С тех пор как Advanced Micro Devices и ATi превратились в одну компанию, у ценителей процессоров AMD и графических карт Radeon ни разу не было возможности собрать компьютер из комплектующих любимого производителя, не поступившись быстродействием в одном из ключевых аспектов — CPU или GPU. Два года тому назад AMD, вооруженная архитектурой Zen, совершила триумфальное возвращение на рынок центральных процессоров, но печальная примета вновь сбылась. Марка Radeon с тех пор и вплоть до настоящего момента переживает свои худшие времена. И началось это гораздо раньше — после Radeon R9 Fury X на чипе Fiji графическое подразделение AMD уже не смогло породить устройство, готовое наравне соревноваться с решениями NVIDIA за мантию самого производительного игрового GPU, да и в нижних ценовых эшелонах позиции «красных» слабеют год от года.

Но теперь, решив вопрос с центральными процессорами, AMD набралась сил для атаки на рынок дискретных графических карт. Сегодня мы представляем обзор ускорителей Radeon RX 5700 и Radeon RX 5700 XT, с помощью которых AMD намеревается потеснить NVIDIA из рыночной ниши, которую оккупировали младшие модели серии GeForce RTX — 2060 и 2070. Причем на этот раз главная ставка AMD сделана не на передовой техпроцесс 7 нм, по которому выпускают чип Navi, а на абсолютно новую логику RDNA, которая пришла на смену GCN — архитектуре с без малого восьмилетним стажем. RDNA должна решить проблемы, которые помешали чипам Polaris и Vega в полную силу выступить против конкурирующего кремния Pascal и Turing, а затем — если первый опыт будет удачным — она откроет дорогу ускорителям AMD к борьбе за титул абсолютного чемпиона.
Трудно удержаться от аналогий с архитектурой Zen, которой удалось за пару лет перевернуть рынок центральных процессоров, да и в истории ATi есть примеры революционных преобразований. И все-таки какие обстоятельства побудили разработчиков Radeon 5000-й серии отказаться от проверенной архитектуры GCN в пользу совершенно иного решения и что такого в RDNA, чтобы на рынке дискретных GPU опять возникла интенсивная конкуренция? Попробуем разобраться в этих вопросах, а затем приступим к долгожданным тестам Radeon RX 5700 и Radeon RX 5700 XT.
⇡#Новая архитектура RDNA
В первые годы GCN, которая дебютировала вместе с ускорителями Radeon HD 7970 еще в конце 2011 года, графические процессоры AMD, по большому счету, совершенно не уступали продуктам NVIDIA на чипах Kepler по энергоэффективности и быстродействию. Однако переход к архитектуре Maxwell, а затем Pascal позволил конкурентам AMD радикально нарастить производительность в 3D-рендеринге, оставаясь в границах прежнего резерва мощности. GCN тем не менее всегда держала паритет с чипами NVIDIA по массиву вычислительных блоков, однако колоссальный резерв теоретического быстродействия, которым отличаются продукты AMD, целиком раскрывается только в расчетах общего назначения — не удивительно, ведь GCN и была задумана как решение для задач GP-GPU в противовес предшествующей архитектуре TeraScale, ориентированной преимущественно на игры.
Для рынка дискретных видеокарт определяющее значение имеет показатель быстродействия на рубль, а не на ватт мощности, поэтому экономный кошелек нередко голосует именно за «красных». Тем не менее, коль скоро чипы GCN с определенного момента утратили возможность настолько эффективно транслировать терафлопсы расчетной производительности в быстродействие 3D-приложений, для того, чтобы поддерживать накал борьбы, видеокартам Radeon требуются более крупные чипы, чем те, которыми довольствуется NVIDIA. А в погоне за локальными победами в той или иной ценовой нише AMD раз за разом принуждала GPU работать на грани оптимальной зоны тактовых частот и питающего напряжения. В результате AMD уже давно не претендует на корону абсолютного быстродействия, да и в нижних категориях производительности NVIDIA было легче придать видеокарте такие характеристики, чтобы оправдать, как правило, более высокую розничную цену.
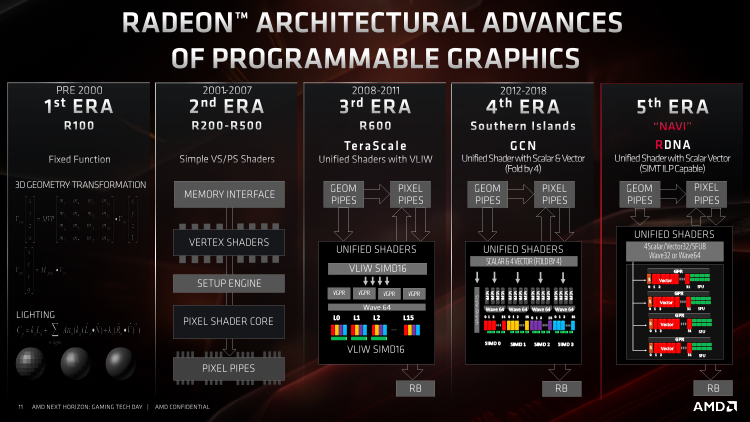
Благодаря архитектуре Turing NVIDIA совершила очередной скачок в энергоэффективности, и теперь стало совершенно ясно, что дальше AMD уже не может ехать по накатанным рельсам. Кроме того, архитектура GCN, несмотря на постоянные оптимизации и попытки консервативной переработки, которые происходили в каждом новом поколении кремния, не располагает такими новаторскими функциями, как аппаратное ускорение трассировки лучей и обработки данных методом машинного обучения. Однако AMD было не так-то просто отказаться от наследия GCN в пользу совершенно новой микроархитектуры. Свою роль сыграл и вероятный дефицит бюджета R&D в те годы, когда комапния работала едва ли не в убыток из-за плачевного положения дел на рынке центральных процессоров, и неудачное партнерство с полупроводниковым контрактором GlobalFoundries, который сперва аннулировал все планы по запуску линии 10 нм, а затем и вовсе прекратил работу над любыми новыми узлами после 14 нм FinFET.
Пространство для маневра наверняка ограничено и союзом с производителями консолей, для которых AMD разработала целую серию SoC с графическим ядром архитектуры GCN. NVIDIA по всем этим причинам чувствует себя более свободно и не стесняется проводить резкие изменения в архитектуре GPU. Неспроста ее то и дело обвиняют в том, что современные игры, рассчитанные на Direct3D 12 и Vulkan, из рук вон плохо работают на старых GPU архитектуры Kepler и Maxwell, — все дело в том, как сильно Pascal и Turing отличаются от прошлых итераций «зеленого» кремния.
Однако для ускорителей Radeon все-таки настал судьбоносный момент. Как утверждает AMD, над принципами архитектуры RDNA компания работала в течение восьми лет и последняя, в отличие от GCN, глубоко уходящей корнями в задачи GP-GPU, всецело сфокусирована на быстродействии 3D-приложений. Это еще совсем не значит, что RDNA не подходит для вычислений общего назначения, но место в этой нише по-прежнему будет занято существующими и, наверняка, грядущими продуктами на основе GCN. AMD последовала успешному примеру NVIDIA и отныне собирается поддерживать два отдельных направления архитектуры GPU — RDNA для игровых ускорителей и GCN для серверов и рабочих станций.
⇡#Легче и быстрее: Compute Unit графического процессора в GCN и RDNA
Для того чтобы понять фундаментальные различия между RDNA и GCN, сперва придется освежить в памяти основные принципы массивно-параллельных вычислительных процессоров, которыми являются GPU, и конкретику их реализации в чипах AMD, начиная с Tahiti — самого первого кристалла на основе GCN.
Львиную долю каждого современного GPU занимает массив шейдерных ALU. AMD называет их потоковыми процессорами, NVIDIA — ядрами CUDA, но, в сущности, и тот и другой блок выполняет одну функцию — арифметические операции над вещественными (с плавающей точкой) или целочисленными данными. Но сила GPU заключается в том, каким образом организована совместная работа шейдерных ALU. 3D-рендеринг и масса вычислительных задач иного рода подразумевает выполнение однотипных действий над массивом разных операндов, поэтому вычислительные блоки внутри чипа группируются так, чтобы одна инструкция могла занять в одно и то же время несколько ALU, а данные поступают на обработку в виде нескольких потоков (threads). Группа из 32 потоков в терминологии NVIDIA называется warp, GCN оперирует группами по 64 потока под названием wavefront. Соответственно, каждая инструкция warp’a или wavefront’а позволяет выполнить необходимую операцию над 32 или 64 операндами (последние мы будем далее называть рабочими единицами — work items).
Основным строительным блоком архитектуры GCN является Compute Unit (CU) — именно его, а вовсе не отдельные ALU можно считать аналогом ядра центральных процессоров, поскольку только CU целиком обладает способностью декодировать и отправлять инструкции на исполнение.
Compute Unit содержит 64 т. н. векторных ALU, разделенных на четыре блока SIMD (Single Instruction Multiple Data). И хотя wavefront’ы в архитектуре GCN состоят как раз из 64 потоков, каждый SIMD обрабатывает собственный wavefront параллельно с другими SIMD’ами, а поскольку в каждом SIMD’е есть всего лишь 16 ALU, для выполнения одной инструкции ему необходимо четыре такта — это ключевая черта архитектуры GCN, определяющая немало сильных и слабых сторон данной архитектуры. Другая важная особенность состоит в том, что векторный планировщик в CU всего один, и для того, чтобы загрузить все четыре SIMD работой, они получают собственные инструкции поочередно.
Для того чтобы запустить CU с нуля, требуется потратить четыре такта, а в течение трех первых часть ALU будет простаивать. Но у подобной логики есть и другой изъян. Все дело в том, что далеко не каждая инструкция требует полной загрузки 16 векторных ALU в течение четырех тактов. Wavefront’ам свойственно ветвиться, и в этот момент получается так, что часть рабочих единиц включает одну операцию, а часть — другую. SIMD должен проходить «ветки» в два приема, независимо от того, сколько векторных ALU при этом будет бездействовать. Кроме того, CU всегда требует не меньше четырех wavefront’ов для максимальной загрузки ALU — условие, которое по тем или иным причинам может кратковременно нарушаться.
Чтобы снизить влияние этих факторов и адаптировать GPU к операциям с меньшим количеством потоков, создатели архитектуры RDNA совершили переход от 64-поточных к 32-поточным wavefront’ам. CU теперь содержит два SIMD’a по 32 векторных ALU, и каждый SIMD снабжен отдельным планировщиком. CU архитектуры RDNA рассчитан на исполнение двух инструкций в течение одного такта, в то время как CU чипов GCN исполняет четыре инструкции в течение четырех тактов.
Заметим, что, поскольку wavefront в то же время стал в два раза уже, старая и новая архитектуры являются эквивалентными по терафлопсам на один CU — ни о каком удвоении пропускной способности тут речи не идет. Тем не менее RDNA действительно обязана проявить высокую эффективность в задачах с «легкопоточной» нагрузкой, и на этом все плюсы реорганизации CU далеко не заканчиваются. Так, благодаря отдельным планировщикам, обслуживающим собственные SIMD’ы, и одновременной отдаче двух инструкций каждый такт, RDNA характеризуется пониженной латентностью исполнения индивидуальных инструкций. И наконец, у RDNA есть еще одно, не столь очевидное достоинство. Как и в GCN, SIMD здесь не привязан к единственному wavefront’у — каждый раз, когда планировщик дает инструкцию на исполнение, она может быть выбрана из нескольких wavefront’ов (вплоть до 10 на каждый SIMD в GCN и 20 в RDNA). Но количество потоков, находящихся в рабочем пуле отдельно взятого CU, в результате уменьшилось с 2560 до 1280 — это значит, что в кешах теперь находятся менее разнородные данные и их объем используется более экономно.
Тем не менее темп исполнения одной инструкции в четыре такта, свойственный GCN, был изначально установлен не без веских оснований. Пока инструкция «бегает» на SIMD в течение четырех тактов, CU может дождаться получения данных, необходимых для следующей инструкции, — например, из оперативной памяти, обращение к которой происходит целую вечность по меркам внутренней логики GPU. Архитектура RDNA, напротив, пролетит через инструкции wavefront’а, пока не столкнется с необходимостью ожидания данных. Конечно, SIMD в этот момент может переключиться на один из 19 других wavefront’ов, но возможно и альтернативное решение проблемы. RDNA допускает работу со старым, 64-поточным форматом wavefront’а. В таком режиме инструкция широкого wavefront’а отдается на исполнение в два приема, и в период отработки за два такта латентность в ожидании отсутствующих данных эффективно маскируется.
Широкие и узкие wavefront’ы могут сосуществовать в пределах рабочего пула одного SIMD без необходимости в смене контекста, однако специфику выбора между тем или иным форматом — существуют ли в ISA архитектуры RDNA инструменты, определяющие ширину wavefront’а, или это является решением драйвера — AMD не раскрывает. Прим. от 09.08.2019: ширину wavefront'a определяет компилятор. Вычислительные шейдеры обычно компилируются в формате Wave32, пиксельные — Wave64. Как бы то ни было, устоявшиеся приложения GP-GPU, тщательно оптимизированные с расчетом на особенности GCN, равно как и игровые шейдеры, скомпилированные в машинном коде (Shader Intrinsics), наверняка нуждаются в ревизии, чтобы извлечь из RDNA максимально высокую эффективность.
Функция Rapid Packed Math, которая появилась в графических процессорах Vega, перекочевала и в RDNA. За счет нее чипы AMD могут выполнять операции над данными половинной точности (FP16 или INT16) с удвоенным темпом по сравнению с FP32 или INT32. На уровне Compute Unit'а принцип действия Rapid Packed Math таков, что два операнда FP16/INT16 объединяются в одной рабочей единице wavefront'a. Последний в таком случае эффективно увеличивается вдвое, но инструкция требует для исполнения такое же количество тактов: четыре в GCN и один в RDNA. GCN может задавать произвольный темп обработки данных двойной точности (FP64) в соответствии с предназначением конкретного чипа — от 1/2 до 1/16 по отношению к FP32. В большинстве потребительских видеокарт AMD пропускная способность FP64 равна 1/16, но есть примечательные исключения — такие, как ускорители на чипах Hawaii (Radeon R9 290/390 и Radeon R9 290/390X) и Radeon VII, у которых соотношение между FP64 и FP32 установлено на уровне 1/4. Сохранилась ли в RDNA такая гибкость, мы пока не знаем, но судя по предварительным тестам, конкретно Radeon RX 5700 и Radeon RX 5700 XT обрабатывают FP64 в темпе 1/16.
⇡#Скалярные ALU в GCN и RDNA
Помимо векторных SIMD, которые обслуживает собственный планировщик, в каждом Compute Unit’е графических процессоров AMD — как GCN, так и RDNA — существует двойной скалярный конвейер, который обслуживает собственная логика декодирования и отправки инструкций. Одна часть скалярного блока выполняет операции условного ветвления в коде шейдерных kernel'ов и некоторые типы синхронизации. Другая представляет собой полноценное целочисленное ALU, открывающее альтернативный путь исполнения для инструкции wavefront’а — на тот случай, когда все из 32 или 64 рабочих единиц содержат однородные данные, и можно смело заменить их единственной операцией вместо того, чтобы делать одну и ту же работу несколько десятков раз подряд.
В GCN скалярный блок может быть использован в течение каждого такта, но только одновременно с тем из четырех SIMD, к которому подошла очередь единого векторного планировщика. В RDNA скалярных блоков два, а поскольку четырехтактная ротация SIMD’ов ушла в прошлое, они способны принимать инструкцию на исполнение каждый такт, причем параллельно векторной инструкции соседнего SIMD’а, что дополнительно усиливает параллелизм в чипах AMD.
⇡#Блоки специального назначения (SFU)
Третий тип исполнительных блоков, который присутствует в Compute Unit’е GCN и RDNA, предназначен для т. н. операций специального назначения. Под этим термином скрываются тригонометрические функции, которые нередко используются при 3D-рендеринге. В рамках GCN блок SFU представляет собой отдельный SIMD, который состоит из четырех ALU, привязан к каждому из основных векторных SIMD’ов и служит в качестве резервного пути исполнения инструкции wavefront’а — для этого требуется 16 тактов, в течение которых векторный SIMD вынужден бездействовать.
В RDNA используется похожая организация SFU: с каждым из двух векторных SIMD ассоциирован SFU, в который входят 8 ALU. Таким образом, тригонометрические операции чип RDNA тоже исполняет в темпе 1/4 от стандартных векторных инструкций. Но есть одно ключевое отличие: из общих ресурсов векторный SIMD и SFU имеют только порт планировщика, а в остальном оперируют независимо друг от друга. Чтобы CU мог загрузить SFU, векторный SIMD должен пропустить лишь один такт, а в течение трех следующих, пока SFU отрабатывает свою инструкцию, SIMD готов принимать и исполнять инструкции в стандартном режиме. Вот еще один источник параллелизма и в конечном счете более высокой фактической производительности в пересчете на терафлопс, который сулит графическим процессорам AMD архитектура RDNA.
⇡#Переработанная структура кешей
Как мы уже писали выше, исполнение инструкций с темпом в один такт, на который рассчитана архитектура RDNA, делает ее уязвимой для задержек исполнения, вызванных ожиданием данных, а значит, чип Navi особенно требователен к организации стека памяти — от внутренних кешей Compute Unit’а до интерфейса оперативной памяти. Ведь даже чипы GCN, для которых характерна латентность исполнения инструкции в четыре такта (включая «Вегу» с чрезвычайно высокой ПСП, которую обеспечивает память HBM2), нуждаются в доступе к данным на коротком расстоянии и значительно выигрывают от разгона RAM. К счастью, создатели RDNA не обошли стороной этот момент и полностью преобразили структуру памяти графического процессора.
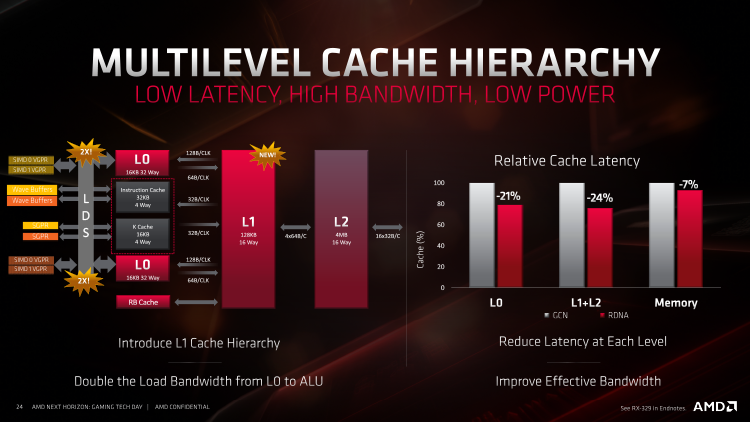
Преобразования не обошли стороной ни один уровень стека памяти графического процессора. Ближайшее хранилище к SIMD'ам — векторные регистры общего назначения (vGPR, Vector General Purpose Registers) — в RDNA увеличилось сразу в четыре раза: с 256 до 1024 регистров на один SIMD. В то же время и скалярных регистров стало 2560 вместо 800. Но это лишь первый пункт длинного списка усовершенствований.
Отдельные CU в составе GCN и RDNA сгруппированы по несколько штук и пользуются несколькими типами разделяемых ресурсов — таких как 32-килобайтный кеш инструкций и скалярный кеш объемом в 16 Кбайт. Однако если в чипах GCN эти хранилища были общими для четырех (а впоследствии трех) CU, то в RDNA группа связанных CU, называемая Workgroup Processor, уменьшена до двух участников, а конкуренция за общие ресурсы в результате ослабевает.
Хранилище LDS (Local Data Store), которое представляет собой наиболее быстрый тип памяти после регистров векторных SIMD, теперь тоже стало общим для двух CU и увеличилось в объеме в два раза — с 64 до 128 Кбайт. Кроме того, количество потоков на отдельно взятый CU при работе с 32-поточными wavefront’ами в RDNA вдвое меньше, чем в GCN, а значит меньше конкуренция и за пространство LDS: GCN запускает вплоть до 10 wavefront'ов на один SIMD, а RDNA — вплоть до 20, но SIMD'ов стало два вместо четырех, и общее количество потоков изменилось с 2560 на 1280. 64-килобайтное хранилище GDS (Global Data Share), к которому имеют доступ wavefront'ы шейдерного kernel'а, работающие на любых CU графического процессора, сохранило прежний объем в 64 Кбайт.
Не менее грандиозные изменения произошли на следующих уровнях стека памяти RDNA: 16-килобайтный кеш L1 в пределах отдельно взятого CU теперь считается кешем нулевого уровня, а попутно инженеры AMD увеличили его ассоциативность с 4 до 32 каналов (а это, в свою очередь, значительно влияет на процент попаданий в кеш) и нарастили вдвое пропускную способность дороги к векторным ALU. Место старого L1 в иерархии памяти RDNA теперь занимает громадный 128-килобайтный кеш, доступный десяти Compute Unit’ам, с 16-канальной ассоциативностью. Он должен снять значительную часть нагрузки с кеша L2, ведь последний обошелся без значительных изменений после предыдущей итерации в чипах Vega: при 16-канальной ассоциативности и объеме в 4 Мбайт кеш L2 чипа Navi связан, с одной стороны, с каждой секцией L1, а с другой — посредством шины Infinity Fabric — с контроллерами RAM и uncore-компонентами SoC (блоками DMA для коммуникации между дискретными GPU, кодеком видеопотока и т. д.).
И наконец, в дополнение к очередной оптимизации алгоритмов компрессии цвета, RDNA допускает передачу сжатых данных по тем участкам конвейера рендеринга, где в GCN было разрешено только движение «сырых» данных. Шейдерные программы могут считывать и записывать компрессированный цвет не только в RAM, но и в кеш-память L1 и L2 (шейдерам в Polaris и Vega было позволено только чтение). Также возможна передача сжатого цвета из L2 в контроллер дисплея.
⇡#GCN vs RDNA vs Turing
Дополнение 18.07.2019
Чип Navi стал кульминацией крупнейших преобразований, которые AMD когда-либо совершала в логике своих графических процессоров после перехода от принципов VLIW к скалярной архитектуре Graphics Core Next почти восемь лет тому назад. RDNA акцентировала достоинства GCN и устранила ее главные недостатки. Однако для того, чтобы оценить RDNA по достоинству, нельзя обойтись без сравнения с тем, чего достиг за это время второй дуополист рынка дискретных GPU. Но перед тем как сделать свои выводы, мы направили AMD массу вопросов о подробностях работы RDNA, которым нет ответа в скудной документации Navi, да и про GCN еще не все известно с исчерпывающей точностью. К сожалению, AMD оказалась не настолько открытой к сотрудничеству с прессой, как того хотелось бы, и в итоге мы решили опубликовать сравнение RDNA с Turing исходя из той неполной информации, которой уже располагаем. Без подтверждения от AMD наши выкладки не застрахованы от ошибок, но в отдельных аспектах архитектуры, которые заставляют нас сомневаться (таких, например, как параллельная отправка инструкций на скалярные и векторные ALU), мы опираемся на вполне обоснованные гипотезы. NVIDIA, с другой стороны, помогла разобраться в том, как работают ее графические процессоры, и за анализ Turing мы полностью ручаемся.
Глубокая ревизия, которой AMD подвергла свою графическую архитектуру, изрядно похожа на то, что сделала NVIDIA в чипах Maxwell (а затем продолжила в Turing), изменив соотношение между исполнительной и управляющей логикой и сократив набор ALU, подчиненных каждому планировщику. Ключевая особенность GCN — исполнение wavefront’a из 64 рабочих единиц за 4 такта — ушла в прошлое, и в целом графический процессор теперь настроен на то, чтобы извлекать параллелизм из легкопоточной нагрузки, нежели большого количества wavefront’ов, которые необходимы GCN для эффективной работы. Однако если сравнивать Navi именно с Turing, то NVIDIA по-прежнему располагает во многих отношениях более сильной и гибкой архитектурой. О принципах работы чипов Turing и особенностях, которые отличают новые графические процессоры NVIDIA от предыдущих итераций — Maxwell и Pascal — мы уже подробно написали в первой части нашего обзора GeForce RTX 2080 Ti, но сейчас не помешает краткое резюме. К тому же, с тех пор нам стали известны некоторые подробности о Turing, которые поначалу не были освещены настолько хорошо.
Аналогом Compute Unit’а в чипах NVIDIA является SM — потоковый мультипроцессор (Streaming Multiprocessor). Начиная с Maxwell, инженеры NVIDIA делят SM на четыре секции с различным числом вычислительных блоков внутри (в зависимости от конкретной реализации в том или ином GPU) и пришли к тому, что в Turing секция SM содержит 16 шейдерных ALU (CUDA-ядер). Последние, по большому счету, выполняют ту же функцию, что один SIMD из 16 ALU в GCN, однако это лишь поверхностное сходство.
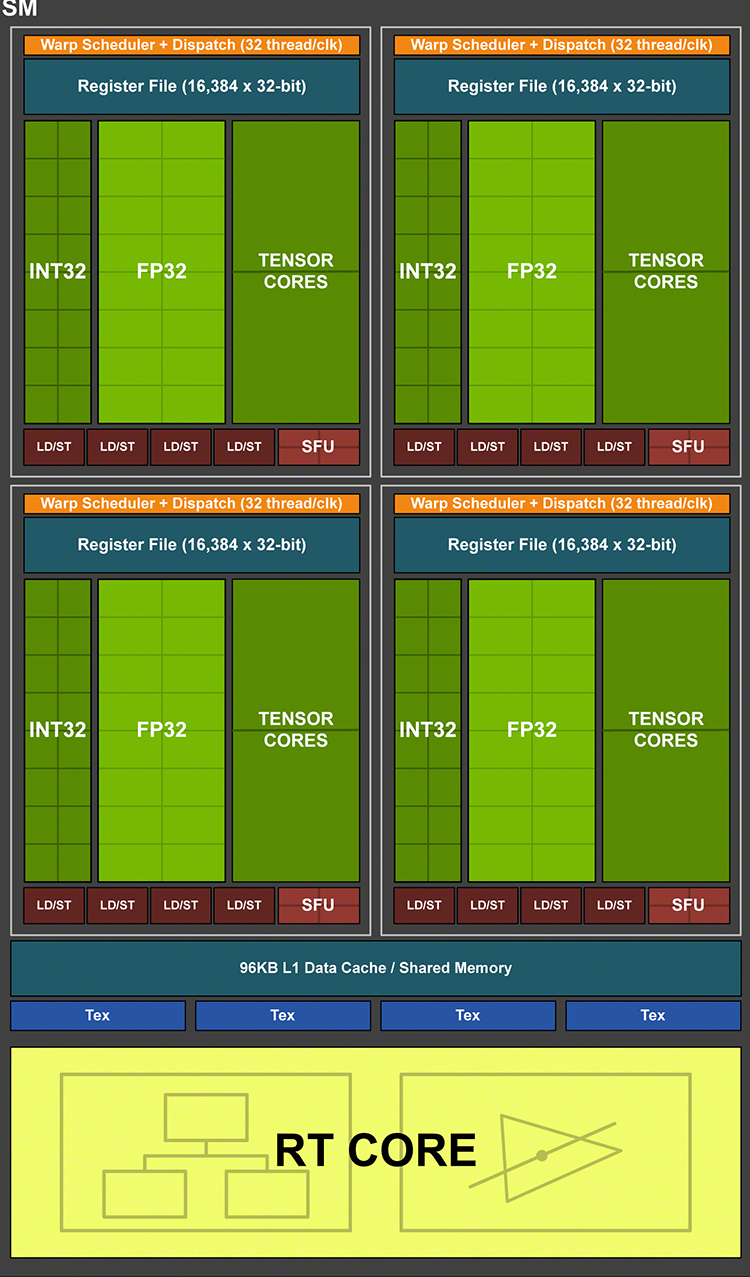
Потоковый мультипроцессор архитектуры Turing
В процессорах Volta и Turing отделили пути данных для операций над целыми числами внутри CUDA-ядер от арифметики с плавающей запятой — таким образом количество независимых ALU внутри SM эффективно удвоилось. Работа планировщиков и выдача инструкций у NVIDIA тоже организована совершенно по-другому. В каждой секции SM находится собственный планировщик, который за такт отправляет на исполнение одну инструкцию warp’a — группы из 32 потоков. Блоку 16 шейдерных ALU нужно два такта, чтобы ее выполнить, а во втором такте планировщик остается свободен. Нечетные такты планировщика могут быть заняты отправкой инструкций — обязательно из другого warp’а — на 16 целочисленных ALU (или другие типы исполнительных блоков, которые мы пока не упоминали), поэтому теоретическая пропускная способность Turing при полной загрузке целочисленными расчетами и операциями с плавающей точкой также увеличивается в два раза по сравнению с исключительно дробной или исключительно целочисленной арифметикой.
Помимо FP- и INT-ALU в каждой секции SM есть блок из четырех ALU специального назначения (SFU), предназначенных для выполнения тригонометрических операций. Одну инструкцию warp’а SFU выполняет за восемь тактов, но занимает только один такт планировщика для инициализации. В наборе инструкций процессоров Turing появились скалярные операции, а значит — есть и скалярные ALU, но их количество и специфику получения инструкций NVIDIA предпочитает держать в секрете.
Среди других исполнительных блоков секции SM есть два тензорных ядра, которые рассчитаны на единственный тип операций — FMA (Fused Multiply Add), — а в качестве операндов принимают матрицы чисел с плавающей запятой. Подобные вычисления используются при обработке данных нейросетями (inference) — как в фирменном алгоритме масштабирования DLSS. Но за пределами машинного обучения у тензорных блоков есть еще одно применение — на них Turing выполняет операции с вещественными числами половинной точности (FP16). В младших чипах Turing — TU116 и TU117 — заменой тензорных ядер является блок из 32 специализированных ALU, однако и в том, и в другом случае результат один: инструкция warp’а над операндами FP16 выполняется за один такт — вдвое быстрее операций стандартной точности.
Общими компонентами SM за пределами четырех секций являются четыре TMU (блока фильтрации текстур) и один блок трассировки лучей. Пара CUDA-ядер для операций двойной разрядности (FP64) присутствуют в Turing для совместимости с кодом, содержащим высокоточные расчеты.
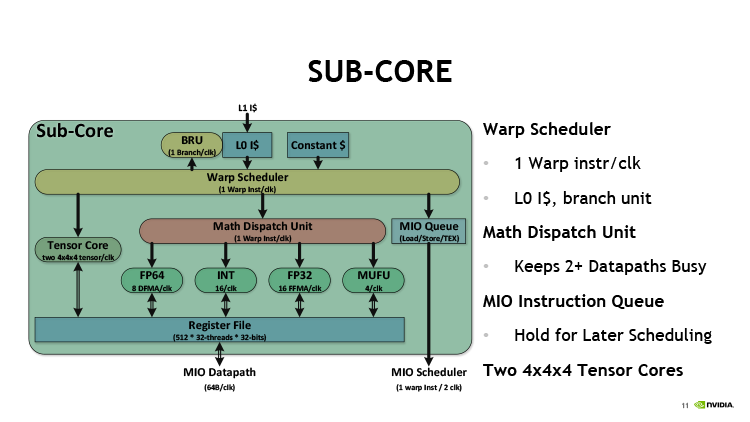
Секция SM архитектуры Volta
Таким образом, секция SM способна оперировать четырьмя типами инструкций — арифметика с вещественными числами одинарной точности (на CUDA-ядрах FP32), с целыми (INT32), с вещественными половинной точности (FP16) и тригонометрические операции (SFU). Однако конкуренция исполнительных блоков за такты планировщика позволяет параллельно загрузить только три типа исполнительных блоков из четырех: благодаря тому, что FP32- и INT32-инструкции бегают на своих ALU по два такта, а SFU — по восемь, возможны различные комбинации между ними. Кроме того, клиентами планировщиков являются еще и блок ветвлений, а также группа блоков load/store. Чтобы задействовать какой-либо из них, в этот такт планировщик не может отдать инструкцию для исполнения на шейдерных ALU. Кстати, архитектура GCN обходит последнее ограничение за счет большого числа портов планировщика (за такт он может отдать вплоть до пяти инструкций различного типа) — запросы к памяти и ветвление выполняются параллельно с выдачей инструкций векторным и скалярным ALU.
Расчеты пропускной способности, которую развивает SM графических процессоров Turing, приведены в таблице для сравнения с GCN и RDNA. Заметим, что мы не пытались охватить абсолютно все сочетания инструкций, которые возможны в рассмотренных архитектурах, а выкладки для GCN и RDNA основаны на предположении, что скалярные блоки действительно обладают отдельным планировщиком и могут получать инструкции параллельно векторным SIMD’ам. Пропуск тактов ALU, который в чипах NVIDIA могут вызывать операции load/store, тоже не берется во внимание. Все, что нам было нужно, это оценить пиковое быстродействие при работе с тем или иным форматом данных: FP32, INT32, FP16, а также тригонометрические операции. А с учетом темпа исполнения медленных инструкций мы взяли за временной интервал пропускной способности восемь тактов GPU — таким образом в таблице остается меньше дробных чисел.
| Compute Unit (GCN 5 поколения) | Compute Unit (RDNA) | Streaming Multiprocessor (Turing) |
|---|
| Исполнительные блоки |
4 × векторных SIMD16;
4 × векторных SIMD4 SFU;
1 × скалярное ALU;
4 × TMU (блока фильтрации текстур).
|
2 × векторных SIMD32;
2 × векторных SIMD8 (SFU);
2 × скалярных ALU;
4 × TMU (блока фильтрации текстур).
|
4 × секции 16 ALU (FP32);
4 × секции 16 ALU (INT32);
4 × секции 4 SFU;
? × скалярных ALU;
4 × секции 2 тензорных ядрер (или 4 × секции 32 FP16 ALU);
2 × ALU (FP64);
1 × RT-ядро; 4 × TMU (блока фильтрации текстур).
|
| Пропускная способность, инструкций за 8 тактов |
8 × FP32 (64 раб. ед.) +
8 × скалярных
ИЛИ
8 × FP16 (2 × 64 раб. ед.)
+ 8 × скалярных
ИЛИ
4 × 1/2 SF FP32 (64 раб. ед.)
+ 8 × скалярных
|
16 × FP32 (32 раб. ед.) +
16 × скалярных
ИЛИ
16 × FP16 (2 × 32 раб. ед.) +
16 × скалярных
ИЛИ
12 × FP32 (32 раб. ед.) +
4 × SF FP32 (32 раб. ед.) +
16 × скалярных
|
16 × FP32 (32 раб. ед.) +
16 × INT32 (32 раб. ед.)
ИЛИ
32 × FP16 (32 раб. ед.)
ИЛИ
4 × (3 + 1/2) FP32 (32 раб. ед.) +
4 × (3 + 1/2) INT32 (32 раб. ед.) +
4 × SF FP32 (32 раб. ед.)
|
|
8 × FP32 (64 раб. ед.) +
16 × скалярных
ИЛИ
8 × FP16 (2 × 64 раб. ед.) +
16 × скалярных
ИЛИ
6 × FP32 (64 раб. ед.) +
2 × SF FP32 (64 раб. ед.) +
16 × скалярных
|
| Пропускная способность, операций за 8 тактов |
512 × FP32/INT32 +
8 скалярных
ИЛИ
1024 × FP16/INT16 +
8 скалярных
ИЛИ
128 × SF FP32 +
8 скалярных
|
512 × FP32/INT32 +
16 скалярных
ИЛИ
1024 × FP16/INT16 +
16 скалярных
ИЛИ
384 × FP32/INT32 +
128 × SF FP32 +
16 × скалярных
|
512 × FP32 +
512 × INT32
ИЛИ
1024 × FP16
ИЛИ
448 × FP32 +
448 × INT32 +
128 × SF FP32
|
Так что же получилось в итоге? RDNA, да и GCN тоже, совершенно не уступает Turing по расчетному быстродействию в операциях FP32/INT32, FP16/INT16 или SFU, когда графический процессор больше ничем не занимается. Кроме того, тригонометрические операции SFU в RDNA теперь не заставляют отдыхать векторные SIMD’ы, хотя их присутствие в шейдерном коде все-таки сильнее бьет по общей пропускной способности, чем в Turing. Ключевое различие между современными архитектурами AMD и NVIDIA на уровне темпа исполнения инструкций — это параллельные операции над целыми и вещественными числами, которые возможны на полной скорости в Turing, но не в GCN и RDNA. Для шейдерного кода современных игр это совсем немаловажный фактор и одна из причин, наряду с RT-ядрами, которые позволяют чипам NVIDIA эффективно выполнять трассировку лучей в реальном времени.
Впрочем, за пределами столь ресурсоемких и специфических задач, как Ray Tracing, достойным соперником RDNA после многолетнего отставания в игровой сфере можно считать и предыдущую архитектуру NVIDIA — Pascal, — которая не обладает возможностью удвоить быстродействие за счет параллельной работы целочисленных и вещественно-численных ALU. Как мы уже не раз отметили, решающее значение имеют не терафлопсы, а способность GPU эффективно распоряжаться своими вычислительными ресурсами — в этом вопросе критерием истины будет практика.
⇡#Графический процессор Navi 10
Наиболее крупной структурой в организации компонентов чипа Navi является Shader Engine. В составе Navi 10 их два — каждый содержит по 20 CU и массив конвейеров растеризации (ROP). Таким образом, полнофункциональная версия Navi 10 включает 2560 шейдерных ALU и 160 блоков фильтрации текстур. Среди чипов прошлого поколения можно безошибочно назвать аналог подобной конфигурации — это старший чип семейства Polaris. Только Polaris, несмотря на две ревизии после его дебюта в составе Radeon RX 480, все-таки не дорос до 40 CU.
Однако между Polaris и Navi можно обнаружить существенные различия, выходящие за пределы внутренней организации Compute Unit’ов, которую мы обсуждали до сих пор, — начиная с того, что Navi досталось вдвое больше ROP: 64 вместо 32. Это совершенно необходимое изменение back-end’a GPU в свете того, что от RDNA ожидается повышенная эффективность в 3D-рендеринге, — считается, что Polaris избегал «пузырей», возникающих при ожидании отработки ROP, попросту за счет общего недостатка эффективной загрузки шейдерных ALU.
Впечатляющий пиксельный филлрейт, который развивают 64 конвейера растеризации, сочетается с поддержкой оперативной памяти типа GDDR6. Navi 10, как и старший Polaris, обходится 256-битной шиной RAM, но высокая пропускная способность GDDR6 (14 Гбит/с на контакт) гарантирует необходимую более эффективной архитектуре скорость доступа к данным. Полная ревизия стека памяти, которую провели инженеры AMD в чипе Navi, заканчивается поддержкой удаленных коммуникаций по шине PCI Express четвертого поколения. Впрочем, увидеть PCI Express 4.0 в деле на первых порах позволит только собственная платформа AMD с процессорами Ryzen 3000-й серии, а Navi 10 в любом случае не сможет загрузить настолько быстрый канал связи с CPU.

Front-end графического конвейера представлен блоками обработки геометрических примитивов. Создатели Navi изменили его топологию таким образом, что часть стадий геометрической логики, включая растеризатор, осталась в пределах Shader Array или, как раньше называли этот блок, Compute Engine (познакомьтесь еще с одним термином архитектуры чипов AMD) — структуры, объединяющей половину всего содержимого Shader Engine. А общий геометрический процессор вынесен за пределы Shader Array, поближе к командным процессорам ACE (Asynchronous Compute Engine), распределяющим потоки шейдерных вычислений между Compute Unit’ами. Всего Navi 10 может получить вплоть до четырех геометрических примитивов, прошедших стадию фильтрации невидимых поверхностей за такт — как Vega. Однако напомним, что в составе полностью функционального чипа Vega на 60 % больше шейдерных ALU и блоков фильтрации текстур, так что пропорция между мощностью геометрического front-end’a и основных ресурсов, обеспечивающих текстурирование и работу шейдерных kernel’ов, в Navi явно более выгодная.
Каким образом AMD поступила с альтернативным конвейером NGG (Next Generation Geometry), мы не можем сказать с полной уверенностью. Vega за счет NGG умеет отсекать невидимые треугольники на ранних стадиях рендеринга и может принять до семнадцати примитивов за такт, чтобы отдать на растеризацию четыре. Условием для этого являются Primitive Shaders — высокоэффективные программы, заменяющие ряд операций в конвейере стандартных графических API (доменные и геометрические шейдеры). Поначалу AMD собиралась активировать примитивные шейдеры на уровне компилятора, но затем по невыясненным причинам отказалась от этой идеи. Ни в игровых движках, ни в виде расширений API прямая поддержка NGG так и не появилась спустя без малого два года жизни Vega на рынке игровых ускорителей. Однако слайды, посвященные RDNA, говорят, что Navi тоже способна отсекать невидимые полигоны «с помощью шейдеров»: восемь на входе и четыре на выходе. Согласно неофициальным, но вполне респектабельным источникам, это и есть следующая версия NGG, которая на этот раз задействована в драйвере и не требует ответных усилий со стороны API и графических движков.
Прим. от 29.07.2019
Судя по результатам профилировки игр с помощью свежей версии Radeon GPU Profiler, блок NGG в чипах Navi действительно запущен, и большая часть вычислений проходит через него, нежели стандартный геометрический конвейер. В дополнение к тому, что примитивные шейдеры используются для отбраковки невидимых поверхностей, ожила и другая функция NGG — шейдеры поверхности (Surface Shaders), которые по решению компилятора заменяют часть шейдерной цепочки, вовлеченной в тесселяцию (Vertex Shaders и Hull Shaders) до того, как данные попадают в собственно тесселятор — блок фиксированной функциональности. Теперь понятны комментарии AMD к топологии разделов GPU, связанных с геометрией, и их обновленная номенклатура. В архитектуре GCN под термином Geometry Processor подразумевается весь геометрический конвейер, кроме растеризатора, повторяющий модель программирования Direct3D. И напротив, в RDNA блок с тем же названием занимается общими этапами работы, а преобладающая часть действий до и после тесселяции распределена по блокам Primitive Unit, находящимся внутри каждого Shader Array.
Как бы то ни было, AMD все-таки не нашла возможности включить NGG на ускорителях архитектуры GCN: между тем, как эта опция реализована в Vega и Navi, явно есть какие-то существенные различия, о которых разработчики предпочитают не говорить. В будущем для NGG может найтись другая работа, помимо эффективной фильтрации невидимых полигонов — среди прочего, генерация карт теней, рендеринг с неравномерным разрешением или с нескольких точек обзора, — но эти функции уже наверняка потребуют эксплицитной поддержки в приложениях или API.
NVIDIA предлагает свою альтернативу стандартной последовательности шейдерных этапов, которая обрабатывает геометрию в рамках распространенных графических API — комбинацию Mesh Shaders и Task Shaders, о которых мы писали в обзоре архитектуры Turing. В конечном счете, и NGG, и то, что сделала NVIDIA, преследуют одну и ту же цель — ускорить ранние стадии рендеринга, но достигают ее разными путями. NGG заменяет проблемные порции геометрического конвейера, свойственного Direct3D, на лету перекодируя старый тип шейдеров в новый — то есть, выполняет прежнюю работу более эффективно. Напротив, Mesh Shaders и Task Shaders позволяют расширить возможности рендеринга благодаря управляемой генерации геометрических деталей прямо на GPU силами шейдерных ALU (в отличие от грубой настройки параметров тесселятора). Mesh Shaders сейчас доступны через расширения к Direct3D 12 и Vulkan, но уже движутся к полноправной интеграции в интерфейс программирования Microsoft. Как знать, быть может инновации NVIDIA и нераскрытые возможности NGG в конце концов объединятся под зонтиком одной программной функции, что побудит разработчиков игр применять их более активно.
Драйвер Navi автоматически включает и тайловый рендеринг, появившийся в графических процессорах Vega, для того, чтобы сократить обращения к оперативной памяти и удержать данные, необходимые для растеризации и шейдеров, в пределах кеша L2.
Что касается упомянутых блоков ACE (Asynchronous Compute Engine), то и они научились новым трюкам. В RDNA доступна такая функция, как Asynchronous Compute Tunneling (ACT). Она оперирует на уровне очередей инструкций, которые драйвер видеокарты получает от графического API, — в отличие от preemption и других методов, работающих на уровне wavefront’ов и отдельных цепочек данных для векторных ALU (к примеру, Direct3D 12 поддерживает одну очередь для рендеринга и несколько для неграфических расчетов). Благодаря ACT графический процессор способен мгновенно приостановить прием дальнейших инструкций из очередей, имеющих низкий приоритет, ради того, чтобы закончить критически важную работу из другой очереди. Главной целью подобных оптимизаций, разумеется, является VR. Разработчики «железа» продолжают уделять шлемам виртуальной реальности повышенное внимание, несмотря на то, к какому плачевному состоянию сегодня пришла эта, когда-то перспективная, идея.

AMD наконец-то обратила должное внимание и на uncore-часть кристалла GPU, а именно блоки фиксированной функциональности, выполняющие кодирование и декодирование видео — UVD (Unified Video Decoder) и VCE (Video Coding Engine). Еще в чипах Polaris компания обещала внедрить аппаратную поддержку стандарта VP9, который используют для компрессии видео стриминговые сервисы — в первую очередь, YouTube. Но в действительности и все три поколения Polaris, и Vega, так и не научились декодировать VP9 без помощи шейдерных ALU — это все еще лучше, чем софтверная обработка на CPU, вот только браузеры «гибридное» декодирование VP9 поддерживают неохотно. Чип Navi 10, как и APU семейства Raven Ridge до него, умеет обрабатывать VP9 полностью в железе, а заодно AMD увеличила пропускную способность обоих компонентов видеодвижка — и на декодирование, и на кодирование потока. Radeon RX 5700 и RX 5700 XT обязаны декодировать видео трех основных стандартов (H.264, HEVC и VP9) при разрешении вплоть до 8К с кадровой частотой 24–30 FPS. Расчетное быстродействие при кодировании достигает 360 FPS в 1080p и 60–90 FPS в режиме 4К: в зависимости от стандарта — H.264 или HEVC.
В обновленном контроллере дисплея Navi реализованы дополнения к интерфейсам HDMI и DisplayPort, которых тоже не было в чипах Polaris и Vega. HDMI повысили с версии 2.0 до 2.0b, а это означает поддержку HDR. Выходы DisplayPort, в свою очередь, получили функцию DSC (Display Stream Compression) — это опциональный метод кодирования в стандарте 1.4, обеспечивающий сжатие данных без потери качества, заметной человеческому глазу. За счет DSC можно добиться трехкратного увеличения пропускной способности интерфейса, а значит подключать одним кабелем мониторы с таким разрешением и частотой смены кадров, для которых раньше был нужен двойной канал или цветовая субдискретизация (chroma subsampling), вызывающая неизбежное падение качества изображения. Интерфейсу DisplayPort 1.4 в сочетании с DSC 1.2a доступно разрешение 4К при частоте 120 Гц или 5К 60 Гц (и то, и другое — одновременно с HDR).
Разумеется, Navi поддерживает и технологию FreeSync 2 в комбинации с широким цветовым охватом и HDR — посредством DisplayPort или, в зависимости от доброй воли производителя телевизора, HDMI. В официальные спецификации HDMI адаптивную частоту обновления добавила версия 2.1, но первым GPU с таким интерфейсом Navi не стал, да и соответствующие телевизоры появились на рынке лишь полгода тому назад.

Однако все те нововведения, которые вобрал в себя чип Navi 10, не достались бесплатно с точки зрения компонентного бюджета. Старший Polaris при такой же конфигурации основных вычислительных блоков обходится скромными 5,7 млрд транзисторов, а для того, чтобы построить Navi 10, понадобилось уже 10,3 млрд — так много места занимает дополнительная управляющая логика и разбухшая система кешей. Неудивительно, что AMD оставит архитектуру GCN для ускорителей неграфических расчетов, ведь всю эту площадь можно попросту забить шейдерными ALU, которым GCN всегда найдет работу в GP-GPU. Для того чтобы эффективно задействовать ресурсы чипа в играх, с такими жертвами волей-неволей приходится мириться. Графические процессоры NVIDIA тоже набирали вес с каждым поколением, а ведь масштаб изменений в архитектуре RDNA можно сравнить одновременно с двумя крупнейшими переходами, которые совершил конкурент, — от Kepler к Maxwell и от Pascal к Turing.
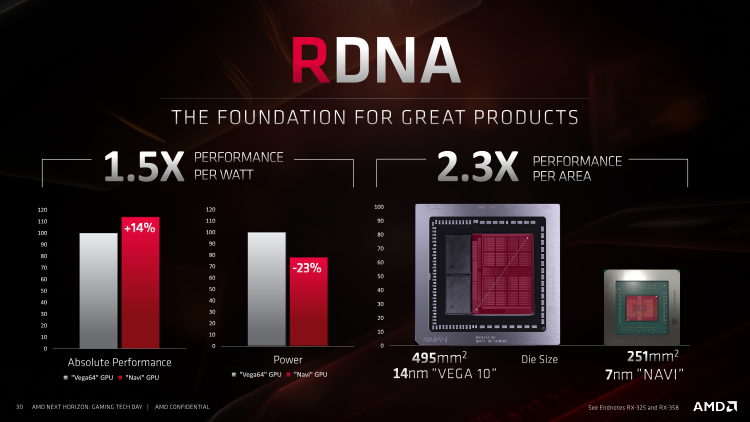
Во всяком случае, техпроцесс 7 нм позволяет упаковывать дополнительные транзисторы намного компактнее, чем при норме 14 нм. Площадь Navi 10 составляет 251 мм2 — немногим больше, чем у Polaris 10/20, а плотность компонентов возросла на 67 %. Куда важнее то, что в играх Navi 10 сулит повысить удельное быстродействие на площадь чипа в 2,3 раза по сравнению с Vega 10, а быстродействие на ватт — на 48 %. Если суммировать информацию из официальных слайдов, посвященных Navi, львиную долю выигранной мощности AMD относит именно на счет архитектуры RDNA, в то время как отдельно взятая смена технологической нормы с 14 на 7 нм дала только 11 %. Свой вклад в энергоэффективность внесла и схемотехника кристалла — в этой части команда Radeon позаимствовала лучшие методы у создателей Ryzen.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex












 Подписаться
Подписаться