|
Опрос
|
реклама
Быстрый переход
Nvidia представила видеокарты с 96 Гбайт GDDR7 — профессиональные RTX Pro Blackwell для серверов, ПК и ноутбуков
18.03.2025 [23:16],
Николай Хижняк
Компания Nvidia представила новые профессиональные настольные и мобильные видеокарты серии Nvidia RTX Pro на архитектуре Blackwell для рабочих станций и серверов. Эти решения предназначены для различных задач, включая работу с агентными ИИ, моделированием, дополненной реальностью, 3D-дизайном, сложными визуальными эффектами, а также разработку ИИ для робототехники и транспортных средств. 
Источник изображений: Nvidia Для дата-центров компания подготовила ускоритель Nvidia RTX Pro 6000 Blackwell Server Edition, построенный на чипе GB202 в полной конфигурации с 24 064 ядрами CUDA, который дополняют 96 Гбайт памяти GDDR7.  Nvidia RTX Pro 6000 Blackwell Server Edition Для настольных систем представлены модели Nvidia RTX Pro 6000 Blackwell Workstation Edition, Nvidia RTX Pro 6000 Blackwell Max-Q Workstation Edition, Nvidia RTX Pro 5000 Blackwell, Nvidia RTX Pro 4500 Blackwell и Nvidia RTX Pro 4000 Blackwell. Видеокарты RTX Pro 6000 предлагают те же характеристики, что и серверная версия, а версия Max-Q отличается от обычной вдвое меньшим энергопотреблением. Остальные карты предлагают более скромные характеристики, от 8960 CUDA и 24 Гбайт памяти до 14 080 CUDA и 48 Гбайт памяти. 
Nvidia RTX Pro 6000 Blackwell Workstation Edition
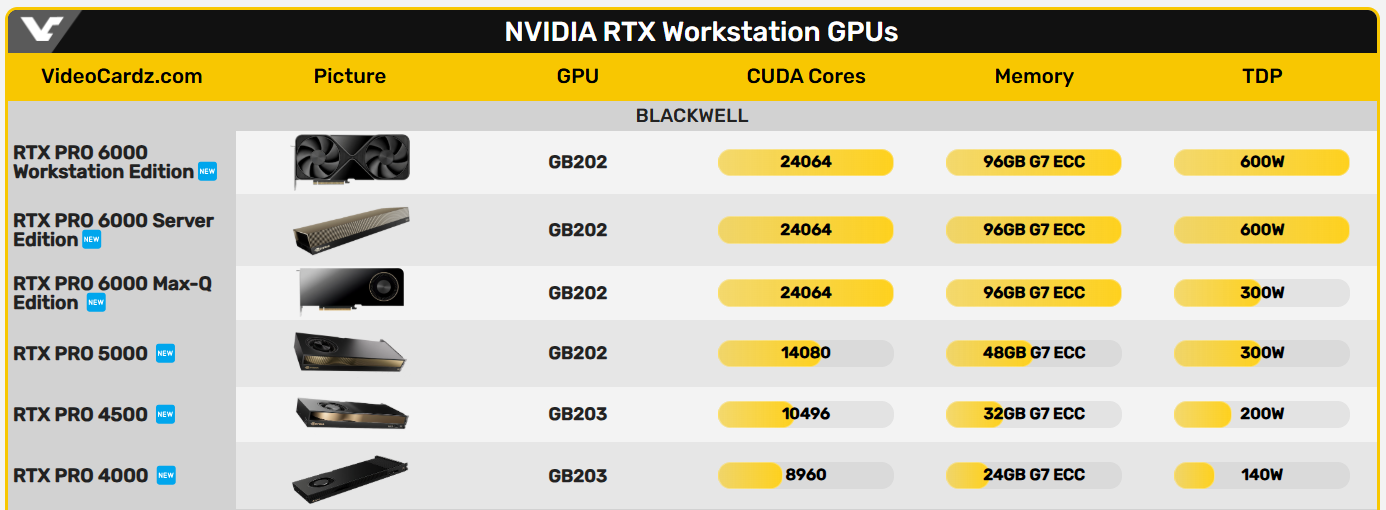 Для мобильных рабочих станций анонсированы видеокарты Nvidia RTX Pro 5000 Blackwell, Nvidia RTX Pro 4000 Blackwell, Nvidia RTX Pro 3000 Blackwell, Nvidia RTX Pro 2000 Blackwell, Nvidia RTX Pro 1000 Blackwell и Nvidia RTX Pro 500 Blackwell. Они предлагают от 6 до 24 Гбайт памяти GDDR7 и графические процессоры поколения Blackwell, которые насчитывают от 1792 до 10 496 ядеро CUDA. 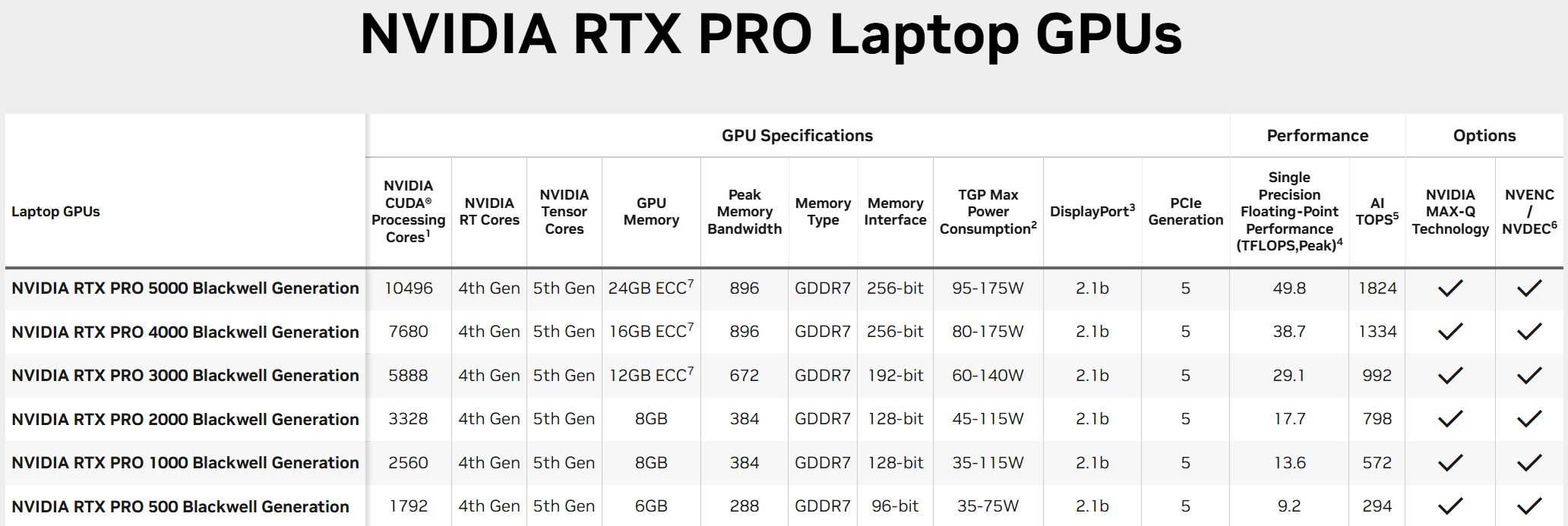 Новые ускорители Nvidia RTX Pro Blackwell обладают рядом преимуществ. Потоковые мультипроцессоры Nvidia обеспечивают до 1,5 раза более высокую пропускную способность и включают новые нейронные шейдеры. Четвёртое поколение RT-ядер обеспечивает двукратный прирост производительности при рендеринге фотореалистичных сцен и сложных 3D-проектов, оптимизированных под Nvidia RTX Mega Geometry. Четвёртое поколение тензорных ядер выполняет до 4000 триллионов ИИ-операций в секунду, поддерживает вычисления FP4 и работу технологии Nvidia DLSS 4 Multi Frame Generation. Ускорители оснащены аппаратным многопоточным кодировщиком Nvidia NVENC девятого поколения с поддержкой кодирования 4:2:2, а также кодировщиком шестого поколения для декодирования 4:2:2 H.264 и HEVC.  Все модели поддерживают интерфейс PCIe 5.0, DisplayPort 2.1 с разрешением до 4K@180 Гц или 8K@165 Гц, а также технологию Multi-Instance GPU (MIG), позволяющую разделять один GPU на четыре независимых виртуальных графических процессора, что вдвое больше по сравнению с предыдущими моделями.  Первые тестирования показали высокую эффективность новинок. Компания Foster + Partners отметила пятикратный рост производительности в среде проектирования Cyclops по сравнению с Nvidia RTX A6000. GE HealthCare зафиксировала двукратный прирост эффективности в обработке алгоритмов реконструкции. SoftServe заявила, что 96 Гбайт памяти у Nvidia RTX Pro Workstation Edition увеличивают продуктивность при работе с Llama 3.3-70B, Mistral 8x7b и платформой Nvidia Omniverse в три раза. 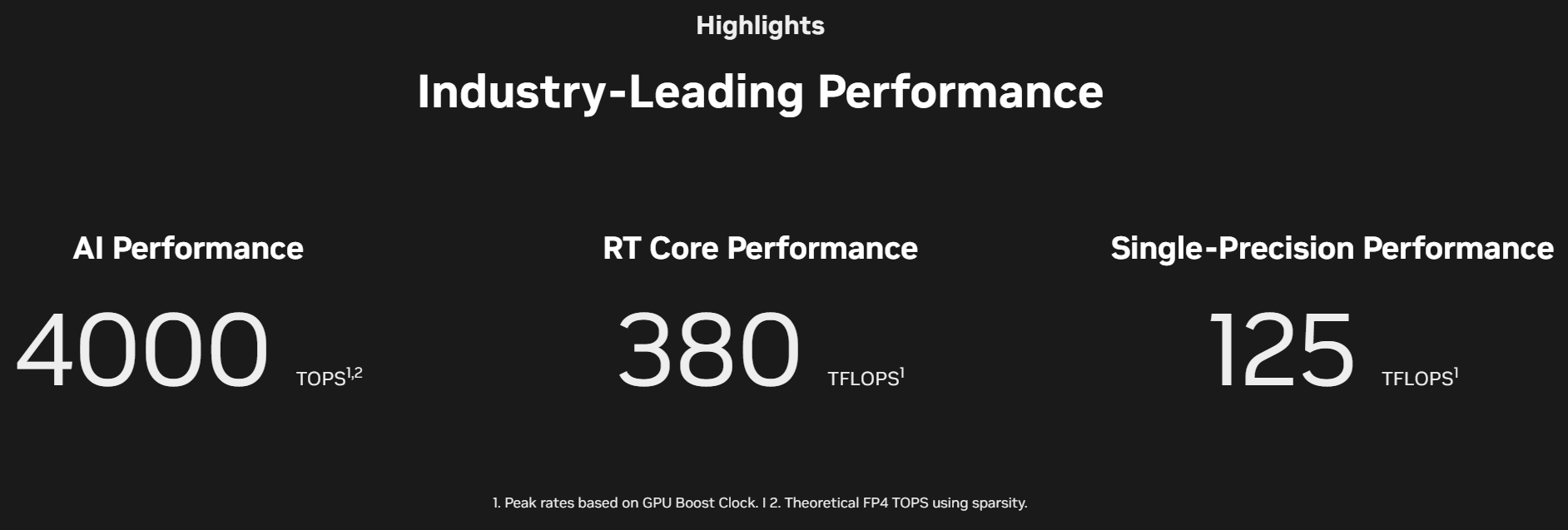 Профессиональные ускорители Nvidia RTX Pro 6000 Blackwell Workstation Edition и Nvidia RTX Pro 6000 Blackwell Max-Q Workstation Edition поступят в продажу через глобальных партнёров-дистрибьюторов, таких как PNY и TD SYNNEX, в апреле. В мае они появятся у BOXX, Dell, HP Inc., Lambda и Lenovo. Модели Nvidia RTX Pro 5000, RTX Pro 4500 и RTX Pro 4000 Blackwell поступят в продажу летом в магазинах BOXX, Dell, HP и Lenovo, а также через глобальных партнеров-дистрибьюторов. Профессиональные ускорители Nvidia RTX Pro для ноутбуков ожидаются в ассортименте компаний Dell, HP, Lenovo и Razer позже в этом году. OpenAI завершит разработку и запустит производство своего ИИ-чипа уже в 2025 году — это первый шаг к снижению зависимости от Nvidia
10.02.2025 [17:54],
Сергей Сурабекянц
Признанный лидер в сфере ИИ, компания OpenAI, прикладывает серьёзные усилия по снижению зависимости от ускорителей ИИ производства Nvidia. В ближайшие несколько месяцев OpenAI планирует завершить разработку собственного чипа и начать его производство на фабриках TSMC с использованием самых передовых техпроцессов. 
Источник изображения: Samsung По мнению аналитиков, «OpenAI находится на пути к достижению своей амбициозной цели массового производства на мощностях TSMC в 2026 году». Наиболее ответственным этапом на пути от дизайна к выпуску готовых чипов является Tape-out («тейпаут») — процесс переноса цифрового проекта чипа на фотошаблон для последующего производства. Обычно этот этап обходится в несколько десятков миллионов долларов, а до выпуска первого чипа проходит до шести месяцев. В случае сбоя требуется диагностировать проблему и повторить процесс. OpenAI рассматривает свой будущий ускоритель ИИ как стратегический инструмент для укрепления переговорных позиций с другими поставщиками чипов. Если первоначальный выпуск пройдёт удачно, OpenAI уже в этом году представит альтернативу чипам Nvidia, которые сейчас занимают более80 % рынка ИИ-ускорителей. В случае успеха первого чипа инженеры OpenAI планируют разрабатывать все более продвинутые процессоры с более широкими возможностями с каждой новой итерацией. Компания уже стала участником инфраструктурной программы Stargate стоимостью $500 млрд, объявленной президентом США Дональдом Трампом (Donald Trump) в прошлом месяце. Чип разрабатывается внутренней командой OpenAI во главе с Ричардом Хо (Richard Ho) в сотрудничестве с Broadcom. Хо более года назад перешёл в OpenAI из Google, где руководил программой по созданию специализированных чипов ИИ. Хотя команда Хо за последние месяцы выросла до 40 сотрудников, это количество по прежнему на порядок меньше, чем в масштабных проектах таких технологических гигантов, как Google или Amazon. Аналитики полагают, что на первом этапе новый ускоритель ИИ от OpenAI будет играть ограниченную роль в инфраструктуре компании. Чтобы создать столь же всеобъемлющую программу по проектированию чипов ИИ, как у Google или Amazon, OpenAI придётся нанять сотни инженеров. Согласно отраслевым источникам, новый дизайн чипа для амбициозной масштабной программы может обойтись в $500 млн. Эти расходы могут удвоиться, если учитывать необходимость создания программного обеспечения и периферийных устройств. Для сравнения: в 2025 году Meta✴ планирует потратить $60 млрд на ИИ-инфраструктуру, а годовые инвестиции Microsoft в этом направлении составят $80 млрд. Низкопробный софт AMD не даёт раскрыть потенциал ИИ-ускорителей Instinct MI300X и обойти Nvidia, выяснили эксперты
23.12.2024 [23:11],
Николай Хижняк
Пятимесячное расследование компании SemiAnalysis показало, что специализированные ИИ-ускорители серии AMD MI300X не раскрывают свой потенциал из-за серьёзных проблем в работе программного обеспечения. Этот факт делает все усилия компании по навязыванию жёсткой конкуренции Nvidia, доминирующей на рынке аппаратного обеспечения для ИИ, бессмысленными. 
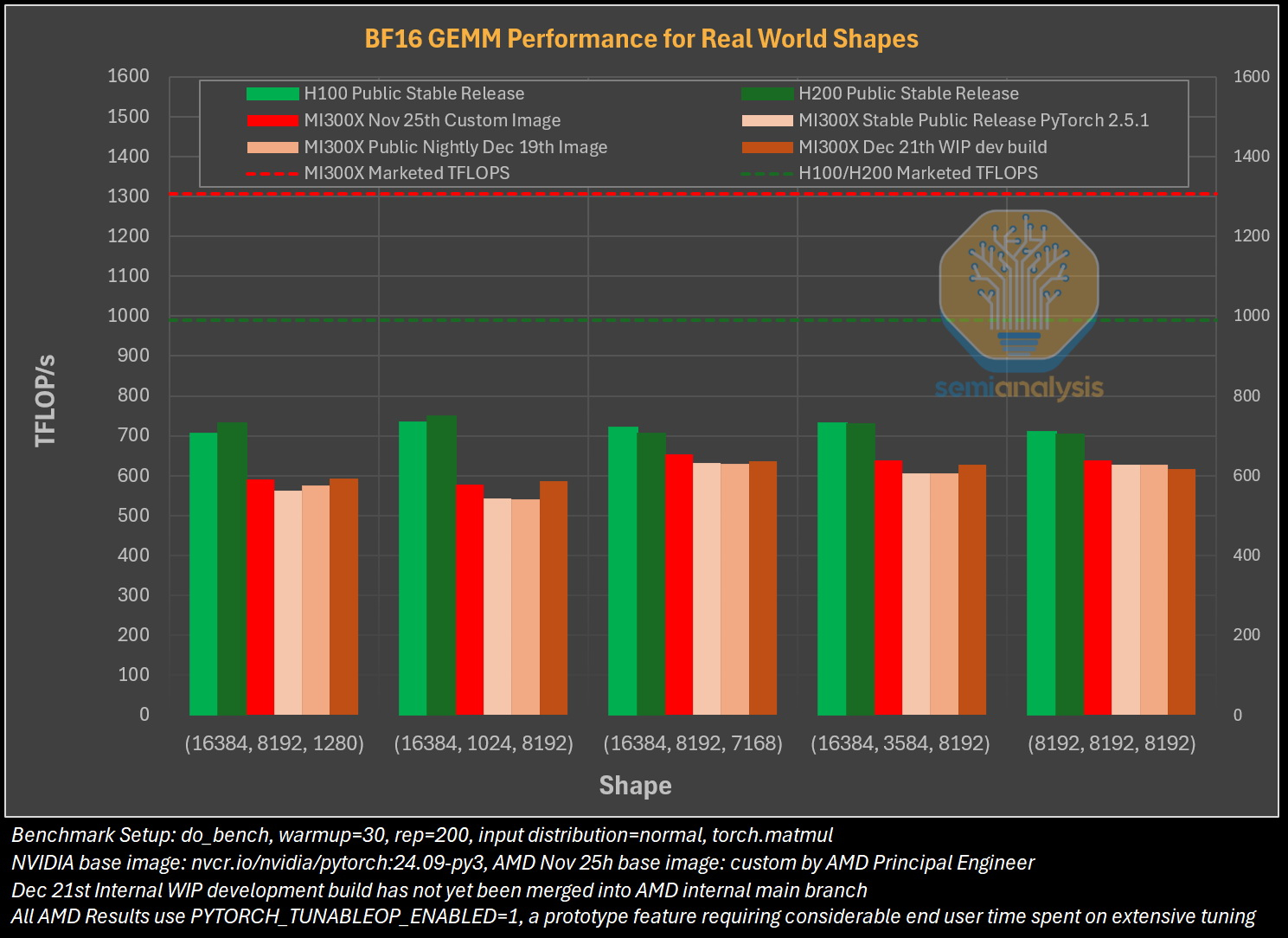
Источник изображения: The Decoder Исследование показало, что программное обеспечение AMD изобилует ошибками, которые делают обучение моделей ИИ практически невозможным без значительной отладки. Таким образом, пока AMD работает над обеспечением качества и простоты использования своих ускорителей, Nvidia продолжает увеличивать разрыв, развёртывая новые функции, библиотеки и повышая производительность своих решений. По итогам обширных тестов, включая тесты GEMM и одноузловое обучение, исследователи пришли к выводу, что AMD не в состоянии преодолеть то, что они называют «неприступным рвом CUDA» — сильное преимущество в виде программного обеспечения, которым обладают ускорители Nvidia. 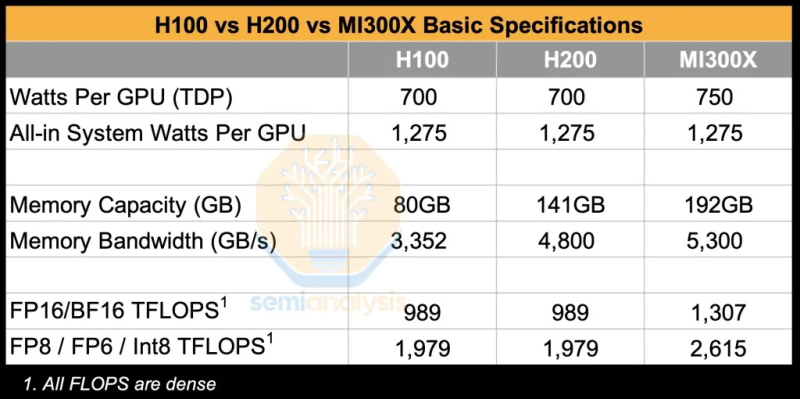
Источник изображения: SemiAnalysis AMD MI300X «на бумаге» выглядят впечатляюще: 1307 Тфлопс в вычислениях FP16 и 192 Гбайт памяти HBM3. Для сравнения, ускорители Nvidia H100 обладают производительностью 989 Тфлопс и имеют только 80 Гбайт памяти. Однако новое поколение ИИ-ускорителей Nvidia H200 с конфигурациями до 141 Гбайт памяти сокращает разрыв в объёме доступного буфера памяти. Кроме того, системы на базе ускорителей AMD также предлагают более низкую общую стоимость владения благодаря более низким ценам на такие системы и более доступной поддержке сетевой инфраструктуры. 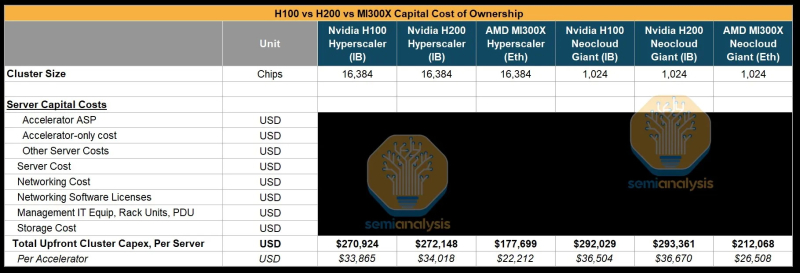
Источник изображения: SemiAnalysis Однако эти преимущества мало что значат на практике. По данным SemiAnalysis, сравнение «голых» спецификаций похоже на «сравнение камер, когда просто проверяешь количество мегапикселей у одной и другой». AMD, отмечают аналитики, таким образом «просто играет с цифрами», но её решения не обеспечивают достаточный уровень производительности в реальных задачах. 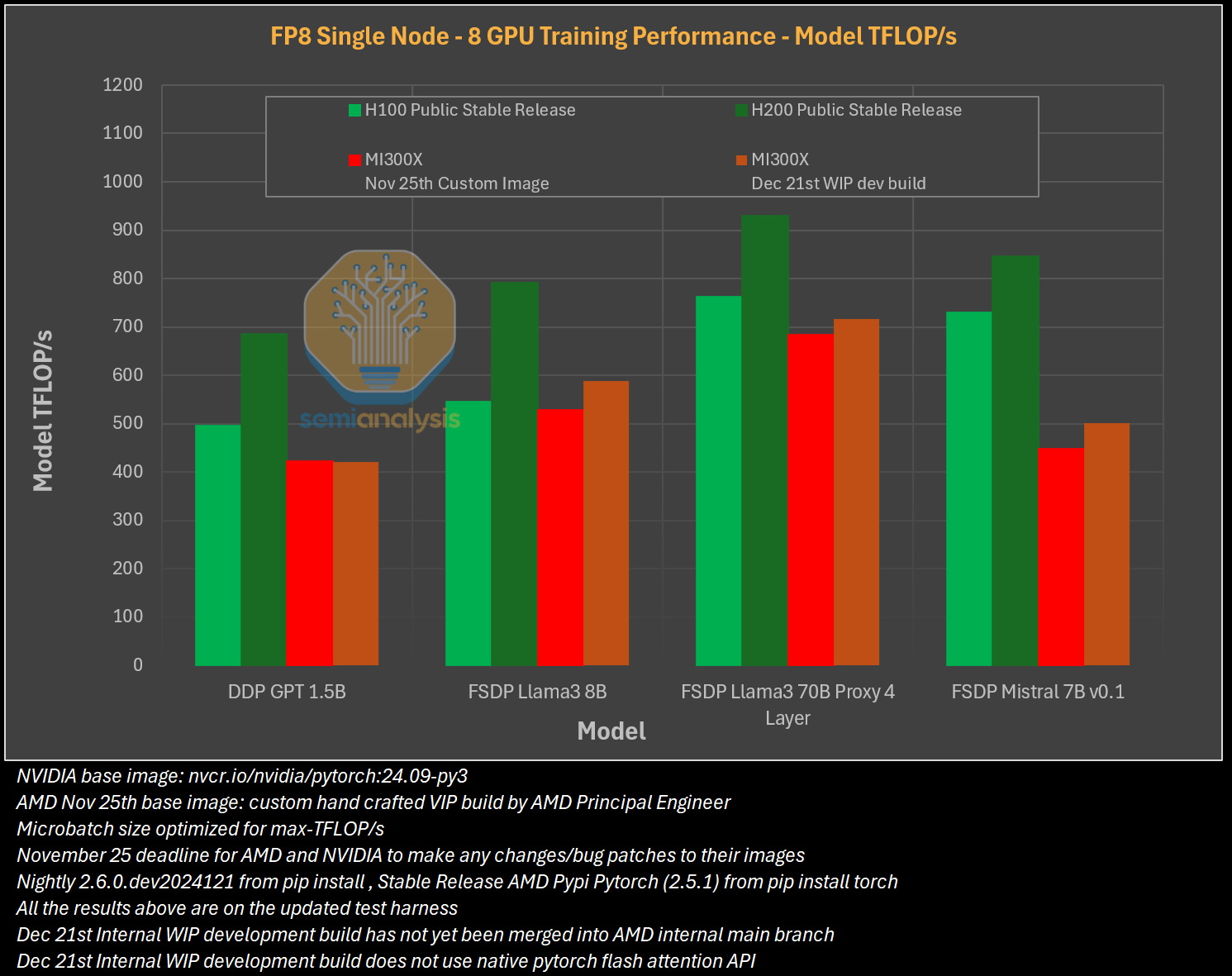
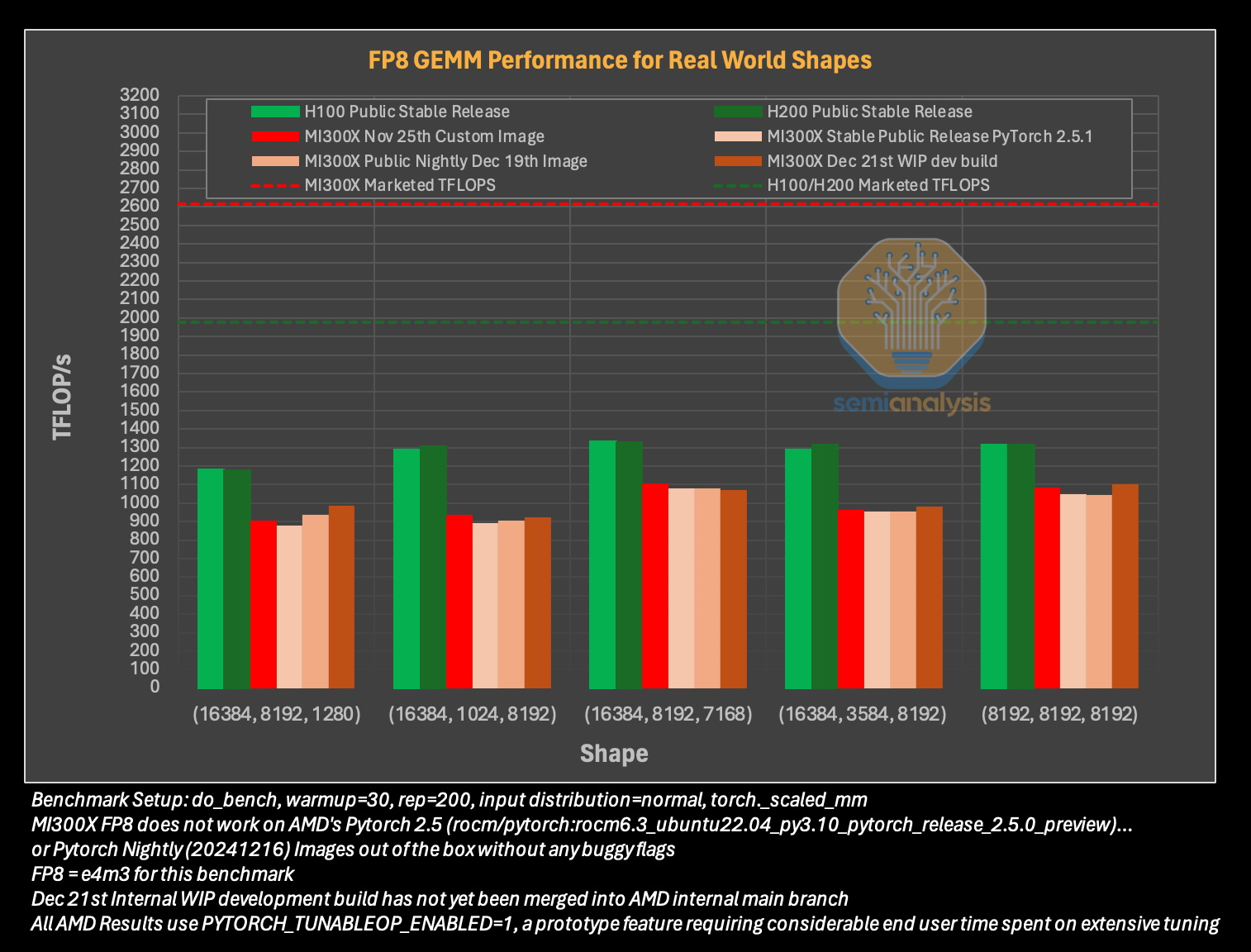 Исследователи отмечают, что им пришлось напрямую работать с инженерами AMD, чтобы исправить многочисленные ошибки в ПО для получения пригодных для оценки результатов тестов. В то же время системы на базе ускорителей Nvidia работали гладко и без каких-либо дополнительных настроек. «С OOBE от AMD (опыт, который пользователь получает при получении продукта после распаковки или при запуске установщика и подготовке к первому использованию, так называемый "опыт из коробки" — прим. ред.) очень сложно работать. И для перехода к пригодному к использованию состоянию [оборудования] может потребоваться немало терпения и усилий», — пишут эксперты. 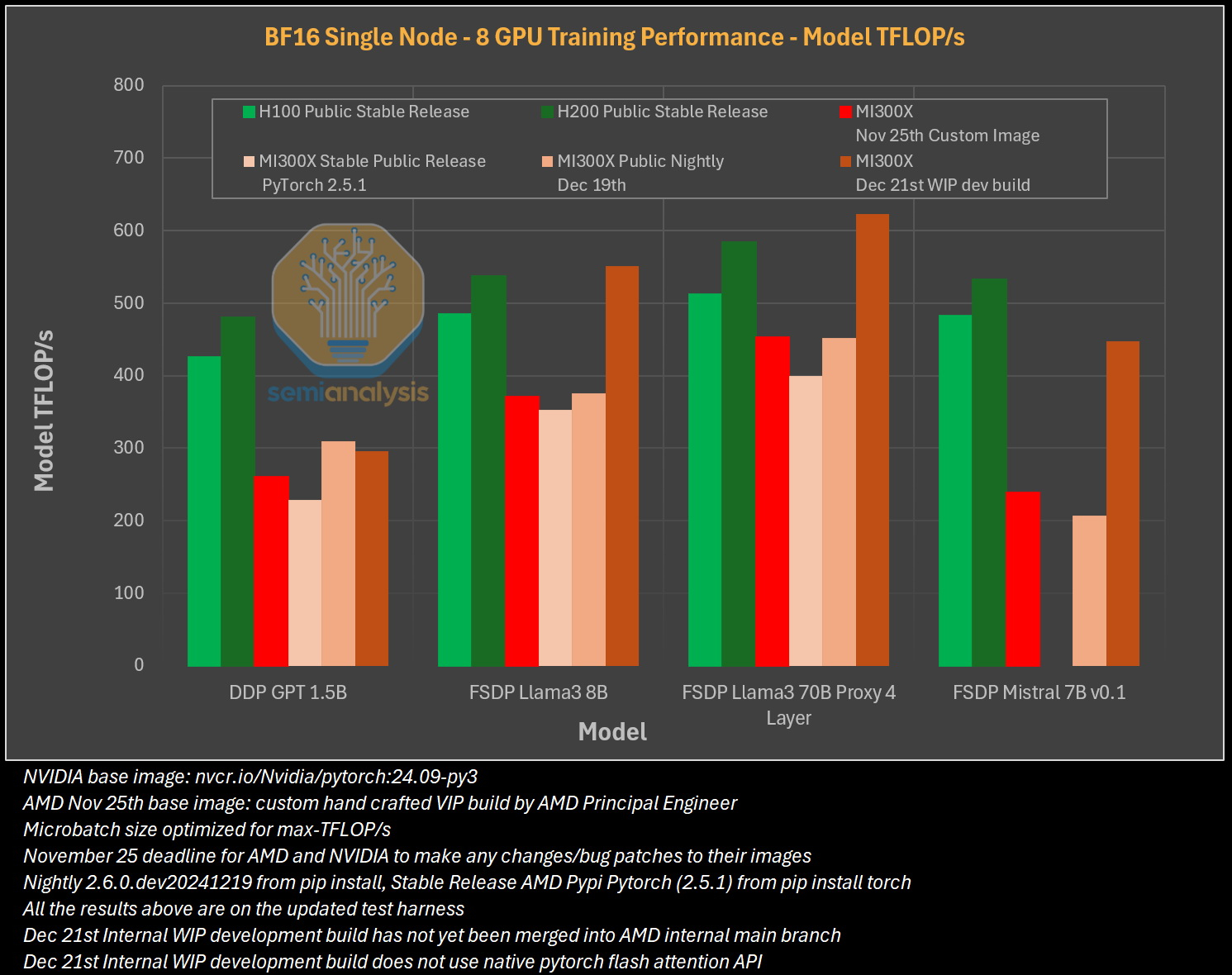
 Особенно показательным для SemiAnalysis оказался случай, когда компания TensorWave, крупнейший поставщик облачных решений на базе графических процессоров AMD, была вынуждена предоставить команде инженеров AMD бесплатный доступ к своим графическим процессорам — тому же оборудованию, которое TensorWave приобрела у AMD — только для устранения проблем с программным обеспечением. Для решения проблем эксперты SemiAnalysis рекомендуют генеральному директору AMD Лизе Су (Lisa Su) более активно инвестировать в разработку и тестирование программного обеспечения. В частности, они предлагают выделить тысячи чипов MI300X для автоматизированного тестирования (аналогичному подходу следует Nvidia для своих ускорителей), упростить сложные переменные среды, одновременно внедрив более эффективные настройки для ускорителей по умолчанию. «Сделайте готовый опыт пригодным к использованию!» — призывают специалисты. Представители SemiAnalysis в своём отчёте признаются, что желают успеха компании AMD в конкуренции с Nvidia, но отмечают, что «к сожалению, для этого ещё многое предстоит сделать». Без существенных улучшений программного обеспечения AMD рискует ещё больше отстать, поскольку Nvidia готовится к массовому выпуску ускорителей нового поколения Blackwell. Хотя, по сообщениям, этот процесс у Nvidia также проходит не совсем гладко. Временная глава Intel не верит в успех ИИ-ускорителей Falcon Shores, но это «первый шаг в верном направлении»
13.12.2024 [17:48],
Николай Хижняк
Руководство компании Intel не верит, что компания сможет в скором времени составить достойную конкуренцию Nvidia и AMD в сфере ИИ-ускорителей. Во всяком случае, такое впечатление сложилось после недавних комментариев одной из временно исполняющей обязанности руководителя компании Мишель Джонстон Холтхаус (Michell Johnston Holthaus) на 22-й ежегодной глобальной технологической конференции Barclays. 
Источник изображений: Intel Напомним, Intel разрабатывает ускорители вычислений Falcon Shores, в основу которого будет положен графический процессор, заточенный под высокопроизводительные вычислений и задачи ЦОД, а дополнят GPU элементы актуальных ИИ-ускорителей Gaudi. Проект по разработке данного решения получил неожиданную оценку от Холтхаус: «Нам действительно нужно подумать о том, как перейти от Gaudi к нашему первому поколению GPU Falcon Shores. Будет ли новый продукт удивительным? Нет, не будет. Но он станет первым шагом в верном направлении». Хольтхаус ещё раз подчеркнула новый прагматичный подход Intel к вопросам разработки аппаратных решений для ускорения ИИ, когда затронула тему стратегии развития продуктов: «Если всё бросить и начать создать новый продукт, то его разработка займёт очень много времени. Прежде чем что-то появится потребуется два–три года. Вместо этого я предпочла бы создать что-то в меньших объёмах, научиться чему-то новому, последовательно совершенствуясь, чтобы в конечном итоге добиться поставленных целей». Врио главы Intel признала устойчивый характер возможностей рынка ИИ, акцентировав текущий интерес индустрии к обучению ИИ-моделей. Однако Хольтхаус также подчеркнула потенциал широких возможностей в других областях: «Очевидно, что ИИ никуда не денется. Очевидно, что обучение [ИИ] сегодня находится центре внимания, но есть возможности развития и на других направлениях, где также отмечаются потребности с точки зрения нового аппаратного обеспечения». По всей видимости она подразумевала инференс — запуск уже обученных нейросетей.  Из сказанного можно сделать вывод, что Falcon Shores не станет для Intel чудесным спасательным кругом, который позволит ей наверстать отставание от Nvidia на рынке GPU-ускорителей. Это в большей степени первая ступень к разработке первоклассного продукта в перспективе. Следующим проектом Intel после Falcon Shores должен стать Jaguar Shores. Его выход ожидается в конце 2025 или начале 2026 года в виде ускорителей ИИ и HPC для центров обработки данных. Однако до его появления компании предстоит проделать немало работы по усовершенствованию не только своего аппаратного, но и программного обеспечения. Доминирующе положение Nvidia на рынке ИИ во многом обязано её программно-аппаратной архитектуре CUDA, поскольку конкуренты, например, AMD, предлагают сопоставимую аппаратную производительность. Перед Intel стоит очень непростая задача. Ей предстоит обеспечить разработку экосистемного программного обеспечения и «бесшовную» интеграцию своих ускорителей следующего поколения, чтобы Jaguar Shores имел шансы догнать остальную часть рынка. У Nvidia нашлась ахиллесова пята — треть выручки зависит от настроения трёх клиентов
22.11.2024 [23:17],
Андрей Созинов
Компания Nvidia сильно зависит от горстки крупнейших заказчиков, которые активно покупают ускорители вычислений для задач ИИ и в совокупности приносят компании более трети дохода. Это ставит Nvidia в уязвимое положение, хотя в ближайшее время компании и её инвесторам вряд ли стоит беспокоиться — спрос на ИИ-ускорители только растёт. 
Источник изображений: Nvidia В квартальном отчёте по форме 10-Q, который компании подают в Комиссию по ценным бумагам и биржам США, Nvidia в очередной раз заявила, что у неё есть ключевые клиенты, которые настолько важны, что заказы каждого из них формируют более 10 % от глобальной выручки Nvidia. При этом компания не раскрывает имена этих клиентов, что логично, поскольку вряд ли бы они хотели, чтобы их инвесторы, сотрудники, критики, активисты и конкуренты узнали, сколько именно денег они тратят на чипы Nvidia. В отчёте за второй квартал Nvidia указала четырёх крупнейших клиентов, а в последнем квартале упоминается три таких «кита», поскольку один из них сократил закупки. Хотя доподлинно неизвестно, что это за клиенты, Мандип Сингх (Mandeep Singh), руководитель глобального отдела технологических исследований Bloomberg Intelligence, считает, что речь идёт о Microsoft, Meta✴ и, возможно, Super Micro.  Сама Nvidia называет их просто «клиент A», «клиент B» и «клиент C». Сообща они приобрели товаров и услуг на общую сумму 12,6 миллиарда долларов в третьем финансовом квартале, завершившемся в конце октября. Это более трети от общей выручки Nvidia, которая составила 35,1 миллиарда долларов. Также отмечается, что каждый из «китов» приобрёл товаров и услуг Nvidia на сумму от 10 до 11 миллиардов долларов за первые девять месяцев текущего финансового года. Примечательно, что вклад «китов» в выручку оказался равнозначным: на каждого пришлось по 12 %, что говорит о том, что они, скорее всего, закупили максимальное количество выделенных им чипов, но не столько, сколько им хотелось бы в идеале. Это согласуется с комментариями генерального директора Дженсена Хуанга (Jensen Huang) о том, что Nvidia ограничена в поставках. Компания не может просто производить больше чипов, поскольку она сама их не выпускает, а заказывает производство у TSMC, мощности которой расписаны на годы вперёд. Поскольку имена крупнейших покупателей чипов Nvidia засекречены, трудно сказать, являются ли они «посредниками», как Super Micro Computer, которая выпускает серверы для центров обработки данных, или конечными пользователями, как Microsoft, Meta✴ или xAI Илона Маска (Elon Musk). Последняя, например, практически из ниоткуда построила мощнейший ИИ-суперкомпьютер всего за три месяца.  Тем не менее полагаться на горстку крупных клиентов весьма рискованно — если кто-то из них, а ещё хуже, все разом, перестанут закупать ИИ-чипы, у Nvidia резко упадёт выручка. К счастью для инвесторов Nvidia, в ближайшее время такое маловероятно. Аналитик Bloomberg Intelligence Мандип Сингх видит лишь несколько долгосрочных рисков для Nvidia. Во-первых, некоторые крупные клиенты, вероятно, со временем сократят заказы в пользу собственных чипов, что приведёт к уменьшению доли компании на рынке. Одним из таких клиентов является Alphabet, у которой есть собственные ИИ-чипы семейства TPU. Во-вторых, Nvidia доминирует в области ускорителей для обучения ИИ, но не может похвастаться тем же в сфере чипов для инференса — запуска уже обученных нейросетей. Для инференса не требуются столь мощные чипы, что означает для Nvidia гораздо большую конкуренцию не только со стороны AMD и других прямых соперников, но и со стороны компаний с собственными чипами, таких как Tesla.  В конечном счёте запуск обученных нейросетей станет гораздо более значимым бизнесом, поскольку всё больше предприятий будут использовать ИИ, считает аналитик. «Многие компании пытаются сфокусироваться на возможностях инференса, потому что для этого не нужен самый мощный GPU-ускоритель», — заявил Сингх. Он также отметил, что в долгосрочной перспективе переход на чипы для инференса является «безусловно» большим риском для Nvidia, чем потеря доли рынка чипов для обучения ИИ. И тем не менее Сингх отмечает, что верит прогнозу Дженсена Хуанга о том, что расходы крупнейших клиентов на ИИ-чипы не прекратятся. Даже если доля Nvidia на рынке ИИ-чипов сократится с нынешних 90 %, компания всё равно сможет ежегодно зарабатывать на этом сотни миллиардов долларов. AMD готовит ответ Nvidia в области нейронного рендеринга для видеоигр
30.10.2024 [06:04],
Анжелла Марина
AMD планирует догнать Nvidia в области технологии трассировки лучей в реальном времени, используя нейронные сети. На данный момент Nvidia доминирует на рынке видеокарт благодаря своим передовым технологиям на основе искусственного интеллекта и машинного обучения, таким как DLSS. AMD пока значительно отстаёт, особенно в потребительском сегменте, однако рассчитывает изменить ситуацию в ближайшее время. 
Источник изображения: PowerColor, Tomshardware.com По информации издания Tom's Hardware, исследования AMD сосредоточены на внедрении трассировки лучей в реальном времени на графических процессорах архитектуры RDNA с помощью нейронных сетей. Разрабатываемая технология направлена на нейронное устранение шумов, возникающих при использовании ограниченного количества лучей в трассировке. Это напоминает подход Nvidia с технологией DLSS 3.5, которая использует восстановление лучей для улучшения изображения при меньшем количестве расчётов. Традиционная трассировка лучей требует огромного количества вычислений — иногда тысячи или десятки тысяч лучей на каждый пиксель, что является стандартом, применяемым в киноиндустрии, где на рендеринг одного кадра могут уходить часы. При трассировке лучей сцена рендерится путём вычисления отражений света, где каждое изменение траектории луча может привести к разной цветовой интерпретации пикселя. Чем больше таких расчётов, тем лучше становится итоговое изображение. Однако для достижения трассировки лучей в реальном времени, что актуально для видеоигр, количество таких расчётов необходимо значительно уменьшить. Но это приведёт к ещё большему появлению шумов в изображениях из-за того, что некоторые лучи часто не достигают определённых пикселей, вызывая неполное освещение сцены. AMD планирует решить этот вопрос с помощью нейронной сети, которая будет устранять эти проблемы и восстанавливать детали сцены, аналогично подходу Nvidia. Собственно инновация AMD заключается в объединении апскейлинга и устранения шума в одной нейронной сети. Как заявляет сама компания, их подход «генерирует высококачественные изображения с устранением шума и суперсемплингом при более высоком разрешении дисплея, чем разрешение рендеринга для трассировки путей в реальном времени». Это позволит выполнять апскейлинг за один проход. Исследования AMD могут привести к созданию новой версии FSR (технология временного масштабирования), которая сможет конкурировать с технологиями Nvidia по производительности и качеству изображения. Однако встаёт вопрос, смогут ли существующие графические процессоры AMD поддерживать нейронные сети для устранения шумов или потребуется новое оборудование? Например, DLSS от Nvidia требует наличия специального ИИ-оборудования на графических процессорах GeForce RTX, а также оптического потокового ускорителя для генерации кадров на GeForce RTX 40-й серии и более поздних моделях. Текущие же графические процессоры AMD в основном не оснащены специальными ускорителями для ИИ, в отличие от Nvidia GeForce RTX, где такие ускорители играют ключевую роль в реализации DLSS. Если AMD сможет реализовать эффективный подход к нейронной трассировке лучей и апскейлингу, это позволит расширить доступ к высококачественной графике на более широком спектре оборудования. Однако учитывая высокие требования к трассировке лучей в современных играх, таких как Alan Wake 2 и Cyberpunk 2077, для достижения высокого уровня качества изображения компании, вероятно, потребуется более мощное оборудование. AMD представила ИИ-ускоритель Instinct MI325X для конкуренции с Nvidia Blackwell и рассказала о ещё более мощном Instinct MI355X
11.10.2024 [08:44],
Анжелла Марина
Компания AMD официально представила флагманский ускоритель вычислений Instinct MI325X, который станет конкурентом для Nvidia Blackwell и уже поступил в производство. Вместе с тем производитель раскрыл подробности об ускорителе следующего поколения — Instinct MI355X на архитектуре CDNA4. 
Источник изображений: AMD В последние годы AMD отмечает значительный рост спроса на свои ИИ-ускорители. При этом серия MI300 пользуется особой популярностью. Однако, как пишет издание Tom's Hardware, MI355X вызывает определённые вопросы по части брендирования, поскольку архитектура CDNA использовалась в MI100, CDNA2 — в MI200, а CDNA3 — в серии MI300. Логично было бы увидеть CDNA4 в ускорителях MI400, но они получат архитектуру следующего поколения.  Как бы от ни было, CDNA4 — это новая архитектура, которая представляет собой значительное обновление прежней CDNA3. AMD описала её как «переосмысление с нуля», хотя, по мнению экспертов, это может быть и некоторым преувеличением. Ускоритель MI355X будет производиться по новому 3-нм техпроцессу N3 от TSMC, потребовав серьёзных изменений по сравнению с N5, но основные элементы дизайна могут остаться схожими с CDNA3. Объём памяти HBM3e достигнет 288 Гбайт. Ускоритель будет оснащён 10 вычислительными элементами на один GPU, а производительность достигнет 2,3 петафлопса вычислительной мощности для операций FP16 и 4,6 петафлопса для FP8, что на 77 % больше по сравнению с ускорителем предыдущего поколения.  Одним из ключевых нововведений MI355X станет поддержка чисел с плавающей запятой FP4 и FP6, которые удвоят вычислительную мощность по сравнению с FP8, позволив достигнуть 9,2 петафлопса производительности в FP4. Для сравнения, Nvidia Blackwell B200 предлагает до 9 Пфлопс производительности в FP4, а более мощная версия GB200 — 10 Пфлопс. Таким образом, AMD Instinct MI355X может стать серьёзным конкурентом для будущих продуктов Nvidia, в том числе благодаря 288 Гбайт памяти HBM3E — это на 50 % больше, чем у Nvidia Blackwell. При этом оба устройства будут иметь пропускную способность памяти до 8 Тбайт/с на GPU.  Как отмечают эксперты, вычислительная мощность и объём памяти — это не единственные ключевые параметры для ИИ-ускорителей. Важным фактором становится масштабируемость систем при использовании большого числа GPU. Пока AMD не раскрыла подробности о возможных изменениях в системе интерконнекта между GPU, что может оказаться важным аспектом в сравнении с Blackwell от Nvidia.  Вместе с анонсом Instinct MI355X компания AMD подтвердила, что ускоритель Instinct MI325X официально запущен в производство и поступит в продажу в этом квартале. Основным отличием MI325X от предыдущей модели MI300X стало увеличение объёма памяти со 192 до 256 Гбайт. Что интересно, изначально планировалось оснастить ускоритель 288 Гбайт памяти, но видимо AMD решили ограничиться приростом в 33 % вместо 50 %. Память HBM3E в новинке обеспечивает пропускную способность более 6 Тбайт/с, что на 13 % больше, чем 5,3 Тбайт/с у MI300X. 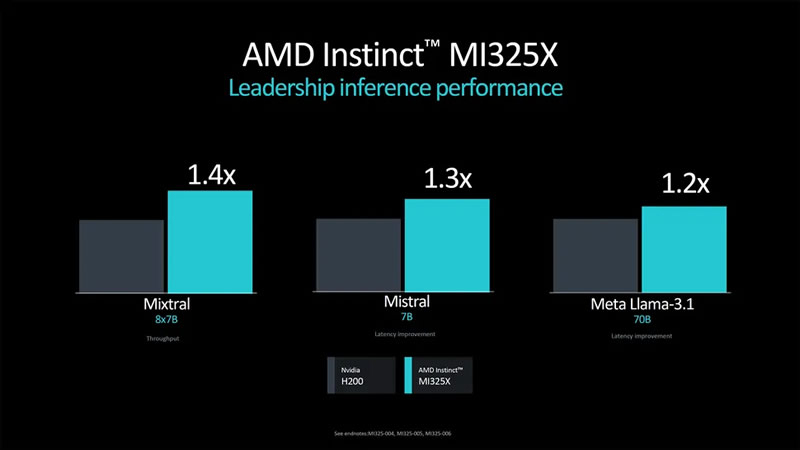 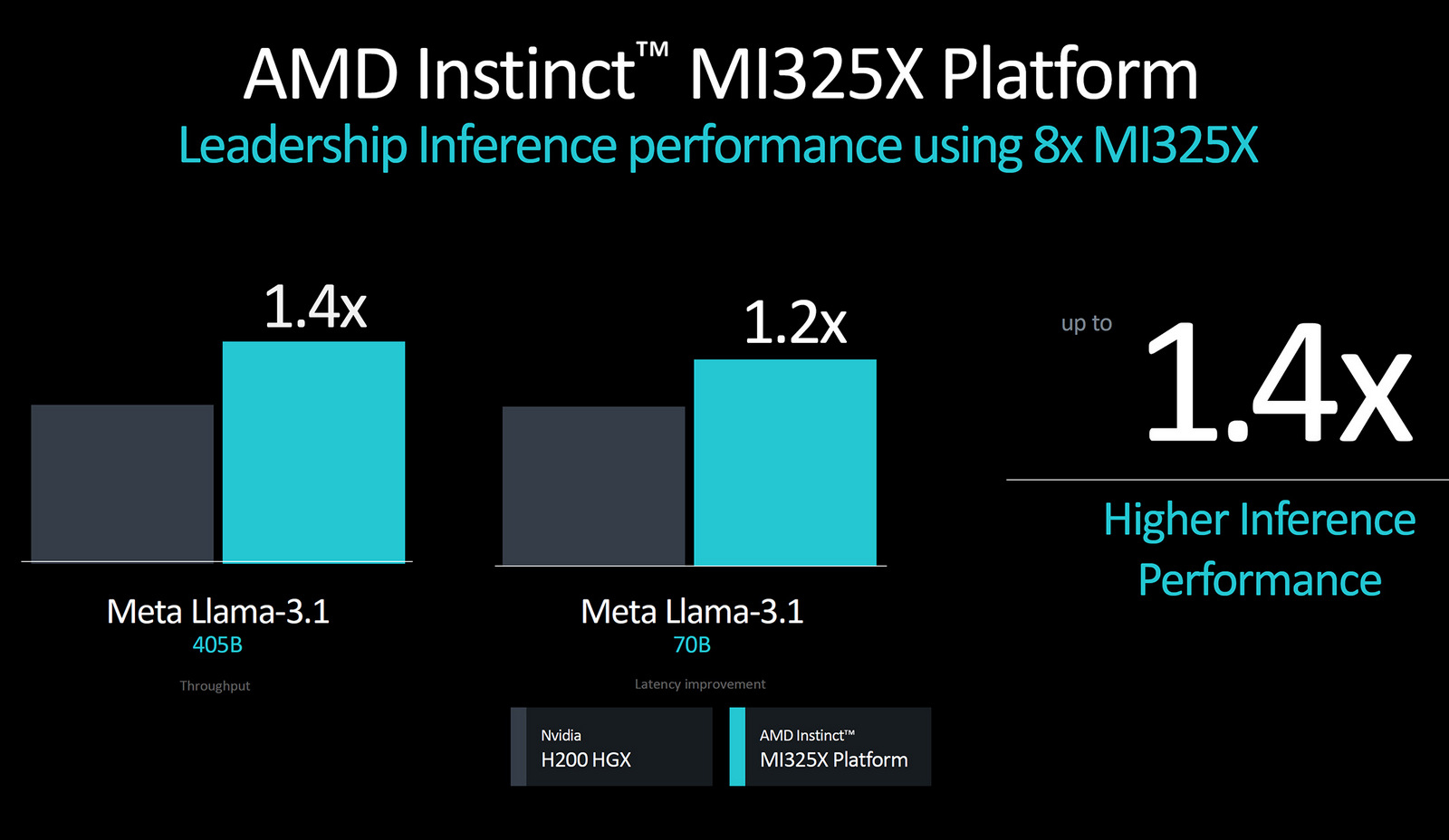 AMD провела сравнительный анализ производительности Instinct MI325X и Nvidia H200. Ускоритель AMD оказался на 20-40 % быстрее конкурента в запуске уже обученных больших языковых моделей, а в обучении нейросетей показал паритет производительности.  AMD не раскрыла стоимость своих ИИ-ускорителей, но представители компании заявили, что одной из целей является предоставление преимущества по совокупной стоимости владения (TCO). Это может быть достигнуто либо за счёт лучшей производительности при той же цене, либо за счёт более низкой цены при одинаковой производительности. Как отметил представитель AMD: «Мы являемся деловыми людьми и будем принимать ответственные решения относительно ценообразования». Instinct MI355X планируется к поставкам во второй половине 2025 года. Дженсен Хуанг: будущее за рассуждающим ИИ, но для этого необходимо в разы удешевить вычисления
09.10.2024 [21:55],
Дмитрий Федоров
Дженсен Хуанг (Jensen Huang), бессменный руководитель Nvidia, заявил, что будущее ИИ — за системами, способными к рассуждению. Однако для реализации этой концепции необходимо значительно снизить стоимость вычислений. Хуанг подчеркнул, что его компания стремится ежегодно увеличивать производительность чипов в 2–3 раза, сохраняя текущий уровень их стоимости и энергопотребления. 
Источник изображения: Nvidia В рамках подкаста, организованного Рене Хаасом (Rene Haas), генеральным директором Arm Holdings, Хуанг поделился своим видением развития ИИ. По его словам, следующее поколение интеллектуальных систем сможет отвечать на запросы пользователей, проходя через сотни или даже тысячи шагов анализа собственных выводов. Эта способность к глубокому рассуждению станет ключевым отличием от современных ИИ, таких как ChatGPT, которым, как признался Хуанг, он пользуется ежедневно. Nvidia стремится создать фундамент для такого прорыва и ставит перед собой амбициозную цель: ежегодно повышать производительность своих чипов в 2–3 раза при сохранении прежнего уровня стоимости и энергопотребления. Такой подход призван революционизировать способность ИИ-систем распознавать сложные паттерны и делать осознанные выводы. «Мы способны обеспечить беспрецедентное снижение затрат на интеллектуальные системы. Все мы осознаём ценность этого достижения. При существенном сокращении расходов мы сможем реализовать на этапе инференса такие сложные процессы, как рассуждение», — подчеркнул Хуанг. Nvidia занимает доминирующую позицию на рынке ускорителей для ИИ, контролируя более 90 % этого сегмента рынка. Однако компания не ограничивается только производством чипов. Её стратегия включает в себя разработку компьютеров, программного обеспечения (ПО), ИИ-моделей, сетевых решений и других сервисов. Такая диверсификация направлена на стимулирование более широкого внедрения ИИ в бизнес-процессы различных компаний. Несмотря на лидирующие позиции, Nvidia сталкивается с растущей конкуренцией. Крупные операторы дата-центров, такие как Amazon Web Services (AWS) и Microsoft, разрабатывают собственные альтернативные решения, чтобы ослабить зависимость от продуктов Nvidia. Кроме того, компания AMD, давний соперник Nvidia на рынке игровых чипов, активно выходит на рынок ИИ-ускорителей, что может усилить конкурентное давление на лидера индустрии. IBM анонсировала 5-нм процессор Telum II и ускоритель Spyre для задач ИИ
27.08.2024 [05:45],
Анжелла Марина
Компания IBM анонсировала новое поколение вычислительных систем для искусственного интеллекта — процессор Telum II и ускоритель IBM Spyre. Оба продукта предназначены для ускорения ИИ и улучшения производительности корпоративных приложений. Telum II предлагает значительные улучшения благодаря увеличенной кеш-памяти и высокопроизводительным ядрам. Ускоритель Spyre дополняет его, обеспечивая ещё более высокие показатели для приложений на основе ИИ. 
Источник изображения: IBM Как сообщается в блоге компании, новый процессор IBM Telum II, разработанный с использованием 5-нанометровой технологии Samsung, будет оснащён восемью высокопроизводительными ядрами, работающими на частоте 5,5 ГГц. Объём кеш-памяти на кристалле получил увеличение на 40 %, при этом виртуальный L3-кеш вырос до 360 Мбайт, а L4-кеш до 2,88 Гбайт. Ещё одним нововведением является интегрированный блок обработки данных (DPU) для ускорения операций ввода-вывода и следующее поколение встроенного ускорителя ИИ. Telum II предлагает значительные улучшения производительности по сравнению с предыдущими поколениями. Встроенный ИИ-ускоритель обеспечивает в четыре раза большую вычислительную мощность, достигая 24 триллионов операций в секунду (TOPS). Архитектура ускорителя оптимизирована для работы с большими языковыми моделями и поддерживает широкий спектр ИИ-моделей для комплексного анализа структурированных и текстовых данных. Кроме того, новый процессор поддерживает тип данных INT8 для повышения эффективности вычислений. При этом на системном уровне Telum II позволяет каждому ядру процессора получать доступ к любому из восьми ИИ-ускорителей в рамках одного модуля, обеспечивая более эффективное распределение нагрузки и достигая общей производительности в 192 TOPS. IBM также представила ускоритель Spyre, разработанный совместно с IBM Research и IBM Infrastructure development. Spyre оснащён 32 ядрами ускорителя ИИ, архитектура которых схожа с архитектурой ускорителя, интегрированного в чип Telum II. Возможность подключения нескольких ускорителей Spyre к подсистеме ввода-вывода IBM Z через PCIe позволяет существенно увеличить доступные ресурсы для ускорения задач искусственного интеллекта. Telum II и Spyre разработаны для поддержки широкого спектра сценариев использования ИИ, включая метод ensemble AI. Этот метод использует преимущества одновременного использования нескольких ИИ-моделей для повышения общей производительности и точности прогнозирования. Примером может служить обнаружение мошенничества со страховыми выплатами, где традиционные нейронные сети успешно сочетаются с большими языковыми моделями для повышения эффективности анализа. Оба продукта были представлены 26 августа на конференции Hot Chips 2024 в Пало-Альто (Калифорния, США). Их выпуск планируется в 2025 году. Etched представила ИИ-чип для нейросетей-трансформеров — он в разы быстрее и дешевле ускорителей Nvidia
25.06.2024 [19:01],
Сергей Сурабекянц
Компания Etched основана два года назад двумя выпускниками Гарварда с целью разработать специализированный ускоритель ИИ. Чипы Etched уникальны тем, что поддерживают лишь один тип моделей ИИ: трансформеры. Эта архитектура, предложенная командой исследователей Google в 2017 году, на сегодняшний день стала доминирующей архитектурой генеративного ИИ. 
Источник изображений: Etched Чип Sohu, разработанный Etched, представляет собой интегральную схему специального назначения (ASIC), изготовленную по 4-нм техпроцессу TSMC. По словам генерального директора компании Гэвина Уберти (Gavin Uberti), новый чип может обеспечить значительно лучшую производительность вывода, чем графические процессоры и другие ИИ-чипы общего назначения, потребляя при этом меньше энергии. «Sohu на порядок быстрее и дешевле, чем даже следующее поколение графических процессоров Nvidia Blackwell GB200 при работе с преобразователями текста, изображений и видео, — утверждает Уберти. — Один сервер Sohu заменяет 160 графических процессоров H100. Sohu станет более доступным, эффективным и экологически чистым вариантом для бизнес-лидеров, которым нужны специализированные чипы».  Эксперты предполагают, что подобных результатов Etched могла добиться при помощи оптимизированного под трансформеры аппаратно-программного конвейера вывода. Это позволило разработчикам отказаться от аппаратных компонентов, нужных для поддержки других платформ и сократить накладные расходы на программное обеспечение. Etched выходит на сцену в переломный момент в гонке инфраструктур генеративного ИИ. Помимо высоких стартовых затрат на оборудование, ускорители вычислений потребляют огромное количество электроэнергии и водных ресурсов. По прогнозам, к 2030 году ИИ-бум приведёт к увеличению спроса на электроэнергию в ЦОД на 160 %, что будет способствовать значительному увеличению выбросов парниковых газов. ЦОД к 2027 году потребуют до 6,5 миллионов кубометров пресной воды для охлаждения серверов.  «Наши будущие клиенты не смогут не перейти на Sohu, — уверен Уберти. — Компании готовы сделать ставку на Etched, потому что скорость и стоимость имеют решающее значение для продуктов искусственного интеллекта, которые они пытаются создать». Похоже, что инвесторы полны оптимизма — Etched на сегодняшний день привлекла финансирование в объёме $125,36 млн. Компания утверждает, что неназванные клиенты уже зарезервировали «десятки миллионов долларов» на приобретение её чипов, а предстоящий запуск Sohu Developer Cloud позволит им предварительно оценить возможности Sohu на интерактивной онлайн площадке. Пока рано говорить о том, будет ли этого достаточно, чтобы продвинуть Etched и её команду из 35 человек в будущее, которым грезят её учредители. Достаточно вспомнить провалы подобных стартапов, таких как Mythic и Graphcore, и обратить внимание на общее снижение инвестиций в предприятия по производству ИИ-чипов в 2023 году. «В 2022 году мы сделали ставку на то, что трансформеры захватят мир, — заявил Уберти. — Мы достигли точки в эволюции искусственного интеллекта, когда специализированные чипы, которые могут работать лучше, чем графические процессоры общего назначения, неизбежны — и лица, принимающие технические решения во всем мире, знают это». 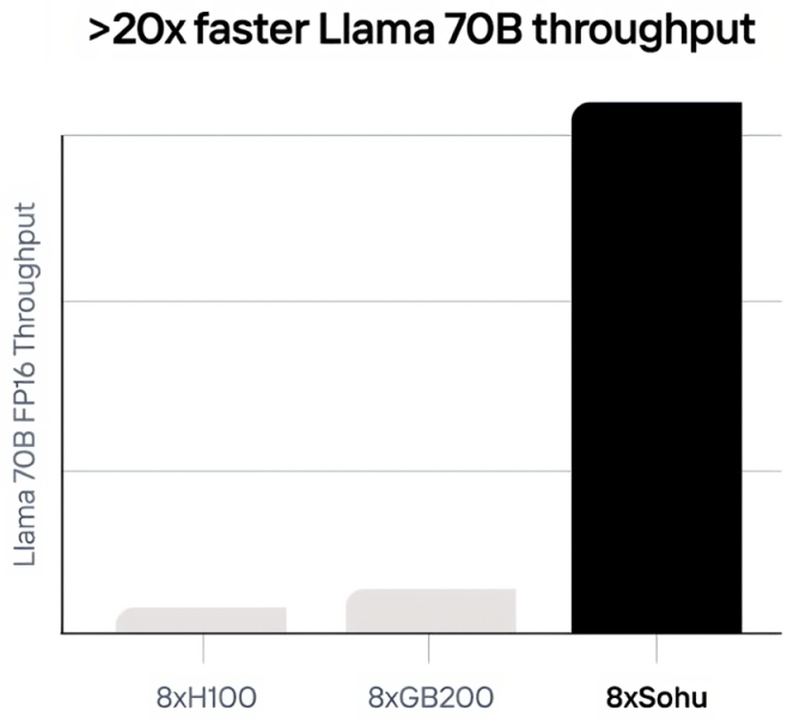 В настоящее время у компании нет прямых конкурентов, хотя стартап по производству ИИ-чипов Perceive недавно анонсировал процессор с аппаратным ускорением для трансформеров, а Groq вложил значительные средства в оптимизацию своих ASIC для конкретных моделей. Nvidia в прошлом году захватила 98 % рынка графических процессоров для ЦОД — поставки достигли 3,76 млн единиц
11.06.2024 [19:58],
Сергей Сурабекянц
Недавний бум искусственного интеллекта озолотил Nvidia. В 2023 году компания поставила 3,76 миллиона графических процессоров для ЦОД, что на миллион больше, чем годом ранее, показав рост продаж на 42 %. Выручка Nvidia за 2023 год достигла $60,9 млрд, на 126 % превысив аналогичный показатель 2022 года. 
Источник изображений: Nvidia По результатам 2023 года Nvidia захватила 98 % рынка графических процессоров для центров обработки данных и 88 % рынка графических процессоров для настольных ПК. Такие результаты компания продемонстрировала несмотря на нехватку в 2023 году производственных мощностей TSMC, выпускающей чипы для Nvidia, и невзирая на запрет США на экспорт передовых чипов Nvidia в Китай. Однако Nvidia не может почивать на лаврах: AMD готовит выпуск гораздо более энергоэффективных чипов, чем полупроводниковый хит сезона Nvidia H100, потребляющий до 700 Вт, а Intel продвигает процессор Gaudi 3 AI, который будет стоить $15 000 — вдвое дешевле, чем H100. В гонку аппаратного обеспечения для ЦОД присоединяются и другие компании. Microsoft представила ускоритель искусственного интеллекта Maia 100, который она планирует использовать в своём анонсированном ЦОД стоимостью $100 млрд. Amazon производит специальные чипы для AWS, а Google планирует использовать собственные серверные процессоры для ЦОД уже в следующем году.  Однако, по утверждению Nvidia, все эти чипы пока менее производительны, чем её графические процессоры применительно к ускорению работы искусственного интеллекта. Nvidia также подчёркивает гибкость архитектуры своих графических процессоров. Таким образом, несмотря на появляющиеся альтернативы, ИИ-ускорители компании в ближайшем будущем сохранят свои лидирующие позиции. AMD представила мощнейший ИИ-ускоритель MI325X с 288 Гбайт HBM3e и рассказала про MI350X на архитектуре CDNA4
03.06.2024 [12:22],
Николай Хижняк
Компания AMD представила на выставке Computex 2024 обновлённые планы по выпуску ускорителей вычислений Instinct, а также анонсировала новый флагманский ИИ-ускоритель Instinct MI325X. 
Источник изображений: AMD Ранее компания выпустила ускорители MI300A и MI300X с памятью HBM3, а также несколько их вариаций для определённых регионов. Новый MI325X основан на той же архитектуре CDNA 3 и использует ту же комбинацию из 5- и 6-нм чипов, но тем не менее представляет собой существенное обновление для семейства Instinct. Дело в том, что в данном ускорителе применена более производительная память HBM3e.  Instinct MI325X предложит 288 Гбайт памяти, что на 96 Гбайт больше, чем у MI300X. Что ещё важнее, использование новой памяти HBM3e обеспечило повышение пропускной способности до 6,0 Тбайт/с — на 700 Гбайт/с больше, чем у MI300X с HBM3. AMD отмечает, что переход на новую память обеспечит MI325X в 1,3 раза более высокую производительность инференса (работа уже обученной нейросети) и генерации токенов по сравнению с Nvidia H200.  Компания AMD также предварительно анонсировала ускоритель Instinct MI350X, который будет построен на чипе с новой архитектурой CDNA 4. Переход на эту архитектуру обещает примерно 35-кратный прирост производительности в работе обученной нейросети по сравнению с актуальной CDNA 3. 
 Для производства ускорителей вычислений MI350X будет использоваться передовой 3-нм техпроцесс. Instinct MI350X тоже получат до 288 Гбайт памяти HBM3e. Для них также заявляется поддержка типов данных FP4/FP6, что принесёт пользу в работе с алгоритмами машинного обучения. Дополнительные детали об Instinct MI350X компания не сообщила, но отметила, что они будут выпускаться в формфакторе Open Accelerator Module (OAM). 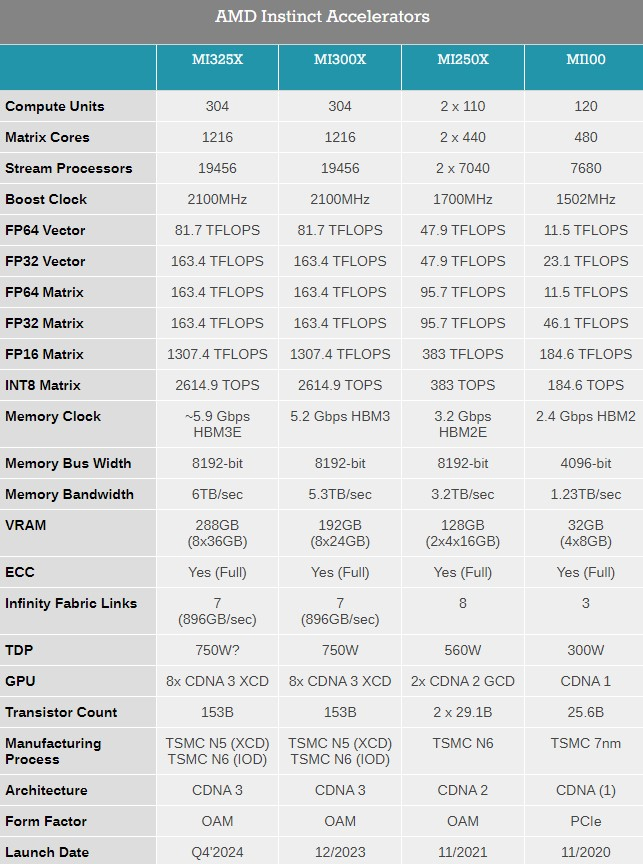
Источник изображения: AnandTech ИИ-ускорители Instinct MI325X начнут продаваться в четвёртом квартале этого года. Выход MI350X ожидается в 2025 году. Кроме того, AMD сообщила, что ускорители вычислений серии MI400 на архитектуре CDNA-Next будут представлены в 2026 году. Акции Nvidia упали на 10 % по сравнению с недавним историческим максимумом
10.04.2024 [19:50],
Сергей Сурабекянц
Nvidia вступила на «территорию коррекции»: её акции упали на 10 % по сравнению с последним историческим максимумом в $950 за акцию. Во вторник торги закрылись на отметке $853,54, падение за сессию составило 2 %. Аналитики связывают снижение стоимости акций Nvidia c представленным накануне компанией Intel ИИ-ускорителем Gaudi 3, «сокращением» моделей ИИ и перенаправлением инвестиций крупных клиентов на разработку собственного оборудования для ИИ. 
Источник изображения: Nvidia Nvidia за последние годы стала ключевым бенефициаром бума искусственного интеллекта благодаря ажиотажному спросу на её чипы, предназначенные для ресурсоёмких приложений ИИ. Ускорители компании являются ключевым компонентом множества центров обработки данных. Nvidia сообщила о росте в четвёртом квартале разводненной прибыли на акцию (non-GAAP) на 486 % благодаря беспрецедентной популярности генеративных моделей искусственного интеллекта. Однако последние две недели акции компании находятся под давлением. Падение курса ценных бумаг составило 10 % по сравнению с последним историческим максимумом, которого они достигли 25 марта. Сегодня акции Nvidia торговались с понижением на 0,7 % по состоянию на 9:45 утра по времени восточного побережья США (16:45 мск). Финансовые эксперты советуют инвесторам фиксировать прибыль, которая может составить более чем 200 % за последние 12 месяцев. 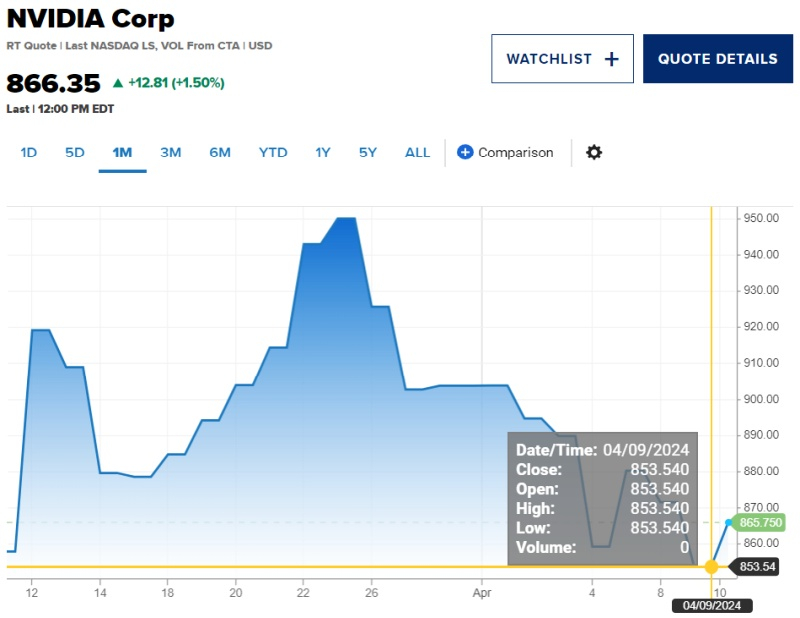
Источник изображения: cnbc.com Одной из возможных причин понижения курса акций Nvidia аналитики называют «сокращение» моделей искусственного интеллекта, включая альтернативы, такие как большая модель Mistral и система LLaMA от Meta✴. «Сочетание сокращения моделей, более устойчивого роста спроса, зрелых инвестиций в гиперскейлеры и растущего использования крупнейшими клиентами собственных чипов не сулит ничего хорошего для Nvidia в ближайшие годы», — полагают эксперты аналитической компании D.A. Davidson. Конкуренция в сфере ускорителей вычислений нарастает. Во вторник компания Intel представила свой новый чип для ускорения искусственного интеллекта под названием Gaudi 3. По утверждению компании, новый чип более чем в два раза энергоэффективнее, чем H100 — самый популярный из ныне выпускаемых ускорителей Nvidia, и может запускать модели искусственного интеллекта в 1,5 раза быстрее, чем H100. Хотя консенсус-оценки говорят о том, что спрос на графические процессоры Nvidia для технологий искусственного интеллекта в этом году будет высоким, в 2025 году ожидается замедление роста, а в 2026 году аналитики предрекают значительный спад для Nvidia, так как крупные покупатели чипов искусственного интеллекта, такие как Amazon и Microsoft, вероятно, направят большую часть своих инвестиций в собственное оборудование. Intel представила ИИ-ускорители Gaudi 3, которые громят NVIDIA H100 по производительности и энергоэффективности
09.04.2024 [23:06],
Владимир Чижевский
Сегодня на мероприятии Vision 2024 компания Intel представила множество новых продуктов, среди которых ИИ-ускорители Gaudi 3. По заявлениям создателей, они позволяют обучать нейросети в 1,7 раза быстрее, на 50 % увеличить производительность инференса и работают на 40 % эффективнее конкурирующих H100 от NVIDIA, которые являются самыми популярными на рынке. 
Источник изображений: Intel Gaudi 3 — третье поколение ускорителей ИИ, появившихся благодаря приобретению Intel в 2019 году компании Habana Labs за $2 млрд. Массовое производство Gaudi 3 для OEM-производителей серверов начнётся в третьем квартале 2024 года. Помимо этого, Gaudi 3 будет доступен в облачном сервисе Intel Developer Cloud для разработчиков, что позволит потенциальным клиентам испытать возможности нового чипа.  Gaudi 3 использует ту же архитектуру и основополагающие принципы, что и его предшественник, но при этом он выполнен по более современному 5-нм техпроцессу TSMC, тогда как в Gaudi 2 использованы 7-нм чипы. Ускоритель состоит из двух кристаллов, на которые приходится 64 ядра Tensor Processing Cores (TPC) пятого поколения и восемь матричных математических движков (MME), а также 96 Мбайт памяти SRAM с пропускной способностью 12,8 Тбайт/с. Вокруг установлено 128 Гбайт HBM2e с пропускной способностью 3,7 Тбайт/с. Также Gaudi 3 укомплектован 24 контроллерами Ethernet RDMA с пропускной способностью по 200 Гбит/с, которые обеспечивают связь как между ускорителями в одном сервере, так и между разными серверами в одной системе.  Gaudi 3 будет выпускаться в двух формфакторах. Первый — OAM (модуль ускорителя OCP) HL-325L, использующийся в высокопроизводительных системах на основе ускорителей вычислений. Этот ускоритель получит TDP 900 Вт и производительность 1835 терафлопс в FP8. Модули OAM устанавливаются по 8 штук на UBB-узел HLB-325, которые можно объединять в системы до 1024 узлов. По сравнению с прошлым поколением, Gaudi 3 обеспечивает вдвое большую производительность в FP8 и вчетверо — в BF16, вдвое большую пропускную способность сети и 1,5 раза — памяти.  OAM устанавливаются в универсальную плату, поддерживающую до восьми модулей. Модули и платы уже отгружены партнёрам, но массовые поставки начнутся лишь к концу года. Восемь OAM на плате HLB-325 дают производительность 14,6 петафлопс в FP8, остальные характеристики масштабируются линейно.  Второй формфактор — двухслотовая карта расширения PCIe с TDP 600 Вт. По заявлениям Intel, несмотря на заметно меньший TDP этой версии, производительность в FP8 осталась той же — 1835 терафлопс. А вот масштабируемость хуже — модули рассчитаны на работу группами по четыре. Gaudi 3 в данном формфакторе появятся в 4 квартале 2024 года. Dell, HPE, Lenovo и Supermicro уже поставили клиентам образцы систем с Gaudi 3 с воздушным охлаждением, а в ближайшее время должны появится модели с жидкостным охлаждением. Массовое производство начнётся лишь в 3 и 4 кварталах 2024 года соответственно. 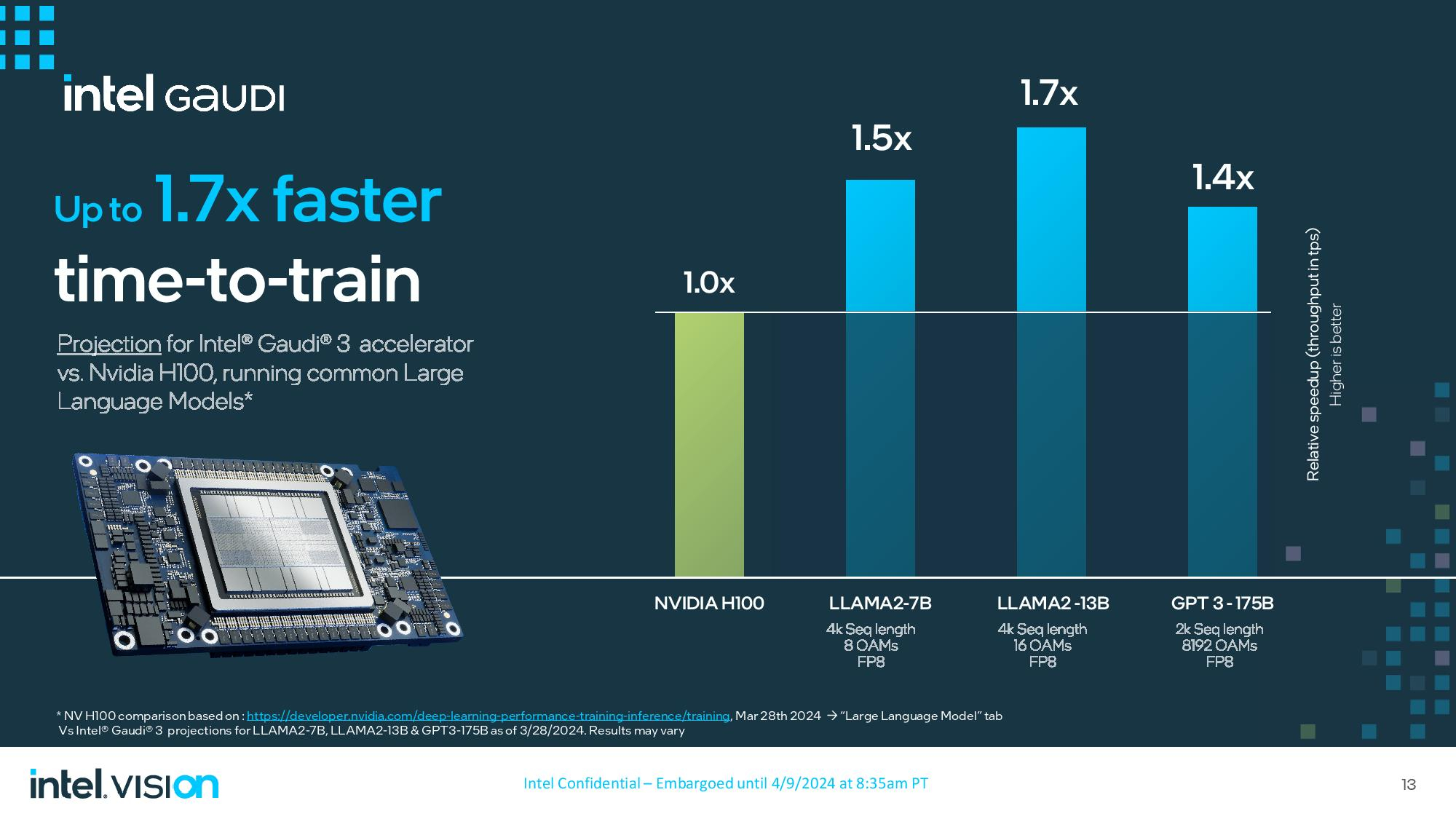 Intel также поделилась собственными тестами производительности, сравнив Gaudi 3 с системами на основе H100. По словам Intel, Gaudi 3 справляется с обучением нейросетей в 1,5–1,7 раза быстрее. Сравнение велось на моделях LLAMA2-7B и LLAMA2-13B на системах с 8 и 16 ускорителями, а также на модели GPT 3-175B на системе с 8192 ускорителями. Intel не стала сравнивать системы на Gaudi 3 с системами на H200 от NVIDIA, у которого на 76 % больше памяти, а её пропускная способность выше на 43 %. 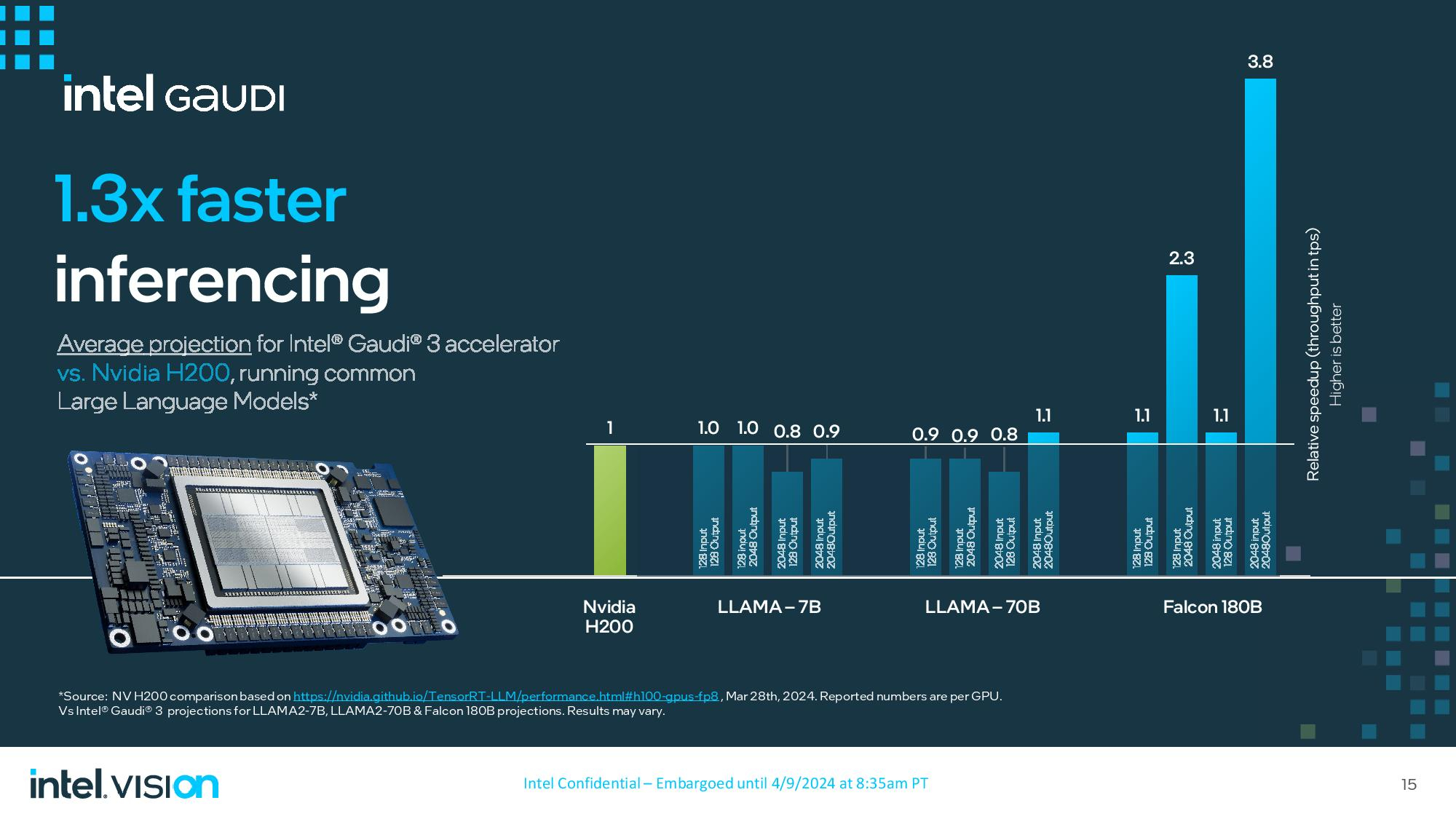 Intel сравнила Gaudi 3 с H200 в инференсе, но уже не кластерами, а отдельным модулем. В пяти тестах с LLAMA2-7B/70B производительность Gaudi 3 оказалась на 10–20 % ниже, в двух равна и в одном чуть выше H200. При этом Intel заявляет о 2,6-кратном преимуществе в энергопотреблении по сравнению с H100. NVIDIA представила самый мощный чип в мире — Blackwell B200, который откроет путь к гигантским нейросетям
19.03.2024 [00:12],
Андрей Созинов
Компания Nvidia в рамках конференции GTC 2024 представила ИИ-ускорители следующего поколения на графических процессорах с архитектурой Blackwell. По словам производителя, грядущие ИИ-ускорители позволят создавать ещё более крупные нейросети, в том числе работать с большими языковыми моделями (LLM) с триллионами параметров, и при этом будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. 
Источник изображений: Nvidia Архитектура GPU Blackwell получила название в честь американского математика Дэвида Блэквелла (David Harold Blackwell) и включает в себя целый ряд инновационных технологий для ускорения вычислений, которые помогут совершить прорыв в обработке данных, инженерном моделировании, автоматизации проектирования электроники, компьютерном проектировании лекарств, квантовых вычислениях и генеративном ИИ. Причём на последнем в Nvidia делают особый акцент: «Генеративный ИИ — это определяющая технология нашего времени. Графические процессоры Blackwell — это двигатель для новой промышленной революции», — подчеркнул глава Nvidia Дженсен Хуанг (Jensen Huang) в рамках презентации. Графический процессор Nvidia B200 производитель без лишней скромности называет самым мощным чипом в мире. В вычислениях FP4 и FP8 новый GPU обеспечивает производительность до 20 и 10 Пфлопс соответственно. Новый GPU состоит из двух кристаллов, которые произведены по специальной версии 4-нм техпроцесса TSMC 4NP и объединены 2,5D-упаковкой CoWoS-L. Это первый GPU компании Nvidia с чиплетной компоновкой. Чипы соединены шиной NV-HBI с пропускной способностью 10 Тбайт/с и работают как единый GPU. Всего новинка насчитывает 208 млрд транзисторов. 
Один из кристаллов Blackwell — в GPU таких кристаллов два По сторонам от кристаллов GPU расположились восемь стеков памяти HBM3E общим объёмом 192 Гбайт. Её пропускная способность достигает 8 Тбайт/с. А для объединения нескольких ускорителей Blackwell в одной системе новый GPU получил поддержку интерфейса NVLink пятого поколения, которая обеспечивает пропускную способность до 1,8 Тбайт/с в обоих направлениях. С помощью данного интерфейса (коммутатор NVSwitch 7.2T) в одну связку можно объединить до 576 GPU. Одними из главных источников более высокой производительности B200 стали новые тензорные ядра и второе поколение механизма Transformer Engine. Последний научился более тонко подбирать необходимую точность вычислений для тех или иных задач, что влияет и на скорость обучения и работы нейросетей, и на максимальный объём поддерживаемых LLM. Теперь Nvidia предлагает тренировку ИИ в формате FP8, а для запуска обученных нейросетей хватит и FP4. Но отметим, что Blackwell поддерживает работу с самыми разными форматами, включая FP4, FP6, FP8, INT8, BF16, FP16, TF32 и FP64. И во всех случаях кроме последнего есть поддержка разреженных вычислений. 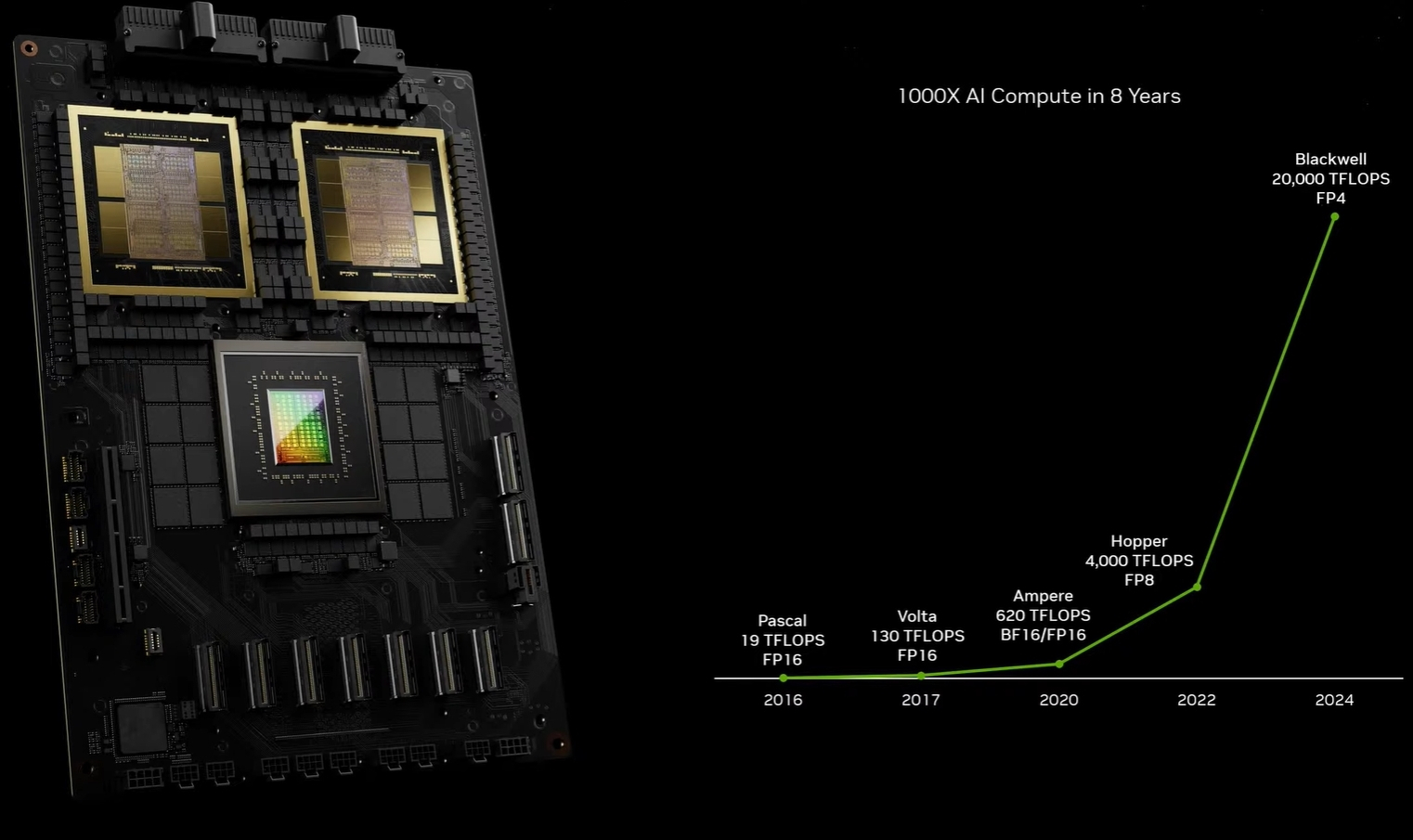 Флагманским ускорителем на новой архитектуре станет Nvidia Grace Blackwell Superchip, в котором сочетается пара графических процессоров B200 и центральный Arm-процессор Nvidia Grace с 72 ядрами Neoverse V2. Данный ускоритель шириной в половину серверной стойки обладает TDP до 2,7 кВт. Производительность в операциях FP4 достигает 40 Пфлопс, тогда как в операциях FP8/FP6/INT8 новый GB200 способен обеспечить 10 Пфлопс. Как отмечает сама Nvidia, новинка обеспечивает 30-кратный прирост производительности по сравнению с Nvidia H100 для рабочих нагрузок, связанных с большими языковыми моделями, а она до 25 раз более экономична и энергетически эффективна.  Ещё Nvidia представила систему GB200 NVL72 — фактически это серверная стойка, которая объединяет в себе 36 Grace Blackwell Superchip и пару коммутаторов NVSwitch 7.2T. Таким образом данная система включает в себя 72 графических процессора B200 Blackwell и 36 центральных процессоров Grace, соединенных NVLink пятого поколения. На систему приходится 13,5 Тбайт памяти HBM3E с общей пропускной способностью до 576 Тбайт/с, а общий объём оперативной памяти достигает 30 Тбайт.  Платформа GB200 NVL72 работает как единый GPU с ИИ-производительностью 1,4 эксафлопс (FP4) и 720 Пфлопс (FP8). Эта система станет строительным блоком для новейшего суперкомпьютера Nvidia DGX SuperPOD. 
На переднем плане HGX-система с восемью Blackwell. На заднем — суперчип GB200 Наконец, Nvidia представила серверные системы HGX B100, HGX B200 и DGX B200. Все они предлагают по восемь ускорителей Blackwell, связанных между собой NVLink 5. Системы HGX B100 и HGX B200 не имеют собственного CPU, а между собой различаются только энергопотреблением и как следствие мощностью. HGX B100 ограничен TDP в 700 Вт и обеспечивает производительность до 112 и 56 Пфлопс в операциях FP4 и FP8/FP6/INT8 соответственно. В свою очередь, HGX B200 имеет TDP в 1000 Вт и предлагает до 144 и 72 Пфлопс в операциях FP4 и FP8/FP6/INT8 соответственно. Наконец, DGX B200 копирует HGX B200 в плане производительности, но является полностью готовой системой с парой центральных процессоров Intel Xeon Emerald Rapids. По словам Nvidia, DGX B200 до 15 раз быстрее в задачах запуска уже обученных «триллионных» моделей по сравнению с предшественником.  Для создания наиболее масштабных ИИ-систем, включающих от 10 тыс. до 100 тыс. ускорителей GB200 в рамках одного дата-центра, компания Nvidia предлагает объединять их в кластеры с помощью сетевых интерфейсов Nvidia Quantum-X800 InfiniBand и Spectrum-X800 Ethernet. Они также были анонсированы сегодня и обеспечат передовые сетевые возможности со скоростью до 800 Гбит/с. Свои системы на базе Nvidia B200 в скором времени представят многие производители, включая Aivres, ASRock Rack, ASUS, Eviden, Foxconn, GIGABYTE, Inventec, Pegatron, QCT, Wistron, Wiwynn и ZT Systems. Также Nvidia GB200 в составе платформы Nvidia DGX Cloud, а позже в этом году решения на этом суперчипе станут доступны у крупнейших облачных провайдеров, включая AWS, Google Cloud и Oracle Cloud. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex

 Подписаться
Подписаться