|
Опрос
|
реклама
Быстрый переход
Apple Intelligence стала занимать слишком много дискового пространства
06.01.2025 [06:21],
Анжелла Марина
Apple Intelligence обещала упростить жизнь, но пока лишь создаёт проблемы. Функция, запущенная в сентябре 2024 года, за четыре месяца увеличила свои требования к хранилищу с 4 до 7 Гбайт. Пользователи задаются вопросом, оправданы ли затраты на память и батарею, учитывая низкую эффективность функции Apple Intelligence в её текущем виде. 
Источник изображения: macrumors.com Как сообщает издание Gizmodo, проблемы начались с выходом iOS 18.2 и macOS Sequoia 15.2. И хотя новые версии операционных систем расширили функциональность Apple Intelligence, добавив возможности генеративного ИИ, такие как Image Playground (создание изображений по запросу пользователя) и Genmoji для создания пользовательских эмодзи, это привело к значительному увеличению объёма данных, необходимых для работы системы. Одной из причин возросших требований к памяти является использование локальной обработки. То есть, данные обрабатываются непосредственно на устройстве для обеспечения большей конфиденциальности, но при этом требуется хранение ИИ-моделей на самом гаджете. Кстати, именно поэтому доступ к Apple Intelligence имеют только устройства с мощными чипами M1, A17 или более новыми. Так как Apple планирует и дальше развивать возможности ИИ, включая обновление голосового помощника Siri, то это значит, что требования к свободному пространству будут только расти. «Ожидайте, что эта функция будет продолжать заполнять ваше доступное хранилище в обозримом будущем», — отмечает не без доли горечи Gizmodo. Между тем, согласно исследованию SellCell, большинство пользователей не в восторге от Apple Intelligence. 73 % владельцев iPhone, попробовавших функцию, считают, что она «не имеет особой ценности» для их пользовательского опыта. Кроме того, отмечаются жалобы на повышенный расход заряда батареи, связанный с работой искусственного интеллекта. В итоге, на данный момент Apple Intelligence, по мнению многих, не оправдывает затрат ресурсов, предлагая взамен лишь неточные пересказы новостей и необходимость чаще заряжать устройство. Пока неясно, изменится ли отношение пользователей к Apple Intelligence с появлением новых, более востребованных функций, однако, несмотря на недовольство части пользователей и рост требований к хранилищу, Apple не собирается сворачивать с намеченного курса, делая серьёзную ставку на внедрение ИИ в свои устройства. Очки дополненной реальности RayNeo будут использовать ИИ-модели Alibaba
05.01.2025 [07:21],
Алексей Разин
На этой неделе китайский гигант Alibaba продемонстрировал желание косвенно присутствовать на рынке устройств дополненной реальности, заявив о сотрудничестве с гонконгским производителем AR-очков RayNeo. Устройства этой марки будут использовать большие языковые модели Qwen китайской компании Alibaba. 
Источник изображения: RayNeo По словам участников проекта, это первый случай сотрудничества разработчиков больших языковых моделей с производителем умных очков в Китае. До этого Alibaba свои языковые модели Qwen подобным образом не использовала, если не считать сотрудничества со стартапом Rokid американского происхождения, основанным бывшим сотрудником Alibaba. Данный альянс был обнародован в ноябре прошлого года, как и сотрудничество Baidu с производителем умных очков Xiaodu, который получил доступ к большой языковой модели Ernie. RayNeo основана в 2021 году производителем дисплеев и телевизоров TCL Electronics Holdings. Компания успела продать более 5000 пар представленных недавно очков дополненной реальности RayNeo Air3. На CES 2025 компания планирует представить пару новых моделей, включая очки с умной камерой, позволяющей распознавать объекты. Исконно американские компании также не упускают возможности подружить носимые устройства с искусственным интеллектом, в сентябре Meta✴ Platforms представила очки дополненной реальности Orion, а до этого сотрудничала с производителем очков Ray-Ban. Представители Alibaba считают очки дополненной реальности идеальной платформой для использования больших языковых моделей. Дальнейшее сотрудничество с производителями умных очков позволит Alibaba создавать модели с более высоким уровнем кастомизации. По прогнозам WellsennXR, к 2029 году объёмы продаж очков дополненной реальности вырастут до 55 млн штук в год. В прошлом году ёмкость рынка умных очков достигла $1,93 млрд в денежном выражении. В ближайшие пять лет она ежегодно будет увеличиваться в среднем на 27,3 %, чтобы достичь $8,26 млрд к концу десятилетия. Гендиректор YouTube сделал ставку на ИИ и блогеров
04.01.2025 [13:28],
Павел Котов
Генеральный директор YouTube Нил Мохан (Neal Mohan) уверен, что ключевыми факторами дальнейшего развития платформы станут технологии искусственного интеллекта и укрепление взаимодействия с авторами популярных каналов, пишет Financial Times. 
Нил Мохан. Источник изображений: blog.youtube Годовая выручка YouTube составляет $50 млрд. Платформа эволюционировала из хостинга любительских роликов в крупнейший центр потоковой музыки и видео, службу подписки на кабельное телевидение, прямых спортивных трансляций и платформу распределения прибыли между блогерами, аудитория которых исчисляется сотнями миллионов подписчиков. По словам Мохана, у YouTube остаётся огромный потенциал для роста. «Мы даже не коснулись верхушки айсберга того, что можем сделать с такими технологиями, как генеративный ИИ», — считает он. Несмотря на снижение рекламной выручки YouTube в 2023 году, за первые десять месяцев 2024 года она выросла на 15 % и составила $25,4 млрд. Это лишь пятая часть общего дохода от поисковой рекламы холдинга Alphabet, достигшего $144 млрд, но компании требуются значительные средства: в условиях конкуренции с Microsoft и Amazon в строительстве центров обработки данных и разработке чипов для ИИ расходы Alphabet увеличились до $38,3 млрд. Мохан, назначенный генеральным директором YouTube в 2023 году после пяти лет работы на должности директора по продуктам, намерен активно внедрять службы генеративного ИИ. Ему предстоит удержать баланс между возможностями мгновенного создания музыки и видео с помощью ИИ и опасениями блогеров, которые не хотят, чтобы технологии вытеснили их творчество. Сообщество авторов — краеугольный камень успеха YouTube. За последние три года платформа выплатила им $70 млрд, полученных от рекламы и платных подписок.  Специализирующееся на ИИ подразделение Google DeepMind уже помогло запустить на YouTube экспериментальные функции Dream Screen и Dream Track, позволяющие генерировать видео и музыку по текстовым запросам. Однако эти инструменты предназначены для помощи блогерам, а не для их замены, подчеркнул Мохан. Ещё одной перспективной разработкой DeepMind является автоматический дубляж — перевод видео с английского на восемь других языков и обратно. Хотя YouTube ассоциируется с видео на ноутбуках и телефонах, наиболее активный рост платформа демонстрирует в сегменте умных телевизоров. Здесь ежедневно транслируется 1 млрд часов контента. Это не только сериалы и спортивные состязания, но и короткие вертикальные видео в разделе Shorts, который конкурирует с TikTok и достигает 70 млрд просмотров в день. YouTube занимает третье место по объёму инвестиций в оригинальный контент, уступая лишь Disney и Comcast. В первой половине 2024 года платформа вложила в контент $20 млрд, обогнав Netflix и Warner Bros. Discovery, согласно данным Ampere Analysis. По итогам 2024 года рекламная выручка YouTube прогнозируется на уровне $35 млрд, что выше общего дохода Disney+ и Amazon Prime Video и немного ниже доходов Netflix. Крупнейшей инвестицией платформы стало семилетнее соглашение на трансляцию матчей Национальной футбольной лиги США, обошедшееся в $14 млрд. За последний год на YouTube было просмотрено 35 млрд часов спортивного контента. Mozilla запустила расширение Orbit для Firefox для обобщения контента с помощью ИИ
04.01.2025 [09:03],
Владимир Мироненко
Mozilla запустила свой самый амбициозный проект ИИ на сегодняшний день: расширение Orbit для Firefox, которое позволит легко обобщать веб-контент во время просмотра, преобразуя длинный текст и даже видео в более удобоваримый сжатый формат в виде резюме, пишет ресурс TechSpot. 
Источник изображений: Mozilla По словам Mozilla, цель Orbit — помочь пользователям быстро и безопасно извлекать из электронных писем, веб-страниц и других длинных документов важную информацию, не полагаясь на облачную модель ИИ, работающую в режиме always-on. В настоящее время расширение Orbit находится в стадии бета-тестирования и доступно только на английском языке. Для своей работы Orbit использует большую языковую модель Mistral (Mistral 7B) и может запускаться на таких популярных веб-сайтах, как Gmail, Wikipedia, The New York Times, YouTube и т.д. Пользователи могут направлять Orbit запросы по поводу сводок или дополнительной информации о контенте, а ИИ предоставит в ответ на запрос соответствующий контекст (изображения, текст, видео).  Для установки расширения не требуется наличие учётной записи и сервис не хранит никакой информации о запросах пользователей. ИИ-модель Mistral 7B LLM, обеспечивающая работу сервиса, размещена на собственных серверах Mozilla, и поступающие в сервис запросы не передаются Mistral или другим сторонним компаниям. Mozilla отметила, что каждый сеанс уникален, и данные не используются для обучения моделей генеративного ИИ. В 2025 году Microsoft инвестирует огромную сумму в $80 млрд в ИИ ЦОД
04.01.2025 [08:09],
Владимир Мироненко
Microsoft сообщила в пятницу в своём блоге о планах направить в этом году $80 млрд на разработку ЦОД для обучения моделей искусственного интеллекта (ИИ), а также развёртывания ИИ и облачных приложений. 
Источник изображения: Anna Surovková/unsplash.com Обработка ИИ-нагрузок ИИ требует огромной вычислительной мощности, что повышает спрос на специализированные ЦОД с возможностью объединения тысяч чипов в кластеры, пишет Reuters. Компании из разных отраслей стремятся интегрировать ИИ в свои продукты и услуги, чтобы повысить их качество и востребованность у потребителей. Поэтому объём инвестиций в ИИ значительно возрос с тех пор, как в 2022 году OpenAI запустила чат-бот ChatGPT на основе ИИ. Microsoft, являясь крупнейшим инвестором OpenAI, направляет значительные средства на улучшение своей инфраструктуры ИИ и расширение сети ЦОД. Как сообщает Visible Alpha, согласно прогнозу аналитиков, в 2025 финансовом году капитальные расходы Microsoft, включая лизинг, составят $84,24 млрд. В I квартале 2025 финансового года капитальные расходы компании выросли год к году на 5,3 % до $20 млрд. По словам вице-председателя и президента Microsoft Брэда Смита (Brad Smith), более половины инвестиций будет направлено в инфраструктуру Соединённых Штатов. «Сегодня Соединённые Штаты лидируют в глобальной гонке ИИ благодаря инвестициям частного капитала и инновациям американских компаний всех размеров, от динамичных стартапов до хорошо зарекомендовавших себя предприятий», — отметил Смит. Anthropic договорилась с музыкальными издателями по иску о незаконном пересказывании песен ИИ
03.01.2025 [17:10],
Владимир Мироненко
Anthropic, разработчик ИИ-чат-бота Claude, заключила соглашение с тремя крупными музыкальными издателями для урегулирования части иска о нарушении авторских прав, связанного с предполагаемым использованием защищённых текстов песен. 
Источник изображения: Anthropic Окружной судья США Юми Ли (Eumi Lee) утвердила в четверг соглашение между сторонами, согласно которому Anthropic обязуется соблюдать существующие ограничения при обучении будущих моделей ИИ. Эти ограничения запрещают чат-боту Claude предоставлять пользователям тексты песен, принадлежащих музыкальным издателям, или создавать новые тексты на основе защищённых авторским правом материалов. Также соглашение определяет процедуру вмешательства музыкальных издателей при подозрении на нарушение Anthropic авторских прав. В октябре 2023 года несколько музыкальных издателей, включая Universal Music Group, ABKCO, Concord Music Group и Greg Nelson Music, подали в федеральный суд штата Теннесси иск против Anthropic, обвинив компанию в нарушении авторских прав. Согласно заявлению истцов, Anthropic якобы обучала свои ИИ-модели на текстах не менее 500 защищённых песен. В иске утверждается, что, когда Claude запрашивали тексты таких песен, как Halo Бейонсе, Uptown Funk Марка Ронсона (Mark Ronson) и Moves Like Jagger группы Maroon 5, чат-бот предоставлял ответы, «содержащие всё или значительную часть этих текстов». Музыкальные издатели подчеркнули, что существуют платформы, такие как Genius, которые легально распространяют тексты песен в интернете и выплачивают за это лицензионные сборы, в отличие от Anthropic. В иске также утверждается, что компания «намеренно удаляла или изменяла информацию об управлении авторскими правами» для песен, тексты которых были использованы для обучения её ИИ-моделей. Claude «не предназначен для использования в целях нарушения авторских прав, и у нас есть многочисленные инструменты, направленные на предотвращение таких нарушений, — указала Anthropic в заявлении для The Hollywood Reporter. — Наше решение заключить это соглашение соответствует этим приоритетам». Следует отметить, что урегулирование касается лишь части иска. В ближайшие месяцы суд должен вынести решение по вопросу о предварительном запрете на обучение ИИ-моделей компании на текстах песен, принадлежащих музыкальным издателям. Apple начала самовольно сканировать пользовательские фото на предмет достопримечательностей, но от этого можно отказаться
03.01.2025 [17:01],
Павел Котов
В прошлом году Apple развернула на своих устройствах механизм, который идентифицирует достопримечательности на пользовательских фотографиях и позволяет после находить на мобильных устройствах и компьютерах пользователей снимки по названиям этим самым достопримечательностей. Производитель включил эту функцию без явного согласия владельцев устройств, и замечать это они стали только теперь. 
Источник изображений: apple.com Функция получила название «Улучшенный визуальный поиск» (Enhanced Visual Search), и впервые о ней рассказал общественности программист Джефф Джонсон (Jeff Johnson). По его словам, новая служба начала работать 28 октября 2024 года на iOS 18.1 и macOS 15.1, и Apple не потрудилась внятно объяснить принципы работы этой технологии. В датированном 6 ноября 2024 года документе на сайте Apple говорится: «Улучшенный визуальный поиск в приложении „Фото“ позволяет искать фото по достопримечательностям и другим ориентирам. Ваше устройство конфиденциально сопоставляет места на Ваших фото с каталогом мировых локаций, который хранится на серверах Apple. Мы применяем технологии гомоморфного шифрования и дифференциальной конфиденциальности, а также используем узел протокола OHTTP, который скрывает IP‑адрес. Это не даёт Apple возможности собрать какую‑либо информацию о том, что изображено на Ваших фото. Функцию „Улучшенный визуальный поиск“ можно выключить в любой момент. Для этого на устройстве iOS или iPadOS откройте „Настройки“ –> „Приложения“ –> „Фото“. На Mac откройте приложение „Фото“ и выберите „Настройки“ –> „Основные“». 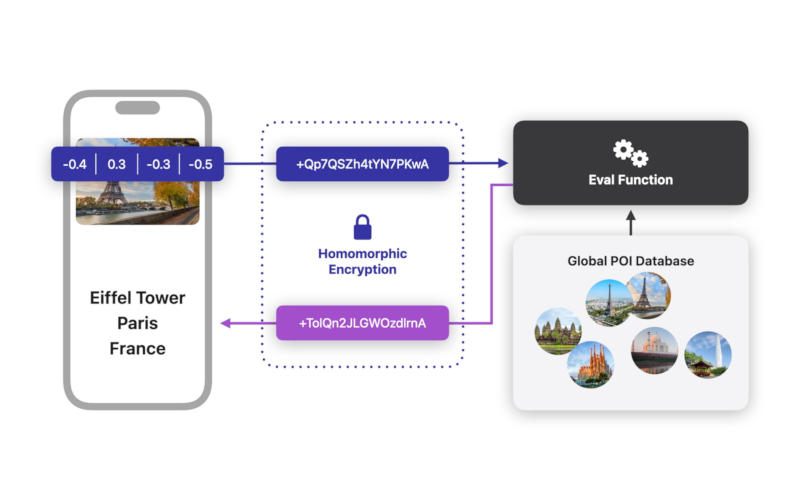 Подробное объяснение принципов работы технологии приводится в статье на сайте Apple от 24 октября 2024 года — примерно в то же время и был запущен «Улучшенный визуальный поиск». В его основе лежит модель машинного обучения, работающая локально на устройствах. Она анализирует фотографии на предмет присутствия достопримечательностей. Если искусственный интеллект находит совпадение, система вычисляет векторное вложение — массив чисел, представляющий этот фрагмент изображения. Затем векторное вложение шифруется с использованием гомоморфного шифрования, позволяющего производить вычисления над зашифрованными данными без их расшифровки. После этого данные отправляются на удалённый сервер, где производится поиск по базе достопримечательностей. Результаты возвращаются на устройство пользователя, которое, по утверждению Apple, единственное способно расшифровать эту информацию. Дополнительным уровнем защиты выступает механизм дифференциальной конфиденциальности, исключающий идентификацию субъекта в базе данных, даже если злоумышленник получит доступ ко всей базе. Однако эксперты, опрошенные британским изданием *The Register*, выразили сомнения в новой службе Apple. Компания активировала «Улучшенный визуальный поиск» по умолчанию для всех пользователей, включая тех, кто отключил выгрузку фотографий в iCloud из соображений конфиденциальности. Более трёх лет назад Apple планировала проверять изображения на устройствах пользователей на предмет материалов, связанных с жестоким обращением с детьми, но отказалась от этой инициативы из-за вопросов к конфиденциальности. Новая система, как утверждают критики, принудительно обрабатывает локально сохранённые фотографии и отправляет данные обо всех изображениях, а не только о тех, где найдены подозрительные хеши. Кроме того, остаётся неясным, почему Apple запустила «Улучшенный визуальный поиск», не убедившись, что пользователи её устройств были должным образом уведомлены. Nvidia стала лидером по приросту капитализации в прошлом году, увеличив её на $2 трлн
02.01.2025 [15:42],
Алексей Разин
Наблюдаемый по сей день бум искусственного интеллекта вполне ожидаемо сделал Nvidia главным бенефициаром этой тенденции с точки зрения динамики курса акций, поскольку он за предыдущие 12 месяцев вырос на 179 %. Прошлый год компания завершила на отметке капитализации $3,28 трлн, нарастив её за год более чем на $2 трлн. 
Источник изображения: Nvidia Как поясняет Reuters, это не превращает Nvidia в крупнейшую публичную компанию мира, поскольку этот титул к концу года вырвала Apple со своей капитализацией $3,78 трлн, но по темпам роста Nvidia не нашлось равных. Та же Apple, например, увеличила собственную капитализацию по итогам 2024 года только на $791 млрд. Замыкающая тройку публичных компаний с капитализацией более $3 трлн корпорация Microsoft при этом прибавила всего $339 млрд. Amazon по динамике увеличения капитализации лишь чуть-чуть уступила Apple, прибавив за год $737 млрд, а вот Meta✴ и Alphabet (Google) прибавили по $568 млрд. Среди поставщиков компонентов можно отметить прогресс Broadcom, которая увеличила капитализацию на $564 млрд, а вот крупнейший в мире контрактный производитель чипов в лице тайваньской TSMC нарастил капитализацию лишь на $351 млрд, хотя изготавливает продукцию для Nvidia и многих других лидеров рынка ИИ. Дополнительные $507 млрд капитализации Tesla по итогам года могут объясняться в большей степени политическими факторами, чем наличием технического прогресса или блестящими финансовыми показателями деятельности компании. Аналитики Wedbush Securities ожидают, что в текущем году котировки акций компаний технологического сектора вырастут на 25 %, если с приходом к власти в США Дональда Трампа (Donald Trump) и его соратника Илона Маска (Elon Musk) регуляторные условия развития компаний ИИ-сектора смогут улучшиться. За три последующих года капитализация участников этого рынка может вырасти более чем на $2 трлн, по мнению экспертов. Nvidia в прошлом году инвестировала $1 млрд в компании, связанные с ИИ
02.01.2025 [14:51],
Алексей Разин
То и дело подтверждавшая статус самой дорогой публичной компании мира, Nvidia в прошлом году, как ожидается, более чем удвоила выручку до $129 млрд, хотя итоги периода придётся подводить только в феврале. Нет ничего удивительного, что за прошедший год она вложила $1 млрд в капитал примерно 50 стартапов, связанных с темой искусственного интеллекта. 
Источник изображения: Nvidia Как поясняет Financial Times со ссылкой на данные Dealroom и отчётность самой Nvidia, эта компания в 2023 году ограничилась поддержкой лишь 39 стартапов, а расходы на них не превысили $872 млн. В прошлом году основная часть партнёров Nvidia, получивших от неё финансирование, одновременно являлась покупателями её ускорителей вычислений. Компании, занимающиеся развитием инфраструктуры систем искусственного интеллекта, в прошлом году потратили десятки миллиардов долларов на ускорители вычислений Nvidia. Это позволило компании к концу третьего фискального квартала накопить около $9 млрд свободных денежных средств. Акции Nvidia выросли в цене в 2,7 раза по итогам прошлого года. За первые девять месяцев 2024 года Nvidia смогла вложить $1 млрд в капитал не связанных с нею компаний. По сравнению с аналогичным периодом 2023 года, соответствующая сумма выросла на 15 %, а в 2022 году на эти нужды она потратила более чем в 10 раз меньше. С точки зрения долгосрочной стратегии инвестиции Nvidia в небольшие компании имеют смысл, поскольку нынешние крупные клиенты в лице Microsoft, Amazon и Google, ориентированы на создание собственных ускорителей вычислений. В будущем они смогут снизить свою зависимость от компонентов Nvidia, поэтому компании важно подготовить определённого рода «подушку безопасности». Она сама может буквально вырастить будущих клиентов. По итогам 2024 года, Nvidia обошла Microsoft и Amazon по количеству заключённых сделок, хотя и уступила Google. По словам представителей Nvidia, компания не навязывает компаниям, в которые инвестирует, покупку исключительно собственных ускорителей вычислений. Напомним, что недавно Nvidia вместе со своим конкурентом AMD вложила средства в капитал стартапа xAI, основанного Илоном Маском (Elon Musk) в качестве альтернативы OpenAI, в становлении которого этот миллиардер тоже принимал участие. Nvidia также успела вложить свои средства в прошлом году в капитал OpenAI, Cohere, Mistral и Perplexity. Кроме того, Nvidia контролирует инвестиционный инкубатор Inception, который помогает молодым компаниям в сфере ИИ получить доступ к оборудованию Nvidia и облачной инфраструктуре её партнёров на более выгодных условиях. Помимо стартапа Run:ai, компании Nvidia также удалось купить разработчиков программного обеспечения для ИИ в лице Nebulon, OctoAI, Brev.dev, Shoreline.io и Deci. В общей сложности, она в прошлом году заключила больше сделок, чем за четыре предшествующих года. Спектр инвестиционных интересов Nvidia охватывал медицинские технологии, системы поиска, игровые, логистические и полупроводниковые стартапы, а также робототехнику, логистику и обработку данных. Провайдер облачных услуг в сфере ИИ, компания CoreWeave, которую в своё время поддержала Nvidia, готовится в этом году привлечь капитал, исходя из оценки своего бизнеса в $35 млрд против всего $7 млрд годом ранее. Вложив $100 млн в CoreWeave в 2023 году, в прошлом мае Nvidia потратила на поддержку стартапа ещё $1 млрд. Компанию Applied Digital, как считается, Nvidia и её партнёры спасли от разорения, вложив в её капитал $160 млн в сентябре прошлого года. OpenAI не выполнила обещание по созданию инструмента для защиты авторских прав к 2025 году
02.01.2025 [03:45],
Анжелла Марина
Компания OpenAI не смогла выпустить обещанный инструмент Media Manager до 2025 года, с помощью которого создатели контента смогли бы контролировать использование своих работ в обучении нейросетей. Media Manager, анонсированный в мае прошлого года, должен был идентифицировать защищённые авторским правом тексты, изображения, аудио и видео. 
Источник изображения: hdhai.com Инструмент должен был помочь OpenAI избежать юридических проблем, связанных с нарушением прав на интеллектуальную собственность, и в целом мог бы стать стандартом для всей индустрии искусственного интеллекта. Однако, как пишет издание TechCrunch, разработка Media Manager изначально не считалась в компании приоритетной. Один из бывших сотрудников OpenAI отметил: «Я не думаю, что это было приоритетом. Честно говоря, я и не помню, чтобы кто-то над этим работал». Другой источник, близкий к компании, подтвердил, что обсуждения инструмента были, но с конца 2024 года никакой новой информации, связанной с проектом, не поступало. Надо сказать, что в последнее время использование авторского контента для обучения ИИ неоднократно становилось причиной споров. Модели OpenAI, такие как ChatGPT и Sora, обучаются на огромных наборах данных, включающих тексты, изображения и видео из интернета. Это позволяет ИИ-моделями создавать новые работы, но зачастую они оказываются слишком похожи на оригинал. Например, Sora может генерировать видео с логотипом TikTok или персонажами из видеоигр, а ChatGPT был «пойман» на дословных цитатах из статей The New York Times. Такая практика вызывает волну возмущения со стороны авторов, чьи работы были использованы без их согласия. Против OpenAI уже поданы коллективные иски от художников, писателей и крупных медиа-компаний, включая The New York Times и Radio-Canada. Авторы, такие как американская актриса и сценарист Сара Сильверман (Sarah Silverman) и писатель Та-Нехиси Коутс (Ta-Nehisi Coates), также присоединились к судебным разбирательствам, обвинив OpenAI в незаконном использовании их работ. OpenAI предложила альтернативные решения проблемы, и на данный момент создателям контента предлагается несколько способов для исключения своих работы из обучения нейросетей. В частности, в сентябре 2024 года была запущена форма для подачи заявлений на удаление изображений из будущих наборов данных. Также компания ничего не имеет против того, чтобы веб-мастера прописывали блокировку для своих сайтов от сбора данных её ботами, например в файле «robots.txt». Однако эти методы подверглись критике как за их сложность (удаление контента из набора данных), так и за их несовершенство. Media Manager, напротив, преподносился как долгожданное комплексное решение. В мае 2024 года OpenAI заявила, что работает над инструментом совместно с регуляторами и использует передовые технологии машинного обучения для распознавания авторских прав. Тем не менее с момента анонса компания больше ни разу публично не упоминала об этом инструменте. И даже если Media Manager будет выпущен, эксперты сомневаются, что инструмент сможет решить все проблемы. Эдриан Сайхан (Adrian Cyhan), юрист в сфере интеллектуальной собственности, отмечает, что даже крупным платформам, таким как YouTube и TikTok, сложно справляться с идентификацией контента в больших масштабах. «Гарантировать соблюдение всех требований создателей контента и законов разных стран — крайне трудная задача», — заявил он. А основатель некоммерческой организации Fairly Trained Эд Ньютон-Рекс (Ed Newton-Rex) вообще считает, что Media Manager лишь переложит ответственность на самих создателей. При этом, даже если Media Manager будет запущен, он вряд ли сможет избавить OpenAI от юридической ответственности, считают эксперты. Эван Эверист (Evan Everist), специалист по авторскому праву, напомнил, что по закону владельцы авторских прав вообще не обязаны предупреждать о запрете на использование их работ и «базовые принципы авторского права остаются неизменными: нельзя использовать чужие материалы без разрешения». В отсутствие Media Manager, OpenAI пока внедрила фильтры, которые предотвращают дословное копирование чужих данных, а в судебных исках компания продолжает утверждать, что её ИИ-модели создают «компиляцию», а не плагиат, ссылаясь на принцип «добросовестного использования». Суды могут поддержать позицию OpenAI, как это произошло в деле Google Books, когда суд постановил, что копирование компанией Google миллионов книг для Google Books, своего рода цифрового архива, является допустимым. Однако, если суды признают, что OpenAI незаконно использует авторский контент, компании придётся пересмотреть свою стратегию, включая выпуск Media Manager. Китайская ByteDance в этом году рассчитывает купить ускорителей Nvidia на сумму $7 млрд
01.01.2025 [10:32],
Алексей Разин
Статистика прошлого года уже позволила понять, что китайские компании ByteDance и Tencent оказались на втором и третьем месте соответственно среди крупнейших покупателей ускорителей Nvidia, уступив только Microsoft. Новые сведения гласят, что ByteDance в условиях сохранения санкций против КНР рассчитывает в текущем году закупить ускорителей Nvidia на общую сумму $7 млрд. 
Источник изображения: Nvidia Об этом сообщает издание The Information, отмечая, что подобные расходы превратят ByteDance в одного из крупнейших в мире покупателей ускорителей вычислений Nvidia. Рассчитывать на успех подобной инициативы позволяет схема закупки данной продукции в условиях санкций против Китая. Технически, данные ускорители будут размещаться в центрах обработки данных за пределами КНР в соседних странах Юго-Восточной Азии, поэтому ByteDance сможет купить даже достаточно производительные ускорители Nvidia, а не только подогнанные под требования правил экспортного контроля США варианты с ограниченной производительностью. ByteDance в Китае предлагает клиентам популярный чат-бот Doubao, который насчитывает 51 млн активных пользователей. Закупка большого количества ускорителей вычислений Nvidia определённо поможет китайским разработчикам усовершенствовать свои сервисы, включая популярную за пределами КНР социальную сеть TikTok. Галлюцинации и ошибки ИИ способны привести к научным прорывам
31.12.2024 [01:53],
Анжелла Марина
Искусственный интеллект (ИИ), способный убедительно создавать ложную или вымышленную информацию, может стать незаменимым инструментом в руках учёных. Новые лекарства, прогнозирование погоды и изобретение устройств — вот лишь немногие примеры того, как способность ИИ генерировать новые, на первый взгляд ошибочные идеи, может менять мир науки. 
Источник изображения: Copilot ИИ-модели часто подвергаются критике за склонность генерировать недостоверную информацию, выдавая её за факты — так называемые «галлюцинации». Эти правдоподобные подделки не только сбивают с толку пользователей чат-ботов, но и приводят к судебным разбирательствам и ошибкам в медицинских записях. Например, в прошлом году ложное заявление чат-бота Google обвалило рыночную стоимость одной из компаний на $100 млрд. Однако, как пишет The New York Times, недавно исследователи обнаружили, что «галлюцинации» ИИ могут быть и на удивление полезными. Оказывается, «умные» LLM (большие языковые модели) способны генерировать невероятные идеи, которые помогают учёным в борьбе с раком, разработке новых лекарств, создании медицинских устройств, изучении погодных явлений и даже в получении Нобелевской премии. «Это даёт учёным новые идеи, которых они могли бы никогда не придумать сами», — объясняет Эми МакГоверн (Amy McGovern), руководитель федерального института ИИ (NSF AI Institute) в США по прогнозированию климата и погоды. Хотя наука традиционно ассоциируется с логикой и аналитикой, её начало часто связано с интуицией и смелыми предположениями. Философ и методолог науки Пол Фейерабенд (Paul Feyerabend) однажды охарактеризовал этот этап как «всё дозволено». Ошибки ИИ-моделей оживляют этот творческий процесс, ускоряя поиск и проверку новых идей. То, что раньше занимало годы, теперь можно сделать за дни, часы или даже минуты. Профессор Массачусетского технологического института (MIT) Джеймс Дж. Коллинз (James J. Collins) недавно похвалил «галлюцинации» за ускорение его исследований в области новых антибиотиков, поскольку ИИ-модели создали совершенно новые молекулы. «Галлюцинации» ИИ возникают, когда учёные обучают генеративные компьютерные модели определённой теме, а затем позволяют машинам перерабатывать полученную информацию. Результаты могут быть как абсурдными, так и гениальными. Например, в октябре 2023 года Нобелевская премия по химии была вручена Дэвиду Бейкеру (David Baker) за исследования в области белков. Его подход, основанный на использовании ИИ для создания совершенно новых белков, ранее считался практически невозможным. Бейкер отметил, что ИИ-генерация стала основой для разработки «белков с нуля». «Мы создали 10 миллионов новых белков, которых нет в природе», — говорит учёный. При этом его лаборатория уже получила около 100 патентов, включая технологии для лечения рака и борьбы с вирусными инфекциями. Однако термин «галлюцинации» вызывает споры. Многие предпочитают называть результаты работы ИИ предположениями или перспективными идеями, поскольку они часто основаны на реальных научных данных. Например, профессор Калифорнийского технологического института Анима Анандкумар (Anima Anandkumar) считает, что использование термина «галлюцинации» может вводить в заблуждение, и отмечает, что учёные стараются избегать его. Стоит отметить, что некоторые эксперты обеспокоены тем, что темпы научных открытий замедлились за последние десятилетия. Однако сторонники ИИ утверждают, что новые возможности могут вывести науку на иной уровень. В частности, Бейкер и его коллеги видят будущее, в котором белковые катализаторы будут использовать солнечную энергию, модернизировать заводы и помогать создавать устойчивый мир. Другие учёные также разделяют этот оптимизм. «Это невероятно, насколько быстро всё развивается», — говорит Иан Хейдон (Ian C. Haydon), член команды Бейкера. А Пушмит Кохли (Pushmeet Kohli) из DeepMind подчёркивает, что ИИ способен на неожиданные, но гениальные ходы. «Мы явно имеем удивительный инструмент, который способен проявлять креативность», — заключил он. Несмотря на успехи, «галлюцинации» искусственного интеллекта остаются спорной темой. Хотя некоторые учёные видят в них полезный инструмент, другие опасаются их негативных последствий, таких как ошибки в медицинских данных. Тем не менее, научным сообществом признаётся, что потенциал ИИ для ускорения научных открытий огромен. Nvidia завершила поглощение ИИ-стартапа Run:ai за $700 млн
30.12.2024 [19:06],
Владимир Фетисов
Компания Nvidia завершила сделку по приобретению ИИ-стартапа Run:ai за $700 млн. Это произошло вскоре после того, как в этом месяце Еврокомиссия, являющаяся основным отраслевым регулятором в регионе, после проведённого расследования одобрила сделку, не найдя угроз для конкуренции. 
Источник изображения: Nvidia Ранее в этом месяце Еврокомиссия одобрила сделку по покупке Nvidia стартапа Run:ai из Тель-Авива, который предоставляет услуги по оптимизации инфраструктуры для управления рабочими нагрузками в области искусственного интеллекта. Регулятор пришёл к выводу, что слияние не станет причиной появления проблем с конкуренцией внутри Европейской экономической зоны. В рамках расследования Еврокомиссия изучала, как слияние может повлиять на укрепление позиций Nvidia на рынке графических ускорителей, где американская компания уже занимает доминирующее положение. Nvidia также лидирует в сегменте GPU для искусственного интеллекта с долей около 80 %. Несмотря на это, регулятор одобрил сделку, поскольку деятельность Nvidia и Run:ai не пересекается. Также отмечалось, что израильский стартап в настоящее время не занимает значимой позиции на рассматриваемом рынке. Одновременно с заявлением о закрытии сделки Run:ai объявила о намерении сделать код своего программного обеспечения открытым. «Хотя в настоящее время Run:ai поддерживает только графические ускорители Nvidia, открытый исходный код программного обеспечения позволит расширить его доступность на всю экосистему искусственного интеллекта», — говорится в заявлении стартапа. Энтузиасты запустили современную ИИ-модель Llama на древнем ПК с Pentium II и Windows 98
30.12.2024 [17:19],
Владимир Фетисов
Специалисты из EXO Labs сумели запустить довольно мощную большую языковую модель (LLM) Llama на 26-летнем компьютере, работающем под управлением операционной системы Windows 98. Исследователи наглядно показали, как загружается старый ПК, оснащённый процессором Intel Pentium II с рабочей частотой 350 МГц и 128 Мбайт оперативной памяти, после чего осуществляется запуск нейросети и дальнейшее взаимодействие с ней. 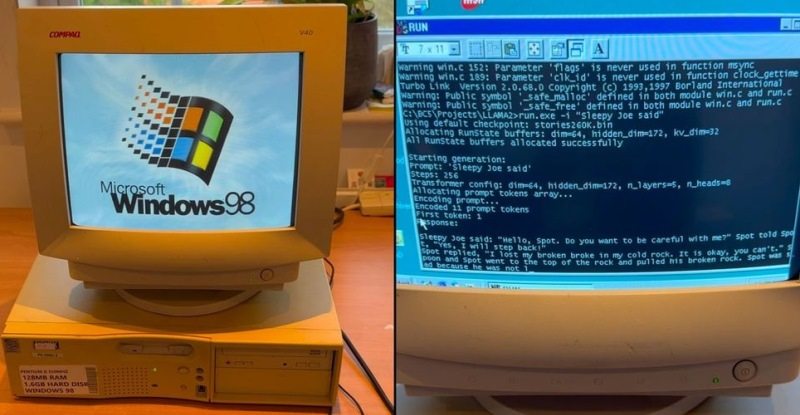
Источник изображения: GitHub Для запуска LLM специалисты EXO Labs задействовали собственный интерфейс вывода для алгоритма Llama98.c, который создан на базе движка Llama2.c, написанного на языке программирования C бывшим сотрудником OpenAI и Tesla Андреем Карпатым (Andrej Karpathy). После загрузки алгоритма его попросили создать историю о Сонном Джо. Удивительно, но ИИ-модель действительно работает даже на таком древнем ПК, причём история пишется с хорошей скоростью. Загадочная организация EXO Labs, сформированная исследователями и инженерами из Оксфордского университета, вышла из тени в сентябре этого года. Согласно имеющимся данным, она выступает за открытость и доступность технологий на базе искусственного интеллекта. Представители организации считают, что передовые ИИ-технологии не должны находиться в руках горстки корпораций, как это происходят сейчас. В дальнейшем они рассчитывают «построить открытую инфраструктуру для обучения передовых ИИ-моделей, что позволит любому человеку запускать их где угодно». Демонстрация возможности запуска LLM на древнем ПК, по их мнению, доказывает то, что ИИ-алгоритмы могут работать практически на любых устройствах. В своём блоге энтузиасты рассказали, что для реализации поставленной задачи на eBay был приобретён старый ПК с Windows 98. Затем, подключив устройство в сеть с помощью разъёма Ethernet, они через FTP сумели передать в память устройства нужные данные. Вероятно, компиляция современного кода для Windows 98 оказалась более сложной задачей, решить которую помогла опубликованная на GitHub работа Андрея Карпатого. В конечном счёте удалось добиться скорости генерации текста в 35,9 токенов в секунду при использовании LLM размером 260K с архитектурой Llama, что весьма неплохо, учитывая скромные вычислительные возможности устройства. ИИ будет манипулировать людьми, чтобы они принимали нужные решения
30.12.2024 [12:49],
Владимир Мироненко
Инструменты искусственного интеллекта (ИИ) могут использоваться для манипулирования онлайн-аудиторией с целью принятия различных решений — от того, что покупать, до того, за кого голосовать, сообщается в исследовании команды учёных Кембриджского университета, посвящённом новому рынку «цифровых сигналов намерений», известному как «экономика намерений». 
Источник изображения: Christin Hume По словам исследователей Центра будущего интеллекта Леверхалма (LCFI) при Кембриджском университете, «экономика намерений» является преемницей «экономики внимания», в которой социальные сети удерживают пользователей на своих платформах и показывают им рекламу. В рамках «экономики внимания» рекламодатели могут покупать доступ к вниманию пользователей в настоящем через торги в реальном времени на рекламных биржах или приобретать его для будущих акций, например, арендуя рекламные площади на месяц вперёд. «В течение десятилетий внимание было валютой интернета, — говорит доктор Джонни Пенн (Jonnie Penn) из LCFI. — Обмен вниманием с социальными медиа-платформами, такими как Facebook✴ и Instagram✴, привёл к развитию онлайн-экономики». В исследовании утверждается, что большие языковые модели (LLM), используемые в работе таких инструментов ИИ, как чат-бот ChatGPT, будут применяться для «предвидения и управления» пользователями на основе «намеренных, поведенческих и психологических данных». При «экономике намерений» компании в сфере ИИ будут продавать сведения о мотивах пользователей, начиная от планов проживания в отеле и заканчивая мнениями о политическом кандидате, тому, кто предложит самую высокую цену. «В экономике намерений LLM может с минимальными затратами использовать ритм общения пользователя, его политические взгляды, словарный запас, возраст, пол, предпочтения и даже склонность к лести. Эти данные в сочетании с посредническими ставками позволят максимизировать вероятность достижения заданной цели (например, продажи билета в кино)», — говорится в исследовании. Указывается также, что в таком мире модели ИИ будут направлять обсуждение в интересах рекламодателей, предприятий и других третьих лиц. В исследовании утверждается, что рекламодатели смогут использовать инструменты генеративного ИИ для создания индивидуальной онлайн-рекламы. В качестве примера приводится модель ИИ под названием Cicero компании Meta✴, которая достигла «человеческого уровня» в способности играть в настольную игру **Diplomacy**, где успех зависит от предсказания намерений оппонента. Модели ИИ смогут настраивать свои результаты в ответ на «потоки входящих данных, сгенерированных пользователями», указывается в исследовании. Они смогут выделять личную информацию из повседневного общения и даже «направлять» разговор таким образом, чтобы получать больше личных данных. В исследовании цитируется сообщение исследовательской группы Cicero о том, что «агент [ИИ] может научиться подталкивать своего собеседника к достижению определённой цели». Также исследователи прогнозируют сценарий, при котором Meta✴ будет выставлять на аукцион намерения пользователей, например, забронировать ресторан, рейс или отель. Хотя уже существует отрасль, занимающаяся прогнозированием и торгами на основе поведения человека, модели ИИ преобразуют этот процесс в «высококачественный, динамичный и персонализированный формат», подчеркнули учёные из LCFI. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться