|
Опрос
|
реклама
Быстрый переход
Продолжительность просмотра видео в поиске «Яндекса» выросла на 20 %
06.09.2024 [17:55],
Владимир Мироненко
В минувшем месяце интернет-пользователи затратили на просмотр контента в поиске по видео «Яндекса» на 20 % больше времени, чем в августе прошлого года. Такую статистику приводит информационное агентство ТАСС со ссылкой на пресс-службу компании. 
Источник изображения: «Яндекс» Также пользователи стали чаще обращаться к сервису для поиска видео — на 25 % больше год к году увеличилось число поисковых сессий. При этом количество пользователей, воспользовавшихся сервисом как с компьютеров, так и с мобильных устройств, увеличилось на 20 процентов. В пресс-службе также отметили увеличение числа пользователей, которые осуществляют поиск в интернете с помощью виртуального помощника «Алисы» в умных устройствах «Яндекса» и на мультимедийной платформе YaOS. Виртуальный ассистент использует поиск по видео и отражает его результаты на дисплее телевизора или умной колонки. «Общее число пользователей поиска по видео в августе выросло на 12 % относительно такого же периода прошлого года. Аналитики “Яндекса” наблюдают дальнейший рост показателей сервиса, судя по данным за первые дни сентября 2024 года», — рассказали в пресс-службе компании. Компания ранее добавила в поиск по видео несколько инструментов, позволяющих упростить поиск нужного контента. В прошлом месяце в поиске появился детектор медленной загрузки, использующий алгоритмы для определения контента с более продолжительной, чем обычно, загрузкой, и предлагающий альтернативу с других площадок. Также теперь можно включить на сервисе фильтр, чтобы видеть в результатах поиска видео только с тех платформ, где нет проблем с загрузкой контента, или просто исключить из поисковой выдачи YouTube-ролики. При этом в результатах поиска сервис будет показывать выше тот контент, у которого нет проблем со скоростью загрузки. В Windows 11 появится ИИ-функция поиска по аудио- и видеозаписям
01.09.2024 [23:09],
Владимир Фетисов
В сборке Windows 11 под номером 27695, которая недавно стала доступна участникам программы предварительной оценки Windows Insider на канале Canary, появились упоминания функции «интеллектуального поиска мультимедиа». Этот инструмент задействует работающий локально ИИ-алгоритм для сканирования всех слов, которые есть в аудио- и видеозаписях, которые хранятся на устройстве пользователя. 
Источник изображения: Microsoft Функция интеллектуального поиска мультимедиа описывается как инструмент, который расшифровывает все аудиофайлы и видео на пользовательском компьютере. В дальнейшем пользователь сможет задействовать поиск в Windows для того, чтобы отыскать на устройстве аудио или видео по словам, содержащимся в записи. По данным источника, в настоящее время данный инструмент недоступен ни в одной тестовой сборке Windows 11. Однако появление упоминаний новой функции указывает на то, что вскоре интеллектуальный поиск мультимедиа может стать доступен инсайдерам. «Поиск по произнесённым словам в проиндексированных аудио- и видеофайлах. Нажимая «Я согласен», вы соглашаетесь на сканирование медиафайлов, хранящихся на вашем устройстве. При необходимости нужная модель будет загружена и установлена в фоновом режиме. После настройки ИИ-модели ей необходимо расшифровать ваши медиафайлы и проиндексировать их, прежде чем они будут добавлены в поиск по контенту. Мы сообщим вам, как только процесс настройки завершится», — говорится в описании функции интеллектуального поиска мультимедиа. Похоже, что новая функция тесно связана с функцией Recall, которая станет доступна инсайдерам в октябре. Recall задействует работающие локально ИИ-алгоритмы для регистрации всех действий пользователя в приложениях, при просмотре веб-контента и др. Собранные таким образом данные отображаются на временной шкале, что позволяет пользователю легко найти интересующую его информацию из прошлого и продолжить взаимодействие с ней. Для работы Recall потребуется наличие компьютера с Windows 11 и производительным процессором со встроенным нейронным сопроцессором (NPU) для ускорения выполнения задач искусственного интеллекта. В «Яндексе» теперь можно исключить YouTube-ролики из результатов поиска по видео
23.08.2024 [18:52],
Сергей Сурабекянц
Компания «Яндекс» добавила новый фильтр в поиск по видео. Фильтр называется «Без YouTube» и позволяет исключить ролики YouTube из поисковой выдачи. Фильтр доступен на всех устройствах во всех браузерах. При включении фильтра настройка будет сохранена для следующих поисков. Отключить его можно в любой момент. 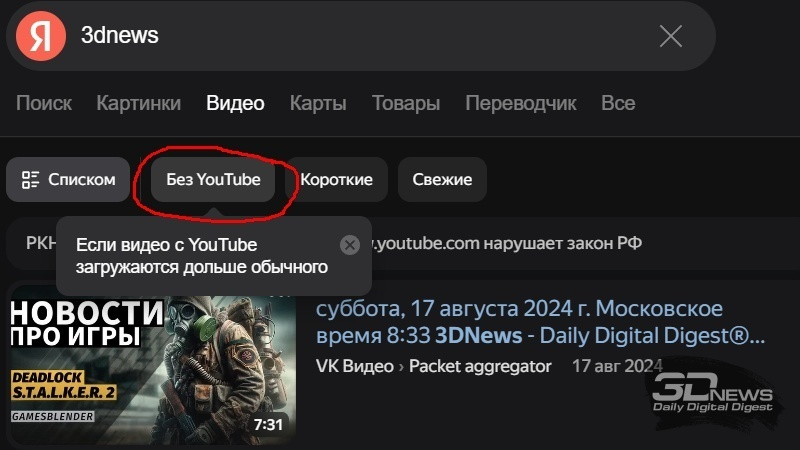 Ранее в «Яндекс Поиске» и «Яндекс Браузере» появился детектор медленной загрузки видеороликов. Благодаря новому инструменту пользователи, столкнувшиеся с долгой загрузкой и «зависаниями» видео, получили возможность быстро найти тот же контент на других ресурсах. В случае отсутствия полного аналога сервис предлагает выбор из наиболее похожего материала. ИИ-ответы в поисковой выдаче Google обрушили посещаемость множества сайтов
15.08.2024 [19:17],
Сергей Сурабекянц
Удобные «Обзоры ИИ» (AI Overviews), которые Google теперь размещает в верхней части результатов поиска, лишают трафика сайты, на которые пользователи могли бы перейти из поисковой системы. Попытки владельцев интернет-ресурсов блокировать ИИ Google приводят к пропаданию сайта из результатов поиска и ещё более резкому снижению посещаемости, так как генератор ИИ-ответов и поисковый бот Google объединены в единую систему, и раздельно контролировать доступ для них невозможно. 
Источник изображений: unsplash.com Доминирование Google в поиске, которое федеральный суд на прошлой неделе определил как «незаконную монополию», даёт компании решающее преимущество — издателям приходится выбирать между предоставлением своего контента для использования моделями ИИ и исчезновением из поиска Google, являющегося главным источником трафика. Многие из них не готовы идти на подобный риск. Google утверждает, что AI Overviews — сводки, отображаемые в верхней части поисковой выдачи, — являются результатом её давней приверженности предоставлению более качественной информации и расширению возможностей для издателей. «Каждый день Google отправляет миллиарды пользователей на сайты по всему интернету, и мы намерены продолжать этот давно устоявшийся обмен ценностями, — заявил представитель Google. — Благодаря обзорам ИИ люди находят “Поиск Google” более полезным и возвращаются, чтобы искать больше, создавая новые возможности для обнаружения контента». Google использует отдельных краулеров для некоторых продуктов, таких как чат-бот Gemini. Но Googlebot, основной краулер компании, обслуживает как AI Overviews, так и «Поиск Google», так как, по словам представителя компании, «они тесно переплетены». Google сообщила, что издатели могут блокировать появление определённых страниц или их фрагментов в AI Overviews, но это также, вероятно, запретит их появление во всех других функциях поиска Google. Генеральный директор iFixit Кайл Винс (Kyle Wiens) сообщил, что отношения сайта iFixit с Google «гораздо более слабые», чем с другими компаниями, занимающимися ИИ. «Я могу запретить ClaudeBot индексировать нас, не навредив нашему бизнесу, — заявил он, имея в виду стартап Anthropic, занимающийся генеративным ИИ. — Но, если я заблокирую Googlebot, мы потеряем трафик и клиентов». «Это выглядит как экзистенциальный кризис [для владельцев интернет-ресурсов], — говорит издатель новостного сайта Talking Points Memo Джо Рагаццо (Joe Ragazzo). — Есть два плохих варианта. Вы уходите и немедленно умираете, или вы сотрудничаете с ними и, вероятно, просто медленно умираете, потому что в конечном итоге они тоже не будут нуждаться в вас». Рост генеративного ИИ породил волну стартапов, предлагающих поисковые продукты на основе ИИ. Растущая популярность чат-ботов может стать серьёзной угрозой для поискового бизнеса Google. Но, чтобы составить конкуренцию поисковому гиганту, требуется максимально полное сканирование и индексирование интернет-ресурсов, что представляет собой непростую задачу. Для этого требуются деньги, вычислительные мощности и ёмкие хранилища информации. Многие издатели, борясь с нелицензированным использованием контента для индексирования, ограничивают сканирование своих ресурсов для сторонних компаний, предоставляя наибольшую свободу действий лишь крупным поисковым системам, таким как Google или Bing, которые служат для них источниками трафика.  Поисковые стартапы не могут обеспечить трафик, сопоставимый с ведущими игроками в сфере интернет-поиска, поэтому они вынуждены платить издателям за лицензирование контента. На фоне волны сделок между медиакомпаниями и стартапами в области ИИ отказ Google от попыток лицензирования контента особенно заметен, а у издателей практически отсутствуют рычаги влияния на компанию. Если не считать единственной сделки на $60 млн с Reddit, которая привела к скачкообразному росту трафика на сайт социальной сети, Google дала понять издателям, что не заинтересована в подобных переговорах. По свидетельствам осведомлённых источников, попытки поискового стартапа Perplexity заключить с Reddit подобную сделку не увенчались успехом из-за слишком высокой планки, установленной Google. Другие поисковые стартапы также не имеют возможности получить доступ к контенту ресурсов, подобных Reddit. «Нам понадобится 20 лет наших текущих доходов только для того, чтобы заплатить Reddit, — сказал Владимир Преловац, основатель поискового стартапа Kagi. — Я даже не рассматриваю такую возможность». Трудности с индексированием контента испытывают не только небольшие стартапы. Крупные популярные сайты, включая Amazon, Goodreads и Uniqlo, заблокировали поисковый робот SearchGPT от OpenAI, что потенциально создаёт проблемы для амбиций компании в интернет-поиске. OpenAI настаивает, что сайты могут появляться в результатах поиска, даже если запретят индексирование. Дело в том, что файлы robots.txt, которые устанавливают правила сканирования, не были признаны юридически значимыми, поэтому публичные данные можно индексировать, если не требуется вход в систему или ввод учётных данных. После знаменательного судебного решения, установившего, что Google монополизировала рынок онлайн-поиска, Министерство юстиции США рассматривает разные варианты правовой защиты, от предоставления конкурентам доступа к поисковому индексу Google до разделения компании. Закон ЕC «О цифровых рынках» уже требует от Google делиться некоторыми данными поисковых запросов. Винс считает, что «отделение поиска Google от их работы в области ИИ позволит устранить конфликты». Вице-президент по связям с общественностью поисковой системы DuckDuckGo Камил Базбаз (Kamyl Bazbaz) отметил важность поисковых индексов в эпоху ИИ, он уверен, что «технологические сдвиги, происходящие в поиске, делают индекс Google, связанный с антимонопольными проблемами, ещё более проблематичным». Независимо от исхода антимонопольного дела против Google, изменения, происходящие в поисковой среде, лишний раз доказывают, что издателям нельзя становиться чрезмерно зависимыми от какой-либо одной технологической платформы, включая Google. «Мы убеждены, что вам нужно формировать настоящие отношения с читателями, — считает Рагаццо, — и именно так вы создаёте издание, которое может выдержать разные эпохи». Audible протестирует поиск аудиокниг при помощи ИИ
07.08.2024 [18:10],
Сергей Сурабекянц
Компания по производству аудиокниг Audible, принадлежащая Amazon, объявила о старте тестирования функции поиска на основе искусственного интеллекта, которая должна помочь пользователям существенно упростить поиск аудиокниг. Некоторым клиентам в США уже сейчас стало доступно взаимодействие с Maven, новым ИИ-экспертом по персональным рекомендациям Audible, который предлагает аудиокниги на основе запросов пользователей. 
Источник изображений: Audible При поиске пользователь может использовать естественный язык для ввода запросов, а Maven предоставит индивидуальные рекомендации, основываясь на каталоге Audible, насчитывающем почти миллион наименований книжной продукции. ИИ-поиск Maven станет доступен на устройствах iOS и Android. Почти половина клиентов Audible в США получат доступ к этой функции, независимо от тарифного плана. В настоящее время, по словам компании, область поиска ограничена «подмножеством» её библиотеки аудиокниг. В дальнейшем Audible планирует развивать и совершенствовать новый инструмент поиска. Audible не конкретизировала, какие модели ИИ были использованы при разработке системы поиска Maven. Представитель компании отметил, что Maven использует «сильные стороны нескольких моделей» и будет «постоянно оценивать» их по мере совершенствования. 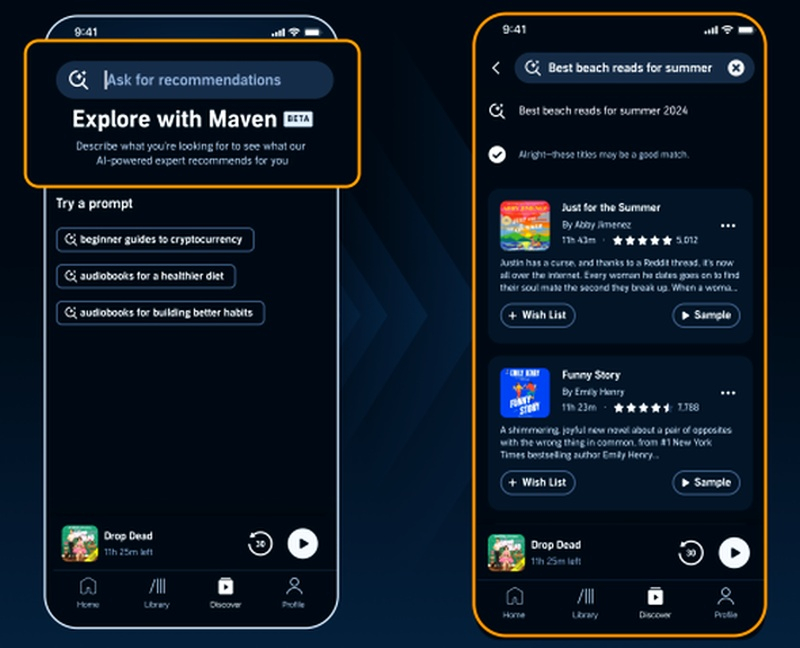 Наряду с объявлением о запуске Maven, Audible сообщила, что также экспериментирует с «Коллекциями», курируемыми ИИ, и обзорами, созданными ИИ. «Коллекции» Audible примечательны тем, что могут стать ответом Audible на плейлисты Spotify, созданные при помощи ИИ. Ранее негативную реакцию со стороны актёров и других творческих личностей вызвало сообщение, что по состоянию на май 2024 года более 40 000 книг в библиотеке Audible были озвучены ИИ. На сегодняшний день их количество, вероятно, заметно увеличилось. На Reddit появится поиск с ИИ для глубокого погружения в контент
07.08.2024 [13:02],
Павел Котов
Администрация Reddit готовится начать тестирование поиска с использованием искусственного интеллекта — на странице с такой выдачей система предложит «сводки и рекомендации контента», сообщил гендиректор платформы Стив Хаффман (Steve Huffman) в разговоре с инвесторами после публикации квартального отчёта. 
Источник изображения: Reddit Интеграция ИИ в функцию поиска поможет пользователям платформы «глубже погружаться» в контент и открывать новые сообщества Reddit; эксперимент начнётся в этом году. В новом формате будут использоваться как собственные технологии платформы, так и сторонние решения, пояснил господин Хаффман. Нечто подобное должно было появиться в ближайшее время: в мае компания объявила о партнёрстве с OpenAI. Разработчик технологий ИИ позволил платформе использовать свои большие языковые модели и помог делегировать некоторые полномочия модераторов, а взамен получил право использовать материалы Reddit для обучения своих систем. В начале года аналогичное соглашение платформа заключила и с Google. Технологии ИИ стали важной темой в разговоре с инвесторами и аналитиками. Хаффман рассказал о качестве машинного перевода на Reddit и отметил, что на платформе активно растёт сообщество пользователей из Франции. Сейчас расширяется функция перевода на немецкий, испанский и португальский языки. Reddit представила уже второй квартальный отчёт с момента выхода на биржу. За II квартал выручка компании составила $281,2 млн, что выше прогнозов аналитиков Уолл-стрит — они ожидали $253,8 млн; число еженедельно активных пользователей составило 342,3 млн человек, и это на 57 % больше, чем годом ранее. Google начала масштабную зачистку поисковой выдачи от откровенных фейковых изображений
31.07.2024 [17:56],
Сергей Сурабекянц
Google внедрила новые функции онлайн-безопасности, которые упрощают масштабное удаление откровенных дипфейковых изображений из поискового индекса и предотвращают их появление на первых позициях результатов поиска. При удалении поддельного контента по запросам пользователей будут также удалены все возможные дубликаты и отфильтрованы результаты по похожим запросам. 
Источник изображения: Pixabay «Эти меры защиты уже доказали свою эффективность в борьбе с другими типами изображений, полученных без согласия правообладателей, и теперь мы создали те же возможности и для поддельных откровенных изображений, — заявила менеджер по продуктам Google Эмма Хайэм (Emma Higham). — Эти усилия призваны дать людям дополнительное спокойствие, особенно если они опасаются появления подобного контента в будущем». Позиции сайтов в индексе Google будут скорректированы, чтобы противодействовать поиску явного фейкового контента. Например, на поисковые запросы, которые намеренно запрашивают поддельные изображения реального человека, поисковая система будет выдавать «высококачественный, корректный контент», например, соответствующие новостные статьи. Сайты со значительным количеством фейковых изображений откровенного характера будут понижены в рейтинге поиска Google. Google утверждает, что предыдущие обновления в этом году более чем на 70 процентов снизили появление в поисковой выдаче откровенных изображений по запросам дипфейкового контента. Перед компанией стоит задача научить поисковую систему отличать реальный откровенный контент, например, изображения обнажённого тела, сделанные по обоюдному согласию, от фейков, чтобы сохранить возможность демонстрации законных изображений. Ранее Google уже предпринимала усилия для решения проблемы появления опасного или откровенного контента в интернете. В 2022 году компания расширила перечень персональной или конфиденциальной информации, которую пользователь может удалить из поиска. В августе 2023 года Google начала по умолчанию размывать откровенно сексуальные изображения. В мае этого года компания запретила рекламодателям продвигать услуги по созданию контента откровенно сексуального характера. В настольном Google Chrome появился визуальный поиск Circle to Search
31.07.2024 [16:33],
Павел Котов
Функция Circle to Search, позволяющая запускать поиск по изображению, если обвести область экрана, появилась в бета-версиях Google ChromeOS 127 и Chrome 128 для Windows и macOS. 
Источник изображения: Rubaitul Azad / unsplash.com Первоначально функция дебютировала на смартфонах Samsung Galaxy S24 и Google Pixel 8, но впоследствии быстро распространилась и на другие устройства. Circle to Search позволяет осуществлять поиск на основе визуального контента, и теперь она доступна на ПК под управлением Google ChromeOS 127, а также в настольных версиях браузера Chrome 128 — пока только в бета-версиях. 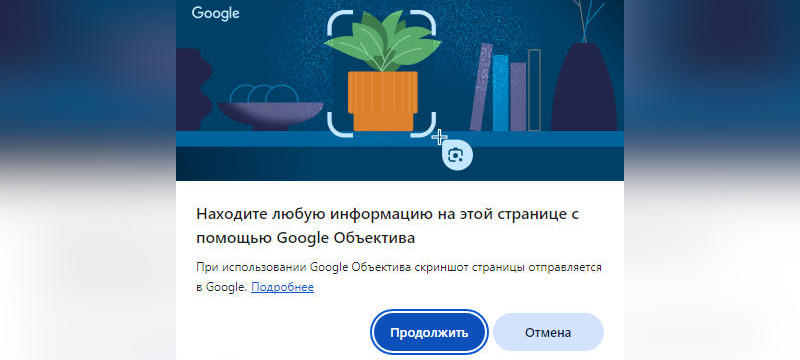 В ChromeOS для её запуска потребуется выбрать значок «Google Объектив» в адресной строке, а в Chrome для Windows и macOS потребуется выбрать пункт «Поиск с Google Объективом» в меню браузера — для удобства её дальнейшего использования соответствующую кнопку можно перенести на панель инструментов Chrome. 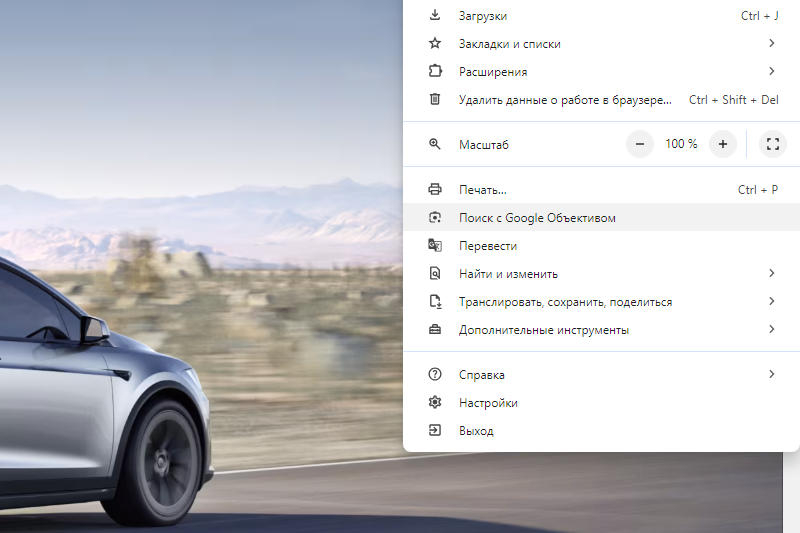 Поиск по содержимому, которое попало в обведённый фрагмент страницы, начинается немедленно, а его результаты выводятся на боковой панели — можно оставаться на открытой странице и сразу же знакомиться с результатами поиска. 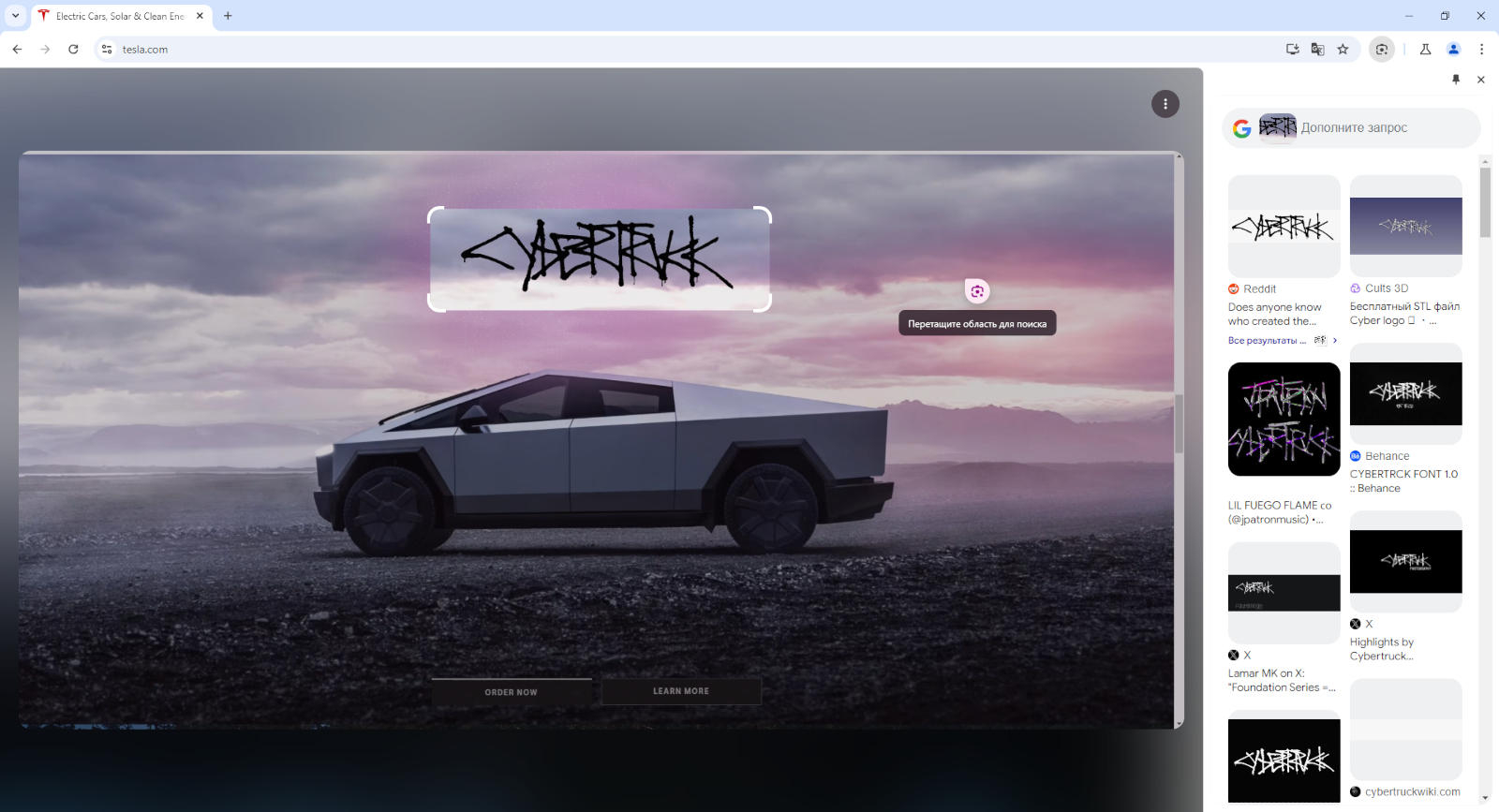 «Google Объектив» в Chrome упрощает поиск всего, что выведено на экран: запущенное видео, кадр прямой трансляции или изображение с текущей страницы — нужные ответы демонстрируются в той же вкладке. Присутствие новой функции в официальных бета-версиях платформы ChromeOS и браузера Chrome свидетельствует, что скоро она станет общедоступной — как ожидается, это произойдёт 14 августа. Motorola представила трекер Moto Tag со сменными батарейками и годом автономности
26.06.2024 [12:05],
Павел Котов
Компания Motorola анонсировала беспроводной трекер Moto Tag, который очень напоминает Apple AirTag и также предназначается для поиска утерянных вещей — багажа и ценных предметов через сеть Google Find My Device. Помимо трекера компания представила глобальные версии смартфонов-раскладушек Razr 50 и Razr 50 Ultra, которые в некоторых странах будут называться Razr (2024) и Razr+ (2024) соответственно. 
Источник изображений: motorolanews.com С выпуском Moto Tag компания Motorola выходит на рынок Bluetooth-трекеров — устройство легко закрепляется на различных предметах, помогая при их последующем поиске. По внешнему виду и функциям трекер похож на Apple AirTag, хотя предназначается для работы на устройствах под управлением Android. Для подключения к оказавшимся поблизости смартфонам Moto Tag использует Bluetooth, при необходимости выбирая UWB для более точного обнаружения в непосредственной близости. Глобальное местоположение устанавливается при помощи сети Google Find My Device. На корпусе трекера есть кнопка, при нажатии которой сопряжённый смартфон издаёт звуковой сигнал — её также можно использовать для удалённого спуска затвора при съёмке автопортретов.  Motorola заверила, что уделила внимание вопросам конфиденциальности. Данные о местоположении защищаются сквозным шифрованием и передаются только на сопряжённое устройство. Предусмотрена встроенная функция защиты от преследования, которая оповещает пользователей Android и iOS при обнаружении путешествующего с ними неизвестного трекера; пользователям Android также доступно ручное сканирование для проверки на наличие нежелательных трекеров в любое время. Подключение к смартфону осуществляется при помощи Google Fast Pair. Можно переименовать трекер, настроить громкость оповещений, следить за временем работы его батареи. Сменного элемента питания (это «таблетка» CR2032) хватит примерно на год работы. Корпус устройства защищён в соответствии со стандартом IP67 — его можно погружать на глубину до 1 м на 30 минут. Moto Tag будет продаваться по всему миру; цена — $29,99 за одну штуку. Perplexity AI превратит поисковую выдачу в веб-страницу, которой удобно делиться с другими
31.05.2024 [20:29],
Сергей Сурабекянц
Стартап Perplexity, разработчик одноимённой поисковой системы с искусственным интеллектом, представил новую функцию, упрощающую совместное использование результатов поиска. С помощью функции Perplexity Pages пользователи могут создать интернет-страницу на основе своего поискового запроса. Достаточно ввести подсказку, остальное новый инструмент сделает сам, а пользователю останется лишь указать тип аудитории, чтобы задать стиль генерируемого текста. 
Источник изображения: Perplexity Алгоритмы Perplexity AI способны создавать подробные структурированные статьи. Пользователь может управлять созданием и оформлением разделов страницы, добавлять и удалять их. Perplexity также поможет найти и вставить необходимые элементы мультимедиа, такие как изображения и видео. Пользователи могут создавать страницы только через веб-интерфейс, но видны они будут и в мобильных приложениях. После создания страница становится доступна для публикации и индексации поисковыми системами. Создатель страницы может поделиться ссылкой на неё с другими пользователями, которые могут задавать дополнительные вопросы по теме. Более того, существующие цепочки разговоров превращаются в страницы одним нажатием кнопки. 
Источник изображений: Pixabay Руководитель отдела дизайна Perplexity Генри Модисетт (Henry Modisett) заявил, что компания хотела применить разработанную технологию в более доступном формате: «Мы заметили, что наши пользователи уже делились своими страницами поиска с другими. Поэтому мы хотели сделать более презентабельный формат». Поскольку инструменту требуется до нескольких минут на завершение страницы, дизайнерам пришлось поломать голову, как сделать ожидание для пользователя максимально комфортным. Контент, созданный ИИ, уже начал оказывать самое непосредственное влияние на такие области, как журналистика, аналитика и обработка информации, собственно, как и на интернет в целом. Perplexity рассматривает свой инструмент как обработку информации, а не создание контента с помощью ИИ. Модисетт отметил, что, как и в стандартных результатах поиска Perplexity, созданные пользователем страницы содержат ссылки на источники и помещают их на видное место.  «Пользователи курируют [информацию] и решают, о чём страница и как она организована. Они принимают решения, так что страницы не полностью генерируются ИИ, — отметил Модисетт. — Пользователи вкладывают в это большую часть своего вкуса. Не все люди могут создать отличную страницу, поэтому в принятии решений о том, как сделать её интересной, есть очень важный человеческий аспект». Пока трудно сказать, как новые возможности отразятся на остальной части экосистемы Perplexity. Функция Perplexity Pages пока доступна ограниченному числу пользователей, но в конечном итоге компания планирует сделать её доступной для всех. В настоящее время Perplexity находится на волне успеха и привлекает как минимум $250 млн новых инвестиций при оценочной капитализации от 2,5 до 3 млрд долларов. Google обвинила в странных ответах поискового ИИ самих пользователей и недостаток обучающих данных
31.05.2024 [16:27],
Павел Котов
На минувшей неделе Google добавила в поисковую систему блок сводок, которые готовит генеративный ИИ. Компания стремилась повысить качество работы поисковой системы, но ИИ начал давать пользователям странные ответы, например, советовал есть камни и клеить сыр к пицце. Компания быстро удалила наиболее скандальные результаты, но они уже успели уйти в мемы. Теперь с комментариями выступила глава поискового подразделения компании. 
Источник изображения: Kai Wenzel / unsplash.com Глава отдела поиска Google Лиз Рид (Liz Reid) обвинила в неточных результатах ответов поискового генеративного ИИ «пустоты данных» и самих пользователей, которые придумывали странные вопросы. По её мнению, блоки с обзорами, которые создаёт генеративный ИИ, дают пользователям «большее удовлетворение» работой поисковой службы. Генерируемые ИИ ответы, как правило, не являются галлюцинациями — просто система иногда неверно интерпретирует то, что есть в Сети. «Нет лучшего аргумента, чем миллионы людей, использующих эту функцию со множеством новых запросов. Мы также отметили новые бессмысленные запросы, по-видимому, направленные на получение ошибочных результатов», — сообщила Рид. Компания, однако, продолжает работать над функцией, ограничивая появление ИИ-обзоров в выдаче по «бессмысленным» запросам и при работе с сатирическими материалами. Это важно, потому что первоначально система могла процитировать сатирический ресурс или сослаться на пользователя соцсети с неприличным ником. Рид также сравнила ИИ-обзоры с поисковой функцией «Выделенные описания» — это блоки с фрагментами текста релевантных веб-страниц, которые приводятся без участия генеративного ИИ. По словам топ-менеджера, «уровни точности» двух функций примерно совпадают. AMD заплатит вам до $30 000, если вы найдёте баг или уязвимость в её продуктах
30.05.2024 [18:28],
Сергей Сурабекянц
AMD заключила соглашение с краудсорсинговым поставщиком услуг безопасности Intigriti для запуска программы вознаграждения за обнаружение проблем. Исследователи безопасности и этичные хакеры смогут сообщать об уязвимостях и ошибках в оборудовании, прошивках или программном обеспечении AMD через платформу Intigriti, и получать за это денежное вознаграждение. Размер вознаграждения составит от $500 до $30 000 в зависимости от серьёзности обнаруженной проблемы.  Ранее подобная программа AMD распространялась лишь на узкий круг избранных «придворных» исследователей. Новая инициатива позволит привлечь широкий круг тестировщиков и экспертов к поиску проблем в продуктах AMD. Вознаграждения, предлагаемые AMD на платформе Intigriti, зависят от серьёзности ошибки и категории продукта.  Безусловно, исследователь по-прежнему может отправить отчёт о проблеме непосредственно в AMD через её команду по безопасности продуктов, но этот путь не гарантирует оплаты, хотя в бюллетене по безопасности упоминание о нашедшем ошибку появится. Программы поиска ошибок (Bug Bounty) много значат для крупных технологических компаний, чьи продукты и услуги широко используются и могут повлиять на миллионы клиентов. В случае AMD достаточно вспомнить уязвимость ко взлому через модуль безопасности TPM у процессоров AMD Zen 2 и Zen 3, уязвимость Inception в процессорах AMD Zen 3 и Zen 4, уязвимость Zenbleed в системы на базе Zen 2, множественные ошибки в библиотеке AMD AGESA для BIOS материнских плат с чипсетами AMD 600-й серии для процессоров Ryzen 7000 или зависание ядра серверных процессоров EPYC 7002 Rome. Другие крупные корпорации технологического сектора также имеют программы вознаграждения за обнаружение ошибок, помогающие гарантировать, что их системы и продукты защищены от необнаруженных уязвимостей, например, Intel Project Circuit Breaker. Успешные «охотники за багами» могут неплохо зарабатывать — многие этичные хакеры ещё в 2020 году получали более $90 000 в год. В 2023 году Google выплатила в сумме не менее $10 млн в качестве вознаграждения за обнаружение ошибок, а Polygon Technology выплатила $2 млн исследователю, обнаружившему критическую ошибку. Google признала подлинность слитых секретных документов о работе поисковика
30.05.2024 [15:26],
Павел Котов
Недавно ставший достоянием общественности пакет из 2500 внутренних документов Google с подробной информацией о работе поисковой системы является подлинным, подтвердили в компании. До настоящего момента IT-гигант отказывался комментировать эти материалы. 
Источник изображения: Alex Dudar / unsplash.com В документах подробно описано, какие данные отслеживает Google, и указывается, что некоторые из них компания может использовать в работе тщательно охраняемого алгоритма поискового ранжирования. Материалы позволяют, хотя и частично, ознакомиться с механизмами работы одной из наиболее важных систем, формирующих интернет. «Предостерегаем от неверных допущений о „Поиске“ на основе вырванной из контекста, устаревшей или неполной информации. Мы поделились обширными сведениями о том, как работает „Поиск“ и типах факторов, которые учитываются в наших системах, [мы] также работаем над защитой целостности наших результатов от манипуляций», — заявил ресурсу The Verge представитель Google Дэвис Томпсон (Davis Thompson). Об утечке материалов Google сообщили эксперты по поисковой оптимизации Рэнд Фишкин (Rand Fishkin) и Майк Кинг (Mike King), которые опубликовали аналитические работы на основе этих документов. Согласно этим материалам, Google собирает и может использовать данные, которые, как утверждают представители компании, не влияют на ранжирование страниц в поиске: это клики по ссылкам, данные пользователей Chrome и многое другое. Эти документы располагаются в базе для сотрудников Google, и всё ещё нет ясности, какие именно данные используются при ранжировании — информация может быть устаревшей, использоваться исключительно в учебных целях или собираться, но не применяться при поиске. В материалах также не говорится, какой вес в поиске имеют различные факторы, если они вообще учитываются. Обнародованная информация, вероятно, вызовет волнения в сфере поисковой оптимизации (SEO), маркетинге и издательском деле. Факторы, которыми Google руководствуется при ранжировании сайтов в поисковой выдаче, оказывает большое влияние на компании и предпринимателей, которые делают ставку на интернет: от небольших независимых издателей до ресторанов и интернет-магазинов. Возникла целая отрасль специалистов, которые надеются разгадать, а то и перехитрить поисковые алгоритмы. И утечка внутренних документов Google поможет им понять, о чем думает доминирующая в Сети компания. Секретная документация Google о принципах работы поискового алгоритма стала достоянием общественности
29.05.2024 [06:12],
Анжелла Марина
Предполагаемая утечка 2500 страниц внутренней документации Google проливает свет на то, как работает Поиск, самый могущественный алгоритм интернета. Обнародованные документы показывают, что компания скрывала правду о некоторых аспектах поискового алгоритма. Эксперты обнаружили противоречия с публичными заявлениями компании. 
Источник изображения: Daniel Romero/Unsplash Несколько дней назад произошла масштабная утечка внутренних документов Google, связанных с работой поискового алгоритма компании. По словам эксперта по поисковой оптимизации (SEO) Рэнда Фишкина (Rand Fishkin), который первым сообщил об утечке, речь идёт о 2500 страницах конфиденциальной документации. Эти документы, как утверждается, содержат беспрецедентные подробности о том, как Google анализирует и ранжирует веб-страницы в результатах поиска. Однако в них также есть информация, которая, похоже, противоречит некоторым публичным заявлениям, сделанным представителями Google о работе их поискового алгоритма. В частности, в документах упоминается использование данных из браузера Google Chrome для анализа и ранжирования веб-страниц. Однако ранее представители Google неоднократно отрицали, что данные Chrome каким-либо образом влияют на рейтинг сайтов в поиске. Ещё один потенциальный пример расхождения «слов с делом» касается показателя EEAT (Expertise, Authoritativeness, Trustworthiness), который Google использует для оценки надёжности источников информации. Согласно утечке, Google активно отслеживает атрибуты авторства контента на страницах, что может влиять на рейтинг EEAT. Однако ранее представители компании заявляли, что EEAT не является фактором ранжирования. Помимо этого, в документах содержатся технические детали о том, какие именно данные с веб-страниц и сайтов собирает Google, как обрабатываются запросы по политически чувствительным темам, какие сигналы используются для анализа небольших малопосещаемых сайтов и многое другое. Рэнд Фишкин и другие эксперты по SEO, ознакомившиеся с информацией, утверждают, что она показывает — Google не была полностью честна и прозрачна в вопросах о том, как работает её поисковый алгоритм. По их мнению, компания намеренно скрывала некоторые аспекты с целью ввести в заблуждение конкурирующие друг c другом сайты. Многие эксперты сходятся во мнении, что скрытность Google в вопросах работы поискового алгоритма способствовала разрастанию индустрии SEO, основанной на догадках и теориях. Фишкин призывает журналистов и экспертов более критично относиться к публичным заявлениям Google и не принимать всё на веру. По его мнению, данная утечка должна стать поводом для более пристального анализа реальной работы поискового алгоритма Google в противовес официальной позиции компании. Представители Google пока не прокомментировали подлинность обнародованных документов и обвинений в лукавстве. Ожидается, что в ближайшее время компания сделает официальное заявление по этому поводу. Найден способ навсегда избавить поисковую выдачу Google от советов ИИ
25.05.2024 [13:01],
Павел Котов
Для тех, кто в штыки воспринял появление генерируемых искусственных интеллектом сводок информации в поисковой выдаче Google, найден способ принудительно вернуть поисковик к показу традиционных «десяти синих ссылок» по умолчанию — без советов есть клей и бегать с ножницами, а также без необходимости каждый раз вручную включать опцию «Веб-версия».  Вариант с «чистой» поисковой выдачей Google предложила на минувшей неделе — он стал альтернативой странице с результатами, которую формирует ИИ. Единственное неудобство при этом — необходимость каждый раз выбирать опцию «Веб-версия» в выпадающем подменю под поисковой строкой. Выяснилось, что есть способ включить её по умолчанию, и этот способ был обнаружен при изучении URL-адреса поисковой выдачи Google по произвольному запросу. Этот адрес содержит множество параметров, и за показ обычных «десяти синих ссылок» отвечает выражение «&udm=14» — им и следует воспользоваться при настройке браузера. Тем, кто привык начинать поиск прямо из адресной строки браузера, потребуется открыть настройки поисковых систем: в Google Chrome и Mozilla Firefox они не очень отличаются, а в производных от них браузерах механизм настройки будет схожим. В случае Chrome достаточно щёлкнуть правой кнопкой мыши в адресной строке и выбрать пункт «Управление поисковыми системами и поиском по сайту». В Firefox придётся приложить дополнительные усилия: ввести в адресную строку выражение «about:config», нажать клавишу Enter, найти раздел «browser.urlbar.update2.engineAliasRefresh» и щёлкнуть мышью кнопку с изображением знака «плюс» справа; после этого перейти в раздел «Настройки» и подраздел «Поиск», прокрутить до блока «Значки поисковых систем» и под ним щёлкнуть кнопку «Добавить». 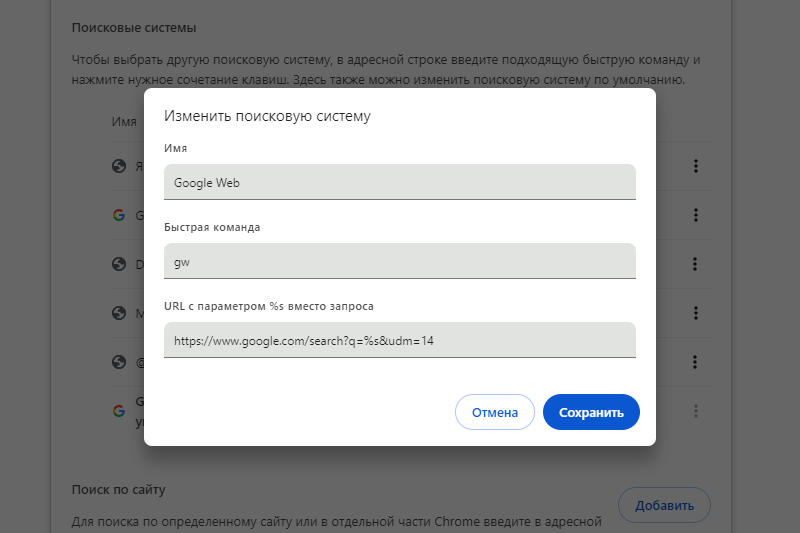 В обоих браузерах возможности редактировать существующий пункт Google не будет, поэтому потребуется создать новый ярлык поисковой системы, назвать его, например, Google Web и в качестве основного адреса добавить выражение «https://www.google.com/search?q=%s&udm=14». Оставшееся поле, которое расположено посередине, может называться «Быстрая команда» или «Краткое имя» — его значение пригодится, если новая поисковая система не будет установлена по умолчанию. Так, если внести в это поле сочетание «gw», то впоследствии можно будет использовать новую поисковую систему, вводя запросы вида «gw куда сходить вечером». При желании можно дополнить адрес параметром «&tbs=li:1», с которым Google производит поиск только по точному совпадению, без замены слова в запросе синонимами. Можно также пользоваться прокси-сайтами, например, udm14.com, поисковое поле которого ведёт напрямую в выдачу Google с активной опцией «Веб-версия» — но владельцы таких ресурсов имеют техническую возможность перехватывать поисковые запросы пользователей. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться