|
Опрос
|
реклама
Быстрый переход
Глава OpenAI раскрыл планы по выпуску GPT-5
13.02.2025 [00:14],
Андрей Созинов
Генеральный директор OpenAI Сэм Альтман (Sam Altman) подробно рассказал о планах компании в отношении грядущих моделей искусственного интеллекта GPT-4.5 и GPT-5. 
Источник изображения: OpenAI В своём посте в соцсети X Альтман признал, что линейка продуктов OpenAI стала сложной, и сказал, что компания хочет провести работу по упрощению своих предложений. «Мы ненавидим подборщик моделей так же, как и вы, и хотим вернуться к магическому унифицированному [искусственному] интеллекту», — написал Альтман. Компания планирует выпустить GPT-4.5, которая, по словам Альтмана, получила внутреннее название Orion и станет «последней нерассуждающей моделью OpenAI». Напомним, OpenAI обучила модель Orion в октябре прошлого года, а позже стало известно, что компания столкнулась с большими расходами и нехваткой данных при её обучении. После выпуска GPT-4.5 «наша главная цель — унифицировать модели серии "o" и модели серии GPT, создав системы, которые могут использовать все наши инструменты, которые будут понимать, когда нужно долго думать, а когда нет, и вообще быть полезными для очень широкого круга задач», — поделился Альтман. 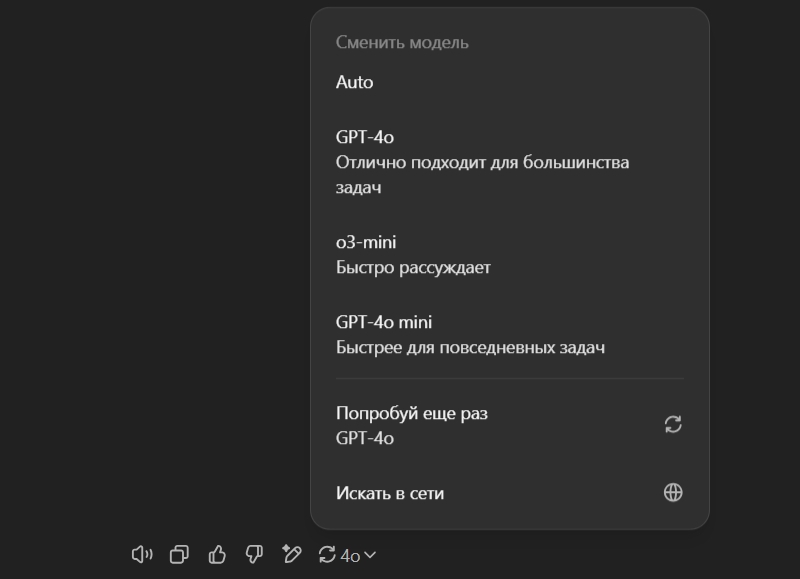 Сейчас бесплатный ChatGPT предлагает три модели ИИ на выбор С помощью ChatGPT и OpenAI API компания планирует «выпустить GPT-5 как систему, объединяющую множество наших технологий, включая o3 (прим. ред. — o3 является самой продвинутой ИИ-моделью OpenAI на данный момент)», — говорит Альтман, добавляя, что «мы больше не будем поставлять o3 как отдельную модель». OpenAI представила o3 в декабре и запустила o3-mini в январе. Альтман рассказал, что после запуска GPT-5 пользователи бесплатного ChatGPT получат «неограниченный доступ к GPT-5 на стандартных настройках интеллекта», но с некими ограничениями для защиты от злоупотреблений. В свою очередь платные подписчики на тарифе Plus смогут использовать GPT-5 на «более высоком уровне интеллекта», а подписчики Pro получат «еще более высокий уровень интеллекта». Альтман не уточнил, когда именно выйдут GPT-4.5 и GPT-5, но отметил, что это займёт «недели/месяцы». OpenAI не удаётся доделать GPT-5 Orion — обучение обходится дорого, а данных не хватает
21.12.2024 [18:05],
Павел Котов
OpenAI отстаёт от графика разработки флагманской модели искусственного интеллекта последней версии — она получит название GPT-5, а пока проходит под кодовым именем Orion. Компания занимается этим уже 18 месяцев, пытаясь выйти на желаемый результат, но терпит неудачи — во всём мире не хватает данных, чтобы сделать модель достаточно умной, пишет Wall Street Journal. 
Источник изображения: Mariia Shalabaieva / unsplash.com OpenAI провела как минимум два больших учебных запуска, каждый из которых предполагает несколько месяцев обработки данных с целью доделать Orion. Всякий раз возникали новые проблемы, и система не давала результатов, на которые надеялись исследователи. В теперешнем виде Orion работает лучше существующих систем OpenAI, но, по версии разработчиков, она недостаточно продвинулась, чтобы оправдать огромные затраты на поддержание новой модели в рабочем состоянии. Обучение продолжительностью шесть месяцев может обойтись примерно в $500 млн только на вычислительные затраты. Два года назад OpenAI и её гендиректор Сэм Альтман (Sam Altman) произвели фурор с выпуском ChatGPT. Тогда казалось, что ИИ проникнет во все аспекты жизни современного человека и существенно её улучшит. Аналитики предсказали, что в ближайшие годы затраты технологических гигантов на ИИ составят до $1 трлн. Самая большая ответственность возлагается на OpenAI, которая и породила бум ИИ. Октябрьский раунд финансирования компании проводился при оценке $157 млрд — не в последнюю очередь из-за того, что Альтман пообещал «значительный скачок вперёд» по всех областях и задачах с GPT-5. Модель, как ожидается, будет совершать научные открытия и с лёгкостью выполнять повседневные человеческие задачи, такие как запись на приём и бронирование билетов на самолёт. Исследователи также надеются, что она научится сомневаться в собственной правоте и станет реже «галлюцинировать» — прекратит уверенно давать не соответствующие действительности ответы. Если принять, что GPT-4 действует на уровне умного старшеклассника, то от GPT-5 в отдельных задачах ждут уровня доктора наук. Чётких критериев определить, достойна ли модель нового поколения называться GPT-5, не существует: системы тестируются на задачах по математике и программированию, но окончательный вердикт исследователи выносят на интуитивном уровне, и этого до сих пор не произошло. Про разработку больших языковых моделей говорят, что это не только наука, но и искусство. 
Источник изображения: Growtika / unsplash.com Тестирование моделей производится во время тренировочных запусков — продолжительных периодов, в которые им отправляются триллионы токенов, то есть фрагментов слов. Крупный тренировочный запуск может потребовать нескольких месяцев работы дата-центров и десятков тысяч ИИ-ускорителей Nvidia. Обучение GPT-4, по словам Альтмана, обошлось в $100 млн; как ожидается, обучение будущих моделей будет стоить дороже $1 млрд. Неудачный тренировочный запуск в чём-то схож с неудачным испытанием ракеты. Исследователи стараются снижать вероятность таких неудач, проводя эксперименты в меньших масштабах — пробные запуски перед полномасштабными. В середине 2023 года OpenAI провела пробный учебный запуск, который стал тестом для вероятной архитектуры Orion — особых результатов эксперимент не принёс: стало ясно, что полномасштабный учебный запуск займёт слишком много времени и обойдётся очень дорого. Результаты проекта Arrakis показали, что создание GPT-5 пойдёт не так гладко, как надеялись исследователи. Они начали вносить некоторые технические изменения, чтобы усилить Orion, и пришли к выводу, что потребуется большой объём разнообразных высококачественных данных, и информации из общедоступного интернета может не хватить. Модели ИИ, как правило, становятся умнее по мере того, как поглощают большие объёмы данных — обычно книг, академических публикаций и других заслуживающих доверия источников, которые помогают ИИ выражаться более чётко и справляться с широким спектром задач. При обучении предыдущих моделей OpenAI не пренебрегала и другими источниками, такими как новостные статьи и даже сообщения в соцсетях. Но чтобы сделать Orion умнее, необходимы дополнительные источники данных, и их недостаточно. Тогда в компании решили создавать эти данные самостоятельно: наняли людей для написания кода и решения математических задач, которые давали пошаговые объяснения своих действий. OpenAI привлекла специалистов по теоретической физике, которые подготовили объяснения, какой подход они бы применили к решению сложнейших проблем в своей области. Процесс идёт чрезвычайно медленно. GPT-4 была обучена на 13 трлн токенов — для сравнения, тысяча человек, которые пишут по пять тысяч знаков в день, сгенерировала бы миллиард токенов за несколько месяцев. Поэтому в OpenAI начали разрабатывать синтетические данные — заставлять другие системы ИИ генерировать данные для обучения нового ИИ. Но исследования показали, что циклы обратной связи между генерацией данных с помощью ИИ для ИИ грозят сбоями или бессмысленными ответами. Для устранения этой проблемы генерацию данных доверили другой модели — o1. 
Источник изображения: Mariia Shalabaieva / unsplash.com К началу 2024 года руководство OpenAI стало понимать, что сроки поджимают. GPT-4 исполнился год, конкуренты стали догонять, а новая модель Anthropic, по некоторым оценкам, её превзошла. Проект Orion застопорился, и OpenAI пришлось переключиться на другие проекты и приложения: вышли облегчённый вариант GPT-4 и генератор видео Sora. В результате возникла внутренняя конкуренция — за ограниченные вычислительные ресурсы состязались разработчики Orion и прочих продуктов. Конкуренция же среди разработчиков ИИ ожесточилась до такой степени, что крупные технологические компании стали публиковать меньше статей о последних открытиях или прорывах, чем это принято в научном сообществе. На рынок хлынул поток денег, и корпорации стали рассматривать результаты исследований как коммерческую тайну, которую следует охранять. Дошло до того, что исследователи перестали работать в самолётах, кофейнях и других общественных местах, где кто-то мог заглянуть через плечо. В начале 2024 года OpenAI подготовилась к очередной попытке запуска Orion, вооружившись более качественным набором данных. В течение нескольких первых месяцев года исследователи провели несколько небольших обучающих запусков, чтобы знать, в каком направлении работать дальше. К маю они решили, что готовы провести крупномасштабный запуск Orion, который должен был продлиться до ноября. Но уже на начальном этапе вскрылась связанная с данными проблема: они оказались менее диверсифицированными, чем ожидалось, что ограничило потенциальное качество обучения ИИ. Проблема не проявлялась в пробных проектах и стала очевидной только после того, как начался большой запуск — но к тому времени OpenAI потратила слишком много времени и денег, чтобы начинать всё заново. Исследователи попытались найти более широкий диапазон данных для передачи модели в процессе обучения, но до сих пор неясно, оказалась ли эта стратегия плодотворной. Трудности с Orion указали OpenAI на новый подход к тому, как сделать большие языковые модели умнее — рассуждения. Способность к рассуждениям помогает ИИ решать сложные проблемы, которым он не обучался. Так устроена модель OpenAI o1 — она генерирует несколько ответов на каждый вопрос и анализирует их в поисках лучшего. Но и в этом уверенности пока нет: по мнению исследователей Apple, «рассуждающие» модели, вероятно, лишь интерпретируют полученные при обучении данные, но новых задач в действительности не решают. К примеру, если внести в условиях исходной задачи незначительные изменения, которые не имеют отношения к её решению, качество ответа ИИ резко падает. Эти дополнительные интеллектуальные способности обходятся дорого: OpenAI приходится оплачивать генерацию нескольких ответов вместо одного. «Оказалось, что если бот думает всего 20 секунд в партии в покер, затраты возрастают так же, как если бы модель разрасталась в 100 000 раз и обучалась в 100 000 раз дольше», — рассказал научный сотрудник OpenAI Ноам Браун (Noam Brown). В основу Orion может лечь более продвинутая и эффективная модель, способная к рассуждениям. Исследователи компании придерживаются этого подхода и надеются объединить его с большими объёмами данных, часть из которых может поступать из других моделей ИИ, созданных OpenAI. Затем результаты её работы будут уточняться на материале, созданном людьми. Китайцы обучили аналог GPT-4 всего на 2000 чипов и в 33 раза дешевле, чем OpenAI
15.11.2024 [09:55],
Анжелла Марина
Китайская компания 01.ai разработала конкурентоспособную ИИ-модель Yi-Lightning, которая, как утверждается, по своим возможностям аналогична GPT-4. Но что удивительно, для этого потребовалось всего 2000 графических процессоров (GPU), а затраты составили всего $3 млн, в то время как OpenAI потратила около $100 млн на обучение своей модели, сообщает Tom's Hardware. 
Источник изображения: Copilot Достижение 01.ai особенно примечательно на фоне ограниченного доступа китайских компаний к передовым графическим процессорам Nvidia. Основатель и глава компании Кай-Фу Ли (Kai-Fu Lee) подчёркивает, что несмотря на то, что китайские компании практически не имеют доступ к GPU Nvidia из-за нормативных актов США, ИИ-модель Yi-Lightning заняла шестое место в рейтинге производительности моделей по версии LMSIS Калифорнийского университета в Беркли. 
Источник изображения: Nvidia «Моих друзей в Кремниевой долине шокирует не только наша производительность, но и то, что мы обучили модель всего за $3 млн, — сказал Кай-Фу Ли. — По слухам, в обучение GPT-5 уже вложен примерно 1 миллиард долларов». Он также добавил, что из-за санкций США, компании в Китае вынуждены искать более эффективные и экономичные решения, чего и удалось достичь 01.ai благодаря оптимизации ресурсов и инженерных идей, получив при этом аналогичные GPT-4 результаты при значительно меньших затратах. Вместо того, чтобы наращивать вычислительные мощности, как это делают конкуренты, компания сосредоточилась на оптимизации алгоритмов и сокращении узких мест в процессе обработки информации. «Когда у нас есть только 2000 графических процессоров, мы должны придумать, как их использовать [эффективно] », — сказал Ли. В результате затраты на вывод модели составили всего 10 центов за миллион токенов, что примерно в 30 раз меньше, чем у аналогичных моделей. «Мы превратили вычислительную проблему в проблему памяти, построив многоуровневый кеш, создав специальный механизм вывода и так далее», — поделился подробностями Ли. Несмотря на заявления о низкой стоимости обучения модели Yi-Lightning, остаются вопросы относительно типа и количества используемых GPU. Глава 01.ai утверждает, что у компании достаточно ресурсов для реализации своих планов на полтора года, но простой подсчёт показывает, что 2000 современных GPU Nvidia H100 по текущей цене в $30 000 за единицу обошлись бы в $6 млн, что вдвое превышает заявленные затраты. Это несоответствие вызывает вопросы и требует дальнейших разъяснений. Тем не менее, достижение компании уже привлекло внимание мировой общественности и показало, что инновации в сфере ИИ могут рождаться даже в условиях ограниченных вычислительных ресурсов. «Ничего, что можно было бы назвать GPT-5» — OpenAI дорабатывает GPT-o1, а GPT-5 не появится в 2024 году
03.11.2024 [10:07],
Дмитрий Федоров
Генеральный директор OpenAI Сэм Альтман (Sam Altman) развеял надежды на скорый релиз GPT-5, сообщив, что до конца 2024 года компания сосредоточится на улучшении версии GPT-o1. Сейчас эта версия ориентирована на углублённый анализ и призвана решать специализированные задачи в таких областях, как наука, математика и академические исследования. В планах OpenAI также развитие независимых «ИИ-агентов», способных работать более самостоятельно, без вмешательства человека. 
Источник изображения: alanajordan / Pixabay В ходе общения с пользователями Reddit Альтман пояснил, что выпуск следующей версии ChatGPT, GPT-5, в 2024 году не запланирован. «Мы представим несколько интересных релизов к концу года, но ничего, что можно было бы назвать GPT-5», — заявил он. Вместо этого компания сосредоточится на выпуске версии GPT-o1, созданной для более обдуманного подхода к решению задач. Эта версия ChatGPT, также известная под кодовым названием Project Strawberry, направлена на специализированные сценарии использования, где требуются вдумчивые решения и точные ответы, особенно в научных и академических областях. Альтман отметил, что возросшая сложность современных ИИ-моделей затрудняет параллельную разработку крупных обновлений. Кроме того, OpenAI сталкивается с жёсткими ограничениями и необходимостью трудного выбора при распределении вычислительных ресурсов, что ограничивает возможность компании выпускать несколько крупных релизов ИИ-моделей одновременно. Следующим значительным достижением ChatGPT станут «ИИ-агенты» — системы, способные выполнять задачи автономно, взаимодействуя с внешним миром без участия человека. Альтман пояснил, что такие функции смогут решать конкретные задачи, например, бронировать авиабилеты, покупать билеты на концерты или отвечать на запросы служб поддержки. OpenAI планирует сделать эти возможности важной частью своих ИИ-моделей, что значительно расширит их функциональность. Вице-президент по разработке в OpenAI Сринивас Нараянан (Srinivas Narayanan) рассказал о своём видение будущего ChatGPT, отметив, что в перспективе ИИ-модель сможет лучше понимать личную информацию пользователя и выполнять действия от его имени. Это, по его мнению, значительно расширит функциональность ChatGPT и сделает его инструментом, активно реагирующим на повседневные запросы пользователя. Альтман также намекнул, что в один прекрасный день он может открыть доступ к контенту для взрослых — «Not Safe For Work», который в настоящее время блокируется. «Мы полностью поддерживаем идею уважительного отношения к взрослым пользователям», — отметил он, добавив, что этот вопрос требует серьёзной проработки и что сейчас у OpenAI есть более срочные задачи. Альтман подчеркнул, что компания планирует вернуться к этому вопросу, когда основные задачи будут решены. Амбициозные цели руководства OpenAI предполагают значительные улучшения возможностей её ИИ-моделей. В мае операционный директор компании Брэд Лайткап (Brad Lightcap) заявил, что через год мы будем смеяться над тем, насколько примитивными были предыдущие версии ChatGPT. Хотя выпуск GPT-5 задерживается, OpenAI предлагает пользователям новые ИИ-инструменты. Недавно был запущен ChatGPT Search, позволяющий искать информацию в интернете напрямую через ChatGPT, что раньше требовало обращения к поисковым системам. Гендиректор OpenAI: современный ИИ будет выглядеть неловко на фоне GPT-5
23.05.2024 [17:55],
Павел Котов
Гендиректор OpenAI Сэм Альтман (Sam Altman) в недавнем интервью намекнул, что модель искусственного интеллекта нового поколения GPT-5 настолько превзойдёт существующие решения, что GPT-4 будет выглядеть «слегка неловко». 
Источник изображения: wikipedia.org OpenAI пока не сообщила, когда выпустит очередную модель ИИ серии GPT, но когда это произойдёт, все предыдущие окажутся в крайне невыгодном положении. С момента выпуска популярного ныне чат-бота ChatGPT разработчик оказался в авангарде отрасли ИИ. С тех пор компания выпустила множество других продуктов с ИИ, последним из которых стала модель GPT-4o, которая в сравнении с предшественницами намного лучше справляется с написанием программного кода, а также демонстрирует способность рассуждать, одинаково хорошо воспринимая текст, изображения и звук. Сегодня это впечатляет, но, подчёркивает разработчик, это ничто в сравнении с GPT-5. В недавнем интервью Сэм Альтман коснулся перспективных разработок в области ИИ, заявив, что новая модель может быть похожа на «виртуальный мозг», демонстрируя «более глубокие „мыслительные“ способности». На её фоне GPT-4 будет выглядеть «слегка неловко», поскольку новая нейросеть значительно более мощная, функциональная и «разумная». Альтман также уверен, что GPT-5 станет значительным шагом на пути к появлению сильного ИИ (AGI), соответствующего или превосходящего человеческие возможности в широком круге задач. Через год сегодняшний ChatGPT будет выглядеть смехотворно плохо, заявил директор OpenAI
08.05.2024 [13:51],
Дмитрий Федоров
Брэд Лайткап (Brad Lightcap), главный операционный директор OpenAI, рассказал на Глобальной конференции в Институте Милкена о будущем компании и её планах на следующие 6–12 месяцев. По его мнению, нынешние системы искусственного интеллекта (ИИ), такие как ChatGPT, являются «смехотворно плохими» по сравнению с тем, что ждёт человечество впереди. Он подчеркнул, что будущие версии ИИ будут настолько продвинутыми, что изменят саму суть взаимодействия с пользователями. 
Источник изображения: JuliusH / Pixabay Лайткап описал нынешнюю версию ChatGPT как начальный этап в эволюции ИИ, предназначенного для выполнения простых задач. «Я думаю, что через год мы оглянемся назад и поймём, насколько несовершенными они были», — заявил Лайткап, когда его спросили о бизнесе OpenAI через 6–12 месяцев. В перспективе он предвидит эволюцию ИИ в направлении более сложных задач, где ИИ станет отличным напарником, способным на равных общаться с людьми, как друг или коллега. Кроме технологических аспектов Лайткап прокомментировал социальные последствия развития ИИ. Он опроверг мнение о том, что развитие ИИ приведёт к массовым увольнениям людей, утверждая, что новые ИИ-системы наоборот спровоцируют спрос на ещё не существующие вакансии. По его мнению, экономика станет более разнообразной и устойчивой, а рынок труда адаптируется к технологическим изменениям. В свете этих заявлений интересно, что генеральный директор OpenAI Сэм Альтман (Sam Altman) также высказывался о будущем ChatGPT на семинаре в Стэнфордском университете, назвав GPT-4 самой глупой моделью, с которой людям придётся работать когда-либо в будущем. Такие заявления вероятно намекают на то, что будущие обновления ChatGPT станут переломными и приведут к значительному улучшению функциональности продуктов OpenAI. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться