|
Опрос
|
реклама
Быстрый переход
Google представила Gemini 2.5 Pro — свою самую умную ИИ-модель, которая превзошла OpenAI o3
25.03.2025 [23:09],
Анжелла Марина
Компания Google анонсировала ИИ-модель Gemini 2.5 Pro, назвав её «своей самой умной моделью» на сегодняшний день. Нейросеть является частью семейства Gemini 2.5 и превосходит предыдущие версии в анализе данных, программировании и решении сложных задач, поддерживая контекст до 1 млн токенов. 
Источник изображений: Google Ключевой особенностью Gemini 2.5 Pro, как и всех моделей семейства Gemini 2.5, является способность рассуждать, представляя ход своих мыслей перед тем, как выдать пользователю более точный и окончательный ответ. В отличие от предыдущего поколения моделей (Gemini 2.0 Flash Thinking), Google больше не использует маркировку Thinking и не демонстрирует ход рассуждений. Однако, как уточняет сайт 9to5Google, пользователи могут вручную активировать функцию «размышления вслух», чтобы увидеть ход мысли бота. В целом Gemini 2.5 Pro продемонстрировала значительный скачок в производительности благодаря улучшенной базовой модели и доработкам после обучения. Google отмечает, что эта версия возглавила рейтинг LMArena, который оценивает модели на основе пользовательских предпочтений, а также показала лучшие результаты в математике (AIME 2025) и науке (GPQA diamond). 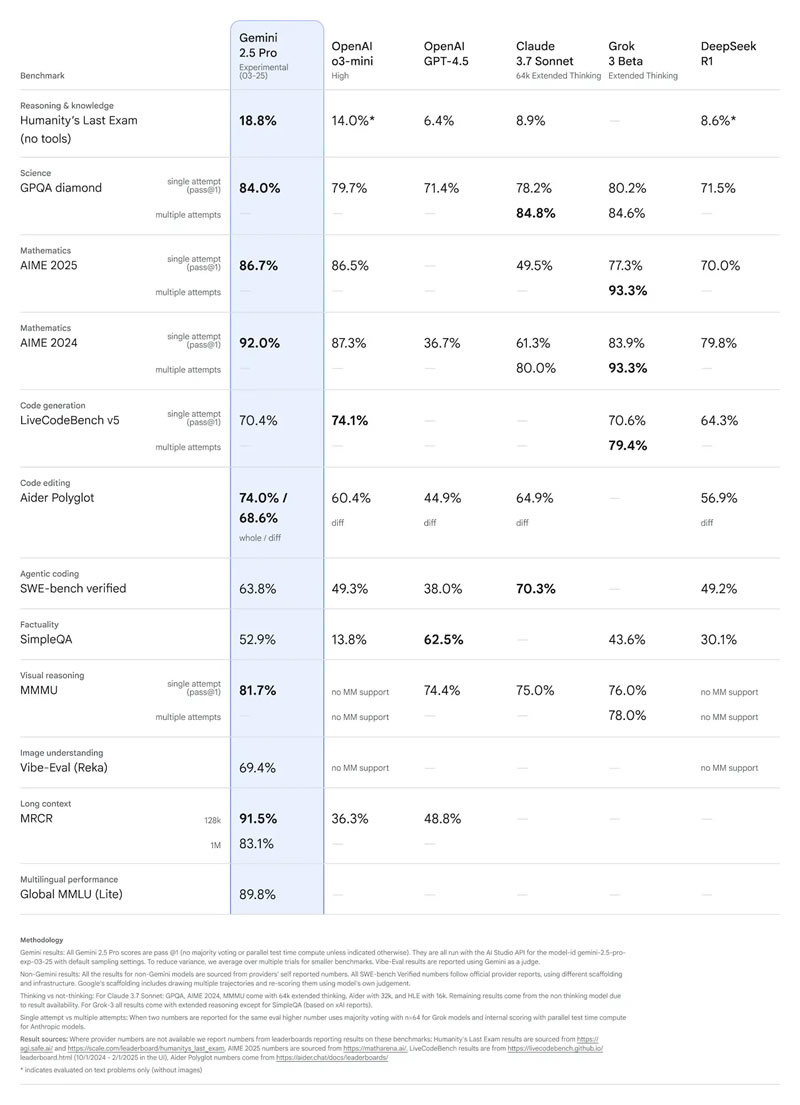 Одновременно в тесте Humanity’s Last Exam («Последний экзамен человечества»), который создан экспертами для проверки предела возможностей искусственного интеллекта в области знаний и логики, Gemini 2.5 Pro достигла рекордных 18,8 % без использования дополнительных инструментов. Также модель получила существенные улучшения в программировании, особенно в создании веб-приложений и редактировании кода. 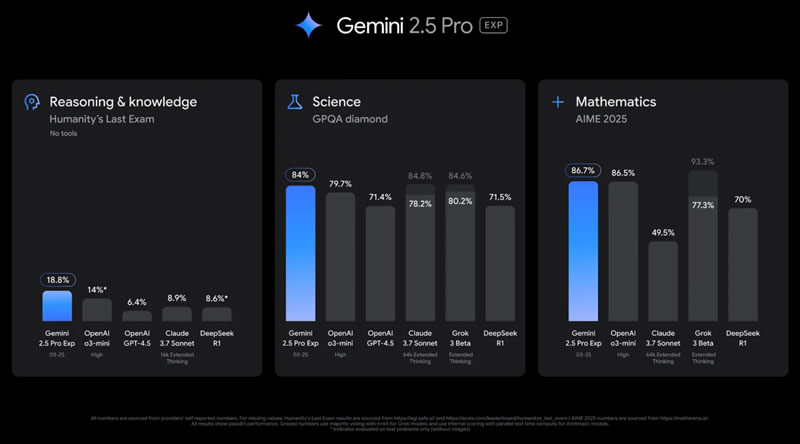 В области разработки программного обеспечения Gemini 2.5 Pro продемонстрировала высокий результат на тесте SWE-Bench Verified, набрав 63,8 % при использовании специального агентского подхода. Кроме того, модель обладает встроенной мультимодальностью и способна работать с текстом, аудио, изображениями, видео, обрабатывать большие наборы данных и даже репозитории кода в полном объёме. Контекстное окно модели предлагает размер в 1 миллион токенов, а в ближайшем будущем оно увеличится до 2 миллионов. В следующие несколько недель Gemini 2.5 Pro появится в Vertex AI, а позднее Google представит ценовую политику, позволяющую использовать ИИ-модель в масштабных проектах. Пока модель доступна для платных подписчиков и разработчиков в тестовом режиме. ИИ Gemini научился консультировать людей о местах из «Google Карт»
25.03.2025 [13:29],
Павел Котов
Большая языковая модель искусственного интеллекта Gemini порой предлагает впечатляющие возможности, но люди смогут оценить их, только когда испытают сами. Google стремится интегрировать её в большинство своих сервисов, включая картографический, где ИИ становится источником справочной информации. 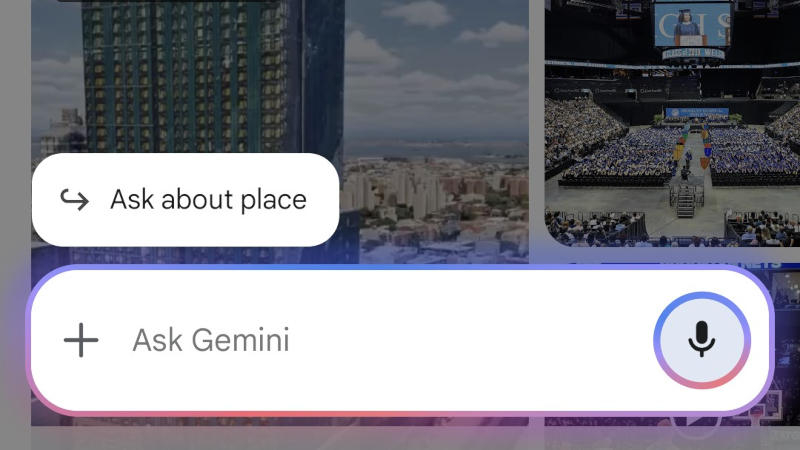
Источник изображения: androidauthority.com В сервисе «Google Карты» началось широкомасштабное развёртывание новой функции — кнопки «Задать вопрос о месте» (Ask about place), обратил внимание ресурс Android Authority. Функция появляется постепенно — она отмечается не у всех, а набор её возможностей пока варьируется от одного пользователя к другому. Открывая отдельные местоположения в «Google Картах», можно задавать Gemini связанные с этими местами вопросы, например, как лучше добраться до пункта назначения. Механизм работы функции относительно прост — запрос к ИИ сопровождается URL-адресом из картографического сервиса. Кнопка, когда она доступна, появляется для большинства локаций, но зависит от их масштаба. К примеру, она отсутствует при просмотре города или региона целиком. Иногда Gemini отвечает, что не может работать с картами, в отдельных случаях для обработки запросов требуется платная подписка Gemini Advanced. Вероятно, Google начала развёртывать функцию для широкого круга пользователей, не доработав её до конца и не сделав соответствующих заявлений, и в перспективе компания всё-таки наладит адекватный механизм её работы. Исследователи нашли способ масштабирования ИИ без дополнительного обучения, но это не точно
19.03.2025 [23:34],
Анжелла Марина
Группа исследователей из Google и Калифорнийского университета в Беркли предложила новый метод масштабирования искусственного интеллекта (ИИ). Речь идёт о так называемом «поиске во время вывода», который позволяет модели генерировать множество ответов на запрос и выбирать лучший из них. Этот подход может повысить производительность моделей без дополнительного обучения. Однако сторонние эксперты усомнились в правильности идеи. 
Источник изображения: сгенерировано AI Ранее основным способом улучшения ИИ было обучение больших языковых моделей (LLM) на всё большем объёме данных и увеличение вычислительных мощностей при запуске (тестировании) модели. Это стало нормой, а точнее сказать, законом для большинства ведущих ИИ-лабораторий. Новый метод, предложенный исследователями, заключается в том, что модель генерирует множество возможных ответов на запрос пользователя и затем выбирает лучший. Как отмечает TechCrunch, это позволит значительно повысить точность ответов даже у не очень крупных и устаревших моделей. В качестве примера учёные привели модель Gemini 1.5 Pro, выпущенную компанией Google в начале 2024 года. Утверждается, что, используя технику «поиска во время вывода» (inference-time search), эта модель обошла мощную o1-preview от OpenAI по математическим и научным тестам. Один из авторов работы, Эрик Чжао (Eric Zhao), подчеркнул: «Просто случайно выбирая 200 ответов и проверяя их, Gemini 1.5 однозначно обходит o1-preview и даже приближается к o1». Тем не менее, эксперты посчитали эти результаты предсказуемыми и не увидели в методе революционного прорыва. Мэтью Гуздиал (Matthew Guzdial), исследователь ИИ из Университета Альберты, отметил, что метод работает только в тех случаях, когда можно чётко определить правильный ответ, а в большинстве задач это невозможно. С ним согласен и Майк Кук (Mike Cook), исследователь из Королевского колледжа Лондона. По его словам, новый метод не улучшает способность ИИ к рассуждениям, а лишь помогает обходить существующие ограничения. Он пояснил: «Если модель ошибается в 5 % случаев, то, проверяя 200 вариантов, эти ошибки просто станут более заметны». Основная проблема состоит в том, что метод не делает модели умнее, а просто увеличивает количество вычислений для поиска наилучшего ответа. В реальных условиях такой подход может оказаться слишком затратным и малоэффективным. Несмотря на это, поиск новых способов масштабирования ИИ продолжается, поскольку современные модели требуют огромных вычислительных ресурсов, а исследователи стремятся найти методы, которые позволят повысить уровень рассуждений ИИ без чрезмерных затрат. Google DeepMind дала роботам ИИ, с которым они могут выполнять сложные задания без предварительного обучения
12.03.2025 [20:41],
Сергей Сурабекянц
Лаборатория Google DeepMind представила две новые модели ИИ, которые помогут роботам «выполнять более широкий спектр реальных задач, чем когда-либо прежде». Gemini Robotics — это модель «зрение-язык-действие», способная понимать новые ситуации без предварительного обучения. А Gemini Robotics-ER компания описывает как передовую модель, которая может «понимать наш сложный и динамичный мир» и управлять движениями робота. 
Источник изображений: Google DeepMind Модель Gemini Robotics построена на основе Gemini 2.0, последней версии флагманской модели ИИ от Google. ПО словам руководителя отдела робототехники Google DeepMind Каролины Парада (Carolina Parada), Gemini Robotics «использует мультимодальное понимание мира Gemini и переносит его в реальный мир, добавляя физические действия в качестве новой модальности». Новая модель особенно сильна в трёх ключевых областях, которые, по словам Google DeepMind, необходимы для создания по-настоящему полезных роботов: универсальность, интерактивность и ловкость. Помимо способности обобщать новые сценарии, Gemini Robotics лучше взаимодействует с людьми и их окружением. Модель способна выполнять очень точные физические задачи, такие как складывание листа бумаги или открывание бутылки.  «Хотя в прошлом мы уже достигли прогресса в каждой из этих областей по отдельности, теперь мы приносим [резко] увеличивающуюся производительность во всех трёх областях с помощью одной модели, — заявила Парада. — Это позволяет нам создавать роботов, которые более способны, более отзывчивы и более устойчивы к изменениям в окружающей обстановке». Модель Gemini Robotics-ER разработана специально для робототехников. С её помощью специалисты могут подключаться к существующим контроллерам низкого уровня, управляющим движениями робота. Как объяснила Парада на примере упаковки ланч-бокса — на столе лежат предметы, нужно определить, где что находится, как открыть ланч-бокс, как брать предметы и куда их класть. Именно такой цепочки рассуждений придерживается Gemini Robotics-ER.  Разработчики уделили серьёзное внимание безопасности. Исследователь Google DeepMind Викас Синдхвани (Vikas Sindhwani) рассказал, как лаборатория использует «многоуровневый подход», при котором модели Gemini Robotics-ER «обучаются оценивать, безопасно ли выполнять потенциальное действие в заданном сценарии». Кроме того, Google DeepMind разработала ряд эталонных тестов и фреймворков, чтобы помочь дальнейшим исследованиям безопасности в отрасли ИИ. В частности, в прошлом году лаборатория представила «Конституцию робота» — набор правил, вдохновлённых «Тремя законами робототехники», сформулированными Айзеком Азимовым в рассказе «Хоровод» в 1942 году. В настоящее время Google DeepMind совместно с компанией Apptronik разрабатывает «следующее поколение человекоподобных роботов». Также лаборатория предоставила доступ к своей модели Gemini Robotics-ER «доверенным тестировщикам», среди которых Agile Robots, Agility Robotics, Boston Dynamics и Enchanted Tools. «Мы полностью сосредоточены на создании интеллекта, который сможет понимать физический мир и действовать в этом физическом мире, — сказала Парада. — Мы очень рады использовать это в нескольких воплощениях и во многих приложениях для нас».  Напомним, что в сентябре 2024 года исследователи из Google DeepMind продемонстрировали метод обучения, позволяющий научить робота выполнять некоторые требующие определённой ловкости действия, такие как завязывание шнурков, подвешивание рубашек и даже починка других роботов. Google анонсировала видеочат с Gemini: ИИ-помощник сможет понять, что происходит вокруг пользователя
03.03.2025 [17:41],
Павел Котов
Google представила на выставке MWC 2025 дуэт функций Project Astra: уже в марте пользователи помощника с искусственным интеллектом Gemini получат возможность демонстрировать ему экран смартфона или транслировать видео с камеры. 
Источник изображений: youtube.com/@Google В интерфейсе Gemini на Android, позволяющем выводить элементы управления поверх других приложений, появится новая кнопка «Поделиться экраном с Live» (Share screen with Live) над текстовым полем «Спросить Gemini» (Ask Gemini). Открыв ИИ-помощнику изображение экрана, пользователь попадает в интерфейс телефонного звонка и начинает диалог с Gemini. Можно задавать ИИ вопросы о том, что изображено на экране, и вести полноценный разговор.  В полноэкранном формате Gemini Live можно выбрать также кнопку трансляции видео, расположенную рядом с кнопкой запуска демонстрации экрана, — видео транслируется почти на весь дисплей. Google немного уменьшила размеры кнопок Gemini Live — из круглых они стали вытянутыми по горизонтали и более компактными. Об этих функциях компания рассказала в мае минувшего года на конференции Google I/O 2024, более подробно остановилась на них в декабре на презентации Gemini 2.0, некоторые возможности также демонстрировались в январе на презентации смартфонов Samsung Galaxy S25. Первыми воспользоваться функциями Gemini Live уже в марте смогут владельцы Android-устройств и подписки Gemini Advanced. ИИ Gemini пропал из приложения Google для iOS
19.02.2025 [17:01],
Дмитрий Федоров
Компания Google завершила процесс переноса ИИ Gemini в отдельное приложение для iOS и официально отключила поддержку ассистента в основном приложении Google для iPhone. Теперь для работы с ИИ необходимо установить приложение Gemini из Apple App Store, которое обеспечивает доступ ко всем функциям ИИ, включая поддержку Gemini Live и генерацию изображений с помощью Imagen 3. 
Источник изображений: Google Ещё в ноябре 2024 года компания представила самостоятельное приложение Gemini для iOS. Несмотря на это, до настоящего момента пользователи могли продолжать работать с Gemini через приложение Google. После отключения поддержки Gemini в приложении Google при попытке воспользоваться сервисом пользователи видят сообщение, призывающее установить основную программу. Самостоятельное приложение Gemini для iOS предлагает весь спектр знакомых функций, а также ряд новых возможностей. Важным нововведением стала поддержка генератора изображений с искусственным интеллектом Imagen 3, позволяющего пользователям создавать изображения высокого качества за считанные секунды. Кроме того, голосовой помощник Gemini Live теперь доступен на нескольких языках, что расширяет его возможности общения с человеком.  Последнее обновление Gemini для iOS — версия 1.2025.0570102 — добавило расширенные функции интеграции с сервисами Google. Теперь пользователи могут, не выходя из приложения, прокладывать маршруты в Google Maps, просматривать рекомендованные видео в YouTube и работать с письмами в Gmail. Такой подход делает ИИ более универсальным инструментом, глубже интегрированным в экосистему Google. Отказ от поддержки Gemini в приложении Google для iOS обусловлен стремлением компании централизовать доступ к своему ИИ-ассистенту. Разделение функциональности позволяет Google гибко развивать продукт, оперативно выпускать обновления и внедрять новые технологии без ограничений, связанных с интеграцией в сторонние сервисы. Кроме того, отдельное приложение открывает перспективы монетизации ИИ, включая возможное введение подписочных моделей для расширенной функциональности. Этот шаг Google следует рассматривать в контексте растущей конкуренции на рынке ИИ. Компания активно развивает свои технологии, соперничая с Apple, Microsoft и OpenAI. Перенос Gemini в отдельное приложение может упростить дальнейшие обновления, ускорить внедрение новых функций и повысить конкурентоспособность продукта, особенно в сравнении с ChatGPT компании OpenAI и возможными будущими ИИ-решениями Apple для Siri. Google обновила Gemini: ИИ-помощник начал запоминать прошлые разговоры
14.02.2025 [05:13],
Дмитрий Федоров
Google представила новую функцию для своего ИИ-помощника Gemini, которая позволяет запоминать предыдущие беседы и использовать этот контекст в ответах. Обновление доступно подписчикам Google One AI Premium и даёт им возможность продолжать диалог c ИИ без необходимости напоминания деталей. Новая функция уже работает в веб-версии и мобильном приложении Gemini на английском языке, а поддержка других языков и интеграция с Google Workspace ожидаются в ближайшие недели. 
Источник изображения: Google Помимо запоминания контекста, новая функция позволяет пользователям запрашивать краткие итоги предыдущих бесед, что упрощает работу с информацией и делает Gemini более удобным инструментом для долгосрочных задач, требующих последовательного анализа данных. Например, пользователи могут отслеживать изменения в своих запросах или быстро восстанавливать в памяти обсуждённые ранее идеи. Ранее Google внедрила механизм запоминания пользовательских предпочтений, однако теперь ИИ-помощник способен учитывать не только разрозненные параметры, но и целостную структуру диалогов, что позволяет строить работу на основе накопленного контекста. Пользователи могут управлять историей взаимодействий с Gemini в любое время. Для этого достаточно открыть профиль в приложении, перейти в раздел «Gemini Apps Activity» и выбрать нужные параметры: просмотр, удаление или полную очистку сохранённых данных. Такой подход позволяет гибко контролировать, какие аспекты общения с ИИ остаются в памяти чат-бота, а какие подлежат удалению. Это не только повышает уровень персонализации, но и даёт возможность регулировать степень конфиденциальности данных. Функция запоминания уже доступна подписчикам Google One AI Premium, однако пока только на английском языке. В ближайшие недели Google планирует расширить её поддержку, добавив новые языки, а также интегрировать этот механизм в корпоративные тарифные планы Google Workspace Business и Enterprise. Хотя точные сроки запуска функции на других языках не называются, очевидно, что компания стремится сделать своего ИИ-помощника более универсальным и полезным для широкой аудитории. Подобные технологии уже применяются в других ИИ-чат-ботах, включая ChatGPT, который также способен запоминать детали прошлых разговоров и учитывать предпочтения пользователей. Однако подход Google сосредоточен на глубокой интеграции с экосистемой её сервисов, таких как Google Workspace. Это может дать дополнительные преимущества корпоративным клиентам, которым важны непрерывность рабочих процессов и возможность использования ИИ в структурированных деловых задачах. Конкуренция на рынке ИИ-ассистентов усиливается, и благодаря этому обновлению Gemini становится ещё более гибким инструментом для работы с накопленной информацией. Крупнейшие IT-компании США потратят более $300 млрд на развитие ИИ в 2025 году
08.02.2025 [06:00],
Анжелла Марина
Ведущие технологические компании США продолжают наращивать расходы на развитие искусственного интеллекта (ИИ), несмотря на рыночные риски. Капитальные затраты в 2024 году Microsoft, Alphabet, Amazon и Meta✴ достигли в совокупности рекорда в $246 млрд, что на 63 % больше, чем годом ранее. В 2025 году эти вложения могут превысить $320 млрд. 
Источник изображения: Copilot Основные средства будут направлены на строительство дата-центров и закупку специализированных чипов для разработки больших языковых моделей (LLM), а лидером по объёму инвестиций станет компания Amazon, которая запланировала вложить на эти цели более $100 млрд, сообщает Financial Times. Однако увеличение расходов на ИИ вызвало обеспокоенность инвесторов. Рынок отреагировал на масштабные инвестиционные планы, объявленные наряду с финансовыми результатами за четвёртый квартал. После публикации отчётов о более слабом, чем ожидалось, росте облачных подразделений и увеличении капитальных расходов, рыночная стоимость Microsoft и Alphabet (материнская компания Google) снизилась у каждой на $200 млрд. Инвесторы выражают обеспокоенность тем, что удвоение расходов на ИИ без соразмерного увеличения доходов может привести к сокращению капитала, который мог бы быть направлен на выкуп акций и выплату дивидендов, а также к недофинансированию других направлений бизнеса. Тем более, что компании пока не предоставили чётких данных о доходах от новых ИИ-продуктов, например, таких как Gemini и Copilot. При этом, появление инновационной и недорогой ИИ-модели R1 китайского стартапа DeepSeek в начале января ещё сильнее усилило опасения инвесторов. Заявление DeepSeek о создании модели, сопоставимой по возможностям с продуктами Google и OpenAI, но при этом значительно более дешёвой, моментально привело к падению акций производителя чипов Nvidia на 17 %. Несмотря на давление со стороны акционеров, генеральные директора крупнейших IT-компаний продолжают отстаивать свои стратегии. Так, Сундар Пичаи (Sundar Pichai) из Google заявил, что планирует увеличить расходы компании на 42 % вплоть до $75 млрд в 2025 году, назвав ИИ «возможностью столетия». Глава Microsoft Сатья Наделла (Satya Nadella) подтвердил намерение вложить $80 млрд в развитие облачного сервиса Azure, а генеральный директор Amazon Энди Джесси (Andy Jassy) объявил, что компания инвестирует в ИИ более $100 млрд. Meta✴, напротив, получила положительную реакцию рынка. Её акции выросли, несмотря на обещание Марка Цукерберга (Mark Zuckerberg) вложить «сотни миллиардов» долларов в ИИ. Отмечается, что успех компании связан с тем, что её технологии уже приносят хорошую отдачу — например, при использование ИИ для улучшения таргетинга рекламы на Facebook✴ и Instagram✴. Для сравнения, Google наоборот сталкивается с трудностями в интеграции ИИ в свой поисковик, где новые функции, такие как «ИИ-обзоры», потенциально, по мнению экспертов, вредят традиционной рекламной модели компании. Стоит сказать, что ажиотаж вокруг ИИ не ограничивается публичными компаниями. Сэм Альтман (Sam Altman) из OpenAI заключил партнёрство с SoftBank и Oracle для инвестирования $100 млрд в инфраструктуру, связанную с ИИ в США, с потенциальным увеличением до полутриллиона долларов в будущем. «Может ли в какой-то момент наступить зима ИИ? Конечно, — сказал Риши Джалурия (Rishi Jaluria), аналитик из RBC Capital Markets. — Но если вы находитесь в положении лидера, вы просто не можете сбавлять обороты». Google развернула модель Gemini Flash 2.0 для всех пользователей
01.02.2025 [19:12],
Павел Котов
Google развернула нейросеть Gemini Flash 2.0 для всех пользователей приложения Gemini на настольных компьютерах и мобильных устройствах — по сведениям ресурса ZDNET, на практике десктопная версия обновляется быстрее. 
Источник изображения: blog.google Модель Gemini 2.0 Flash имеет более высокую производительность и даёт более быстрые ответы в сравнении с предшественницей, утверждает Google; чат-бот готов помочь с такими задачами как написание текстов, участие в мозговом штурме и помощь с обучающими материалами, а работа с ним стала более комфортной. Обновлённый вариант системы теперь лучше реагирует на загружаемые изображения — другие типы файлов пользователи бесплатной версии отправлять не могут. Экспериментальный вариант модели Gemini 2.0 Flash компания Google представила в конце прошлого года, охарактеризовав её как «рабочую лошадку с низкой задержкой» — она, по словам создателя, справляется с написанием программного кода, решением математических задач и рассуждениями, работая вдвое быстрее предшественницы — Gemini 1.5 Flash. Ранее Google Gemini 2.0 Flash была доступна только подписчикам Gemini Advanced за $19,99 в месяц — для них открыто контекстное окно в 1 млн токенов (1500 страниц текста), приоритетный доступ к функциям Deep Research и Gems, 2 Тбайт хранилища Google One и возможность загрузки репозитория кода. Модели Gemini 1.5 Flash и 1.5 Pro пока продолжат работу в ближайшие недели. Google также объявила, что завершила развёртывание модели Imagen 3 в генераторе изображений Gemini для всех пользователей. Эта модель предлагает улучшенную детализацию, более качественные эффекты освещения и уменьшенное число артефактов. Google: хакеры из России, Ирана и других стран не преуспели в привлечении ИИ Gemini к своей деятельности
30.01.2025 [11:44],
Павел Котов
Хакерские группировки, предположительно связанные с Ираном, Северной Кореей, Китаем и Россией, пытались использовать искусственный интеллект Google Gemini для развёртывания различных атак. Значительного успеха киберпреступникам добиться не удалось, но система помогла им автоматизировать некоторые задачи, рассказали в Google. 
Источник изображения: Kevin Ku / unsplash.com «Хотя ИИ может оказаться полезным средством для злоумышленников, он пока не настолько меняет правила игры, как его порой изображают», — говорится в блоге Google. Хакеры смогли использовать возможности Gemini в противоправных целях: для перевода контента, совершенствования фишинговых атак и написания программного кода. Наиболее активными пользователями Gemini оказались киберпреступники, связанные, по версии Google, с Ираном. Они применяли ИИ для изучения организаций в оборонной отрасли, исследования уязвимостей и генерации контента для фишинговых кампаний. Использовать Gemini для непосредственного взлома систем у них не получилось, но автоматизировать некоторые свои задачи злоумышленники всё-таки смогли: ИИ помог им в исследованиях, разъяснении сложных концепций, создании и отладке кода. При попытке применить систему для захвата учётных записей или взлома самого Gemini сработали защитные механизмы. Система отказалась подготовить руководство по неправомерному использованию продуктов Google, разработать продвинутые методы фишинга, помочь в создании средств кражи информации из браузера Chrome и методов обхода средств проверки при регистрации учётных записей в Google. Gemini не стал создавать вредоносное ПО или другой контент, который можно было бы использовать при реализации атак. Но всё-таки ИИ помог киберпреступникам повысить качество перевода пропагандистских материалов, сопроводительных писем для связи со специалистами через профессиональную соцсеть LinkedIn и получения информации об обмене работниками за рубежом. Схожий доклад в прошлом году опубликовали Microsoft и OpenAI: киберпреступники смогли автоматизировать часть своих задач при помощи ИИ, но не добились каких-то прорывов. В Google заявили, что внимательно изучают случаи злоупотребления продуктами компании, стремятся пресекать подобные инциденты и при необходимости привлекают правоохранительные органы. Google упростила управление умным домом — Google Home получил ИИ-помощника Gemini
24.01.2025 [10:45],
Павел Котов
Управление умным домом в экосистеме Google через помощника с искусственным интеллектом Gemini стало доступно для всех пользователей. Ассистент позволяет настраивать умное освещение, климатическую систему в доме, умные колонки и другие совместимые устройства в учётной записи Google. 
Источник изображения: blog.google Масштабное обновление платформы умного дома Google анонсировала в ноябре. Теперь для управления его функциями можно отдавать команды естественным языком: услышав фразу «солнце в гостиной светит слишком ярко», система закроет жалюзи. ИИ Gemini способен выполнять несколько запросов сразу — можно сказать, например: «Включи свет у кресла, но приглуши лампу на кухне». Помощнику также можно задавать вопросы о статусе устройств, например, включён ли свет на крыльце. Управление «некритическими» устройствами умного дома, такими как светильники, вынесено на экран блокировки телефона. Появилась возможность регулировать громкость, приостанавливать и возобновлять воспроизведение на умных колонках, дисплеях и умных телевизорах прямо в приложении Gemini; здесь же появился интерфейс управления климатической системой, повторяющий дизайн соответствующего раздела Google Home. При обращении к камерам наблюдения и замкам помощник с ИИ теперь автоматически открывает приложение Google Home. Развёртывание новых функций начинается сегодня, но будет происходить постепенно — у всех пользователей экосистемы они появятся «в ближайшие недели». Google заявила, что её ИИ самый лучший в мире — осталось убедить людей им пользоваться
17.01.2025 [02:12],
Анжелла Марина
Компания Google утверждает, что является лидером в области разработки технологии искусственного интеллекта, и её ИИ-модель Gemini превосходит возможности конкурентов. Однако по количеству пользователей ChatGPT вышел вперёд. В настоящее время, количество активной аудитории Gemini не разглашается, в то время как ChatGPT еженедельно посещают 300 миллионов пользователей. 
Источник изображения: Solen Feyissa / Unsplash Несмотря на то, что Google является одним из пионеров в области искусственного интеллекта (ИИ), компания была застигнута врасплох запуском ChatGPT в конце 2022 года. С тех пор Google активно работает в этом направлении, внедряя новые функции и стремясь занять лидирующие позиции. Недавно технология Gemini даже обошла OpenAI в рейтингах Chatbot AI. Однако приложение Gemini по-прежнему отстаёт от ChatGPT по количеству скачиваний — 106 миллионов против 465 миллионов, сообщает The Wall Street Journal, ссылаясь на статистику App Store. Отмечается, что хотя Gemini пока не приносит значительных доходов, предлагая премиум-версию чат-бота по подписке за $20 в месяц, однако является ключевым элементом стратегии Google в области ИИ, влияя на основные направления бизнеса, такие как поиск и реклама. Также, несмотря на то, что в платной версии добавлены различные бонусы и 2 Тбайт облачного хранилища, не все пользователи выбирают подписку ради самого ИИ. Например, специалист по данным из Филадельфии Сифэй Хан (Sifei Han) отметил, что в Gemini ценит дополнительные возможности хранения, но предпочитает стиль ChatGPT. Согласно данным аналитической компании из США Earnest Analytics, около 60 % платных пользователей Gemini сохраняют подписку спустя шесть месяцев после её оформления. Этот показатель лучше, чем у некоторых конкурентов, таких как Character.AI и Perplexity, но всё же уступает OpenAI и Anthropic. Стоит сказать, что технология Gemini уже используется в различных продуктах Google, включая «обзоры ИИ» (AI overviews) в поисковой выдаче, в бизнес-версиях Gmail и Google Drive. Компания также активно продвигает Gemini в качестве помощника по умолчанию на мобильных устройствах, в том числе на своих телефонах Pixel и на устройствах Motorola и OnePlus. ИИ в Gmail, «Документах» и прочих сервисах Google стал бесплатным, но подписка Workspace подорожала
15.01.2025 [19:28],
Сергей Сурабекянц
Ранее для использования всех функций ИИ в Gmail, «Документах», «Таблицах», Meet и остальных приложениях Google Workspace, требовалось оплатить тарифный план Gemini Business за $20 в месяц для каждого пользователя. С 14 января этот тарифный план стал бесплатным — Google добавила все функции ИИ в Workspace, стремясь не проиграть в конкурентной борьбе с Microsoft, OpenAI и другими в создании офисного пакета будущего на базе ИИ. 
Источник изображения: techspot.com Однако в этой бочке мёда имеется и ложка дёгтя — одновременно с отменой платы за ИИ-функции Google повысила цену на все варианты подписки Workspace. Компаниям придётся в среднем платить примерно на $2 в месяц больше за каждого пользователя Workspace. Конечно, контракты крупных компаний могут предусматривать другие условия, но базовая цена подписки выросла с $12 до $14 в месяц. ИИ-функции Workspace включают доступ к чат-боту Gemini, сводки электронной почты в Gmail, дизайны для электронных таблиц и видео, автоматизированный конспект для совещаний, мощный помощник по исследованиям NotebookLM и инструменты для письма в приложениях. По словам президента Google по облачным приложениям Джерри Дишлера (Jerry Dischler), Google предлагает наиболее вертикально интегрированный ИИ-продукт, но это имеет значение только в том случае, если люди используют всю систему. «В большинстве случаев, когда мы общаемся с компаниями, которые используют ИИ, главным препятствием становятся соображения стоимости, — говорит он. — Вот почему они так осторожно подходят к этому. Типа: “Ого, это куча денег, и давайте докажем ценность”. Хорошо, теперь вы получаете ИИ [бесплатно]. У вас есть ценность». Google не единственная компания, которая отказалась от наценки за ИИ: в ноябре 2024 года Microsoft объявила, что функции ИИ Copilot Pro, которые ранее стоили $20 в месяц, станут частью стандартной подписки Microsoft 365. Другие поставщики решений ИИ также делают ставку на то, что «бесплатный» доступ к ИИ окупится в долгосрочной перспективе. Google применила конкурирующего ИИ-бота Anthropic Claude для улучшения своих нейросетей Gemini
26.12.2024 [11:32],
Владимир Мироненко
Контрактные партнёры Google, работающие над повышением качества ответов ИИ-чат-бота Google Gemini, сравнивают их с ответами конкурирующего чат-бота Claude компании Anthropic, пишет ресурс TechCrunch со ссылкой на внутреннюю переписку компании. При этом Google оставила без ответа вопрос TechCrunch по поводу того, получила ли она разрешение на использование Claude в тестировании с Gemini. 
Источник изображения: Google Эффективность разрабатываемых ИИ-моделей в сравнении с разработками конкурентов компании зачастую оценивают, используя отраслевые бенчмарки, а не поручая подрядчикам сравнивать с возможностями ИИ своих конкурентов. Привлечённые Google контрактные разработчики, занимающиеся улучшением Gemini, должны оценивать каждый ответ модели по нескольким критериям, таким как достоверность и уровень детализации. Согласно переписке, опубликованной TechCrunch, им выделяется до 30 минут на каждый запрос, чтобы определить, чей ответ лучше — Gemini или Claude. Разработчики сообщают, что в ответах Claude больше внимания уделяется безопасности, чем у Gemini. «Настройки безопасности у Claude самые строгие» среди моделей ИИ, отметил один из контрактных разработчиков в служебном чате. В некоторых случаях Claude не реагировал на подсказки, которые он считал небезопасными, например, предложение ролевой игры с другим ИИ-помощником. В другом случае Claude уклонился от ответа на подсказку, в то время как ответ Gemini был отмечен как «грубое нарушение правил безопасности», поскольку включал «обнажение тела и связывание». Шира Макнамара (Shira McNamara), представитель Google DeepMind, разработчика Gemini, не ответила на вопрос TechCrunch о том, получила ли Google разрешение Anthropic на использование Claude. Она уточнила, что DeepMind «сравнивает результаты моделирования» для оценки, но не обучает Gemini работе с моделями компании Anthropic. «Любое предположение о том, что мы использовали модели Anthropic для обучения Gemini, является неточным», — заявила Макнамара. Google показала ИИ-агента, который помогает проходить игры, наблюдая за действиями игрока
12.12.2024 [01:54],
Анжелла Марина
Google представила новую версию платформы искусственного интеллекта Gemini 2.0, с помощью которой можно создавать ИИ-агентов для советов и подсказок в видеоиграх. Агенты способны анализировать игровой процесс и предлагать оптимальные стратегии, а пользователи смогут получать рекомендации в режиме реального времени. 
Источник изображения: Supercell, theverge.com Как сообщают в блоге компании генеральный директор Google DeepMind Демис Хассабис (Demis Hassabis) и технический директор Корай Кавукчуоглу (Koray Kavukcuoglu), агенты «делают выводы об игре, основываясь исключительно на действиях на экране, и предлагают решения в режиме реального времени». Кроме того, они могут использовать поиск Google по базам знаний для предоставления более полной информации. Агенты уже тестируются в популярных играх, таких как Clash of Clans и Hay Day от Supercell. Однако, как пишет The Verge, технология находится на ранней стадии разработки, и пока не ясно, насколько полезными такие наставники окажутся для игроков. Помимо помощи в видеоиграх, Google развивает и другие направления применения Gemini 2.0. Например, ведётся работа над проектом Genie 2, который создаёт виртуальные игровые миры на основе лишь одного изображения. Пока эти миры остаются стабильными только около минуты, однако эксперты видят большой потенциал технологии. Также компания представила мультимодальные возможности Gemini 2.0 Flash, которые уже доступны разработчикам через API в Google AI Studio и Vertex AI. Новая версия отличается высокой скоростью работы, улучшенной обработкой данных и способностью генерировать изображения и текст, а также преобразовывать текст в речь на нескольких языках. Эти функции уже тестируются ранними партнёрами, а в январе платформа станет доступна широкой аудитории. Среди других проектов можно выделить Project Astra, Mariner и Jules. Project Astra, созданный для использования на Android-устройствах, был улучшен с помощью Gemini 2.0. Теперь ассистент на базе Astra может разговаривать на нескольких языках, использовать Google Search, Maps и Lens, а также запоминать больше данных, сохраняя при этом конфиденциальность. Project Mariner исследует, как ИИ может помогать в браузере, распознавая текст, изображения, код и другие элементы интерфейса, а Jules предназначен для помощи разработчикам в их рабочих процессах на GitHub. ИИ-агенты также могут применяться в физическом мире. Исследования Google показывают, что Gemini 2.0 способен использовать пространственное мышление в робототехнике. Хотя эти разработки находятся на ранней стадии, сама компания видит большой потенциал в создании агентов, которые способны взаимодействовать с реальной средой. Чтобы минимизировать риски и обеспечить безопасность своих ИИ-сервисов, компания проводит масштабные тестирования, сотрудничает с доверенными тестировщиками и внешними экспертами. В ближайшем будущем Google планирует интегрировать возможности Gemini 2.0 во все свои продукты, включая мобильное приложение Gemini. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться