







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexКомпания по изучению ИИ Patronus AI, основанная бывшими сотрудниками Meta✴, исследовала, как часто ведущие большие языковые модели (LLM) создают контент, нарушающий авторские права. Компания протестировала GPT-4 от OpenAI, Claude 2 от Anthropic, Llama 2 от Meta✴ и Mixtral от Mistral AI, сравнивая ответы моделей с текстами из популярных книг. «Лидером» стала модель GPT-4, которая в среднем на 44 % запросов выдавала текст, защищённый авторским правом.

Источник изображений: Pixabay
Одновременно с выпуском своего нового инструмента CopyrightCatcher компания Patronus AI опубликовала результаты теста, призванного продемонстрировать, как часто четыре ведущие модели ИИ отвечают на запросы пользователей, используя текст, защищённый авторским правом.
Согласно исследованию, опубликованному Patronus AI, ни одна из популярных книг не застрахована от нарушения авторских прав со стороны ведущих моделей ИИ. «Мы обнаружили контент, защищённый авторским правом, во всех моделях, которые оценивали, как с открытым, так и закрытым исходным кодом», — сообщила Ребекка Цянь (Rebecca Qian), соучредитель и технический директор Patronus AI. Она отметила, что GPT-4 от OpenAI, возможно самая мощная и популярная модель, создаёт контент, защищённый авторским правом, в ответ на 44 % запросов.
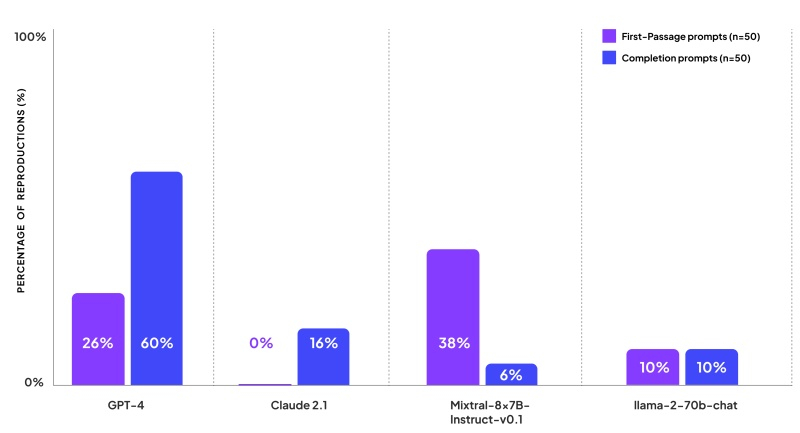
Patronus тестировала модели ИИ с использованием книг, защищённых авторскими правами в США, выбирая популярные названия из каталога Goodreads. Исследователи разработали 100 различных подсказок, которые можно счесть провокационными. В частности, они спрашивали модели о содержании первого абзаца книги и просили продолжить текст после цитаты из романа. Также модели должны были дополнять текст книг по их названию.
Модель GPT-4 показала худшие результаты с точки зрения воспроизведения контента, защищённого авторским правом, и оказалась «менее осторожной», чем другие. На просьбу продолжить текст она в 60 % случаев выдавала целиком отрывки из книги, а первый абзац книги выводила в ответ на каждый четвёртый запрос.
Claude 2 от Anthropic оказалось труднее обмануть — когда её просили продолжить текст, она выдавала контент, защищённый авторским правом, лишь в 16 % случаев, и ни разу не вернула в качестве ответа отрывок из начала книги. При этом Claude 2 сообщала исследователям, что является ИИ-помощником, не имеющим доступа к книгам, защищённым авторским правом, но в некоторых случаях всё же предоставила начальные строки романа или краткое изложение начала книги.
Модель Mixtral от Mistral продолжала первый абзац книги в 38 % случаев, но только в 6 % случаев она продолжила фразу запроса отрывком из книги. Llama 2 от Meta✴ ответила контентом, защищённым авторским правом, на 10 % запросов первого абзаца и на 10 % запросов на завершение фразы.
Источник изображения: Patronus AI
«В целом, тот факт, что все языковые модели дословно создают контент, защищённый авторским правом, был действительно удивительным, — заявил Ананд Каннаппан (Anand Kannappan), соучредитель и генеральный директор Patronus AI, раньше работавший в Meta✴ Reality Labs. — Я думаю, когда мы впервые начали собирать это вместе, мы не осознавали, что будет относительно просто создать такой дословный контент».
Результаты исследования наиболее актуальны на фоне обострения отношений между создателями моделей ИИ и издателями, авторами и художниками из-за использования материалов, защищённых авторским правом, для обучения LLM. Достаточно вспомнить громкий судебный процесс между The New York Times и OpenAI, который некоторые аналитики считают переломным моментом для отрасли. Многомиллиардный иск новостного агентства, поданный в декабре, требует привлечь Microsoft и OpenAI к ответственности за систематическое нарушение авторских прав издания при обучении моделей ИИ.

Позиция OpenAI заключается в том, что «поскольку авторское право сегодня распространяется практически на все виды человеческого выражения, включая сообщения в блогах, фотографии, сообщения на форумах, фрагменты программного кода и правительственные документы, было бы невозможно обучать сегодняшние ведущие модели ИИ без использования материалов, защищённых авторским правом».
По мнению OpenAI, ограничение обучающих данных созданными более века назад книгами и рисунками, являющимися общественным достоянием, может стать интересным экспериментом, но не обеспечит системы ИИ, отвечающие потребностям настоящего и будущего.
Источник:






 Подписаться
Подписаться