







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexВ конце сентября в сердце калифорнийской Кремниевой Долины - городе Сан Хосе, состоялась очередная ежегодная технологическая конференция компании NVIDIA - GTC 2010 (GPU Technology Conference).

Ядерные физики; биофизики; астрофизики; астрономы; микробиологи; специалисты по гидродинамике, молекулярной динамике и искусственному интеллекту; создатели звуковых, световых и 3D-эффектов для Голливуда; лингвисты; программисты баз данных; практикующие врачи и врачи-исследователи; руководители и научные сотрудники технологических фирм; финансисты; разработчики 3D-игр, встраиваемых систем, систем отображения информации – трудно себе представить ещё одну причину кроме GPU вычислений, ради которой представители этих и многих других профессий собрались бы в одном месте.
Сразу же хотелось бы подчеркнуть сугубо практический, прикладной, не развлекательный характер этого мероприятия: как и в прошлом году, конференция собрала в своих стенах тысячи исследователей, разработчиков, учёных и технологов, для которых было проведено более 240 технических сессий. Ещё до начала конференции, в так называемый «нулевой день», был прочитан ряд лекций по темам CUDA C, DirectCompute, Stereoscopic 3D, OpenCL, OpenGL, Ray Tracing и ряду других. В дни проведения конференции состоялись десятки сессий по высокопроизводительным вычислениям (HPC) с применением GPU на базе масштабируемых приложений, были озвучены доклады и технические сессии в области десятков направлений современной науки и промышленности. Наконец, в каждый из трёх дней конференции мы имели возможность присутствовать на ключевых докладах – так называемых «кейнотах», где представители NVIDIA вместе с приглашёнными специалистами из различных областей науки и промышленности рассказывали нам о нынешних достижениях и идеях на будущее.
В рамках GTC 2010, также по традиции, проводилась выставка, на которой десятки компаний демонстрировали свои аппаратные, программные и комплексные системы с применением графических решений NVIDIA.
Нам, журналистам, кроме возможности освещения этого мероприятия, выпала уникальная возможность принять участие в ряде технических сессий и докладов. А поскольку каждый из нас непременно является увлечённым идеями в одной или нескольких областях, после кейнотов мы растворялись среди других участников на различных сессиях по интересам: кто-то шёл слушать о новых техниках программирования под DirectX 11, кто-то вникал в архитектурные нововведения CUDA, и так далее. Мной, например, не был пропущен ни один доклад, имевший отношение к съёмке и обработке трехмерных фото и видеоматериалов.
Для лучшего понимания сути и значения такого мероприятия как NVIDIA GTC, самое время сделать лирическое отступление. У многих из нас решения NVIDIA по привычке ассоциируются исключительно с графическими решениями Tegra и GeForce для бытовых систем и графикой Quadro для профессиональных рабочих станций. Совсем недавно так все и было. Однако зародившаяся несколько лет назад идея использования графических решений в качестве аппаратной базы для производительных параллельных вычислений буквально на глазах воплотилась в мощное явление современности, востребованное наукой, промышленностью, медициной, армией, индустрией развлечений, центрами обработки данных и т.д.
Выяснилось, что разработанная в NVIDIA технология параллельных вычислений на базе архитектуры CUDA способна значительным образом ускорять решение многих прикладных и теоретических задач, а в некоторых случаях, где требуется проведение расчётов в реальном времени, стала просто незаменимой. После выхода первых графических чипов GeForce 8 с архитектурой CUDA, появилась возможность создания вычислительных систем Tesla, масштабируемых до серверных и кластерных уровней организации.
Резкий, взрывообразный рост популярности технологии произошёл не в последнюю очередь благодаря её широкой доступности: покупая обычную современную графическую карту GeForce, вы, по сути, автоматически становитесь обладателем средней мощности суперкомпьютера для параллельных вычислений. Всё, что требуется для начала разработки собственных приложений под этот домашний суперкомпьютер – это скачать бесплатный SDK с сайта NVIDIA.
Тем временем, рост популярности архитектуры CUDA не остался незамеченным производителями прикладного, развлекательного и научного ПО. И действительно, раз уж в системе имеется готовое «железо», способное на порядки быстрее решать задачи после их распараллеливания, грех не воспользоваться такими возможностями. Так на рынке один за другим начали появляться релизы популярных программ Adobe, Corel, Roxio и других компаний, «заточенные» под возможности CUDA. Счёт подобным предложениям с поддержкой CUDA давно пошёл на сотни.
Надеюсь, после этого небольшого отступления нашим читателям не придётся объяснять, почему в рамках GTC разговоры о чипах NVIDIA и игрушках занимают далеко не центральное место. Впрочем, с этого места – обо всём по порядку.
Ключевым событием GTC 2010 стал кейнот первого дня, по традиции проводящийся Дженсеном Хуаном (Jen-Hsun Huang), соучредителем, президентом и CEO NVIDIA, с привлечением множества знаковых спикеров индустрии. Ключевые моменты этого важнейшего события конференции мне удалось записать на видео, так что далее по тексту вам будут встречаться ролики, наглядно иллюстрирующие доклад. Также отмечу, что в этом году, впрочем, как и в дни GTC 2009, и на NVISION 08, многие материалы – и не только на докладах, но и на лекциях, иллюстрировались в 3D-формате. Что, конечно, несколько затрудняет пересказ событий в репортаже, но значительным образом облегчает восприятие доклада при очном присутствии.
Основной тезис в начале доклада Дженсена: цели, поставленные перед архитектурой CUDA изначально, в целом достигнуты, и сегодня технология применяется повсеместно - военными, в энергетике, в науке. Сейчас общей тенденцией является процесс возвращения компьютерных архитектур. Речь о параллельных вычислениях, которые уже были в своё время в фаворе, однако в последние двадцать лет уступили лидерство распространённым ныне архитектурам.

Переход на распараллеленные вычисления – общая индустриальная тенденция, факт которой подтверждается исследованиями и наработками, имеющимися у всех представителей CPU/GPU-индустрии. И самое время продемонстрировать, чего достигла архитектура CUDA к сегодняшнему дню.
В первом демонстрационном ролике нам показали возможности тесселяции при современном рендеринге объёмных объектов с очень высоким разрешением с производительностью до гигабайт в секунду. С увеличением разрешения также значительно усложнилась и геометрия объектов.
Второй демо-ролик представил парочку тестов с симуляцией тумана с помощью смог-машины. Такая технология широко применяется при эмуляции крэш-тестов и при моделировании процессов гидродинамики, а также в современных 3D-играх. Один из примеров работы новейшей вычислительной графики: отличное отображение деталей, 20 трлн операций в секунду.
Третий пример - многоуровневая объёмная симуляция взаимодействия жидкостей с рендерингом в реальном времени для следующего поколения игр.
После демонстрации возможностей современных параллельных вычислений, Дженсен перешёл к рассказу о вехах развития и распространения архитектуры CUDA. Так, если в прошлом году комплект SDK CUDA был скачан 293 тысячи раз, то в нынешнем, ещё не закончившемся году, количество загрузок уже превысило 668 тысяч. Если в прошлом году ОЕМ-разработкой специализированных систем на базе Tesla занималась одна компания, то в этом году уже насчитывается 19 оригинальных разработок от девяти компаний, в том числе из России. В то же время, значительно возрос интерес к GTC, в результате чего число подписавшихся выросло до 334 - более чем в пять раз по сравнению с 2009 годом.

Далее последовал ключевой анонс дня, и, возможно, всей конференции: в содружестве с PGI (The Portland Group, подразделение STMicroelectronics по разработке компиляторов для HPC) было объявлено новое CUDA-ускоряемое решение - SDK CUDA-x86.

Значение этого анонса трудно переоценить. До сих пор технология параллельных вычислений CUDA функционировала в системах с графическими чипами NVIDIA. С появлением CUDA-x86, в частности, грядущего компилятора PGI CUDA C, разработчики приложений могут оптимизировать приложения CUDA для любых настольных и серверных систем с процессорной архитектурой x86, максимально используя многоядерность и потоковые инструкции SIMD (Single Instruction Multiple Data) процессоров Intel и AMD для параллельных вычислений.
По предварительным данным, CUDA x86 будет впервые продемонстрирована 13-15 ноября в Новом Орлеане, в дни конференции SC10 Supercomputing, затем станет известно о сроках появления финальной версии пакета.
На протяжении нескольких последних лет многие ведущие софтверные компании объявляли о поддержке CUDA своими ключевыми приложениями. На практике это означает, что уже имеющийся в распоряжении пользователя компьютер позволяет обсчитывать большие объёмы данных значительно быстрее, благодаря наличию в системе видеокарты NVIDIA и возможности распараллелить процесс обработки этих данных. В некоторых случаях обработка информации ускоряется в разы без наращивания аппаратных возможностей. Разумеется, для специфических задач науки и промышленности, пишутся эксклюзивные приложения для распараллеливания обработки данных, но для массового потребителя гораздо важнее наличие серийных продуктов, уже знакомых по предыдущим версиям и готовых к немедленному применению.
Аккурат к GTC 2010 была подготовлена целая серия громких анонсов о поддержке CUDA новыми версиями широко известных индустриальных, промышленных, финансовых и мультимедийных приложений. Например, приложение для расчётов в биологии, квантовой физике и механике - Multi-GPU симулятор молекулярной динамики AMBER версии 11; пакет прикладных программ для решения задач технических вычислений MATLAB версии R2010b от MathWorks; универсальная программная система конечно-элементного анализа ANSYS Mechanical версии R13; научно-инженерный пакет Mathematica 8 компании Wolfram Research.

Анонс поддержки CUDA-вычислений профессиональной системой обработки трёхмерной графики Autodesk 3ds Max 2011, в том числе, за счёт поддержки PhysX и технологии GPU-ускорения iRay от mental images, сопровождался рядом впечатляющих демонстраций возможностей нового пакета. Например, демонстрацией поддержки рендеринга в облачных вычислениях на системах с наличием до 32 процессоров Fermi.
Впервые мы увидели утилиту для рендеринга объёмных объектов в Интернете в реальном времени, справляющуюся за считанные секунды с тем, на что ранее в 3D Max уходило до получаса вычислений. Это впечатляет.

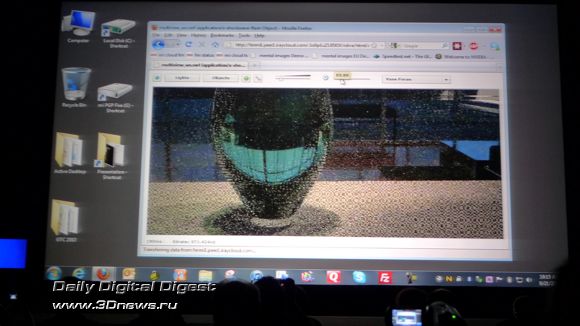
Очень интересно и содержательно выступили представители Adobe. Компания давно и последовательно поддерживает CUDA-вычисления в своих продуктах, а в рамках GTC 2010 было объявлено о расширении этой поддержки. Кроме того, представители Adobe рассказали об интереснейшем концепте цифровой «пленоптической» (plenoptic) фотокамеры, где конечное изображение получается с помощью оптической матрицы из десятков миниатюрных линз, расположенных перед сенсором камеры.

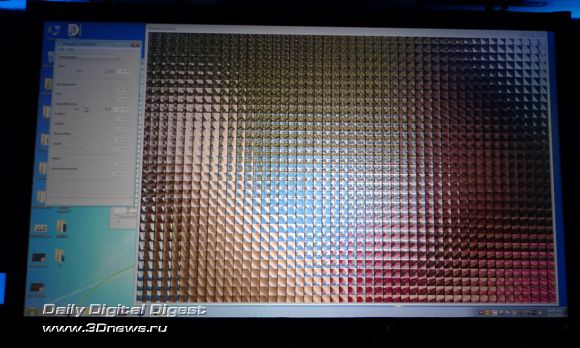
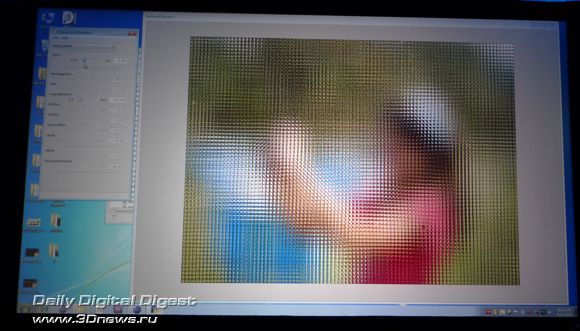

Полученный массив из множества небольших и частично перекрывающих друг друга снимков далее склеивается в один огромный снимок, и после обработки с полученным изображением можно творить чудеса – раскладывать его на трёхмерные картины, создавать HDR-изображения, менять и зону резкости и даже (!) глубину фокусировки.
В процессе демонстрации нам показали трехмерный снимок, сделанный таким мега-сенсором. Непосредственно в реальном времени докладчик менял различные настройки, от чего зона резкого изображения уходила на передний или задний план, менялся объём снимка. Фактически, на наших глазах из одного снимка были синтезированы несколько точек зрения, и делалось это играючи движками утилиты.

Заинтересовавшись идеей, я позже посетил специальный семинар Adobe, где об этой разработке рассказали в подробностях. Оказывается, на сегодняшний день такая камера уже выпускается серийно под названием Raytrix-R11. Другое дело, что ключевая особенность технологии заключается даже не столько в «железе» аппарата, сколько в программном обеспечении Adobe, творящего все эти невероятные чудеса. Конечно же, без поддержки CUDA обработка таких мощных массивов данных была бы не столь эффективна.
Не обошлось в первый день работы конференции без анонсов новых аппаратных решений. Дженсен Хуан объявил о трёх новых ОЕМ-партнёрах NVIDIA по разработке и продвижению решений на базе платформы Tesla. Ими стали компания IBM с новыми CUDA-серверами BladeCenter, компания Cray с новой Tesla-системой XE6, и известнейший российский производитель суперкомпьютеров компания «Т-Платформы» (T-Platforms) с сервером TB2 собственной разработки, также на базе Tesla.
Приятно отметить, что в рамках GTC 2010 российская «Т-Платформы» была представлена отдельным стендом, где демонстрировались образцы новой продукции компании. Совсем не случайно у стенда россиян постоянно образовывалась «пробка» из желающих ознакомиться с техническими деталями предлагаемого ими решения, оно действительно уникально даже в рамках мировой практики.

Дело в том, что сервер TB2-TL представляет собой гибридный вычислительный модуль, предназначенный для конструирования на его основе суперкомпьютеров высшего диапазона производительности, с самой высокой вычислительной плотностью и энергоэффективностью среди всех вычислительных систем, представленных на мировом IT-рынке.


Система T-Blade2 на основе таких модулей позволяет достичь производительности до 1 Пфлопс при использовании всего 10 стандартных стоек – в 4 раза меньше, чем у обычных современных суперкомпьютеров. Система также обеспечивает рекордное соотношение производительности и энергопотребления в 1450 Мегафлопс/Вт – почти вдвое лучше, чем у лидера текущей редакции рейтинга самых энергоэффективных суперкомпьютеров мира Green500.org.
Кроме того, по словам представителей компании, производительность TB2-TL при меньшем энергопотреблении и такой же цене превышает возможности аналогичного решения на базе 64 шестиядерных процессоров Intel Xeon. Начало поставок серверов TB2-TL запланировано на четвертый квартал 2010 года, а широкая доступность решения ожидается в первом квартале 2011 года.
В разговоре с представителями компании на их выставочном стенде также удалось уточнить, что к новому решению "Т-Платформ" уже присматривается ряд влиятельных отечественных заказчиков, так что вполне возможно, что в ближайшее время мы сообщим нашим читателям о первых российских суперкомпьютерах на базе систем TB2-TL. К тому же, сам факт участия компании "Т-Платформы" в престижной международной конференции GTC 2010 оставляет надежду на то, что решениями российских разработчиков заинтересуются зарубежные заказчики. Пожелаем же им успехов в продвижении на международный рынок.
В соответствии с известным циклом разработки новых графических решений – порядка 24 месяцев, и типичными сроками перехода на новые производственные техпроцессы – примерно 18 месяцев, никто не ожидал анонсов архитектурных решений в рамках GTC 2010. Тем более приятным оказался сюрприз, когда Дженсен Хуан анонсировал подробности о планах NVIDIA по выпуску следующих после архитектуры Fermi поколений GPU, а затем, в ходе пресс-конференции после доклада, поведал о них ряд дополнительных подробностей. Постараюсь рассказать об этом как можно подробнее.
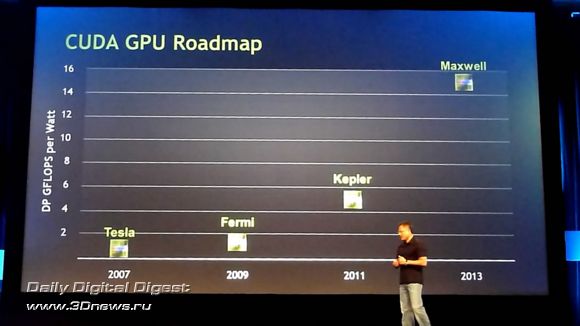
Согласно озвученным планам, NVIDIA планирует представить следующее поколение графической CUDA-архитектуры для параллельных вычислений с рабочим названием Kepler во второй половине 2011 года (не удивлюсь, если это произойдёт в дни GTC 2011, точная дата проведения которой, впрочем, пока не определена). Ожидается, что первые GPU с микроархитектурой Kepler будут выпускаться на производственных линиях с соблюдение норм 28-нм техпроцесса. Напомню, что нынешние чипы NVIDIA выпускаются на фабриках TSMC по 40-нм техпроцессу, что в целом сравнимо с возможностями другого известного контрактного производителя GPU, компании GLOBALFOUNDRIES.

Далее – в 2013 году, наступит черёд новой микроархитектуры с рабочим названием Maxwell, выпуск которой, скорее всего, будет налажен на линиях с соблюдением норм 20-нм техпроцесса.
Ввод новых архитектур GPU сопровождается планами NVIDIA по удвоению точности вычислений с плавающей запятой с вводом каждого нового поколения с одновременным снижением энергопотребления и многократным увеличением производительности.
Особенно прошу обратить внимание на размерность вертикальной оси графика – GFLOPS per Watt. То есть, прирост производительности новых поколений графических архитектур в первую очередь привязывается к эффективности их энергопотребления. Таким образом, удельная, если так можно выразиться, производительность чипов Kepler ожидается примерно с трёхкратным превышением возможностей Fermi, а вычислительные способности на Ватт у GPU класса Maxwell превысят возможности Tesla примерно в 16 раз.
С учётом того, что нынешние 40-нм чипы GeForce GTX 480 / Tesla C2070 содержат порядка 3,2 млрд транзисторов, и придерживаясь теории об удвоении числа транзисторов для каждого нового поколения (хотя, на практике шаг техпроцесса порой позволяет реализовать лишь порядка 40% прироста числа транзисторов), можно теоретически предположить, что 28-нм чипы Kepler могут быть выполнены уже примерно на 6 млрд транзисторов, а для 20-нм архитектуры Maxwell их число может достичь 12 млрд. Кроме того, об архитектуре Maxwell также было сказано, что она претерпит значительные изменения, в частности, ожидается поддержка уникальных функций и совершенно новых типов памяти.
Завершая тему аппаратных инноваций NVIDIA, стоит упомянуть состояние дел с мобильной платформой Tegra. Дженсен Хуан заявил, что в настоящее время близка к завершению разработка чипов поколения Tegra 3 и уже ведутся работы над следующим поколением.
Вопрос о популярности платформы Tegra Дженсен напрямую связал с тем, что рынок решений на базе этой платформы сейчас находится в стадии начального развития, и со временем Tegra будет востребована не только в телефонах, но также суперфонах и планшетах. В связи с этим платформе как никогда требуется мощная индустриальная поддержка программными продуктами. Будет достаточный объем приложений – вырастет и популярность платформы.
На вопрос, когда же на рынке появится первый планшет на базе Tegra, Дженсен ответил в том же ключе: планшет не смысла выпускать на рынок ввиду неготовности достаточного количества приложений, которые ожидаются от парнёров компании. Таким образом, сроки определятся как только закончится формирование необходимой для этого программной инфраструктуры.
До сих пор в этом репортаже речь велась преимущественно о достижениях архитектуры параллельных вычислений CUDA, о последовательно нарастающей её поддержке со стороны индустрии аппаратных и программных решений, о перспективах развития. Теперь самое время уделить внимание прикладному аспекту внедрения. Понятное дело, CUDA – это, фактически, универсальный инструментарий, пригодный для решения любых задач, поддающихся распараллеливанию. Тем не менее, было интересно услышать примеры решения реальных задач на базе этой платформы.

Фактически, в каждом докладе на конференции рассказывалось о тех или иных способах использования CUDA для решения задач теоретической и прикладной науки, медицины, промышленности, индустрии развлечений и т.д.

Одним из наиболее интересных мне хотелось бы назвать рассказ исследователей из Гарварда, где с помощью специальных программных приложений исследуют вопросы компенсации движения сердца, что очень важно для точной хирургии.
В представленном ниже видеоролике примерно с середины четвёртой минуты вы можете увидеть запись удивительного процесса, когда анализ трёхмерного изображения сердца позволяет предсказать ритм и характер сердцебиения, и таким образом, компенсировать движение сердца в реальном времени при проведении операции хирургическим роботом, сведя к минимуму последствия вторжения в процесс его функционирования. Ролик демонстрировался зрителям доклада в трёхмерном формате, и это было захватывающее дух зрелище (именно поэтому заметно двоение картинки при просмотре невооружённым глазом, мы надевали соответствующие очки). Будет ли кто-нибудь спорить, что за такими роботами-хирургами будущее?
Кроме хирургии сердца, использование CUDA для медицинских целей демонстрировали представители ряда университетов. В частности, исследователи из университета Пенсильвании рассказали об использовании параллельных вычислений на базе GPU для расчёта алгоритмов, используемых при автоматическом анализе в рентгенографии. Учёные из университета Джорджа Мэйсона (George Mason) используют CUDA для двадцатикратного ускорения при моделировании динамики межклеточного проникновения кальция, что играет ключевую роль при возникновении сердечных аритмий. Наконец, специалистам из GE Global Research, благодаря распараллеливанию и оптимизации традиционных алгоритмов моделирования снимков магнитно-резонансного томографа с помощью CUDA, удалось ускорить процесс практически в 10 раз (по сравнению с системой на базе двух четырёхъядерных процессоров) и, таким образом, сделать его практически мгновенным.
Ключевой доклад второго дня, на котором выступил Клаус Шультен (Klaus Schulten), глава кафедры теоретической и вычислительной биофизики при университете Иллинойса в Урбана-Шампани, был полностью посвящён вопросам использования CUDA для создания вычислительного микроскопа, обеспечивающего обсчёт огромного потока данных в реальном времени.

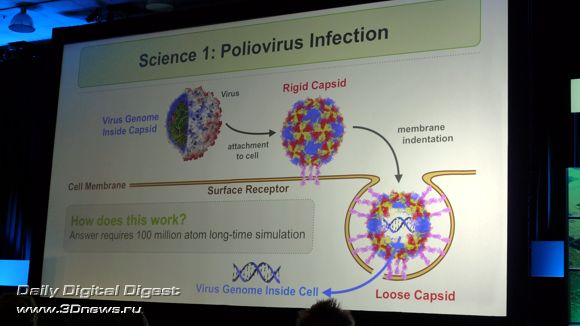

Тем, кто хотя бы немного в ладах с английским и интересуется проблемами современной биофизики, весьма рекомендую к просмотру видеозапись этого выступления. По сути, столь глубокое исследование тайн живой материи было бы просто немыслимо без сегодняшних вычислительных параллельных технологий.
Технология CUDA используется сегодня и астрофизиками лаборатории Lockheed Martin Solar & Astrophysics для исследования динамики структуры Солнца. В режиме реального времени учёные отслеживают все изменения, а также имеют все возможности для моделирования возможных ситуаций поведения солнечной фотосферы и короны.
Примеры удачного применения CUDA в самых различных приложениях можно приводить бесконечно. В три дня конференции уложились и рассказы сотрудников студии Walt Disney о создании трёхмерной анимации, и доклад студии Foundry об использовании CUDA-приложения Nuke для работы над такими фильмами как Avatar, Harry Potter, The Dark Knight и других. Сотни докладов, прочитанных в рамках GTC 2010, были посвящены не только обучению способам программирования и использования параллельных архитектур CUDA, но и демонстрации успехов, которых уже удалось достичь таким образом.
По традиции, в огромном холле конвент-центра Сан Хосе, в котором, собственно, и проходила конференция GTC 2010, были установлены десятки крупноразмерных постеров с примерами удачного внедрения технологии параллельных вычислений на GPU для решения самых различных задач. Здесь можно было найти примеры научных публикаций на самые различные темы вплоть до таких экзотических, как, например, преобразование речи в текст, распознавание зрительных образов искусственным интеллектом и т.д.






Ряд интересных и многообещающих примеров создания прикладных решений на базе CUDA-платформ демонстрировался на выставке конференции. Посетители надолго останавливались у стенда с диковинным роботом-манипулятором, в «щупальце» которого встроена интеллектуальная камера для распознавания объектов, у шатра, создающего удивительную объёмную иллюзию микромира, у стендов с программным обеспечением PQ Labs, позволяющим с помощью сенсорного экрана заниматься дизайнерскими разработками.
Всего на выставке были представлены стенды с программными и аппаратными решениями более чем от сотни различных компаний. Посмотреть было на что, и что вдвойне ценно, здесь же можно было познакомиться с разработчиками всех этих чудес, пообщаться, взять адрес электронной почты или просто обменяться визитными карточками для продолжения общения.


Резюмируя итоги поездки, хотелось бы подчеркнуть главное впечатление по итогам участия в GTC 2010: сегодняшний день компании NVIDIA – это не только графические чипы в традиционном их определении, технология CUDA уже превратилась в индустриальный стандарт для параллельных вычислений.
Растущая востребованность технологии CUDA в промышленной, финансовой, военной, научной и медицинской сфере; всесторонняя поддержка параллельных вычислений на базе GPU NVIDIA разработчиками программного обеспечения; серийное производство суперкомпьютерного оборудования на базе GPU Tesla индустриальными лидерами – всё это свидетельствует о стремительной трансформации бизнеса компании NVIDIA.
Если темпы этих изменений в ближайшее время останутся столь же высокими, не исключено, что достаточно скоро мы будем говорить о NVIDIA в первую очередь как о производителе решений для HPC, и лишь во вторую как о поставщике графических карт. Которые, впрочем, по-прежнему останутся устройствами двойного назначения, и даже в самом бюджетном исполнении для настольного ПК будут успешно ускорять графику или работать в качестве небольшого суперкомпьютера для параллельных вычислений.
Три дня пролетели как один миг, но рассказать обо всём увиденном и услышанном не хватит и десяти репортажей. Позже, когда удастся перевести дух и оформить впечатления в удобочитаемый вид, постараюсь рассказать нашим читателям о сессиях конференции, непосредственным участником которых довелось быть лично мне, а именно – на всех лекциях и докладах, посвящённых съёмке и последующей обработке трёхмерных фотографий и видеороликов. Содержание этих мероприятий настолько, на мой взгляд, ценно, что стоило съездить в Калифорнию только исключительно ради этого.
А на сегодня всё. Хотелось бы поблагодарить за столь содержательную и полезную поездку компанию NVIDIA, и в особенности сотрудников российского представительства, и пожелать компании и впредь поддерживать славную ежегодную традицию под названием GTC.






 Подписаться
Подписаться