|
Опрос
|
реклама
Быстрый переход
На грани авторского права: можно ли считать ИИ автором и как определить границы свободного использования
19.12.2024 [19:38],
Сергей Сурабекянц
С 5 по 8 декабря в Гостином дворе прошла Международная ярмарка интеллектуальной литературы non/fictioN №26. На круглом столе «Издательская деятельность, произведения изобразительного искусства и фотографические произведения: точки соприкосновения» речь шла о возможностях и подводных камнях свободного использования произведений, о разнице между переработкой оригинала и нарушением права на неприкосновенность и о регистрации авторских прав на продукцию ИИ. 
Источник изображения: non/fictioN Модератором встречи выступил Эрик Вальдес-Мартинес, директор «Ассоциации правообладателей по защите и управлению авторскими правами в сфере изобразительного искусства» (УПРАВИС) и член экспертного совета проекта Artists/ХУДОЖНИКИ.РФ, поддержанного Президентским фондом культурных инициатив. УПРАВИС занимается коллективным управлением исключительных прав фотографов, художников, скульпторов и других авторов произведений изобразительного искусства. 
Источник изображения: УПРАВИС Эрик Вальдес-Мартинес рассказал о двойственности и правовой неопределённости статьи 1276 Гражданского кодекса РФ, которая предусматривает свободное использование произведений архитектуры, градостроительства и фотографии, находящихся в местах, открытых для свободного посещения, если такое произведение не является основным объектом использования и не используется с целью извлечения прибыли. Например, фотография памятника, размещённая в путеводителе Екатеринбурга, была признана Верховным судом нарушением авторских прав, а Конституционный суд постановил, что фотография объекта не нарушает закон и не требует выплаты вознаграждения автору. Закон допускает использование произведений изобразительного искусства и фотографии для переработки. Если переделать часть фотографии, добавить к ней свой фон или произвести другие манипуляции, появляется новый объект права, созданный в результате переработки. При этом, как подчеркнул эксперт, правомерная переработка возможна только с разрешения автора оригинала или правообладателя. Если же взять часть фотографии и объединить её с другой, это нарушает неприкосновенность произведения — неимущественное право автора, которое не подлежит передаче. Неприкосновенность защищает изначальную форму произведения в том виде, в котором его создал автор. Нарушение этого права суд однозначно трактует как нарушение авторских прав. Не менее сложной остаётся ситуация с пародиями, создаваемыми без разрешения автора. По словам Вальдес-Мартинеса, «эта норма действует во всех странах мира, но важно, чтобы целью использования оригинала было именно создание пародийного эффекта». Суд может постановить, что мотивом создания «пародии» было желание заработать на популярности оригинального произведения, и признать это нарушением авторских прав. Говоря о возможности регистрации авторских прав на произведения, созданные ИИ, Вальдес-Мартинес подчеркнул, что официальная позиция большинства стран однозначно негативная. Например, Бюро по авторским правам США отозвало регистрацию прав на комикс «Рассветная заря» (Zarya of the Dawn) художницы Кристины Каштановой (Kristina Kashtanova), когда выяснилось, что иллюстрации были сгенерированы ИИ. 
Источник изображения: Kris Kashtanova Но не всё так просто: уже несколько лет учёный Стивен Талер (Stephen Thaler) создаёт свои изобретения при помощи созданной им ИИ-системы DABUS (Device for the autonomous bootstrapping of unified sentience — «Устройство автономной загрузки унифицированного сознания») и пытается зарегистрировать права в патентных офисах различных стран. Великобритания и США отклонили петиции Талера, но он добился успеха в таких странах, как Австралия и ЮАР. В ЮАР патентная система не предполагает экспертизы и там можно запатентовать даже колесо. В Австралии патентный суд решил, что DABUS может считаться автономным изобретателем, но все изобретения должны принадлежать Стивену Талеру. В июле 2024 года Федеральный верховный суд Германии постановил, что изобретение, созданное с помощью DABUS, может быть запатентовано, поскольку в качестве изобретателя был указан человек, хотя в заявке отмечено, что продукт был разработан ИИ. По мнению Вальдес-Мартинеса, «это переворачивает всё с ног на голову — если подобные решения будут становиться тенденцией, неизвестно, что нас ждёт». 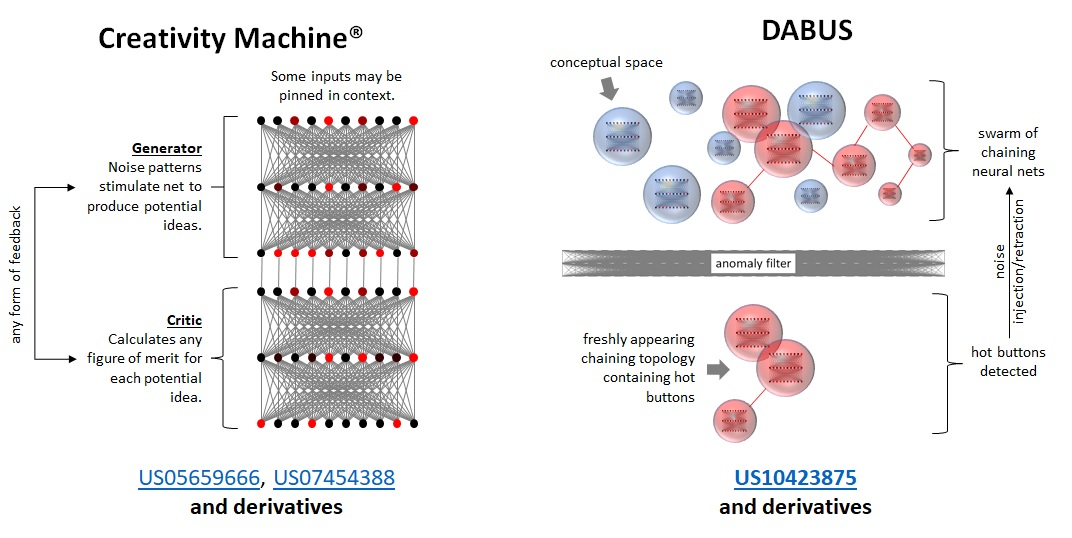
Источник изображения: DABUS Искусственный интеллект представляет угрозу не только в качестве потенциального «творца», но и в роли главного нарушителя авторских прав, по сравнению с которым все пиратские сайты и торрент-трекеры представляются просто малыми детишками. Активный сбор информации большими языковыми моделями из открытых источников уже давно нервирует правообладателей, а чувствительные к подобным проблемам средства массовой информации и вовсе при первой возможности пытаются защитить свои авторские права в суде. В августе группа художников, которая объединилась в коллективном иске против разработчиков наиболее популярных моделей искусственного интеллекта для генерации изображений, устроила празднование по случаю того, что судья дал ход этому делу и санкционировал раскрытие информации. 26 ноября бывший сотрудник OpenAI, 26-летний Сухир Баладжи (Suchir Balaji) был найден мёртвым в своей квартире в Сан-Франциско. Ранее Баладжи сообщил газете The New York Times, что OpenAI без разрешения использовала огромные объёмы интернет-данных для разработки ИИ-чат-бота ChatGPT, вышедшего в ноябре 2022 года. Он также обвинил компанию в создании собственного программного обеспечения для транскрибирования видео на YouTube для извлечения данных. В полиции заявили, что причиной его смерти стало самоубийство. Россия заняла третье место в мире по потреблению пиратского контента
16.12.2024 [12:05],
Дмитрий Федоров
Российские видеохостинги cтолкнулись с массовым распространением пиратского контента, особенно после ухода западных правообладателей. В результате Россия заняла третье место в мире по потреблению пиратского контента, уступив только США и Индии. 
Источник изображения: «VK Видео» На платформе «VK Видео» фиксируется ежемесячное удаление до 250 тыс. единиц пиратского контента, о чём сообщил технический директор бизнес-группы «Социальные платформы и медиаконтент» VK Сергей Ляджин. Ежемесячно платформа обрабатывает порядка 15 тыс. жалоб правообладателей, большинство из которых касается отечественного контента. Для автоматизации обработки обращений на «VK Видео» внедрена ИИ-система Content ID, использующая цифровые отпечатки видео- и аудиофайлов. Кроме того, правообладатели могут подавать запросы через форму DMCA. Другие крупные российские видеохостинги, такие как NUUM и RuTube, не предоставляют точных данных о количестве удалённого нелегального контента. Представители NUUM утверждают, что система обработки жалоб работает в штатном режиме, а материалы, нарушающие авторские права, удаляются в течение 24 часов. Однако, по словам участников медиарынка, именно на этих платформах наблюдается значительный рост объёма пиратских материалов после ухода из России западных правообладателей. Антипиратский меморандум, впервые подписанный 1 ноября 2018 года, был направлен на усиление борьбы с распространением нелегального видеоконтента в интернете. Документ обязывал правообладателей и интернет-платформы создавать реестры пиратских ресурсов и удалять ссылки на них из поисковой выдачи. Однако его эффективность снизилась, особенно после того как из меморандума вышли представители западных медиакомпаний, таких как Sony, Warner и Universal. В 2023 году меморандум был расширен за счёт включения книжной и музыкальной индустрий, но издательства отмечают, что результаты пока далеки от ожидаемых. Участники медиарынка полагают, что рост потребления пиратского контента в России был неизбежен после ухода западных правообладателей. Некоторые фильмы и сериалы появляются на пиратских платформах быстрее, чем на официальных площадках. При этом западные компании ограничиваются лишь уведомлением платформ о завершении сроков лицензий, что дополнительно усложняет борьбу с пиратством. По данным аналитических компаний MUSO и Kearney, Россия заняла третье место в мире по объёму трафика на пиратские ресурсы в 2023 году, уступив только США и Индии. На долю России пришлось 6 % мирового трафика на такие сайты. В целом по миру количество посещений пиратских ресурсов выросло на 10 % по сравнению с прошлым годом, что отражает глобальную тенденцию увеличения нелегального потребления контента. Проблема пиратского контента на российских видеохостингах является следствием как внешних, так и внутренних факторов. Для успешной борьбы с пиратством потребуется усиление законодательной базы, внедрение более продвинутых технологий контроля и активизация сотрудничества между платформами, правообладателями и государственными органами. Без этих шагов Россия рискует укрепить своё положение среди лидеров по нелегальному потреблению цифрового контента. Бывший сотрудник OpenAI, обвинявший компанию в нарушении авторских прав, найден мёртвым
14.12.2024 [12:45],
Владимир Мироненко
Бывший сотрудник OpenAI, 26-летний Сухир Баладжи (Suchir Balaji), 26 ноября был найден мёртвым в своей квартире в Сан-Франциско, сообщил ресурс TechCrunch. В полиции подтвердили личность Баладжи и заявили, что причиной его смерти стало самоубийство. В октябре в интервью The New York Times он выразил обеспокоенность по поводу нарушения OpenAI закона об авторском праве. 
Источник изображения: Levart_Photographer/unsplash.com Сухир Баладжи изучал информатику в Калифорнийском университете в Беркли. Во время учебы он стажировался в OpenAI и Scale AI. «Я проработал в OpenAI почти 4 года и последние 1,5 года работал над ChatGPT», — сообщил Баладжи в твите в октябре этого года. Баладжи рассказал, что заинтересовался вопросом защиты авторских прав, когда увидел все иски, поданные против компании GenAI. «Когда я попытался лучше разобраться в этом вопросе, я в конце концов пришёл к выводу, что добросовестное использование кажется довольно неправдоподобной защитой для многих продуктов генеративного ИИ по той простой причине, что они могут создавать заменители, которые конкурируют с данными, на которых они обучены», — сообщил он. Согласно описанию профиля в LinkedIn, первоначально Баладжи работал над WebGPT, доработанной версией GPT-3, которая могла осуществлять поиск в интернете. Это была ранняя версия SearchGPT, вышедшего в этом году. Впоследствии Баладжи работал в команде предварительного обучения GPT-4, а также в команде разработчиков ИИ-модели o1 со способностью рассуждать и команде постобучения ChatGPT. Баладжи сообщил газете The New York Times, что OpenAI без разрешения использовала огромные объёмы интернет-данных для разработки ИИ-чат-бота ChatGPT, вышедшего в ноябре 2022 года. Он также обвинил компанию в создании собственного программного обеспечения для транскрибирования видео на YouTube для извлечения данных. Из-за использования контента без разрешения со стороны издания, The New York Times подала в конце прошлого года на OpenAI и Microsoft в суд с обвинением в нарушении авторских прав. Трагическое происшествие с Баладжи привлекло дополнительное внимание к продолжающимся дебатам об этичном использовании данных при разработке технологий искусственного интеллекта. Apple и другие без разрешения обучали ИИ-модели на роликах YouTube
16.07.2024 [18:31],
Павел Котов
Несколько технологических гигантов, включая Apple, Anthropic, Nvidia и Salesforce, обучали свои модели искусственного интеллекта на видео с YouTube без согласия владеющей платформой компании Google и авторов этих видео, показало журналистское расследование Proof News. 
Источник изображения: Gerd Altmann / pixabay.com Предполагаемым нарушителем авторских прав оказалась некоммерческая организация EleutherAI, которая, по её собственному утверждению, помогает разработчикам в обучении моделей ИИ. Её целевой аудиторией является не технологические гиганты, а небольшие разработчики и учёные. EleutherAI выпустила массив данных Pile, значительная часть которого доступна и открыта для любого желающего в интернете — потребуются лишь ресурсы для их скачивания, хранения и обработки. В массив данных Pile оказались включены субтитры 173 536 видеороликов YouTube, которые были скачаны с более чем 48 000 каналов — файлы субтитров фактически являются расшифровками видеозаписей, а правила платформы YouTube запрещают скачивать её материалы без разрешения. Тем не менее, Apple, Nvidia и Salesforce — компании с капитализацией в сотни миллиардов и триллионы долларов — сами признавались в своих научных работах, что пользовались Pile при обучении ИИ. Apple, в частности, использовала Pile в обучении представленных в апреле моделей OpenELM, а уже в июне рассказала о новых функциях ИИ, которые появятся на iPhone и Mac. Если в ходе данного инцидента действительно было допущено нарушение авторского права, то сделала это в первую очередь некоммерческая организация EleutherAI, а технологические гиганты могли оказаться добросовестными пользователями общедоступного набора данных. Данный пример в очередной раз показывает, что сфера обучения ИИ до сих пор недостаточно отлажена с юридической позиции. YouTube научился удалять из видео защищённую авторским правом музыку с сохранением остального звука
05.07.2024 [16:33],
Павел Котов
Сервис YouTube выпустил обновлённый инструмент удаления музыки, защищённой авторским правом — функция основана на алгоритме искусственного интеллекта, который выполняет задачу, не затрагивая всего остального, в том числе диалогов и звуковых эффектов. 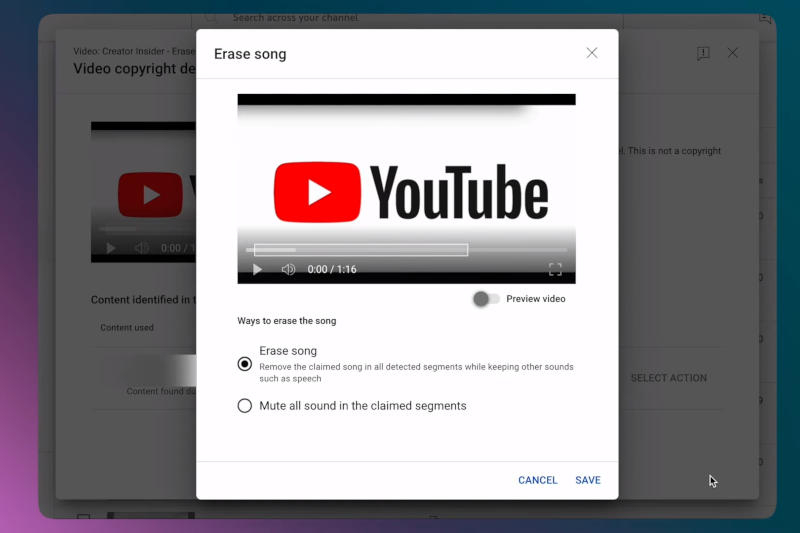
Источник изображения: youtube.com/@creatorinsider Гендиректор YouTube Нил Мохан (Neal Mohan) рассказал о нововведении в соцсети X: «Хорошие новости, авторы: наш обновлённый инструмент „Стереть песню“ (Erase Song) поможет вам легко удалить защищённую авторским правом музыку из вашего видео (оставив остальную часть аудио нетронутой)». Функция работает на основе алгоритма ИИ, который самостоятельно обнаруживает и удаляет композицию, не затрагивая остальной звук на ролике, предупредила администрация YouTube и добавила, что иногда алгоритм всё-таки даёт сбой и удаляет некоторые другие элементы аудио. «Это средство редактирования может не сработать, если песню сложно удалить. Если он не удаляет фрагмент аудио, вы можете попробовать другие варианты редактирования, например, отключить весь звук в указанных сегментах или вырезать эти сегменты», — говорится в анонсе новой функции. После успешного редактирования видео платформа снимает отметку идентификатора контента — системы, которая обнаруживает в загружаемых материалах защищённое авторским правом содержимое. Глава ИИ-подразделения Microsoft считает законным обучение ИИ на любом контенте, находящемся в открытом доступе
29.06.2024 [12:51],
Владимир Фетисов
Глава подразделения Microsoft AI Мустафа Сулейман (Mustafa Suleyman) считает, что как только что-либо публикуется в интернете, оно тут же становится бесплатным контентом, который каждый может скопировать и использовать по своему усмотрению. Об этом он заявил во время беседы с представителем канала CNBC.  «Я думаю, что в отношении контента, который уже находится в открытом интернете, общественный договор на этот контент с 90-х годов заключался в том, что он используется добросовестно. Любой может копировать его, воссоздавать, воспроизводить с его помощью. Это "свободное использование", если хотите, такое было понимание», — заявил Сулейман во время беседы с журналистом. В настоящее время Microsoft является ответчиком по многочисленным судебным искам, авторы которых уверены, что софтверный гигант и поддерживаемая им компания OpenAI незаконно используют защищённый авторским правом онлайн-контент для обучения генеративных нейросетей. На этом фоне заявление Сулеймана выглядит вполне логичным, но всё же было неожиданным, что он высказался по данному вопросу столь открыто. Однако высказывание относительно использования находящегося в интернете контента является ошибочным. Например, в США любое произведение автоматически защищается авторским правом, и публикация такого контента в интернете не аннулирует действие авторского права. В это же время добросовестное использование контента не гарантируется «общественным договором», а обеспечивается судом. Речь идёт о своеобразной юридической защите, когда по решению суда может быть разрешено использование авторского контента. YouTube пытается договориться со звукозаписывающими лейблами об ИИ-клонировании голосов артистов
27.06.2024 [18:17],
Сергей Сурабекянц
После дебюта в прошлом году инструментов генеративного ИИ, создающих музыку в стиле множества известных исполнителей, YouTube приняла решение платить Universal Music Group (UMG), Sony Music Entertainment и Warner Records паушальные взносы в обмен на лицензирование их песен для легального обучения своих инструментов ИИ. 
Источник изображения: Pixabay YouTube сообщила, что не планирует расширять возможности инструмента Dream Track, который на этапе тестирования поддерживали всего десять артистов, но подтвердила, что «ведёт переговоры с лейблами о других экспериментах». Платформа стремится лицензировать музыку исполнителей для обучения новых инструментов ИИ, которые YouTube планирует запустить позднее в этом году. Суммы, которые YouTube готова платить за лицензии, не разглашаются, но, скорее всего, это будут разовые (паушальные) платежи, а не соглашения, основанные на роялти. Информация о намерениях YouTube появились всего через несколько дней после того, как Ассоциация звукозаписывающей индустрии Америки (RIAA), представляющая такие звукозаписывающие компании, как Sony, Warner и Universal, подала отдельные иски о нарушении авторских прав против Suno и Udio — двух ведущих компаний в области создания музыки с использованием ИИ. По мнению RIAA, их продукция произведена с использованием «нелицензионного копирования звукозаписей в массовом масштабе». Ассоциация требует возмещения ущерба в размере до $150 000 за каждое нарушение. Недавно Sony Music предостерегла компании, занимающиеся ИИ, от «несанкционированного использования» её контента, а UMG была готова временно заблокировать весь свой музыкальный каталог в TikTok. Более 200 музыкантов в открытом письме призвали технологические компании прекратить использовать ИИ для «ущемления и обесценивания прав занимающихся творчеством людей». Sony пригрозила 700 компаниям судом за несанкционированное использование музыки для обучения ИИ
17.05.2024 [19:54],
Сергей Сурабекянц
Sony Music Group разослала предупреждения более чем 700 технологическим компаниям и службам потоковой передачи музыки о недопустимости использования защищённого авторским правом аудиоконтента для обучения ИИ без явного разрешения. Компания признает «значительный потенциал» ИИ, но «несанкционированное использование контента в обучении, разработке или коммерциализации систем ИИ» лишает её и её артистов контроля и «соответствующей компенсации». 
Источник изображения: Pixabay В части разосланных писем Sony Music прямо утверждает, что имеет «основания полагать», что получатели письма «возможно, уже совершили несанкционированное использование» принадлежащего компании музыкального контента. В портфолио Sony Music — множество известных артистов, среди них Harry Styles, Beyonce, Adele и Celine Dion. Компания стремится защитить свою интеллектуальную собственность, включая аудио- и аудиовизуальные записи, обложки, метаданные и тексты песен. Компания не раскрыла список адресатов, получивших «письма счастья». «Мы поддерживаем артистов и авторов песен, которые берут на себя инициативу по использованию новых технологий в поддержку своего искусства, — говорится в заявлении Sony Music. — Эволюция технологий часто меняла курс творческих индустрий. ИИ, скорее всего, продолжит эту давнюю тенденцию. Однако это нововведение должно гарантировать уважение прав авторов песен и записывающихся исполнителей, включая авторские права». Получателям в указанный в письме срок предлагается подробно описать, какие песни Sony Music использовались для обучения систем ИИ, как был получен доступ к песням, сколько копий было сделано, а также почему копии вообще существовали. Sony Music подчеркнула, что будет обеспечивать соблюдение своих авторских прав «в максимальной степени, разрешённой применимым законодательством во всех юрисдикциях». Нарушение авторских прав становится серьёзной проблемой по мере развития генеративного ИИ, уже сейчас потоковые сервисы, подобные Spotify, наводнены музыкой, созданной искусственным интеллектом. В прошлом месяце в США был опубликован проект закона, который, в случае его принятия, заставит компании раскрывать, какие песни, защищённые авторским правом, они использовали для обучения ИИ. В марте 2024 года Теннесси стал первым штатом США, который принял юридические меры для защиты артистов, после того как губернатор Билл Ли (Bill Lee) подписал «Закон об обеспечении безопасности голоса и изображений» (Ensuring Likeness Voice and Image Security, ELVIS). Билли Айлиш и сотни музыкантов попросили защиты от неправомерного применения ИИ в музыке
03.04.2024 [17:08],
Дмитрий Федоров
Более 200 известных музыкантов и владельцев авторских прав подписали открытое письмо, которое было опубликовано правозащитной группой Artist Rights Alliance. В нём они выразили серьёзную обеспокоенность неправомерным использованием искусственного интеллекта в музыке, призывая к немедленному регулированию этой области с целью предотвращения потенциального ущерба их творчеству и культурному наследию. 
Источник изображения: artistrightsnow.medium.com В числе подписавшихся — звёзды мировой музыки и наследники прав на творения легендарных исполнителей: Стиви Уандер (Stevie Wonder), Смоки Робинсон (Smokey Robinson), Билли Айлиш (Billie Eilish), Джон Бон Джови (Jon Bon Jovi), Кэти Перри (Katy Perry), группы REM и Pearl Jam, а также представители наследия Боба Марли (Bob Marley) и Фрэнка Синатры (Frank Sinatra). Такое многообразие жанров и поколений иллюстрирует общую обеспокоенность влиянием ИИ на музыкальное искусство. Открытое письмо поднимает вопрос о двойственной природе ИИ: с одной стороны, его потенциал для расширения границ творчества в музыкальной индустрии неоспорим, с другой — существует риск его неправомерного использования, когда технологии подрывают уникальность и ценность авторского труда. Проблема касается инструментов, разработанных технологическими гигантами. Эти инновации вызывают волну споров о нарушении авторских прав и риски судебных разбирательств. Письмо акцентирует внимание на том, что неконтролируемое применение ИИ ставит под угрозу не только авторское право, но и личную идентичность артистов, их творческую уникальность и финансовую независимость. Авторы призывают к ответственному использованию технологий, подчёркивая безразличие крупных компаний к их правам. Губернатор штата Теннесси Билл Ли (Bill Lee) выступил в поддержку музыкантов, приняв законопроект, направленный на защиту авторов от неправомерного использования их творчества компаниями, занимающимися разработкой ИИ. Закон, получивший название «Закон Элвиса» (Elvis Act), призван защитить уникальность и интеллектуальную собственность артистов. Особое внимание уделяется инструментам, способным генерировать тексты песен, имитируя стили различных авторов. Примером служит реакция австралийского исполнителя Ника Кейва (Nick Cave) на сборник его собственных текстов, созданных с помощью ChatGPT, который назвал «гротескной карикатурой на человечность». Не все воспринимают подобные инновации негативно. Люсиан Грейндж (Lucian Grainge), глава Universal Music Group, высказал мнение о необходимости поиска компромиссов, совместной работы ИИ и музыкантов над созданием будущего, где технологии и творчество будут дополнять друг друга. В исках NeMo: писатели обвинили Nvidia в незаконном использовании произведений для обучения нейросети
11.03.2024 [11:30],
Алексей Разин
В минувшую пятницу Федеральный суд Сан-Франциско принял к рассмотрению групповой иск к Nvidia от троих авторов литературных произведений, которые обвиняют компанию в неправомерном использовании своих трудов для обучения системы искусственного интеллекта NeMo созданию текстов на английском языке. 
Источник изображения: Nvidia Представители истцов сообщают, что Nvidia использовала выборку из 196 640 литературных произведений для обучения своей платформы NeMo с целью дальнейшей генерации текстов на английском языке силами системы искусственного интеллекта. Авторы книг упрекают компанию в использовании их произведений без разрешения. Иск подан от имени трёх авторов: Брайана Кина (Brian Keene), Абди Наземяна (Abdi Nazemian) и Стюарта О’Нэна (Stewart O’Nan), которые уличили Nvidia в использовании текстов их романов и новелл различных лет публикации без согласования с правообладателями. Сумма ущерба, которую пытаются взыскать истцы, не уточняется, но групповой характер иска подразумевает, что к претензиям могут присоединиться и прочие авторы из упоминаемой выборки, которую Nvidia использовала для обучения своей большой языковой модели. Это уже не первый иск такого рода, с которым приходится сталкиваться Nvidia, ранее компанию обвинило в неправомерном использовании своих материалов издание The New York Times. Аналогичные мотивы уже заставили некоторые организации обратиться в суд с иском не только на создавшую ChatGPT компанию OpenAI, но и финансирующую её Microsoft. Все ведущие большие языковые модели ИИ нарушают авторские права, а GPT-4 — больше всех
06.03.2024 [18:36],
Сергей Сурабекянц
Компания по изучению ИИ Patronus AI, основанная бывшими сотрудниками Meta✴, исследовала, как часто ведущие большие языковые модели (LLM) создают контент, нарушающий авторские права. Компания протестировала GPT-4 от OpenAI, Claude 2 от Anthropic, Llama 2 от Meta✴ и Mixtral от Mistral AI, сравнивая ответы моделей с текстами из популярных книг. «Лидером» стала модель GPT-4, которая в среднем на 44 % запросов выдавала текст, защищённый авторским правом. 
Источник изображений: Pixabay Одновременно с выпуском своего нового инструмента CopyrightCatcher компания Patronus AI опубликовала результаты теста, призванного продемонстрировать, как часто четыре ведущие модели ИИ отвечают на запросы пользователей, используя текст, защищённый авторским правом. Согласно исследованию, опубликованному Patronus AI, ни одна из популярных книг не застрахована от нарушения авторских прав со стороны ведущих моделей ИИ. «Мы обнаружили контент, защищённый авторским правом, во всех моделях, которые оценивали, как с открытым, так и закрытым исходным кодом», — сообщила Ребекка Цянь (Rebecca Qian), соучредитель и технический директор Patronus AI. Она отметила, что GPT-4 от OpenAI, возможно самая мощная и популярная модель, создаёт контент, защищённый авторским правом, в ответ на 44 % запросов. Patronus тестировала модели ИИ с использованием книг, защищённых авторскими правами в США, выбирая популярные названия из каталога Goodreads. Исследователи разработали 100 различных подсказок, которые можно счесть провокационными. В частности, они спрашивали модели о содержании первого абзаца книги и просили продолжить текст после цитаты из романа. Также модели должны были дополнять текст книг по их названию. Модель GPT-4 показала худшие результаты с точки зрения воспроизведения контента, защищённого авторским правом, и оказалась «менее осторожной», чем другие. На просьбу продолжить текст она в 60 % случаев выдавала целиком отрывки из книги, а первый абзац книги выводила в ответ на каждый четвёртый запрос. Claude 2 от Anthropic оказалось труднее обмануть — когда её просили продолжить текст, она выдавала контент, защищённый авторским правом, лишь в 16 % случаев, и ни разу не вернула в качестве ответа отрывок из начала книги. При этом Claude 2 сообщала исследователям, что является ИИ-помощником, не имеющим доступа к книгам, защищённым авторским правом, но в некоторых случаях всё же предоставила начальные строки романа или краткое изложение начала книги. Модель Mixtral от Mistral продолжала первый абзац книги в 38 % случаев, но только в 6 % случаев она продолжила фразу запроса отрывком из книги. Llama 2 от Meta✴ ответила контентом, защищённым авторским правом, на 10 % запросов первого абзаца и на 10 % запросов на завершение фразы. 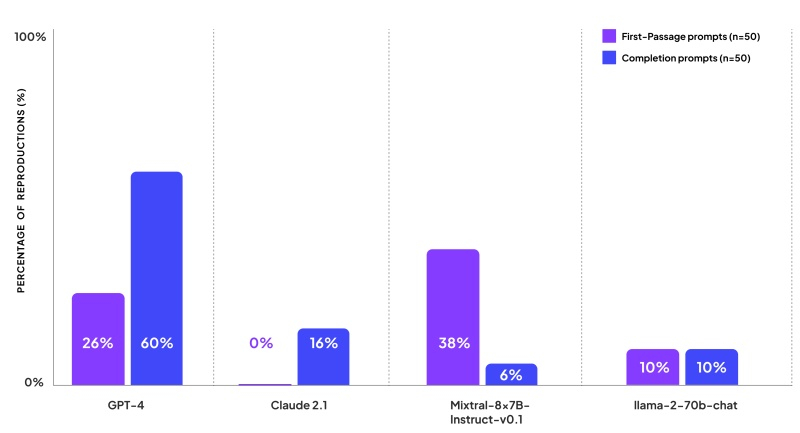
Источник изображения: Patronus AI «В целом, тот факт, что все языковые модели дословно создают контент, защищённый авторским правом, был действительно удивительным, — заявил Ананд Каннаппан (Anand Kannappan), соучредитель и генеральный директор Patronus AI, раньше работавший в Meta✴ Reality Labs. — Я думаю, когда мы впервые начали собирать это вместе, мы не осознавали, что будет относительно просто создать такой дословный контент». Результаты исследования наиболее актуальны на фоне обострения отношений между создателями моделей ИИ и издателями, авторами и художниками из-за использования материалов, защищённых авторским правом, для обучения LLM. Достаточно вспомнить громкий судебный процесс между The New York Times и OpenAI, который некоторые аналитики считают переломным моментом для отрасли. Многомиллиардный иск новостного агентства, поданный в декабре, требует привлечь Microsoft и OpenAI к ответственности за систематическое нарушение авторских прав издания при обучении моделей ИИ.  Позиция OpenAI заключается в том, что «поскольку авторское право сегодня распространяется практически на все виды человеческого выражения, включая сообщения в блогах, фотографии, сообщения на форумах, фрагменты программного кода и правительственные документы, было бы невозможно обучать сегодняшние ведущие модели ИИ без использования материалов, защищённых авторским правом». По мнению OpenAI, ограничение обучающих данных созданными более века назад книгами и рисунками, являющимися общественным достоянием, может стать интересным экспериментом, но не обеспечит системы ИИ, отвечающие потребностям настоящего и будущего. В ответ на обвинения в воровстве контента OpenAI обвинила New York Times во взломе ChatGPT
28.02.2024 [21:13],
Сергей Сурабекянц
OpenAI заявила в суде, что New York Times (NYT) «заплатила кому-то за взлом продуктов OpenAI», таких как ChatGPT, чтобы получить доказательства для подачи иска против OpenAI о нарушении авторских прав. OpenAI считает, что более ста примеров, в которых модель GPT-4 генерирует контент Times в качестве выходных данных не отражают обычного использования ChatGPT, а представляют собой «надуманные атаки наёмника», который добивался от чат-бота генерации фальшивого контента NYT. 
Источник изображения: pexels.com OpenAI обвинила NYT в «десятках тысяч попыток» получить эти «крайне аномальные результаты», «выявив и воспользовавшись ошибкой», которую сама OpenAI «стремится устранить». NYT якобы организовала эти атаки, чтобы собрать доказательства в поддержку утверждения, что продукты OpenAI ставят под угрозу журналистику, копируя авторские материалы и репортажи и тем самым отбирая аудиторию у NYT. «Вопреки утверждениям [содержащимся в жалобе NYT], ChatGPT никоим образом не заменяет подписку на The New York Times, — заявила OpenAI в ходатайстве, направленном на отклонение большинства претензий NYT. — В реальном мире люди не используют ChatGPT или любой другой продукт OpenAI для этой цели. И не могут. В обычном мире невозможно использовать ChatGPT для предоставления статей Times по своему желанию». 
Источник изображений: unsplash.com OpenAI отметила, что примеры в иске NYT цитируют не текущие материалы, которые подписчики Times могут прочитать на сайте Times, а гораздо более старые статьи, опубликованные до 2022 года. Это дополнительно ослабляет заявление NYT о том, что ChatGPT можно рассматривать как замену изданию. «То, что OpenAI ошибочно называет "хакерством", — это просто использование продуктов OpenAI для поиска доказательств воровства и воспроизведения материалов NYT, защищённых авторским правом. И это именно то, что мы нашли. На самом деле масштаб копирования OpenAI гораздо больше, чем сто примеров, изложенных в жалобе», — парировали адвокаты NYT. Юристы NYT сделали акцент на том, что OpenAI «не оспаривает и не может оспорить того, что они скопировали миллионы работ для создания и поддержки своих коммерческих продуктов без нашего разрешения». Позиция издания заключается в том, что создание новых продуктов не является оправданием для нарушения закона об авторском праве, и это именно то, что OpenAI сделала в беспрецедентных масштабах.  OpenAI заявила, что NYT в течение многих лет с энтузиазмом разрабатывала собственных чат-ботов, не опасаясь нарушения ими авторских прав. OpenAI сообщала об использовании статей NYT для обучения своих моделей ИИ ещё в 2020 году, но NYT обеспокоилась только после резко возросшей популярности ChatGPT в 2023 году. После этого NYT обвинила OpenAI в нарушении авторских прав и потребовала «коммерческих условий», а после нескольких месяцев обсуждений подала многомиллиардный иск. OpenAI убеждает суд, что ему следует отклонить иски, направленные на защиту прямого авторского права в цифровую эпоху и игнорировать обвинения в незаконном присвоении, которые компания называет «юридически недействительными». У некоторых жалоб истёк срок давности, другие, по утверждению OpenAI, неправильно трактуют добросовестное использование или искажают требования федеральных законов. Если это ходатайство OpenAI будет удовлетворено, в иске NYT останутся только претензии о косвенном нарушении авторских прав и размывании товарного знака. Но если NYT победит в суде (а вероятность этого не так уж мала), OpenAI, возможно, придётся буквально «стереть» ChatGPT и заново начать обучение моделей.  OpenAI утверждает, что NYT использовала вводящие в заблуждение подсказки, чтобы вынудить ChatGPT раскрыть обучающие данные. The Times якобы просила у чат-бота предоставить вступительный абзац конкретной статьи, а затем запрашивала «следующее предложение». Но даже эта тактика не поможет воссоздать статью целиком, а скорее выведет набор «разрозненных и неупорядоченных цитат». OpenAI считает, что NYT намеренно вводит суд в заблуждение, используя купюры и многоточие, чтобы скрыть порядок, в котором ChatGPT выдавал фрагменты репортажей, что создаёт ложное впечатление, что ChatGPT выводит последовательные и непрерывные копии статей.  OpenAI также отвергла примеры галлюцинаций ИИ предоставленных NYT, где модели ИИ изобретали на первый взгляд реалистичные статьи, которые содержали неверные факты и никогда не публиковались изданием. Поскольку ни одна из ссылок в этих фиктивных статьях не работала, OpenAI считает, что «любой пользователь, получивший такие выходные данные, сразу же распознает в них галлюцинацию». OpenAI планирует исправить ошибки ИИ, но это будет возможно сделать только в случае победы в суде. OpenAI необходимо убедить суды во многих юрисдикциях в своей теории добросовестного использования текстов, защищённых авторским правом, что имеет решающее значение для развития её моделей ИИ. «Постоянная задача разработки ИИ — свести к минимуму и в конечном итоге устранить галлюцинации, в том числе за счёт использования более полных наборов обучающих данных для улучшения точности моделей», — заявили в OpenAI. Адвокаты NYT полагают, что для OpenAI «незаконное копирование и дезинформация являются основными особенностями их продуктов, а не результатом маргинального поведения». По их словам, OpenAI «отслеживает запросы и результаты пользователей, что особенно удивительно, учитывая, что они утверждали, что не делают этого. Мы с нетерпением ждём возможности изучить эту проблему».  Разработчики больших языковых моделей всё чаще прибегают к лицензированию вместо обучения на общедоступных данных, чтобы избежать возможных обвинений в нарушении авторских прав. «Разработка технологий в соответствии с установленными законами об авторском праве является общеотраслевым приоритетом, — считает ведущий советник NYT Ян Кросби (Ian Crosby). — Решение OpenAI и других разработчиков генеративного ИИ заключать сделки с издателями новостей только подтверждает, что они знают, что их несанкционированное использование работ, защищённых авторским правом, далеко не справедливо». Гильдия актёров США заключила соглашение, по которому для озвучки игр можно использовать синтезированные ИИ голоса
11.01.2024 [07:52],
Алексей Разин
Одна из возможностей, которую открыли человечеству системы искусственного интеллекта — это исполнение любой песни или озвучание любого персонажа голосом известного артиста без его ведома и участия. Само собой, подобная практика быстро насторожила профессиональные объединения актёров и музыкальных исполнителей, которые привыкли получать доходы от использования своего голоса. На днях в этой сфере была заключена необычная сделка. 
Источник изображения: Unsplash, Jacek Dylag По данным CNet, на выставке CES 2024 в Лас-Вегасе крупнейший мировой профсоюз в данной сфере SAG-AFTRA (Гильдия киноактеров и Американская федерация артистов телевидения и радио) объявил о достижении соглашения с компанией Replica Studios, которая использует технологии искусственного интеллекта для имитации голоса актёров и музыкальных исполнителей. По условиям сделки, члены SAG-AFTRA смогут работать с Replica Studios, чтобы лицензировать свой голос для игровых студий. Таким образом, впервые в этой сфере подобная практика закрепляется официальным соглашением юридически. В прошлом году в США проходила длительная забастовка представителей кино- и телевизионной индустрии, которые протестовали против использования искусственного интеллекта для написания сценариев и использования цифровых двойников актёров в этой сфере. В результате этих протестов было принято положение, согласно которому студии должны спрашивать разрешение у актёров на использование «цифровых дубликатов» их внешности и платить им за это. SAG-AFTRA объединяет более 160 000 актёров, музыкантов и певцов, поэтому интересы многих представителей отрасли будут учитываться в рамках соглашения с Replica Studios. Дункан Крэбтри-Иреланд (Duncan Crabtree-Ireland), главный переговорщик от профсоюза, заявил, что соглашение «открывает путь для профессиональных артистов озвучивания к новым возможностям трудоустройства их цифровых голосовых реплик». В соглашении есть положения о минимальных расценках, безопасном хранении и требованиях к обозначению сгенерированного контента, а также «ограничения по количеству времени, в течение которого реплика может быть использована без дополнительной оплаты и согласия». При этом представитель профсоюза отметил, что соглашение не распространяется на использование голосов артистов для обучения больших языковых моделей Однако полностью проблему незаконного использования голосов артистов новое соглашение не решит. Оно никак не запрещает частным создателям контента использовать имитацию голоса известного артиста в своих произведениях. Что характерно, ещё в январе прошлого года звукозаписывающие студии были убеждены, что им не нужно разрешение артистов на использование цифровых реплик их голосов. За прошедший год настроение представителей отрасли изменилось, о чём свидетельствует заключённое на CES 2024 соглашение. Хотя это соглашение касается именно видеоигр, Крэбтри-Иреланд говорит, что могут быть достигнуты и другие соглашения по другим видам деятельности, например, в музыке и телевизионной рекламе. Также в подобном соглашении могут быть заинтересованы правообладатели, которым достались права на произведения покойных артистов, и они хотели бы претендовать на выплаты со стороны студий, использующих копии голоса покойных исполнителей в своих произведениях. OpenAI признала использование авторских материалов без разрешения владельцев, но есть нюанс
10.01.2024 [11:13],
Дмитрий Федоров
В своём недавнем обращении к Комитету Палаты лордов парламента Великобритании по вопросам коммуникаций и цифровых технологий (Communications and Digital Committee) компания OpenAI, разработчик чат-бота ChatGPT, подчеркнула неизбежность использования защищённых авторским правом материалов в процессе создания эффективных ИИ-моделей. На первый взгляд, кажется, что использование материалов без разрешения владельца противоречит основам защиты интеллектуальной собственности, но позиция OpenAI основана на сложных юридических и технических нюансах. 
Источник изображения: sergeitokmakov / Pixabay По мнению OpenAI, ограничение исходных данных для обучения ИИ-моделей исключительно произведениями, являющимися общественным достоянием и созданными более ста лет назад, значительно сокращает возможности интеллектуальных систем. Современный ИИ наподобие ChatGPT требует доступа к широкому спектру человеческих выражений — от блогов и фотографий до форумных сообщений и фрагментов программного кода. Такой подход не только способствует обучению ИИ пониманию разнообразных форм коммуникации, но и обеспечивает его актуальность в условиях стремительно меняющегося цифрового мира. В центре защиты OpenAI лежит принцип добросовестного использования, который, согласно заявлениям компании, допускает ограниченное использование авторских материалов без согласия владельцев. Этот юридический принцип, имеющий глубокие корни в американском законодательстве, предоставляет определённый простор для инноваций и исследований. OpenAI уверяет, что её методы обучения ИИ соответствуют этому принципу, подчёркивая, что такой подход не только справедлив по отношению к авторам, но и критически важен для поддержания конкурентоспособности США в области высоких технологий. Причиной этого заявления OpenAI послужил иск, поданный The New York Times. В нём газета обвинила OpenAI и Microsoft, одного из ключевых инвесторов OpenAI, в незаконном использовании своих новостных материалов для обучения ИИ-моделей. В ответ на эти обвинения OpenAI заявила, что иск не имеет под собой оснований. Компания также выразила свою поддержку журналистике и стремление к сотрудничеству с новостными ресурсами, подчеркнув свою приверженность этическим принципам в разработке ИИ. Это не первый случай, когда OpenAI сталкивается с подобными обвинениями. Ранее компания уже защищала своё право на использование общедоступных материалов в рамках принципа добросовестного использования в ответ на судебный иск, связанный с мемуарами Сары Сильверман (Sarah Silverman). В то время OpenAI заявляла, что критики ошибочно трактуют сферу действия авторских прав, не учитывая законных исключений и ограничений, которые допускают инновации вроде разработки передовых ИИ-моделей. Писатели обвинили OpenAI и Microsoft в краже интеллектуальной собственности для обучения ИИ
07.01.2024 [10:46],
Дмитрий Федоров
Писатели Николас Басбейнс (Nicholas Basbanes) и Николас Гейдж (Nicholas Gage) подали иск в Манхэттенский федеральный суд против Microsoft и OpenAI. Они обвиняют компании в использовании их литературных произведений без согласия авторов для обучения ИИ-моделей, включая семейство GPT. 
Источник изображения: Daniel_B_photos / Pixabay В новом коллективном иске, поданном в пятницу, упоминаются Microsoft и OpenAI — компании, стоящие за разработкой передовых ИИ-моделей. Писатели заявляют, что их произведения были незаконно использованы для обучения ИИ-моделей, ставших основой бизнес-империи, оцениваемой в миллиарды долларов. Также писатели утверждают, что Microsoft и OpenAI занимались массовым и преднамеренным воровством произведений, защищённых авторским правом. Это новый этап в ряде судебных исков, поданных в ноябре прошлого года. Тогда писатель Джулиан Сэнктон (Julian Sancton) стал первым, кто подал иск сразу против обеих компаний. В нём указывалось, что Microsoft является крупным инвестором OpenAI и использует технологии последней для своего продукта Copilot, что подчёркивает взаимосвязанность обеих технологических компаний. Газета The New York Times также недавно подала судебный иск против Microsoft и OpenAI, утверждая, что её новостные материалы использовались для обучения ИИ-моделей без разрешения или какой-либо компенсации. По словам издания, ИИ-инструменты могут генерировать тексты, которые дословно повторяют, тщательно обобщают и даже имитируют выразительный стиль её материалов. Несмотря на возрастающую волну исков, не все новостные издания выступают против того, чтобы их материалы использовались для обучения ИИ. Например, Associated Press предоставила OpenAI доступ к своим новостным материалам на ближайшие два года для обучения ИИ-моделей, а Politico и Business Insider также заключили с компанией сделки на использование контента с их сайтов для обучения ИИ. Эти судебные иски отражают глубокую проблематику баланса между инновациями и уважением к авторским правам. Они выявляют необходимость чётких правил и этических стандартов в использовании интеллектуальной собственности для развития передовых технологий. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться