|
Опрос
|
реклама
Быстрый переход
Приложение «Фотографии» в Windows 11 получит большое обновление, основанное на ИИ
25.03.2025 [18:18],
Сергей Сурабекянц
Приложение «Фотографии» в Windows 11 скоро пополнится новыми инструментами на базе ИИ. Microsoft в настоящее время тестирует обновление, которое добавляет кнопку Copilot и ярлыки для инструментов ИИ в контекстное меню «Проводника» и возможность поиска в интернете по распознанному тексту. Также появилась возможность использовать фильтры для настройки отображения содержимого вложенных папок и галерей. 
Источник изображений: Microsoft Участники программы Windows Insider в канале Release Preview получили возможность протестировать несколько новых функций на основе ИИ. Многие из этих функций уже некоторое время находятся в разработке, но их появление в канале Release Preview говорит о скором появлении в общедоступной стабильной версии системы. Microsoft запланировала мероприятие, посвящённое ИИ, на 4 апреля 2025 года, приурочив его к 50-летию компании. Ожидается презентация новых функций ИИ для Windows 11 и приложений Microsoft. В конце января для участников программы Windows Insiders в Windows 11 и Windows 10 в приложении «Фотографии» появилась функция оптического распознавания символов (OCR), поддерживающая более 160 языков. Для распознавания текста достаточно нажать кнопку «Сканировать текст» в приложении. Теперь стало возможным использовать функцию «Поиск в интернете», чтобы найти распознанный текст прямо из приложения. Такой подход упрощает извлечение и поиск онлайн-результатов текста из документов, заметок, снимков экрана и других изображений. Microsoft добавила новые ярлыки для инструментов ИИ в «Проводник». Они обеспечивают быстрый доступ к редактированию при помощи ИИ и визуальному поиску без необходимости открывать приложение «Фотографии». Теперь достаточно щёлкнуть правой кнопкой мыши изображение в «Проводнике», чтобы добавить форматированный текст, настроить композицию с помощью выбора объекта или улучшить цветопередачу. Ярлык «Стереть объект» позволяет быстро удалить нежелательные элементы. А «Визуальный поиск с помощью Bing» быстро находит похожие изображения и связанные продукты. В галерее приложения «Фотографии» появилась возможность использовать фильтры для настройки отображения содержимого вложенных папок и галерей. Функция «Показать вложенные папки» показывает в галерее все изображения и видео из вложенных папок, что может в некоторых случаях упростить навигацию. В верхней части приложения «Фотографии» добавлена выделенная красным кнопка Copilot, которая при помощи ИИ позволяет:
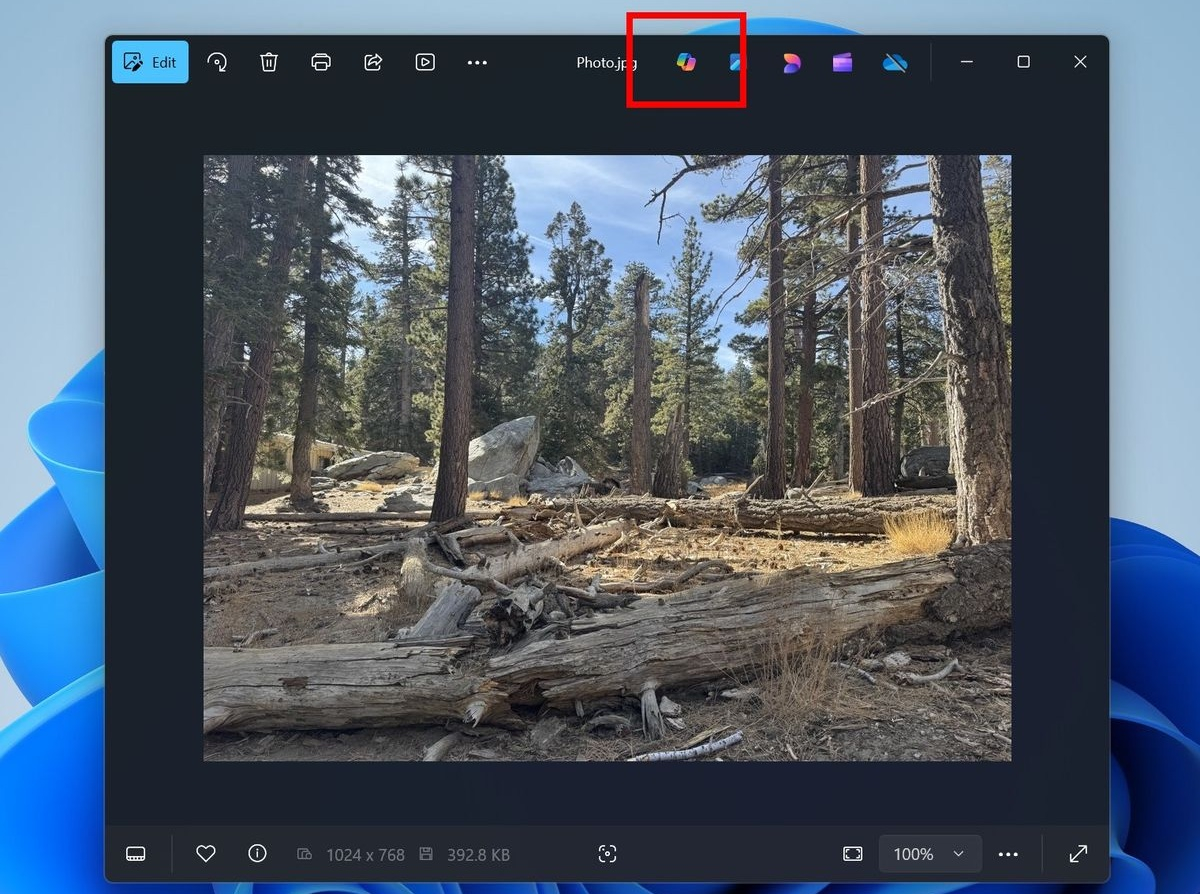 Из других изменений стоит упомянуть добавленную в приложение поддержку файлов формата JXL. Приложение «Фотографии» вряд ли сможет составить конкуренцию таким программным монстрам для редактирования изображений, как Photoshop или CorelDraw, но будет весьма полезным для быстрого внесения незначительных изменений без дополнительных затрат и подписок. Российские специалисты из Smart Engines расшифровали рукописи Пушкина при помощи ИИ
06.02.2025 [17:59],
Сергей Сурабекянц
Специалисты российской компании Smart Engines расшифровали зачёркнутые фрагменты черновых рукописей Александра Пушкина с помощью разработанной ими системы искусственного интеллекта «Да Винчи». Нейросетевая архитектура «Да Винчи» широко используется для распознавания документов, в частности российских паспортов, вне зависимости от угла и условий съёмки. 
Источник изображения: Wikipedia, «Литературные места России» В процессе обучения ИИ запомнил, какие движения пера в незачёркнутых словах характерны для почерка великого русского поэта, а затем восстановил утраченные места, пользуясь созданной моделью движений его руки. Таким способом удалось идентифицировать несколько неопределяемых ранее слов из черновых рукописей Пушкина. Эти находки внесли существенный вклад в понимание творческого процесса поэта. Узнать, какие слова пришлись Пушкину не по душе, удалось с помощью нейросетевой архитектуры «Да Винчи», разработанной специалистами Smart Engines для удаления линий разграфки, затрудняющих распознавание рукописных данных в официальных документах. Эта технология позволяет автоматически определять геометрию документа и распознавать данные вне зависимости от его расположения в кадре, наличия помех и искажений. Технология одинаково успешно справляется как со сканами, так и с фотографиями документов, в том числе в зеркальном отражении. Алгоритмы Smart Engines уже интегрированы в решения для мгновенного распознавания данных паспорта и других документов. Распознавание паспорта РФ при помощи камеры смартфона требует всего 0,15 секунды. Серверные решения позволяют распознавать до 55 паспортов в секунду на процессор без использования GPU. 
Источник изображения: Smart Engines «Проведённый нами эксперимент по расшифровке ранее нечитаемых слов в рукописях Александра Пушкина подтвердил колоссальный потенциал нейросетей в самых разных областях науки. Мы видим, что искусственный интеллект может стать надёжным инструментом для исследователя […] Предложенный метод снятия зачёркиваний при помощи ИИ может быть применён не только к рукописям Пушкина, но и к архивным записям других известных авторов, а также историческим документам. Это открывает новые возможности для изучения творческого процесса написания знаменитых литературных произведений», — уверен генеральный директор Smart Engines Владимир Арлазаров. Остаётся неясным лишь одно: если великий русский поэт какие-то слова зачёркивал, возможно, он не хотел, чтобы кто-нибудь их прочитал, в том числе и искусственный интеллект? Nvidia представила ИИ-модель Fugatto, которая «понимает и генерирует звук, как это делают люди»
25.11.2024 [18:33],
Сергей Сурабекянц
Nvidia представила новую экспериментальную генеративную модель ИИ, которую компания описывает как «швейцарский армейский нож для звука». Модель Fugatto (Foundational Generative Audio Transformer Opus 1) использует текстовые подсказки для генерации новых или изменения существующих музыкальных, голосовых и звуковых файлов. В создании модели принимали участие разработчики со всего мира, что усилило «многоакцентные и многоязычные возможности модели». 
Источник изображения: Nvidia «Мы хотели создать модель, которая понимает и генерирует звук, как это делают люди», — рассказал участник проекта и менеджер по прикладным исследованиям звука в Nvidia Рафаэль Валле (Rafael Valle). Компания предложила несколько сценариев, в которых модель Fugatto может оказаться востребованной:
Исследователи утверждают, что модель при некоторой дополнительной тонкой настройке также может выполнять задачи, не входившие в её предварительное обучение. Модель может объединять отдельные инструкции, например, генерировать речь с определёнными интонациями и акцентом или звук пения птиц во время грозы. Модель также умеет генерировать изменяющиеся со временем звуки, например, шум приближающегося ливня или удаляющегося поезда. Fugatto не является первой технологией генеративного ИИ, которая может создавать звуки из текстовых подсказок. Ранее Meta✴ выпустила аналогичную модель ИИ с открытым исходным кодом. Google предлагает ИИ-инструмент собственной разработки для преобразования текста в музыку MusicLM, доступ к которому можно получить через сайт компании AI Test Kitchen. Nvidia пока не предоставила публичный доступ к Fugatto и воздержалась от комментариев на этот счёт. «Сбер» запустил GigaChek — детектор текстов, написанных ИИ
28.06.2024 [12:05],
Павел Котов
«Сбер» представил технологию GigaChek, которая помогает определять происхождение текста: был ли он написан человеком или сгенерирован искусственным интеллектом. Опробовать решение можно в демо-версии службы на сайте или через чат-бот в Telegram. 
Источник изображения: sber.ru Сервис, помогающий определить происхождение текста, окажется полезным при проверке дипломов, диссертаций и других научных работ; им смогут пользоваться редакторы, которые принимают работу копирайтеров и писателей; а владельцы пабликов смогут выявить написанные нейросетями комментарии. Пока текст оценивается на основе контента, который в нём преобладает. В перспективе технология будет усовершенствована и позволит осуществлять интервальный поиск — такая возможность должна появиться в обозримом будущем. «Задача нашей технологии — иметь такой уровень качества работы, что для обхода текст придётся исказить до степени неприменимости в реальных задачах. Например, диплом с разбросанными символами „;“ просто не пройдёт нормоконтроль, а такой комментарий в паблике сразу будет выделяться», — рассказали в «Сбере». Когда новый сервис будет официально запущен, компания подготовит инструменты API, которые помогут интегрировать технологию. Рукописи не горят: ИИ прочитал испорченные извержением вулкана свитки из древнеримской библиотеки
06.02.2024 [13:52],
Геннадий Детинич
Благодаря машинному обучению археология совершила рывок вперёд. С помощью ИИ разработан метод чтения сожжённых или иным образом повреждённых свитков папируса. Таких документов множество, и находятся всё новые и новые. Технологию ещё предстоит доработать, однако первые результаты оказались успешными. 
Внешний вид обугленного свитка, который был прочитан с помощью ИИ (источник изображения: scrollprize.org) Ещё в 18 веке при раскопках римской виллы в Геркулануме было обнаружено более 1000 целых или частичных свитков в особняке, который, как считалось, принадлежал тестю Юлия Цезаря. Извержение Везувия в 79 году н.э. и последующее погребение свитков землёй превратили их в обугленные останки, развернуть которые можно было только один раз — они при этом рассыпались. Тексты также были нечитаемые, поскольку чернила выгорели вместе с основой. Прочесть всё это и многое другое — это достойно усилий. Попытки создать технологию для прочтения обугленных свитков из Геркуланума много лет возглавлял специалист по информатике из Университета Кентукки Брент Силз (Brent Seales). Он и его команда с помощью рентгеновской томографии на ускорительном комплексе Diamond Light Source — источнике синхротронного излучения третьего поколения в графстве Оксфордшир — научились распознавать следы чернил в волокнах папируса, не трогая и не разрушая свиток. Но распознать чернила — это только начало. Необходимо было «развернуть» свиток и прочитать текст. Для этого в 2023 году на деньги спонсоров был объявлен конкурс Vesuvius Challenge с призом около $1 млн. К концу года начали определяться лидеры. В частности, студент факультета компьютерных наук в Университете Небраски в Линкольне Люк Фарритор (Luke Farritor) был объявлен победителем этапа «Первые буквы» за расшифровку первых связных фраз из сожжённого текста, за что получил $40 тыс. Позже к Фарритору присоединились Юсеф Надер (Youssef Nader) из Германии и Джулиан Шиллигер (Julian Schilliger) из Швейцарии. Они разработали алгоритм «разворачивания» свитков. Все вместе они смогли прочесть более 2000 букв из свитка. Как стало известно на днях, приз в размере $700 тыс. ушёл этой команде. Искусственный интеллект справляется с задачей в несколько этапов. Свиток разбивается на сектора с определением каждого слоя. Предложено несколько способов решить эту головоломку. Например, ИИ отслеживает паутинку трещин в каждом слое, что позволяет точно определить слой и потом выровнять его цифровую копию. Пожалуй, это самая сложная часть работы. Распознавание букв греческого алфавита также происходит не напрямую из текста, что важно для подтверждения опыта команды сторонними группами исследователей. Все данные берутся из базы, полученной рентгеновской томографией, а не с помощью программ по оптическому распознаванию символов. Немаловажно и то, что предложенный группой победителей конкурса код открыт и может быть использован другими группами для проверки результатов. И они были подтверждены. ИИ на самом деле восстанавливает текст по обнаруженным остаткам чернил в волокнах свитков. Технология далека от совершенства, но её возможности обещают привнести множество нового в наши знания о прошлом. Она может быть применена также к прочтению текстов папирусов, в которые заворачивали мумии. Этих папирусов груды в каждом приличном музее, а это кладезь информации о жизни тысячи лет назад. Искусственный интеллект скоро сможет правдоподобно имитировать почерк человека
16.01.2024 [10:17],
Алексей Разин
Уже сейчас нейросети способны правдоподобно воссоздавать голос человека и имитировать его мимику в соответствии с якобы произносимым текстом. Как считают учёные, вскоре искусственному интеллекту будут по плечу и задачи правдоподобного воспроизведения почерка человека, для этого нейросетям будет достаточно ознакомиться лишь с несколькими абзацами «исходного материала». 
Источник изображения: Unsplash, Hannah Olinger Команде специалистов Университета искусственного интеллекта имени Мухаммеда бен Заида в ОАЭ, как сообщает Bloomberg, уже удалось создать профильную нейросеть и опробовать её в деле. Эту разработку авторам даже удалось запатентовать в юрисдикции США. Пока использование данной нейросети сторонними клиентами не подразумевается, и авторы разработки уже выражают опасения по поводу способности недобросовестных пользователей применять её во вред обществу. Прежде чем этот инструмент начнёт распространяться, по мнению разработчиков, необходимо создать защитные механизмы, предотвращающие его некорректное с этической точки зрения применение. «Это всё равно что создать антивирус для вируса», — пояснили представители университета. Подобные соображения не мешают создателям нейросети планировать её коммерческое применение в течение ближайших месяцев, они уже ищут партнёров для реализации сопутствующего потенциала данной технологии. Помимо прочего, такая система могла бы распознавать рукописный текст — например, для обработки записей в историях болезни пациентов. На генерируемых нейросетью рукописях можно было бы обучать другие подобные системы. Пока нейросеть способна распознавать и генерировать рукописный текст на английском и французском языках, но в перспективе разработчики хотели бы добавить к ним и арабский. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться