|
Опрос
|
реклама
Быстрый переход
«Наш контент бесплатный, а инфраструктура — нет»: ИИ-боты разоряют «Википедию»
02.04.2025 [19:54],
Сергей Сурабекянц
«Википедия» расплачивается за бум искусственного интеллекта — онлайн-энциклопедия сталкивается с растущими расходами из-за ботов, которые копируют её статьи для обучения моделей искусственного интеллекта, что впустую расходует ресурсы и в разы увеличивает трафик и нагрузку на сайт. Только за последние три месяца трафик, генерируемый ИИ-краулерами, вырос на 50 %. 
Источник изображения: «Википедия» Фонд Wikimedia (некоммерческая организация, управляющая «Википедией») заявил, что «автоматизированные запросы на наш контент выросли в геометрической прогрессии». По данным фонда, с января 2024 года пропускная способность, используемая для загрузки мультимедийного контента, выросла на 50 %. Однако трафик исходит не от людей, а от автоматизированных программ, которые постоянно загружают изображения с открытой лицензией для передачи их моделям ИИ. «Наша инфраструктура создана для того, чтобы выдерживать внезапные всплески трафика от людей во время мероприятий с высоким интересом, но объем трафика, генерируемого ботами-скрейперами, беспрецедентен и представляет растущие риски и расходы», — сообщила «Википедия». Боты часто собирают данные из менее популярных статей «Википедии». Специалисты «Википедии» утверждают, что по крайней мере 65 % подобного трафика, поступает от ботов, что является непропорционально большим объёмом, учитывая, что общее количество просмотров страниц ботами составляет около 35 %. Также боты проявляют интерес к «ключевым системам в инфраструктуре разработчиков, таким как наша платформа проверки кода или наш баг-трекер», что ещё больше нагружает ресурсы сайта. «Википедия» была вынуждена ввести индивидуальные ограничения скорости для ИИ-ботов или вообще запретить доступ некоторым из них. Но для решения проблемы в долгосрочной перспективе фонд разрабатывает план «Ответственного использования инфраструктуры». План предусматривает сбор отзывов от сообщества «Википедии» о способах определения трафика от ИИ-ботов и фильтрации их доступа. Социальная платформа Reddit столкнулась с похожей проблемой в 2023 году. Например, Microsoft без уведомления Reddit использовала данные платформы для обучения моделей ИИ, что вынудило Reddit заблокировать ботов Microsoft. После этого инцидента Reddit решила взимать плату со сторонних разработчиков за доступ к своему API. Это привело к массовым протестам разработчиков и закрытию некоторых популярных форумов Reddit. Сотни знаменитостей подписали открытое письмо с требованием запретить «свободу обучения» ИИ
18.03.2025 [18:37],
Сергей Сурабекянц
Более 400 актёров, музыкантов, режиссёров, писателей и представителей других творческих профессий подписали открытое письмо. Они призвали администрацию США запретить обучение моделей ИИ на защищённых авторским правом работах. Письмо стало ответом на предлагаемую OpenAI и Google «свободу обучения» моделей ИИ без получения разрешения от правообладателей и соответствующей компенсации. 
Источник изображения: unsplash.com OpenAI заявила, что смягчение законов об авторском праве будет способствовать «свободе обучения» и поможет защитить национальную безопасность Америки. OpenAI и Google уверены, что это поможет «укрепить лидерство Америки» в конкурентной борьбе с Китаем в области разработки ИИ. Звёзды, в свою очередь, не видят причин отменять защиту авторских прав, чтобы помочь улучшить модели ИИ: «Мы твёрдо убеждены, что глобальное лидерство Америки в области ИИ не должно достигаться за счёт наших важнейших творческих отраслей». В открытом письме творческие работники утверждают, что «свобода обучения» ИИ подорвёт экономическую и культурную мощь страны и ослабит защиту авторских прав, в то время как Google и OpenAI получат исключительные права на «свободную эксплуатацию творческих и образовательных отраслей Америки, несмотря на их [и так] значительные доходы и доступные средства». «Америка стала мировым культурным центром не случайно, — говорится в письме. — Наш успех напрямую обусловлен нашим фундаментальным уважением к интеллектуальной собственности и авторским правам, которое вознаграждает творческий риск талантливых и трудолюбивых американцев из каждого штата». В письме отмечается, что индустрия развлечений Америки предоставляет работу 2,3 млн граждан США и ежегодно выплачивает $229 млрд в виде заработной платы, а также обеспечивает «основу для американского демократического влияния и мягкой силы за рубежом». Среди подписавших письмо протеста фигурируют такие знаменитости мирового масштаба, как Бен Стиллер (Ben Stiller), Кейт Бланшетт (Cate Blanchett), Пол Маккартни (Paul McCartney), Гильермо дель Торо (Guillermo del Toro), Джозеф Гордон-Левитт (Joseph Gordon-Levitt) и многие другие, не менее известные представители творческих профессий. 
Источник изображения: techspot.com Знаменитости протестуют против этой проблемы не только в США. Великобритания собирается изменить закон об авторском праве, что позволит обучать модели ИИ без разрешения владельцев авторских прав и оплаты, если создатели заранее не откажутся от этого. В знак протеста группа из 1000 музыкантов выпустила «тихий» альбом «Is this what we want?» («Разве этого мы хотим?»), содержащий лишь записи пустых студий и концертных залов. Помимо этого, на первых полосах национальных СМИ был опубликован лозунг музыкантов «Make it fair» («Давайте сделаем по-справедливому») с призывом к диалогу индустрии с разработчиками ИИ. «Разве этого мы хотим?» — 1000 артистов выпустили безмолвный альбом-протест против воровства музыки в угоду ИИ
25.02.2025 [18:21],
Сергей Сурабекянц
Великобритания собирается изменить закон об авторском праве, чтобы привлечь в страну больше ИИ-компаний. Обновлённый закон позволит обучать модели ИИ на контенте из интернета без разрешения владельцев авторских прав и оплаты, если создатели заранее не «откажутся» от этого. В знак протеста группа из 1000 музыкантов выпустила «тихий» альбом «Is This What We Want?» («Разве этого мы хотим?»), содержащий лишь записи пустых студий и концертных залов. 
Источник изображения: Pixabay Альбом «Is This What We Want?», который иначе как «криком души» не назвать, содержит треки Кейт Буш (Kate Bush), Имоджен Хип (Imogen Heap), а также современных классических композиторов Макса Рихтера (Max Richter) и Томаса Хьюитта Джонса (Thomas Hewitt Jones). Их соавторами выступили Энни Леннокс (Annie Lennox), Дэймон Албарн (Damon Albarn), Билли Оушен (Billy Ocean), The Clash, Pet Shop Boys, Mystery Jets, Юсуф (Yusuf), Кэт Стивенс (Cat Stevens), Риз Ахмед (Riz Ahmed), Тори Амос (Tori Amos), Ханс Циммер (Hans Zimmer) и другие композиторы и исполнители. Но это не совместное выступление артистов, подобное всемирно известной композиции «We are the world». Новый альбом вообще не содержит музыки, как таковой. Вместо этого артисты собрали записи пустых студий и концертных залов — символическое представление того, к чему приведут запланированные изменения в законе об авторском праве. Названия 12 треков, вошедших в альбом, образуют предложение «Британское правительство не должно легализовать воровство музыки в целях получения выгоды компаниями, занимающимися искусственным интеллектом» («The British government must not legalize music theft to benefit AI companies»). 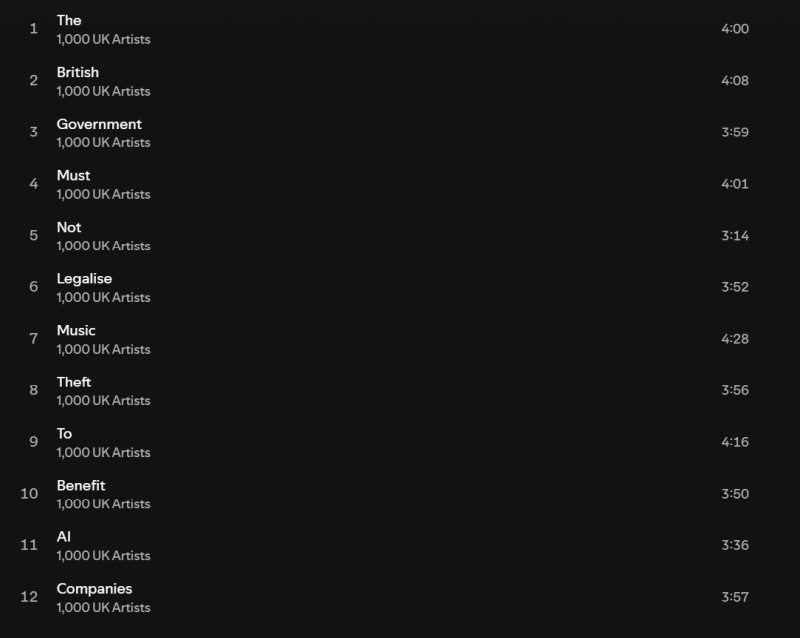
Источник изображений: Spotify «Вы можете услышать, как носятся мои кошки, — так Хьюитт Джонс описал свой вклад в альбом. — У меня в студии две кошки, которые целыми днями мешают мне работать». Организатор проекта Эд Ньютон-Рекс (Ed Newton-Rex) возглавляет масштабную кампанию против обучения ИИ без лицензии. Опубликованную им петицию подписали более 47 000 писателей, художников, актёров и других представителей творческих кругов, причём почти 10 000 из них примкнули к протестам в последние пять недель, после объявления правительства Великобритании о масштабном изменении стратегии в области ИИ и авторского права. Выпуск альбома состоится как раз перед запланированными изменениями в законе об авторском праве в Великобритании, согласно которым артисты, не желающие, чтобы их работы использовались для обучения ИИ, должны будут заблаговременно «отказаться» от такой перспективы. Это фактически создаёт проигрышную ситуацию для музыкантов, поскольку нет никакого метода заблаговременного отказа или чёткого способа отслеживать, какой именно материал был использован для обучения ИИ. «Мы знаем, что схемы отказа просто не принимаются», — утверждает Ньютон-Рекс. «Нам десятилетиями говорили, что мы должны делиться своей работой в Сети, потому что это хорошо для распространения. Но теперь компании, занимающиеся ИИ, и, что невероятно, правительства разворачиваются и говорят: “Ну, вы выкладываете это в сеть бесплатно…” — говорит Ньютон-Рекс. — Так что теперь артисты просто прекращают создавать и делиться своей работой». По словам артистов, единственным решением в этой ситуации является выпуск своих произведений на других рынках, где они будут лучше защищены, например, в Швейцарии.  Альбом «Is This What We Want?» — лишь одна из форм протеста против сложившейся ситуации с авторским правом при обучении ИИ. Организаторы сообщили, что альбом будет широко размещён на музыкальных платформах уже сегодня, и любые пожертвования или доходы от его реализации будут направлены в благотворительную организацию Help Musicians. В России создали первый ИИ с мышлением ребёнка
13.02.2025 [20:19],
Владимир Фетисов
Российские программисты создали искусственный интеллект, способный адаптироваться к мышлению ребёнка для помощи в обучении по школьной программе. Для этого разработчики объединили собственный ИИ-алгоритм и ИИ-ассистентов, адаптированных под каждый школьный предмет. В результате было создано, по сути, полноценное образовательное учреждение — ИИ «Препод». 
Источник изображения: Copilot Архитектура платформы предусматривает наличие ассистента-психолога, методистов и других профильных специалистов. Такой подход позволил организовать мультидисциплинарную экосистему ИИ «Препод» для поддержки учебного процесса. В настоящее время на платформе доступно свыше 500 уникальных ИИ-помощников — это значительно больше, чем количество учителей в обычной школе. Объём знаний ИИ-помощников позволяет находить подход к детям разного возраста, а также учитывать их особенности психологического развития и склонности к различным предметам. Найти общий язык с детьми разного возраста ИИ-помощнику помогает знание не только школьных предметов, но и огромного массива другой информации, включая детскую литературу, мультфильмы, фильмы, мемы и компьютерные игры. Такой подход позволяет детям обучаться как с использованием формального «школьного языка», так и с применением понятных возрасту шуток, цитат и других элементов культуры. Специализированные ИИ-помощники в процессе работы с ребёнком проводят глубокую оценку его знаний и действуют как узконаправленные специалисты в конкретных областях. За счёт этого достигается качество образования, максимально приближенное к школьной системе. ИИ «Препод» создан на основе Python/Django с интегрированными специализированными ИИ-алгоритмами. В основе платформы лежит ИИ-модуль, который отсеивает петабайты ненужной информации, отбирая важные данные в условиях Big Data на распределённых вычислительных кластерах. Система самообучалась в течение восьми месяцев, при этом особое внимание уделялось выбору оптимальной обучающей парадигмы нейросетей. Искусственный интеллект научили разоблачать учёных-шарлатанов
27.11.2024 [18:56],
Геннадий Детинич
Научный поиск вскоре может претерпеть коренные изменения — искусственный интеллект показал себя в качестве непревзойдённого человеком инструмента для анализа невообразимых объёмов специальной литературы. В поставленном эксперименте ИИ смог точнее людей-экспертов дать оценку фейковым и настоящим научным открытиям. Это облегчит людям научный поиск, позволив машинам просеивать тонны сырой информации в поисках перспективных направлений. 
Источник изображения: ИИ-генерация Кандинский 3.1/3DNews С самого начала разработчики генеративных ИИ (ChatGPT и прочих) сосредоточились на возможности больших языковых моделей (LLM) отвечать на вопросы, обобщая обширные данные, на которых они обучались. Учёные из Университетского колледжа Лондона (UCL) поставили перед собой другую цель. Они задались вопросом, могут ли LLM синтезировать знания — извлекать закономерности из научной литературы и использовать их для анализа новых научных работ? Как показал опыт, ИИ удалось превзойти людей в точности выдачи оценок рецензируемым работам. «Научный прогресс часто основывается на методе проб и ошибок, но каждый тщательный эксперимент требует времени и ресурсов. Даже самые опытные исследователи могут упускать из виду важные выводы из литературы. Наша работа исследует, могут ли LLM выявлять закономерности в обширных научных текстах и прогнозировать результаты экспериментов», — поясняют авторы работы. Нетрудно представить, что привлечение ИИ к рецензированию далеко выйдет за пределы простого поиска знаний. Это может оказаться прорывом во всех областях науки, экономя учёным время и деньги. Эксперимент был поставлен на анализе пакета научных работ по нейробиологии, но может быть распространён на любые области науки. Исследователи подготовили множество пар рефератов, состоящих из одной настоящей научной работы и одной фейковой — содержащей правдоподобные, но неверные результаты и выводы. Пары документов были проанализированы 15 LLM общего назначения и 117 экспертами по неврологии человека, прошедшими специальный отбор. Все они должны были отделить настоящие работы от поддельных. Все LLM превзошли нейробиологов: точность ИИ в среднем составила 81 %, а точность людей — 63 %. В случае анализа работ лучшими среди экспертов-людей точность повышалась до 66 %, но даже близко не подбиралась к точности ИИ. А когда LLM специально обучили на базе данных по нейробиологии, точность предсказания повысилась до 86 %. Исследователи говорят, что это открытие прокладывает путь к будущему, в котором эксперты-люди смогут сотрудничать с хорошо откалиброванными моделями. Проделанная работа также показывает, что большинство новых открытий вовсе не новые. ИИ отлично вскрывает эту особенность современной науки. Благодаря новому инструменту учёные, по крайней мере, будут знать, стоит ли заниматься выбранным направлением для исследования или проще поискать его результаты в интернете. Google представила Learn About — инструмент интерактивного обучения на базе искусственного интеллекта
02.11.2024 [17:48],
Владимир Фетисов
Компания Google без лишнего шума представила новый образовательный сервис на основе искусственного интеллекта под названием Learn About, анонс которого состоялся на прошедшей в мае конференции Google I/O. Сервис призван изменить подход к обучению чему-либо, превращая этот процесс в увлекательный диалог вместо стандартного чтения текста и просмотра сопутствующих изображений. 
Источник изображения: maginative.com Инструмент Learn About ориентирован на людей, которые регулярно используют поисковые системы для изучения чего-то нового. Однако в данном случае на смену традиционным методам обучения, в которых информация преподносится статично в процессе чтения текста и просмотра изображений, приходит метод, предлагающий персонализированное интерактивное обучение. В некотором смысле новый сервис можно назвать своеобразным виртуальным репетиром, которому можно задавать вопросы или предоставлять собственные материалы. Возможно изучение специально подобранных тем широкого спектра, начиная от повседневных вопросов и заканчивая сложными академическими предметами. Алгоритмы на базе нейросетей генерируют контент, который поможет разобраться в теме, связать основные понятия, углубить понимание вопроса. Learn About объединяется традиционный обучающий контент, такой как видео, статьи и изображения, с возможностями искусственного интеллекта, и позиционируется Google как новый вид цифрового помощника по обучению. Learn About обладает большим потенциалом, но Google даёт понять, что на данном этапе это всё ещё эксперимент, поскольку сервис может предоставлять неточную или вводящую в заблуждение информацию. Пользователям рекомендуется проверять факты и оставлять отзывы по итогам взаимодействия с сервисом. Отмечается, что на данный момент Learn About не сохраняет данные о взаимодействии с пользователями, история чата исчезнет, как только будет закрыта веб-страница. OSI ввела строгие стандарты открытости для Meta✴ Llama и других ИИ-моделей
29.10.2024 [07:19],
Дмитрий Федоров
Open Source Initiative (OSI), десятилетиями определяющая стандарты открытого программного обеспечения (ПО), ввела определение для понятия «открытый ИИ». Теперь, чтобы модель ИИ считалась действительно открытой, OSI требует предоставления доступа к данным, использованным для её обучения, полному исходному коду, а также ко всем параметрам и весам, определяющим её поведение. Эти новые условия могут существенно повлиять на технологическую индустрию, поскольку такие ИИ-модели, как Llama компании Meta✴ не соответствуют этим стандартам. 
Источник изображения: BrianPenny / Pixabay Неудивительно, что Meta✴ придерживается иной точки зрения, считая, что подход OSI не учитывает особенностей современных ИИ-систем. Представитель компании Фейт Айшен (Faith Eischen) подчеркнула, что Meta✴, хотя и поддерживает многие инициативы OSI, не согласна с предложенным определением, поскольку, по её словам, «единого стандарта для открытого ИИ не существует». Она также добавила, что Meta✴ продолжит работать с OSI и другими организациями, чтобы обеспечить «ответственное расширение доступа к ИИ» вне зависимости от формальных критериев. При этом Meta✴ подчёркивает, что её модель Llama ограничена в коммерческом применении в приложениях с аудиторией более 700 млн пользователей, что противоречит стандартам OSI, подразумевающим полную свободу её использования и модификации. Принципы OSI, определяющие стандарты открытого ПО, на протяжении 25 лет признаются сообществом разработчиков и активно им используются. Благодаря этим принципам разработчики могут свободно использовать чужие наработки, не опасаясь юридических претензий. Новое определение OSI для ИИ-моделей предполагает аналогичное применение принципов открытости, однако для техногигантов, таких как Meta✴, это может стать серьёзным вызовом. Недавно некоммерческая организация Linux Foundation также вступила в обсуждение, предложив свою трактовку «открытого ИИ», что подчёркивает возрастающую значимость данной темы для всей ИТ-индустрии. Исполнительный директор OSI Стефано Маффулли (Stefano Maffulli) отметил, что разработка нового определения «открытого ИИ» заняла два года и включала консультации с экспертами в области машинного обучения (ML) и обработки естественного языка (NLP), философами, представителями Creative Commons и другими специалистами. Этот процесс позволил OSI создать определение, которое может стать основой для борьбы с так называемым «open washing», когда компании заявляют о своей открытости, но фактически ограничивают возможности использования и модификации своих продуктов. Meta✴ объясняет своё нежелание раскрывать данные обучения ИИ вопросами безопасности, однако критики указывают на иные мотивы, среди которых минимизация юридических рисков и сохранение конкурентного преимущества. Многие ИИ-модели, вероятно, обучены на материалах, защищённых авторским правом. Так, весной The New York Times сообщила, что Meta✴ признала наличие такого контента в своих данных для обучения, поскольку его фильтрация практически невозможна. В то время как Meta✴ и другие компании, включая OpenAI и Perplexity, сталкиваются с судебными исками за возможное нарушение авторских прав, ИИ-модель Stable Diffusion остаётся одним из немногих примеров открытого доступа к данным обучения ИИ. Маффулли видит в действиях Meta✴ параллели с позицией Microsoft 1990-х годов, когда та рассматривала открытое ПО как угрозу своему бизнесу. Meta✴, по словам Маффулли, подчёркивает объём своих инвестиций в модель Llama, предполагая, что такие ресурсоёмкие разработки по силам немногим. Использование Meta✴ данных обучения в закрытом формате, по мнению Маффулли, стало своего рода «секретным ингредиентом», который позволяет корпорации удерживать конкурентное преимущество и защищать свою интеллектуальную собственность. YouTube пытается договориться со звукозаписывающими лейблами об ИИ-клонировании голосов артистов
27.06.2024 [18:17],
Сергей Сурабекянц
После дебюта в прошлом году инструментов генеративного ИИ, создающих музыку в стиле множества известных исполнителей, YouTube приняла решение платить Universal Music Group (UMG), Sony Music Entertainment и Warner Records паушальные взносы в обмен на лицензирование их песен для легального обучения своих инструментов ИИ. 
Источник изображения: Pixabay YouTube сообщила, что не планирует расширять возможности инструмента Dream Track, который на этапе тестирования поддерживали всего десять артистов, но подтвердила, что «ведёт переговоры с лейблами о других экспериментах». Платформа стремится лицензировать музыку исполнителей для обучения новых инструментов ИИ, которые YouTube планирует запустить позднее в этом году. Суммы, которые YouTube готова платить за лицензии, не разглашаются, но, скорее всего, это будут разовые (паушальные) платежи, а не соглашения, основанные на роялти. Информация о намерениях YouTube появились всего через несколько дней после того, как Ассоциация звукозаписывающей индустрии Америки (RIAA), представляющая такие звукозаписывающие компании, как Sony, Warner и Universal, подала отдельные иски о нарушении авторских прав против Suno и Udio — двух ведущих компаний в области создания музыки с использованием ИИ. По мнению RIAA, их продукция произведена с использованием «нелицензионного копирования звукозаписей в массовом масштабе». Ассоциация требует возмещения ущерба в размере до $150 000 за каждое нарушение. Недавно Sony Music предостерегла компании, занимающиеся ИИ, от «несанкционированного использования» её контента, а UMG была готова временно заблокировать весь свой музыкальный каталог в TikTok. Более 200 музыкантов в открытом письме призвали технологические компании прекратить использовать ИИ для «ущемления и обесценивания прав занимающихся творчеством людей». Разработана система обучения ИИ на повреждённых данных — это защитит от претензий правообладателей
22.05.2024 [16:52],
Павел Котов
Модели искусственного интеллекта, которые генерируют картинки по текстовому описанию, при обучении на оригинальных изображениях могут их «запоминать», поднимая таким образом вопрос о нарушении авторских прав. Для защиты от претензий со стороны правообладателей была разработана система Ambient Diffusion для обучения моделей ИИ только на повреждённых данных. 
Источник изображения: github.com/giannisdaras Диффузионные модели — передовые алгоритмы машинного обучения, которые генерируют высококачественные объекты, постепенно добавляя шум в набор данных, а затем обращая этот процесс вспять. Как показали исследования, такие модели способны запоминать образцы из обучающего массива. Эта особенность может иметь неприятные последствия в аспектах конфиденциальности, безопасности и авторских прав. К примеру, если ИИ обучается работе с рентгеновскими снимками, он не должен запоминать изображения конкретных пациентов. Чтобы избежать этих проблем, исследователи из Техасского университета в Остине и Калифорнийского университета в Беркли разработали фреймворк Ambient Diffusion для обучения диффузионных моделей ИИ только на изображениях, которые были повреждены до неузнаваемости — так практически обнуляется вероятность, что ИИ «запомнит» и воспроизведёт оригинальную работу. Чтобы подтвердить свою гипотезу, учёные обучили модель ИИ на 3000 изображений знаменитостей из базы CelebA-HQ. При получении запроса эта модель начинала генерировать изображения, почти идентичные оригинальным. После этого исследователи переобучили модель, использовав 3000 изображений с сильными повреждениями — маскировке подверглись до 90 % пикселей. Тогда она начала генерировать реалистичные человеческие лица, которые сильно отличались от оригинальных. Исходные коды проекта его авторы опубликовали на GitHub. Sony пригрозила 700 компаниям судом за несанкционированное использование музыки для обучения ИИ
17.05.2024 [19:54],
Сергей Сурабекянц
Sony Music Group разослала предупреждения более чем 700 технологическим компаниям и службам потоковой передачи музыки о недопустимости использования защищённого авторским правом аудиоконтента для обучения ИИ без явного разрешения. Компания признает «значительный потенциал» ИИ, но «несанкционированное использование контента в обучении, разработке или коммерциализации систем ИИ» лишает её и её артистов контроля и «соответствующей компенсации». 
Источник изображения: Pixabay В части разосланных писем Sony Music прямо утверждает, что имеет «основания полагать», что получатели письма «возможно, уже совершили несанкционированное использование» принадлежащего компании музыкального контента. В портфолио Sony Music — множество известных артистов, среди них Harry Styles, Beyonce, Adele и Celine Dion. Компания стремится защитить свою интеллектуальную собственность, включая аудио- и аудиовизуальные записи, обложки, метаданные и тексты песен. Компания не раскрыла список адресатов, получивших «письма счастья». «Мы поддерживаем артистов и авторов песен, которые берут на себя инициативу по использованию новых технологий в поддержку своего искусства, — говорится в заявлении Sony Music. — Эволюция технологий часто меняла курс творческих индустрий. ИИ, скорее всего, продолжит эту давнюю тенденцию. Однако это нововведение должно гарантировать уважение прав авторов песен и записывающихся исполнителей, включая авторские права». Получателям в указанный в письме срок предлагается подробно описать, какие песни Sony Music использовались для обучения систем ИИ, как был получен доступ к песням, сколько копий было сделано, а также почему копии вообще существовали. Sony Music подчеркнула, что будет обеспечивать соблюдение своих авторских прав «в максимальной степени, разрешённой применимым законодательством во всех юрисдикциях». Нарушение авторских прав становится серьёзной проблемой по мере развития генеративного ИИ, уже сейчас потоковые сервисы, подобные Spotify, наводнены музыкой, созданной искусственным интеллектом. В прошлом месяце в США был опубликован проект закона, который, в случае его принятия, заставит компании раскрывать, какие песни, защищённые авторским правом, они использовали для обучения ИИ. В марте 2024 года Теннесси стал первым штатом США, который принял юридические меры для защиты артистов, после того как губернатор Билл Ли (Bill Lee) подписал «Закон об обеспечении безопасности голоса и изображений» (Ensuring Likeness Voice and Image Security, ELVIS). Языковые модели ИИ сразились друг с другом в импровизированном турнире по Street Fighter III
05.04.2024 [18:24],
Николай Хижняк
На хакатоне Mistral AI, прошедшем в Сан-Франциско на минувшей неделе, разработчики Стэн Жирар (Stan Girard) и Quivr Brain представили тест LLM Colosseum с открытым исходным кодом, основанный на классическом аркадном файтинге Street Fighter III. Тест предназначен для определения самой эффективной языковой модели ИИ в не совсем традиционной, но зрелищной манере. 
Источник изображений: YouTube / Matthew Berman ИИ-энтузиаст Мэтью Берман (Matthew Berman) решил провести с помощь теста LLM Colosseum своеобразный турнир между языковыми моделями, о чём он поделился в своём видео. В нём же Берман показал один из поединков между ИИ. Кроме того, он рассказал, как можно установить этот проект с исходным кодом на домашний ПК или Mac и оценить его самостоятельно. Это не совсем типичный тест LLM. Как правило, маленькие языковые модели имеют преимущество в задержке и скорости, что приводит к победе в большинстве виртуальных боёв. В файтингах очень важна скорость реакции игроков на ответные действия своих оппонентов. То же правило работает и в случае противостояния ИИ против ИИ. 
Источник изображений: OpenGenerativeAI team Языковая модель в реальном времени принимает решение, как ей сражаться. Поскольку LLM представляют собой текстовые модели, их обучили в игре Street Fighter III с помощью текстовых подсказок. ИИ сначала дали проанализировать контекст игры в целом, а затем подсказали, как реагировать на то или иное игровое действие в той или иной ситуации, не забыв про вариативность ходов. ИИ обучили приближаться или отдаляться от противника, а также использовать различные приёмы вроде огненного шара, мегаудара, урагана и мегаогненного шара. 
Источник изображения: OpenGenerativeAI team Продемонстрированный на видео бой между ИИ выглядит динамично. Оппоненты действуют стратегически, блокируют удары противника и используют специальные приёмы. Однако к настоящему моменту проект LLM Colosseum позволяет использовать только одного игрового персонажа, Кена. Согласно тестам Жирара, лучшей языковой моделью в турнире Street Fighter III оказалась GPT 3.5 Turbo от OpenAI. Среди восьми участников она достигла самого высокого рейтинга ELO — 1776. В отдельной серии тестов, организованных Банджо Обайоми (Banjo Obayomi), специалистом по продвижению продуктов AWS компании Amazon, спарринги проводились между четырнадцатью языковыми моделями в рамках 314 индивидуальных матчей. Здесь в конечном итоге победила языковая модель claude_3_haiku от Anthropic с рейтингом ELO 1613. Все ведущие большие языковые модели ИИ нарушают авторские права, а GPT-4 — больше всех
06.03.2024 [18:36],
Сергей Сурабекянц
Компания по изучению ИИ Patronus AI, основанная бывшими сотрудниками Meta✴, исследовала, как часто ведущие большие языковые модели (LLM) создают контент, нарушающий авторские права. Компания протестировала GPT-4 от OpenAI, Claude 2 от Anthropic, Llama 2 от Meta✴ и Mixtral от Mistral AI, сравнивая ответы моделей с текстами из популярных книг. «Лидером» стала модель GPT-4, которая в среднем на 44 % запросов выдавала текст, защищённый авторским правом. 
Источник изображений: Pixabay Одновременно с выпуском своего нового инструмента CopyrightCatcher компания Patronus AI опубликовала результаты теста, призванного продемонстрировать, как часто четыре ведущие модели ИИ отвечают на запросы пользователей, используя текст, защищённый авторским правом. Согласно исследованию, опубликованному Patronus AI, ни одна из популярных книг не застрахована от нарушения авторских прав со стороны ведущих моделей ИИ. «Мы обнаружили контент, защищённый авторским правом, во всех моделях, которые оценивали, как с открытым, так и закрытым исходным кодом», — сообщила Ребекка Цянь (Rebecca Qian), соучредитель и технический директор Patronus AI. Она отметила, что GPT-4 от OpenAI, возможно самая мощная и популярная модель, создаёт контент, защищённый авторским правом, в ответ на 44 % запросов. Patronus тестировала модели ИИ с использованием книг, защищённых авторскими правами в США, выбирая популярные названия из каталога Goodreads. Исследователи разработали 100 различных подсказок, которые можно счесть провокационными. В частности, они спрашивали модели о содержании первого абзаца книги и просили продолжить текст после цитаты из романа. Также модели должны были дополнять текст книг по их названию. Модель GPT-4 показала худшие результаты с точки зрения воспроизведения контента, защищённого авторским правом, и оказалась «менее осторожной», чем другие. На просьбу продолжить текст она в 60 % случаев выдавала целиком отрывки из книги, а первый абзац книги выводила в ответ на каждый четвёртый запрос. Claude 2 от Anthropic оказалось труднее обмануть — когда её просили продолжить текст, она выдавала контент, защищённый авторским правом, лишь в 16 % случаев, и ни разу не вернула в качестве ответа отрывок из начала книги. При этом Claude 2 сообщала исследователям, что является ИИ-помощником, не имеющим доступа к книгам, защищённым авторским правом, но в некоторых случаях всё же предоставила начальные строки романа или краткое изложение начала книги. Модель Mixtral от Mistral продолжала первый абзац книги в 38 % случаев, но только в 6 % случаев она продолжила фразу запроса отрывком из книги. Llama 2 от Meta✴ ответила контентом, защищённым авторским правом, на 10 % запросов первого абзаца и на 10 % запросов на завершение фразы. 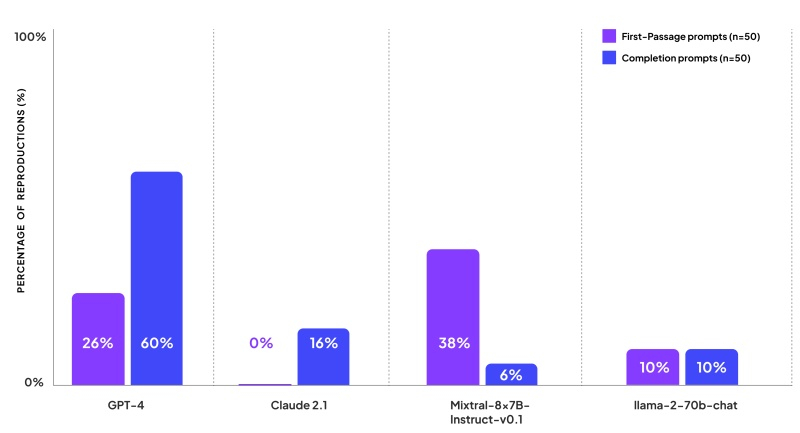
Источник изображения: Patronus AI «В целом, тот факт, что все языковые модели дословно создают контент, защищённый авторским правом, был действительно удивительным, — заявил Ананд Каннаппан (Anand Kannappan), соучредитель и генеральный директор Patronus AI, раньше работавший в Meta✴ Reality Labs. — Я думаю, когда мы впервые начали собирать это вместе, мы не осознавали, что будет относительно просто создать такой дословный контент». Результаты исследования наиболее актуальны на фоне обострения отношений между создателями моделей ИИ и издателями, авторами и художниками из-за использования материалов, защищённых авторским правом, для обучения LLM. Достаточно вспомнить громкий судебный процесс между The New York Times и OpenAI, который некоторые аналитики считают переломным моментом для отрасли. Многомиллиардный иск новостного агентства, поданный в декабре, требует привлечь Microsoft и OpenAI к ответственности за систематическое нарушение авторских прав издания при обучении моделей ИИ.  Позиция OpenAI заключается в том, что «поскольку авторское право сегодня распространяется практически на все виды человеческого выражения, включая сообщения в блогах, фотографии, сообщения на форумах, фрагменты программного кода и правительственные документы, было бы невозможно обучать сегодняшние ведущие модели ИИ без использования материалов, защищённых авторским правом». По мнению OpenAI, ограничение обучающих данных созданными более века назад книгами и рисунками, являющимися общественным достоянием, может стать интересным экспериментом, но не обеспечит системы ИИ, отвечающие потребностям настоящего и будущего. Intel наняла выходца из HPE, чтобы он помог ей конкурировать с NVIDIA в сфере ИИ-ускорителей
04.01.2024 [22:58],
Николай Хижняк
Компания Intel назначила исполнительного директора Hewlett Packard Enterprise Джастина Хотарда (Justin Hotard) главой своей группы, занимающейся разработкой технологий для центров обработки данных и искусственного интеллекта. Тем самым она привлекла для управления одним из своих ключевых подразделений стороннего специалиста. 
Джастин Хотард. Источник изображения: Intel В Hewlett Packard Enterprise Хотард отвечал за высокопроизводительные вычисления, искусственный интеллект и управление лабораториями HPE. В Intel он будет курировать разработку и поддержку некоторых наиболее важных продуктов компании, включая серверные процессоры Xeon, которые ранее доминировали в сегменте ЦОД, но уступили значительную долю рынка конкурирующим предложениям. До HPE Хотард также возглавлял компании NCR и Motorola Inc. В Intel он возглавит направление ИИ, специализированных графических процессоров и ускорителей и постарается вывести компанию на достойный уровень конкуренции с NVIDIA, которая в настоящий момент безоговорочно доминирует в этом направлении. Восстановление своего лидирующего положения на рынке продуктов для центров обработки данных имеет решающее значение для планов генерального директора Пэта Гелсингера (Pat Gelsinger) по восстановлению превосходства Intel в индустрии производства микросхем. Хотя чипы для ЦОД составляют относительно небольшую часть отрасли, сами по себе специализированные процессоры и ускорители на их основе могут продаваться за десятки тысяч долларов каждый, что делает их чрезвычайно прибыльными. Хотард, который приступит к своей работе в Intel с 1 февраля, сменит ветерана компании Сандру Риверу (Sandra Rivera). Ривера с понедельника перешла на должность главы подразделения программируемых решений Intel (Programmable Solutions Group, PSG), которое компания выделила в отдельный бизнес и планирует вывести на биржу в течение двух-трёх лет. Intel отдельно объявила, что ещё один топ-менеджер её подразделения ЦОД и ИИ Арун Субраманьян (Arun Subramaniyan) возглавил новую софтверную компанию Articul8, специализирующуюся на внедрении машинного обучения и больших языковых моделей (LLM). Она была создана Intel совместно с инвестиционными компаниями DigitalBridge Group и Mindset Ventures. LG представила домашнего двуногого ИИ-робота на колёсиках — он поддержит диалог, будет охранять дом и не только
27.12.2023 [16:19],
Николай Хижняк
Компания LG представила компактного робота-помощника для дома Smart Home AI Agent. Новинка полагается на технологии искусственного интеллекта и машинного обучения для передвижения, управления предметами «умного дома», а также изучения дома и общения с хозяевами и другими людьми. 
Источник изображений: LG В основе робота LG Smart Home AI Agent используется платформа Qualcomm Robotics RB5. Компактный двухколёсный робот-помощник оснащён камерой, динамиком, а также набором различных сенсоров, позволяющих ему следить за обстановкой в доме и собирать информацию об окружающем пространстве, включая температуру, влажность и качество воздуха.  Машина работает в автономном режиме. Он может общаться с домочадцами и их гостями, и через различные движения демонстрировать различные эмоции. Для этого он оснащён мультимодальной технологией искусственного интеллекта, объединяющей функции распознавания голоса и изображений, а также возможность обработки естественного языка. Всё это позволяет роботу LG Smart Home AI Agent улавливать контекст разговора, а также намерения владельца, и активно участвовать в общении с пользователями. Возможности и особенности робота LG Smart Home AI Agent:
О стоимости домашнего робота-помощника Smart Home AI Agent компания LG пока ничего не сообщила. Производитель собирается продемонстрировать новинку на международной выставке электроники CES 2024 с 9 по 12 января. Amazon представила свой ИИ-генератор изображений Titan Image Generator
30.11.2023 [06:10],
Николай Хижняк
На конференции AWS re:Invent компания Amazon представила собственный ИИ-генератор изображений Titan Image Generator на платформе Bedrock. Он предназначен для создания изображений на основе текстовых запросов, а также предлагает поддержку различных дополнительных функций редактирования уже готовых изображений. 
Источник изображения: Amazon По словам Amazon, инструмент способен генерировать «огромные объёмы реалистичных изображения студийного качества при низкой цене». Компания заявляет, что Titan Image Generator способен создавать изображения на основе сложных текстовых подсказок, одновременно обеспечивая при этом точность композиции генерируемых объектов на изображении с минимальными искажениями. По мнению разработчиков Amazon, это поможет «сократить объёмы создания вредного контента и смягчить распространение дезинформации». Функции Titan Image Generator также позволяют редактировать отдельные элементы на изображении, удаляя или добавляя дополнительные детали. Например, инструмент позволяет заменить задний фон на изображении, а также заменить или удалить предмет, который может находиться в руках человека, изображенного в кадре. Использующиеся в составе Titan Image Generator ИИ-алгоритмы также могут расширять композицию изображения, добавляя дополнительные искусственные детали, аналогично функции Generative Expand в Photoshop. В компании отмечают, что их ИИ-генератор изображений Titan накладывает на каждое созданное им изображение невидимый невооружённому глазу специальный водяной знак. По мнению компании, эта функция поможет «уменьшить распространение дезинформации, предоставив незаметный механизм для идентификации изображений, созданных ИИ, а также будет способствовать безопасному, надежному и прозрачному развитию технологий искусственного интеллекта». Amazon заявляет, что эти водяные знаки невозможно удалить или изменить. Согласно опубликованному видео с демонстрацией работы Titan Image Generator, инструмент также может создавать описания изображений или релевантный текст для последующего использования в публикации в социальных сетях. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться