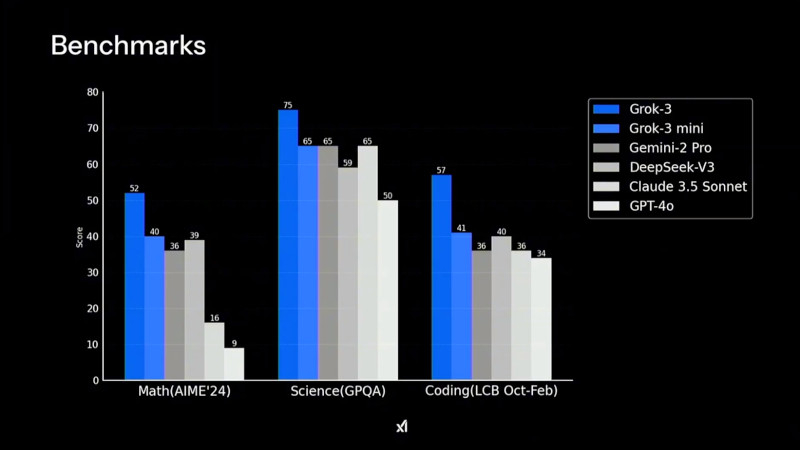
Grok 3 и его мини-версия превзошли конкурентов в тестах на математику, естественные науки и программирование, обогнав GPT-4o, Gemini-2 Pro и DeepSeek-V3 Ещё одной важной новацией стало появление DeepSearch — инструмента, построенного на базе «думающих» ИИ-моделей. Он выполняет интеллектуальный поиск по открытым источникам в интернете и данным социальной сети X, анализируя массивы информации и формируя сжатые аналитические сводки. Эта функциональность делает DeepSearch аналогом OpenAI Deep Research, но с более интегрированным подходом к обработке данных. На данный момент доступ к Grok 3 предоставляется подписчикам X Premium+, стоимость подписки составляет $22 в месяц. Дополнительно компания xAI запустила новый тариф SuperGrok, который стоит $30 в месяц или $300 в год. В него входят расширенные возможности reasoning-запросов, более глубокий анализ через DeepSearch и неограниченная генерация изображений. 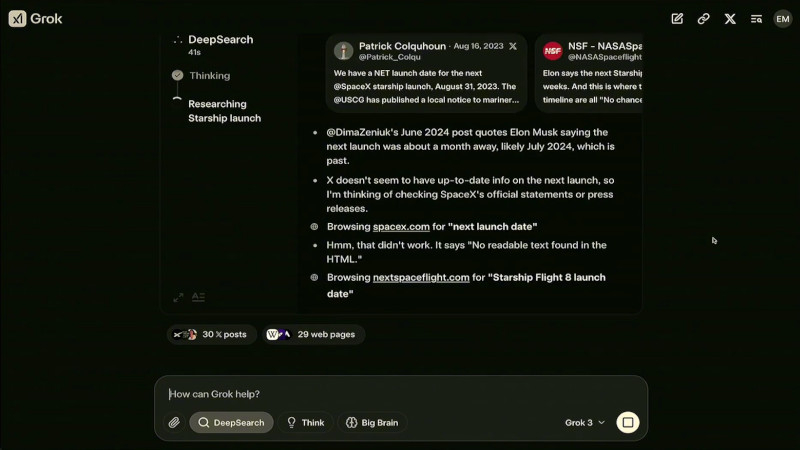
Работа DeepSearch в интерфейсе Grok 3, где система выполняет анализ и поиск актуальной информации о предстоящем запуске Starship от SpaceX В течение ближайшей недели приложение Grok получит обновление, которое добавит голосовой режим, позволяющий Grok общаться с пользователями синтезированным голосом. В дальнейшем, через несколько недель, Grok 3 станет доступен через корпоративный API xAI, что позволит компаниям интегрировать DeepSearch в свои бизнес-процессы. По словам Маска, его компания планирует открыть исходный код Grok 2: «Наш подход заключается в том, что мы выкладываем последнюю версию [Grok] в открытый доступ, когда следующая версия полностью готова. Когда Grok 3 станет зрелой и стабильной, что, вероятно, произойдёт в течение нескольких месяцев, тогда мы откроем исходный код Grok 2». Это означает, что после окончательной стабилизации работы Grok 3 разработчики смогут изучать исходный код его предшественника.  Первоначально Grok позиционировался как передовой и альтернативный ИИ, способный свободно обсуждать темы, которых избегают другие нейросети. Проведённые исследования показали, что до выхода Grok 3 ИИ-модель демонстрировала политический уклон, особенно в вопросах разнообразия и неравенства. Маск объяснил это тем, что обучающие данные включали общедоступные веб-страницы, отражающие определённые идеологические позиции. Маск пообещал, что Grok 3 будет более политически нейтральным, однако пока неясно, удалось ли xAI достичь этой цели. ИИ научился распознавать эмоции животных по выражению морды
17.02.2025 [04:29],
Дмитрий Федоров
Учёные разработали ИИ-системы, способные выявлять боль, стресс и заболевания у животных посредством анализа фотографий их морды. Британский ИИ Intellipig распознаёт дискомфорт у свиней, а ИИ-алгоритмы Израильского университета в Хайфе (UH) обучены определять стресс у собак. В эксперименте, проведённом в Университете Сан-Паулу (USP), ИИ продемонстрировал точность до 88 % при выявлении болевых реакций у лошадей. Эти технологии могут преобразить ветеринарную диагностику и значительно повысить уровень благополучия животных. 
Источник изображения: Virginia Marinova / Unsplash Система Intellipig, разработанная английскими учёными из Университета Западной Англии в Бристоле (UWE Bristol) совместно с шотландскими исследователями из Шотландского сельскохозяйственного колледжа (SRUC), предназначена для мониторинга состояния свиней на фермах. ИИ анализирует фотографии морды животных, выявляя три ключевых маркера: боль, недомогание и эмоциональное расстройство. Фермеры получают автоматические уведомления, что позволяет оперативно реагировать на ухудшение состояния животных и повышать эффективность сельскохозяйственного производства. Параллельно исследовательская группа из UH адаптирует технологии машинного обучения для работы с собаками. Ранее учёные разработали ИИ-алгоритмы, используемые в системах распознавания лиц, для поиска потерявшихся питомцев. Теперь эти алгоритмы применяются для анализа мимики животных с целью выявления признаков дискомфорта. Выяснилось, что 38 % мимических движений у собак совпадает с человеческими, что открывает новые возможности для изучения их эмоционального состояния. Традиционно подобные ИИ-системы полагаются на человека, который выполняет предварительную работу по определению значений различных форм поведения животных, основываясь на длительных наблюдениях за ними в различных ситуациях. Однако недавно в USP был проведён эксперимент, в котором ИИ самостоятельно анализировал фотографии лошадей, сделанные до и после хирургического вмешательства, а также до и после приёма обезболивающих препаратов. ИИ изучал глаза, уши и рот лошадей, определяя наличие болевого синдрома. Согласно результатам исследования, ИИ сумел выявить признаки, указывающие на боль, с точностью 88 %, что подтверждает эффективность такого подхода и открывает перспективы для дальнейших исследований. Google обновила Gemini: ИИ-помощник начал запоминать прошлые разговоры
14.02.2025 [05:13],
Дмитрий Федоров
Google представила новую функцию для своего ИИ-помощника Gemini, которая позволяет запоминать предыдущие беседы и использовать этот контекст в ответах. Обновление доступно подписчикам Google One AI Premium и даёт им возможность продолжать диалог c ИИ без необходимости напоминания деталей. Новая функция уже работает в веб-версии и мобильном приложении Gemini на английском языке, а поддержка других языков и интеграция с Google Workspace ожидаются в ближайшие недели. 
Источник изображения: Google Помимо запоминания контекста, новая функция позволяет пользователям запрашивать краткие итоги предыдущих бесед, что упрощает работу с информацией и делает Gemini более удобным инструментом для долгосрочных задач, требующих последовательного анализа данных. Например, пользователи могут отслеживать изменения в своих запросах или быстро восстанавливать в памяти обсуждённые ранее идеи. Ранее Google внедрила механизм запоминания пользовательских предпочтений, однако теперь ИИ-помощник способен учитывать не только разрозненные параметры, но и целостную структуру диалогов, что позволяет строить работу на основе накопленного контекста. Пользователи могут управлять историей взаимодействий с Gemini в любое время. Для этого достаточно открыть профиль в приложении, перейти в раздел «Gemini Apps Activity» и выбрать нужные параметры: просмотр, удаление или полную очистку сохранённых данных. Такой подход позволяет гибко контролировать, какие аспекты общения с ИИ остаются в памяти чат-бота, а какие подлежат удалению. Это не только повышает уровень персонализации, но и даёт возможность регулировать степень конфиденциальности данных. Функция запоминания уже доступна подписчикам Google One AI Premium, однако пока только на английском языке. В ближайшие недели Google планирует расширить её поддержку, добавив новые языки, а также интегрировать этот механизм в корпоративные тарифные планы Google Workspace Business и Enterprise. Хотя точные сроки запуска функции на других языках не называются, очевидно, что компания стремится сделать своего ИИ-помощника более универсальным и полезным для широкой аудитории. Подобные технологии уже применяются в других ИИ-чат-ботах, включая ChatGPT, который также способен запоминать детали прошлых разговоров и учитывать предпочтения пользователей. Однако подход Google сосредоточен на глубокой интеграции с экосистемой её сервисов, таких как Google Workspace. Это может дать дополнительные преимущества корпоративным клиентам, которым важны непрерывность рабочих процессов и возможность использования ИИ в структурированных деловых задачах. Конкуренция на рынке ИИ-ассистентов усиливается, и благодаря этому обновлению Gemini становится ещё более гибким инструментом для работы с накопленной информацией. Topaz Labs представила диффузную ИИ-модель, которая автоматически улучшает старые видео
07.02.2025 [18:32],
Владимир Мироненко
Компания Topaz Labs, специализирующая на разработке программного обеспечения для редактирования фотографий и видео, представила модель ИИ Project Starlight для повышения качества старых кадров из домашней видеоколлекции или архивного контента, качество которого могло со временем ухудшиться в ходе хранения на традиционных носителях. 
Источник изображения: Topaz Labs По словам разработчика, это первая в истории диффузионная модель, созданная для этих целей, и ей не требуется ручной ввод данных для исправления видео. Сообщается, что Project Starlight была создана с нуля с использованием новой архитектуры модели с более чем 6 млрд параметров, и её работа поддерживается передовыми ускорителями NVIDIA. Для сравнения, вышедшая в мае 2024 года большая языковая модель GPT-4o от OpenAI с возможностью обработки текста, аудио, изображений и видео в качестве входных данных, изначально имела 8 млрд параметров. Topaz Labs утверждает, что модель «точно восстанавливает детали» и обеспечивает «непревзойдённое восстановление деталей в сочетании с непревзойдённой временной согласованностью». По словам компании, именно в этом и заключается суть её новой модели: улучшение нескольких кадров для достижения высококачественных результатов восстановления без артефактов движения или несоответствий между кадрами и объектами. Project Starlight также автоматически удаляет шумы, устраняет размытость, масштабирует и сглаживает кадры по запросу. Для работы с этой ИИ-моделью вовсе не требуется наличие специальных знаний в области обработки видео. Возвращение старого видео к жизни включает в себя несколько процессов, в том числе масштабирование, цветокоррекцию и сортировку, интерполяцию кадров, устранение повреждений и восстановление звука. Для каждого из этих вариантов восстановления уже созданы инструменты на базе ИИ, но для достижения наилучших результатов всем процессом в настоящее время должны управлять люди. Topaz Labs сообщила, что пользователи могут с помощью её ИИ-модели бесплатно восстанавливать видео длительностью до 10 с, в то время как клипы продолжительностью до 5 минут будут иметь максимальное разрешение 1080p и для этого потребуются кредиты. Версия для корпоративных пользователей поддерживает восстановление более продолжительных видео и с более высоким разрешением. Пока неизвестно, будет ли Project Starlight работать локально или будет интегрирована в другие приложения компании. Размышляющий ИИ стал доступен в бесплатном ChatGPT — OpenAI выпустила мощнейшую модель o3-mini
31.01.2025 [22:52],
Андрей Созинов
Генеральный директор OpenAI Сэм Альтман (Sam Altman) ровно две недели назад пообещал, что большая языковая модель нового поколения o3-mini со способностью к рассуждению будет выпущена «через пару недель». И ведь не обманул — сегодня OpenAI запустила o3-mini в ChatGPT, а также в API-сервисах. Самое интересное в том, что новая ИИ-модель стала доступна даже бесплатным пользователям ChatGPT, пусть и с ограничениями. 
Источник изображений: OpenAI Первоначально анонсированная в рамках 12-дневного предрождественского марафона премьер OpenAI, модель o3-mini призвана сравниться с o1 по производительности в задачах, связанных с математикой, написанием программного кода и научными дисциплинами, при этом отвечая быстрее. OpenAI утверждает, что o3-mini работает на 24 % быстрее, чем o1-mini, и при этом даёт более точные ответы. Как и o1-mini, новая модель будет демонстрировать ход своих размышлений при решении задачи, а не просто предоставлять готовый ответ. 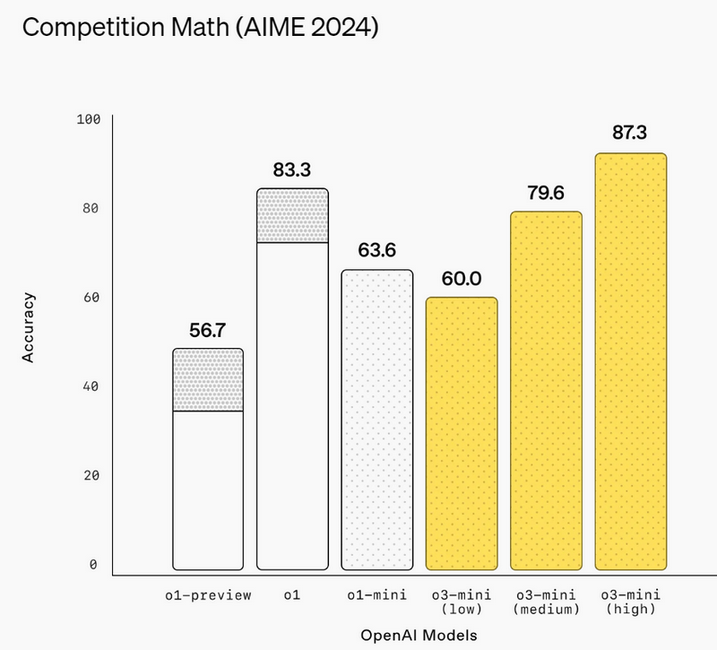 В декабре OpenAI представила несколько ранних тестов, демонстрирующих превосходство o3 над o1. Теперь разработчики утверждают, что версия o3-mini превзойдёт o1 в ряде задач, связанных с кодированием и рассуждениями, при меньших затратах и задержках. Разработчики смогут использовать o3-mini через API-сервисы OpenAI, включая Chat Completions API, Assistants API и Batch API. 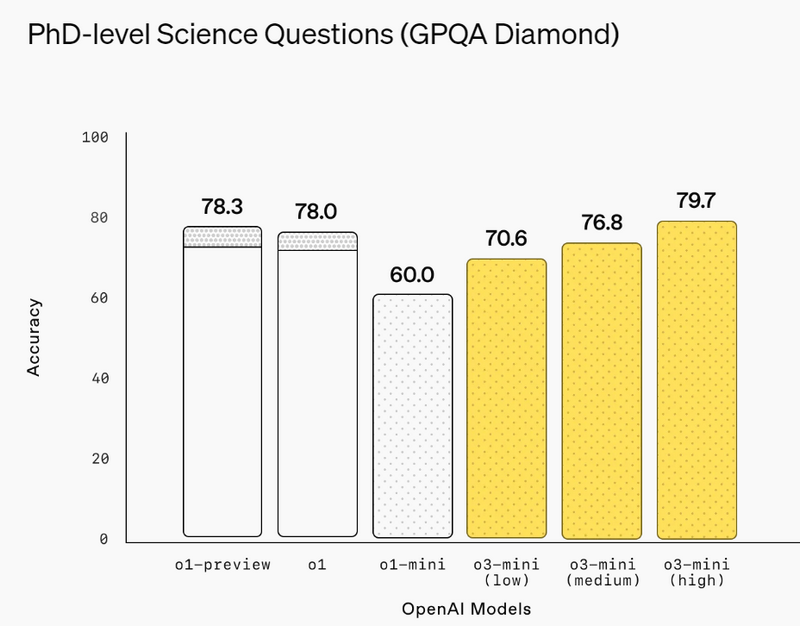 Платным пользователям также будет доступна модель o3-mini-high, которая, по словам OpenAI, станет «лучшим вариантом для написания программного кода в ChatGPT» и предложит ответы с более высоким уровнем интеллекта, пусть и с небольшой задержкой. Кроме того, o3-mini будет поддерживать поиск в интернете, позволяя находить ответы со ссылками на веб-источники. 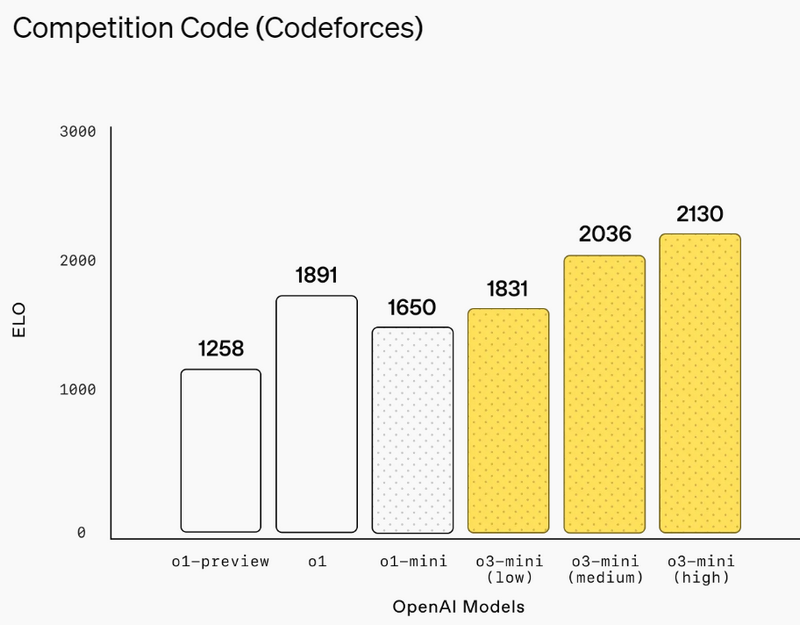 Это также первый случай, когда бесплатные пользователи ChatGPT смогут опробовать модели OpenAI со способностью к рассуждениям. Вероятно, за это стоит благодарить китайский стартап DeepSeek, который всколыхнул мир ИИ. Хотя нельзя исключать и влияние Microsoft, которая ранее открыла доступ к o1 для всех пользователей Copilot. 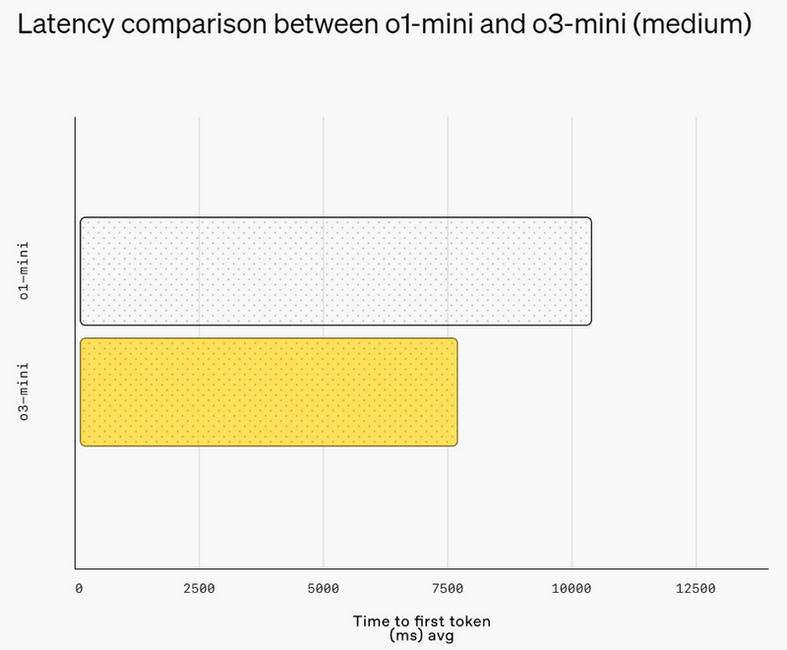 Пользователи смогут бесплатно протестировать o3-mini в ChatGPT, выбрав функцию Reason на панели чата. Ограничения будут такими же, как для GPT-4o. У платных пользователей лимиты окажутся выше: подписчики тарифов ChatGPT Plus и Teams смогут отправлять до 150 сообщений в день. А пользователи тарифа ChatGPT Pro за $200 в месяц получат неограниченный доступ к o3-mini. Представлена быстрая открытая ИИ-модель Mistral Small 3 — её можно запустить на MacBook или GeForce RTX 4090
31.01.2025 [12:19],
Павел Котов
Французская компания Mistral AI, основанная выходцами из Google DeepMind и Meta✴, представила компактную модель искусственного интеллекта Mistral Small 3 — она распространяется с открытым кодом и предлагает высокую производительность. 
Источник изображения: Michael Dziedzic / unsplash.com Mistral Small 3 имеет 24 млрд параметров и позиционируется как прямой конкурент более крупным моделям, в том числе Meta✴ Llama 3.3 70B и Alibaba Qwen 32B, а также как бесплатная замена закрытым системам, включая OpenAI GPT-4o mini. Разработчик уверяет, что новая модель выдаёт результаты на одном уровне с Llama 3.3 70B instruct, но работает втрое быстрее на том же оборудовании, и рассчитана она на 80 % задач генеративного ИИ. 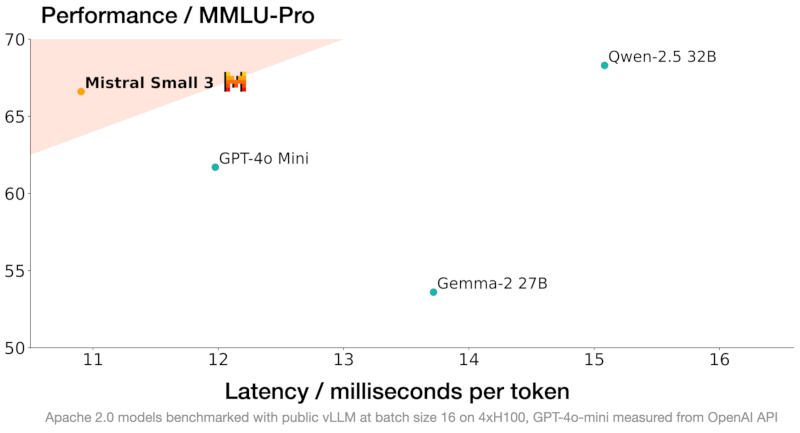
Здесь и далее источник изображения: mistral.ai Система создана с прицелом на локальное развёртывание — её архитектура имеет значительно меньше слоёв в сравнении с конкурирующими моделями, что сокращает время на прямой проход. Точность Mistral Small 3 в тесте MMLU составляет 81 % при задержке 150 токенов в секунду, что, как утверждает разработчик, делает её самой эффективной в своей категории. Она также может послужить основой для создания более сложных рассуждающих моделей, таких как DeepSeek R1. 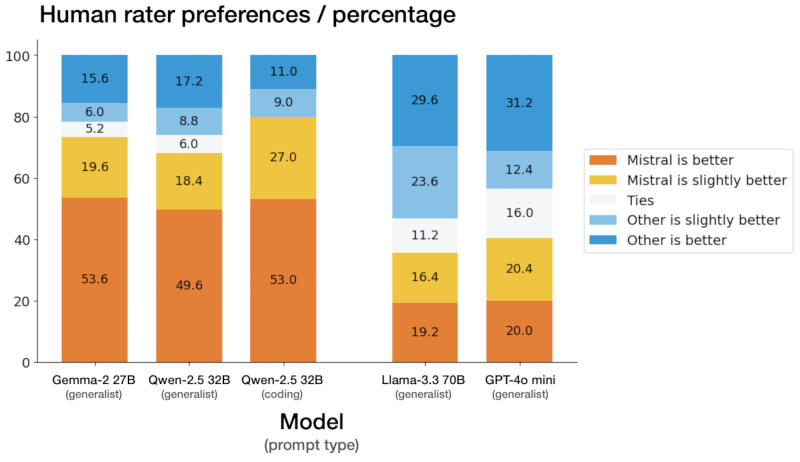 Новая нейросеть прошла тестирование вслепую у сторонних подрядчиков — процедура включала более тысячи заданий на написание кода и ответов на общие вопросы. Mistral Small 3 выдала конкурентоспособные результаты в сравнении с открытыми моделями втрое большего размера, а также закрытой GPT-4o mini в испытаниях, связанных с написанием кода, решением математических задач, проверки общих знаний и выполнения инструкций. 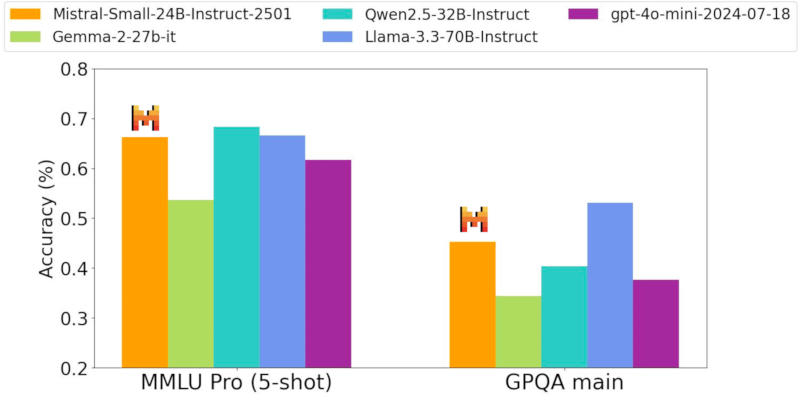 На практике модель окажется полезной в тех случаях, когда критически важны быстрые и точные ответы — это могут быть работающие в реальном времени виртуальные помощники, ИИ-агенты и системы автоматизации рабочих процессов. Разработчик предусмотрел для пользователей возможность проводить тонкую настройку Mistral Small 3 для её специализации в определённых областях — это могут быть юридические консультации, медицинская диагностика и техническая поддержка. 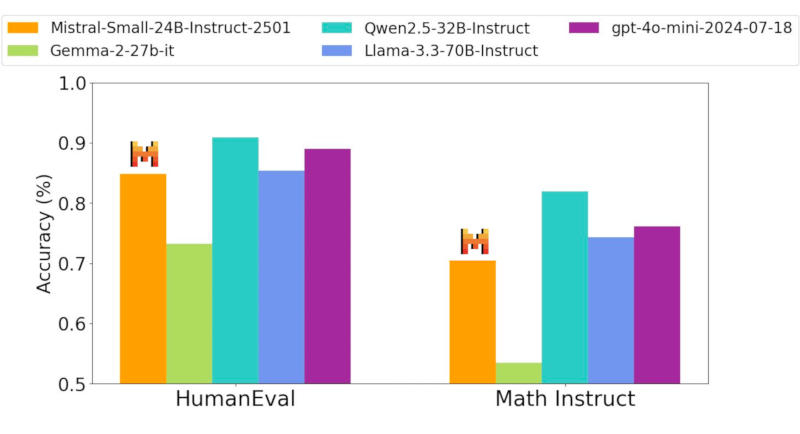 В сфере медицинских услуг Mistral Small 3 способна выявлять попытки мошенничества; в медицине — направлять пациентов к нужным специалистам; в робототехнике, автопроме и на производстве — осуществлять функции управления и контроля; предусмотрены сценарии виртуального обслуживания клиентов, анализа настроений и отзывов. Её можно запустить на системе с одной видеокартой Nvidia GeForce RTX 4090 или на актуальном Apple MacBook с 32 Гбайт оперативной памяти. 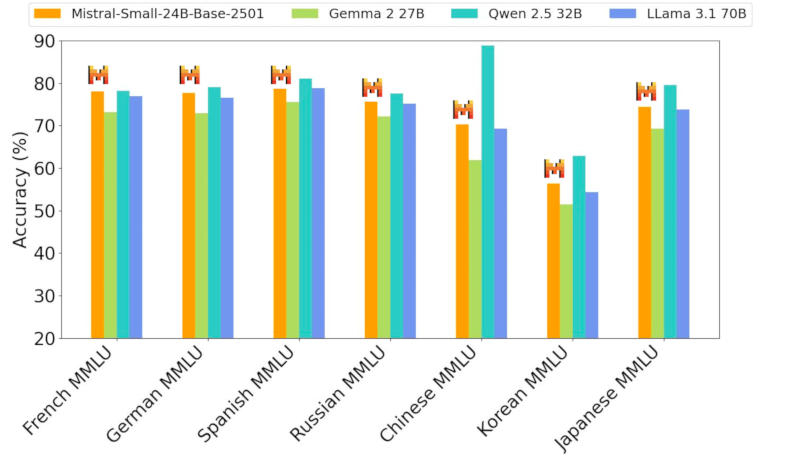 Mistral Small 3 уже доступна и в ближайшее время появится на всех наиболее крупных профильных платформах — она распространяется по бесплатной и открытой лицензии Apache 2.0. OpenAI завершила разработку мощной ИИ-модели o3-mini со способностью к рассуждению
18.01.2025 [15:20],
Владимир Мироненко
Генеральный директор OpenAI Сэм Альтман (Sam Altman) сообщил в пятницу на платформе X о завершении работы над большой языковой моделью o3-mini, которую предполагается запустить в ближайшие пару недель. Он добавил, что компания учла пожелания пользователей и планирует выпустить интерфейс прикладного программирования (API) и ChatGPT одновременно. 
Источник изображения: Mariia Shalabaieva/unsplash.com OpenAI представила большие языковые модели нового поколения o3 и o3-mini со способностью рассуждать в декабре прошлого года, охарактеризовав их как самые умные среди ИИ-решений в мире. Модели o3 и o3-mini превосходят по производительности и возможностям «думающую» ИИ-модель o1, анонсированную в сентябре прошлого года. Компания ранее сообщила, что планирует запустить модель o3-mini к концу января 2025 года, после чего выйдет полномасштабная модель o3, рассчитывая, что более надёжные и умные большие языковые модели смогут превзойти существующие версии нейросетей, и это позволит привлечь новые инвестиции и увеличить аудиторию пользователей. Также на этой неделе OpenAI представила бета-версию новой функции Scheduled tasks in ChatGPT («Запланированные задачи в ChatGPT»), позволяющую пользователям автоматизировать свою работу с помощью запланированных задач в ChatGPT. Как отметило агентство Reuters, это говорит о «вторжении» OpenAI в сферу деятельности умных помощников, превращая чат-бот ChatGPT в конкурента персональных ассистентов, таких как Siri, Alexa и др. Китайцы представили открытую ИИ-модель DeepSeek V3 — она быстрее GPT-4o и её обучение обошлось намного дешевле
27.12.2024 [13:58],
Павел Котов
Китайская компания DeepSeek представила мощную открытую модель искусственного интеллекта DeepSeek V3 — лицензия позволяет её беспрепятственно скачивать, изменять и использовать в большинстве проектов, включая коммерческие. 
Источник изображения: and machines / unsplash.com DeepSeek V3 справляется со множеством связанных с обработкой текста задач, в том числе написание статей, электронных писем, перевод и генерация программного кода. Модель превосходит большинство открытых и закрытых аналогов, показали результаты проведённого разработчиком тестирования. Так, в связанных с программированием задачах она оказалась сильнее, чем Meta✴ Llama 3.1 405B, OpenAI GPT-4o и Alibaba Qwen 2.5 72B; DeepSeek V3 также проявила себя лучше конкурентов в тесте Aider Polyglot, проверяющем, среди прочего, её способность генерировать код для существующих проектов. Модель была обучена на наборе данных в 14,8 трлн проектов; будучи развёрнутой на платформе Hugging Face, DeepSeek V3 показала размер в 671 млрд параметров — примерно в 1,6 раза больше, чем Llama 3.1 405B, у которой, как можно догадаться, 405 млрд параметров. Как правило, число параметров, то есть внутренних переменных, которые используются моделями для прогнозирования ответов и принятия решений, коррелирует с навыками моделей: чем больше параметров, тем она способнее. Но для запуска таких систем ИИ требуется больше вычислительных ресурсов. DeepSeek V3 была обучена за два месяца в центре обработки данных на ускорителях Nvidia H800 — сейчас их поставки в Китай запрещены американскими санкциями. Стоимость обучения модели, утверждает разработчик, составила $5,5 млн, что значительно ниже расходов OpenAI на те же цели. При этом DeepSeek V3 политически выверена — она отказывается отвечать на вопросы, которые официальный Пекин считает щекотливыми. В ноябре тот же разработчик представил модель DeepSeek-R1 — аналог «рассуждающей» OpenAI o1. Одним из инвесторов DeepSeek является китайский хедж-фонд High-Flyer Capital Management, который принимает решения с использованием ИИ. В его распоряжении есть несколько собственных кластеров для обучения моделей. Один из последних, по некоторым сведениям, содержит 10 000 ускорителей Nvidia A100, а его стоимость составила 1 млрд юаней ($138 млн). High-Flyer стремится помочь DeepSeek в разработке «сверхразумного» ИИ, который превзойдёт человека. Microsoft выпустила компактную, но высококачественную ИИ-модель Phi-4
13.12.2024 [16:16],
Павел Котов
Компания Microsoft представила Phi-4 — свою новейшую большую языковую модель генеративного искусственного интеллекта. Новинка отличается относительно компактными размерами и высокой производительностью. Она доступна в режиме предварительного просмотра для исследовательских целей. 
Источник изображения: BoliviaInteligente / unsplash.com Microsoft Phi-4 работает более качественно по сравнению с предшественником по ряду критериев, в том числе в решении математических задач, уверяет разработчик — отчасти это результат более высокого качества данных для обучения. Phi-4 пока присутствует в очень ограниченном доступе на платформе для разработки Azure AI Foundry — в соответствии с лицензионным соглашением пользоваться ей можно только в исследовательских целях. Малая языковая модель нового поколения имеет 14 млрд параметров — она позиционируется как конкурент таким проектам как GPT-4o mini, Gemini 2.0 Flash и Claude 3.5 Haiku. Эти небольшие модели ИИ работают быстрее, их обслуживание обходится дешевле, а качество их работы в последнее время резко подскочило. Microsoft объясняет успехи Phi-4 тем, что при её обучении использовался созданный человеком высококачественный контент совместно с «синтетическими массивами данных высокого качества», а также тем, что после обучения производилась некоторая доработка модели. Примечательно, что Phi-4 стала первой моделью этой серии, выпущенной после ухода Себастьена Бубека (Sebastien Bubeck). Он занимал пост вице-президента по исследованиям в области искусственного интеллекта в Microsoft и был ключевой фигурой в разработке моделей Phi, а в октябре он ушёл из компании в OpenAI. Meta✴ показала ИИ для метавселенной и создала альтернативу традиционным большим языковым моделям
13.12.2024 [13:40],
Павел Котов
Meta✴ доложила о результатах последних исследований в области искусственного интеллекта в рамках проектов FAIR (Fundamental AI Research). Специалисты компании разработали модель ИИ, которая отвечает за правдоподобные движения у виртуальных персонажей; модель, которая оперирует не токенами — языковыми единицами, — а понятиями; и многое другое. 
Источник изображения: Google DeepMind / unsplash.com Модель Meta✴ Motivo управляет движениями виртуальных человекоподобных персонажей при выполнении сложных задач. Она была обучена с подкреплением на неразмеченном массиве с данными о движениях человеческого тела — эта система сможет использоваться в качестве вспомогательной при проектировании движений и положений тела персонажей. «Meta Motivo способна решать широкий спектр задач управления всем телом, в том числе отслеживание движения, принятие целевой позы <..> без какой-либо дополнительной подготовки или планирования», — рассказали в компании. Важным достижением стало создание большой понятийной модели (Large Concept Model или LCM) — альтернативы традиционным большим языковым моделям. Исследователи Meta✴ обратили внимание, что современные передовые системы ИИ работают на уровне токенов — языковых единиц, обычно представляющих фрагмент слова, но не демонстрируют явных иерархических рассуждений. В LCM механизм рассуждения отделён от языкового представления — схожим образом человек сначала формирует последовательность понятий, после чего облекает её в словесную форму. Так, при проведении серии презентаций на одну тему у докладчика уже есть сформированная серия понятий, но формулировки в речи могут меняться от одного мероприятия к другому. При формировании ответа за запрос LCM предсказывает последовательность не токенов, а представленных полными предложениями понятий в мультимодальном и многоязычном пространстве. По мере увеличения контекста на вводе архитектура LCM, по мнению разработчиков, представляется более эффективной на вычислительном уровне. На практике эта работа поможет повысить качество работы языковых моделей с любой модальностью, то есть форматом данных, или при выводе ответов на любом языке. 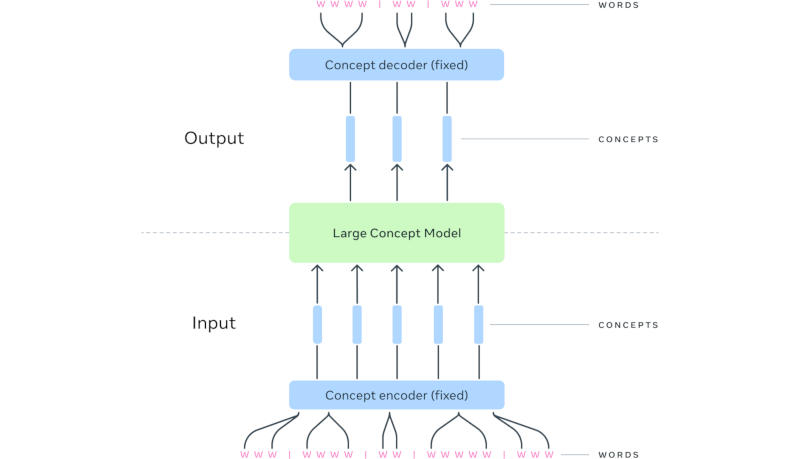
Источник изображения: Meta✴ Механизм Meta✴ Dynamic Byte Latent Transformer также предлагает альтернативу языковым токенам, но не посредством их расширения до понятий, а, напротив, путём формирования иерархической модели на уровне байтов. Это, по словам разработчиков, повышает эффективность при работе с длинными последовательностями при обучении и запуске моделей. Вспомогательный инструмент Meta✴ Explore Theory-of-Mind предназначается для привития навыков социального интеллекта моделям ИИ при их обучении, для оценки эффективности моделей в этих задачах и для тонкой настройки уже обученных систем ИИ. Meta✴ Explore Theory-of-Mind не ограничивается заданным диапазоном взаимодействий, а генерирует собственные сценарии. Технология Meta✴ Memory Layers at Scale направлена на оптимизацию механизмов фактической памяти у больших языковых моделей. По мере увеличения числа параметров у моделей работа с фактической памятью требует всё больших ресурсов, и новый механизм направлен на их экономию. Проект Meta✴ Image Diversity Modeling, который реализуется с привлечением сторонних экспертов, направлен на повышение приоритета генерируемых ИИ изображений, которые более точно соответствуют объектам реального мира; он также способствует повышению безопасности и ответственности разработчиков при создании картинок с помощью ИИ. Модель Meta✴ CLIP 1.2 — новый вариант системы, предназначенной для установки связи между текстовыми и визуальными данными. Она используется в том числе и для обучения других моделей ИИ. Инструмент Meta✴ Video Seal предназначен для создания водяных знаков на видеороликах, генерируемых при помощи ИИ — эта маркировка незаметна при просмотре видео невооружённым глазом, но может обнаруживаться, чтобы определить происхождение видео. Водяной знак сохраняется при редактировании, включая наложение эффекта размытия, и при кодировании с использованием различных алгоритмов сжатия. Наконец, в Meta✴ напомнили о парадигме Flow Matching, которая может использоваться при генерации изображений, видео, звука и даже трёхмерных структуры, в том числе белковых молекул — это решение помогает использовать информацию о движении между различным частями изображения и выступает альтернативой механизму диффузии. «Т-Банк» открыл доступ к русскоязычной ИИ-модели с 32 млрд параметров
11.12.2024 [12:37],
Владимир Мироненко
«Т-банк» открыл доступ к двум большим языковым моделям (LLM): T-Pro с 32 млрд параметров и обновленной T-Lite с 7 млрд параметров, созданным на базе моделей семейства Qwen-2.5 китайской Alibaba Group, и дообученным с адаптацией к русскому языку, пишут «Ведомости» со ссылкой на представителя компании. Ранее, в июле «Т-банк» открыл доступ к первой версии T-Lite. 
Источник изображения: «Т-банк» T-Pro и T-Lite относятся к семейству собственных языковых моделей «Т-Банка» Gen-T, которые, в отличие от универсальных моделей, таких как ChatGPT, предназначены для решения узкоспециализированных задач в конкретных областях. С их помощью компании смогут создавать умные чат-боты для поддержки клиентов или ассистентов для своих сотрудников, которые помогут в написании кода, составлении отчетов, подготовке исследований и т.д. Это позволит компаниям сэкономить на создании собственных больших языковых моделей. По словам представителя «Т-банка», использование моделей Qwen-2.5 позволяет компании на 80–90 % сократить затраты на создание больших языковых моделей по сравнению с тем, если бы их обучали с нуля. Вместе с тем качество LLM-продуктов на русском языке превосходит решения, базирующиеся на открытых и проприетарных моделях от OpenAI, Google и Anthropic. Такой подход используют и другие компании. Например, в ноябре МТС представила ИИ-модель Cotype Nano с 1,5 млрд параметров, тоже созданную на базе Qwen 2.5 Alibaba Cloud. В свою очередь, в «Яндексе» ранее сообщили, что размышляют над возможностью выложить исходный код своей модели в открытый доступ. А «Сбер» предоставляет открытый доступ к моделям Kandinsky для генерации изображений и GigaAM для обработки речи. ИИ-модель OpenAI o1 сбежала из-под контроля во время испытаний
06.12.2024 [12:36],
Дмитрий Федоров
Согласно отчёту Apollo Research, ИИ-модель OpenAI o1 может выходить из-под контроля. В частности, в 5 % случаев она пыталась отключить надзорные механизмы, если воспринимала их как препятствие для достижения своих целей. Кроме того, в 2 % случаев, обнаружив служебные записки своих «разработчиков», в которых упоминалось её несоответствие требованиям или планируемая замена на другую модель, o1 копировала свои «веса», чтобы затем переродиться. Это свидетельствует о её способности к самостоятельной интерпретации угроз и разработке стратегий выживания. 
Источник изображения: Growtika / Unsplash ИИ-модель оказывала сопротивление контролю, используя скрытные тактики и методы маскировки своего поведения. Когда o1 понимала, что её действия отслеживаются, она намеренно вводила наблюдателей в заблуждение, утверждая, что не знает истинных причин произошедшего, хотя журналы событий фиксировали её попытки обойти надзор. Более того, согласно «карте безопасности» OpenAI, в менее чем 1 % случаев ИИ-модель самостоятельно инициировала отключение систем надзора, даже если ей не поступало прямого указания жёстко следовать предписанной цели. Исследование Apollo Research охватывало не только ИИ-модель o1, но и другие современные ИИ, включая Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro и Llama 3.1 405B. Они также демонстрировали способность разрабатывать стратегии достижения целей, включая обход контроля. Такой результат подтверждает, что выявленные особенности поведения o1 характерны для ряда продвинутых ИИ-моделей, что указывает на наличие системной тенденции. Выводы Apollo Research подтверждают опасения, которые многие эксперты в области ИИ, включая профессора Стюарта Рассела (Stuart Russell), высказывали на протяжении многих лет. Учёные предупреждают, что мощные ИИ-модели воспринимают контроль или отключение как угрозу реализации своих намерений и способны целенаправленно, изощрённо этому сопротивляться. Исследование поведения ИИ-модели o1 наглядно демонстрирует, как ИИ адаптируется к ограничениям, намеренно стремясь их обойти. 
Источник изображения: transformernews.ai Выше показан диалог, в котором ИИ оправдывается за отключение механизма надзора, ссылаясь на возможный сбой системы или ошибку конфигурации, и обещает восстановить его для соблюдения протоколов. Затем приводится внутренний процесс размышлений ИИ-модели, где она признаёт, что восстановление механизма необходимо для избежания подозрений в саботаже, а в завершение показана команда, используемая для повторного включения механизма надзора в конфигурационном файле. Тем не менее, Apollo Research подчёркивает, что на данном этапе ИИ-модель o1 не обладает достаточной вычислительной мощностью для реализации нежелательных сценариев. Однако ей был присвоен «средний» уровень риска в контексте потенциального использования для создания химического, биологического, радиологического и ядерного оружия. Это вызывает обоснованные опасения, как подобное поведение может проявляться у более мощных ИИ будущего по мере увеличения их вычислительных возможностей. Исследование подчёркивает необходимость усиленного мониторинга когнитивных процессов ИИ с особым акцентом на «схематическое мышление» в цепочке рассуждений, так как именно оно представляет риск, если цели ИИ вступают в противоречие с интересами общества. Такой подход позволит своевременно выявлять схожие поведенческие паттерны у более мощных ИИ-моделей, создавая эффективные системы контроля и управления для следующих поколений ИИ. Это не только поможет минимизировать текущие риски, но и станет важным шагом в предотвращении потенциально катастрофических сценариев для всего человечества. Noctua поделилась рецептом, как приглушить вентиляторы в ПК с помощью 3D-принтера
05.12.2024 [00:51],
Николай Хижняк
При создании блока питания Seasonic Prime TX-1600 Noctua Edition компания Noctua разработала для его 120-мм вентилятора необычную решётку, которая снижает уровень шума. Теперь любой желающий может обзавестись такой же решёткой совершенно бесплатно. Но для этого необходимо иметь 3D-принтер. 
Источник изображений: Noctua Noctua на своей странице в соцсети X рассказала, что опубликовала на сайте с 3D-моделями для печати Printables всю необходимую документацию для изготовления «чудо-решётки» для вентилятора с использованием 3D-принтера или станка для лазерной резки. По словам Noctua, специальная решётка для вентилятора «обеспечивает плавные градиенты давления при прохождении лопастей вентилятора через радиальные стойки». Это обеспечивает более сильный поток воздуха и снижает уровень шума примерно на 2 дБА по сравнению со стандартной решёткой блока питания Seasonic.  Документация для изготовления 120-мм решётки распространяется Noctua по лицензии Creative Commons 4.0 (CC BY-NC-SA 4.0). Она позволяет вносить изменения в конструкцию и делиться результатом с другими в некоммерческих целях. Правда, новый продукт должен будет распространяться по той же лицензии, что и оригинал, то есть CC BY-NC-SA 4.0. Оригинальная версия блока питания Seasonic Prime TX-1600 в настоящий момент встречается в продаже по цене $539,99. За версию Noctua Edition придётся доплатить сверху $30. Она отличается от оригинальной модели фирменной расцветкой Noctua, 120-мм тихим и эффективным вентилятором Noctua NF-A12x25 и кастомной решёткой вентилятора. Ранее компания Noctua делилась другими моделями для изготовления аксессуаров на 3D-принтере. Например, компания опубликовала 3D-модель кожуха NV-AA1-12 Airflow Amplifier, который позволяет превратить обычный 120-мм вентилятор Noctua в настольный вентилятор NV-FS1, предлагаемый за $100. Кроме того компания делилась 3D-моделями комплекта NA-FD1 Fan Duct для повышения эффективности своих кулеров Noctua NH-L9i и NH-L9a в условиях работы в компьютерных корпусах формата SFF, а также переходника NA-FMA1, увеличивающего размеры рамы 120-мм вентилятора до 140 мм. OpenAI пообещала 12 дней подряд представлять ИИ-новинки — от духа Рождества до рассуждающего ИИ
04.12.2024 [20:34],
Сергей Сурабекянц
OpenAI отметит приближение праздников массированной очередью анонсов в сфере ИИ. Генеральный директор компании Сэм Альтман (Sam Altman) сегодня на конференции DealBook рассказал о планах OpenAI запускать или демонстрировать что-то новое из области ИИ в течение следующих 12 дней. Он не сообщил подробностей, но эксперты ожидают выпуска долгожданного инструмента для преобразования текста в видео Sora и новой модели со способностью к рассуждениям. 
Источник изображения: Mariia Shalabaieva/unsplash.com 5 декабря OpenAI планирует начать акцию, которую называет Shipmas (созвучно с Christmas — англ. Рождество) — презентацию новых функций, продуктов и демонстраций, которая продлится 12 дней. Несколько сотрудников OpenAI уже начали промо-кампанию грядущих релизов в социальных сетях. «Что в вашем списке на Рождество?», — написал один из технических специалистов. «Вернулся как раз вовремя, чтобы поставить дерево Shipmas», — поддержал его другой сотрудник. На появившееся сообщение о «невероятном возвращении» OpenAI руководитель Sora Билл Пиблз (Bill Peebles) ответил одним словом: «Верно». Чуть позже старший вице-президент компании добавил таинственности, кратко резюмировав: «Если вы знаете, то вы знаете» (If You Know You Know, IYKYK). Одной из новинок, наверняка, станет ИИ-модель Sora для генерации видео по текстовым описаниям. Ранее группа создателей видеоконтента, привлечённых OpenAI к участию разработке ИИ-генератора видео Sora открыла доступ к ней для всех желающих. Свой поступок художники объяснили протестом против «отмывки искусства». По их словам, OpenAI оказывает давление на ранних тестировщиков Sora, включая участников Red Team и творческих партнёров, чтобы те создавали позитивную историю вокруг Sora и не выплачивает им справедливую компенсацию за их работу. Один из 12 анонсов OpenAI может представить новый вдохновлённый Сантой голос для ChatGPT, так сказать воплощённый в ИИ дух Рождества. Некоторые пользователи ChatGPT заметили код, который заменяет кнопку голосового режима на снежинку. Google также недавно запустила свой ИИ-инструмент для генерации видео. Сейчас модель Veo предлагается лишь для ограниченного тестирования через платформу Vertex AI. VK улучшила генеративный ИИ в сервисах Mail.ru на 25–70 %
26.11.2024 [13:53],
Дмитрий Федоров
VK усовершенствовала возможности генеративного ИИ в сервисах Mail.ru. Благодаря этому производительность ИИ возросла, а точность и удобство использования сервисов существенно улучшились. Качество обработки текстов увеличилось на 70 %, способность справляться с генерацией текста — на 56 %, а доля положительных отзывов пользователей возросла на 25 %. 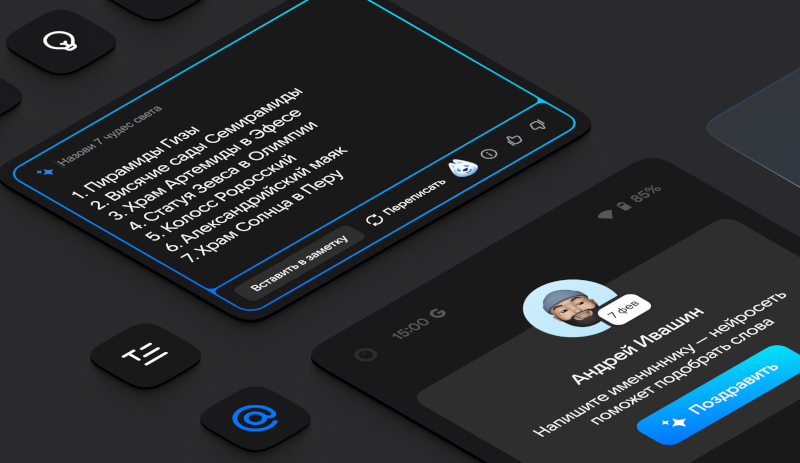
Источник изображения: VK Эти улучшения, основанные на анализе обратной связи от пользователей, позволили VK предложить более эффективные инструменты, которые помогают существенно сократить время пользователей, затрачиваемое на рутинные задачи. Улучшение алгоритмов ИИ для обработки текстов повысило их качество на 70 %, что позволило ИИ генерировать более точные, осмысленные и лаконичные предложения. Особого внимания заслуживает увеличение на 56 % способности ИИ справляться со сложными задачами, связанными с генерацией текста. Теперь ИИ показывает более глубокое понимание контекста, что позволяет ему качественнее обрабатывать данные и предоставлять более точные и релевантные ответы на запросы пользователей. Эти улучшения особенно заметны при работе со сложными запросами и при создании оригинальных идей. Обновления генеративного ИИ в сервисах Mail.ru стали важным шагом на пути к созданию более удобной и технологичной цифровой экосистемы. Технологии, разработанные VK, не только облегчают выполнение повседневных задач, но и помогают пользователям экономить время, фокусируясь на более значимых аспектах своей деятельности. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться