







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Нейроморфные вычислители: как придумать колесо?
В прошлых наших материалах об аппаратных нейроморфных вычислителях мы вкратце останавливались на общих принципах их работы и на одних из наиболее удачных полупроводниковых реализаций такого рода систем — чипах Intel Loihi и Loihi 2. При этом неоднократно подчёркивали, что, хотя аппаратная нейроморфика теоретически представляется невероятно перспективным направлением развития ИИ, особенно с точки зрения энергоэффективности производимых вычислений, на практике её сдерживает целый ряд серьёзных препятствий — преодоление которых потребует от разработчиков, похоже, больше усилий и времени, чем виделось энтузиастам этого направления изначально. При этом привычные на сегодня нейросети, целиком и полностью реализуемые программно — в оперативной памяти классических фон-неймановских компьютеров, — тоже не стоят на месте. И, хотя обходятся в обучении и эксплуатации очень дорого (если учесть астрономические величины энергопотребления ИИ-серверов с графическими адаптерами Nvidia прежде всего), результаты демонстрируют вполне ощутимые и привлекательные. Нейроморфные же вычислители продолжают во многом оставаться экспериментальными прототипами, а не рабочими лошадками для нуждающихся в решении ИИ-задач заказчиков из самых разных сфер экономики, — и с этим их разработчикам явно нужно что-то делать. ⇡#На (долгую? добрую?) память«Обычные» нейросети, называемые в англоязычной практике просто искусственными — atrtificial neural network (ANN), — более строго могут быть классифицированы как «сети с прямым распространением данных», feed-forward neural network (FFNN). Информационный сигнал в них движется лишь в одном направлении, от входного слоя перцептронов через скрытые к выходному, не формируя петель и/или возвратных потоков, — и этого, как показывает практика, оказывается вполне достаточно для решения огромного класса дискриминативных задач, таких как различение изображений кошечек и собачек, или рукописных букв и цифр, или же распознавание лиц — и т. п. Проходящий по нейронным слоям сигнал не оставляет за собой информационного следа; чтобы корректировать веса на входах перцептронов (что необходимо в процессе тренировки, когда выданный FFNN результат не соответствует заданному эталону в ходе обучения с учителем, например), следует предусматривать особые механизмы. Для эмулируемых полностью в компьютерной памяти нейросетей с этим нет никаких проблем: каждый вес представляет собой число, и поменять значение нужной переменной в таблице тривиально. Зато с точки зрения аппаратной нейроморфики организация надёжного быстрого доступа к сотням и тысячам (а лучше — миллионам и миллиардам) условных реостатов, что задавали бы веса на входах связанных с ними физических перцептронов, — задача глубоко нерядовая, и как раз трудность её реализации — один из сильнейших факторов, что сдерживают развитие по-настоящему крупных аппаратных нейросетевых вычислителей. 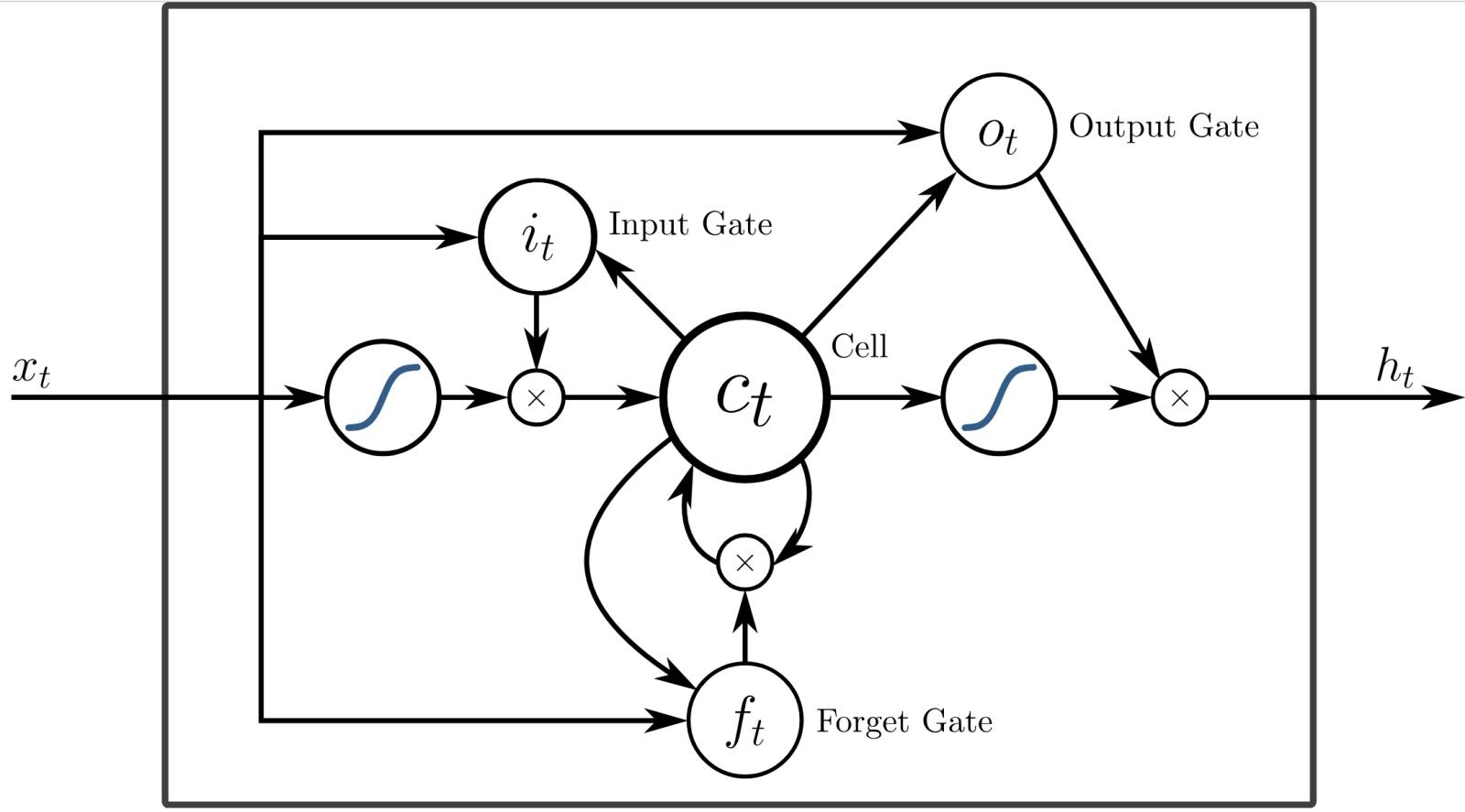
Одна из возможных реализаций RNN-ячейки с особым вентилем, активирующим «забывание» (стирание) ранее сохранённой в локальной памяти информации (источник: Wikimedia Commons) С рекуррентными нейросетями (recurrent neural network, RNN), подтипом которых являются рассмотренные нами ранее импульсные — они же спайковые — нейросети (spike neural network, SNN), всё ещё интереснее. В RNN нейроны обмениваются информацией между собой, а не просто передают её строго вперёд, от слоя к слою, — в частности, имеют возможность сверяться с данными о предыдущих своих состояниях в процессе изменения текущего под воздействием очередной порции поступившей на них информации. По сути, RNN — это нейросети с внутренней памятью (пример чему как раз и являет устройство чипов Loihi с ячейками SDRAM, привязанными к отдельным искусственным нейронам), и потому они наилучшим образом походят для обработки последовательностей данных. Не статичной картинки, изображение на которой нужно классифицировать (кошечка/собачка), а растянутой во времени цепочки событий; скажем, череды нот в генерируемой музыкальной композиции, когда на основе «выученных» нейросетью представлений о гармонии и заданных оператором жанровых рамок уже подобранная на прежних этапах последовательность звуков дополняется новым, заведомо не диссонирующим с предыдущими. Эксперты сравнивают FFNN с простыми математическими функциями: вот некая строго заданная (в данном случае весами на входах перцептронов) последовательность операций, вот входные данные — и в итоге за один проход получается, как по формуле, некий вполне определённый ответ. RNN, напротив, скорее напоминают программируемые вычислительные машины: формула получения ответа сама задаётся поступающей информацией. Строго говоря, наличие внутренней памяти делает рекуррентные нейросети полными по Тьюрингу, т. е. способными при наличии достаточного запаса времени решить по сути любую вычислительную задачу. Это, кстати, вовсе не комплимент: раз любую, то, в частности, и заведомо вредоносную тоже, что разом открывает широчайший простор для потенциального хакинга нейроморфных RNN-вычислителей. Который невозможно предотвратить, что называется, by design — поскольку сама потенциальная возможность взлома оказывается обусловлена имманентными свойствами внутренней структуры таких систем. Собственно, и с наиболее совершенной из известных нам природных нейросетевых структур, человеческим мозгом, та же история: каких только способов взламывать эту Тьюринг-полную машину не изобретено — от пропаганды и мошеннических уловок до индуцированной извне организма химической активации определённых нейронных связей. Так что, если в обозримой перспективе изощрённые нейроморфные вычислители всё же займут место нынешних эмулируемых в памяти x86-серверов «умных» чат-ботов, морочить им головы — или как там будут называться вместилища аппаратных RNN — будет удаваться с куда большей эффективностью, чем сегодня реализовывать джейлбрейкинг больших языковых моделей. 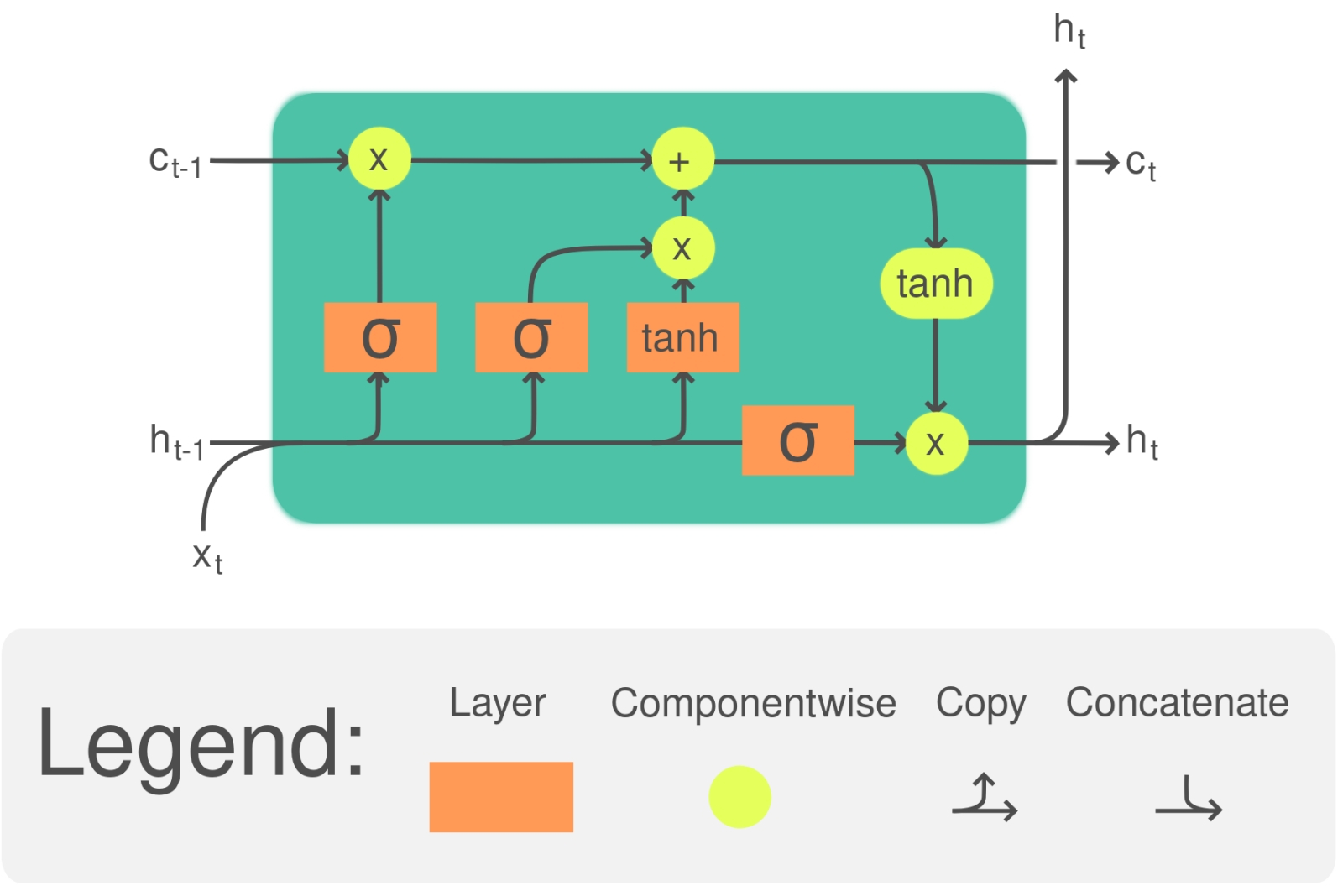
Ячейка LSTM способствует последовательной обработке поступающих на искусственный нейрон спайковой сети данных, но при этом сохраняет информацию о своих прежних значениях, пока не поступит явного предписания её «забыть» (источник: Wikimedia Commons) Память в составе RNN может быть организована достаточно сложным образом — стоит упомянуть в этой связи «протяжённую краткосрочную память» LSTM, long short-term memory, способную сохранять информацию не только о предыдущем состоянии ячейки, но и о (нескольких в общем случае) более ранних. Управляя особыми вентилями забывания (forget gate), система получает таким образом возможность работать с весьма протяжёнными рядами входных данных — ипмульсов-спайков в случае SNN. Как раз нейронные сети с LSTM-ячейками (реализованные, разумеется, исключительно на программном уровне) вплоть до бума генеративного ИИ применялись в основном в системах машинного перевода, поскольку неплохо обеспечивают сохранность не только контекста переводимой в данный момент фразы, но и синтаксических и даже стилистических особенностей всего текста в целом (точнее, корпуса текстов, на которых проводится обучение). Да и сегодня, с учетом склонности генеративных моделей к галлюцинациям, RNN с LSTM не собираются сходить со сцены. На них во многом полагаются средства автоматизированной генерации программного кода, разделения текста на значимые слова, автозаполнения различных форм и многие иные «умные» инструменты, для которых мощь универсальных FFNN оказывается чрезмерной. Тем более, что мощь эта, как упоминалось уже не раз, достаётся вовсе не бесплатно (и прежде всего в энергетическом смысле), а RNN даже в виде компьютерной эмуляции в памяти x86-машин всё-таки более экономичны. ⇡#Потянуть за языкЕсли у RNN так здорово выходит анализировать структуру последовательностей едва ли не произвольных данных — биржевых котировок, литературного/технического текста, музыкальных композиций, графика сезонных изменений температуры и влажности в данной географической точке и т. п., — почему же сегодня так оглушительно популярны именно генеративные модели на базе FFNN, а не основанные на рекуррентных нейросетях? Во многом — потому, что RNN в исходном своём виде не ориентированы на выдачу содержательной информации: они блестяще справляются с выявлением закономерностей, но не с дистилляцией смыслов. FFNN же (особенно наиболее актуальные, с активным применением свёрток и трансформеров), хотя время от времени и галлюцинируют, выхватывают благодаря своей многослойной конструкции определённые смыслы из массива обучающих данных и как раз потому кошечку от собачки на картинке отличают довольно уверенно. Да, система машинного обучения сама не осознаёт этих смыслов, — контуры рефлексии и интроспекции в многослойной нейросети отсутствуют. Но абстрактные идеи неких «кошкости» и «собачести» как объективно постижимых признаков генеративная модель бесспорно фиксирует в результате анализа десятков тысяч изображений — на уровне связанных с соответствующими токенами векторов в существенно многомерном пространстве, определяемых, в свою очередь, весами на входах её многочисленных перцептронов. 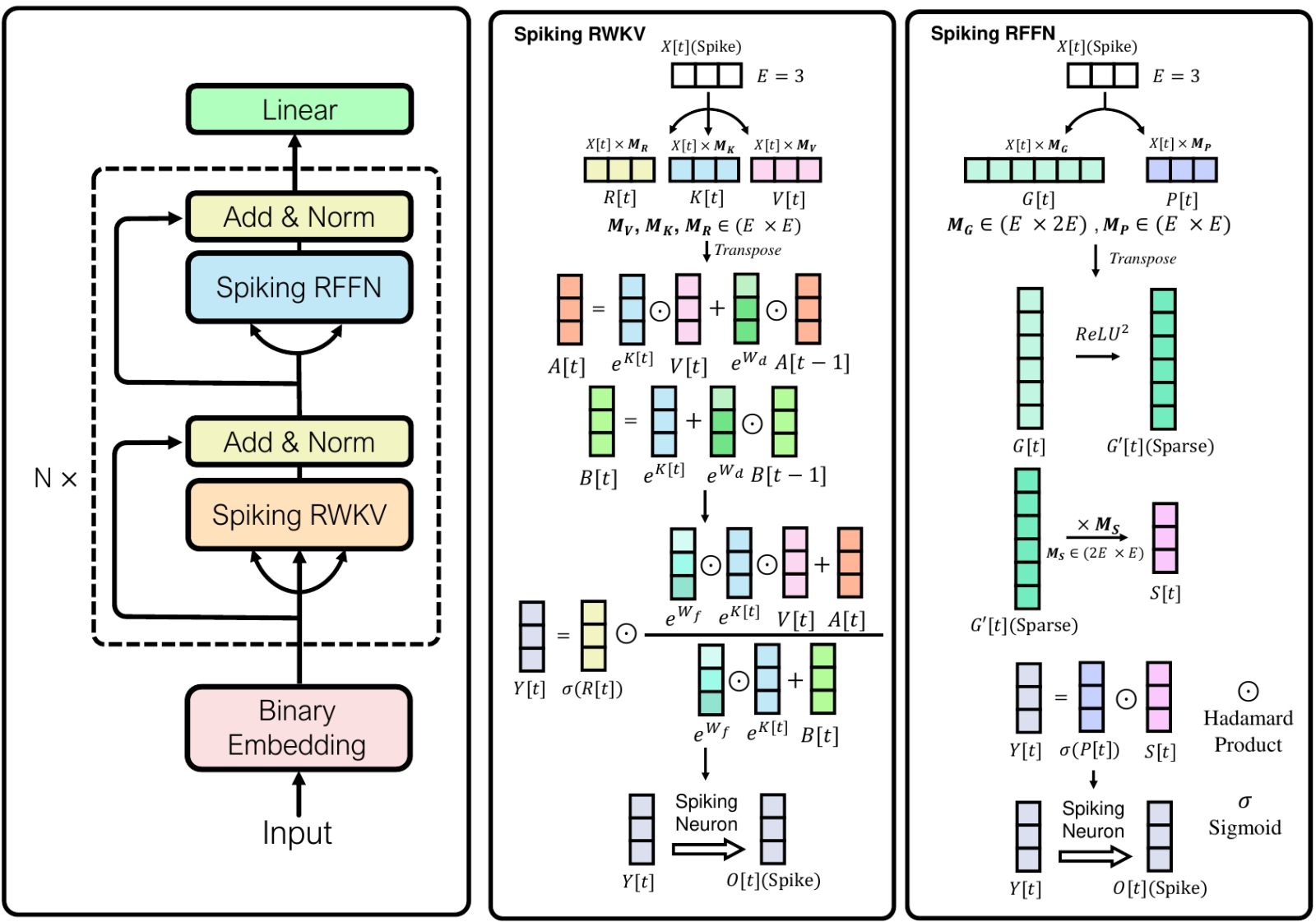
Принципиальная схема действия SpikeGPT на основе языковой модели, которая построена на принципах ключевого значения, взвешенного по восприимчивости, — Receptance Weighted Key Value, RWKV (источник: University of California, Santa Cruz) RNN же сконцентрирована, скорее, на вычленении протяжённой во времени структуры в последовательности предложенных ей данных, будь то такты музыкальной композиции, слова в предложении или операторы во фрагменте программного кода, — именно структуры, не содержания. Как раз поэтому рекуррентным нейросетям так хорошо удаётся «бредогенерация» (nonsense generation) — когда на основе скормленного модели массива исходных данных (пьес Шекспира, статей из онлайн-энциклопедии прямо с XML-разметкой, эссе по алгебраической геометрии в формате LaTeX, т. е. прямо с математически корректными формулами и диаграммами, и проч.) RNN порождает выдачу, на первый беглый взгляд неотличимую от оригинала — в плане грамматики, синтаксиса, даже стилистики, — но чаще всего не содержащую решительно никакого смысла. Такие фразы, составленные из словарных слов по всем правилам грамматики, но лишённые какого-либо предметного содержания — их представляет известный всем, кто изучал философию науки, пример «луна умножает четырёхугольно», — Бертран Рассел (Bertrand Russell) относил к «бессмыслице второго типа». Внешне они мало чем отличаются от галлюцинаций генеративных моделей, но на глубинном уровне разница значимая. Одно дело — сбой вектора, который должен был указывать на некую вполне определённую (благодаря предварительной тренировки модели) область в латентном пространстве, но по той или иной причине промахнулся; другое — заведомо и не предполагавшее никакого «извлечения смыслов» на более раннем этапе комбинирование никак не связанных между собой (для данной нейросети) элементов по хорошо затверженным (той же самой нейросетью) формальным правилам. Впрочем, на нынешнем этапе развития RNN приближаются по части «извлечения смыслов» к основанным на архитектуре трансформеров FFNN, вплоть до появления (пока в виде экспериментального, недоступного широкой публике, но вполне функционирующего прототипа) генеративной модели SpikeGPT, что оперирует ключевыми величинами, взвешенными по восприимчивости, — receptance weighted key value (RWKV). RWKV-блоки открывают для импульсной нейросети возможность ускоренного (за счёт распараллеливания потоков) обучения, а ведь как раз существенно более долгая тренировка снижает практическую ценность даже чисто виртуальной реализации современных RNN в сравнении с FFNN. Тем не менее одно из главных преимуществ рекуррентной нейросети — линейная зависимость вычислительной сложности от масштаба (а не квадратичная, как у трансформеров), так что RNN-модели с сопоставимым числом параметров будут заведомо энергоэффективнее привычных сегодня генеративных систем, построенных на архитектуре трансформеров. Так, упомянутая SpikeGPT в вариантах с 45 млн и 216 млн параметров производила, по утверждению её создателей, в двадцать раз меньше вычислительных операций, чем основанные на трансформерах её соперницы сопоставимой сложности, — демонстрируя притом сопоставимые результаты в целом ряде тестов, знаковых для оценки возможностей систем машинного обучения. 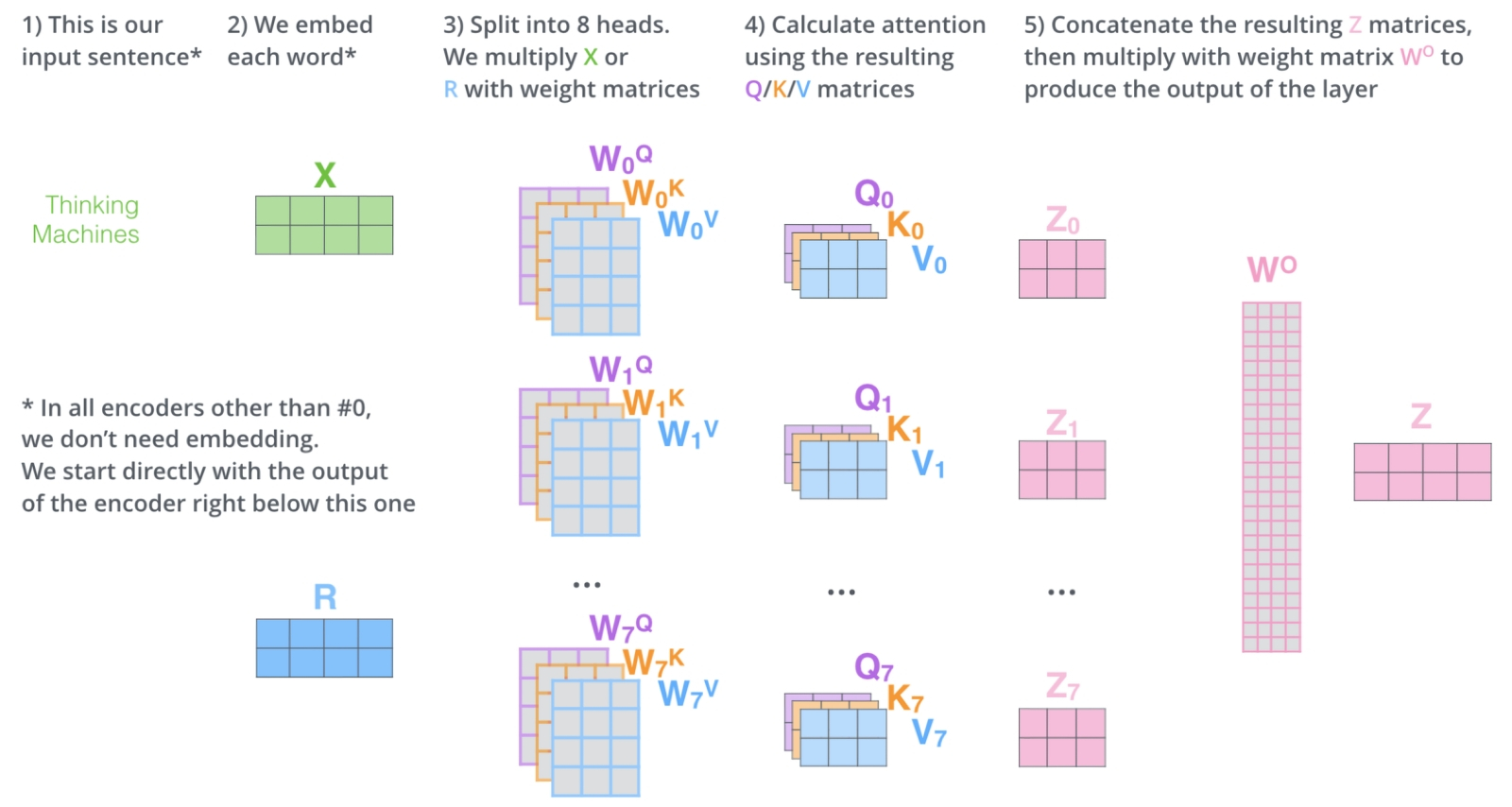
Общий принцип работы слоя самовнимания (self-attention layer) в архитектуре трансформера (источник: The Illustrated Transformer) По словам Майка Дэвиса (Mike Davies), директора лаборатории нейроморфных вычислений Intel, масштабирование импульсных нейросетей до уровня доминирующих сегодня в мире больших языковых моделей на базе FFNN с трансформерами продолжит оставаться серьёзным вызовом до тех пор, пока для RNN не будет предложена эффективная аппаратная основа (он говорил даже более определённо — о полупроводниковых нейроморфных вычислителях: «This is going to be a really exciting path forward in this domain, and while we’re not there yet—we will need a silicon iteration to support it»). И понятно почему: эмуляция сложных нейросетей в памяти фон-неймановских компьютеров обходится чрезмерно дорого как раз вследствие важнейшей архитектурной особенности этих вычислительных систем. А именно — физического отделения хранилища данных (памяти; в частности, высокоскоростной оперативной) от собственно производящего вычисления узла (процессора). Чем сложнее нейросеть, тем интенсивнее требуется перемещать данные между ОЗУ и ЦП для обеспечения её работы, — и ограниченная ширина полосы пропускания становится одним из ключевых препятствий для масштабирования такой системы. Рассмотренные уже нами чипы Loihi и целый ряд схожих с ними полупроводниковых реализаций нейроморфных вычислителей как раз и призваны, размещая ячейки памяти поближе к примитивным, но высокоскоростным процессорным узлам, реализовывать преимущества RNN с использованием уже прекрасно отлаженных полупроводниковых производственных технологий. ⇡#Проблемы и решенияНемаловажная причина в числе прочих, из-за которых те же самые чипы Loihi 2 не вытеснили пока пожирающие ватты многими сотнями за раз серверные адаптеры Nvidia из дата-центров по всему миру, — это трудности с обучением рекуррентных нейросетей. Мало создать аппаратную основу для их энергоэффективного функционирования: если полученная таким образом умная машина станет генерировать ответы со значительно бóльшим, чем у той же GPT-4o или её аналогов, процентом некорректных ответов, сам факт существенного снижения энергоёмкости такого устройства вряд ли утешит его пользователей. Проблема заключается в том, что самый распространённый способ обучения FFNN (отлично подходящий в том числе и усиленным трансформерами моделям), обратное распространение ошибки (back propagation), в случае RNN напрямую применяться не может. Поскольку ячейки рекуррентной нейросети так или иначе хранят информацию о прежних состояниях, просто изменять веса на входах недостаточно — нужно ещё и воздействовать на «память» о прошлых их значениях, т. е. применять обратное распространение во времени — back propagation through time, BPTT. 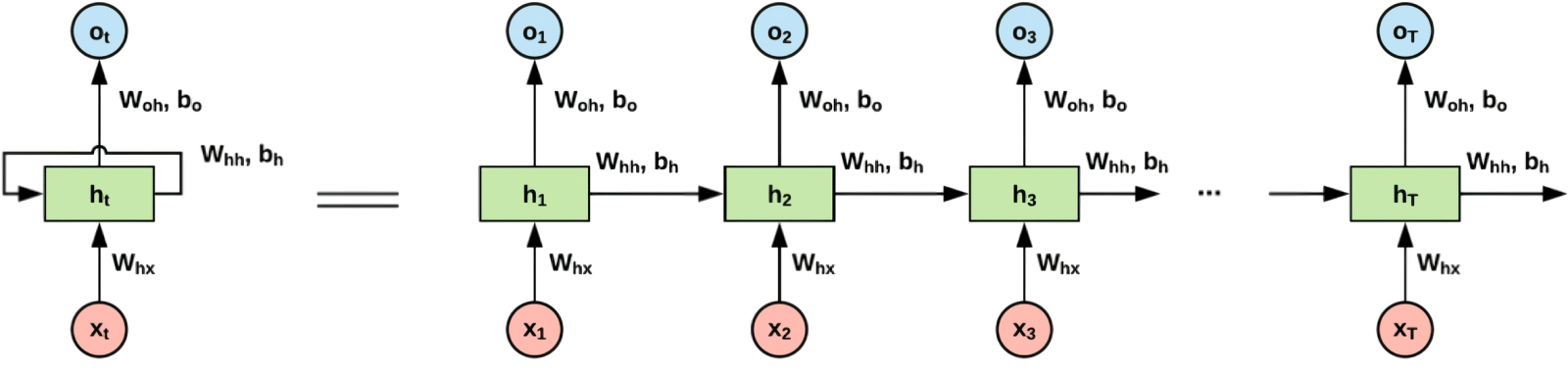
Каждый блок RNN, меняя своё состояние под воздействием очередного импульса, сохраняет память о прошлом, — и при тренировке с обратным распространением ошибки это приходится учитывать (источник: Stanford.edu) Но с этим тоже не всё просто, причём на принципиальном, математическом уровне. Главный рабочий инструмент настройки нейросетей — градиент — представляет собой вектор частных производных функции потерь по всем корректируемым весам: именно такой вектор указывает направление наибольшего роста функции потерь на всей совокупности весов разом. Частные же производные отражают — в том числе нередко крайне сильные — перепады между значениями отдельных весов: это характерно, кстати, не только для RNN, но и для многослойных FFNN. В результате сплошь и рядом возникают неприятные ситуации, когда градиент взрывается (exploding gradient) или, наоборот, исчезает (vanishing gradient), т. е. его величина либо переполняет тип данных, в котором она хранится, либо уменьшается до пренебрежимо малой величины — и в этом случае далее ошибка, как нетрудно понять, уже не распространяется, т. е. обучение фактически останавливается. Борются с этим в случае SNN, в частности, организацией тренировки через временно-зависимую пластичность импульсов (spike timing dependent plasticity, STDP), характерную, кстати, и для биологических нейросетей, но для реализации STDP, в отличие от BPTT, требуются куда более изощрённые алгоритмы, разработка которых сама по себе сродни искусству и во многом опирается на особенности аппаратной реализации той или иной нейроморфной системы. Речь уже начинает заходить о метаобучении (meta-learning) — т. е. о натаскивании рекуррентных нейронных сетей не на решение какой-то конкретной задачи, а в целом на то, каким образом им самим научаться такие задачи решать. Перечень вызовов, встающих перед разработчиками нейроморфных систем, поистине огромен — и это мы, заметьте, ещё даже не приступали к рассмотрению возможных вариантов аппаратной их реализации, помимо разве что полупроводниковой, на приведённом в предыдущей статье этой серии примере Loihi. Достаточно указать лишь на некоторые наиболее значимые:

Сборка из 16 полупроводниковых нейроморфных чипов, созданных в рамках программы DARPA SyNAPSE (Systems of Neuromorphic Adaptive Plastic Scalable Electronics): 28-нм техпроцесс, 1 млн искусственных нейронов и 256 млн синапсов в каждой микросхеме (источник: Wikimedia Commons) Тем не менее исследователи не отступают: слишком уж велики потенциальные выгоды от внедрения нейроморфных систем в регулярный обиход, пусть даже применяться они будут для ограниченного круга задач и не вытеснят полностью построенные на трансформерах FFNN-нейросети. Упомянутый ранее Майк Дэвис в интервью изданию EE Times привёл такой пример: по метрике энергозадержки (energy delay; совместный учёт затраченной на выполнение определённой задачи энергии и латентности при исполнении этой задачи на вычислительном контуре) аппаратные нейроморфные системы способны обеспечить превосходство над генеративными нейросетями, исполняемыми в памяти фон-неймановских машин, на три десятичных порядка величины. В числе задач, которые по плечу почти исключительно нейроморфным вычислителям — и, в ещё более отдалённой перспективе, квантовым (просто потому, что обычное «железо» слишком для их решения неэффективно), — квадратичная оптимизация без ограничений (quadratic unconstrained binary optimization, QUBO) с широчайшей областью применимости, а также предиктивный контроль робототехники в реальном времени. Пожалуй, действительно умных роботов, адекватно действующих в переменчивом окружении реального мира, нам в отсутствие поставленных на поток нейроморфных вычислителей и вправду не видать. А вот какой именно может оказаться материальная основа для их нейроморфных «мозгов», мы разберём в следующем материале серии, — вариантов уже сегодня предлагается изрядно. ⇡#Материалы по теме
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
|
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()




 Подписаться
Подписаться