|
Опрос
|
реклама
Быстрый переход
Чат-бот Grok от xAI Илона Маска обзавёлся генератором фотореалистичных изображений
08.12.2024 [06:24],
Алексей Разин
Концентрация нескольких динамично развивающихся компаний в руках Илона Маска (Elon Musk) приводит к их взаимной интеграции, а чат-бот Grok уже давно доступен подписчикам социальной сети X, а вчера он добрался и до бесплатных пользователей. Функциональность первого недавно дополнилась новым генератором изображений Aurora, который способен создавать фотореалистичные изображения, пусть и не лишённые недостатков. 
Источник изображения: X, EnsoMatt Бета-версия генератора изображений Aurora, как отмечает TechCrunch, стала доступна пользователям социальной сети X на вкладке Grok вчера. Доступ к этим возможностям не требует подписки, но имеет ограничения в бесплатном варианте. В частности, без подписки нельзя направить чат-боту Grok более 10 запросов за два часа, а количество генерируемых Aurora изображений ограничено тремя штуками в день. Кстати, некоторые пользователи X уже успели обнаружить, что лишены доступа к Aurora. Официально этот генератор изображений находится в бета-версии. Это уже второй генератор изображений для Grok компании xAI. Если в случае с первым, Flux, стартап Илона Маска сотрудничал с другими разработчиками, то история происхождения второго, Aurora, пока не раскрывается. По крайней мере, представители xAI только успели заявить, что принимали участие в настройке данной системы. Пользователи социальной сети X начали выкладывать образцы сгенерированных Aurora изображений, на одном из них можно лицезреть Адама Сэндлера (Adam Sandler) и его партнёра по сериалу Рэя Романо (Ray Romano), и если лица актёров на сгенерированных изображениях оказались похожими на настоящие, то с пальцами рук у генератора изображений возникли традиционные проблемы. Как отмечается, пейзажи и натюрморты у Aurora получаются гораздо лучше, но и там не обходится без дефектов. Китайская Tencent представила генератор видео HunyuanVideo, который пользователи назвали лучшим из существующих
05.12.2024 [10:57],
Павел Котов
Китайский технологический гигант Tencent анонсировал HunyuanVideo — передовую модель искусственного интеллекта для генерации видео, опубликованную с открытым исходным кодом. Впервые код вывода и веса модели ИИ с такими возможностями доступны всем желающим. 
Источник изображения: Tencent HunyuanVideo, как утверждает Tencent, способна генерировать видеоролики на уровне ведущих мировых систем с закрытым исходным кодом — эти видео отличают высокое качество картинки, разнообразие движений объектов в кадре, способность синхронизировать визуальный и звуковой ряд, а также стабильность генерации. Это крупнейшая модель для генерации видео — у неё 13 млрд параметров. Пакет HunyuanVideo включает в себя фреймворк с инструментами для управления данными; инструментами для совместного обучения моделей, работающих с изображениями и видео; а также инфраструктуру с поддержкой крупномасштабного обучения моделей и их запуска. Tencent протестировала модель при поддержке профессионального сообщества, которое установило, что HunyuanVideo превосходит по качеству закрытые проекты Runway Gen-3 и Luma 1.6. Чтобы добиться такого результата, разработчик обратился к гибридной архитектуре передачи «двойного потока в одинарный» (Dual-stream to Single-stream). На начальном этапе видео- и текстовые токены обрабатываются независимо несколькими блоками модели-трансформера, благодаря чему данные разных форматов преобразуются без помех. На этапе единого потока видео- и текстовые токены передаются в последующие блоки трансформера, обеспечивая эффективное слияние мультимодальных данных. Это позволяет зафиксировать сложные отношения между визуальной и семантической информацией, а общая производительность модели повышается. Выпустив HunyuanVideo, компания Tencent сделала значительный шаг к демократизации технологий создания видео при помощи ИИ. Благодаря открытому исходному коду модель способна произвести революцию в экосистеме генерации видео. «Ростех» импортозаместил один из важных элементов электроники, радиостанций и навигаторов
24.11.2024 [22:15],
Владимир Фетисов
Холдинг «Росэлектроника», являющийся частью госкорпорации «Ростех», создал линейку высокостабильных кварцевых генераторов, которые позволят заменить американские и немецкие аналоги в составе вычислительной техники, радиостанций, навигационных приёмников ГЛОНАСС-GPS. В настоящее время реализуется этап освоения серийного производства новых электронных компонентов. 
Источник изображения: «Ростех» Напомним, кварцевый генератор используется для синхронизации работы разных функциональных узлов электронных устройств. Он является одним из важнейших компонентов цифровой электроники, поскольку от его сигнала зависит стабильная работа всего прибора. Линейка новых изделий завода «Метеор», входящего в состав «Росэлектроники», включает в себя термокомпенсированные и тактовые кварцевые генераторы. Термокомпенсированные генераторы обеспечивают стабильную и точную опорную частоту при рабочей температуре от -40 °C до +85 °C. Такие устройства предназначены для поверхностного монтажа, имеют размеры 3,2 × 2,5 мм и обладают высокой механической прочностью. Всё это позволяет использовать такие генераторы в составе мобильных и стационарных устройств разного назначения. Также были созданы три модификации тактовых кварцевых генераторов разного размера. Они предназначены для стабилизации тактового сигнала в составе всех видов цифровой электроники. Гендиректор завода «Метеор» Юрий Валов рассказал, что основные тенденции развития компонентной базы, включая устройства стабилизации частоты, связаны с улучшением их эксплуатационных характеристик и уменьшением размеров. Он также добавил, что характеристики разработанных предприятием кварцевых генераторов не уступают характеристикам зарубежных аналогов, которые выпускаются компаниями из США и Германии. Google предложила помощь ИИ в создании клипартов для документов
16.11.2024 [12:22],
Павел Котов
На платформе Google Workspace появился генератор изображений на основе искусственного интеллекта Gemini прямо в приложении «Google Документы» — он позволяет быстро создавать иллюстрации к текстам. По сути, это генератор клипартов, схожий с аналогичной функцией в офисном пакете Microsoft. 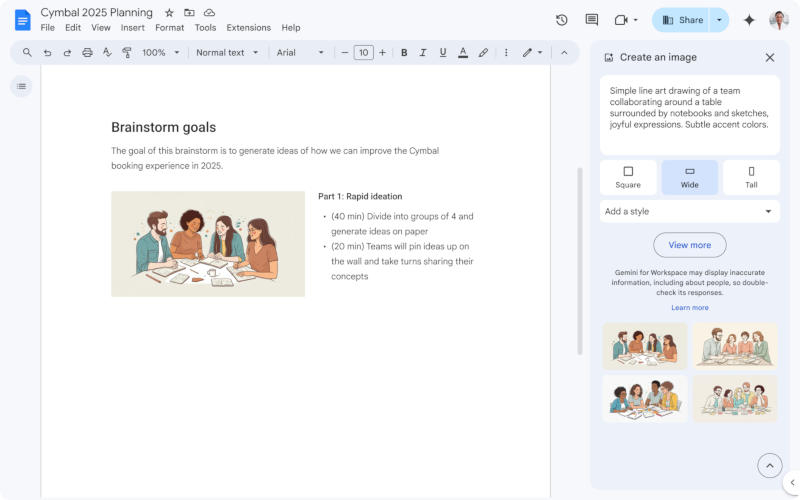
Источник изображения: workspaceupdates.googleblog.com Генератор изображений для «Google Документов» доступен для обладателей платных учётных записей Workspace, в том числе Gemini Business, Enterprise, Education, Education Premium и Google One AI Premium. Те, у кого новая функция уже заработала, могут открыть её через меню «Вставка», в котором требуется последовательно выбрать пункты «Изображение» и «Помогите мне создать изображение». Появляется боковая панель, на которой можно ввести описание требуемой иллюстрации; на ней же есть выпадающий список художественных стилей — например, «Фотография» или «Эскиз». Изображение будет квадратным либо вытянутым в горизонтальном или вертикальном направлении — можно выбрать то, что лучше впишется в макет документа. Доступно создание и изображения для обложки, которое протянется на всю страницу. За новую функцию отвечает новейший генератор Google Imagen 3 — он, по словам компании, обеспечивает «лучшую детализацию, более насыщенное освещение и меньше лишних артефактов». У части учётных записей новая функция появится в ближайшие 15 дней; для других она начнёт развёртываться 16 декабря. ИИ-функция Google Vids для генерации видео стала доступна пользователям Workspace
08.11.2024 [19:47],
Владимир Фетисов
В апреле этого года Google представила инструмент Vids, который построен на базе искусственного интеллекта, предназначен для генерации или редактирования видео, а также позиционируется как средство для совместной работы. Он позволит пользователям создавать ролики профессионального уровня без необходимости учиться работе с ПО для редактирования и обработки видео. Теперь же этот инструмент становится доступен пользователям платформы Google Workspace. 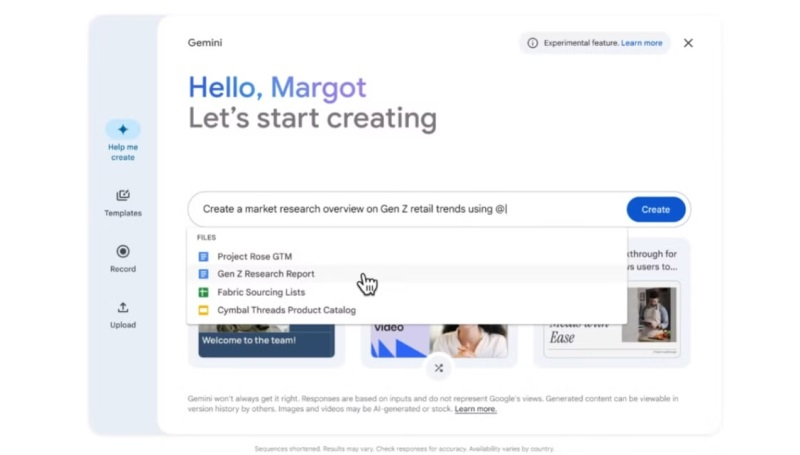
Источник изображения: Google В новом сообщении разработчиков в блоге Workspace подчёркивается, что Vids будет полезен для команд, занимающихся обучением клиентов, развитием разных проектов, маркетингом, хотя по сути данный инструмент может пригодиться кому-угодно для реализации творческих идей. Основой Vids стала нейросеть Gemini, которая позволяет быстро генерировать видео, которые могут потребоваться бизнес-клиентам компании. К примеру, одна из функций позволяет сгенерировать раскадровку на основе текстового запроса и документа из Google Диска. В раскадровке излагаются подтемы, которые будут рассмотрены в будущем видео, а пользователь может менять их очередность, удалять какие-то пункты и добавлять новые. После выбора стиля алгоритм объединит черновик видео с созданным сценарием, включая выбранные медиафайлы, текст, сценарии для каждой сцены и даже фоновую музыку. Пользователи также получат доступ к готовым шаблонам, которые можно быстро адаптировать под свои задачи. При необходимости к видео можно добавить закадровый голос, генерируемый ИИ-алгоритмом. Отметим, что входящие в состав Vids функции на основе ИИ, такие как «Помоги мне создать», «Удалить фон изображения», «Создать закадровый голос», будут доступны бесплатно до конца 2025 года. В сообщении разработчиков сказано, что ограничения на использование ИИ-функций в Vids могут быть введены, начиная с 2026 года. Google начала тестировать Vids с привлечением ограниченного числа пользователей летом этого года. Теперь же этот инструмент становится доступным бизнес-клиентам платформы Workspace. Отмечается, что для оптимальной работы в Vids лучше использовать последние версии браузеров Chrome, Firefox и Edge для Windows. Другие браузеры также поддерживаются, но некоторые функции могут работать в них некорректно. Adobe показала проект Super Sonic для создания звуковых эффектов для видео при помощи ИИ
15.10.2024 [18:05],
Сергей Сурабекянц
На ежегодной конференции Max компания Adobe продемонстрировала экспериментальный проект Super Sonic — прототип программного обеспечения на основе ИИ, которое может превращать текст в аудио, распознавать объекты и голос автора для быстрого создания звуковых эффектов и фонового аудио для видеопроектов. 
Источник изображения: Adobe «Мы хотели дать нашим пользователям контроль над процессом, […] выйти за рамки первоначального рабочего процесса преобразования текста в звук, и именно поэтому мы работали над таким аудиоприложением, которое действительно даёт вам точный контроль над энергией и синхронизацией и превращает его в выразительный инструмент», — рассказал руководитель отдела ИИ Adobe Джастин Саламон (Justin Salamon). Super Sonic использует ИИ для распознавания объектов в любом месте видеоряда, чтобы создать запрос и сгенерировать нужный звук. В другом режиме инструмент анализирует различные характеристики голоса и спектр звука и использует полученные данные для управления процессом генерации. Пользователю необязательно использовать голос, можно хлопать в ладоши, играть на инструменте или извлекать исходный звук любым другим доступным способом. Стоит отметить, что на конференции Max компания Adobe традиционно представляет ряд экспериментальных функций. В дальнейшем многие из них попадают в Adobe Creative Suite. Super Sonic может стать полезным дополнением, например, к Adobe Premiere, но пока дальнейшие перспективы проекта неясны, и он остаётся в статусе демонстрационной версии. Ранее разработчики Super Sonic участвовали в разработке функции генеративного ИИ Firefly под названием Generative Extend, которая позволяла удлинять короткие видеоклипы на несколько секунд, включая звуковую дорожку. Возможность создавать звуковые эффекты из текстового запроса или голоса — полезная функция, но далеко не новаторская. Многие компании, такие как ElevenLabs, уже предлагают подобные коммерческие инструменты. Представлена ИИ-модель YandexART 2.0 с поддержкой генерации текста на изображениях
10.10.2024 [17:09],
Павел Котов
«Яндекс» выпустил YandexART 2.0 — генератор картинок нового поколения. Нейросеть научилась создавать надписи на изображении и выдерживать на одной картинке сразу несколько стилей; объекты в пространстве и относительно друг друга теперь располагаются более естественно; а при создании изображений учитывается большее число деталей запроса. 
Источник изображений: «Яндекс» Отличительной особенностью YandexART 2.0 является гибридная архитектура нейросети, сочетающая черты свёрточной и трансформерной моделей. Свёрточная модель работает по принципу человеческого глаза, определяя ключевые признаки объекта, например, его форму, текстуру и края, но она ограничена в длине контекста, поэтому в длинных запросах ей помогает трансформер. Эта архитектура помогает YandexART 2.0 выдерживать несколько жанров в одном изображении — к примеру, она может изобразить анимешную этикетку на фотореалистичной бутылке лимонада.  Для обучения нейросети YandexART 2.0 использовались несколько сотен миллионов пар изображений и текстовых описаний к ним; более точное их соотношение обеспечила дополнительная VLM-модель, при помощи которой картинки анализировались и сопровождались подробными текстовыми описаниями. Массив обучающих данных был расширен за счёт нескольких сотен тысяч изображений с текстом — это помогло YandexART 2.0 дополнять картинки надписями латинскими буквами. 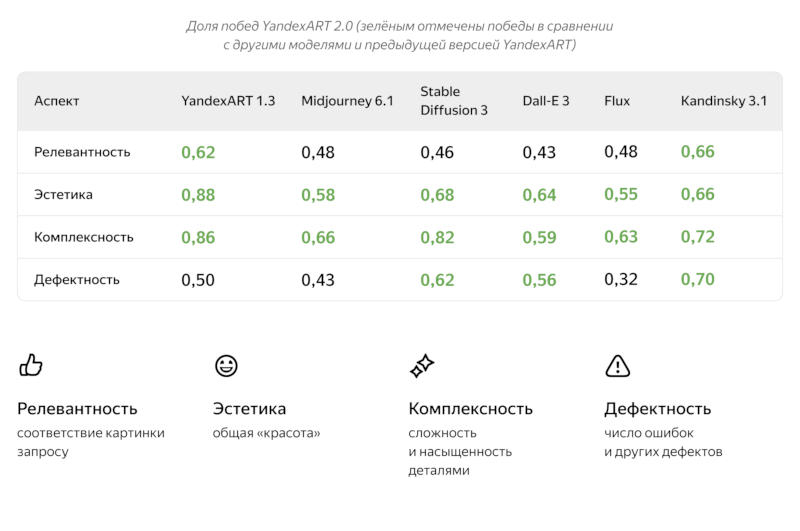 «Яндекс» также разработал собственную систему оценки качества работы для генератора изображений: новая модель выиграла у Midjourney v6.1 по критериям комплексности и эстетичности в 66 % и 58 % случаев соответственно, а также приблизилась к нему в аспекте релевантности запросам.  Бизнес-пользователи могут поработать с YandexART 2.0 на платформе Yandex Cloud — при помощи API можно интегрировать генератор изображений в любые приложения; есть возможность протестировать её работу в демонстрационном режиме для подбора оптимальных запросов. Корпоративные клиенты могут генерировать логотипы, иллюстрации для статей, презентаций или социальных сетей.  Визуальная нейросеть доступна также частным пользователям в веб-версии «Алисы» и собственном приложении виртуального помощника; владельцы бесплатных учётных записей могут запросить до пяти изображений в сутки, а у подписчиков опции «Алиса Про» такое ограничение отсутствует. С YandexART 2.0 можно создать аватарку для соцсетей, значок приложения, принт для футболки, открытку для друга или иллюстрацию для публикации. Meta✴ представила ИИ-генератор видео Movie Gen: он создаёт ролики со звуком и умеет вставлять в них реальных людей
04.10.2024 [18:06],
Павел Котов
Meta✴ представила основанный на искусственном интеллекте генератор видео Movie Gen, который позволяет по простому текстовому запросу создавать или редактировать видеоролики — компания становится всё более серьёзным конкурентом OpenAI и Google в области ИИ, пишет Bloomberg. 
Источник изображений: Gerd Altmann / pixabay.com На основе текстовых запросов Movie Gen создаёт новые видео длиной до 16 секунд. Эти же запросы могут использоваться для генерации звука к существующим видеозаписям, для редактирования готовых роликов или для создания видео с участием реального человека на основе предложенной фотографии. Пока пользоваться Movie Gen могут лишь некоторые сотрудники компании, а также её партнёры, в том числе некоторые режиссёры; а в будущем году Meta✴ намеревается добавить поддержку нейросети в свои популярные приложения. Руководство компании пока ещё обсуждает, как лучше реализовать эту интеграцию, но цель Movie Gen состоит в том, чтобы побудить пользователей соцсетей активнее создавать или редактировать публикации с видеозаписями, рассказал Коннор Хейс (Connor Hayes), вице-президент Meta✴, курирующий направление генеративного ИИ. «Инструмент будет удобным в использовании, полезным для блогеров, хорошим для общего взаимодействия в приложениях, но на данный момент у нас нет конкретного плана продукта, как он будет выглядеть», — рассказал Хейс. Meta✴ располагает большими объёмами данных, которых достаточно для обучения ИИ, способного генерировать текст, звук или видео. Компания вложила в это направление несколько миллиардов долларов и встроила в большинство своих приложений чат-бот Meta✴ AI, способный отвечать на вопросы пользователей и поддерживать разговор. Собственные генераторы видео есть и у других крупных компаний — например, это OpenAI Sora и Google Veo. С запуском Movie Gen компания не спешит: сейчас создание видео по текстовому запросу занимает «несколько десятков минут», и едва ли рядовой пользователь соцсетей будет пользоваться таким инструментом на телефоне. Meta✴ также предстоит решить несколько важных вопросов, «связанных с безопасностью и ответственностью»: к примеру, у одного человека не должно быть возможности создать видео недопустимого содержания с участием другого; компания также намеревается помечать генерируемые ИИ видео, чтобы люди знали об их источнике — истории с дипфейками стали для неё важным уроком. Сейчас направление ИИ является приоритетным для Meta✴ — ИИ, уверен её глава Марк Цукерберг (Mark Zuckerberg), способен стать фактором роста как пользовательской базы на сервисах компании, так и её доходов. Кроме того, роль ИИ будет возрастать как в приложениях Meta✴, так и в устройствах будущего, которые она выпускает или намеревается выпускать — включая умные очки. ИИ занимал важное место на презентации прототипа голографических очков дополненной реальности Orion, который Meta✴ представила на минувшей неделе. Amazon запустила собственный ИИ-генератор видео — он будет создавать рекламу
20.09.2024 [01:17],
Анжелла Марина
На фоне конкуренции с Google, компания Amazon анонсировала запуск ИИ-инструмента для быстрого создания видеорекламы. Video Generator, представленный на конференции Accelerate, позволяет преобразовывать всего одно изображение товара в увлекательный видеоролик, демонстрирующий особенности продукта. 
Источник изображения: BoliviaInteligente/Unsplash Хотя функциональность инструмента пока ограничена, пишет издание TechCrunch, однако он уже позволяет создавать пользовательские видео без дополнительных затрат. «Видео, созданные с помощью Video Generator, используют уникальные знания Amazon о розничной торговле и представляют продукт таким образом, чтобы сделать его наиболее привлекательным для клиентов», — говорится в блоге компании. На данный момент видеогенератор находится на стадии бета-тестирования и доступен ограниченному числу рекламодателей в США. Вице-президент Amazon Ads Джей Ричман (Jay Richman) заявил, что инструмент будет дорабатываться перед более широким запуском. Вместе с Video Generator также представлена функция Live Image, которая генерирует короткие анимированные GIF-файлы из статичных изображений. Эта функция, находящаяся в стадии бета-тестирования, является частью Image Generator — набора инструментов Amazon для создания изображений на основе искусственного интеллекта. Отметим, что выход Amazon на рынок генеративного видео происходит на фоне активного развития этой технологии и другими компаниями. В частности, стартапы Runway и Luma недавно запустили API для генерации видео, компания Google начала интегрировать свою модель Veo в YouTube Shorts, Adobe обещает добавить функцию генерации видео в Creative Suite к концу года, а OpenAI планирует открыть свою технологию Sora широкой публике до конца осени. Компания Amazon пока не предоставила примеры видео, созданных с помощью новых инструментов, и не раскрыла подробностей относительно максимальной длительности и разрешения генерируемых видеороликов. AMD Fluid Motion Frames 2 получила исправление стабильности и оптимизацию под Warhammer 40K Space Marine 2
08.09.2024 [10:20],
Анжелла Марина
AMD представила обновление для своей технологии повышения FPS в играх Fluid Motion Frames 2 в рамках технической предварительной версии, устранив ошибки и улучшив общую стабильность. Кроме того, заявлена оптимизация для игры Warhammer 40K Space Marine 2, запуск которой до это момента был невозможен с Frame Generation на некоторых системах, поскольку игра поддерживает только AMD FSR 2. 
Источник изображения: AMD/YouTube Как пишет Tom's Hardware, в плане функциональности и производительности не стоит ожидать кардинальных изменений между предыдущей и текущей версиями AFMF 2. «Это, по сути, обновление, направленное на исправление ошибок, поэтому любое дальнейшее снижение задержки ввода будет связано исключительно с оптимизациями для Space Marine 2 или устранением ранее существовавших проблем», — поясняют разработчики. В списке исправленных ошибок значится: отключение AFMF 2 при активации некоторых экранных оверлеев; периодическое отображение «N/A» в оверлее с метриками производительности после переключения задач при определённых конфигурациях дисплея; сбои в работе Baldur's Gate 3 на процессорах AMD Ryzen AI 300 серии; периодические зависания драйвера при открытии Xbox Game Bar во время работы AFMF 2 и RSR в некоторых играх на Vulkan, а также периодическое отключение AFMF 2 после переключения задач при использовании определённых приложений. Помимо официального списка исправленных ошибок, обновление AFMF 2 включает новую оптимизацию для игр и общие исправления стабильности. Конкретные изменения в этой части не раскрываются. Оптимизации для Warhammer 40 000: Space Marine 2 также не уточняются, но AMD призывает пользователей использовать AFMF 2 совместно с поддержкой AMD FSR 2. Это позволит приблизить качество работы Frame Generation к FSR 3, однако не достигнет всех преимуществ, которые доступны при использовании встроенной в движок игры технологии Frame Generation, как в FSR 3+ или DLSS 3+. По результатам тестирования AFMF 2 сообществом, технология показала себя вполне работоспособной и значительно превосходит в этом плане оригинальный AFMF. Несмотря на то, что встроенные в движок решения по-прежнему остаются предпочтительнее, AFMF 2 на данный момент выглядит как хорошо оптимизированное решение на уровне драйвера для игр без нативной поддержки генерации кадров, позволяя большему числу геймеров получить высокую частоту обновления. Google наконец починила ИИ-генератор изображений в Gemini — он перебарщивал с расовой инклюзивностью
29.08.2024 [00:41],
Николай Хижняк
Компания Google скоро вернёт пользователям доступ к генератору картинок в ИИ-чат-боте Gemini. Функция была удалена из чат-бота в феврале из-за того, что что она допускала серьёзные исторические ошибки в изображении людей, связанные с расовыми и гендерными вопросами. К примеру, расовое разнообразие солдат по запросу «римский легион» — явный анахронизм. 
Источник изображения: Google Ранний доступ к новому генератору изображений Imagen 3 от Google откроется платным пользователям Gemini на тарифах Advanced, Business и Enterprise в ближайшие дни, сообщил в официальном блоге Google Дэйв Ситрон (Dave Citron), старший директор по продуктам Gemini. Изначально функция будет поддерживать запросы только на английском языке. «Мы внесли технические исправления в продукт, а также поработали над более продвинутыми алгоритмами оценки и защитой от red-teaming-атак», — написал Ситрон. В феврале этого года Google приостановила работу функцию генерации изображений в Gemini, объяснив это тем, что она предлагает «неточности» при генерации исторических изображений. Компания приняла решение направить генератор изображений Gemini на доработку менее чем через сутки после поступления первых жалоб. По словам Ситрона, новый генератор Imagen 3 «не поддерживает создание фотореалистичных идентифицируемых лиц, изображений несовершеннолетний или чрезмерно кровавые, жестокие или сексуальные сцены». «Конечно, как и в случае с любым генеративным инструментом ИИ, не каждое изображение, создаваемое Gemini, будет идеальным, но мы продолжим прислушиваться к отзывам пользователей и будем совершенствовать наш продукт». Он также пообещал, что в дальнейшем пользоваться генератором изображений смогут больше людей, а сама функция получит поддержку дополнительных языков. Веб-версия генератора изображений Midjourney стала доступной для всех
24.08.2024 [13:07],
Павел Котов
Генеральный директор Midjourney Дэвид Хольц (David Holz) сообщил в Discord, что любой желающий теперь может открыть сайт сервиса и начать генерировать изображения. Бесплатная демо-версия платформы позволяет создать до 25 картинок. 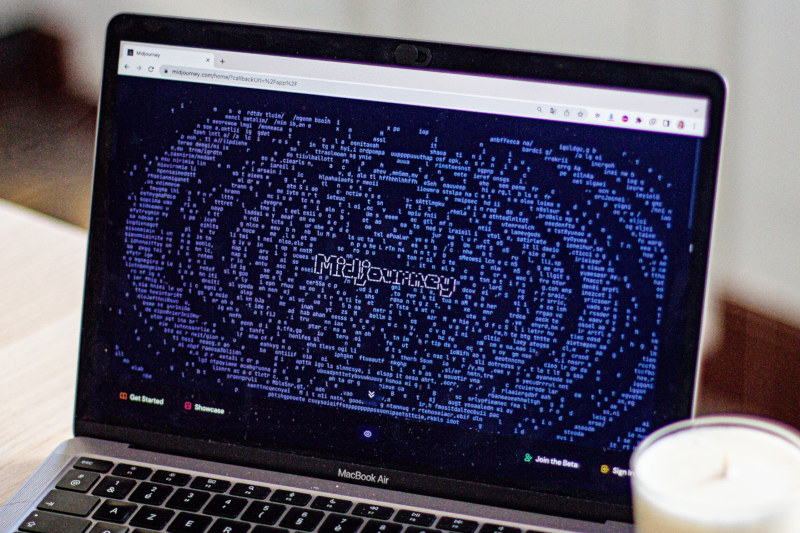
Источник изображения: Swello / unsplash.com Ранее для доступа к генератору Midjourney было необходимо пользоваться мессенджером Discord. Это было непросто, потому что приходилось особым образом составлять запросы. Чтобы привлечь пользователей, которым в Discord не нравилось, был запущен сайт платформы, но к работе в веб-интерфейсе допустили лишь тех, кто создал не менее 10 000 изображений через мессенджер. Теперь же сайт Midjourney открыт для всех желающих. Для регистрации потребуется учётная запись в Google или Discord — обладатели аккаунтов на обеих платформах могут подключить их к одной учётной записи в Midjourney и входить через любую их двух. После входа в систему набор основных инструментов доступен на левой боковой панели. Можно ознакомиться с изображениями, созданным по запросам других пользователей или попробовать сгенерировать картинку самостоятельно, предварительно посмотрев обучающий ролик. В верхней части страницы есть поле для ввода запроса, в ответ на который Midjourney предложит четыре изображения — качество наиболее удачного настраивается с помощью специальных инструментов: уменьшить, увеличить картинку или скорректировать ракурс. Есть и редактор изображений, где можно скорректировать запрос, изменить определённые области картинки, выбрать другое соотношение сторон и добавить новые элементы. Есть раздел, где собраны все созданные пользователем изображения. Картинку из коллекции можно посмотреть, изменить, скопировать или скачать. На сайте доступны чаты, где можно посмотреть, что создали другие люди, или разместить собственное изображение. По исчерпании лимита в 25 картинок Midjourney предложит оформить подписку на один из четырёх тарифных планов — они отличаются ценами и квотами на число изображений. Учёные создали очень мощный наногенератор, который станет конкурентом солнечным панелям
23.08.2024 [13:39],
Геннадий Детинич
Как сообщают учёные, вскоре обычная утренняя пробежка позволит надолго заряжать батареи гаджетов. В этом поможет удивительный наногенератор, разработанный сотрудниками Университета Суррея (University of Surrey). Устройство как минимум в 140 раз мощнее всех ранее предложенных решений в этой области, что в перспективе может позволить отказаться от солнечных панелей для зарядки множества вещей и датчиков. 
Источник изображения: University of Surrey Этот наногенератор относится к так называемым трибоэлектрическим генераторам, когда энергия извлекается в процессе движения или трения. Прорыв был совершён в области, которая позволяет регенерировать и усиливать заряд, достигая рекордного уровня плотности генерируемой мощности. Если альтернативные схемы позволяют вырабатывать до 10 мВт энергии, то предложенное британскими учёными решение обещает довести её до 1000 мВт (1 Вт). Это означает, что наногенераторы на основе сбора энергии от движения и вибраций смогут легко питать даже смартфоны, не говоря о микродатчиках и встроенных в тело чипов. Вот он, Святой Грааль для адептов чипирования человечества! Учёные из Университета Суррея разработали схему генерации, которая чем-то похожа на эстафету с передачей палочки следующему бегуну, как поясняют разработчики. «Мечта наногенераторов — улавливать и использовать энергию от повседневных движений, таких как утренняя пробежка, механические вибрации, океанские волны или открывание двери. Ключевым новшеством нашего наногенератора является то, что мы усовершенствовали технологию с помощью 34 крошечных коллекторов энергии с использованием лазерной технологии, которая может быть расширена для производства с целью дальнейшего повышения энергоэффективности», — поясняют изобретатели. «Что действительно интересно, так это то, что наше маленькое устройство с высокой плотностью сбора энергии может в один прекрасный день сравниться по мощности с солнечными батареями и может быть использовано для управления чем угодно — от датчиков с автономным питанием до систем "умного дома", которые работают без необходимости замены батареи», — уверены учёные. Добавим, статья о разработке свободно доступна на сайте журнала Nano Energy. Google открыла всем американским пользователям доступ к генератору изображений Imagen 3
16.08.2024 [17:31],
Павел Котов
Google без громких анонсов открыла всем пользователям из США доступ к последней модели генератора изображений с искусственным интеллектом Imagen 3 на платформе ImageFX. Компания также опубликовала исследовательскую работу, в которой подробно описывается эта технология. 
Источник изображения: deepmind.google Модель Imagen 3 была анонсирована в мае на конференции Google I/O и выпущена в ограниченный доступ для пользователей платформы Vertex AI. «Представляем Imagen 3 — модель скрытой диффузии, которая генерирует высококачественные изображения по текстовым запросам. На момент проведения оценки Imagen 3 является более предпочтительной, чем другие современные модели», — говорится в научной работе. Выпуск Google нового генератора изображений для широкой общественности в США — важный стратегический шаг для компании, вступившей в гонку технологий ИИ. С одной стороны, разработчику удалось повысить качестве её работы, с другой — модель подвергается критике за излишне строгие фильтры контента. Пользователи Reddit, в частности, сообщают, что генератор изображений отклоняет до половины запросов, даже если не предлагать ему «нарисовать» нечто сомнительное — дошло до того, что он отказался создать изображение киборга. Это резко контрастирует с подходом стартапа Илона Маска (Elon Musk) xAI, который на этой неделе выпустил модель Grok-2. Она генерирует изображения практически без ограничений, допуская создание картинок с общественными деятелями и деталями, которые на других платформах считаются недопустимыми. Это тоже вызвало недоумение общественности и породило предположения, что на xAI будет оказываться давление. Перед отраслью ИИ встаёт вопрос о балансе между творчеством и ответственностью, а также возможном влиянии генераторов изображений на публичный дискурс и достоверность информации. Художники одержали важную победу в деле об авторских правах против Stability AI и Midjourney
14.08.2024 [17:11],
Павел Котов
Группа художников, которая объединилась в коллективном иске против разработчиков наиболее популярных моделей искусственного интеллекта для генерации изображений, устроила празднование по случаю того, что судья дал ход этому делу и санкционировал раскрытие информации. 
Источник изображения: Alexandra_Koch / pixabay.com Ответчиками по делу выступают создатели сервисов Midjourney, Runway, Stability AI и DeviantArt — по версии истцов, разработчики систем на основе модели Stable Diffusion использовали их защищённые авторским правом работы для обучения ИИ. Судья Северного окружного суда Калифорнии Уильям Оррик (William H. Orrick), курирующий Сан-Франциско, где располагаются многие крупнейшие разработчики систем ИИ, пока не вынес окончательного решения по делу, но счёл, что предъявленных ответчикам обвинений достаточно, чтобы дело перешло к стадии раскрытия информации. Это значит, что представляющие истцов юристы могут изучить документы компаний — разработчиков генераторов изображений с ИИ; огласке будут преданы подробности о массивах обучающих данных, механизмах и внутренней работе систем. Модель Stable Diffusion предположительно обучалась на наборе данных LAION-5B из 5 млрд изображений, который был опубликован в 2022 году. Но, как отмечается в деле, эта база содержала только URL-адреса, то есть ссылки на изображения, а также их текстовые описания, то есть компаниям приходилось самостоятельно собирать эти изображения. Основанные на Stable Diffusion модели используют в работе механизм «CLIP-guided diffusion», помогающий им при генерации изображений отталкиваться от пользовательских запросов, которые могут включать имена художников. Метод CLIP (Contrastive Language-Image Pre-training) разработала и ещё в 2021 году опубликовала компания OpenAI — более чем за год до выпуска ChatGPT. Модель OpenAI CLIP способна работать как база данных по фирменному стилю, и если при обучении схожей с ней модели Midjourney использовались имена художников и их работы с сопоставленными с ними описаниями, то этот факт может представлять собой нарушение авторских прав. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться