|
Опрос
|
реклама
Быстрый переход
Разработчиков ИИ уличили в сборе данных с сайтов СМИ вопреки прямым запретам
22.06.2024 [12:28],
Павел Котов
Несколько компаний, занимающихся разработкой систем искусственного интеллекта, игнорируют принятый отраслью веб-стандарт, который позволяет издателям блокировать сбор своего контента с целью его последующего включения в массивы для обучения генеративного ИИ. Об этом сообщает Reuters. 
Источник изображений: Gerd Altmann / pixabay.com Информация о неправомерных действиях разработчиков ИИ в отношении сайтов СМИ появилась в рамках публичного разбирательства ИИ-стартапа Perplexity и ресурса Forbes, при этом компании, предположительно оказавшиеся правонарушителями и пострадавшими, не называются. Деловое издание публично обвинило Perplexity в плагиате материалов своих расследований — в составляемых генеративным ИИ сводках оказываются материалы Forbes без запросов разрешения и ссылок на авторов. Поисковый веб-сканер Perplexity, вероятно, игнорирует директивы, которые указываются издателями в файле robots.txt — распространённый стандарт помогает администраторам сайтов определять, какие разделы разрешено сканировать поисковым роботам. О проблеме сообщила компания TollBit — стартап, выступающий посредником между испытывающими потребность в обучающих материалах ИИ-компаниями и открытыми для заключения лицензионных соглашений издателями. Perplexity — не единственный нарушитель, который предположительно игнорирует директивы robots.txt, считают в TollBit. Сейчас в базе посредника значатся 50 издателей, и «чем больше журналов издателей мы принимаем, тем больше проявляется эта закономерность».  Протокол robots.txt был создан в середине девяностых годов, чтобы защитить сайты от перегрузок из-за поисковых роботов. Чёткого механизма правового принуждения соблюдать директивы файла не существует, но исторически они соблюдались добровольно. Недавно robots.txt стал основным инструментом, который издатели использовали, чтобы не допустить бесплатного включения их контента в массив данных для генеративного ИИ. Этот контент используется как для обучения ИИ, так и для создания сводок информации на его основе в режиме реального времени. Некоторые издатели, включая New York Times, пытаются засудить разработчиков ИИ за нарушение авторских прав в связи с использованием материалов для этих целей. Другие подписывают с создателями ИИ лицензионные соглашения. Стороны часто расходятся во мнениях относительно ценности материалов — некоторые разработчики даже утверждают, что не нарушают законов, получая доступ к материалам СМИ бесплатно. Android будет предварительно проверять все устанавливаемые приложения на наличие угроз
19.10.2023 [17:45],
Павел Котов
Чтобы защитить пользователей от потенциально опасных и явно вредоносных мобильных приложений под Android, Google разработала механизм их предварительной проверки прямо на этапе установки. И пока непонятно, можно ли будет отключить эту проверку. 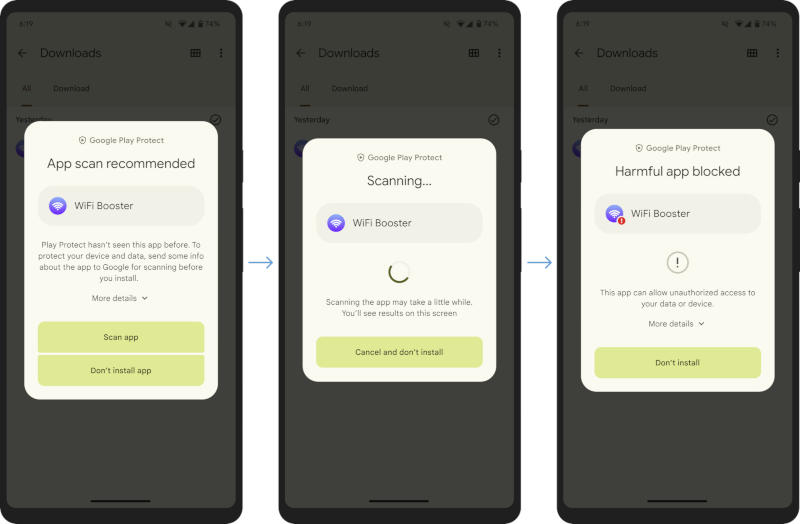
Источник изображения: security.googleblog.com Система обнаружения вредоносного ПО Google Play Protect, входящая в магазин приложений «Play Маркет», всегда имела возможность проверять устанавливаемые из сторонних источников приложения на наличие угроз, только ранее такая проверка осуществлялась в фоновом режиме. Теперь этот процесс будет производиться с полноэкранным интерфейсом и глубоким сканированием кода. Google Play Protect станет предлагать такое сканирование не при каждой установке приложения из стороннего источника, а лишь в тех случаях, когда система ранее не была с ним знакома. По результатам сканирования она сообщит пользователю, какова оценка приложения: является ли оно безобидным или содержит потенциальную угрозу. Google даже опубликовала скриншоты интерфейса механизма сканирования, и, если верить картинкам, у пользователя будут лишь два варианта: «Сканировать приложение» или «Не устанавливать приложение». Хотя ещё есть пункт «Подробнее» (More details), под которым может скрываться опция «Пропустить». Функция сканирования приложений из сторонних источников дебютирует в Индии — эта страна лидировала в распространении вредоносного мобильного ПО в 2018 году, гласят отчёты Google. Ранее стало известно, что механизм проверки безопасности на смартфонах Xiaomi блокирует в Китае установку приложений, которые заблокировали местные власти — в частности, установить Telegram не получится. Маск против чужих нейросетей: X полностью запретила сканирование и парсинг, чтобы на данных соцсети не обучали ИИ
08.09.2023 [19:06],
Сергей Сурабекянц
X (ранее Twitter) обновила свои условия использования, полностью запретив парсинг и сканирование — вероятно, чтобы предотвратить обучение любых моделей искусственного интеллекта на её данных. Новые условия, вступающие в силу 29 сентября, запрещают любые виды парсинга или сканирования без «предварительного письменного согласия». Предыдущая версия условий разрешала сканирование в соответствии с файлом robots.txt, содержащим инструкции для поисковых роботов. Источник изображения: X За последние несколько месяцев X изменила свой файл robots.txt, который содержит инструкции для сканирующих ботов о том, какие части сайта им разрешено посещать, удалив инструкции для всех роботов-сканеров, кроме Google. В 2015 году Twitter заключила соглашение с Google об отображении твитов в результатах поиска. Неясно, изменились ли характер или условия этой сделки при новом руководстве. Комментариев от обеих компаний пока получить не удалось Теперь настройки файла robots.txt запрещают сканерам получать информацию о лайках и ретвитах (или теперь их стоит называть «реиксами»?), относящихся к конкретным сообщениям. Он также запрещает поисковым роботам просматривать лайки, медиафайлы и фотографии аккаунта. В июне соцсеть на короткое время запретила не вошедшим в систему пользователям просматривать публикации. Несколько дней спустя компания всё же убрала требование входа в систему для просмотра твитов. Илон Маск (Elon Musk) объяснял эту временную меру «разворовыванием данных сайта, что ухудшает качество обслуживания обычных пользователей». Маск решительно протестует против компаний, собирающих данные X для обучения моделей ИИ. В апреле он пригрозил подать в суд на Microsoft за незаконное использование данных соцсети для обучения моделей ИИ. В июле он подал иск по этому поводу против нескольких неназванных компаний. Ранее в этом месяце X изменила свою политику конфиденциальности, заявив, что может использовать общедоступные данные для обучения моделей ИИ. Маск ранее отмечал в своём аккаунте X, что компания xAI, основанная им в июле, будет использовать общедоступные данные, такие как публикации в X, для обучения своих моделей. Новая политика конфиденциальности X также содержит положения о сборе биометрических данных пользователей, об их образовании и истории трудовой деятельности. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться