
Опрос
|
реклама
Быстрый переход
Nvidia выпустила мультимодальную модель ИИ с открытым исходным кодом, и она не уступает GPT-4
02.10.2024 [19:27],
Сергей Сурабекянц
Nvidia представила новое семейство больших мультимодальных языковых моделей NVLM 1.0, включая обученную на 72 миллиардах параметров NVLM-D-72B. Модели демонстрируют высокую производительность в широком спектре задач, таких как машинное зрение, создание программного кода, анализ изображений, решение математических задач и генерация текстов. Похоже, что лидерам отрасли во главе с OpenAI и Google придётся потесниться. 
Источник изображения: freepik.com «Мы представляем NVLM 1.0, семейство передовых мультимодальных больших языковых моделей, которые достигают самых современных результатов в задачах зрения и языка, конкурируя с ведущими фирменными моделями (например, GPT-4o) и моделями с открытым доступом», — утверждают разработчики Nvidia. По их мнению, открытый исходный код предоставляет исследователям и разработчикам беспрецедентный доступ к передовым технологиям. Флагманская модель NVLM-D-72B демонстрирует адаптивность при обработке сложных визуальных и текстовых входных данных. Исследователи подчёркивают способность модели интерпретировать мемы, анализировать изображения и пошагово решать математические задачи. Разработчики также отметили, что NVLM-D-72B улучшает свою производительность в текстовых задачах после мультимодального обучения, в отличие от большинства аналогичных моделей. Проект NVLM также представляет инновационные архитектурные решения, включая гибридный подход, который объединяет различные методы мультимодальной обработки. По оценкам сторонних исследователей, модель NVLM-D-72B «находится на одном уровне с Llama 3.1 405B по математике и кодированию, а также имеет видение». Выпуск Nvidia NVLM 1.0 знаменует собой поворотный момент в разработке ИИ. Открывая исходный код модели, которая конкурирует с проприетарными гигантами, Nvidia не просто делится кодом — она бросает вызов самой структуре индустрии ИИ. Благодаря Nvidia множество небольших организаций и независимых исследователей смогут вносить более значительный вклад в развитие ИИ, что может открыть эру беспрецедентного сотрудничества и инноваций в области ИИ. Этот шаг может вызвать цепную реакцию — другим лидерам в области ИИ также придётся открыть свои исследования, что потенциально ускорит прогресс ИИ по всем направлениям. Нужно отметить, что выпуск NVLM 1.0 не лишён рисков. По мере того, как мощный ИИ становится все более доступным, возрастают и опасения по поводу его неправильного использования и возможных этических последствий. Сообщество ИИ уже столкнулось с необходимостью ответственного использования новых технологий. Одно можно сказать наверняка: политика Nvidia в отношении ИИ затронет всю индустрию. Вопрос только в том, насколько радикальным окажется её влияние, и смогут ли конкуренты адаптироваться достаточно быстро, чтобы преуспеть в этом новом мире открытого ИИ. AMD выпустила свою первую языковую модель ИИ — AMD-135M
01.10.2024 [01:18],
Николай Хижняк
Поскольку AMD пытается нарастить своё присутствие на рынке ИИ, производитель выпускает не только аппаратное обеспечение под эти нужды, но также решил заняться разработкой языковых моделей. Результатом этого стал анонс первой малой языковой AMD-135M. 
Источник изображения: AMD Новая малая языковая модель AMD-135M принадлежит к семейству Llama и нацелена на развёртывание в частном бизнесе. Неясно, имеет ли новая ИИ-модель AMD какое-либо отношение к недавнему приобретению компанией стартапа Silo AI (сделка ещё не завершена и пока не одобрена различными регуляторами, поэтому, вероятно, нет). Однако это явный шаг в направлении удовлетворения потребностей конкретных клиентов с помощью предварительно обученной модели, созданной AMD с использованием её же оборудования. Преимущество языковой модели AMD заключается в том, что она использует так называемое спекулятивное декодирование. Последнее представляет собой меньшую «черновую модель», которая генерирует несколько токенов-кандидатов за один прямой проход. Затем токены передаются в более крупную, более точную «целевую модель», которая проверяет или исправляет их. С одной стороны, такой подход позволяет генерировать несколько токенов одновременно, но с другой стороны, это приводит к повышению потребляемой мощности за счёт увеличения передачи данных. Языковая модель AMD представлена в двух версиях: AMD-Llama-135M и AMD-Llama-135M-code. Каждая из них оптимизирована для определённых задач путём повышения производительности вывода с помощью технологии спекулятивного декодирования. Базовая модель AMD-Llama-135M была обучена с нуля на базе 670 млрд токенов общих данных. Этот процесс занял шесть дней с использованием четырех 8-канальных узлов на базе AMD Instinct MI250. Модель AMD-Llama-135M-code в свою очередь была улучшена за счёт дообучения на базе дополнительных 20 млрд токенов, специально ориентированных на написание программного кода. Дополнительное обучение модели заняло четыре дня с использованием того же набора оборудования AMD. Компания считает, что дальнейшие оптимизации её моделей могут привести к дополнительному повышению их производительности и эффективности. Чтобы духу Nvidia не было: ByteDance обучит новую ИИ-модель исключительно на ускорителях Huawei
30.09.2024 [17:58],
Сергей Сурабекянц
Китайская компания ByteDance планирует разработать новую модель ИИ, обученную на ускорителях искусственного интеллекта Ascend 910B от Huawei Technologies. ByteDance последовательно диверсифицирует свою вычислительную инфраструктуру, ориентируясь на китайских производителей полупроводников. Компания также ускорила разработку собственных ускорителей ИИ. 
Источник изображения: Pixabay На условиях конфиденциальности несколько источников сообщили, что следующим шагом ByteDance в ИИ-гонке станет использование чипа Huawei Ascend 910B для обучения собственной большой языковой модели ИИ. Ранее компания использовала этот ускоритель в основном для менее вычислительно интенсивных задач, основанных на предварительно обученных моделях ИИ. Обучение моделей ИИ требует огромного количества вычислительных ресурсов. На сегодняшний день самыми производительными ускорителями ИИ являются новейшие графические процессоры Nvidia, которые стали недоступны китайским компаниям из-за санкционной политики США. Поэтому возможности и сложность новой модели, использующей чипы Huawei Ascend 910B, будут ниже, чем у существующей модели ИИ ByteDance Doubao, обученной при помощи процессоров Nvidia. Текущая технология искусственного интеллекта ByteDance используется в её флагманской большой языковой модели, выпущенной в августе 2023 года. На ней базируется чат-бот Doubao и множество других приложений, включая инструмент преобразования текста в видео Jimeng. Эти приложения становятся всё более востребованными, а чат-бот ByteDance стал одним из самых популярных приложений в Китае с более чем 10 миллионами активных пользователей в месяц. ByteDance заказала более 100 000 чипов Ascend 910B в этом году, но по состоянию на июль получила менее 30 000, что слишком мало для удовлетворения потребностей компании. По словам источников, задержки поставок и ограниченная вычислительная мощность этих чипов пока не позволяют сделать прогноз о сроках появления новой модели ИИ. Комментируя создавшуюся ситуацию, представитель ByteDance Майкл Хьюз (Michael Hughes) заявил: «Вся предпосылка здесь неверна. Никакой новой модели не разрабатывается». Однако источники утверждают, что ByteDance является одним из крупнейших покупателей ИИ-чипов Huawei и планирует обучать свою новую модель именно на них. Компания стала крупнейшим покупателем ИИ-чипа H20 от Nvidia, который американский производитель адаптировал для китайского рынка в ответ на торговые ограничения США. Сообщалось, что в прошлом году ByteDance потратила $2 млрд на чипы Nvidia. Компания также является первым по величине азиатским клиентом Microsoft в сфере облачных вычислений. Джеймс Кэмерон стал частью стартапа Stability AI, который работает над ИИ-генератором видео
25.09.2024 [10:26],
Алексей Разин
Американский режиссёр Джеймс Кэмерон (James Cameron), приложивший руку к таким шедеврам, как две первые части «Терминатора» и «Титаник», всегда был сторонником передовых технических средств визуализации, а потому в эпоху расцвета систем генеративного искусственного интеллекта решил прикоснуться к их созданию, войдя в состав совета директоров британского стартапа Stability AI. 
Источник изображения: Dell Эта молодая компания создаёт средства автоматической генерации видео по текстовому описанию, конкурируя с гигантами типа OpenAI и Google. Представители американской киноиндустрии проявили интерес к подобным инструментам ещё после демонстрации в феврале этого года аналогичного решения Sora компании OpenAI. Для британского стартапа Stability AI связь с таким деятелем кинокультуры, как Кэмерон, позволяет увереннее находить рынки сбыта для своих разработок. В 2022 году капитализация Stability AI оценивалась в $1 млрд, а в текущем году компании удалось привлечь $80 млн. Исполнительным председателем совета директоров Stability AI стал бывший президент Facebook✴ Шон Паркер (Sean Parker). Программное средство Stable Video Diffusion позволяет создавать видео силами искусственного интеллекта на базе текстового описания. По словам Кэмерона, пересечение генеративного искусственного интеллекта с генерируемыми компьютером изображениями «открывает перед художниками новые способы рассказывать истории, которые они ранее не могли себе даже представить». Даже с учётом воодушевления режиссёра-новатора, отношения Голливуда с разработчиками систем генеративного искусственного интеллекта нельзя назвать гладкими. Актёры и сценаристы в прошлом году устроили забастовку, выражая протест против их замещения плодами деятельности искусственного интеллекта. Они призвали ограничить применение таких технологий при создании кинопродукции и телевизионных программ. Meta✴ похвасталась ростом спроса на языковые модели Llama в 10 раз — всё благодаря их открытости
29.08.2024 [22:42],
Николай Хижняк
Компания Meta✴ сообщила, что количество загрузок её больших языковых моделей ИИ (LLM) Llama приближается к 350 млн. Это в 10 раз больше показателя загрузок за аналогичный период прошлого года. Примерно 20 млн из этих загрузок были сделаны только за последний месяц, после того как компания выпустила языковую модель Llama 3.1, которая, по заявлению Meta✴, позволит ей напрямую конкурировать с решениями компаний OpenAI и Anthropic. 
Источник изображения: Gerd Altmann / pixabay.com У некоторых крупнейших поставщиков облачных услуг, сотрудничающих с Meta✴, ежемесячное использование языковых моделей Llama выросло в десять раз с января по июль этого года. Также отмечается, что с мая по июль использование Llama на серверах её партнёров среди провайдеров облачных услуг выросло более чем вдвое по количеству токенов. Помимо Amazon Web Services (AWS) и Microsoft Azure, компания сотрудничает с Databricks, Dell, Google Cloud, Groq, Nvidia, IBM watsonx, Scale AI и Snowflake и другими, чтобы сделать свои LLM более доступными для разработчиков. Meta✴ считает, что успех её языковых моделей связан с тем, что они распространяются по открытой лицензии. По словам компании, открытое распространение её LLM позволило «расширить и разнообразить экосистему ИИ и предоставить разработчикам больше выбора». Когда Meta✴ выпустила Llama 3.1, глава компании Марк Цукерберг (Mark Zuckerberg) превозносил достоинства ИИ с открытым исходным кодом, назвав его «движением вперёд». Он также рассказал, что компания предпринимает шаги, чтобы сделать ИИ с открытым исходным кодом отраслевым стандартом. В своём последнем отчёте Meta✴ также рассказала, как её партнёры используют большие языковые модели. Например, оператор связи AT&T использует Llama для более точного пользовательского поиска. Один из крупнейших американских доставщиков еды DoorDash использует LLM, чтобы упростить работу своих инженеров по программному обеспечению. Языковая модель также используется для генерации живых реакций и цифровых существ в игре Peridot от компании Niantic. В свою очередь Zoom использует Llama, а также другие языковые модели, для работы ИИ-ассистента, который может подводить итоги встреч и делать умные заметки. Alibaba выпустила математические языковые модели Qwen2-Math, которые лучше аналогов от OpenAI и Google
13.08.2024 [19:39],
Владимир Фетисов
Alibaba Group Holding продолжает активно работать в сфере искусственного интеллекта. На этой неделе гигант электронной коммерции выпустил несколько больших языковых моделей (LLM) под общим названием Qwen2-Math, которые ориентированы на решение сложных математических задач и, по заявлению разработчиков, справляются с этим лучше ИИ-алгоритмов других компаний. 
Источник изображения: Shutterstock Всего было представлено три большие языковые модели, которые отличаются друг от друга количеством параметров, влияющих на точность ответов алгоритма. Модель с наибольшим количеством параметров Qwen2-Math-72B-Instruct, по данным разработчиков, превосходит в плане решения математических задач многие ИИ-алгоритмы, включая GPT-4o от OpenAI, Claude 3.5 Sonnet от Anthropic, Gemini 1.5 Pro от Google и Llama-3.1-405B от Meta✴ Platforms. «За последний год мы проделали большую работу по изучению и расширению логических возможностей больших языковых моделей, уделяя особое внимание их способности решать арифметические и математические задачи <…> Мы надеемся, что Qwen2-Math внесёт свой вклад в усилия сообщества по решению сложных математических задач», — говорится в сообщении разработчиков. Языковые модели Qwen2-Math протестировали с помощью разных бенчмарков, включая GSM8K (8500 сложных и разнообразных математических задач школьного уровня), OlympiadBench (двуязычный мультимодальный научный бенчмарк высокого уровня) и Gaokao (один из сложнейших вступительных математических экзаменов для университетов). Отмечается, что новые модели имеют некоторые ограничения из-за «поддержки только английского языка». В дальнейшем разработчики планируют создать двуязычные и многоязычные LLM. Google представила компактную языковую модель Gemma 2 2B, которая превосходит GPT 3.5 Turbo
01.08.2024 [16:36],
Николай Хижняк
Компания Google представила Gemma 2 2B — компактную, но мощную языковую модель искусственного интеллекта (LLM), которая может составить конкуренцию лидерам отрасли, несмотря на свой значительно меньший размер. Новая языковая модель, содержащая всего 2,6 миллиарда параметров, демонстрирует производительность не хуже гораздо более крупных аналогов, включая OpenAI GPT-3.5 и Mistral AI Mixtral 8x7B. 
Источник изображений: Google В тесте LMSYS Chatbot Arena, популярной онлайн-платформы для сравнительного тестирования и оценки качества моделей искусственного интеллекта, Gemma 2 2B набрала 1130 баллов. Этот результат немного опережает результаты GPT-3.5-Turbo-0613 (1117 баллов) и Mixtral-8x7B (1114 баллов) — моделей, обладающих в десять раз большим количеством параметров. 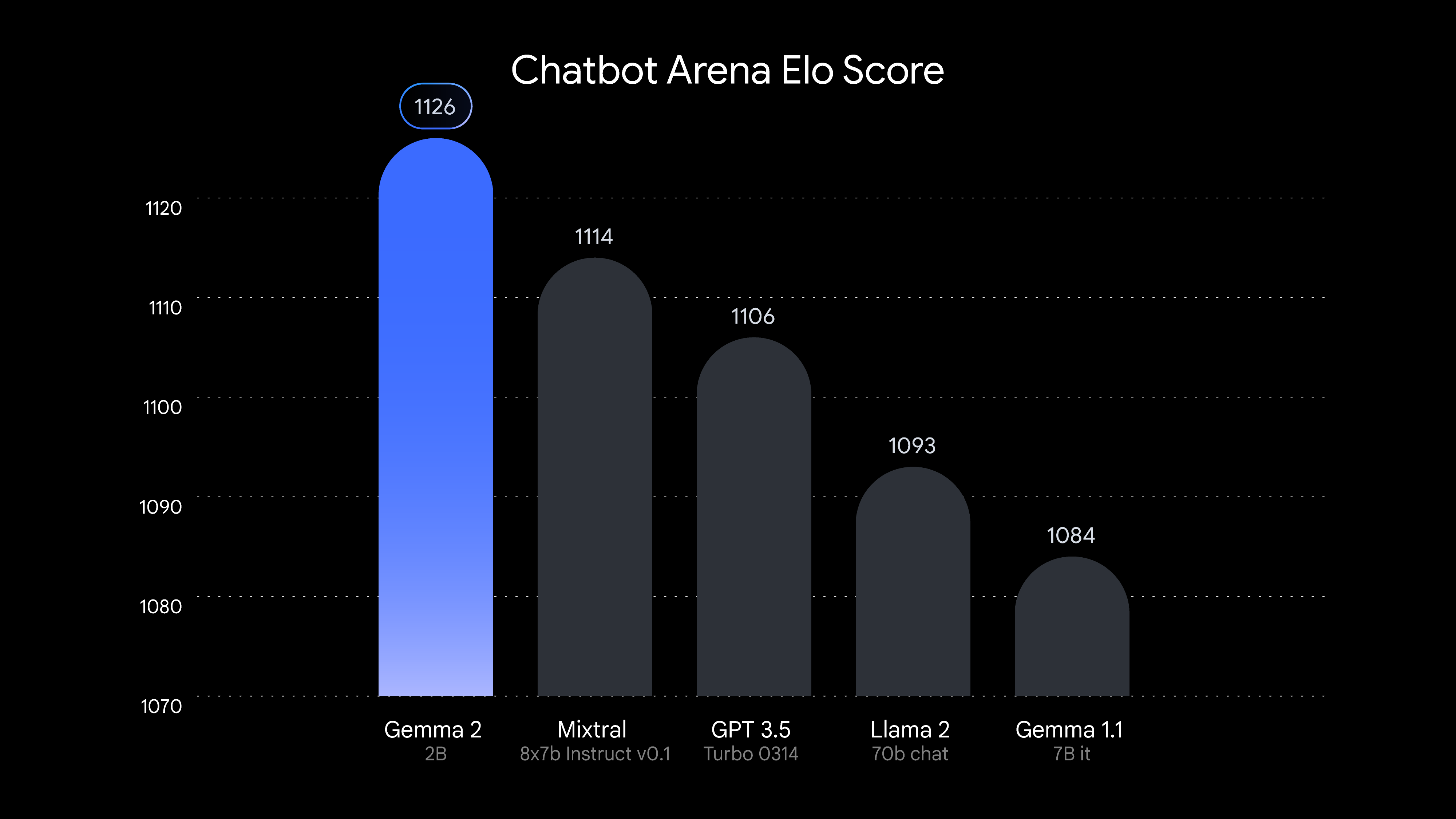 Google сообщает, что Gemma 2 2B также набрала 56,1 балла в тесте MMLU (Massive Multitask Language Understanding) и 36,6 балла в тесте MBPP (Mostly Basic Python Programming), что является значительным улучшением по сравнению с предыдущей версией. Gemma 2 2B бросает вызов общепринятому мнению, что более крупные языковые модели изначально работают лучше компактных. Производительность Gemma 2 2B показывает, что сложные методы обучения, эффективность архитектуры и высококачественные наборы данных могут компенсировать недостаток в числе параметров. Разработка Gemma 2 2B также подчеркивает растущую важность методов сжатия и дистилляции моделей ИИ. Возможность эффективно компилировать информацию из более крупных моделей в более мелкие открывает возможности к созданию более доступных инструментов ИИ, при этом не жертвуя их производительностью. Google обучила Gemma 2 2B на огромном наборе данных из 2 триллионов токенов, используя системы на базе своих фирменных ИИ-ускорителей TPU v5e. Поддержка нескольких языков расширяют её потенциал для применения в глобальных приложениях. Модель Gemma 2 2B имеет открытый исходный код. Исследователи и разработчики могут получить доступ к модели через платформу Hugging Face. Она также поддерживает различные фреймворки, включая PyTorch и TensorFlow. Вышла крупнейшая ИИ-модель Llama 3.1 от Meta✴ — её самая большая версия имеет 405 млрд параметров
24.07.2024 [00:56],
Анжелла Марина
Компания Meta✴ объявила о выпуске крупнейшей на сегодня открытой языковой модели искусственного интеллекта Llama 3.1, насчитывающей более 400 миллиардов различных параметров. По заявлению генерального директора Meta✴ Марка Цукерберга (Mark Zuckerberg) модель может превзойти GPT-4 по производительности уже в ближайшее время, а к концу года станет самым популярным ИИ-помощником в мире. 
Источник изображения: Reuters Как сообщает издание The Verge, разработка новой модели потребовала больших инвестиций. Llama 3.1 значительно сложнее, чем более ранние версии, выпущенные всего несколько месяцев назад. Старшая версия ИИ-модели имеет 405 миллиардов параметров и была обучена с использованием более 16 000 ускорителей H100 от Nvidia. Meta✴ не раскрывает вложенных средств в её разработку, но, исходя из стоимости одних только чипов Nvidia, можно с уверенностью предположить, что речь идёт о сотнях миллионов долларов. Несмотря на высокую стоимость разработки, Meta✴ решила сделать код модели открытым (Open Source). В письме, опубликованном в официальном блоге компании, Цукерберг утверждает, что ИИ-модели с открытым исходным кодом обгонят проприетарные модели, подобно тому, как Linux стал операционной системой с открытым исходным кодом, которая сегодня управляет большинством телефонов, серверов и гаджетов. Одним из ключевых обновлений стало расширение географии доступности сервиса Meta✴ AI, который построен на Llama. Теперь ассистент доступен в 22 странах, включая Аргентину, Чили, Колумбию, Эквадор, Мексику, Перу и Камерун. Кроме того, если раньше Meta✴ AI поддерживала только английский язык, то сейчас добавлены французский, немецкий, хинди, итальянский, португальский и испанский. Однако стоит отметить, что некоторые из новых функций пока доступны только в определённых регионах или для конкретных языков. 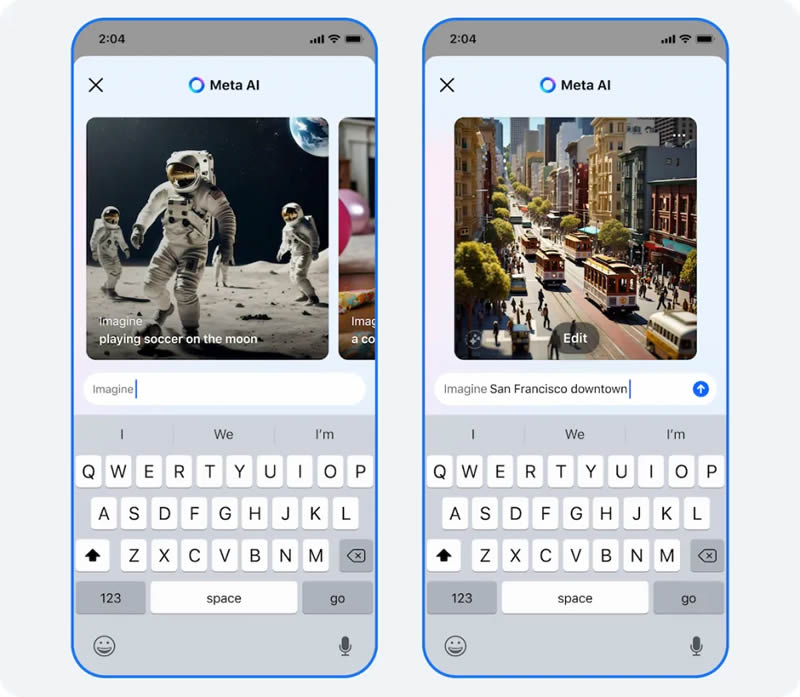
Источник изображения: Meta✴ Также появилась интересная функция Imagine me (представь меня), которая использует генеративную ИИ-модель Imagine Yourself, сообщает TechCrunch. Эта модель способна создавать изображения на основе фотографии пользователя и текстового запроса в требуемом контексте. Например, «Представь меня сёрфингистом» или «Представь меня на пляже». После чего искусственный интеллект сгенерирует соответствующее изображение. Функция доступна в бета-версии и активируется вводом фразы «Imagine me». 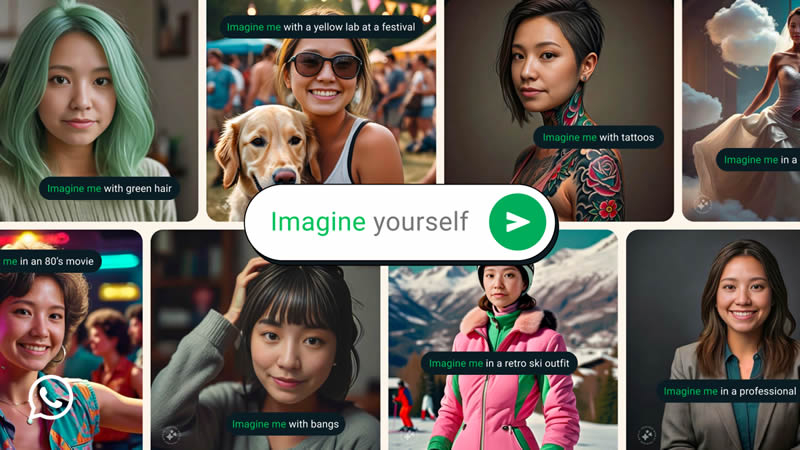
Источник изображения: Meta✴ В ближайшее время Meta✴ AI также получит новые инструменты редактирования изображений. Пользователи смогут добавлять, удалять и изменять объекты на изображениях с помощью текстовых запросов. А со следующего месяца разработчики обещают внедрить кнопку «Edit with AI» (редактирование с помощью ИИ) для доступа к дополнительным опциям тонкой настройки. Позднее появятся новые ярлыки для быстрой публикации изображений, созданных ИИ, в лентах, историях и комментариях в приложениях Meta✴. Напомним, запуск Meta✴ AI состоялся в сентябре 2023 года. Сервис основан на большой языковой модели Llama 2 и предоставляет пользователям возможность получать информацию, генерировать текст, делать переводы на различные языки и выполнять другие задачи с помощью искусственного интеллекта. «Т-Банк» открыл доступ к русскоязычной ИИ-модели T-lite с 8 млрд параметров
22.07.2024 [13:55],
Владимир Мироненко
«Т-Банк» открыл доступ к русскоязычной большой языковой модели T-lite с 8 млрд параметров, созданной Центром искусственного интеллекта финансовой организации (AI-центр). Как было объявлено на первой конференции «Т-Банка» по машинному обучению Turbo ML Conf, T-lite показала в индустриальных и внутренних бенчмарках лучшие результаты в решении бизнес-задач на русском языке среди открытых моделей с 7–8 млрд параметров. 
Источник изображений: Т-Банк В частности, результаты T-lite были лучше, чем у зарубежных llama3-8b-instruct и chat-gpt 3.5. При этом на создание T-lite потребовалось всего 3 % вычислительных ресурсов, которые обычно необходимы для такого типа моделей, отметил «Т-Банк». 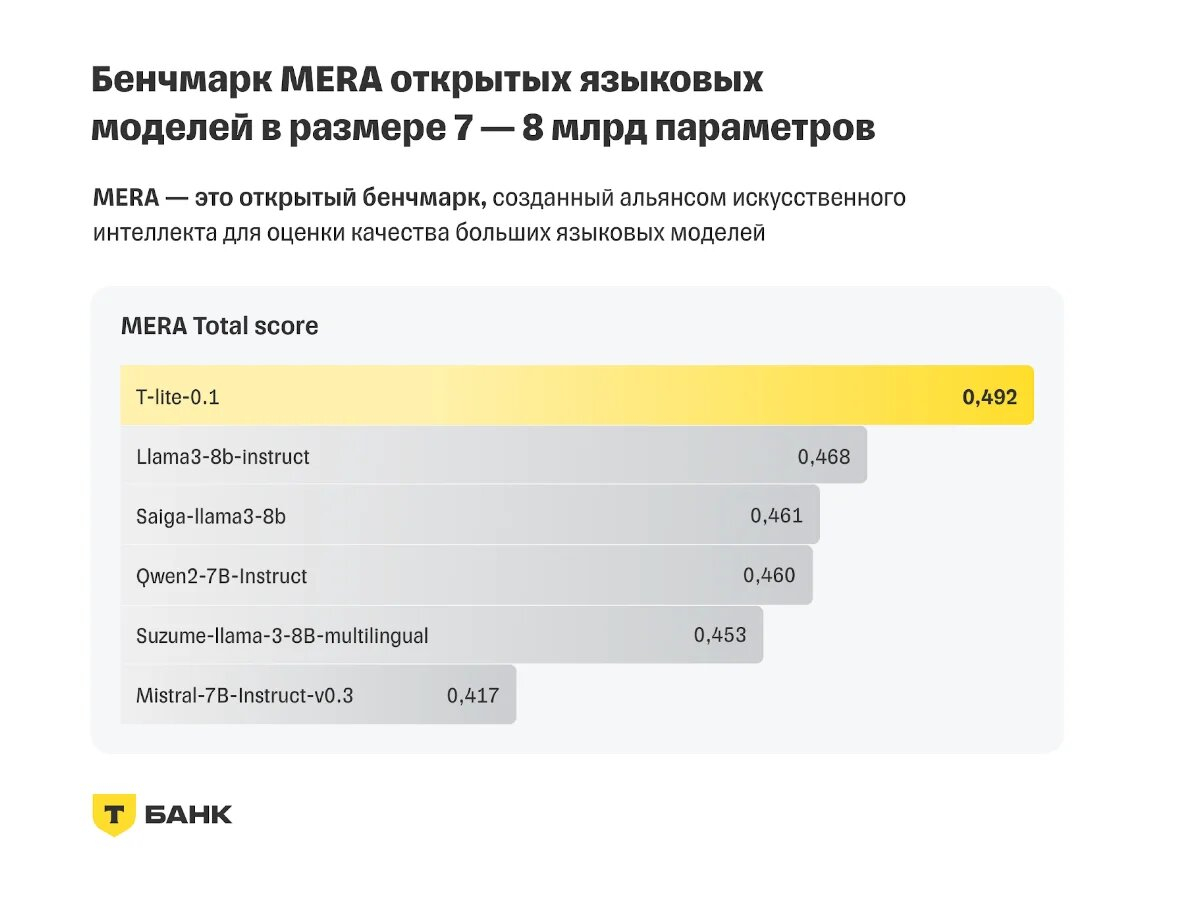 С увеличением количества параметров ИИ-модели растут её возможности для выполнения сложных заданий, но вместе с тем ухудшается экономическая эффективность модели. В свою очередь, T-lite после дообучения для выполнения конкретных бизнес-задач в области обработки естественного языка (NLP) предоставляет ответы, сопоставимые по качеству с проприетарными моделями размером от 20 млрд параметров, но при этом значительно дешевле в эксплуатации. 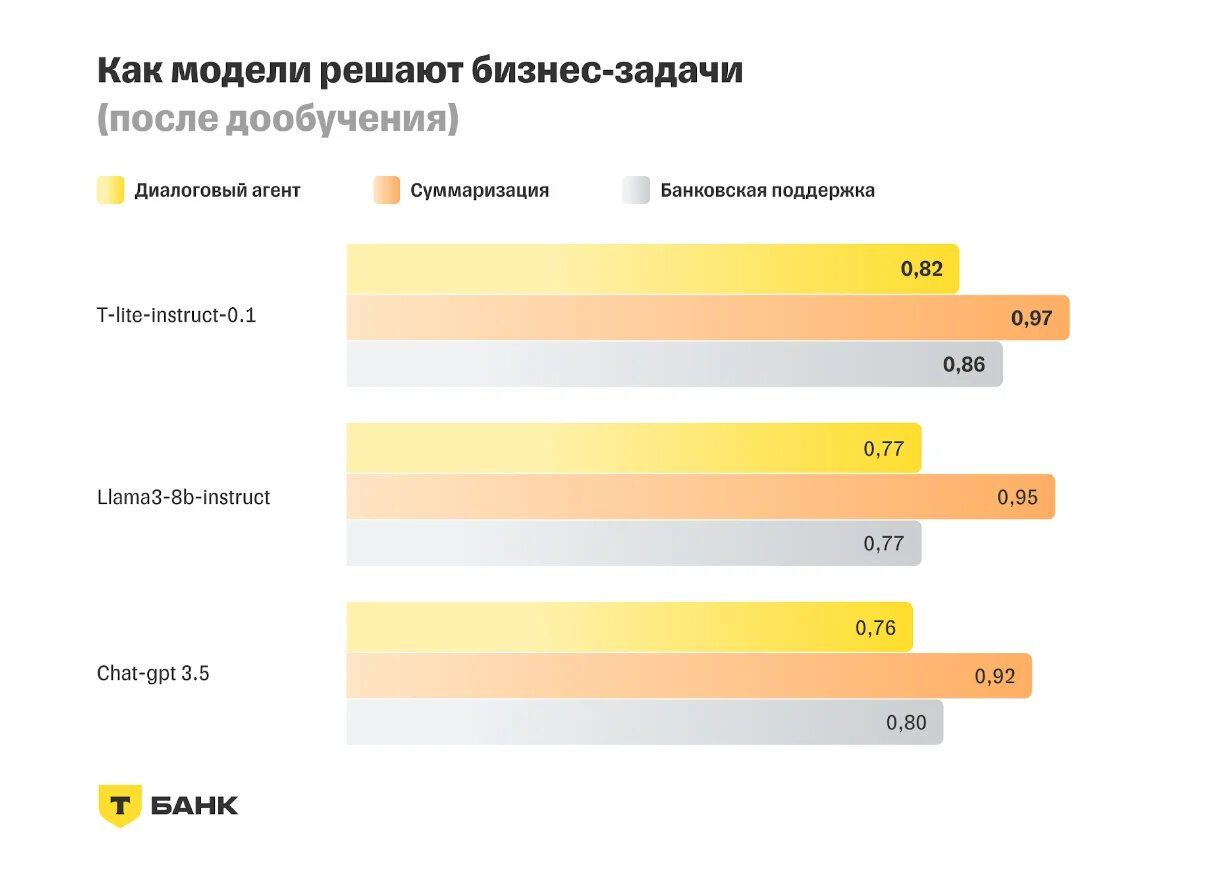 T-lite входит в семейство собственных специализированных языковых моделей «Т-Банка» Gen-T, способных обучаться для решения конкретных узкоспециализированных задач. В отличие от универсальных моделей, таких как ChatGPT, модели семейства Gen-T ориентированы на использование в конкретных областях с максимальной адаптацией под нужды пользователя. OpenAI представила облегченную мощную ИИ-модель GPT-4o Mini — она заменит GPT-3.5 для всех пользователей
18.07.2024 [20:53],
Владимир Фетисов
Компания OpenAI официально представила упрощённую и более доступную версию своей самой мощной большой языковой модели GPT-4o. Речь идёт о нейросети GPT-4o Mini, использование которой для разработчиков будет более выгодно с экономической точки зрения, но при этом её производительность выше, чем у GPT-3.5. 
Источник изображения: Growtika / unsplash.com Создание приложений с использованием языковых моделей OpenAI может обернуться огромными расходами. При отсутствии достаточного количества средств разработчики могут отказаться от их использования в пользу более доступных аналогов, таких как Gemini 1.5 Flash от Google или Claude 3 Haiku от Anthropic. Теперь же с запуском GPT-4o Mini в этом сегменте конкуренция будет более острой. «Я думаю, что GPT-4o Mini действительно соответствует миссии OpenAI — сделать более доступный для людей ИИ-алгоритм. Если мы хотим, чтобы ИИ приносил пользу в каждом уголке мира, в каждой отрасли, в каждом приложении, мы должны сделать ИИ гораздо более доступным», — рассказал представитель OpenAI. Начиная с сегодняшнего дня, пользователи ChatGPT на тарифах Free, Plus и Team могут использовать GPT-4o Mini вместо GPT-3.5 Turbo, а пользователи на тарифе Enterprise получат такую возможность на следующей неделе. Это означает, что языковая модель GPT-3.5 больше не будет доступна для пользователей ChatGPT, но её по-прежнему смогут задействовать разработчики через соответствующий API, если они не планируют перейти на GPT-4o Mini. Когда именно доступ к GPT-3.5 будет закрыт полностью, пока неизвестно. Языковая модель GPT-4o Mini поддерживает работу с текстом, изображениями, аудио- и видеоконтентом. При этом алгоритм всё же предназначен для решения простых задач, поэтому он может оказаться полезным для добавления разных узконаправленных функций в приложения сторонних разработчиков. В эталонном тесте MMLU новая языковая модель OpenAI набрала 82 %. Для сравнения, результат GPT-3.5 в этом же тесте 70 %, GPT-4o — 88,7 %, Gemini Ultra — 90 %. Конкурирующие с GPT-4o Mini языковые модели Claude 3 Haiku и Gemini 1.5 Flash набрали в этом тесте 75,2 % и 78,9 % соответственно. Учёные нашли способ запускать большие ИИ-модели на системах мощностью 13 Вт, вместо 700 Вт
26.06.2024 [22:08],
Анжелла Марина
Исследователи из Калифорнийского университета в Санта-Круз разработали метод, позволяющий запускать большие языковые модели искусственного интеллекта (LLM) с миллиардами параметров при значительно меньшем потреблении энергии, чем у современных систем. 
Источник изображения: Stefan Steinbauer/Unsplash Новый метод позволил запустить LLV с миллиардами параметров при энергопотреблении системы всего в 13 Вт, что эквивалентно потреблению бытовой светодиодной лампы. Это достижение особенно впечатляет на фоне текущих показателей энергопотребления ИИ-ускорителей. Современные графические процессоры для центров обработки данных, такие как Nvidia H100 и H200, потребляют около 700 Вт, а грядущий Blackwell B200 вообще может использовать до 1200 Вт на один GPU. Таким образом, новый метод оказывается в 50 раз эффективнее популярных сегодня решений, пишет Tom's Hardware. Ключом к успеху стало устранение матричного умножения (MatMul) из процессов обучения. Исследователи применили два метода. Первый — это перевод системы счисления в троичную, использующую значения -1, 0 и 1, что позволило заменить умножение на простое суммирование чисел. Второй метод основан на внедрении временных вычислений, при котором сеть получила эффективную «память», позволившую работать быстрее, но с меньшим количеством выполняемых операций. Работа проводилась на специализированной системе с FPGA, но исследователи подчёркивают, что большинство их методов повышения эффективности можно применить с помощью открытого программного обеспечения и настройки уже существующих на сегодня систем. Исследование было вдохновлено работой Microsoft по использованию троичных чисел в нейронных сетях, а в качестве эталонной большой модели учёные использовали LLaMa от Meta✴. Рюдзи Чжу (Rui-Jie Zhu), один из аспирантов, работавших над проектом, объяснил суть достижения в замене дорогостоящих операций на более дешёвые. Хотя пока неясно, можно ли применить этот подход ко всем системам в области ИИ и языковых моделей в качестве универсального, потенциально он может радикально изменить ландшафт ИИ. Немаловажно, что учёные открыли исходный код своей разработки, что позволит крупным игрокам рынка ИИ, таким как Meta✴, OpenAI, Google, Nvidia и другим беспрепятственно воспользоваться новым достижением для обработки рабочих нагрузок и создания более быстрых и энергоэффективных систем искусственного интеллекта. В конечном итоге это приведёт к тому, что ИИ сможет полнофункционально работать на персональных компьютерах и мобильных устройствах, и приблизится к уровню функциональности человеческого мозга. «Яндекс» разрабатывает нейросеть SpeechGPT для задач на стыке текста и звука, но она вряд ли дотянет до уровня ChatGPT
03.06.2024 [16:24],
Владимир Мироненко
«Яндекс» занимается разработкой новой нейросетевой модели SpeechGPT и для этого нанимает в свою команду специалиста в области машинного обучения, пишет «Коммерсантъ» со ссылкой на раздел вакансий компании. Согласно описанию вакансии, новая модель «умеет воспринимать текст и звук, отвечать текстом и звуком, решать разные задачи на стыке текста и звука», то есть, относится к категории мультимодальных ИИ-систем. 
Источник изображения: geralt/Pixabay В «Яндексе» не стали отвечать на вопрос о модели SpeechGPT, пояснив, что работают над мультимодальностью в ассистенте «Алиса» и других сервисах. Как полагает эксперт в области ИИ и продвинутой аналитики компании Axenix Владимир Кравцев, MVP (минимально жизнеспособный продукт) SpeechGPT, вероятно, появится в ближайшие месяцы, «дальше пойдёт процесс непрерывных улучшений». По его мнению, SpeechGPT прежде всего будут встраивать в «уже существующие сервисы, связанные с каналами коммуникации с клиентами, партнёрами “Яндекса”, то есть, будет происходить постепенная замена текущих более простых моделей на современные». Директор по продукту Hybrid Светлана Другова считает, что новая модель «Яндекса» вряд ли будет сопоставима по возможностям с мультимодальными моделями Google семейства Gemini или OpenAI, поскольку на создание подобных им требуются миллиарды долларов. Тем не менее, с учётом того, что у «“Яндекса” уже есть наработки, затраты будут несколько меньше», говорит она. Российские компании продолжают закупать ИИ-ускорители Nvidia, несмотря на санкции, но затраты растут
01.06.2024 [00:31],
Владимир Мироненко
Несмотря на санкции, российским компаниям в сфере ИИ-технологий пока удаётся закупать необходимое оборудование, в первую очередь — ускорители вычислений Nvidia, которые можно объединять в высокопроизводительные кластеры, пишет «Коммерсантъ». Данные ускорители сейчас особенно нужны — они служат основой для систем искусственного интеллекта. 
Источник изображения: geralt/Pixabay Российские технологические компании стали активнее коммерциализировать ИИ-решения. Например, «Яндекс» и «Сбер» интегрировали большие языковые модели (LLM), соответственно YandexGPT и GigaChat, в свои ассистенты и предлагают другим компаниям использовать их для обработки или генерации контента. VK и МТС тоже представили собственные продукты на базе генеративного ИИ, использующие собственные LLM. Создание LLM требует значительных вычислительных мощностей, в основном построенных на графических ускорителях. Лидирует в этой сфере Nvidia. Согласно исследованию Dell’Oro Group, в 2023 году на её серверные графические ускорители приходилось 97 % всей выручки, которую приносит сегмент во всём мире. Чем больше у LLM параметров, тем больше число вычислительных операций необходимо для её тренировки. Да и обращение с запросом к нейросетям, прошедшим обучение, тоже требует вычислительных ресурсов. Как сообщил директор бизнес-группы поиска и рекламных технологий «Яндекса» Дмитрий Масюк, стоимость ответов на основе YandexGPT в пересчёте на пользователя в семь раз выше, чем при использовании классических технологий вроде интернет-поиска. В VK рост числа связанных друг с другом высокопроизводительных серверов (HPC-кластеры) на базе графических ускорителей примерно в полтора раза превосходит рост обычных систем, сообщил «Коммерсанту» вице-президент компании по ИИ, контентным и рекомендательным сервисам Антон Фролов. Рост спроса на ресурсы подтвердили и в Beeline Cloud, отметив, что санкции усложняют закупки и поставки серверов «с адекватными конфигурациями и ценами». С ростом объёма данных, передаваемых в ходе высокопроизводительных вычислений, возникает потребность в расширении сетей, отметил вице-президент по развитию инфраструктуры МТС, глава облачной платформы MWS Игорь Зарубинский. А также растёт потребность в быстрых и ёмких хранилищах данных. «Развитие ИИ приводит к росту спроса на накопители и диски. В будущем потребуется строительство высокоплотных энергонагруженных ЦОДов», — прогнозирует он. IT-директор облачного провайдера Oxygen Александр Будкин утверждает, что рост потребности клиентов в высоких мощностях требует «переосмысления ЦОДа как конечного коммерческого продукта для ИТ рынка». По его мнению, если тенденция сохранится на четыре-пять лет, можно будет говорить о проектах строительства ЦОД именно под ИИ: «Они могут быть размещены в регионах с холодным климатом, работать от электричества с электростанций на попутном газе». Такие проекты обсуждались и раньше, но были признаны нецелесообразными из-за относительной неразвитости каналов связи, но ИИ «более толерантен к задержкам». OpenAI представила ИИ-модель GPT-4o — она гораздо умнее старых версий и будет доступна бесплатно
13.05.2024 [22:50],
Владимир Мироненко
OpenAI представила мощную мультимодальную модель генеративного искусственного интеллекта (ИИ) GPT-4o, которая будет внедрена в её решения для разработчиков и потребителей в течение следующих нескольких недель. Буква «о» в названии GPT-4o означает omni (всесторонний), что указывает на мультимодальность GPT-4o. 
Источник изображений: OpenAI Технический директор OpenAI Мира Мурати (Mira Murati) сообщила в ходе презентации продукта в офисе OpenAI в Сан-Франциско (США), что GPT-4o имеет интеллект «уровня GPT-4», но более высокие возможности в работе с текстом и изображениями, а также с аудио. «GPT-4o воспринимает голос, текст и визуальные образы, — сообщила Мурати. — И это невероятно важно, поскольку мы думаем о будущем взаимодействии между нами и машинами». Её предшественница — GPT-4 Turbo — обучалась на сочетании изображений и текста. Она способна анализировать изображения и текст для выполнения таких задач, как извлечение текста из изображений и даже описание содержимого этих изображений. В свою очередь, в GPT-4o к этим возможностям добавили речь. GPT-4o получил контекстное окно в 128 тысяч токенов.  Сообщается, что GPT-4o позволит значительно улучшить работу ИИ-чат-бота ChatGPT. Последний уже давно поддерживает голосовой режим, в котором ответы чат-бота расшифровываются с использованием модели преобразования текста в речь, но GPT-4o усилит эту функцию, позволяя пользователям взаимодействовать с чат-ботом больше как с помощником. Например, ему можно будет задать вопрос и прервать его, когда он отвечает. По словам OpenAI, модель GPT-4o обеспечивает реагирование «в реальном времени» и может даже улавливать эмоции в голосе пользователя, генерируя в ответ голос «в различных эмоциональных стилях» в соответствии с текущей ситуацией. GPT-4o также улучшит визуальные возможности ChatGPT. Исходя из предложенной фотографии или экрана рабочего стола, ChatGPT теперь сможет быстро отвечать на сопутствующие вопросы: от «Что происходит в этом программном коде» до «Какую рубашку какого бренда носит этот человек?». В дальнейшем возможности модели будут расширяться. Если сейчас GPT-4o позволяет, например, переводить сфотографированное меню на другой язык, то в будущем с её помощью ChatGPT сможет «смотреть» спортивную игру в прямом эфире и объяснять вам правила, говорит Мурати.  Начиная с сегодняшнего дня GPT-4o доступна как платным, так и бесплатным пользователям ChatGPT, но для подписчиков платных тарифных планов ChatGPT Plus и Team ограничение на количество сообщений будет «в 5 раз выше». При превышении лимита ChatGPT автоматически переключится на GPT-3.5 у бесплатных пользователей и на GPT-4 у платных. Бесплатным пользователям ChatGPT при взаимодействии с GPT-4o станут доступны некоторые функции, которые прежде были только у платных подписчиков. В частности, обновлённый чат-бот сможет искать информацию не только в своей ИИ-модели, но также в интернете; анализировать данные и создавать графики; работать с пользовательскими изображениями и файлами; а также лучше помнить прежние взаимодействия с пользователем. Также бесплатные пользователи получат доступ к GPT Store. OpenAI сообщила, что GPT-4o поддерживает больше языков, с улучшенной производительностью на 50 различных языках. В API OpenAI GPT-4o в два раза быстрее, чем GPT-4 (в частности, GPT-4 Turbo), вдвое дешевле и имеет более высокие лимиты по скорости. В настоящее время поддержка голосового общения не включена в API GPT-4o для всех клиентов. OpenAI пояснила, что из-за риска неправильного использования планирует впервые запустить в ближайшие недели поддержку новых аудиовозможностей GPT-4o для «небольшой группы доверенных партнёров». Microsoft запустила разработку собственной большой языковой модели ИИ — это добавит независимости от OpenAI
07.05.2024 [10:17],
Алексей Разин
Вложившая в капитал стартапа OpenAI более $10 млрд американская корпорация Microsoft, по данным The Information, занялась разработкой собственной большой языковой модели ИИ, которая добавит компании независимости от той же OpenAI и усилит конкуренцию с Google. Модель получила обозначение MAI-1 и создаётся с использованием собственных ресурсов. 
Источник изображения: Nvidia Руководит этой инициативой в Microsoft, как отмечает первоисточник, Мустафа Сулейман (Mustafa Suleyman), который занимался разработкой систем искусственного интеллекта в Google, а также возглавлял стартап Inflection, прежде чем его не поглотила Microsoft, заплатив $650 млн в марте этого года. Впрочем, источники подчёркивают, что Microsoft самостоятельно разрабатывает MAI-1, не опираясь на существовавшие в Inflection программные решения. Впрочем, использование каких-то технологий этого стартапа в том или ином виде не исключается. MAI-1 станет значительно более крупной языковой моделью по сравнению с теми разработками с открытым исходным кодом, которые до сих пор использовала Microsoft. Она потребует не только большего количества входных данных, но и более значимых вычислительных ресурсов. MAI-1 будет использовать около 500 млрд параметров. Если учесть, что передовая ChatGPT-4 стартапа OpenAI использует 1 трлн параметров, для собственной модели Microsoft это будет существенный прорыв в сложности модели. Назначение MAI-1 пока не определено и будет выбрано в зависимости от промежуточных успехов в её разработке. Microsoft может рассказать подробности об этой инициативе на конференции Build ближе к концу текущего месяца. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться