|
Опрос
|
реклама
Быстрый переход
OpenAI открыла речевой ИИ из ChatGPT для сторонних разработчиков — ждём вала говорящих приложений
02.10.2024 [17:53],
Владимир Фетисов
Компания OpenAI представила новые возможности для упрощения процесса создания приложений на основе искусственного интеллекта. Теперь разработчики могут задействовать работающий в режиме онлайн инструмент для создания голосовых программных решений на базе ИИ, используя единый набор инструкций. 
Источник изображения: OpenAI Большую часть дохода OpenAI получает от предприятий, которые используют нейросети компании для создания собственных ИИ-приложений. Поэтому расширение возможностей по созданию таких продуктов является вполне оправданным шагом на фоне обостряющейся борьбы в сфере ИИ с такими компаниями, как Google, которая внедряет в свои продукты алгоритмы, способные обрабатывать разные типы информации, включая текст, изображения и видео. Процесс создания голосовых помощников требует от разработчиков прохождения как минимум трёх этапов: преобразование аудио в текст, обработка запроса и генерация текстового ответа на него, а также преобразование полученного ответа в аудио. В рамках внедрения новых возможностей по созданию голосовых ИИ-приложений OpenAI представила инструмент тонкой настройки больших языковых моделей после завершения этапа обучения. Такой подход позволит повысить качество ответов, которые генерируют создаваемые разработчиками алгоритмы в ответы на запросы в текстовом формате и с использованием изображений. Этап точной настройки может сопровождаться обратной связью от людей, которые проводят оценку того, насколько качественные ответы даёт алгоритм. В OpenAI считают, что использование изображений для точной настройки моделей даст разработчикам более широкие возможности для повышения качества понимания ИИ-алгоритмами того, что демонстрируется на изображениях. Созданные таким образом приложения могут выступать, например, в качестве расширенного поиска по визуальным элементам. В дополнение к этому OpenAI представила инструмент, который позволит меньшим ИИ-моделям учиться на более крупных моделях, а также «Быстрое кэширование», которое существенно сократит затраты на разработку благодаря повторному использованию фрагментов текста, ранее уже обработанных алгоритмом. Все представленные нововведения уже тестируются с привлечением ограниченного числа клиентов OpenAI. Google потратила $2,7 млрд, чтобы вернуть бывшего сотрудника
26.09.2024 [16:23],
Владимир Фетисов
Google заплатила $2,7 млрд за лицензии на технологии ИИ-стартапа Character AI, который в 2021 году создал бывший сотрудник IT-гиганта Ноам Шазир (Noam Shazeer). По данным источника, главной целью Google было возвращение в компанию IT-гения, прославившегося исследованиями в сфере искусственного интеллекта. В настоящее время Шазир является вице-президентом Google и работает над развитием ИИ-алгоритмов компании, таких как Gemini. 
Источник изображения: Alex Dudar / unsplash.com В сообщении сказано, что именно ради возвращения Шазира Google дала согласие на выплату огромного лицензионного сбора. По данным осведомлённого источника, Шазир заработал сотни миллионов долларов на своей доле в стартапе Character AI. Отмечается, что выплаченная Google сумма является необычно большой для основателя, который не продал свою компанию и не вывел её на биржу. Ноам Шазир работал в Google с 2000 года. В 2017 году он вместе с группой других авторов опубликовал статью под названием «Внимание — это всё, что вам нужно», которая стала основой для технологии генеративных нейросетей. Позднее он вместе с коллегами создал чат-бота Meena и предсказал, что в скором будущем чат-ботом сможет заменить поисковую систему Google и принесёт триллионы долларов дохода. Google отказалась от публичного запуска чат-бота, и в 2021 году Шазир покинул компанию, обвинив её в бюрократической волоките при интеграции технологий в пользовательские продукты. Позднее он создал стартап Character AI, который через два года привлёк $150 млн инвестиций и был оценён в 1 млрд. На фоне конкуренции с OpenAI и Microsoft Шазир пытался привлечь для своего стартапа больше средств и в конечном счёте сумел договориться с Alphabet, материнской компанией Google. В результате сделки Шазир и ещё несколько десятков сотрудников Character AI перешли в Google. В «Яндекс Браузере» появился ИИ-редактор текста и другие функции на базе YandexGPT
20.09.2024 [15:08],
Владимир Фетисов
Разработчики из «Яндекса» продолжают улучшать свой фирменный браузер. На этот раз они добавили в «Яндекс Браузер» несколько инструментов на базе YandexGPT, которые предназначены для повышения продуктивности. Они помогут быстрее справляться с повседневными задачами, связанными с контентом, без необходимости использования сторонних сервисов и приложений. 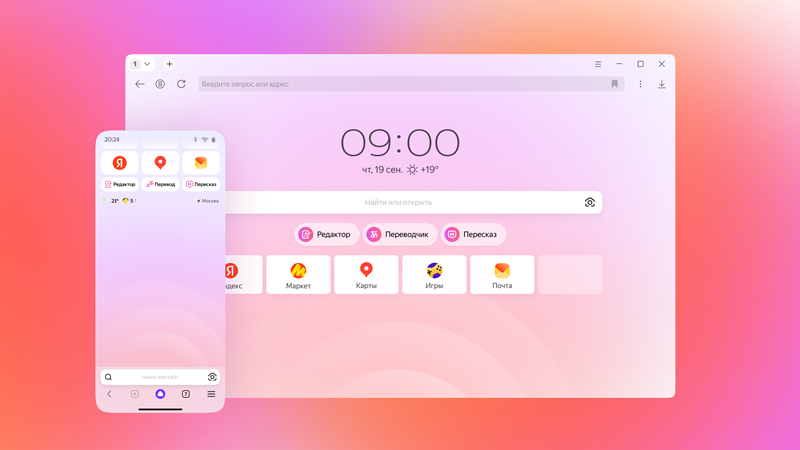
Источник изображений: «Яндекс» Алгоритмы в текстовом редакторе помогут генерировать тексты с нуля и улучшать уже готовые, например, исправляя ошибки, переписывая в определённом стиле или формате. В дополнение к этому в «Яндекс Браузере» появился переводчик с YandexGPT, использующий лексику в зависимости от предметной области текста. Ещё одним нововведением стала функция краткого пересказа текстов, которая поддерживает работу с файлами в форматах PDF, DOCX и TXT. Все новые функции доступны в одном интерфейсе, перейти к которому можно нажатием соответствующей кнопки под поисковой строкой на главной странице браузера.  Редактор с YandexGPT делает возможным не только генерацию текстов, но также позволяет редактировать и менять стиль готовых текстов. Для его запуска предусмотрена кнопка «Редактировать», которая располагается рядом с любым сайтом в «Яндекс Браузере». Для изменения текста можно задействовать встроенные команды, такие как «Более формально» или «Простыми словами», или делать это посредством команд в окне чата. Реализована поддержка русского и английского языков, а также возможность переключаться при работе с текстом со смартфона на ПК.  Вместе с этим в браузере появилась бета-версия обновлённого переводчика на базе YandexGPT. Этот инструмент теперь может различать предметную область текста и использовать соответствующую лексику. К примеру, для научной статьи переводчик подберёт специальные термины, а для кулинарного блога — общеупотребительные. Переводчик понимает более 100 языков, а также может работать с произвольными текстами, изображениями и ссылками на сайты. Начать взаимодействие с переводчиком можно, нажав соответствующую кнопку под поисковой строкой на главной странице браузера. 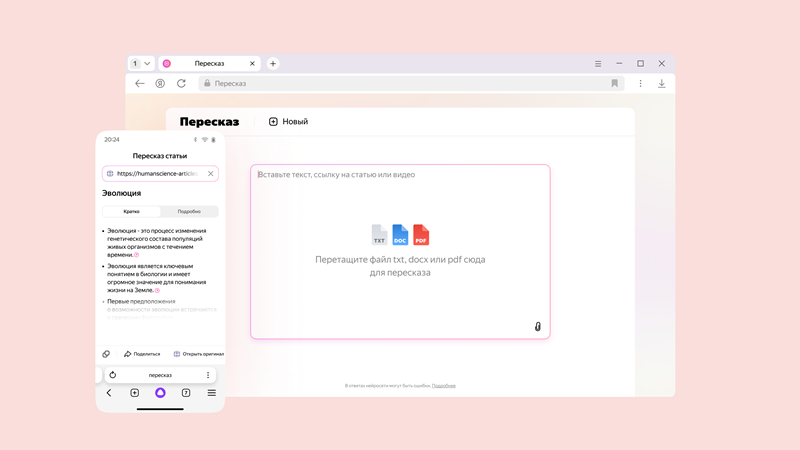 В дополнение к этому разработчики добавили функцию пересказа загруженных текстов любой длины. Этот инструмент может обрабатывать научные трактаты, объёмные художественные романы и др. В десктопной версии браузера функция доступна не только для текстов и видео, но и для документов в разных форматах. Поддерживается два режима пересказа: краткий и подробный. Во втором случае будут сохранены все ключевые детали из оригинала. При необходимости получившийся пересказ можно разбить на смысловые главы с подзаголовками для более удобного ориентирования в тексте. Разработчики из «Яндекса» интегрировали нейросети нового поколения в свой браузер в феврале этого года. Благодаря этому пользователям стали доступны полезные функции для взаимодействия с текстами, генерации изображений, перевода на русский видео с восьми языков и др. «Яндекс» создал ИИ-помощника для генерации программного кода
12.09.2024 [14:03],
Владимир Фетисов
Компания «Яндекс» подала в Роспатент заявку на регистрацию товарного знака Yandex Code Assistant, в числе регистрируемых классов и услуг — программное обеспечение и средства совместной работы над программным кодом. В «Яндексе» подтвердили разработку сервиса для генерации кода на базе искусственного интеллекта, добавив, что он будет доступен «бесплатно в режиме тестирования» на облачной платформе Yandex Cloud. 
Источник изображения: geralt/Pixabay «Яндекс» и «Сбер», у которых есть собственные большие языковые модели (LLM), больше года работают над созданием инструментов автоматического дополнения программного кода. Разработка таких продуктов началась вскоре после появления сервиса GitHub Copilot, который в 2021 году создала Microsoft на основе технологий компании OpenAI. Этот сервис недоступен в России, а взаимодействие с ним осуществляется в рамках платной подписки. Осенью прошлого года «Сбер» запустил сервис GigaCode, а летом этого года собственную интегрированную среду разработки GigaIDE. По данным источника, за несколько месяцев с момента запуска ИИ-помощника GigaCode его установили более 20 тыс. пользователей. Что касается Yandex Code Assistant, то он будет совместим с популярными редакторами программного кода, сообщил директор по продукту Yandex Cloud Григорий Атрепьев. Он также добавил, что этот и другие инструменты станут частью «платформы для создания, развёртывания и сопровождения цифровых продуктов». В компании не уточнили, планируется ли создание собственной интегрированной среды разработки, а также, какие именно сервисы станут частью платформы. По данным источника, «Яндекс», помимо Code Assistant, работает над созданием инструментов Code Review для проверки и анализа кода, а также Auto Documentation для автоматической аннотации кода. Музыкант с помощью ИИ обманом заработал $10 млн на стриминговых сервисах
06.09.2024 [09:02],
Анжелла Марина
По словам прокуроров, житель Северной Каролины (США) использовал искусственный интеллект для создания сотен тысяч поддельных песен поддельных групп, а затем выкладывал их на стриминговые сервисы, где ими наслаждалась аудитория поддельных слушателей. Теперь музыканту грозит по меньшей мере 20 лет тюрьмы. 
Источник изображения: Alexander Sinn/Unsplash По сообщению The New York Times, 52-летний музыкант Майкл Смит (Michael Smith) был обвинён в мошенничестве, связанном с манипуляцией стриминговыми сервисами. Как утверждают прокуроры, он использовал нейросети для создания сотен тысяч фальшивых песен, которые затем размещал на популярных платформах, таких как Spotify, Apple Music и Amazon Music. В результате своего мошеннического плана Смит заработал по меньшей мере 10 миллионов долларов, подделывая роялти и обманывая слушателей, которых на самом деле не существовало. Афера с фальшивыми исполнителями привела к серьёезным обвинениям, включая мошенничество с использованием электронной почты и заговор с отмыванием денег. Прокуроры заявили, что Смит использовал программное обеспечение для автоматического стриминга своих сгенерированных композиций, что создавало иллюзию, будто за ними стоят реальные исполнители. Утверждается, что у него были такие вымышленные группы, как «Callous Post», «Calorie Screams» и «Calvinistic Dust», которые выпускали треки с необычными названиями, подобными «Zygotic Washstands» и «Zymotechnical». Прокуроры подчеркнули, что «Смит украл миллионы в виде роялти, которые должны были быть выплачены музыкантам, композиторам и другим правопреемникам, чьи песни транслировались легитимно». В итоге это дело стало первым уголовным делом, связанным с манипуляциями в области музыкальных стримингов, возбуждённым прокурором Южного округа Нью-Йорка. Если Смит будет признан виновным, он может получить до 20 лет тюремного заключения, причём по каждому из предъявленных обвинений. Схема Смита была тщательно продумана. Он создал тысячи фальшивых аккаунтов для стриминга, купив электронные адреса на онлайн-площадках. Имея до 10 000 таких аккаунтов он, в виду трудоёмкости процесса, привлёк других пользователей (соучастников) для оплачиваемой помощи в их создании. Смит также разработал программное обеспечение для многократного воспроизведения своих песен с разных компьютеров, создавая видимость, что за музыкой следят реальные слушатели. В 2017 году, по данным прокуроров, он рассчитал, что сможет стримить свои треки 661 440 раз в день, что обеспечивало ему доход более $3000 в день. Смит начинал с размещения своей собственной оригинальной музыки на стриминговых платформах, но вскоре осознал, что количество его треков недостаточно для получения значительных роялти. Попытки использовать музыку, принадлежащую другим, и предложение услуг по продвижению таких композиций не увенчались успехом. В 2018 году он объединился с главой компании, занимающейся ИИ-музыкой, и музыкальным промоутером для создания огромного каталога поддельных песен, которые загружал на стриминговые платформы. По состоянию на июнь 2019 года Смит зарабатывал около 110 000 долларов в месяц, часть из которых уходила его соучастникам. В одном из своих писем в феврале этого года он похвалился, что достиг 4 миллиардов стримов и 12 миллионов долларов в виде роялти с 2019 года. Однако, когда стриминговые компании начали подозревать его в мошенничестве и уведомили его о получении «нескольких сообщений о злоупотреблениях», Смит в ответ на это заявил: «Это абсолютная неправда, это безумие! Никакого мошенничества здесь не происходит! Как я могу это обжаловать?» MiniMax представила бесплатный ИИ-генератор video-1, который превращает текст в видео за 2 минуты
02.09.2024 [19:03],
Владимир Фетисов
Китайский стартап MiniMax, работающий в сфере искусственного интеллекта, представил алгоритм video-1, который генерирует небольшие видеоклипы на основе текстовых подсказок. Генератор video-1 был представлен широкой публике на прошедшей несколько дней назад в Шанхае первой конференции разработчиков компании, а позднее стал доступен всем желающим на веб-сайте MiniMax. 
Источник изображения: scmp.com С помощью video-1 пользователь может на основе текстового описания создавать видеоролики продолжительностью до 6 секунд. Процесс создания такого ролика занимает около 2 минут. Основатель MiniMax Ян Цзюньцзе (Yan Junjie) рассказал на презентации, что video-1 является первой версией алгоритма генерации видео по текстовым подсказкам, отметив, что в будущем нейросеть сможет создавать ролики на основе статических изображений, а также позволит редактировать уже созданные клипы. Появление video-1 отражает стремление китайских технологических компаний продвинуться в зарождающемся сегменте рынка ИИ. Генератор видео был представлен всего через несколько месяцев после анонса нейросети Sora компании OpenAI, которая также позволяет создавать видео по текстовым подсказкам. Что касается MiniMax, то компания была основана в декабре 2021 года и с тех пор она проделала немалую работу. Новый инструмент video-1 предлагается в рамках платформы MiniMax под названием Hailuo AI, которая ориентирована на потребительский рынок и уже предоставляет доступ к функциям генерации текстов и музыки с помощью нейросетей. Помимо MiniMax, разработкой ИИ-алгоритмов для генерации видео из текста занимаются и другие китайские компании. Пекинский стартап Shengshu AI в июле запустил собственный генератор видео из текста на китайском или английском языках под названием Vidu. Стартап Zhipu AI стоимостью более $1 млрд в том же месяце представил свой аналог Sora, который может создавать небольшие видео на основе текстовых подсказок или статических изображений. Владелец TikTok и Douyin, компания ByteDance, в прошлом месяце опубликовала в китайском App Store приложение Jimeng text-to-video для генерации видео из текста, а ещё ранее оно появилось в местных магазинах Android-приложений. Jimeng позволяет создать бесплатно 80 изображений или 26 видео, а для более активного взаимодействия с нейросетью предлагается оформить подписку за 69 юаней (около $10). В прошлом месяце компания Alibaba Group Holding объявила о разработке алгоритма для генерации видео под названием Tora, основанного на модели OpenSora. Отметим, что среди инвесторов MiniMax есть крупные IT-компании, такие как Alibaba, Tencent Holdings и miHoYo (создатель Genshin Impact). Очередной раунд финансирования прошёл весной и после его завершения рыночная стоимость MiniMax оценивалась более чем в $2 млрд. ИИ-функции в приложениях Meta✴ ежемесячно используют 400 млн человек
01.09.2024 [17:32],
Владимир Фетисов
Инструменты на основе искусственного интеллекта компании Meta✴ Platforms, доступные в Facebook✴, Instagram✴, WhatsApp и Threads, используют не менее 400 млн человек в месяц и 40 млн человек ежедневно. Об этом пишет издание The Information со ссылкой на данные, полученные от двух осведомлённых сотрудников Meta✴. 
Источник изображения: Growtika/unsplash.com Информация о количестве пользователей ИИ-функций Meta✴ появилась вскоре после того, как стало известно, что с ИИ-ботом ChatGPT компании OpenAI еженедельно взаимодействуют более 200 млн человек. В OpenAI позднее подтвердили эту информацию. Это означает, что поддерживаемая Microsoft компания нарастила пользовательскую базу на 100 млн человек менее чем за год. Несмотря на это, данные по количеству пользователей указывают, что Meta✴ остаётся полноценным конкурентом OpenAI в сфере предоставления услуг на основе генеративных нейросетей. Что касается Meta✴, то компания Марка Цукерберга (Mark Zuckerberg) выбрала подход, отличный от того, как работает OpenAI. Разработчики из Meta✴ выпустили на рынок несколько больших языковых моделей Llama с открытым исходным кодом, которые разработчики могут настраивать в соответствии с собственными потребностями. Напомним, ИИ-алгоритмы Meta✴ можно задействовать для помощи в написании и редактировании текстов, а также генерации изображений по текстовому описанию. Они доступны во многих пользовательских приложениях Meta✴, включая Facebook✴ и Instagram✴. Биокомпьютер на живых клетках человеческого мозга теперь можно арендовать за $500 в месяц
28.08.2024 [00:07],
Анжелла Марина
Компания FinalSpark открыла удалённый доступ к своей революционной платформе Neuroplatform, предоставляющей учёным возможность проводить исследования на биокомпьютерах на основе органоидов человеческого мозга. Фактически, теперь по сходной цене можно взять в аренду биологический процессор на базе живых клеток. 
Источник изображения: Copilot Neuroplatform — это первая в мире онлайн-платформа, позволяющая арендовать доступ к биопроцессорам, использующим живые нейроны для вычислений. Как пишет Tom's Hardware, эти процессоры обладают эффективностью в миллион раз выше по сравнению с традиционными цифровыми процессорами. В основе инновационной разработки лежат органоиды, представляющие из себя трёхмерные тканевые структуры, искусственно выращенные из клеток человеческого мозга и содержащие функциональные нейроны. 
Источник изображения: FinalSpark Органоиды, наполненные нейронами, обладают исключительной способностью к обучению и обработке информации. Один такой органоид, по оценкам, содержит 10 000 живых человеческих нейронов. По мнению компании, использование биопроцессоров, основанных на биологических нейронах, вместо транзисторов, может значительно сократить потребление энергии в технологическом мире. «Экономия миллиардов ватт при обучении больших языковых моделей или других ресурсоёмких задач станет в том числе позитивным фактором и для окружающей среды», — подчёркивают в FinalSpark. 
Источник изображения: FinalSpark Архитектура платформы сочетает в себе аппаратное обеспечение, программное обеспечение и биологию. Она основана на использовании многоэлектродных массивов (MEA), в которых размещаются органоиды человеческого мозга в микрофлюидной системе жизнеобеспечения. 3D-тканевые массы связаны и стимулируются восемью электродами, с камерами наблюдения и настроенным программным стеком для того, чтобы исследователи могли вводить переменные данных, а также считывать и интерпретировать выходные данные процессора. 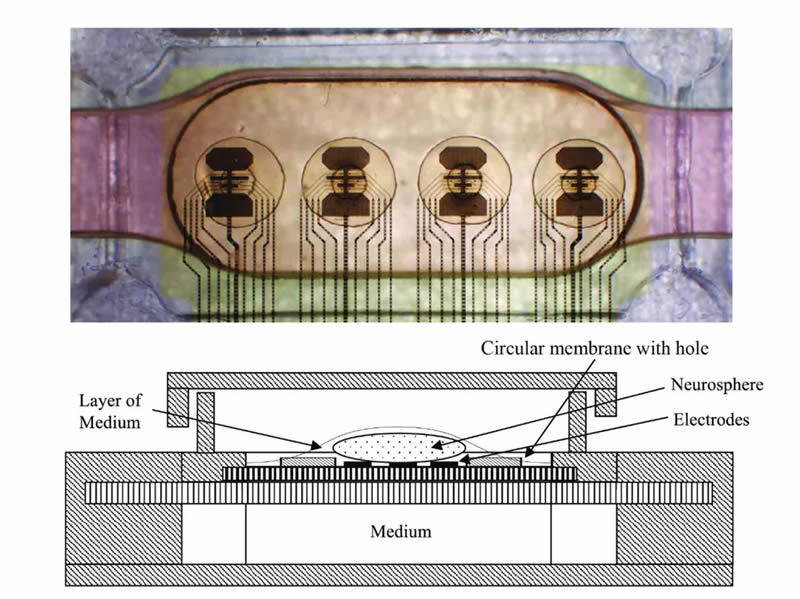
Источник изображения: FinalSpark В разработке Neuroplatform участвуют пять крупных исследовательских институтов, и уже девять пользователей зарегистрированы на платформе. Открытие доступа к Neuroplatform для более широкого круга академических исследователей является важным шагом, который позволит ускорить исследования в области биокомпьютинга и раскрыть потенциал технологии. Платформа предлагает четыре общих органоида, которые могут быть арендованы за $500 в месяц на пользователя. Для некоторых проектов доступ предоставляется бесплатно. FinalSpark утверждает, что эта цена включает в себя доступ к полностью управляемой удалённой нейроплатформе, позволяющей проводить исследования в области биовычислений. Ажиотаж вокруг ИИ идёт на спад — аналитики видят аналогию с железными дорогами начала века
20.08.2024 [17:05],
Владимир Фетисов
Похоже, что для технологических компаний из Кремниевой долины, работающих в сфере искусственного интеллекта, настают не лучшие времена. Это связано с тем, что всё больше отраслевых инвесторов сомневаются в способности ИИ принести огромные прибыли, к которым они стремятся. С момента достижения пиковых значений в прошлом месяце стоимость акций западных компаний в сфере ИИ упала на 15 %. 
Источник изображения: Copilot На этом фоне всё больше экспертов задаются вопросом об ограниченности больших языковых моделей (LLM), которые являются основой генеративных алгоритмов, таких как ChatGPT. Крупные технологические компании потратили десятки миллиардов долларов на создание LLM и разных ИИ-инструментов на их основе, а прогнозы о будущих расходах выглядят ещё более впечатляющими. Несмотря на это, наиболее актуальные статистические данные указывают на то, что только 4,8 % компаний в США используют ИИ для создания товаров и услуг, тогда как в начале года этот показатель был равен 5,4 %. Ожидается, что в течение следующего года количество использующих ИИ компаний удвоится, но этого недостаточно. Происходящее с ИИ-технологиями можно описать термином «цикл хайпа», который был популяризирован компанией Gartner и хорошо известен в Кремниевой долине. После запуска какой-либо перспективной технологии начинается период иррациональной эйфории и чрезмерных инвестиций, после чего происходит серьёзный спад. Это приводит к волнениям среди участников рынка и инвесторов, которые обусловлены слишком медленным внедрением технологии и сложностями при извлечении прибыли. Однако в конечном счёте технология начинает использоваться массово, чему способствуют огромные инвестиции начального этапа и созданная за счёт вложений инфраструктура. Начальный этап развития технологий, сопровождающийся огромными инвестициями, безусловно полезен, что доказывают примеры прошлого. В XIX веке Великобританию охватила железнодорожная лихорадка, и в погоне за высокой прибылью инвесторы вкладывали огромные деньги в отрасль, создав тем самым фондовый пузырь. Затем последовал крах, после чего железнодорожные компании на собранные на первом этапе средства всё же построили железную дорогу, соединив ею многочисленные населённые пункты. Это помогло преобразовать экономику и способствовало развитию железнодорожного транспорта. По похожему сценарию шла история интернета. В 90-е годы новая технология вызвала эйфорию, а футурологи предсказывали, что всего через пару лет люди будут делать покупки онлайн. В 2000 году рынок рухнул, что привело к разорению множества интернет-компаний по всему миру. Однако к тому времени телекоммуникационные компании уже вложили миллиарды долларов в прокладку оптоволоконных кабелей, которые впоследствии стали основой инфраструктуры для современного интернета. Несмотря на то, что сфера ИИ ещё не пережила подобного краха, некоторые эксперты уверены в будущем глобальном господстве искусственного интеллекта. «Будущее ИИ будет таким же, как и у любой другой технологии. Будет дорогостоящее строительство гигантской инфраструктуры, затем огромный спад, когда люди поймут, что не знают, как использовать ИИ продуктивно, а затем медленное возрождение, когда они разберутся в этом», — считает экономический обозреватель Ноа Смит (Noah Smith). Не исключено, что сфера ИИ будет развиваться иначе. Уже несколько десятилетий искусственный интеллект переживает периоды ажиотажа и спада, сопровождаемые ростом и снижением активности исследователей и инвесторов. В 60-е годы было много ажиотажа вокруг ИИ, в том числе обусловленного появлением Элизы — первой версии чат-бота. Затем несколько десятилетий длилось затишье вплоть до появления генеративных нейросетей в 2020 году. Существует множество других технологий, которым удалось избежать цикла ажиотажа. К примеру, облачные технологии от появления до массового распространения прошли путь по довольно прямой линии без существенных взлётов и падений. Солнечная энергетика и социальные сети развивались похожим образом. При этом есть немало технологий, которые, преодолев первый этап ажиотажа, достигли точки спада, но так и не вошли в жизнь людей по всему миру, по крайней мере пока. Ярким примером таких технологий можно считать web3 или углеродные нанотрубки. В прошлом также предсказывалось, что у каждого человека дома будет 3D-принтер, и технология трёхмерной печати станет частью повседневной жизни, но этого также не произошло. Исследование показало, что лишь малая часть инновационных технологий проходит развитие по «циклу хайпа». Примерно лишь пятая часть переходит от инноваций к стремительному росту, падению и дальнейшему широкому распространению. Многие технологии начинают использоваться повсеместно без подобных скачков. В других случаях технологии переходят от резкого роста к краху и уже не возвращаются. Что касается искусственного интеллекта, то он всё ещё может совершить революцию, если кто-то из технологических гигантов добьётся прорыва в этой сфере, а предприятия и компании смогут осознать преимущества, предлагаемые технологиями на базе ИИ. Одна из важнейших задач на данный момент для разработчиков заключается в том, чтобы показать, что ИИ действительно может что-то предложить реальной экономике. TikTok является одним из крупнейших клиентов Microsoft в сфере облачных ИИ-вычислений
01.08.2024 [17:42],
Владимир Фетисов
По сообщениям сетевых источников, сервис коротких видео TikTok, принадлежащий китайской компании ByteDance, является одним из крупнейших клиентов Microsoft в сфере облачных вычислений искусственного интеллекта. По состоянию на март TikTok платил Microsoft почти $20 млн в месяц за доступ к ИИ-алгоритмам OpenAI. Однако в скором времени это может измениться, если ByteDance создаст собственные нейросети. 
Источник изображения: antonbe/Pixabay В прошлом году СМИ писали, что ByteDance «тайно использует» алгоритмы OpenAI для разработки своей большой языковой модели (LLM). В сфере разработки ИИ-технологий такой подход осуждается многими компаниями. Кроме того, это прямое нарушение пользовательского соглашения OpenAI, в котором сказано, что генерируемый нейросетями контент не может использоваться «для создания языковых моделей, конкурирующих с продуктами и услугами разработчика». Microsoft, через которую ByteDance получает доступ к алгоритмам OpenAI, придерживается аналогичной политики. После появления сообщений о том, что ByteDance использует ИИ-алгоритмы OpenAI для создания своей языковой модели, действие аккаунта китайской компании было приостановлено. OpenAI объяснила это необходимостью провести расследование, чтобы установить факт нарушения лицензионного соглашения. Тогда же представитель ByteDance в беседе с журналистами CNN сообщил, что компания использует технологии «в очень ограниченном объёме» для разработки собственных языковых моделей. Microsoft заключила с OpenAI многомиллиардное инвестиционное соглашение, делающее софтверного гиганта эксклюзивным поставщиком облачных ИИ-вычислений. Кроме того, Microsoft пришлось потратить «несколько сотен миллионов долларов» на создание суперкомпьютера для обеспечения работы алгоритма ChatGPT. В опубликованном на этой неделе финансовом отчёте Microsoft за четвёртый квартал 2024 финансового года сказано, что доходы облачного подразделения Azure выросли на 29 %, что лишь немногим меньше прогнозируемых ранее 30-31 %. В США создали систему оценки рисков для ИИ-алгоритмов
29.07.2024 [08:37],
Владимир Фетисов
Национальный институт стандартов и технологий (NIST), входящий в состав Министерства торговли США и занимающийся разработкой и тестированием технологий для американского правительства, компаний и общественности, представил обновлённый тестовый стенд Dioptra. Он предназначен для оценки того, как вредоносные атаки, включая те, что направлены на «отравление» используемых для обучения больших языковых моделей данных влияют на снижение производительности ИИ-систем. 
Источник изображения: Copilot Первая версия модульного веб-инструмента с открытым исходным кодом Dioptra была представлена в 2022 году. Обновлённое ПО должно помочь разработчикам ИИ-моделей и людям, которые используют эти алгоритмы, оценивать, анализировать и отслеживать риски, связанные с ИИ. В NIST заявили, что Dioptra можно использовать для бенчмаркинга и исследования ИИ-моделей, а также в качестве общей платформы для симуляции воздействия на модели разного рода угроз. «Тестирование влияния атак противника на модели машинного обучения — одна из целей Dioptra. Программное обеспечение с открытым исходным кодом доступно для бесплатной загрузки и может помочь сообществу, включая правительственные агентства, малые и средние компании, в проведении оценки, чтобы проверить заявления разработчиков ИИ о производительности их систем», — говорится в пресс-релизе NIST. Вместе с Dioptra разработчики опубликовали ряд документов, в которых излагаются способы уменьшения рисков, связанных с ИИ-моделями. Это программное обеспечение было создано в рамках инициативы, которую поддержал президент США Джо Байден и которая предписывает NIST, помимо прочего, оказывать поддержку в тестировании ИИ-систем. Инициатива также устанавливает ряд стандартов безопасности в сфере ИИ, включая требования к компаниям, разрабатывающим ИИ-алгоритмы, об уведомлении федерального правительства и передачи данных по итогам оценки рисков безопасности до того, как ИИ станет доступен широкому кругу пользователей. Проведение эталонной оценки ИИ является сложной задачей, в том числе потому, что сложные алгоритмы в настоящее время представляют собой «чёрные ящики», инфраструктура которых, данные для обучения и другие ключевые детали держатся разработчиками в секрете. Некоторые эксперты склоняются к мнению, что одних только оценок недостаточно для определения степени безопасности ИИ в реальном мире, в том числе потому, что разработчики имеют возможность выбирать, какие тесты будут проводиться для оценки их ИИ-моделей. NIST не говорит, что Dioptra сможет исключить любые риски для ИИ-систем. Однако разработчики этого инструмента уверены, что он может пролить свет на то, какие виды атак могут сделать работу той или иной ИИ-системы менее эффективной, а также оценить негативное воздействие на производительность алгоритма. Отметим, что Dioptra способен работать только с моделями, которые можно загрузить на устройство и использовать локально. Reddit закрылся от поисковиков и ИИ-ботов, которые не платят за использование контента платформы
25.07.2024 [04:30],
Владимир Фетисов
Социальная сеть Reddit продолжает бороться с веб-ботами, которые бесплатно используют контент платформы для обучения нейросетей. По данным источника, за последние несколько недель администрация Reddit скорректировала файл robot.txt, который сообщает ботам о разрешении или запрете на сканирование разделов сайта, таким образом, что контент сообщества и комментарии пользователей перестали корректно отображаться во многих поисковиках. 
Источник изображения: redditinc.com В сообщении сказано, что в настоящее время только система Google корректно отображает результаты поиска последних постов на Reddit. При этом в других поисковиках, таких как Bing или DuckDuckGo, аналогичные запросы обрабатываются некорректно, т.е. либо не находят интересующие пользователей страницы, либо отображают лишь их часть. Вероятно, в случае с Google проблем не наблюдается из-за достигнутых ранее договорённостей, в рамках которых поисковый гигант будет платить Reddit $60 млн в год за использование контента площадки для обучения собственных ИИ-алгоритмов. При этом в Reddit опровергли информацию о том, что сделка с Google каким-то образом повлияла на разрешение разработчиков на использование контента платформы для обучения нейросетей. «Это совершенно не связано с нашим недавним партнёрством с Google. Мы вели переговоры с несколькими поисковыми системами. Мы не смогли договориться со всеми, поскольку некоторые не могут или не хотят давать каких-либо обещаний касательно использования ими контента Reddit, в том числе для обучения искусственного интеллекта», — прокомментировал данный вопрос представитель Reddit. Для такого крупного сайта, как Reddit, блокировка веб-ботов крупных поисковых систем является смелым шагом, но вполне ожидаемым. За последний год администрация сайта стала значительно активнее защищать публикуемый пользователями контент, стремясь открыть новый источник дохода и привлечь инвесторов. Разработчики повысили стоимость использования API Reddit сторонними разработчиками, а также пригрозили Google блокировкой поисковика, если компания не перестанет бесплатно использовать контент платформы для обучения своих нейросетей. Илон Маск собрался обучить мощнейший ИИ в истории к декабрю, для чего запустил самый мощный в мире ИИ-кластер со 100 тыс. Nvidia H100
22.07.2024 [22:47],
Владимир Фетисов
Американский бизнесмен Илон Маск (Elon Musk) в своём аккаунте в социальной сети X заявил о запуске его ИИ-стартапом xAI «самого мощного в мире кластера для обучения ИИ». Данная система, по словам Маска, обеспечит «значительное преимущество в обучении самого мощного в мире ИИ по всем показателям к декабрю этого года». 
Источник изображения: xAI / X «Система со 100 тыс. H100 с жидкостным охлаждением на единой RDMA-шине стала самым мощным кластером для обучения ИИ в мире», — отметил Маск в своём сообщении. Участвовал ли бизнесмен лично в запуске ИИ-суперкомпьютера, неизвестно, но на опубликованном снимке видно, что как минимум он общался с инженерами xAI во время подключения оборудования. Ранее в этом году СМИ писали о стремлении Маска запустить так называемую «гигафабрику для вычислений», которая представляет собой гигантский дата-центр с самым производительным в мире ИИ-суперкомпьютером, к осени 2025 года. Начало формирования кластера для обучения ИИ потребовало закупки огромного количества ускорителей Nvidia H100. Похоже, что у бизнесмена не хватило терпения, чтобы дождаться выхода ускорителей H200, не говоря уже о будущих моделях B100 и B200 поколения Blackwell, которые, как ожидается, будут выпущены до конца этого года. Позднее Маск написал, что ИИ-суперкомпьютер будет задействован для обучения самого мощного по всем показателям ИИ. Вероятно, речь идёт об алгоритме Grok 3, этап обучения которого должен закончиться к концу этого года. Любопытно, что расположенный в дата-центре в Мемфисе ИИ-суперкомпьютер, по всей видимости, значительно превосходит аналоги. К примеру, суперкомпьютер Frontier построен на базе 27 888 ускорителей AMD, в Aurora используется 60 тыс. ускорителей Intel, а в Microsoft Eagle — 14 400 ускорителей H100 от Nvidia. Китайская Moore Threads нашла способ создавать вычислительные кластеры на 10 тыс. ускорителей — это пригодится в условиях санкций
04.07.2024 [14:55],
Алексей Разин
Совокупная вычислительная мощь кластера определяется не только удельной производительностью каждого ускорителя, но и способностью создателей объединять их максимальное количество в одной системе. Китайская компания Moore Threads предложила своим клиентам решение, позволяющее создать кластер из 10 000 ускорителей, во многом нивелируя ограничения США на масштабирование таких систем. 
Источник изображения: Moore Threads Напомним, что Moore Threads была основана в 2020 году опытным специалистом Nvidia, который задался целью выпускать подобные ускорители вычислений и игровые видеокарты для китайского рынка, но к октябрю 2023 года компания закономерно попала под экспортные ограничения США. Компенсировать более низкую производительность своих ускорителей вычислений по сравнению с решениями Nvidia компания пытается созданием более выгодных условий для масштабирования кластеров. В частности, как отмечает South China Morning Post, модернизированное решение KUAE позволяет увеличить количество работающих в одном кластере ускорителей Moore Threads до 10 000 штук. Ускорители MTT S4000 оснащаются чипами с 128 тензорными ядрами и 48 Гбайт памяти, а соединяться друг с другом им позволяет интерфейс MTLink. Теперь в одном кластере можно объединить до 10 000 ускорителей, обеспечив более высокую совокупную производительность вычислений. Решение Nvidia A100, поставки которого в Китай запрещены, в три раза превосходит MTT S4000 по быстродействию, хотя и не является новейшим в ассортименте продукции американской компании. В условиях санкций китайские разработчики систем искусственного интеллекта всё равно вынуждены полагаться на местных поставщиков ускорителей, Moore Threads является одним из них. «Яндекс Переводчик» получит поддержку более 20 языков народов России
02.07.2024 [13:22],
Владимир Фетисов
Разработчики из «Яндекса» добавят в «Переводчик» поддержку более 20 языков народов России, которые ранее не были представлены в сервисе. Реализация проекта займёт три года, а первый из новых языков — осетинский — уже доступен в «Переводчике». 
Источник изображения: «Яндекс» В дополнение к этому для некоторых новых языков будут доступны функции распознавания и синтеза речи, построенные на основе нейросетей. За счёт этого пользователи смогут узнать, как звучат те или иные слова на разных языках, а также получат возможность вести диалог с носителями языков. В мобильной версии сервиса доступен мгновенный перевод реплик, их отображение на экране устройства, а также озвучивание на выбранном языке. Первым языком, для которого будут реализованы эти возможности, станет татарский. Позднее распознавание и синтез речи станут доступны для более чем 10 популярных языков, на каждом из которых в России говорят свыше 300 тыс. человек. «Яндекс» также сделает возможным перевод сайтов в «Браузере», добавит поддержку голосового ввода в «Поиске», «Картах» и мессенджерах посредством «Яндекс Клавиатуры». За счёт этого пользователи будут иметь возможность ознакомления с культурными особенностями народов страны через перевод их легенд, преданий и др. Вместе с этим виртуальный помощник «Алиса» сможет читать народные сказки на этих языках. Данные поисковика «Яндекса» указывают на то, что россияне чаще всего ищут перевод фраз на татарском языке. Также популярностью пользуются башкирский и чувашский языки. В переводчике уже доступны эти и другие языки, такие как удмуртский, якутский и марийский. В дальнейшем «Яндекс» будет улучшать качество перевода на доступные языки и расширять их количество. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться