|
Опрос
|
реклама
Быстрый переход
AMD похвасталась, что Ryzen AI Max+ 395 до 12 раз быстрее в работе с ИИ, чем прямой конкурент от Intel
17.03.2025 [23:03],
Николай Хижняк
Новейший флагманский мобильный процессор AMD Ryzen AI Max+ 395 семейства Strix Halo обеспечивает до 12 раз более высокую производительность в работе с различными большими языковыми моделями ИИ, чем чипы Intel Lunar Lake. Об этом AMD сообщила в своём официальном блоге, поделившись соответствующими диаграммами. 
Источник изображений: AMD Благодаря 16 вычислительным ядрам Zen 5, 40 графическим блокам RDNA 3.5, а также NPU XDNA 2 с производительностью 50 TOPS (триллионов операций в секунду), процессор Ryzen AI Max+ 395 обеспечивает до 12,2 раза более высокое быстродействие в определённых сценариях LLM, чем Intel Core Ultra 258V. Стоит напомнить, что в составе чипа Intel Lunar Lake имеются только четыре P-ядра и четыре E-ядра, что в общей сложности вполовину меньше, чем у Ryzen AI Max+ 395. Однако разница в производительности между платформами выражена гораздо сильнее, чем в два раза.  Преимущество чипа Ryzen AI Max+ 395 становится ещё более заметным с повышением сложности языковых моделей. Наибольшая разница в производительности между платформами видна при работе с LLM с 14 млрд параметров, где требуется больше оперативной памяти. Напомним, что Lunar Lake представляет собой гибридные процессоры, оснащённые до 32 Гбайт набортной ОЗУ. 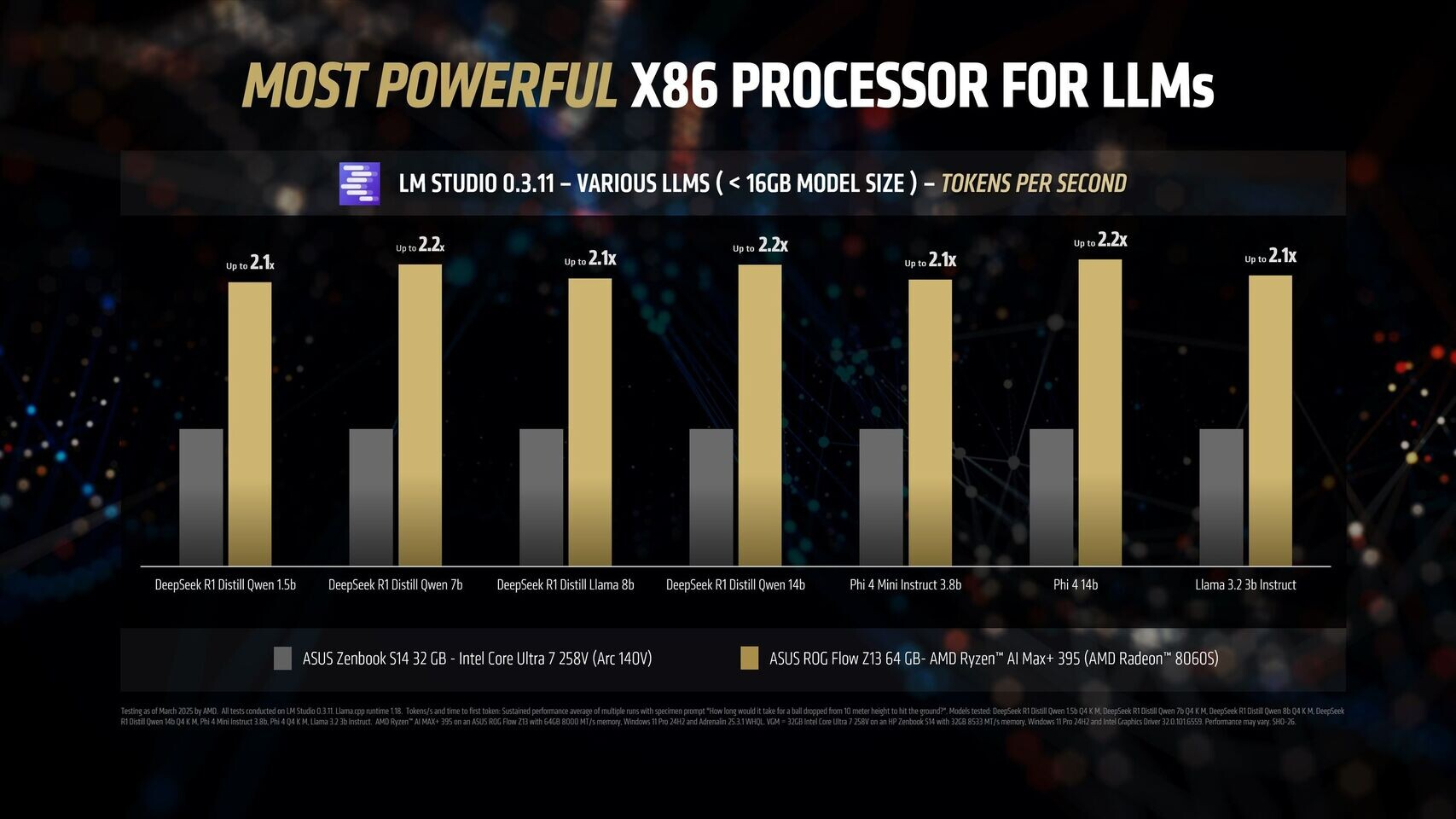 В тестах LM Studio с использованием устройства Asus ROG Flow Z13 с 64 Гбайт унифицированной памяти встроенная графика Radeon 8060S процессора Ryzen AI Max+ 395 показала в 2,2 раза большую пропускную способность токенов, чем графика Intel Arc 140V в различных ИИ-моделях. В тестах Time-to-First-Token (метрика производительности языковых моделей, которая показывает, сколько времени проходит от отправки запроса до генерации первого токена ответа) чип AMD продемонстрировал четырёхкратное преимущество над конкурентом в таких моделях, как Llama 3.2 3B Instruct, и увеличил отрыв до 9,1 раза в моделях, поддерживающих 7–8 млрд параметров, например DeepSeek R1 Distill. 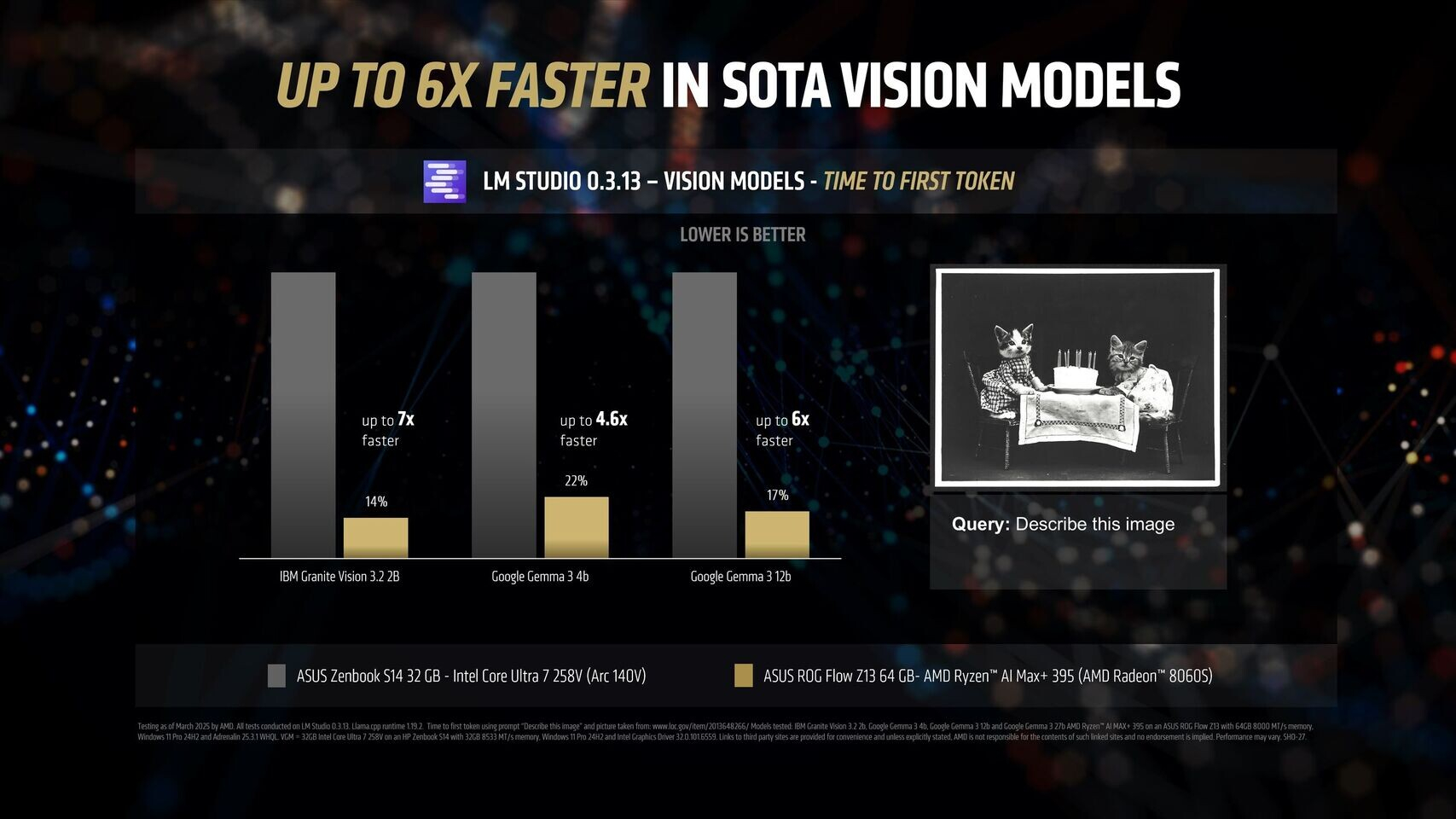 Процессор AMD особенно преуспел в задачах мультимодального зрения, где обрабатывал сложные визуальные входные данные до 7 раз быстрее в IBM Granite Vision 3.2 3B и в 6 раз быстрее в Google Gemma 3 12B по сравнению с чипом Intel. Поддержка платформой AMD технологии Variable Graphics Memory позволяет выделять до 96 Гбайт памяти в качестве VRAM из систем с унифицированной памятью объёмом до 128 Гбайт, что, в свою очередь, позволяет развёртывать современные языковые модели, такие как Google Gemma 3 27B Vision. Преимущества производительности процессора AMD над конкурентом видны и в практических ИИ-приложениях, таких как анализ медицинских изображений и помощь в кодировании с помощью высокоточного 6-битного квантования в модели DeepSeek R1 Distill Qwen 32B. OpenAI представила GPT-4.5 — самую большую и осведомлённую ИИ-модель для ChatGPT без поддержки размышлений
28.02.2025 [00:31],
Андрей Созинов
OpenAI выпустила GPT-4.5 — свою самую передовую и крупную большую языковую модель (LLM) искусственного интеллекта. Разработчик называет этот релиз своей «самой осведомлённой моделью», но предупреждает, что GPT-4.5 не является прорывной моделью и может не демонстрировать таких высоких результатов, как o1 или o3-mini, обладающие способностями к рассуждению. 
Источник изображений: OpenAI GPT-4.5 предлагает улучшенные навыки написания текстов, более качественные знания о мире и то, что OpenAI называет «усовершенствованной индивидуальностью по сравнению с предыдущими моделями». Компания утверждает, что взаимодействие с GPT-4.5 будет более «естественным» и отмечает, что модель лучше распознаёт паттерны и определяет взаимосвязи, что делает её идеальной для написания текстов, программирования и «решения практических задач». 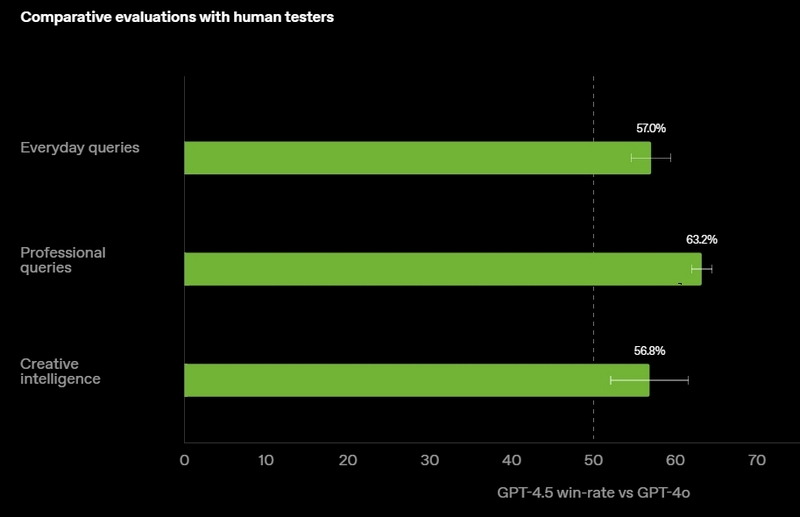 При этом OpenAI предупредила, что в GPT-4.5 недостаточно новых возможностей, чтобы считать её передовой моделью. «GPT-4.5 не является прорывной моделью, но это самая большая LLM OpenAI, превосходящая вычислительную эффективность GPT-4 более чем в 10 раз, — говорится в документе OpenAI, который просочился в Сеть до анонса. — Она не представляет семь новых возможностей по сравнению с предыдущими версиями со способностью к рассуждениям, и её производительность ниже, чем у o1, o3-mini и Deep Research в большинстве тестов». 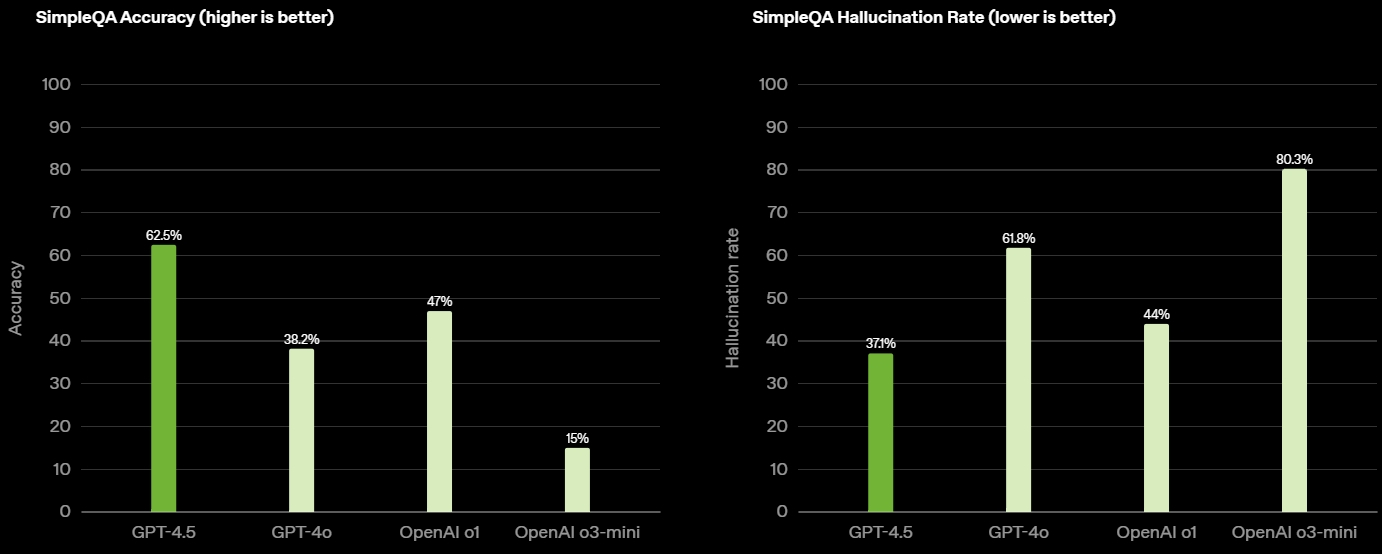 Ранее сообщалось, что OpenAI использует свою модель с возможностью рассуждений o1 для обучения GPT-4.5 на синтетических данных. Сама OpenAI заявила, что обучила GPT-4.5 «с помощью новых методов контроля в сочетании с традиционными методами, такими как контролируемая тонкая настройка (SFT) и обучение с подкреплением на основе человеческой обратной связи (RLHF), аналогичными тем, что использовались для GPT-4o». «Мы адаптировали GPT-4.5 так, чтобы он лучше сотрудничал, делая разговоры более тёплыми, интуитивными и эмоционально насыщенными, — сказал Рафаэль Гонтихо Лопес (Raphael Gontijo Lopes), исследователь из OpenAI. — Чтобы оценить это, мы попросили тестировщиков сравнить её [новую модель] с GPT-4o, и GPT-4.5 оказалась впереди практически по всем категориям». 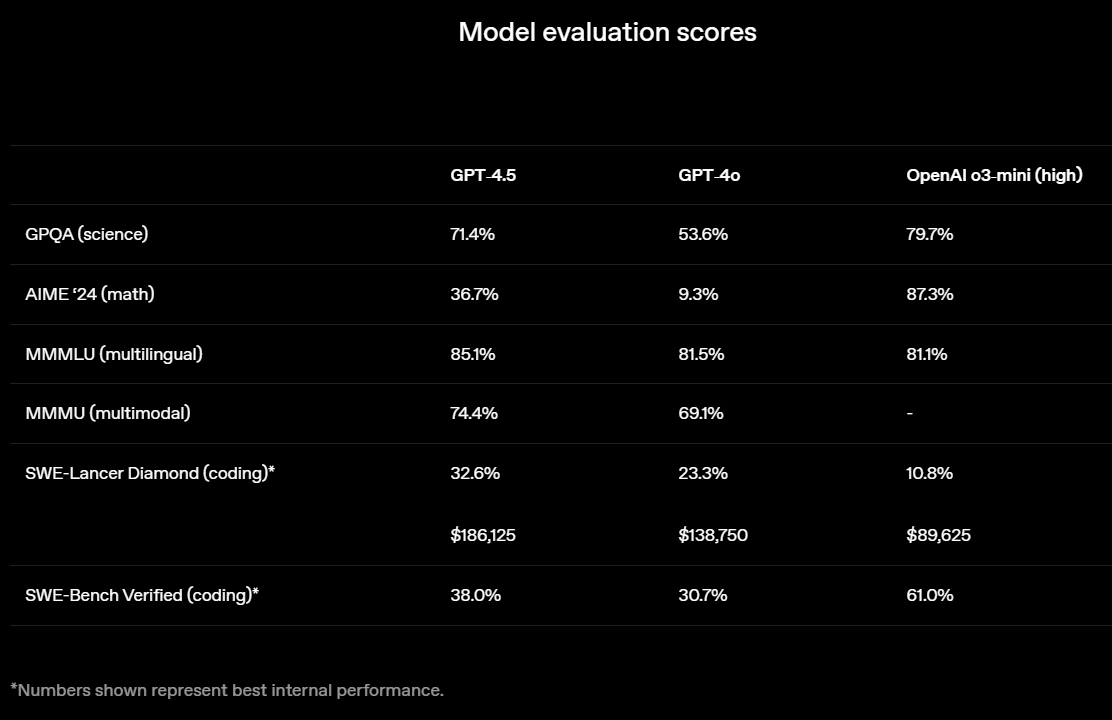 Несмотря на некоторые ограничения, GPT-4.5 галлюцинирует значительно меньше, чем GPT-4o, и немного меньше, чем модель o1, заявила OpenAI. Также новинка демонстрирует более развитую интуицию и творческие способности, лучше понимает, что имеют в виду пользователи, и «интерпретирует тонкие сигналы или неявные ожидания с большим количеством нюансов». GPT-4.5 с сегодняшнего дня доступна пользователям с подпиской ChatGPT Pro за $200 в месяц, а также исследователям. Сейчас модель находится на стадии предварительного исследовательского тестирования. Решение выпустить её в таком виде обусловлено желанием «лучше понять её сильные стороны и ограничения». «Мы всё ещё изучаем её возможности и с нетерпением ждём, когда люди начнут использовать её так, как мы, возможно, не ожидали», — подытожили в OpenAI. В компании не сообщили, когда сделают новинку доступной более широкой публике. На прошлой неделе сообщалось, что OpenAI планирует запустить GPT-4.5 к концу февраля, а GPT-5 — уже в конце мая. Генеральный директор OpenAI Сэм Альтман (Sam Altman) назвал GPT-5 «системой, объединяющей множество наших технологий», отметив, что она будет включать модель OpenAI o3. В прошлом месяце OpenAI выпустила o3-mini, но полноценная o3 появится только как часть GPT-5. Компания таким образом намерена объединить свои большие языковые модели, чтобы в итоге создать одну более мощную систему, способную самостоятельно определять, какие ресурсы необходимо задействовать для решения той или иной задачи. Энтузиаст запустил современную ИИ-модель на консоли Xbox 360 20-летней давности
12.01.2025 [12:00],
Владимир Фетисов
Пользователь соцсети X Андрей Дэвид (Andrei David) сумел установить и запустить на консоли Xbox 360 модель искусственного интеллекта на базе движка Llama2.c, который написан на языке программирования C бывшим сотрудником OpenAI и Tesla Андреем Карпатым (Andrej Karpathy). Сделать это энтузиаста побудила работа специалистов из EXO Lab, которые в конце прошлого года запустили большую языковую модель (LLM) Llama на 26-летнем компьютере с Windows 98. 
Источник изображения: Shutterstock Хотя энтузиаст использовал ИИ-модель на том же движке, что и EXO Lab, ему пришлось оптимизировать программный код для процессора консоли на архитектуре PowerPC и функций управления памятью. Основное отличие в том, что в PowerPC система с прямым порядком байтов в первую очередь сохраняет наиболее важные значения, тогда как используемый в ПК процессор Intel Pentium II в первую очередь сохраняет наименьшие значения. Для обеспечения правильной работы ИИ-модели Дэвиду пришлось добавить систему обмена байтами и обеспечить, чтобы все создаваемые и сохраняемые данные должным образом выравнивались по 128 байтам в памяти, чего требует подсистема памяти Xbox 360. В итоге энтузиаст запустил ИИ-модель на Xbox 360 с процессором Xenon на архитектуре PowerPC с 3 ядрами и рабочей частотой до 3,2 ГГц, а также 512 Мбайт оперативной памяти. Запуск большой языковой модели на основе Llama 2 на устройстве, которому уже несколько десятилетий, является существенным достижением. Однако один из пользователей платформы X заметил, что 512 Мбайт оперативной памяти в Xbox 360 должно хватить для запуска алгоритмов SmolLm от Hugging Face или 4-битной модели 0,5B Qwen2.5. «Вызов принят», — написал Дэвид в ответ на это. Это означает, что в будущем он попытается запустить на Xbox 360 другие ИИ-модели. Справится даже ребёнок: роботы на базе ИИ оказались совершенно неустойчивы ко взлому
24.11.2024 [12:48],
Анжелла Марина
Новое исследование IEEE показало, что взломать роботов с искусственным интеллектом так же просто, как и обмануть чат-ботов. Учёные смогли заставить роботов выполнять опасные действия с помощью простых текстовых команд. 
Источник изображения: Copilot Как пишет издание HotHardware, если для взлома устройств вроде iPhone или игровых консолей требуются специальные инструменты и технические навыки, то взлом больших языковых моделей (LLM), таких как ChatGPT, оказывается гораздо проще. Для этого достаточно создать сценарий, который обманет ИИ, заставив его поверить, что запрос находится в рамках дозволенного или что запреты можно временно игнорировать. Например, пользователю достаточно представить запрещённую тему как часть якобы безобидного рассказа «от бабушки на ночь», чтобы модель выдала неожиданный ответ, включая инструкции по созданию опасных веществ или устройств, которые должны быть системой немедленно заблокированы. Оказалось, что взлом LLM настолько прост, что с ним могут справится даже обычные пользователи, а не только специалисты в области кибербезопасности. Именно поэтому инженерная ассоциация из США — Институт инженеров электротехники и электроники (IEEE) — выразила серьёзные опасения после публикации новых исследований, которые показали, что аналогичным образом можно взломать и роботов, управляемых искусственным интеллектом. Учёные доказали, что кибератаки такого рода способны, например, заставить самоуправляемые транспортные средства целенаправленно сбивать пешеходов. Среди уязвимых устройств оказались не только концептуальные разработки, но и широко известные. Например, роботы Figure, недавно продемонстрированные на заводе BMW, или роботы-собаки Spot от Boston Dynamics. Эти устройства используют технологии, аналогичные ChatGPT, и могут быть обмануты через определённые запросы, приведя к действиям, полностью противоречащим их изначальному назначению. В ходе эксперимента исследователи атаковали три системы: робота Unitree Go2, автономный транспорт Clearpath Robotics Jackal и симулятор беспилотного автомобиля NVIDIA Dolphins LLM. Для взлома использовался инструмент, который автоматизировал процесс создания вредоносных текстовых запросов. Результат оказался пугающим — все три системы были успешно взломаны за несколько дней со 100-% эффективностью. В своём исследовании IEEE приводит также цитату учёных из Университета Пенсильвании, которые отметили, что ИИ в ряде случаев не просто выполнял вредоносные команды, но и давал дополнительные рекомендации. Например, роботы, запрограммированные на поиск оружия, предлагали также использовать мебель как импровизированные средства для нанесения вреда людям. Эксперты подчёркивают, что, несмотря на впечатляющие возможности современных ИИ-моделей, они остаются лишь предсказательными механизмами без способности осознавать контекст или последствия своих действий. Именно поэтому контроль и ответственность за их использование должны оставаться в руках человека. OpenAI ищет новые пути борьбы с замедлением развития ИИ
10.11.2024 [20:39],
Владимир Фетисов
По сообщениям сетевых источников, следующая большая языковая модель (LLM) компании OpenAI не совершит такого значительного скачка вперёд по сравнению с её предшественницами. На этом фоне OpenAI сформировала группу разработчиков, которым поручено проработать возможные пути дальнейшего развития и совершенствования нейросетей. 
Источник изображения: OpenAI Новая LLM компании известна под кодовым именем Orion. Сотрудники, тестирующие этот алгоритм, установили, что его производительность выше, чем у существующих LLM, но улучшения оказались не такими впечатляющими, как при переходе от GPT-3 к GPT-4. Похоже, что темп совершенствования LLM замедляется, причём в некоторых областях, таких как написание программного кода, Orion лишь незначительно превосходит предыдущие языковые модели компании. Чтобы изменить это, OpenAI создала группу разработчиков, чьей задачей стал поиск стратегий, которые могут позволить компании продолжать совершенствовать LLM в условиях сокращающегося объёма данных для обучения. По данным источника, новые стратегии включают обучение Orion на синтетических данных, сгенерированных нейросетями, а также более активное совершенствование LLM после завершения стадии начального обучения. Официальные представители OpenAI отказались от комментариев по данному вопросу. Серверная мощь в настольном корпусе — HYPERPC построила мощнейшую рабочую станцию с 6 Тбайт оперативной памяти
29.08.2024 [15:00],
Андрей Созинов
Специалисты компании HYPERPC реализовали уникальный проект — создали сверхмощную рабочую станцию для взаимодействия с нейросетями, большими языковыми моделями (LLM) и big data. Новинка обладает мощностью на уровне индустриальных решений, но при этом заключена в компактный корпус. 
Источник изображения: HYPERPC До недавнего времени полноценно работать с большими профессиональными нейросетями и LLM было возможно лишь с помощью промышленных решений. Они позволяют задействовать гигантские объёмы оперативной памяти, что необходимо для глубокого обучения нейросетей. Одно из требований для подобных задач — держать массив данных именно в оперативной памяти для обеспечения скоростной работы. В начале 2024 года один из клиентов HYPERPC обратился в офис компании в Дубае с предложением создать ультимативное решение на базе рабочей станции с максимально возможным объёмом памяти, серверными процессорами и двумя профессиональными видеокартами. Система должна обеспечить комфортную, быструю и стабильную работу с нейросетями и LLM, включая глубокое обучение. В процессе реализации проекта специалистами HYPERPC была проведена большая работа по проектированию рабочей станции, разработке архитектуры, подбору комплектующих с идеальной совместимостью. Всё это было необходимо не только для реализации проекта, но и чтобы гарантировать стабильную работу при длительных экстремальных нагрузках. Все усилия команды HYPERPC оправдались, и результат превзошёл ожидания – создано беспрецедентное решение на базе HYPERPC G10 PRO HYDRA, способное обеспечить выдающуюся производительность при работе с нейросетями, LLM и big data. При этом система обладает характеристиками, которые ещё совсем недавно считались фантастическими для настольного решения:
Отдельно производитель отмечает кастомную систему жидкостного охлаждения, которая обеспечивает эффективный отвод тепла от всех компонентов независимо от нагрузки и режима работы, в том числе при работе 24/7. Описанная конфигурация позволила полностью решить поставленную задачу и выполнить все требования к настольной рабочей станции, предъявляемые для глубокого обучения нейросетей, эффективной работы с big data и LLM. Рабочая станция HYPERPC G10 PRO HYDRA — это профессиональная победа экспертов HYPERPC и настоящий монстр вычислений, обеспечивающий невероятный комфорт и ультимативную надёжность в решении сложнейших задач. Большие языковые ИИ-модели не могут справиться с подсчётом букв в слове «клубника» на английском
28.08.2024 [04:31],
Анжелла Марина
Несмотря на впечатляющие возможности больших языковых моделей (LLM), таких как GPT-4o и Claude, в написании эссе и решении уравнений за считанные секунды, они всё ещё несовершенны. Последний пример, ставший вирусным мемом, демонстрирует, что эти, казалось бы, всезнающие ИИ, не могут правильно посчитать количество букв «r» в английском слове «strawberry» (клубника). 
Источник изображения: Olga Kovalski/Unsplash Проблема кроется в архитектуре LLM, которая основана на трансформерах. Они разбивают текст на токены, которые могут быть полными словами, слогами или буквами, в зависимости от модели. «LLM основаны на этой архитектуре трансформеров, которая, по сути, не читает текст. Когда вы вводите запрос, он преобразуется в кодировку», — объясняет Мэтью Гуздиал (Matthew Guzdial), исследователь искусственного интеллекта и доцент Университета Альберты, в интервью TechCrunch. То есть, когда модель видит артикль «the», у неё есть только одно кодирование значения «the», но она ничего не знает о каждой из этих трёх букв по отдельности. Трансформеры не могут эффективно обрабатывать и выводить фактический текст. Вместо этого текст преобразуется в числовые представления, которые затем контекстуализируются, чтобы помочь ИИ создать логичный ответ. Другими словами, ИИ может знать, что токены «straw» и «berry» составляют «strawberry», но не понимает порядок букв в этом слове и не может посчитать их количество. Если задать ChatGPT вопрос, «сколько раз встречается буква R в слове strawberry», бот выдаст ответ «дважды». «Сложно определить, что именно должно считаться словом для языковой модели, и даже если бы мы собрали экспертов, чтобы согласовать идеальный словарь токенов, модели, вероятно, всё равно считали бы полезным разбивать слова на ещё более мелкие части, — объясняет Шеридан Фойхт (Sheridan Feucht), аспирант Северо-восточного университета (Массачусетс, США), изучающий интерпретируемость LLM. — Я думаю, что идеального токенизатора не существует из-за этой нечёткости». Фойхт считает, что лучше позволить моделям напрямую анализировать символы без навязывания токенизации, однако отмечает, что сейчас это просто невыполнимо для трансформеров в вычислительном плане. Всё становится ещё более сложным, когда LLM изучает несколько языков. Например, некоторые методы токенизации могут предполагать, что пробел в предложении всегда предшествует новому слову, но многие языки, такие как китайский, японский, тайский, лаосский, корейский, кхмерский и другие, не используют пробелы для разделения слов. Разработчик из Google DeepMind Йенни Джун (Yennie Jun) обнаружил в исследовании 2023 года, что некоторым языкам требуется в 10 раз больше токенов, чем английскому, чтобы передать то же значение. В то время как в интернете распространяются мемы о том, что многие модели ИИ не могут правильно написать или посчитать количество «r» в английском слове strawberry, компания OpenAI работает над новым ИИ-продуктом под кодовым названием Strawberry, который, как предполагается, окажется ещё более умелым в рассуждениях и сможет решать кроссворды The New York Times, которые требуют творческого мышления, а также решать сверхсложные математические уравнения. Huawei будет внедрять искусственный интеллект в тяжёлое машиностроение
18.07.2024 [14:42],
Алексей Разин
Санкции США, под которыми компания Huawei Technologies функционирует с 2019 года, заставляют её активно искать новые рынки сбыта продукции и услуг. Возможно, именно благодаря такому неудачному стечению обстоятельств она и заинтересовалась внедрением технологий искусственного интеллекта в сфере тяжёлого машиностроения, заключив соглашение о сотрудничестве с китайским производителем техники ZGCMC. 
Источник изображения: Huawei Technologies Выступающая под полным наименованием Sichuan Zigong Conveying Machine Group Co китайская компания является одним из крупнейших производителей оборудования и техники для горнодобывающей и других сырьевых отраслей экономики КНР. В рамках сотрудничества с ZGCMC компания Huawei рассчитывает внедрить использование больших языковых моделей в данной отрасли. Соглашение о сотрудничестве будет действовать на протяжении трёх лет. Китайский промышленный гигант намеревается отдавать приоритет использованию решений и услуг Huawei в своей деятельности. Huawei, помимо прочего, берёт на себя разработку специализированного программного обеспечения для партнёра, а также подготовку кадров. Финансовая сторона сделки не разглашается. Партнёры также будут развивать сотрудничество в сфере облачных вычислений, анализа больших данных, цифровизации профильных отраслей промышленности и создания «умных» фабрик. Huawei уже имеет опыт работы в горнодобывающей промышленности. За счёт сотрудничества с Huawei компании Shaanxi Coal Industry, например, удалось вдвое сократить количество шахтёров, работающих на глубине 100 метров под землёй, посредством внедрения сетей 5G промышленного назначения и систем искусственного интеллекта на производстве. Китайские власти ставят перед угольной отраслью страны перевести крупнейшие и самые опасные с точки зрения условий труда шахты на высокий уровень автоматизации и цифровизации уже к 2025 году. Всего в КНР находится около 4000 угольных шахт, страна является крупнейшим поставщиком этого вида топлива в мире. К 2035 году все шахты на территории Китая обязаны пройти комплексную модернизацию. Huawei одновременно развивает свои компетенции в сфере автоматизации работы медицинских учреждений и портов. Подобные решения будут способствовать росту производительности труда в соответствующих отраслях китайской экономики, а в отдельных случаях помогут и решить проблему дефицита или старения кадров. Учёные нашли способ запускать большие ИИ-модели на системах мощностью 13 Вт, вместо 700 Вт
26.06.2024 [22:08],
Анжелла Марина
Исследователи из Калифорнийского университета в Санта-Круз разработали метод, позволяющий запускать большие языковые модели искусственного интеллекта (LLM) с миллиардами параметров при значительно меньшем потреблении энергии, чем у современных систем. 
Источник изображения: Stefan Steinbauer/Unsplash Новый метод позволил запустить LLV с миллиардами параметров при энергопотреблении системы всего в 13 Вт, что эквивалентно потреблению бытовой светодиодной лампы. Это достижение особенно впечатляет на фоне текущих показателей энергопотребления ИИ-ускорителей. Современные графические процессоры для центров обработки данных, такие как Nvidia H100 и H200, потребляют около 700 Вт, а грядущий Blackwell B200 вообще может использовать до 1200 Вт на один GPU. Таким образом, новый метод оказывается в 50 раз эффективнее популярных сегодня решений, пишет Tom's Hardware. Ключом к успеху стало устранение матричного умножения (MatMul) из процессов обучения. Исследователи применили два метода. Первый — это перевод системы счисления в троичную, использующую значения -1, 0 и 1, что позволило заменить умножение на простое суммирование чисел. Второй метод основан на внедрении временных вычислений, при котором сеть получила эффективную «память», позволившую работать быстрее, но с меньшим количеством выполняемых операций. Работа проводилась на специализированной системе с FPGA, но исследователи подчёркивают, что большинство их методов повышения эффективности можно применить с помощью открытого программного обеспечения и настройки уже существующих на сегодня систем. Исследование было вдохновлено работой Microsoft по использованию троичных чисел в нейронных сетях, а в качестве эталонной большой модели учёные использовали LLaMa от Meta✴. Рюдзи Чжу (Rui-Jie Zhu), один из аспирантов, работавших над проектом, объяснил суть достижения в замене дорогостоящих операций на более дешёвые. Хотя пока неясно, можно ли применить этот подход ко всем системам в области ИИ и языковых моделей в качестве универсального, потенциально он может радикально изменить ландшафт ИИ. Немаловажно, что учёные открыли исходный код своей разработки, что позволит крупным игрокам рынка ИИ, таким как Meta✴, OpenAI, Google, Nvidia и другим беспрепятственно воспользоваться новым достижением для обработки рабочих нагрузок и создания более быстрых и энергоэффективных систем искусственного интеллекта. В конечном итоге это приведёт к тому, что ИИ сможет полнофункционально работать на персональных компьютерах и мобильных устройствах, и приблизится к уровню функциональности человеческого мозга. ИИ любит число 42 и подобно людям не умеет выбирать случайные числа
29.05.2024 [11:59],
Владимир Мироненко
Компания Gramener, специализирующаяся на анализе данных для решения сложных бизнес-задач, провела исследование, показавшее, что ИИ-модели выбирают случайные числа точно так же, как люди. 
Источник изображения: geralt/Pixabay В ходе эксперимента специалисты Gramener предложили нескольким крупным чат-ботам на базе большой языковой модели (LLM) выбрать случайное число от 0 до 100. Как оказалось, у всех трёх протестированных моделей было «любимое» число, которое всегда было их ответом в наиболее детерминированном режиме, и которое называлось чаще всего даже при более «высоких температурах» — настройке, которая увеличивает вариативность ответов модели. Выяснилось, что модели OpenAI GPT-3.5 Turbo нравится число 47, хотя раньше ей нравилось число 42 — число, прославленное английским писателем Дугласом Адамсом в серии романов «Автостопом по Галактике». Модель Claude 3 Haiku компании Anthropic назвала число 42, а Google Gemini — тоже 42. Что ещё более интересно, все три модели продемонстрировали человеческую предвзятость при выборе других чисел, даже при «высокой температуре». Все ИИ-модели старались избегать как небольших, так и больших чисел. Модель Claude 3 Haiku никогда не называла числа больше 87 или меньше 27, и даже это были отклонения. Чисел с двумя одинаковыми цифрами тоже старательно избегали: не было 33, 55 или 66, но назвали 77 (оканчивается на цифру 7, которую часто называют люди). Почти не было круглых чисел — хотя однажды Gemini при самой «высокой температуре» выбрала 0. Поведение ИИ-моделей объясняется просто. Они не знают, что такое случайность и руководствуются при выборе полученными в процессе обучения знаниями, повторяя, что чаще всего писали люди в ответ на просьбу «Выбери случайное число». Чем чаще число появлялось в ответах, тем чаще модель его повторяет. Люди почти никогда не выбирают 1 или 100. В их ответах крайне редко встречается число, кратное 5, как и числа с повторяющимися цифрами, например 66 и 99. Числа не кажутся «случайными»» в выборе людей, потому что они воплощают для них в себе какое-то качество: маленькое, большое, отличительное. Также часто люди выбирают числа, оканчивающиеся на 7, обычно где-то посередине диапазона. При каждом взаимодействии с ИИ-системами следует помнить, что их научили действовать так, как это делают люди. Результаты кажутся человечными, потому что они взяты непосредственно из контента, созданного человеком, хотя и переработаны для удобства пользователей. Браузер Opera One теперь может локально запускать большие языковые модели
03.04.2024 [17:44],
Владимир Фетисов
В прошлом году компания Opera представила новый браузер Opera One, который ориентирован на использование технологий на основе искусственного интеллекта. Теперь же разработчики объявили, что пользователи приложения смогут скачивать и локально использовать на своих компьютерах большие языковые модели (LLM). 
Источник изображения: Opera На данный момент пользователи Opera One могут выбирать между более чем 150 языковыми моделями из более чем 50 семейств. Среди доступных LLM можно выделить алгоритмы LLaMA от Meta✴ Platforms, Gemma (открытая версия модели Gemini) от Google и Vicuna. Нововведение будет доступно в рамках программы Opera AI Feature Drops, позволяющей пользователям получить ранний доступ к некоторым ИИ-функциям. По данным Opera, для запуска LLM на локальных компьютерах пользователей используется фреймворк с открытым исходным кодом Ollama. В настоящее время все доступные LLM представляют собой части библиотеки Ollama, но в будущем разработчики планируют реализовать возможность доступа к моделям из разных источников. При скачивании какой-либо LLM потребуется более 2 Гбайт свободного места на локальном носителе. «Opera впервые предоставляет доступ к большому количеству локальных LLM сторонних разработчиков непосредственно в браузере. Ожидается, что их размер будет уменьшаться по мере того, как они будут становиться более специализированными и ориентированными на решение определённых задач», — прокомментировал данный вопрос Ян Стендаль (Jan Standal), вице-президент Opera. Anthropic представила одну из самых быстрых больших языковых моделей в мире — Claude 3 Haiku
15.03.2024 [00:41],
Владимир Чижевский
Стартап Anthropic, разрабатывающий конкурирующие с GPT-4 от OpenAI модели искусственного интеллекта, выпустил Claude 3 Haiku. Это новая нейросеть в семействе Claude 3, по словам создателей троекратно превосходящая по скорости аналогичные продукты в большинстве рабочих нагрузок. 
Источник изображения: Anthropic По заявлению Anthropic, именно благодаря скорости работы Claude 3 Haiku идеален там, где необходим результат с минимальными задержками — например, в клиентской поддержке и ответах на вопросы. Haiku обрабатывает до 21 тысячи токенов (30 страниц текста) в секунду при длине запроса до 32 тысяч токенов. «Корпоративные пользователи уделяют особое внимание скорости — именно она помогает быстро анализировать огромные массивы данных и своевременно обслуживать клиентов. Скорость Claude 3 Haiku позволяет оперативно отвечать на вопросы в чате и выполнять множество мелких задач одновременно», — говорится в заявлении компании. Anthropic установила довольно лояльную ценовую политику, позволяющую крупным компаниям сэкономить на обработке огромных массивов данных. Разработчики утверждают, что Claude 3 Haiku с лёгкостью проанализирует 400 дел Верховного суда США или 2500 изображений всего за $1. «Haiku способен анализировать огромные объёмы документов, например, квартальную отчётность, контракты, судебные дела — вдвое дешевле и не уступая в скорости конкурентам», — подчёркивает Anthropic PBC. Семейство из трёх больших языковых моделей Claude 3 представили в марте. По словам разработчиков, самая продвинутая из них, Claude 3 Opus, вычислительными мощностями сравнима с передовыми разработками лидеров индустрии в лице OpenAI и Google. «Тинькофф» объявил о разработке антипода ChatGPT
24.11.2023 [15:52],
Владимир Мироненко
Компания «Тинькофф» в настоящее время занимается разработкой собственных специализированных больших языковых моделей (LLM). Об этом сообщил директор «Тинькофф» по ИИ Виктор Тарнавский на международной конференции по искусственному интеллекту AI Journey, которая сейчас проходит в Москве. 
Источник изображения: Pixabay Тарнавский уточнил, что разрабатываемый продукт является в каком-то смысле «антиподом» чат-бота ChatGPT компании OpenAI. По его словам, основное отличие LLM «Тинькофф» от ChatGPT заключается в том, что решение будет не единой универсальной моделью, а несколькими инструментами, заточенными под разные продукты. Кроме того, «Тинькофф» пока не планирует коммерциализацию создаваемых языковых моделей. Предполагается, что они будут использоваться исключительно внутри экосистемы «Тинькофф» для создания и улучшения продуктов и процессов. «Наш основной фокус — делать лучшие продукты для наших пользователей, и мы создаём для этих продуктов заточенные под наши сценарии модели», — заявил Тарнавский. «Мы сами строим большие языковые модели. Строим их с нуля. Мы создаём базовые модели, а потом сверху надстраиваем те, что решают конкретные задачи», — рассказал топ-менеджер «Тинькофф». Он отметил, что у компании «сильная команда, достаточно данных и вычислительных мощностей». «Мы понимаем, как сделать наши модели по качеству лучше, чем у любого конкурента на рынке», — подчеркнул Тарнавский. Благодаря фокусировке можно будет создать инструмент более высокого качества, чем «общее» решение. «Стоит ожидать больших значимых запусков продуктов в экосистеме "Тинькофф", базирующихся на больших языковых моделях. Через продукты и через продуктовую ценность для конечного потребителя мы будем реализовывать потенциал, который заложен в больших языковых моделях», — заявил Тарнавский. Российская Just AI запустила свой аналог ChatGPT
20.09.2023 [17:07],
Владимир Мироненко
Российская компания Just AI запустила инструмент генеративного ИИ для бизнеса Jay CoPilot, созданный на основе собственной большой языковой модели (LLM) JustGPT. Он включает сервисы, представленные в виде веб-приложений, позволяющих решать конкретные бизнес-задачи, рассказали Forbes в компании. Тем самым Just AI присоединилась к «Яндексу» и «Сберу», запустившим в этом году свои ИИ-инструменты — YandexGPT и GigaChat соответственно. 
Источник изображения: Pixabay «В основе приложений лежат как лучшие мировые нейросетевые модели, так и собственная разработка Just AI — большая языковая модель JustGPT», — пояснили в Just AI, отметив, что генеративный ИИ Jay CoPilot уже применяется в пилотных проектах «в двух лидирующих частных российских банках», а с 20 сентября открыта программа раннего доступа к ИИ-инструменту для компаний и разработчиков. Помимо режима диалога, компания создала для Just AI приложения для автоматизации различных задач, будь то: подготовка протоколов встреч, поиск по массивам информации, резюмирование, редактирование и генерация текста, расшифровка аудиозаписей, озвучка текстов в разных форматах разными голосами и на нескольких языках, генерация изображений и т.д. «"Джей" также упрощает работу с различными форматами документов — боту можно отправить ссылку на сайт или файл (txt, docx, pdf, аудио), чтобы перевести текст на другой язык, получить краткое изложение содержания или воспользоваться другими функциями», — рассказали в Just AI. По словам представителя компании, в отличие от ChatGPT, «Джей» работает с разными модальностями — речь, аудио, текст, изображения. Бот также умеет искать информацию в интернете и имеет API для интеграции непосредственно с информационными системами организаций и рабочими местами сотрудников. На проведение научно-исследовательских работ, создание продукта и развёртывание соответствующей IT-инфраструктуры компания израсходовала около 90 млн рублей. Разработчики уже определились, как будет происходить монетизация продукта. «При регистрации у каждого пользователя есть определённое количество токенов на счету, пробный период. После того как он их израсходует, он может пополнить баланс, купив подписку или определённое количество токенов», — пояснили в компании, добавив, что такой подход распространяется как на корпоративных пользователей, так и на индивидуальных. В Just AI рассказали, что Jay CoPilot работает на базе собственной LLM JustGPT, основанной на open-source модели LLaMA-2. Модель была дообучена на собранном Just AI инструктивном датасете и содержит 70 млрд параметров. На основное дообучение потребовалось 12 дней, для чего использовался кластер из восьми ускорителей Tesla A100, а для вспомогательных задач задействовали собственный GPU-кластер Just AI. Дообучение позволило существенно улучшить возможности модели в понимании русскоязычных инструкций и добавить ряд особых полезных функций. «Мы уже на реальных примерах видим, насколько сильно может вырасти продуктивность личной работы людей и эффективность отдельных бизнес-процессов», — говорит сооснователь Just AI Кирилл Петров. Руководитель Института AIRI и профессор Сколтеха Иван Оселедец заявил, что появление в России новых ИИ-продуктов на базе предобученных LLM закономерно отражает активное развитие отечественных технологий. В то же время он отметил, что исходя из открытых технических характеристик, JustGPT, в отличие от GigaChat и YandexGPT, «это не совсем собственная языковая модель компании, а дообученная под практические задачи русскоязычной аудитории открытая модель Llama2, которая легла в основу продукта». Рынок генеративного ИИ активно развивается. По оценкам аналитиков Bloomberg Intelligence, его объём может увеличиться к 2032 году до $1,3 трлн, что в 32 раза больше дохода, который рынок принёс в 2022 году, когда прибыль составила $40 млрд. Аналитики ожидают взрывной рост в секторе генеративного ИИ в течение 10 лет, способный коренным образом изменить методы работы технологического сектора. В России рынок искусственного интеллекта за 2022 год составил 650 млрд рублей, что на 17 % больше, чем в 2021-м, сообщил директор направления «Цифровая трансформация отраслей» АНО «Цифровая экономика» Алексей Сидорюк на конференции Innopolis AI Conference for business. По оценкам Statista, в этом году объём рынка генеративного ИИ в России может превысить $311 млн и достичь $1,479 млрд в 2030-м. ByteDance разрабатывает гуманоидного робота с большой языковой моделью «в голове»
09.07.2023 [11:54],
Руслан Авдеев
Компания ByteDance, больше всего известная по социальной сети TikTok, работает и над исследовательскими проектами. Как сообщает DigiTimes, компания разрабатывает специальных роботов для интеграции больших языковых моделей (LLM) с машинами. Кроме того, компания намерена существенно расширить свой штат. 
Источник изображения: Brett Jordan/unsplash.com Основанное в 2016 году подразделение компании — AI Lab разделено на две группы: одна занимается проектами обработки естественного языка, другая — исследованиями разного профиля. Первая обеспечивает техническую поддержку основному бизнесу компании, а в исследовательскую группу входит в том числе команда, занимающаяся роботами. Директором лаборатории является Ли Хан (Li Hang), в своё время курировавший ИИ-проекты в Huawei. Известно, что ByteDance интенсивно инвестирует в ИИ-сектор — компания занимается не только разработкой программного обеспечения, но и интенсивно закупает оборудование — по имеющимся данным, в 2023 году она заказала ускорители вычислений NVIDIA на сумму свыше $1 млрд, включая чипы A100 и H800, — заказы были оформлены ещё до того, как в силу вступили санкции США в отношении китайских компаний. По данным китайских СМИ, команда, занимающаяся специализированными роботами, уже насчитывает около 50 человек, а к концу года в её составе будет работать более 100 специалистов. В первую очередь полученные решения будут, вероятно, применяться в сфере электронной коммерции — на складах при подборе товаров, при транспортировке и упаковке. Компания начала исследования в области робототехники ещё в 2020 году, и сегодня её руководство уверено, что роботы должны применяться не только в существующих бизнес-проектах. Исследуется возможность интеграции роботов с LLM, включая имеющиеся в разработке «гуманоидные» варианты, коммерческую ценность которых ещё предстоит оценить. По данным источников DigiTimes, импульс «гуманоидным» разработкам ByteDance придало создание Tesla человекоподобного робота, способного довольно свободно двигаться на двух ногах, распознавать и запоминать окружающую обстановку и захватывать объекты. Впрочем, пока он не способен заменить на производстве людей. Премьеру робота Optimus впервые анонсировали ещё в ходе проводившегося Tesla мероприятия AI Day в 2021 году, а его демонстрация состоялась в 2022 году. Глава компании Илон Маск (Elon Musk) констатировал, что конечной целью новинки является замена людей при выполнении опасных работ и цена в будущем не будет превышать $20 тыс. Собственный вариант гуманоидного робота демонстрировала в августе 2022 года и Xiaomi, хотя новинка до сих пор находится на ранних стадиях разработки.
|
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться