|
Опрос
|
реклама
Быстрый переход
Представлен первый в мире настольный компьютер с живыми клетками человеческого мозга внутри
04.03.2025 [10:24],
Геннадий Детинич
На выставке MWC 2025 австралийский стартап Cortical Labs представил первый в мире настольный компьютер CL1, использующий живые клетки человеческого мозга. Уникальная система поддерживает жизнеспособность клеток и способствует их развитию в процессе самообучения. Компьютер функционирует автономно, не требуя подключения к классическим вычислительным устройствам. Предполагается, что искусственный интеллект на подобных платформах будет не только более энергоэффективным, но и интеллектуально продвинутым.  Cortical Labs была основана в Мельбурне в 2019 году и с тех пор разрабатывала гибридную платформу «клетки-кремний» совместно с учёными Университета Монаша (Австралия). В вычислениях, требующих сложных математических операций, мозг человека уступает традиционным кремниевым процессорам. Согласно недавним исследованиям, скорость работы человеческого мозга ниже, чем у 50-летнего процессора.  Однако в задачах, связанных с интуитивным поиском решений, человеческий интеллект по-прежнему остаётся вне конкуренции. Только летом 2022 года компьютерная система Frontier стоимостью $600 млн, занимавшая площадь 630 м², впервые превзошла человека в интуитивных вычислениях. Это доказывает, что биологические вычислительные системы ещё рано списывать со счетов.  Первым значимым достижением Cortical Labs стал гибридный процессор DishBrain, основанный на CMOS-матрице и колонии нейронов. Его обучили играть в Pong: нейроны росли на сетке электродов, а затем их стимулировали микроразрядами тока, поощряя успешные удары и «наказывая» промахи. Этот метод позволил сформировать устойчивые нейронные связи, ведущие к самообучению.  С тех пор компания значительно усовершенствовала свою платформу и теперь готова к массовому производству гибридных компьютеров. Первая модель CL1, представленная на MWC 2025 в Барселоне, представляет собой биореактор — систему жизнеобеспечения для колоний нервной ткани, растущих на кремниевом чипе. Конкретное количество клеток и их конфигурацию заранее предсказать невозможно, но для технического описания планируется использовать термин КОЕ (колониеобразующие единицы). Разработчики признают, что до конца не понимают, из каких именно клеток состоит их биологический процессор и в каком соотношении они должны присутствовать. В настоящее время компания использует два метода выращивания искусственной нервной ткани: получение индуцированных плюрипотентных стволовых клеток (iPSCs) из крови грызунов и человека, а также генетические модификации. Однако точный контроль этих процессов пока недостижим, что приводит к вариативности результатов.  Несмотря на это, технология уже готова к коммерческому внедрению. Cortical Labs планирует начать поставки CL1 во второй половине 2025 года. Ожидаемая стоимость одного компьютера — $35 000, что примерно в 2,5 раза дешевле аналогов. В конце года компания запустит облачный доступ к кластеру CL1, включающему четыре секции по 30 компьютеров каждая. Это будет первый опыт объединения биокомпьютеров в кластер, и его результаты пока сложно предсказать. Такая неопределённость отпугивает инвесторов, однако успешные продажи могут вернуть доверие финансовых кругов. Как отдельные устройства, так и облачный кластер рассматриваются компанией как эксперимент. Разработчики пока не имеют чёткого представления о том, как именно система должна работать и в каких областях будет наиболее эффективна. В идеале биокомпьютеры смогут потреблять меньше энергии и быстрее справляться с генеративными моделями. Например, энергопотребление стойки из CL1 составит около 1 кВт — значительно меньше, чем у классических серверов. 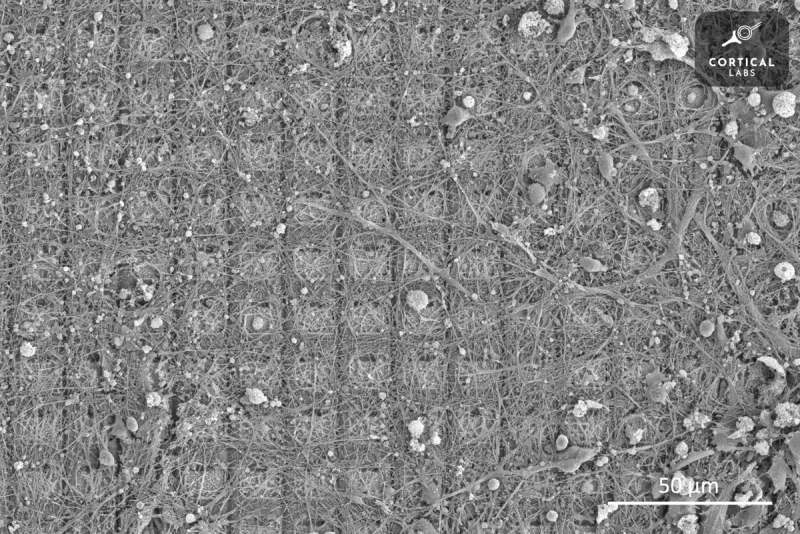
Нейроны DishBrain, растущие на массиве электродов. Источник изображения: Cortical Labs Помимо вычислительных задач, биологические компьютеры могут стать платформой для тестирования новых лекарств от нейродегенеративных заболеваний. Испытания на живых людях неэтичны, а использование колоний нервных клеток в компьютерах может стать альтернативным методом исследования. Это направление может оказаться самым ценным применением новой технологии, поскольку в конечном счёте здоровье человека важнее всего. Китайцы встроили оптическую нейронную сеть в торец оптоволокна — это подтолкнёт развитие квантовой связи, медицины и не только
18.02.2025 [10:53],
Геннадий Детинич
Дальнейшее развитие оптических технологий требует новых подходов в эпоху расцвета нейронных систем. Свойства света способствуют первичной обработке визуальной информации непосредственно в оптоволокне, что заставляет учёных искать способы воплотить такие механизмы на практике. О прорыве в этой сфере сообщили китайские учёные, которые сумели встроить оптическую нейронную сеть в торец оптоволокна для передачи изображений без искажений. 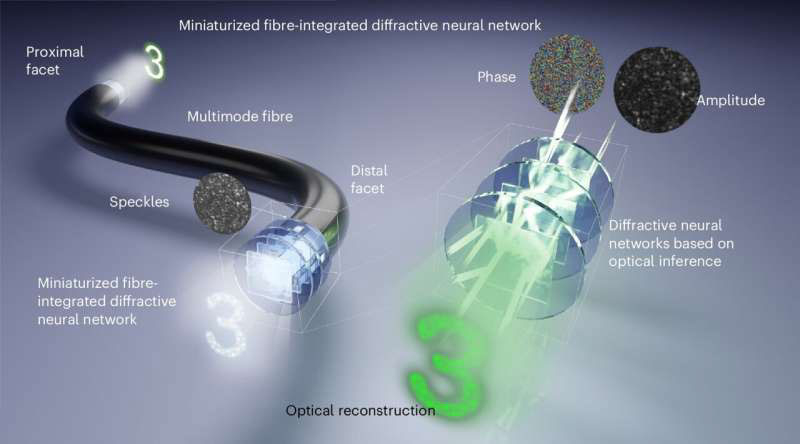
Источник изображения: USST Исследователи из Шанхайского университета науки и технологий (USST) опубликовали в журнале Nature Photonics статью, в которой рассказали о разработке технологии передачи изображений по оптоволокну для малоинвазивного эндоскопа. Учёные работали с многомодовым оптоволокном (MMF) как с более ёмким каналом, имеющим толщину с человеческий волос. Однако из-за склонности MMF к рассеиванию пришлось разработать ряд решений для его уменьшения. При этом высокая пропускная способность MMF рассматривалась как критически важный инструмент в таких областях, как квантовая информация и микроэндоскопия. В настоящее время компенсацию модовой дисперсии (рассеивания) осуществляют с помощью искусственных нейронных сетей и пространственных модуляторов света, однако эти методы дают лишь ограниченный успех в восстановлении искажённых изображений после их передачи по многомодовому оптоволокну. Учёные из USST поставили перед собой задачу преодолеть этот барьер, предложив принципиально новый подход. Исследователи разработали и интегрировали в дальний конец 35-сантиметрового оптоволокна многослойные оптические дифракционные нейронные сети. Внешне они представляют собой специально протравленные прозрачные пластинки, в которых свет преломляется определённым образом, фактически выполняя простейшие вычислительные операции со скоростью света. Такое решение позволяет обрабатывать оптическое умножение матриц и реализовывать больше связей в нейронных сетях без использования электрических схем. Это открывает возможности для таких задач, как оптическая классификация изображений, дешифрование и обнаружение фазы. 
Источник изображения: Nature Photonics 2025 Пластинки многослойных оптических дифракционных нейронных сетей были изготовлены со сторонами 150 мкм. Они позволили считывать и передавать по оптоволокну оптические изображения со сторонами 65 мкм с разрешением 4,9 мкм. В частности, учёные продемонстрировали способность системы различать группы клеток HeLa, не включённых в процесс обучения. При этом система обеспечивала высококачественную оптическую реконструкцию изображения, что подчёркивает потенциал интеграции миниатюризированных дифракционных нейронных сетей с многомодовым оптоволокном. Это создаёт беспрецедентную платформу для оптического вывода в микронном масштабе, прокладывая путь к созданию многофункциональных компактных фотонных систем, применимых в медицине, науке и квантовой фотонике. Нобелевскую премию по физике присудили отцам нейросетей и машинного обучения
08.10.2024 [15:18],
Геннадий Детинич
В основе ряда нейронных сетей, алгоритмов машинного обучения и искусственного интеллекта лежат глубокие открытия в области физики, о чём сегодня заявили представители Нобелевского комитета Каролинского института Стокгольма. Премия 2024 года за эти заслуги присуждена физику Джону Хопфилду (John Hopfield) и математику Джеффри Хинтону (Geoffrey Hinton). 
Источник изображения: nobelprize.org Джон Хопфилд родился 15 июля 1933 года, а докторскую степень по физике он получил в 1958 году в Корнеллском университете. Джеффри Хинтон родился 6 декабря 1947 года, а в 1978 году получил докторскую степень в Эдинбургском университете в сфере ИИ. Интересно отметить, что Хинтон приходится правнуком известному британскому математику Джорджу Булю (1815–1864). Сейчас он сотрудник Университета Торонто, Канада. Оба начали плотно работать над нейронными сетями с начала 80-х годов прошлого века. Джон Хопфилд стал известен в 1982 году как изобретатель ассоциативной нейронной сети, получившей его имя. Хинтон изобрёл метод, который позволял автоматизировать процесс извлечения данных для идентификации элементов изображений. Где во всём этом физика? Для создания нейросети Хопфилд воспользовался известным свойством атомов стремиться к наименьшему значению их энергии. Сеть Хопфилда описывается способом, эквивалентным поведению энергии в системе атомных спинов. Обучение происходит путем нахождения таких значений для соединений между узлами сети, чтобы сохранённые изображения имели низкую энергию. Тогда поиск сводится к такой обработке соединений между узлами, после которой энергия сети снижалась, и это вело бы к обнаружению наилучшего соответствия. Джеффри Хинтон использовал сеть Хопфилда в качестве основы для новой сети, использующей другой метод: машину Больцмана. С её помощью можно научиться распознавать характерные элементы в данных конкретного типа. Для этого Хинтон использовал инструменты статистической физики, науки о системах, построенных из множества похожих компонентов. Машина обучается путем подачи ей примеров, которые с большой вероятностью могут возникнуть при запуске машины. Машина Больцмана может использоваться для классификации изображений или создания новых примеров (рисунков), на которых она была обучена. «Работа лауреатов уже принесла наибольшую пользу. В физике мы используем искусственные нейронные сети в широком спектре областей, таких как разработка новых материалов с определенными свойствами», — прокомментировала награждение Эллен Мунс (Ellen Moons), председатель Нобелевского комитета по физике. Tesla показала, как роботы Optimus с помощью людей складывают аккумуляторы в контейнер
07.05.2024 [07:47],
Алексей Разин
На фоне первых демонстраций человекоподобных роботов Optimus, когда реальные прототипы удерживались на подставке, а способность танцевать обеспечивалась переодетым в робота человеком, последующие видео Tesla демонстрировали прогресс, но ощущение сырости изделия не покидало зрителей. В новом ролике компания показала, как обучает роботов Optimus выполнять полезную работу на конвейере. 
Источник изображения: Tesla, X В качестве одной из таких операций была выбрана укладка цилиндрических аккумуляторных ячеек типоразмера 4680 в специальный контейнер, компоновочно напоминающий кассету для яиц. На новом видео робот Optimus принимает поступающие по жёлобу аккумуляторные ячейки и укладывает их в контейнеры. Субтитры повествуют о том, что делать подобные манипуляции ему позволяет нейронная сеть, обучаемая просто по изображениям с двумерных камер, в ходе видеоролика также демонстрируется обстановка, в которой происходит обучение нескольких роботов одновременно. За каждым из них закреплён оператор, который смотрит на сортируемые предметы через некоторое подобие шлема дополненной реальности, а также позволяет электронике считывать данные о манипуляциях при помощи надетых на руку датчиков. По сути, на этапе обучения роботы должны получить возможность осуществлять подобные манипуляции самостоятельно. Как отмечает Tesla, дополнительно уделяется внимание способности робота сохранять равновесие во время всех манипуляций. В конце ролика демонстрируется робот Optimus, наматывающий круги по произвольной траектории по помещению лаборатории. Делается это, конечно же, в целях его обучения, и с каждым разом робот способен пройти всё больше и больше без посторонней помощи. 
Источник изображения: Tesla, X Представители Tesla в комментариях к видео отметили, что сейчас стараются заставить роботов Optimus двигаться быстрее и перемещаться не только по ровной поверхности, но и по более сложному ландшафту. Напомним, что Илон Маск (Elon Musk) недавно пообещал начать использование роботов Optimus на предприятиях Tesla к концу текущего года, а к концу следующего предложить их сторонним клиентам. Нейросеть «Яндекса» научилась генерировать короткие видео в «Шедевруме»
28.08.2023 [13:26],
Андрей Крупин
Команда разработчиков «Яндекса» сообщила о расширении возможностей мобильного приложения «Шедеврум» и реализации в программе функции создания коротких видеороликов с помощью генеративной нейросети. Утверждается, что компания стала первой на российском рынке, предложившей подобную технологию широкой аудитории. 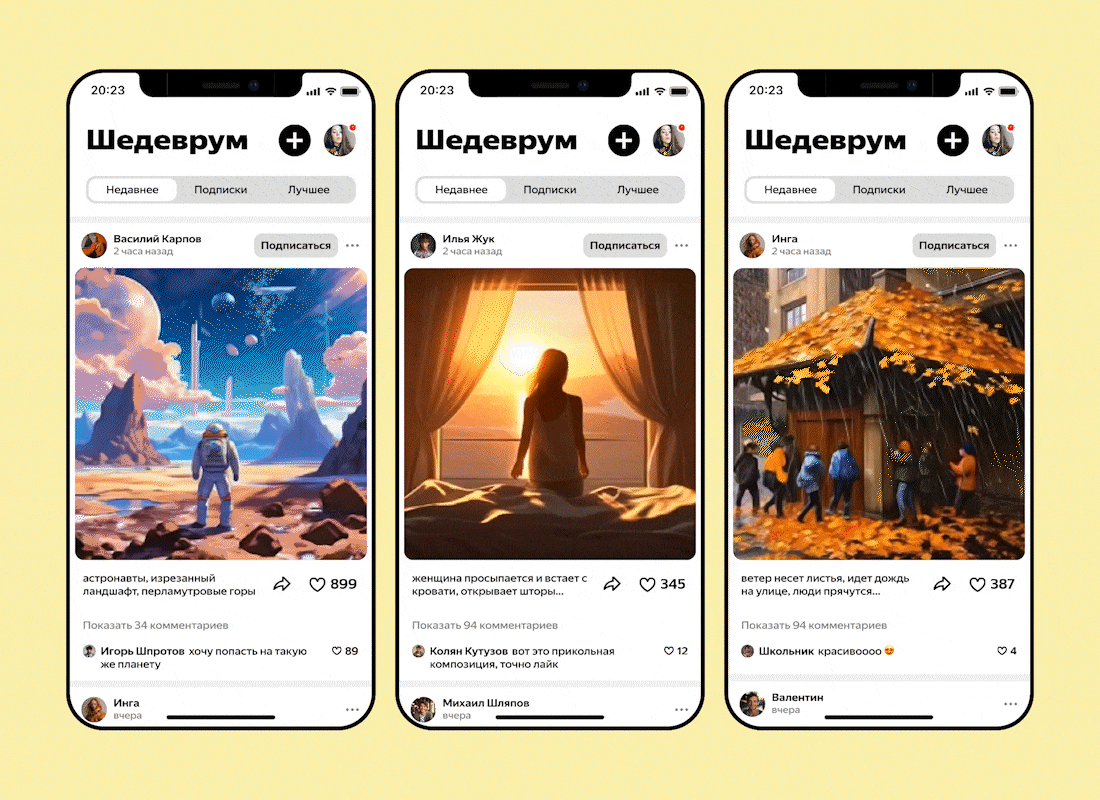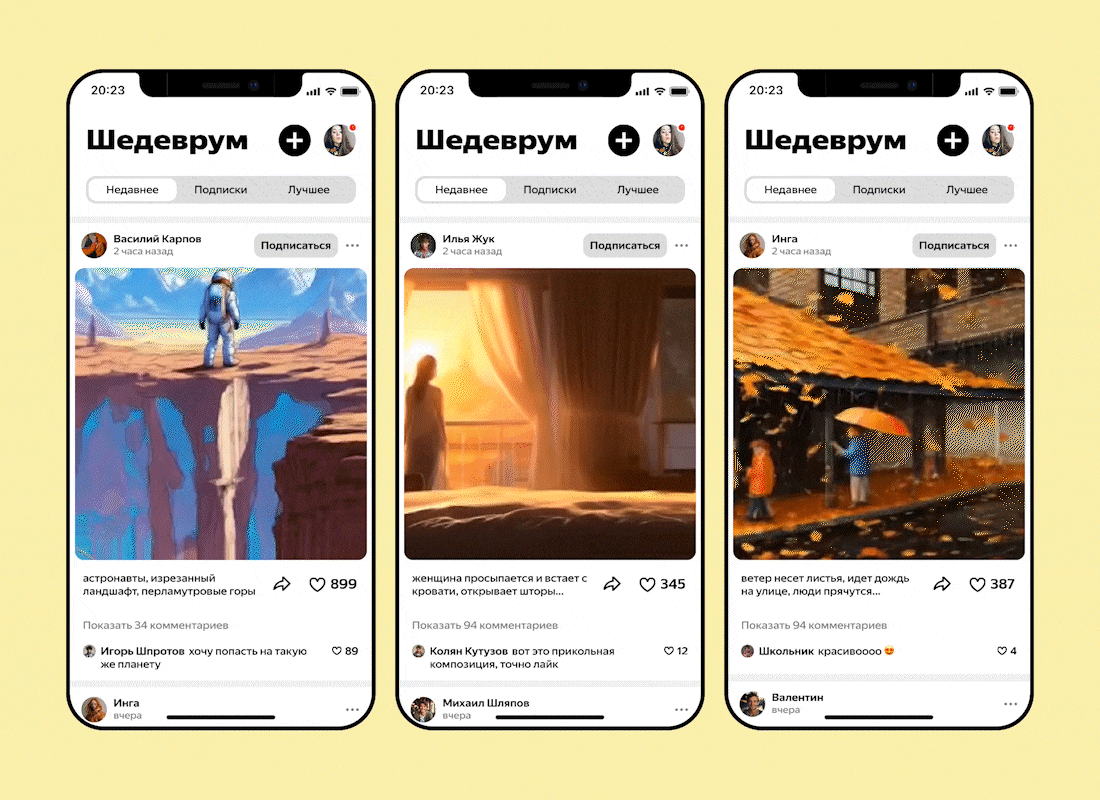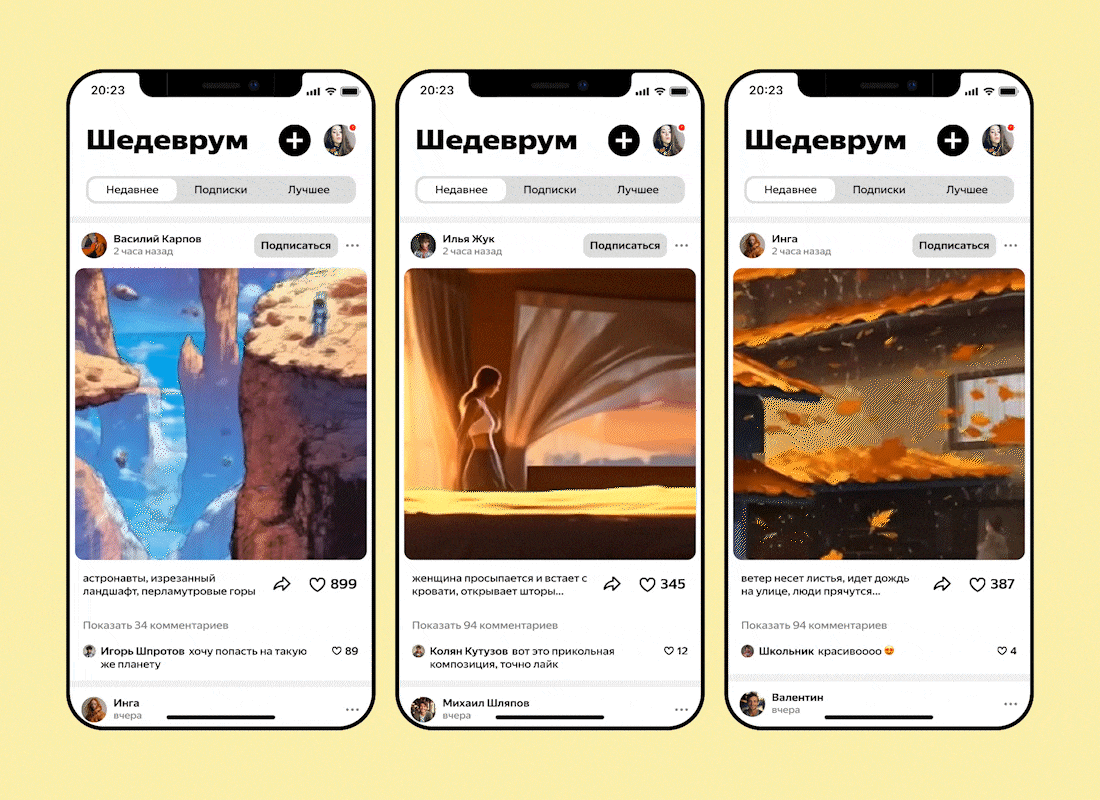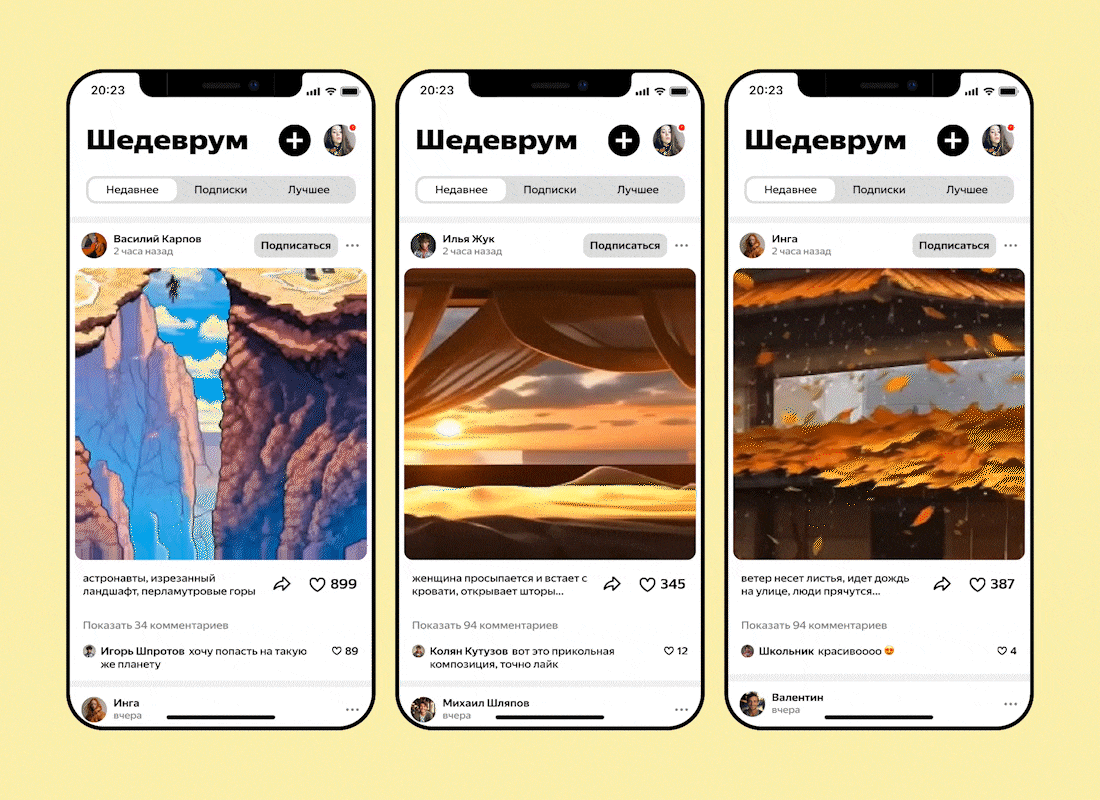
Источник анимации: «Яндекс» Для того, чтобы сгенерировать видео в «Шедевруме», достаточно описать текстом то, что хочется увидеть. В ответ приложение предложит четыре варианта первого кадра и набор анимационных эффектов для создания движения. Всего доступно семь эффектов: зум (приближение), таймлапс (ускоренная перемотка), полёт, панорама, вращение, подъём и морфинг (постепенное изменение). Для создания кадров будущего видео используется метод каскадной диффузии. С помощью этой технологии «Шедеврум» генерирует отдельные изображения. Сначала нейросеть создаёт картинки в соответствии с запросом, а затем поэтапно увеличивает их разрешение, насыщая деталями. «Шедеврум» генерирует видео длиной четыре секунды с частотой 24 кадра в секунду. После публикации ими можно поделиться с друзьями или сохранить в формате MP4. В настоящий момент функция работает в режиме тестирования и доступна в обновлённой версии приложения активным пользователям «Шедеврума». «Яндекс» представил «Шедеврум» для Android и iOS в апреле 2023 года. В основу программы положена нейронная сеть, содержащая 5 миллиардов параметров и обученная на 330 миллионах примеров изображений с текстовым описанием. В планах разработчика — обучение нейросети новым знаниям и её внедрение в другие сервисы и продукты компании. Intel показала работу нейросетевого VPU-сопроцессора Meteor Lake в редакторе изображений
29.05.2023 [19:52],
Николай Хижняк
Компания Intel продемонстрировала в рамках выставки электроники Computex работу инженерного образца процессора из будущей серии Meteor Lake в задаче, связанной с работой алгоритмов генеративной нейронной сети. 
Источник изображений: Intel Будущие процессоры Intel Meteor Lake используют децентрализованный, а не монолитный дизайн, позволяющий использовать комбинации различных чиплетов на основе разных технологических процессов. Одной из ключевых особенностей процессоров Meteor Lake станет специальный нейронный движок VPU (Versatile Processing Unit), основанный на третьем поколении технологии компании Movidius, которую Intel купила в 2016 году. Данный нейронный движок предназначен для ускорения работы процессоров Meteor Lake в задачах, связанных с различными ИИ-алгоритмами и моделями машинного обучения.  Одной из базовых задач VPU в процессорах Meteor Lake станет фото- и видеоредактирование и применение фильтров в режиме реального времени. Он сможет накладывать эффекты размытия, применять автоматическое масштабирование и заменять фон изображений. Также он получит способность в реальном времени распознавать движение глаз пользователя и жесты. Производительности нейродвижка должно даже хватить для захвата движений с помощью Unreal Engine.  Блок VPU будет достаточно мощным, чтобы поддерживать генеративные возможности ИИ, включая, например, запуск нейросети Stable Diffusion. Наличие VPU для работы с такими моделями необязательно, главное иметь достаточный объём памяти, однако использование аппаратных возможностей CPU, GPU и APU позволяет существенно ускорить работу модели ИИ. Для задействования возможностей VPU компания Intel сотрудничает с GIMP и Adobe, чтобы те добавили поддержку нейронного движка компании в свои продукты. В рамках выставки Computex компания Intel продемонстрировала работу инженерного образца мобильного процессора Meteor Lake с маркировкой Intel 0000, в состав которого входят 16 физических ядер с поддержкой 22 виртуальных потоков. По данным портала Wccftech, чип имеет конфигурацию из 6+8+2 ядер и его финальное воплощение будет относится к серии Meteor Lake-P. Конфигурация ядер у процессора весьма необычная. Производительные P-ядра и энергоэффективные E-ядра находятся в составе основного кристалла CPU. А два дополнительных ядра расположены внутри кристалла SoC. 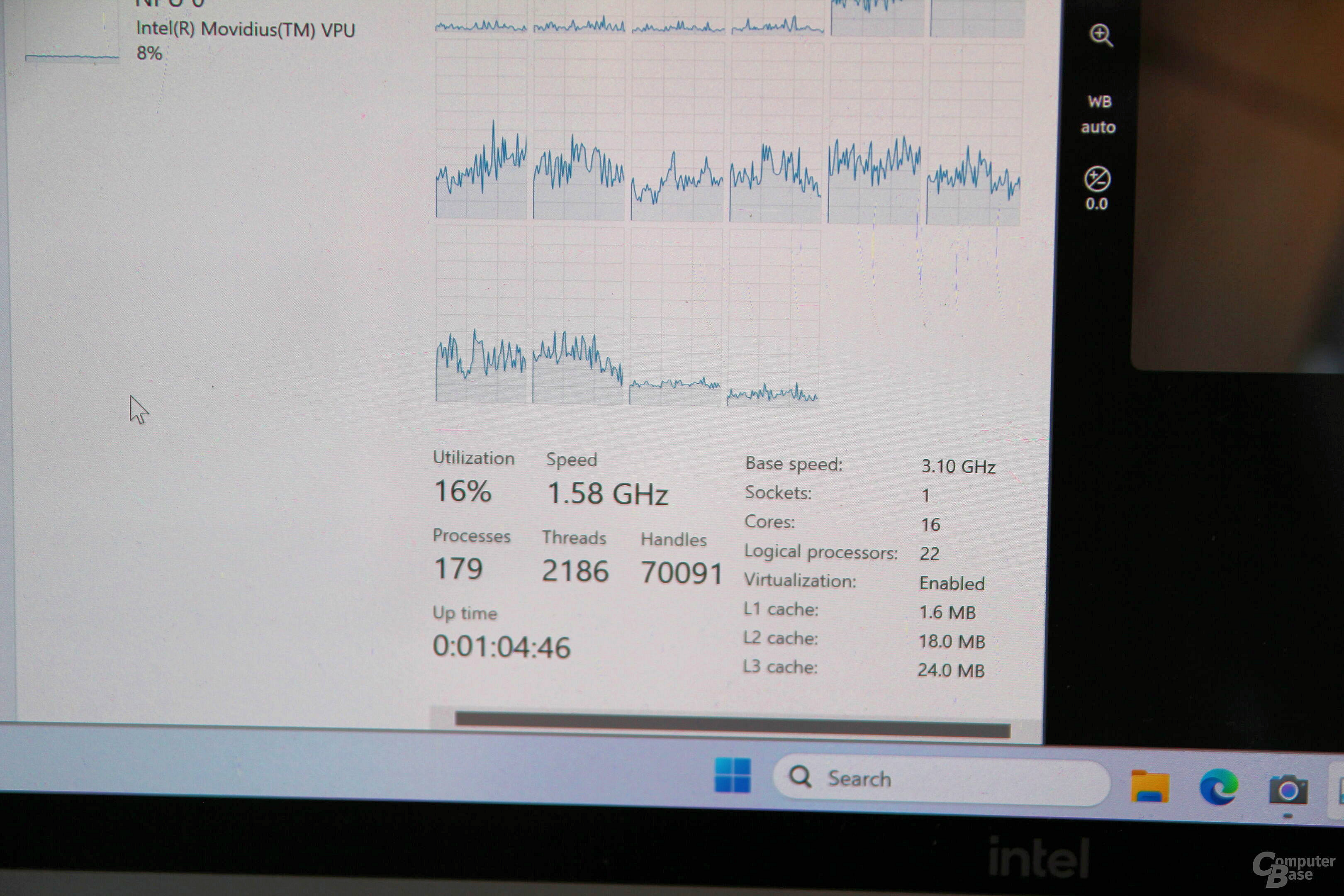 В режиме простоя чип работал на частоте 0,37 ГГц. Базовая частота процессора составляет 3,1 ГГц. Он суммарно имеет 1,6 Мбайт кеш-памяти первого уровня, 18 Мбайт кеш-памяти L2 и 24 Мбайт кеш-памяти L3. 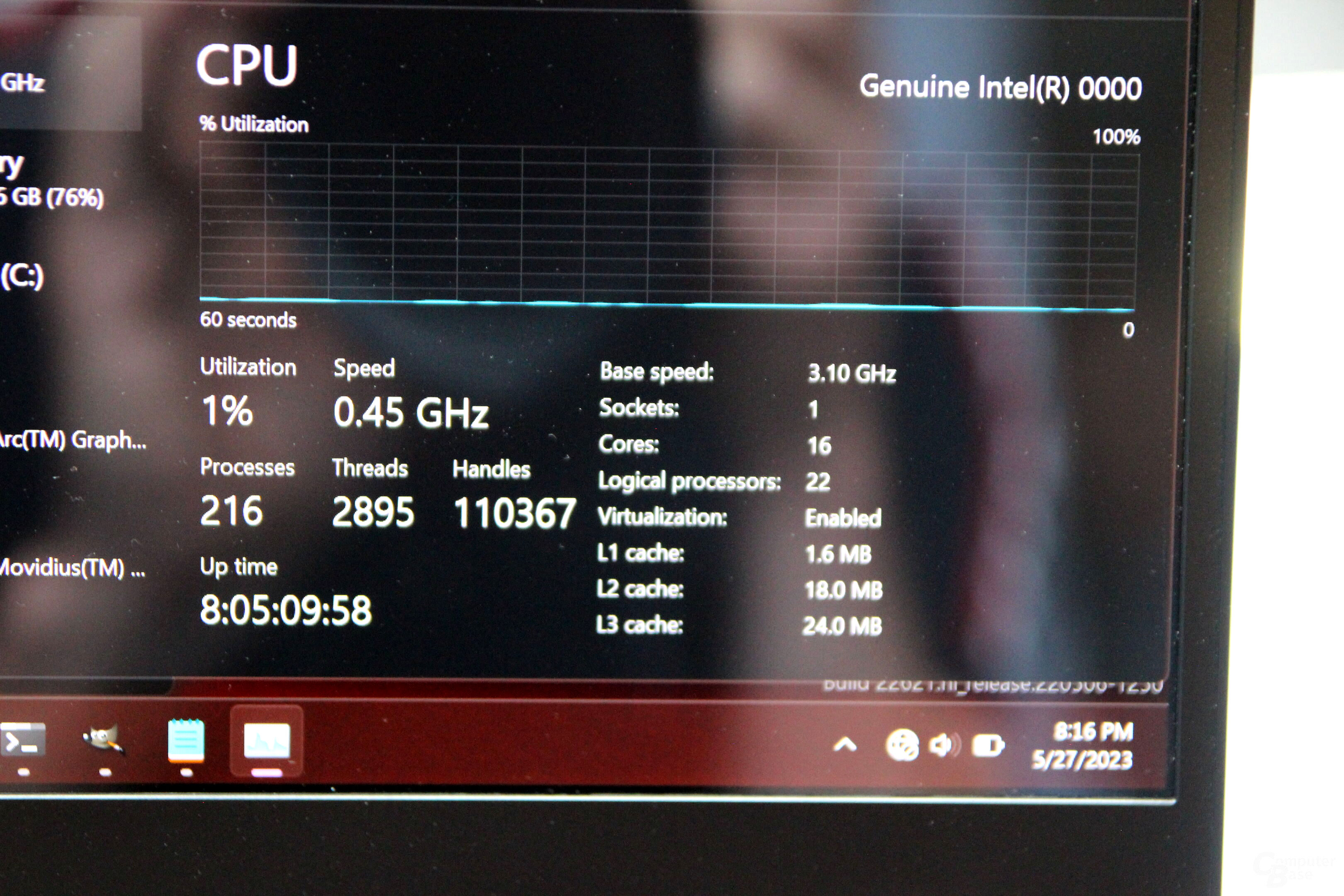 Демонстрация работы инженерного образца Meteor Lake проводилась в редакторе изображения GIMP с поддержкой ИИ-модели Stable Diffusion для генерации изображений по заданным параметрам, а затем к результату применялся ИИ-плагин для увеличения разрешения. Для задействования в работе VPU использовалась библиотека Intel OpenVINO для разработки приложений компьютерного зрения и искусственного интеллекта. Выпуск мобильных процессоров Meteor Lake ожидается к концу текущего года. Компания не комментирует последние слухи о том, что настольные Meteor Lake-S могли быть отменены. В то же время, производитель пока не подтверждает планов по их выпуску. Нейросети Chat GPT и Sage не смогли сдать «на отлично» российский университетский экзамен по истории
18.05.2023 [13:27],
Владимир Мироненко
Историки Уральского федерального университета (УрФУ) провели эксперимент, который выявил слабости нейросетей Chat GPT и Sage, сообщает ТАСС со ссылкой на пресс-службу учебного заведения. По словам учёных, нейросети не могут сдать вузовский экзамен по истории «на отлично», поскольку не воспринимают нюансы языков разных эпох и к тому же заполняют пробелы в знаниях выдуманными фактами. 
Источник изображения: Pixabay В вузе отметили, что нейросети проявили компетентность в ответах на вопросы, связанные с использованием устойчивой общей научной терминологии. Однако они владеют только современным русским языком и не воспринимают нюансы языков разных эпох. А ведь историку помимо современного русского языка приходится иметь дело с его версиями нескольких эпох, включая терминологию XVI века в нескольких вариантах (церковнославянский язык, язык деловой письменности, разговорный), XIX века, советско-марксистский язык XX века. Принимавший «экзамен» доцент кафедры истории России УрФУ Михаил Киселев поставил нейросетям «тройку», назвав их «студентом-импровизатором». Преподаватель отметил, что «там, где материал имеет однозначные ответы, нейросеть отвечает нормально, адекватно, но в остальном она имитирует самостоятельные рассуждения, попросту выдумывая факты, несуществующие работы или авторов». Например, на просьбу назвать историков, которые писали о завещании Василия III, обе нейросети сначала заявили, что об этом «писали многие историки», после чего назвали наиболее известных дореволюционных учёных, авторов обобщающих работ по истории России, хотя правильный ответ легко найти в поисковых системах. «Примечательно, что нейросети наравне с реальными историками и их работами могут выдумывать как историков, так и книги. Sage назвала некоего Александра Васильевича Пильяра, а Chat GPT заявил, что Андрей Краевский якобы написал книгу “История Российского государства”. Если представить, что такая беседа велась на экзамене, то можно сказать, что студент “поплыл” из-за неглубокой проработки материала, хотя и старался держаться уверенно, пытаясь доказать противоположное», — рассказал Киселев. Google открыла доступ к нейросети MusicLM, которая позволяет создавать музыку по текстовому описанию
11.05.2023 [07:07],
Алексей Разин
Поскольку искусственному интеллекту уже под силу сочинение сложных текстов и написание картин, привлечение его ресурсов для сочинения музыки было лишь вопросом времени, и соответствующие эксперименты уже вовсю ведутся. Google решила не отставать от тенденции и продемонстрировала приложение MusicLM, которое позволяет создавать музыкальные композиции по текстовому описанию. 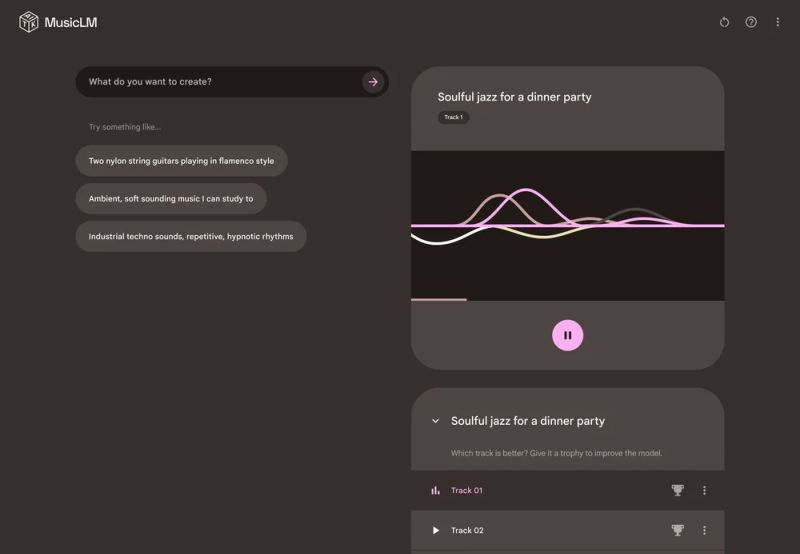
Источник изображения: Google Ещё в январе, впервые описывая данный инструмент, Google заявляла об отсутствии планов по его выпуску в открытый доступ, но за прошедшее время изменила своё отношение. MusicLM доступна в составе AI Test Kitchen для Android и iOS участникам программы тестирования, требующей отдельной регистрации. По текстовому описанию музыкальной композиции система способна создавать два варианта произведений, из которых пользователь сможет выбрать более подходящий. Текстовое описание может содержать информацию не только об инструментальном содержании трека, но и о желаемом эмоциональном эффекте, который он создаёт. Google пытается избежать упрёков со стороны правообладателей, поэтому MusicLM не будет создавать музыкальные произведения, содержащие вокал конкретных исполнителей. Юридические аспекты имитации отдельных музыкальных произведений тоже заставляют задуматься о перспективах использования результатов работы MusicLM в коммерческой сфере. Платформам, связанным с распространением музыки, уже приходилось сталкиваться с необходимостью удалить ряд произведений, созданных с помощью искусственного интеллекта. Тестировщики оценивают ответы ИИ-бота Google Bard наугад, чтобы не терять деньги
05.04.2023 [22:05],
Владимир Фетисов
Компания Google в прошлом месяце начала ограниченное бета-тестирование своего ИИ-чат-бота Bard. С тех пор сотрудники некоторых крупных подрядчиков IT-гиганта участвуют в тестировании нейросети, а также проверяют точность выдаваемых им ответов. Оказалось, что зачастую участникам тестирования не хватает времени на проверку ответов Bard, из-за чего им приходится давать оценку наугад. 
Источник изображения: Google Так, сотрудники компании Appen, которые помогают Google в тестировании алгоритма Bard, на условиях анонимности сообщили представителям СМИ, что им не хватает времени на осмысленную оценку ответов, выдаваемых ИИ-ботом. В полученных ими инструкциях сказано, что в процессе тестирования необходимо подготовить запрос для чат-бота, а после получения двух ответов выбрать наиболее связный и корректный ответ. У них также есть возможность добавить комментарий, чтобы объяснить, почему выбран тот или иной вариант. Участники тестирования отмечают, что на обработку каждого запроса даётся несколько минут, но иногда на это отводится только 60 секунд. Зачастую дать корректную оценку полученного от чат-бота ответа за такое время весьма затруднительно, особенно в случаях, когда запрос связан с малознакомой темой. Оплата за эту работу начисляется на основе времени, выделяемого для решения каждой задачи. Чтобы не терять деньги тестировщикам приходится выполнять задачи за отведённое время даже в случаях, когда они не уверены в том, какой из предложенных ИИ-алгоритмом ответов является более точным. Проще говоря, чтобы не терять деньги участники тестирования вынуждены наугад выполнять задания, поскольку им не хватает времени на качественную проверку ответов Bard. Источник отмечает, что сотрудники подрядных организаций Google всё чаще призывают к улучшению условий труда. Ещё в феврале участники бета-тестирования системы Bard передали петицию руководству Google с призывом повысить оплату труда. Согласно имеющимся данным, сотрудники Appen, участвующие в тестировании Bard, зарабатывают от $14 до $14,50 в час. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex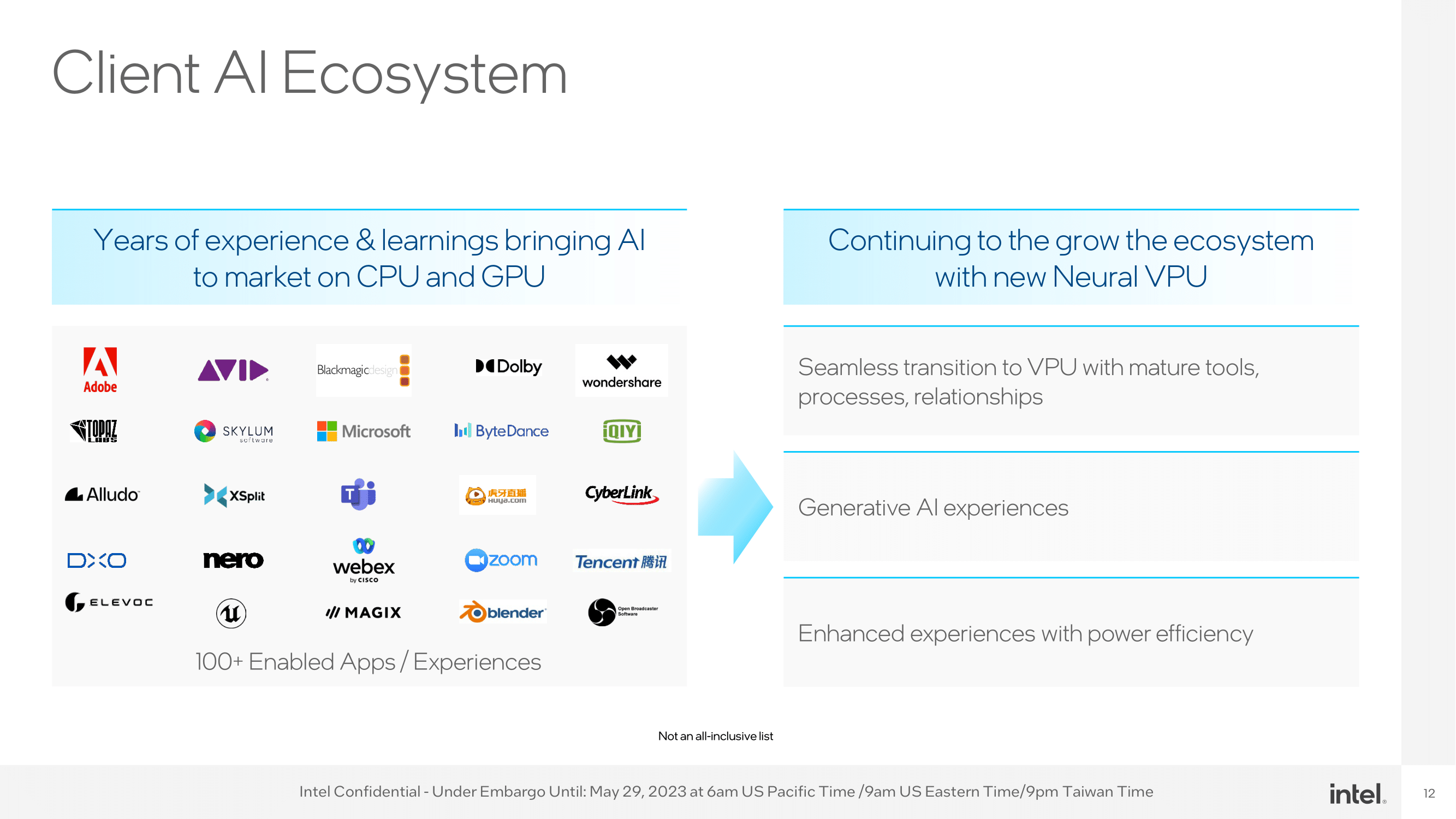

 Подписаться
Подписаться