|
Опрос
|
реклама
Быстрый переход
Сроки поставок ИИ-ускорителей Nvidia H100 сократились до 2–3 месяцев
10.04.2024 [20:59],
Николай Хижняк
Cроки поставок ИИ-ускорителей Nvidia H100 сократились с 3–4 до 2–3 месяцев (8–12 недель), сообщает DigiTimes со ссылкой на заявление директора тайваньского офиса компании Dell Теренса Ляо (Terence Liao). ODM-поставщики серверного оборудования отмечают, что дефицит специализированных ускорителей начал снижаться по сравнению с 2023 годом, когда приобрести Nvidia H100 было практически невозможно. 
Источник изображения: Nvidia По словам Ляо, несмотря на сокращение сроков выполнения заказов на поставки ИИ-ускорителей, спрос на это оборудование на рынке по-прежнему чрезвычайно высок. И несмотря на высокую стоимость, объёмы закупок ИИ-серверов значительно выше закупок серверного оборудования общего назначения. Окно поставок в 2–3 месяца — это самый короткий срок поставки ускорителей Nvidia H100 за всё время. Всего шесть месяцев назад он составлял 11 месяцев. Иными словами, клиентам Nvidia приходилось почти год ждать выполнение своего заказа. С начала 2024 года сроки поставок значительно сократились. Сначала они упали до 3–4 месяцев, а теперь до 2–3 месяцев. При таком темпе дефицит ИИ-ускорителей может быть устранён к концу текущего года или даже раньше. Частично такая динамика может быть связана с самими покупателями ИИ-ускорителей. Как сообщается, некоторые компании, имеющие лишние и нигде не использующиеся H100, перепродают их для компенсации огромных затрат на их приобретение. Также нынешняя ситуация может являться следствием того, что провайдер облачных вычислительных мощностей AWS упростил аренду ИИ-ускорителей Nvidia H100 через облако, что в свою очередь тоже частично помогает снизить на них спрос. Единственными клиентами Nvidia, которым по-прежнему приходится сталкиваться с проблемами в поставках ИИ-оборудования, являются крупные ИИ-компании вроде OpenAI, которые используют десятки тысяч подобных ускорителей для быстрого и эффективного обучения своих больших языковых ИИ-моделей. ИИ-ускоритель Intel Gaudi2 оказался на 55 % быстрее Nvidia H100 в тестах Stable Diffusion 3, но есть нюанс
12.03.2024 [18:34],
Сергей Сурабекянц
Компания Stability AI, разработчик популярной модели генеративного ИИ Stable Diffusion, сравнила производительность модели Stable Diffusion 3 на популярных ускорителях вычислений для центров обработки данных, включая Nvidia H100 Hopper, A100 Ampere и Intel Gaudi2. По утверждению Stability AI, Intel Gaudi2 продемонстрировал производительность примерно на 56 % выше, чем Nvidia H100. 
Источник изображения: Intel В отличие от H100, который представляет собой суперскалярный графический процессор с тензорными CUDA-ядрами, Gaudi2 специально спроектирован для ускорения генеративного ИИ и больших языковых моделей (LLM). В тестах приняли участие пары кластеров, которые в сумме обеспечивали по 16 тех или ускорителей, а проводились тесты с постоянным размером батча (число тренировочных объектов) в 16 на каждый ускоритель (всего 256). Системы на Intel Gaudi2 оказались способны генерировать 927 изображений в секунду по сравнению с 595 изображениями для ускорителей H100 и 381 изображением в секунду для массива A100. 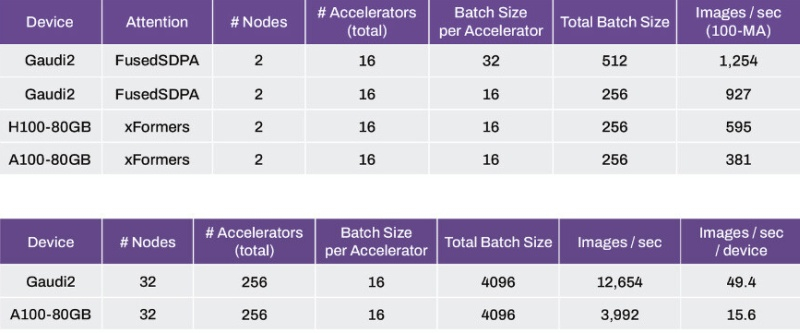
Источник изображения: Stability AI При увеличении количества кластеров до 32, а числа ускорителей до 256 и размере батча 16 на ускоритель (общий размер 4096), массив Gaudi2 генерирует 12 654 изображения в секунду или 49,4 изображения в секунду на ускоритель, по сравнению с 3992 изображениями в секунду или 15,6 изображениями в секунду на устройство у массива A100 Ampere. 
Источник изображения: Nvidia Необходимо отметить, что производительность ускорителей ИИ измерялась с использованием фреймворка PyTorch, а в случае применения оптимизации TensorRT чипы A100 создают изображения до 40 % быстрее, чем Gaudi2. Тем не менее, исследователи Stability AI ожидают, что при дальнейшей оптимизации Gaudi2 превзойдёт A100. Компания полагает, что более быстрый интерконнект и больший объем памяти (96 Гбайт) делают решения Intel вполне конкурентоспособными и планирует использовать ускорители Gaudi2 в Stability Cloud. 
Источник изображения: techpowerup.com По сообщению Stability AI, в более ранних тестах модели Stable Diffusion XL с использованием фреймворка PyTorch ускоритель Intel Gaudi2 генерирует при 30 шагах изображение размером 1024 × 1024 за 3,2 секунды по сравнению с 3,6 секунды для PyTorch на Nvidia A100 и 2,7 секунды при использовании оптимизации TensorRT на Nvidia А100. NVIDIA отгрузила 900 тонн ускорителей H100 в прошлом квартале
17.09.2023 [07:10],
Алексей Разин
Объёмы поставок ускорителей NVIDIA для систем искусственного интеллекта в новостях фигурируют преимущественно в контексте обсуждения дефицита данного вида компонентов, но представители Omdia использовали неожиданный подход для оценки масштабов отгрузки этой продукции NVIDIA — за второй квартал, по их мнению, компания поставила клиентам не менее 900 тонн ускорителей H100. 
Источник изображения: NVIDIA Как поясняет ресурс Tom’s Hardware, данный показатель увязывается авторами исходной оценки со способностью NVIDIA отгрузить по итогам второго квартала около 300 000 ускорителей H100. Средняя масса такого изделия в сочетании с системой охлаждения достигает 3 кг, по данным первоисточника, что и даёт в итоге 900 тонн. Следует учитывать, что на базе чипов H100 создаются ускорители разных типоразмеров. Плата с разъёмом PCI Express весит 1,2 кг, но масса модуля SXM в открытых источниках не фигурирует, и лишь по приблизительным оценкам можно судить, что она наверняка приближается к 2 кг. На недавней технологической конференции финансовый директор компании Колетт Кресс (Colette Kress) призналась, что во втором квартале NVIDIA отгрузила примерно равное количество ускорителей H100 и A100, поэтому в массовом выражении последних было выпущено тоже около 900 тонн, если ориентироваться на оценки Omdia. Существуют ещё и адаптированные под условия антикитайских санкций США ускорители A800 и H800, которые не должны отличаться по массе от исходных A100 и H100, но пока сложно судить, учитывались ли они в этой статистике. Представители NVIDIA не раз за последние недели подчеркнули, что с каждым кварталом компания будет увеличивать объёмы поставок ускорителей, и темпы этой экспансии сейчас во многом зависят от способности подрядчиков выпускать необходимое количество профильной продукции. «Узким местом», например, многими экспертами считается этап тестирования и упаковки чипов силами компании TSMC. С учётом некоторого количества поставленных в первом квартале ускорителей вычислений, по итогам всего года NVIDIA наверняка выпустит более 1 млн одних только H100. Сейчас данный вид деятельности является источником основных доходов для NVIDIA, поэтому она заинтересована в максимально быстрой экспансии. Tesla запустила суперкомпьютер на 10 тыс. ускорителей NVIDIA H100 — на нём будут учить автопилот
30.08.2023 [21:06],
Николай Хижняк
Компания Tesla сообщила о запуске на этой неделе нового суперкомпьютера для решения ресурсоемких задач, связанных с ИИ. В его основе используются 10 тыс. специализированных графических ускорителей NVIDIA H100. 
Источник изображений: HPC Wire Отмечается, что система обеспечивает пиковую производительность в 340 Пфлопс в операциях FP64 для технических вычислений и 39,58 Эфлопс в операциях INT8 для задач ИИ. Таким образом, по производительности FP64 кластер превосходит суперкомпьютер Leonardo, который располагается на четвёртой позиции в нынешнем мировом рейтинге суперкомпьютеров Тор500 с показателем 304 Пфлопс. Новый суперкомпьютер Tesla с ускорителями NVIDIA H100 является одной из самых мощных платформ в мире. На формирование кластера потрачено около $300 млн. Он подходит не только для обработки алгоритмов ИИ, но и для НРС-задач. Благодаря данной системе компания рассчитывает значительно расширить ресурсы для создания полноценного автопилота.  На фоне сформировавшегося дефицита ускорителей NVIDIA H100 компания хочет диверсифицировать вычислительные мощности. Для этого Tesla ведёт разработку своего собственного проприетарного суперкомпьютера Dojo. В проект планируется инвестировать $1 млрд. Уже к октябрю следующего года Tesla рассчитывает преодолеть барьер в 100 Эфлопс производительности, что более чем в 60 раз мощнее самого производительного суперкомпьютера в мире на сегодняшний день. Помимо простого аппаратного обеспечения, новая вычислительная инфраструктура предоставит Tesla преимущество в обработке огромных наборов данных, что имеет решающее значение для реальных сценариев обучения ИИ. Очередь за ускорителями вычислений NVIDIA H100 растянулась до 2024 года
10.08.2023 [10:26],
Алексей Разин
Ажиотажный спрос на ускорители вычислений NVIDIA для систем искусственного интеллекта уже привёл к дефициту данного вида продукции, и старшая карта H100 с архитектурой Hopper востребована в такой степени, что все доступные объёмы таких ускорителей уже распределены до начала следующего года. 
Источник изображения: NVIDIA По крайней мере, уверенность в этом в интервью ресурсу Barron’s выразил технический директор стартапа CoreWeave Брайан Вентуро (Brian Venturo), поскольку приближённый к NVIDIA поставщик инфраструктурных решений для ускорения вычислений силами GPU имеет актуальное представление о положении дел на рынке. Как пояснил Брайан Вентуро, ещё в первом квартале текущего года с доступом к нужным объёмам ускорителей проблем не было, но в апреле всё резко изменилось. Сроки исполнения заказов растянулись до конца текущего года, и спрос неожиданно подскочил буквально за одну неделю. Ускорители теперь нужны не только крупным облачным провайдерам, но и исследовательским лабораториям, и крупным предприятиям, которые экспериментируют с внедрением систем искусственного интеллекта. Как поясняет этот поставщик ускорителей, сейчас желающие получить самую производительную версию в исполнении NVIDIA, которая обозначается H100, вынуждены рассчитывать сроки поставки на первый или второй квартал следующего года. Непосредственно CoreWeave, инвестором которой является сама NVIDIA, сможет возобновить закупку ускорителей серии H100 не ранее второго или третьего квартала следующего года. По словам руководителя компании, решения NVIDIA в этой сфере востребованы в силу наличия развитой экосистемы для разработчиков, универсальности и сопутствующей инфраструктуры передачи информации в виде скоростных решений InfiniBand. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться