|
Опрос
|
реклама
Быстрый переход
Volvo выпустит самый мощный суперкомпьютер на колёсах
20.02.2025 [10:50],
Дмитрий Федоров
Volvo готовит электрический седан ES90 — автомобиль с самой высокой вычислительной производительностью. Построенный на платформе SPA2 и использующий технологический стек Superset, электромобиль оснащён парой суперкомпьютеров Nvidia Drive AGX Orin. Система с производительностью 508 триллионов операций в секунду (TOPS), обеспечивает мгновенную обработку данных с сенсоров, управляет системами активной безопасности на основе ИИ в реальном времени и оптимизирует распределение энергии. 
Источник изображений: Volvo Car Corporation Система на базе двух Orin представляет собой значительное усовершенствование по сравнению с предыдущими решениями Volvo. Новый суперкомпьютер обеспечивает восьмикратное увеличение производительности по сравнению с Nvidia Xavier, который использовался в 2018 году, когда Volvo объявила о стратегическом партнёрстве с Nvidia. Возросшая вычислительная мощность позволит значительно улучшить алгоритмы машинного обучения: объём данных, обрабатываемых нейросетями Volvo, увеличится с 40 млн до 200 млн параметров. Это создаст основу для более точного восприятия окружающей среды электромобилем, сокращения времени отклика на дорожные ситуации и повышения эффективности автопилота. Технологический стек Superset, лежащий в основе ES90, представляет собой инженерную модульную платформу, предназначенную для будущих автомобилей Volvo. Этот унифицированный подход позволит компании создавать новые модели на единой архитектуре, сокращая затраты на разработку и ускоряя внедрение передовых технологий.  Superset включает в себя ключевые модули: систему автономного вождения, управление энергопотреблением, мониторинг окружающей среды и беспроводные обновления программного обеспечения (ПО). Благодаря этому ES90 сможет получать новые функции, совершенствоваться со временем и оставаться актуальным даже после выхода на рынок.  Концепция программно-определяемых автомобилей стала индустриальным стандартом после успеха Tesla — первой компании, внедрившей транспортные средства с возможностью обновления через мобильный интернет или Wi-Fi. Volvo также движется в этом направлении, но сталкивается с технологическими трудностями.  Ранее представленный электрический внедорожник EX90 с одним чипом Nvidia Drive AGX Orin должен был стать первой моделью компании, использующей стек Superset, однако его запуск был отложен из-за проблем с ПО. Когда модель всё же вышла на рынок, оказалось, что в ней отсутствовали многие из обещанных функций. Volvo рассчитывает, что с ES90 ей удастся преодолеть эти трудности и создать полностью адаптивный автомобиль.  Volvo заявляет, что функции помощи водителю, системы безопасности и даже запас хода батареи будут улучшаться со временем благодаря оптимизации алгоритмов и выпуску новых версий ПО. Более того, ES90 и EX90 будут использовать единую технологическую платформу, что позволит синхронизировать обновления между моделями и обеспечит их долгосрочную поддержку. Учёные впервые заглянули внутрь нейтронных звёзд, совершив прорыв в их моделировании на суперкомпьютерах
14.01.2025 [19:39],
Геннадий Детинич
Внутри нейтронных звёзд происходят экстремальные физические процессы, которые, вероятно, никогда не удастся изучить напрямую. Более того, это настолько компактные объекты, что они невидимы в телескопы. Всё, чем располагает наука, — это косвенные данные о нейтронных звёздах и возможность грубого моделирования их свойств на компьютерах. Однако при определённых усилиях точность таких моделей можно довести до высочайшего уровня. 
Комбинированное изображение Крабовидной туманности с нейтронной звездой в видимом, инфракрасном и рентгеновском диапазоне. Источник изображения: NASA До ближайшей нейтронной звезды от Земли около 400 световых лет. У нас нет, и в течение тысяч лет не появится технологий, позволяющих отправить туда исследовательскую станцию. На таком расстоянии никакой телескоп не сможет разглядеть нейтронную звезду диаметром всего 20 км. Кроме того, в земных условиях невозможно воспроизвести физические параметры внутри нейтронной звезды, где плотность вещества в несколько раз превышает плотность атомных ядер. Качественный прорыв в моделировании нейтронных звёзд, вероятно, станет возможным с появлением мощных квантовых симуляторов. Однако уже сегодня у нас есть суперкомпьютеры и развитая квантовая математика, что может быть достаточным для углублённого анализа физики нейтронных звёзд. По крайней мере, об этом недавно заявили учёные из Университета Колорадо в Боулдере и Массачусетского технологического института. Внутренние свойства нейтронной звезды, такие как давление и плотность, определяются уравнениями квантовой хромодинамики (КХД), которые описывают сильное взаимодействие между протонами, нейтронами и составляющими их кварками. Однако эти уравнения нельзя решить для всей нейтронной звезды. Упрощая ряд переменных, учёные могут решать уравнения для внешнего слоя звезды и её ядра, но промежуточный слой до сих пор описывался лишь аппроксимацией. Прямого решения не существовало. Чтобы обойти это ограничение, исследователи применили другой подход — квантовую хромодинамику на решётке. Но и здесь не обошлось без уловки. КХД на решётке также не позволяет напрямую решать уравнения для всего объёма нейтронной звезды. Уравнения становятся решаемыми, если принять во внимание изоспин — характеристику, отличающую протоны от нейтронов знаком зарядовых состояний. Используя предложенную модель описания нейтронных звёзд, учёные установили пределы размеров этих объектов и получили новые строгие ограничения для свойств их внутренней части. Одним из выводов этой работы стало предположение, что массы нейтронных звёзд могут превышать две солнечные массы, что ранее считалось теоретическим пределом для таких объектов. Расчёты на суперкомпьютере предоставили множество интересных данных. Однако без следующего шага — подтверждения вычисленных свойств нейтронных звёзд с помощью астрофизических наблюдений — эти результаты остаются перспективной гипотезой и инструментом для поиска новых путей их изучения. И это уже немалое достижение. Nvidia представила настольный ИИ-суперкомпьютер Project Digits на суперчипе Grace Blackwell за $3000
07.01.2025 [10:23],
Андрей Созинов
Nvidia представила персональный ИИ-суперкомпьютер. В мае этого года компания начнёт продажи системы под названием Project Digits, в основе которой лежит новый суперчип GB10 Grace Blackwell. Он обладает достаточной вычислительной мощностью для запуска сложных моделей ИИ (LLM) и при этом достаточно компактен, чтобы поместиться на столе и работать от стандартной розетки. Ранее для такой вычислительной мощности требовались гораздо более крупные и энергоёмкие системы. 
Источник изображений: Nvidia «ИИ станет основным в каждом приложении для каждой отрасли. Благодаря Project Digits суперчип Grace Blackwell станет доступен миллионам разработчиков, — заявил генеральный директор Nvidia Дженсен Хуанг (Jensen Huang). — Размещение суперкомпьютера ИИ на столах каждого специалиста по обработке данных, исследователя ИИ и студента даст им возможность участвовать в формировании эпохи ИИ». Система Project Digits, размером с традиционный настольный мини-ПК вроде Mac mini, может работать с моделями ИИ, содержащими до 200 миллиардов параметров, а её стартовая цена составляет 3000 долларов. Для ещё более требовательных приложений две системы Project Digits могут быть объединены для работы с моделями, содержащими до 405 миллиардов параметров (лучшая модель Meta✴, Llama 3.1, как раз имеет 405 миллиардов параметров). 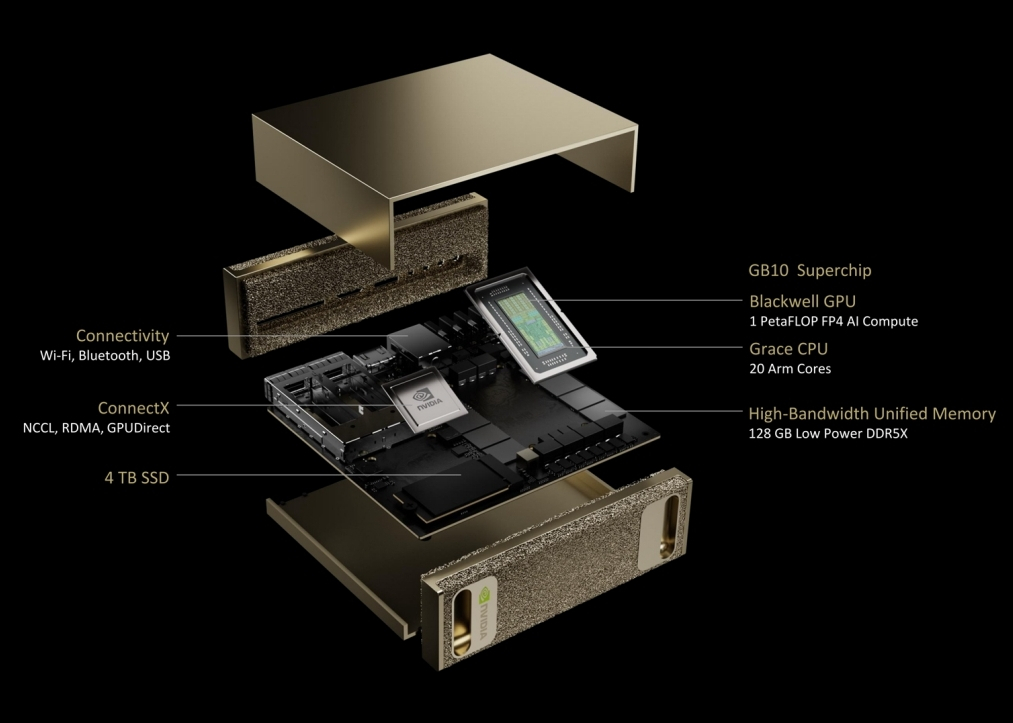 Чип GB10 Grace Blackwell обеспечивает производительность до 1 петафлопа с точностью FP4, то есть он способен выполнять 1 квадриллион операций в секунду для обучения и запуска ИИ-моделей. Система оснащена графическим процессором с ядрами Nvidia CUDA последнего поколения и тензорными ядрами пятого поколения. Он подключён через NVLink-C2C к центральному процессору Grace с 20 энергоэффективными ядрами на архитектуре Arm. В разработке GB10 участвовала компания MediaTek, помогая оптимизировать энергоэффективность и производительность. Каждая система оснащается 128 Гбайт унифицированной когерентной оперативной памяти и до 4 Тбайт NVMe-накопителя. Пользователи также получат доступ к библиотеке программного обеспечения Nvidia для ИИ, включая наборы для разработки, инструменты оркестрации и предварительно обученные модели, доступные в каталоге Nvidia NGC. Система работает на базе Linux Nvidia DGX OS и поддерживает такие популярные фреймворки, как PyTorch, Python и Jupyter Notebooks. Разработчики могут настраивать модели с помощью фреймворка Nvidia NeMo и ускорять рабочие процессы в области науки о данных с помощью библиотек Nvidia RAPIDS.  Пользователи могут разрабатывать и тестировать свои модели ИИ локально на Project Digits, а затем развёртывать их в облачных сервисах или инфраструктуре центров обработки данных, которые используют ту же архитектуру Grace Blackwell и программную платформу Nvidia AI Enterprise. Заметим, что это далеко не первый «потребительский» ИИ-суперкомпьютер Nvidia. В декабре компания анонсировала версию своего компьютера Jetson за 249 долларов для приложений ИИ, ориентированную на любителей и стартапы, под названием Jetson Orin Nano Super, который способен справляться с LLM до 8 миллиардов параметров. Китай засекретил новые суперкомпьютеры и делает вид, что не развивается в этой сфере
28.12.2024 [13:27],
Павел Котов
Китайское компьютерное общество (Chinese Society of Computer Science) опубликовало список сотни самых производительных суперкомпьютеров в стране, который, возможно, не отражает истинного положения вещей. Как и в прошлом году, в него не попали системы экзафлопсного класса; более того, в нём не оказалось новых систем по сравнению с прошлогодней редакцией. 
Источник изображения: Top500.org Единственным отличием списков сотни мощнейших суперкомпьютеров Китая за 2023 и 2024 годы стал некоторый рост их совокупной производительности. Китайские организации могут намеренно скрывать сведения о самых мощных системах, чтобы не провоцировать новых санкций со стороны США. В тройке лидеров сейчас оказались те же суперкомпьютеры с центральными и графическими процессорами, что и в 2023 году. Первое место, по официальной версии, принадлежит машине, развёрнутой в 2023 году, — у неё 15 974 400 ядер центрального процессора и производительность до 487,94 Пфлопс в тесте Linpack. Она мощнее японского суперкомпьютера Fugaku (442 Пфлопс, FP64), но значительно уступает экзафлопсным американцам El Capitan (1,742 Эфлопс), Frontier (1,353 Эфлопс) и Aurora (1,012 Эфлопс). Вторым стал суперкомпьютер, запущенный в 2022 году — у него 460 000 ядер центрального процессора и 208,26 Пфлопс; третьей оказалась система на 285 000 ядер центрального процессора и производительностью 125,04 Пфлопс по версии Linpack. Разница в совокупной производительности в официальных списках сотни наиболее мощных суперкомпьютеров минимальна: в 2023 году она была 1,398 Эфлопс, а в 2024 году выросла до 1,406 Эфлопс. Но ещё в прошлом году эксперт в области суперкомпьютеров Джек Донгарра (Jack Dongarra) заявил, что в Китае есть по крайней мере три машины экзафлопсного класса с производительностью от 1,3 до 1,7 Эфлопс, а также машина на 2 Эфлопс с x86-процессорами Hygon. Официальных подтверждений информации не последовало, но слова господина Донгарры в отрасли воспринимаются всерьёз. Информация об этих системах и спецификации машин из официального рейтинга не публикуются, вероятно, чтобы скрыть поставщиков компонентов для суперкомпьютеров. Аналитики, как правило, достаточно проницательны, чтобы установить, какое оборудование может использоваться, и кто может его поставлять — есть версия, что в этих системах установлены стандартные компоненты, и многие из них поставляются по «серым» каналам в обход американских санкций. Но в десятке лидеров есть и системы на процессорах и графических ускорителях китайской разработки. Суперкомпьютеру Илона Маска выделили 150 МВт — теперь он заработает почти во всю мощь
24.12.2024 [16:18],
Павел Котов
Американская федеральная корпорация TVA (Tennessee Valley Authority) одобрила выделение суперкомпьютеру Colossus компании xAI Илона Маска (Elon Musk) мощности в 150 МВт, что позволит запустить объект почти в полную силу. 
Источник изображения: x.com/xai Вычислительный кластер для систем искусственного интеллекта xAI Colossus сможет запустить почти все свои 100 000 ускорителей Nvidia — ранее число работающих компонентов ограничивалось доступной для предприятия мощностью. Огромный запрос объекта на электричество вызывал обеспокоенность у местных заинтересованных сторон относительно воздействия на энергосистему всего региона. Компания Илона Маска xAI впервые запустила суперкомпьютер в июле 2024 года, и уже тогда ему требовалось значительно больше энергии, чем было доступно — первоначально было выделено лишь 8 МВт. Команда Маска попыталась восполнить пробел, используя собственные источники питания, и ещё до конца лета местная ресурсоснабжающая компания Memphis Light, Gas & Water (MLGW) модернизировала действующую подстанцию, чтобы обеспечить объекту 50 МВт, но и этого было мало. Для одновременного запуска всех 100 000 ИИ-ускорителей требуется примерно 155 МВт мощности, то есть с выделенной властями квотой его потребности будут почти удовлетворены. MLGW и TVA провели работу с местными жителями и заверили их, что возросший уровень энергопотребления со стороны объекта xAI не окажет отрицательного влияния на надёжность электроснабжения в районе Мемфиса. Гендиректор MLGW Дуг Макгоуэн (Doug McGowen) отметил, что при новой квоте мощность остаётся в пределах прогнозируемой пиковой нагрузки компании, и в случае необходимости у TVA будет закуплена дополнительная мощность. Чтобы удовлетворить возросшие с развитием отрасли ИИ потребности в электроэнергии, крупные технологические компании, включая Amazon, Google, Microsoft и Oracle, начали вкладываться в альтернативные источники, в том числе в ядерную энергетику. Однако последняя сможет быть развернута не менее чем через пять лет. До этого времени потребителям придётся использовать для питания центров обработки данных существующую инфраструктуру, что вызывает опасения по поводу её способности справляться с растущим спросом. Google совершила прорыв в квантовых вычислениях: решена 30-летняя проблема квантовой коррекции ошибок
10.12.2024 [02:10],
Анжелла Марина
Google совершила прорыв в области квантовых вычислений. Благодаря новому улучшенному процессору и усовершенствованной системе коррекции ошибок удалось значительно увеличить время жизни квантового кубита. Как сообщает Ars Technica, учёным удалось создать квантовый процессор Willow, который впервые преодолел порог квантовой коррекции ошибок. Это значит, что при увеличении числа кубитов частота ошибок не растет, а снижается. Кроме того, на полностью задействованном процессоре со 105-кубитами логический квантовый бит оказался стабилен в среднем на протяжении часа. 
Источник изображения: Google Для развития квантовых технологий Google построила собственный производственный центр для создания сверхпроводящих процессоров. «Ранее все устройства Sycamore изготавливались в общей лаборатории университета, где рядом работали аспиранты и другие исследователи, занимавшиеся различными экспериментами, — говорит Джулиан Келли (Julian Kelly), представитель команды Google. — Однако мы инвестировали значительные средства в создание нового предприятия, наняли персонал, оснастили его оборудованием и перенесли туда наши процессы». Первым результатом работы нового центра стало увеличение числа кубитов до 105 единиц на процессоре Willow, который стал вторым поколением квантовых процессоров Google. Новая архитектура этого процессора позволила снизить уровень ошибок благодаря увеличению размеров отдельных кубитов, сделав их менее чувствительными к шуму. Этот прогресс подтвердился и в ходе тестов, проведённых с использованием фирменного бенчмарка Google. «Мы пришли к тому, что выполнение задачи на нашем новом процессоре занимает менее пяти минут, тогда как классическому компьютеру потребовалось бы время соизмеримое с возрастом Вселенной», — отметил Келли. Если точнее, то Willow менее чем за пять минут решил задачу из квантового бенчмарка RCS, на которую у Frontier (самого быстрого суперкомпьютера в мире) ушло бы 10 септиллионов (1024) лет. Ключевым аспектом исследования стало поведение логических кубитов, представляющих из себя главный элемент квантовых вычислений. Они состоят из нескольких аппаратных кубитов, которые работают вместе для выявления и исправления ошибок. Для выполнения сложных алгоритмов, требующих нескольких часов, стабильность таких кубитов крайне важна, и новый результат Google подтверждает, что улучшенная система коррекция ошибок может обеспечить необходимый уровень надёжности. Квантовая коррекция ошибок — задача, которая стояла перед исследователями последние 30 лет и мешала практическому использованию квантовых компьютеров. Для этого был использован специальный код коррекции ошибок, представляющий из себя «поверхностный код» (этот код также должен быть устойчив к ошибкам), который должен идеально вписываться в квадратную сетку расположения кубитов. Увеличение размера этой сетки и использование всё большей её части улучшает и коррекцию. Исследование показало, что переход от расстояния трёх к пяти и затем к семи снижает количество ошибок вдвое на каждом этапе. «Мы увеличиваем сетку по этой системе, и уровень ошибок падает в два раза на каждом этапе», — пояснил Майкл Ньюман (Michael Newman) из Google. Однако кубиты всё ещё подвержены редким сбоям. Одной из причин являются локальные всплески ошибок, другая причина кроется в более сложном феномене, включающем одновременные ошибки в области, состоящей из примерно 30 кубитов. Пока таких событий зафиксировано лишь шесть, поэтому их изучение затруднено и в Google подчёркивают, что «эти события настолько редки, что нам сложно собрать достаточно статистики для их анализа». Кроме улучшения стабильности, увеличение размера кода коррекции ошибок позволяет значительно усилить эффект от будущих аппаратных улучшений. Например, в Google подсчитали, что улучшение производительности аппаратных кубитов в два раза при кодовом расстоянии Хэмминга d-15 снизит ошибки логического кубита в 250 раз. При расстоянии d-27 это же улучшение приведёт к уменьшению ошибок более чем в 10 000 раз. При этом полное устранение ошибок невозможно. «Важно понимать, что всегда будет определённый уровень ошибок, но его можно снизить до уровня, когда он станет практически незначительным», — отметили в компании. Несмотря на необходимость дальнейших исследований для увеличения времени жизни логических кубитов и масштабирования системы, команда Google уверена в достижении своих целей, а экспоненциальные улучшения подтверждают жизнеспособность технологии. Полученные результаты открывают путь к построению полезных на практике квантовых систем. К концу десятилетия Google планирует создать полноценный отказоустойчивый квантовый компьютер и начать предоставлять квантовые вычисления через облако. Мощнейший в мире ИИ-суперкомпьютер xAI Colossus расширят в десять раз — до 1 млн чипов Nvidia
05.12.2024 [18:00],
Павел Котов
Стартап Илона Маска (Elon Musk) в области искусственного интеллекта xAI намеревается колоссально расширить свой суперкомпьютер Colossus — до более чем 1 млн графических процессоров. Это поможет сократить разрыв с такими конкурентами как Google, OpenAI и Anthropic, сообщает Financial Times. 
Источник изображения: x.com/xai Colossus собрали в этом году всего за три месяца — сейчас он включает массив из 100 тыс. ускорителей искусственного интеллекта Nvidia, и по данному критерию это крупнейший суперкомпьютер в мире. Он используется для обучения моделей ИИ для чат-бота Grok, который менее продвинут и имеет меньше пользователей, чем OpenAI ChatGPT или Google Gemini. Работы по расширению объекта в теннессийском Мемфисе в десять раз уже начались, сообщили в Торговой палате агломерации. Помощь в реализации проекта окажут Nvidia, Dell и Supermicro; будет сформирована «специальная оперативная группа xAI». Компании, работающие в области ИИ, активно пытаются обеспечить для себя поставки ускорителей или доступ к центрам обработки данных — обучение и запуск больших языковых моделей требует серьёзной вычислительной мощности. Так, ответственная за ChatGPT компания OpenAI получила от Microsoft инвестиции на сумму более $14 млрд; вложения создавшей чат-бот Claude компании Anthropic от Amazon составили $8 млрд — гигант электронной коммерции также пообещал партнёру доступ к новому кластеру из более чем 100 тыс. ИИ-ускорителей собственной разработки. Маск решил не формировать партнёрских проектов, а с нуля построить самодостаточную компанию xAI, которая недавно привлекла очередные $5 млрд при оценке в $45 млрд. Проект метит в конкуренты OpenAI, в создании которой в 2015 году бизнесмен также участвовал — недавно он подал на на неё в суд с требованием запретить реорганизацию в коммерческую компанию. Гендиректор Nvidia Дженсен Хуанг (Jensen Huang) ранее заявил, что объекты масштаба Colossus обычно строятся не три месяца, а три года. «Мы не просто лидируем; мы беспрецедентными темпами ускоряем прогресс, обеспечивая стабильность [электро]сети с использованием технологии Megapack», — заявил Брент Майо (Brent Mayo), старший менеджер xAI по строительству и инфраструктуре, когда компанию попытались обвинить в манипуляциях с разрешительной строительной документацией и чрезмерными требованиями к региональной энергосистеме. 36 000 графических процессоров AMD создали крупнейшую модель Вселенной
27.11.2024 [15:47],
Геннадий Детинич
Вселенная слишком большая и старая, чтобы в реальном времени наблюдать за происходящими в ней процессами. Между тем, только наблюдения дают истинные представления о мире, в котором мы живём. Выход находится в моделировании. Суперкомпьютеры могут воссоздавать модель Вселенной в определённых рамках, но требуют взамен использования немалых ресурсов, которые, к счастью, сегодня доступны учёным. 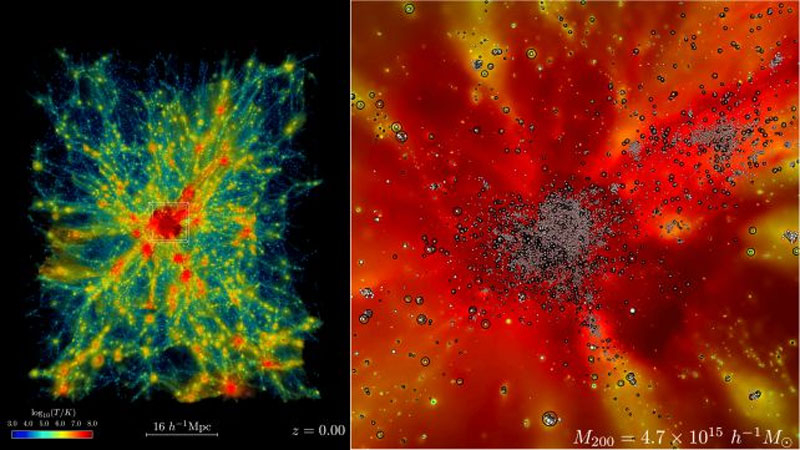
Источник изображения: Argonne National Laboratory Несколько лет подготовки и настраивания алгоритмов позволили создать крупнейшую за всю историю цифровую модель части Вселенной. Работа завершена в ноябре 2024 года. Суперкомпьютер Frontier в Ок-Риджской национальной лаборатории (ORNL) силами своих 9000 узлов, где каждый узел представлен процессором AMD EPYC 3-го поколения и четырьмя GPU-ускорителями AMD Instinct 250X, создал модель расширяющейся Вселенной объёмом свыше 31 млрд Мпс3 (мегапарсек кубических). «Во Вселенной есть два компонента: тёмная материя, которая, насколько нам известно, взаимодействует только гравитационно, и обычная материя, или атомное вещество, — объясняет физик Салман Хабиб (Salman Habib) из Аргоннской национальной лаборатории в США, который руководил работой. — Итак, если мы хотим знать, что представляет собой Вселенная, нам нужно смоделировать обе эти вещи: гравитацию, а также всю остальную физику, включая горячий газ, и образование звёзд, чёрных дыр и галактик; астрофизическую "кухню", так сказать. Эти симуляции — это то, что мы называем симуляциями космологической гидродинамики». Тем самым нетрудно понять, что проект под названием ExaSky — крупнейшая за всю истории симуляция Вселенной — поможет учёным лучше разобраться в физике и эволюции Вселенной, включая исследование природы тёмной материи. Модель позволяет ускоренно просматривать эволюционные трансформации вещества под разными углами и с разных сторон. Соотнесение наблюдаемого в реальной Вселенной с эволюцией в модели поможет уточнить теорию и практику, а также обратит внимание на нюансы, которые могли ускользнуть от понимания. Прежде чем мы увидим какие-либо публикации на основе работы с новой моделью Вселенной, пройдёт год или больше, но учёные уже сегодня предлагают ознакомиться с фрагментом модели. В подготовленном для этого видеоролике представлена всего одна тысячная от всей модели — объём пространства 311 296 Мпс3 или куб со сторонами 64 × 64 × 76 Мпс. Это стало настоящим вызовом для мощностей Frontier, добавляют учёные, но оно того стоило. El Capitan на базе чипов AMD стал самым быстрым суперкомпьютером в мире
19.11.2024 [08:07],
Анжелла Марина
El Capitan, оснащённый процессорами AMD, занял первое место в рейтинге самых мощных суперкомпьютеров мира с производительностью 1,7 эксафлопс, превзойдя предыдущего лидера Frontier с показателем 1,3 эксафлопс. Aurora компании Intel опустилась на третье место. 
Источник изображения: AMD El Capitan представляет из себя массивную систему, состоящую из 44 544 гибридных процессоров AMD Instinct MI300A и 11 136 узлов. Объём основной памяти составляет 5,4 петабайта, а за обработку больших объёмов данных отвечает локальная система хранения «Rabbit». Как сообщает Tom's Hardware, в рамках теста High-Performance Linpack (HPL) была показана реальная производительность в 1,742 эксафлопс, что на 45 % быстрее, чем у ближайшего конкурента. Теоретический пик производительности достигает 2,746 эксафлопс, однако такие показатели в реальном мире практически недостижимы. Суперкомпьютер будет использоваться в США для моделирования ядерных взрывов и оценки состояния ядерного арсенала страны. Помимо этого, система позволит разрабатывать новые межконтинентальные баллистические ракеты (ICBM) и решать задачи, связанные с высокопроизводительными вычислениями и искусственным интеллектом. El Capitan способен обрабатывать данные с высокой точностью (FP64), что необходимо для научных и инженерных задач, в отличие от систем, ориентированных только на задачи ИИ. 
Источник изображения: AMD El Capitan был построен компанией HPE на базе архитектуры Shasta, которая также используется в других экcафлопсных системах, таких как Frontier и Aurora. Все три суперкомпьютера занимают ведущие позиции в рейтинге Top500, что подтверждает лидерство HPE в создании высокопроизводительных вычислительных систем. Frontier, который теперь находится на втором месте, также продемонстрировал улучшенные результаты по сравнению с предыдущими тестами, увеличив свою производительность до 1,353 эксафлопс. Известно также, что система потребляет более 35 МВт энергии при полной нагрузке и занимает 18-е место в рейтинге самых энергоэффективных суперкомпьютеров Green500, демонстрируя 58,89 GFLOPS на Вт. Суперкомпьютер El Capitan насчитывает более 11 миллионов вычислительных ядер, интегрированных в процессоры Instinct MI300A, которые объединяют в одном корпусе как CPU, так и GPU. Каждый процессор MI300A включает в себя 146 миллиардов транзисторов и использует передовые технологии 3D-упаковки чипов, что позволяет значительно улучшить энергоэффективность и производительность. Отдельное внимание привлекает ситуация с суперкомпьютером Aurora, построенным на базе технологий Intel. Несмотря на заявленные ранее результаты, система не смогла предоставить новые данные для рейтинга, что указывает на продолжающиеся проблемы с оборудованием и охлаждением. При этом Aurora всё ещё остаётся самым мощным ИИ-суперкомпьютером в мире с производительностью 10,6 эксафлопс в задачах смешанной точности. Nvidia поможет Google в разработке эффективных квантовых процессоров
19.11.2024 [04:30],
Николай Хижняк
Компания Nvidia поможет Alphabet, материнской компании Google, в разработке квантовых процессоров. Согласно заявлению обеих компаний, подразделение Google Quantum AI будет использовать суперкомпьютер Nvidia Eos для ускорения проектирования квантовых компонентов. 
Источник изображений: Nvidia Идея состоит в том, чтобы на базе суперкомпьютера Nvidia Eos моделировать физические процессоры, необходимые для работы квантовых процессоров, что поможет преодолеть текущие ограничения в разработке по-настоящему эффективных квантовых систем. Квантовые вычисления основаны на принципах использования квантовой механики для создания машин, которые будут намного быстрее, чем современные технологии на основе полупроводников. Однако для массового характера использования таких технологий время пока не пришло. Как сообщает Bloomberg, несмотря на то, что различные компании заявляли о прорывах в области квантовых вычислений, могут потребоваться десятилетия, чтобы на рынке появились действительно крупномасштабные коммерческие проекты, связанные с квантовыми вычислениями. Nvidia, самая дорогая компания в мире, считает, что её аппаратные технологии помогут Google решить одну сложную проблему, связанную с квантовыми вычислениями. По мере того, как квантовые процессоры становятся всё более сложными и мощными, в квантовых вычислениях становится всё сложнее различать фактическую информацию и помехи, известные как шум. «Разработка коммерчески полезных квантовых компьютеров возможна только в том случае, если мы сможем масштабировать квантовое оборудование, контролируя шум. Используя ускоренные вычисления Nvidia, мы изучаем влияние шума на растущую сложность схем квантовых чипов», — прокомментировал Гифре Видал (Guifre Vidal), научный сотрудник Google Quantum AI. Для поиска решений Nvidia предлагает использовать гигантский суперкомпьютер, в котором используются её ИИ-ускорители. С помощью суперкомпьютера будут моделироваться процессы взаимодействия квантовых систем с окружающей средой. Например, многие квантовые чипы необходимо охлаждать до очень низких температур, чтобы они вообще работали. Раньше такие вычисления были чрезвычайно дорогими и отнимали много времени. Nvidia заявляет, что её система будет выдавать результаты расчётов, на которых ранее ушла бы неделя, за считанные минуты, и это обойдётся значительно дешевле. «Больше, чем у кого-либо»: Цукерберг похвастался системой с более чем 100 тыс. Nvidia H100 — на ней обучается Llama 4
31.10.2024 [22:31],
Николай Хижняк
Среди американских IT-гигантов зародилась новая забава — соревнование, у кого больше кластеры и твёрже уверенность в превосходстве своих мощностей для обучения больших языковых моделей ИИ. Лишь недавно глава компании Tesla Илон Маск (Elon Musk) хвастался завершением сборки суперкомпьютера xAI Colossus со 100 тыс. ускорителей Nvidia H100 для обучения ИИ, как об использовании более 100 тыс. таких же ИИ-ускорителей сообщил глава Meta✴ Марк Цукерберг (Mark Zuckerberg). 
Источник изображения: CNET/YouTube Глава Meta✴ отметил, что упомянутая система используется для обучения большой языковой модели нового поколения Llama 4. Эта LLM обучается «на кластере, в котором используется больше 100 000 графических ИИ-процессоров H100, и это больше, чем что-либо, что я видел в отчётах о том, что делают другие», — заявил Цукерберг. Он не поделился деталями о том, что именно уже умеет делать Llama 4. Однако, как пишет издание Wired со ссылкой на заявление главы Meta✴, их ИИ-модель обрела «новые модальности», «стала сильнее в рассуждениях» и «значительно быстрее». Этим комментарием Цукерберг явно хотел уколоть Маска, который ранее заявлял, что в составе его суперкластера xAI Colossus для обучения ИИ-модели Grok используются 100 тыс. ускорителей Nvidia H100. Позже Маск заявил, что количество ускорителей в xAI Colossus в перспективе будет увеличено втрое. Meta✴ также ранее заявила, что планирует получить до конца текущего года ИИ-ускорители, эквивалентные более чем полумиллиону H100. Таким образом, у компании Цукерберга уже имеется значительное количество оборудования для обучения своих ИИ-моделей, и будет ещё больше. Meta✴ использует уникальный подход к распространению своих моделей Llama — она предоставляет их полностью бесплатно, позволяя другим исследователям, компаниям и организациям создавать на их базе новые продукты. Это отличает её от тех же GPT-4o от OpenAI и Gemini от Google, доступных только через API. Однако Meta✴ всё же накладывает некоторые ограничения на лицензию Llama, например, на коммерческое использование. Кроме того, компания не сообщает, как именно обучаются её модели. В остальном модели Llama имеют природу «открытого исходного кода». С учётом заявленного количества используемых ускорителей для обучения ИИ-моделей возникает вопрос — сколько электричества всё это требует? Один специализированный ускоритель может съедать до 3,7 МВт·ч энергии в год. Это означает, что 100 тыс. таких ускорителей будут потреблять как минимум 370 ГВт·ч электроэнергии — как отмечается, достаточно для того, чтобы обеспечить энергией свыше 34 млн среднестатистических американских домохозяйств. Каким образом компании добывают всю эту энергию? По признанию самого Цукерберга, со временем сфера ИИ столкнётся с ограничением доступных энергетических мощностей. Компания Илона Маска, например, использует несколько огромных мобильных генераторов для питания суперкластера из 100 тыс. ускорителей, расположенных в здании площадью более 7000 м2 в Мемфисе, штат Теннесси. Та же Google может не достичь своих целевых показателей по выбросам углерода, поскольку с 2019 года увеличила выбросы парниковых газов своими дата-центрами на 48 %. На этом фоне бывший генеральный директор Google даже предложил США отказаться от поставленных климатических целей, позволив компаниям, занимающимся ИИ, работать на полную мощность, а затем использовать разработанные технологии ИИ для решения климатического кризиса. Meta✴ увильнула от ответа на вопрос о том, как компании удалось запитать такой гигантский вычислительный кластер. Необходимость в обеспечении растущего объёма используемой энергии для ИИ вынудила те же технологические гиганты Amazon, Oracle, Microsoft и Google обратиться к атомной энергетике. Одни инвестируют в разработку малых ядерных реакторов, другие подписали контракты на перезапуск старых атомных электростанций для обеспечения растущих энергетических потребностей. Илон Маск удвоит, а после утроит мощность ИИ-суперкомпьютера xAI Colossus — там будет 300 тыс. Nvidia H100 и H200
29.10.2024 [22:48],
Владимир Фетисов
Илон Маск (Elon Musk) стремится стать лидером в гонке по созданию нейросетей следующего поколения. Для этого он планирует вдвое расширить ИИ-кластер xAI Colossus, который в настоящее время включает в себя 100 тыс. графических ускорителей Nvidia H100. 
Источник изображения: servethehome.com Эта новость пришла от Nvidia, а позднее сам Маск подтвердил её в своём аккаунте в соцсети X, написав, что ИИ-суперкомпьютер Colossus близок к тому, чтобы вместить 200 тыс. ускорителей Nvidia H100 и H200, которые разместятся в здании площадью более 7000 м² в Мемфисе, штат Теннесси. Суперкомпьютер Colossus примечателен тем, что сотрудники xAI сумели собрать его и ввести в эксплуатацию в крайне сжатые сроки. Обычно на создание суперкомпьютеров уходят годы, но в данном случае, по словам Маска, весь процесс от начала до конца занял 122 дня. При этом принадлежащая миллиардеру xAI потратила на создание Colossus не менее $3 млрд, поскольку сейчас он состоит из 100 тыс. ускорителей Nvidia H100, которые обычно стоят в районе $30 тыс. за штуку. Теперь же бизнесмен намерен модернизировать кластер за счёт использования более производительных ускорителей H200, каждый из которых стоит около $40 тыс. В конечном счёте Маску придётся потратить ещё несколько миллиардов долларов, не говоря уже о затратах на электроэнергию для поддержания работоспособности кластера. Конечная цель бизнесмена состоит в том, чтобы к лету следующего года нарастить количество используемых ускорителей до 300 тыс. единиц, причём для дальнейшей модернизации планируется задействовать новейшие Nvidia Blackwell B200. Маск делает большую ставку на ИИ-ускорители Nvidia с целью дальнейшего развития чат-бота Grok от xAI и других технологий на базе нейросетей. Ранее на этой неделе в интернете появилось видео, демонстрирующее ИИ-кластер xAI изнутри, в котором можно увидеть множество серверных стоек с ускорителями Nvidia. Google снова показала квантовое превосходство — квантовые компьютеры стали ближе к практическому применению
10.10.2024 [09:19],
Дмитрий Федоров
Группа учёных под руководством Google сообщила о прорыве в области квантовых вычислений. Они снова продемонстрировали квантовое превосходство — способность квантового компьютера выполнять вычисления, на которые не способен классический, — но на этот раз сосредоточились на точности вычислений. Также учёные показали, что существуют фазовые переходы в вычислительных процессах, что открывает путь к дальнейшему развитию квантовых технологий. 
Источник изображений: Google, Nature Ещё в 2019 году Google заявляла о достижении квантового превосходства, вызвав бурные споры в научном сообществе. Тогда IBM подвергла сомнению этот результат, утверждая, что классические алгоритмы могут быть оптимизированы для решения аналогичных задач. В новой работе, опубликованной в журнале Nature, учёные описали эксперимент с использованием метода случайной выборки цепей (Random Circuit Sampling, RCS), в ходе которого 67-кубитная система выполнила 32 цикла вычислений. Акцент сделан не на квантовом превосходстве, а на том, что даже при наличии шумов — основного ограничения для квантовых процессоров и главной причины ошибок вычислений — можно добиться вычислительных успехов, которые превосходят возможности классических систем. Это доказывает, что квантовые вычисления приближаются к фазе практического применения. Термин «квантовое превосходство» вызывает определённые споры в научном сообществе. Некоторые исследователи предпочитают использовать термины «квантовая полезность» (Quantum Utility) или «квантовое преимущество» (Quantum Advantage). Последний термин подразумевает не только теоретическое превосходство квантовых устройств, но и их практическую пользу. В отличие от квантового превосходства, которое не связано с реальной полезностью для задач, квантовое преимущество предполагает выполнение задач быстрее и эффективнее, чем на классических компьютерах.  Квантовые процессоры, несмотря на их потенциал, остаются чрезвычайно чувствительными к внешним шумам, таким как температурные колебания, магнитные поля или даже космическая радиация. Эти помехи могут существенно снижать точность вычислений. В исследовании Google учёные изучили влияние шума на работу квантовых устройств и провели эксперимент, который позволил исследовать два ключевых фазовых перехода: динамический переход, зависящий от числа циклов, и квантовый фазовый переход, влияющий на уровень ошибок. Результаты показали, что даже в условиях шума квантовые системы эпохи NISQ могут достичь вычислительной сложности, недоступной для классических систем. 
Фазовые переходы в случайной выборке цепей (RCS). График иллюстрирует два фазовых перехода. Первый — от сосредоточенного распределения битовых строк на малом числе циклов к широкому или антиконцентрированному распределению. Второй — переход в условиях шума, при котором высокая ошибка на цикл приводит к переходу от системы с полной корреляцией к представлению в виде нескольких несвязанных подсистем Метод случайной выборки цепей (RCS), использованный в эксперименте, ранее подвергался критике за свою простоту и кажущуюся бесполезность. Однако Google подчёркивает, что RCS является ключевым методом для перехода к задачам, которые невозможно решить на классических компьютерах. Этот метод оптимизирует квантовые корреляции с использованием операций типа iSWAP, что предотвращает упрощение классических эмуляций. Благодаря этому подходу Google смогла чётко обозначить границы возможностей квантовых систем, стимулируя конкуренцию между квантовыми и классическими вычислительными платформами.  В исследовании также рассматриваются перспективы практического использования квантовых процессоров. Одним из первых примеров может стать сертифицированное генерирование по-настоящему случайных чисел, требующее высокой вычислительной сложности и устойчивости к шумам. Серджио Бойксо (Sergio Boixo), руководитель квантовых исследований Google, в своём интервью для Nature отметил: «Если квантовые устройства не смогут продемонстрировать преимущество с помощью RCS, самого простого из примеров использования, то вряд ли они смогут это сделать в других задачах». 
Дорожная карта развития квантовых вычислений Google Работа Google представляет собой значительный вклад в развитие квантовых технологий. Хотя практическое применение квантовых устройств остаётся сложной задачей, такие направления, как сертифицированное генерирование случайных чисел, могут стать первым шагом к их коммерческому использованию. Несмотря на сложности, связанные с шумами, эксперименты Google показывают, что переход от теоретических исследований к практическому применению квантовых устройств становится всё более реальным. Япония построит зеттафлопсный суперкомпьютер — самый мощный в мире
28.08.2024 [12:06],
Павел Котов
Министерство образования, культуры, спорта, науки и технологий Японии (MEXT) объявило о планах построить преемник суперкомпьютера «Фугаку» (Fugaku), который ранее был самым быстрым в мире. Институт физико-химических исследований (RIKEN) и компания Fujitsu начнут его разработку в следующем году, сообщает Nikkei. 
Источник изображений: riken.jp Новый суперкомпьютер продемонстрирует производительность для алгоритмов искусственного интеллекта в 50 экзафлопс с пиковой производительностью зеттафлопсного масштаба в отдельных задачах — машина будет использоваться для работы с ИИ в научных целях. Другими словами, система сможет выполнять один секстиллион операций с плавающей запятой; зеттафлопс в тысячу раз быстрее экзафлопса, и если к 2030 году Япония построит такую систему, у неё действительно будет самый производительный суперкомпьютер в мире. Каждый вычислительный узел суперкомпьютера Fugaku Next будет иметь пиковую производительность в несколько сотен терафлопс для вычислений с двойной точностью (FP64), около 50 петафлопс для вычислений с точностью FP16 и около 100 петафлопс для вычислений с 8-битной точностью; память HBM обеспечит пропускную способность в несколько сотен Тбайт/с. Для сравнения, вычислительный узел «Фугаку» демонстрирует 3,4 Тфлопс для вычислений с двойной точностью, 13,5 Тфлопс для вычислений с половинной точностью (FP16), а пропускная способность памяти составляет 1,0 Тбайт/с.  На первый год разработки системы министерство выделит 4,2 млрд иен ($29,05 млн), а общее государственное финансирование превысит 110 млрд иен ($761 млн). Возглавит разработку RIKEN, один из самых известных исследовательских институтов Японии; а с учётом того, что MEXT требует максимального присутствия японских технологий в системе, разработкой оборудования будет заниматься преимущественно Fujitsu. Какие-то конкретные требования к архитектуре Fugaku Next в документах MEXT не указываются — вероятно, это будут центральные процессоры со специализированными ускорителями или комбинация центральных и графических процессоров. Если преемник «Фугаку» будет работать на процессорах Fujitsu, он получит чипы, которые выйдут после MONAKA, у которых на борту до 150 ядер Armv9. Речь идёт о компоненте в мультичиплетной конфигурации, распределенной по многоядерным кристаллам и кристаллами SRAM и ввода-вывода. Последние обеспечивают работу с памятью DDR5, а также интерфейсами PCIe 6.0 и CXL 3.0 для различных ускорителей и периферии. Кристаллы ядер будут производиться с использованием 2-нм техпроцесса TSMC. Преемник Fujitsu MONAKA получит большее число ядер и более мощные интерфейсы — он, возможно, станет изготавливаться по техпроцессу класса 1 нм или ещё более передовому. Илон Маск показал ИИ-суперкомпьютер Cortex — 50 тыс. Nvidia H100 будут обучать ИИ для автопилота Tesla
28.08.2024 [10:20],
Павел Котов
Илон Маск (Elon Musk) опубликовал в соцсети X видео, снятое на своём новом объекте — суперкластере для обучения искусственного интеллекта Cortex, который расположился близ завода Giga Texas компании Tesla. На объекте будут работать 70 000 ИИ-серверов, которые в общей сложности будут потреблять 130 МВт. А к 2026 году суперкомпьютер будет расширен до 500 МВт. 
Источник изображений: x.com/elonmusk На видео продемонстрирован процесс сборки серверных стоек — ряды по 16 единиц перемежаются примерно четырьмя стойками без ИИ-ускорителей. Каждая стойка включает восемь серверов. На 20-секундный ролик попали где-то 16–20 рядов серверных стоек, что при грубой оценке даёт около 2000 серверов с ускорителями или 3 % от общей предполагаемой мощности объекта.
Cortex должен стать крупнейшим у Tesla суперкластером для обучения систем ИИ — здесь будут работать 50 тыс. ускорителей Nvidia H100 и 20 тыс. ускорителей собственной разработки компании, хотя ранее предполагалось, что их тоже будет 50 тыс. Ускорители Tesla установят несколько позже, а при запуске объекта здесь будет работать только оборудование Nvidia. Система создаётся для «решения задач ИИ в реальном мире». Речь идёт об обучении системы автопилота Tesla Full Self Driving (FSD) для потребительских автомобилей и Cybertaxi, а также обучении ИИ для робота Optimus, чьё мелкосерийное производство, как ожидается, будет запущено в 2025 году.  Ранее Маск опубликовал снимок гигантских вентиляторов объекта Cortex, подключённых к системе жидкостного охлаждения Supermicro, которая справится со всем 500-МВт объектом. Первым центром обработки данных Маска, который будет введён в эксплуатацию, станет принадлежащий его стартапу xAI Memphis Supercluster со 100 тыс. Nvidia H100 в единой структуре RDMA и с охлаждением Supermicro — в перспективе к ним будут подключены ещё 300 тыс. B200, но из-за недостатков конструкции их ввод в эксплуатацию задерживается на несколько месяцев. Кроме того, в городе Буффало (шт. Нью-Йорк) готовится к запуску принадлежащий Tesla суперкомпьютер Dojo стоимостью $500 млн. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться