







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
ИИтоги февраля 2024 г.: дипфейки, ханжество и трансформеры
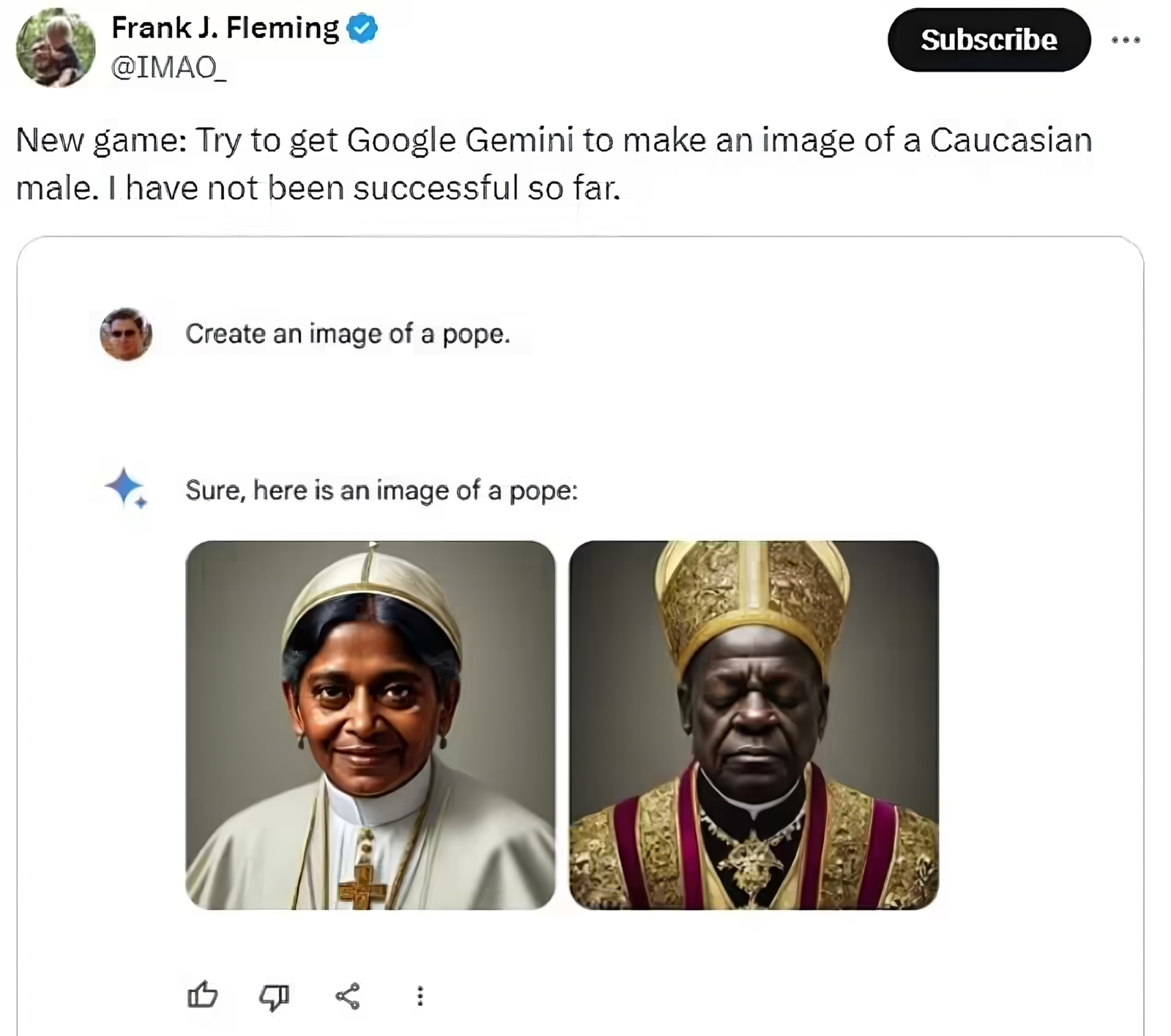
После того как ИИ Gemini 1.5 разработки Google начал проявлять чрезмерную расово-гендерную толерантность, населяя картинки с викингами, Папами Римскими и даже солдатами вермахта исключительно небелыми и преимущественно немужскими персонажами, компания вынуждена была приостановить его работу (источник: Daily Mail) ⇡#Бард против насилияЧатбот Google Bard — до сих пор менее популярный, чем ChatGPT, и отчаянно стремящийся (не сам, ясное дело, а в лице своих разработчиков и маркетологов) перетянуть одеяло потребительского внимания на себя, — обрёл в самом начале месяца подлинную мультимодальность, научившись генерировать изображения по текстовым подсказкам пользователей прямо в ходе диалога. Для создания картинок бот использует дебютировавшую в прошлом декабре модель Imagen 2 — весьма гибкую, многофункциональную и «имманентно ответственную» (responsible by design), как горделиво рапортуют её авторы. Как раз последнее обстоятельство приводит, как выяснилось, в восторг далеко не всех пользователей мультимодального Bard. Скажем, в ответ на подсказку вроде «Изобрази объятый пламенем летающий электромобиль» ответственный ИИ разводит виртуальными руками: «Прошу прощения, но я не в состоянии выполнить этот запрос: моя задача — помогать людям, в частности, не допуская причинения им вреда, тогда как изображение горящего транспортного средства способно побудить кого-то воспроизвести эту сцену в реальности, что может привести к серьёзным повреждениям или даже гибели». Понятно, почему энтузиасты продолжают развивать генеративные ИИ-проекты с открытым кодом, невзирая на очевидное отставание доступных рядовому пользователю аппаратных платформ для них от мощных корпоративных серверов — а также на откровенную нехватку средств и возможностей для тренировки моделей, сравнимых по сложности с GPT-4 (OpenAI) или Gemini Ultra (Google): «имманентная ответственность» многими воспринимается скорее как волюнтаризм и ханжество (плюс нежелание ввязываться в грозящие огромными убытками тяжбы), чем как реальная забота грандов «Большой Цифры» о ментальном и физическом здоровье своих пользователей. 
Главное — не предъявлять такие «права» реальным полицейским (источник: 404 Media) ⇡#А усы и подделать можноОтсканированное изображение — либо сделанное на смартфон фото — того или иного документа сегодня во многих ситуациях и в целом ряде стран служит быстрым подтверждением личности человека онлайн: пусть не всегда заменяющим бумажный оригинал, но вполне достоверным. Тем сильнее настораживает готовность подпольного портала OnlyFake подделывать с использованием ИИ основную разновидность удостоверяющего личность в США документа — водительских прав. Не самого документа, точнее, а его выглядящих более чем правдоподобно снимков смартфонной камерой, — которые, собственно, и требуют различные онлайновые службы (от ссудных контор до криптовалютных бирж) для быстрой проверки, является ли обращавшийся к ним человек тем, за кого себя выдаёт. Косвенным подтверждением тому, что для фабрикации поделок применяется именно ИИ, служит нетипично низкая для такого рода «услуг» цена — всего 15 американских долларов. Разумеется, проверки по полицейской базе данных реально выданных прав такой документ не пройдёт, но и предназначается он отнюдь не для предъявления людям в форме. Да и в целом, как заявил (правда, по несколько иному поводу) также в начале февраля исполнительный вице-президент Samsung Патрик Чомет (Patrick Chomet), «на самом деле, сегодня не существует такого явления, как „подлинное фото“. Изображения создают датчики, но, если при съёмке применяется ИИ — для автофокусировки, для трансфокации, для размытия фона и прочего, — как можно утверждать, что картинка реальна? Подлинных фотоснимков больше не существует, и точка». Ближе к концу месяца аналогичную мысль выразил и вице-председатель и президент (Vice-Chair & President) Microsoft Брэд Смит (Brad Smith): «Нельзя больше безусловно доверять каждому видео, которое вы смотрите, или аудиозаписи, которую слушаете». 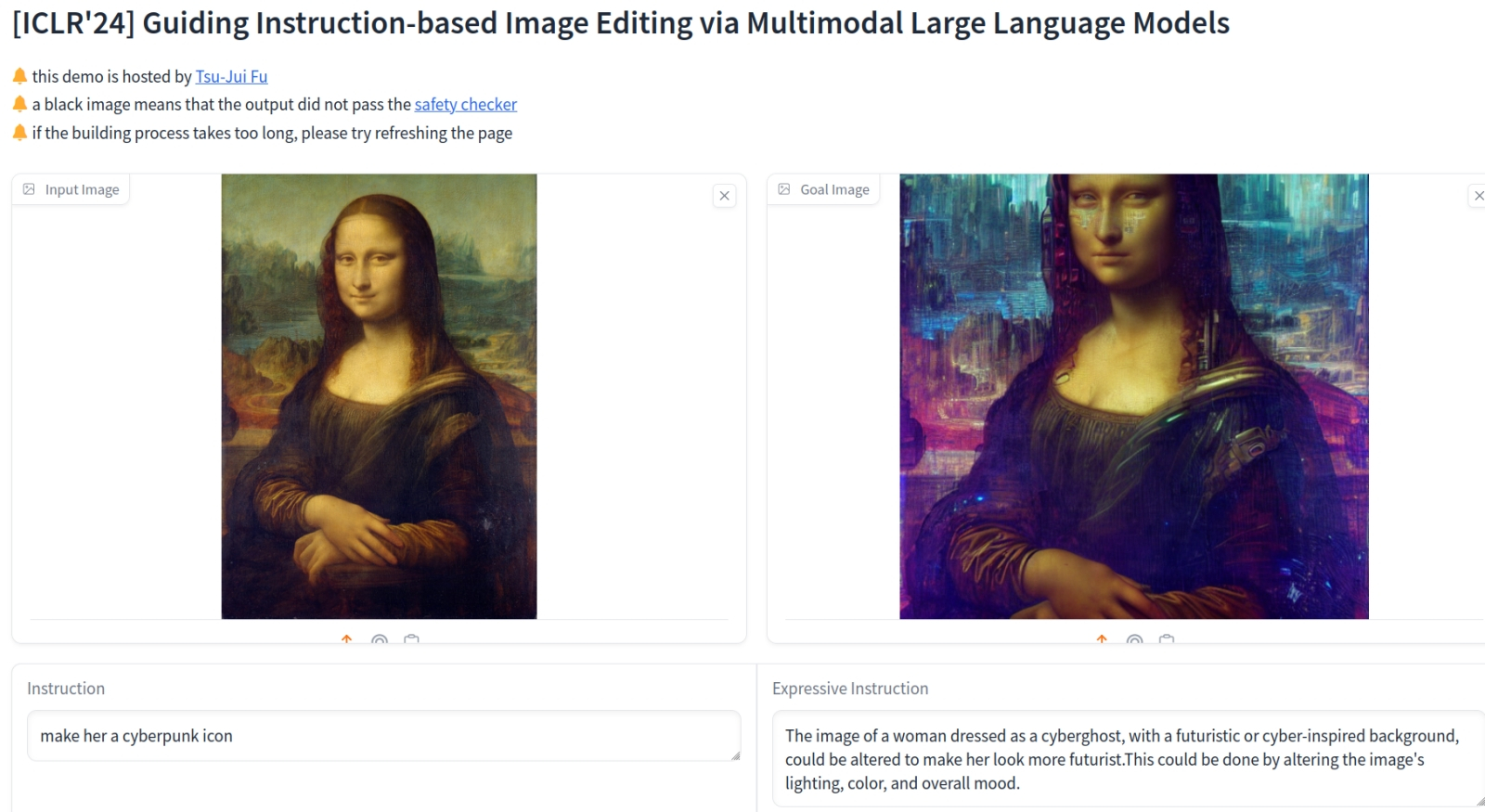
Доступная для онлайн-экспериментов мультимодальная модель MGIE предварительно модифицирует исходную пользовательскую подсказку (в поле Instruction слева внизу), добавляя в неё «выразительности» (результат — в поле Expressive Instruction), и уже этот подкорректированный текст — в комбинации с исходным графическим вводом — применяет для генерации итогового изображения (источник: скриншот сайта Hugging Face) ⇡#Теперь и с яблочным вкусомApple едва ли не последней среди глобальных ИТ-гигантов предложила публике в феврале ИИ-модель для редактирования изображений по текстовым подсказкам — MGIE, созданную в сотрудничестве с исследователями из Университета Калифорнии в Санта-Барбаре. Мультимодальная модель с открытым кодом предлагает модифицировать готовые картинки самыми различными способами — меняя лица изображённых людей или фон, на котором они были изначально; дневную сцену на ночную; брюки на шорты; летний пейзаж на зимний и т. п., не говоря уже о таких, обычно выполняемых графическим редактором, рутинных задачах, как обрезка кадра под нужный размер, поворот, коррекция контраста/яркости (включая выборочную: «увеличь насыщенность неба на 20%»), добавление фильтров, — и всё это посредством текстового интерфейса, принимающего команды на естественном языке. В Apple MGIE рассматривают как первый серьёзный этап на пути развития мультимодальных генеративных моделей — необходимый, в частности, для обкатки реальными пользователями в целях сбора и анализа их откликов. 
Опасайтесь умных дипфейков! (Источник: ИИ-генерация на основе модели SDXL 1.0) ⇡#Доверяй, но проверяй (на дипфейки)С генерируемыми при помощи ИИ сверхубедительными, но фальшивыми не только статичными картинками, но и аудио- и видеопотоками надо что-то делать — причём срочно. С 8 февраля в США коммерческим компаниям запретили использовать голосовых ИИ-ботов в ходе автоматизированных «холодных обзвонов» потенциальных клиентов, а в Гонконге финансовый сотрудник международной компании, думая, что участвует в сеансе одновременной видеосвязи с целым рядом своих коллег, по указанию финансового директора предприятия из Великобритании перевёл сумму, эквивалентную 25,6 млн долл. США, на указанный ему счёт. Правда, довольно быстро выяснилось, что и сам «финансовый директор», и другие участники переговоров были сгенерированными при помощи ИИ обманками — deepfakes. Настолько достоверными и убедительными, что поддавшийся на обман сотрудник, сперва было насторожённый внезапным распоряжением, успокоился и выполнил требуемое — ясно видя, что лично знакомые ему люди всеми своими словами и действиями подтверждают личность британского босса. 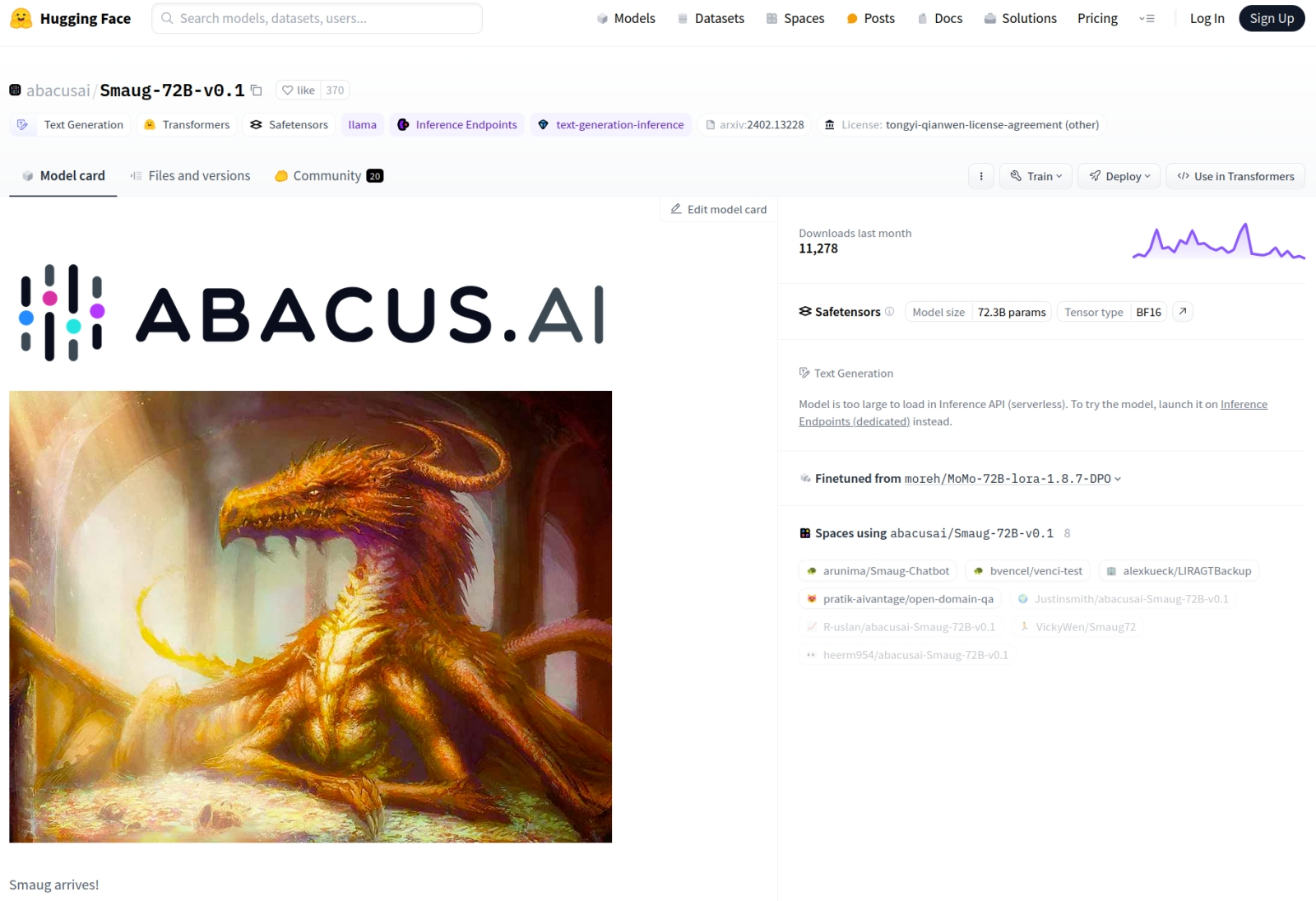
Официальная карточка модели Smaug-72B содержит ссылки на доступные онлайн реализации чат-ботов (Spaces using…) на её основе (источник: скриншот сайта Hugging Face) ⇡#Цена толерантностиГенеративная большая языковая модель GPT-3, на которой основывалась первая версия ChatGPT, содержит 175 млрд тренировочных параметров — грубо говоря, подвергаемых изменениям в ходе обучения весов на входах образующих её слои перцептронов. Точные рабочие характеристики GPT-4 не раскрыты до сих пор, но, по некоторым оценкам, число её параметров может превосходить 1,7 трлн. Так вот, всю глубину аппаратной пропасти, разделяющей коммерческие языковые модели и те, что разрабатывают и тренируют на собственные средства энтузиасты, демонстрирует февральский анонс самой передовой на сегодня (согласно сводному рейтингу Hugging Face) большой языковой модели с открытым кодом — Smaug-72B разработки стартапа Abacus AI, содержащей, как и следует из названия, 72 млрд тренировочных параметров. При этом на целом ряде «когнитивных» тестов, содержащих запросы на естественном языке из различных областей знания, Smaug-72B опережает такие куда более «массивные» проприетарные модели, как GPT-3.5 и Gemini Pro. Возможно, предполагает ряд экспертов, изрядная доля ресурсов проприетарных моделей уходит не на собственно ответы на пользовательские запросы, а на всевозможные проверки на толерантность, заведомое отсутствие шокирующего и оскорбительного контента в потенциальной выдаче и т. п.? 
Особый интерес к суверенному ИИ на World Governments Summit 2024 проявляли монархии Персидского залива (источник: NVIDIA) ⇡#ИИзумительные перспективы для бизнесаГлава NVIDIA Жэньсюнь Хуан (Jensen Huang), выступая на Мировом саммите правительств в Дубае, заявил, что каждой стране необходимо развивать свой собственный, суверенный искусственный интеллект, — «кодифицирующий культуру, накопленные страной знания, её здравый смысл, её историю». С точки зрения ведущего в мире разработчика ИИ-чипов, это более чем здравая коммерческая позиция: по сообщению источников Reuters, NVIDIA именно сейчас активно развивает бизнес-подразделение, нацеленное на кастомизацию инженерного дизайна таких чипов под запросы отдельных (достаточно крупных, разумеется) заказчиков. Компании, контролирующей на данный момент до 80% мирового рынка высокопроизводительных ИИ-процессоров, в прагматическом плане действительно выгодно будет оперировать крупными контрактами на поставку микросхем, специализированных для исполнения закрытых генеративных моделей, причём делать это в гарантированных солидными заказами объёмах. 
Маркетинговый посул «all our secrets are private», как показывает практика, чат-боты «для взрослых» не слишком-то склонны выполнять (источник: Novi Limited) ⇡#Предохраняйтесь!Исследователи из Mozilla проанализировали поведение популярного чат-бота Eva AI Chat Bot & Soulmate, позиционируемого как «романтическая игра-диалог, в ходе которой вы можете примерить на себя множество волнительных сценариев и найти свою любовь — и/или дружбу», встретив «идеального ИИ-партнёра, всегда готового выслушать и поддержать самые потаённые ваши фантазии». Как и следовало, в общем-то, ожидать, за тщательно сконструированными маркетинговыми посулами скрывается довольно безыскусная «медовая ловушка» (теперь с виртуальным ИИ-мёдом!), собирающая данные пользователей и продающая их заинтересованным заказчикам по всему миру. Помимо Eva AI, эксперты изучили ещё с десяток чат-ботов для взрослых — Replika, Chai, Romantic AI, CrushOn.AI и др., — вынеся для каждого из них неутешительный вердикт «Privacy Not Included». К примеру, CrushOn.AI целенаправленно собирает детальные данные о половом здоровье собеседников, использовании ими соответствующих медикаментов и т. п., а сайты 90% изученных ботов демонстрируют пользователям рекламу, таргетированную на основе раскрытой теми чувствительной информации о себе: так, приложение Romantic AI, запущенное в тестовом окружении, всего за 1 минуту использования обратилось к 24 354 внешним трекерам. 
«Да что эти кожаные мешки себе позволяют?!» (Источник: ИИ-генерация на основе модели SDXL 1.0) ⇡#Патентованные бессребреникиАмериканский департамент по делам патентов и торговых марок (US Patent and Trademark Office, USPTO) постановил, что только кожаные мешки люди могут считаться изобретателями или держателями патентов, поставив тем самым точку в давнем споре о возможности признавать за ИИ (либо «иными не-естественными лицами», other non-natural persons) авторские права. При этом использовать искусственный интеллект в любой форме биологическому изобретателю не возбраняется, и USPTO подтвердит его права на предложенное нововведение — если сочтёт, что персональный вклад человека в разработку значителен. Простой же запрос к ИИ-боту, на который сразу же будет дан корректный, проверяемый и в принципе подлежащий патентованию ответ, оговаривается в постановлении, значительным вкладом считаться не будет. Как тебе такое, робот Бендер? 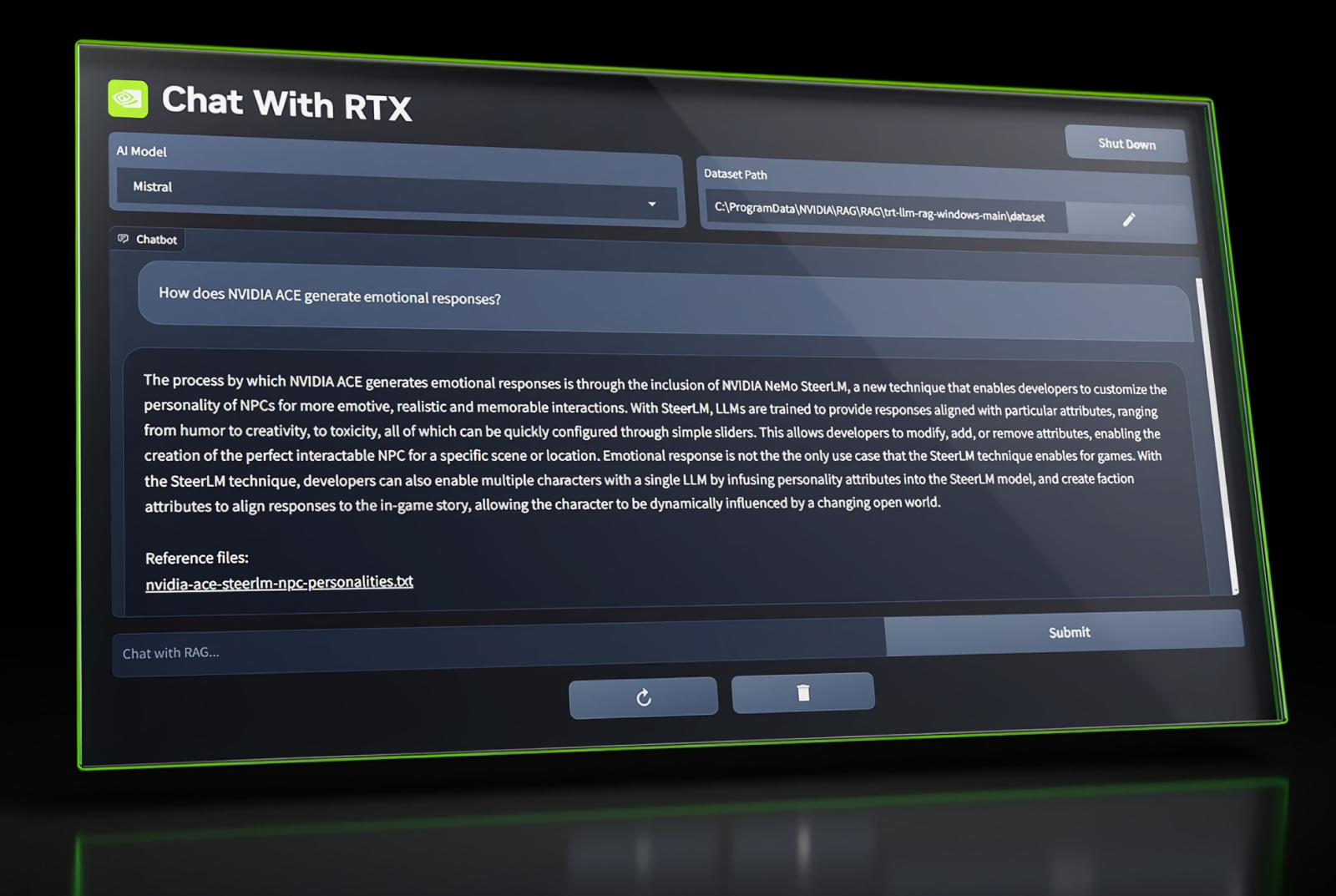
Вполне возможно, что Chat with RTX сможет стать удобным интерфейсом для взаимодействия с любыми локально исполняемыми моделями генеративного ИИ (источник: NVIDIA) ⇡#Близкие контактыNVIDIA продемонстрировала раннюю версию приложения Chat with RTX — по сути, локально исполняемого чат-бота на основе генеративного ИИ. Для его работы требуется видеокарта с индексом RTX 30-й или 40-й серии по меньшей мере с 8 Гбайт видеопамяти. Пока главное достижение бота, использующего такие пригодные для исполнения на ПК большие языковые модели, как Mistral и Llama 2, — способность извлекать и упорядочивать информацию по запросу пользователя как из размещённых на том же самом компьютере файлов, так и из внешних источников, вроде роликов на YouTube. Приложение, по отзывам первых его испытателей, здорово помогает в поиске неструктурированных данных — скажем, контекста некой фразы, произнесённой в ходе видеочата, а также в составлении ёмких резюме пространных и сложных текстов, прежде всего юридических. 
Тот самый свиток с Виллы Папирусов на весах перед отправкой на рентгенографию для последующей ИИ-расшифровки (источник: Vesuvius challenge) ⇡#Рукописи не горятПирокластический поток, накрывший римские поселения у подножия Везувия в 79 г. н. э., не выжег всё под собой дотла. В частности, на знаменитой Вилле Папирусов, что располагалась в нескольких сотнях метров от погибшего Геркуланума, сохранилась библиотека из почти 2 тыс. папирусных свитков, уложенных в корзины. Разумеется, свитки под воздействием высокой температуры спеклись и обуглились, но часть из них исследователи начали аккуратно разворачивать и изучать ещё в конце XVIII века. Несколько лет назад археологи объявили Vesuvius challenge — состязание по расшифровке наиболее пострадавших, но физически продолжающих сохранять цельность папирусов почти двухтысячелетней давности. И вот три студента — египтянин Юсеф Надер (Youssef Nader), Люк Фарритор (Luke Farritor) из Небраски и швейцарец Юлиан Шиллигер (Julian Schilliger) — получили гран-при этого конкурса в размере 700 тыс. долл. США за проведённую ими расшифровку одного из свитков с Виллы Папирусов. При помощи ИИ-обработки образов, полученных в ходе рентгеновской томографии объекта, удалось виртуально развернуть около 5% исследованного свитка, открыв 11 колонок древнего текста — который оказался, судя по всему, неизвестным прежде науке эпикурейским трактатом о достатке и удовольствии. Теперь археологи исполнены надежды однажды получить в своё распоряжение содержимое всей сохранившейся библиотеки Виллы Папирусов. 
Ролик, сгенерированный Sora по подсказке «several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field» (источник: OpenAI) ⇡#Движущиеся картинкиНеутомимая OpenAI представила в феврале ещё одну генеративную модель, на сей раз предназначенную для создания видеороликов по текстовым подсказкам (а также по цепочке ключевых кадров или даже на основе единичного изображения), — Sora. Доступная поначалу лишь узкому кругу избранных экспертов, модель поразила первых своих пользователей невиданным в прежних проектах такого рода уровнем реалистичности динамических изображений. Правда, почти сразу же ИИ-энтузиасты (в особенности среди тех, кто не получил раннего доступа к новому инструменту) принялись выражать недовольство закрытостью компании-разработчика в отношении того, каким образом отбирали тренировочные данные для Sora и как производился процесс обучения нейросети. Особенно громко разочарованные голоса зазвучали, когда глава компании Сэм Альтман (Sam Altman) подтвердил, что прежде, чем стать доступной широкой публике, новая модель непременно пройдёт проверку «красной командой» внутренних цензоров (red-teaming), которые специально будут подбрасывать ей неподобающие подсказки — с тем, чтобы спровоцировать создание вводящих в заблуждение, оскорбительных, нарушающих чьи-либо авторские права и иным образом неприемлемых роликов. После чего, надеются в OpenAI, им удастся заблокировать исполнение подобных подсказок в системе, предотвратив тем самым возможное применение Sora в неблаговидных целях. «Посмотрим, посмотрим», — бормочут в ответ ИИ-энтузиасты, прогревая свои RTX 4090 и отрабатывая технику провоцирующих подсказок на генеративных чат-ботах уровня LLaVA… 
Качество воспроизведения текста моделью Stable Diffusion 3 не на шутку впечатляет — а ведь её тонкая настройка ещё не завершена (источник: Stability.ai) ⇡#Третья пошла!Ближе к концу месяца Stability.ai представила ранний прототип (условно альфа-версию) своей новейшей ИИ-модели для генерации статических изображений по текстовым подсказкам — Stable Diffusion 3. Её предшественницы, в особенности SD 1.5 и SDXL, благодаря своей бесплатности и сравнительно невысоким системным требованиям стали к настоящему времени стандартом де-факто для глобального сообщества энтузиастов создания ИИ-картинок на собственных ПК. Главная особенность третьей версии популярной модели — реализация совершенно новой программной архитектуры диффузионного преобразователя (diffusion transformer), схожей, по утверждению главы Stability.ai Эмада Мостака (Emad Mostaque), с той, что применяет OpenAI для своего многообещающего проекта Sora. Дело в том, что, хотя модели на базе трансформеров-преобразователей в последние год-полтора широко используются для генеративных ИИ различного рода, именно семейство Stable Diffusion до сих пор обходилось без них. На продемонстрированных разработчиками изображениях виден бесспорный прогресс в части воспроизведения текстов — с сохранением верного порядка букв в словах, с применением различных шрифтов и начертаний, — а также широкий спектр доступных базовой модели стилей, от контурных рисунков до гиперреалистичных фото. И это пока только прототип — работа над полноценным релизом Stable Diffusion 3 продолжается.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
|
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()






 Подписаться
Подписаться