|
Опрос
|
реклама
Быстрый переход
Человекоподобные роботы станут массовыми уже через несколько лет, заявили главы Nvidia и XPeng
20.03.2025 [13:41],
Алексей Разин
Сфера искусственного интеллекта и робототехника развиваются синхронно, поскольку от степени успеха первой будут зависеть темпы прогресса второй. Глава Nvidia считает, что на производстве человекоподобные роботы получат распространение менее чем через пять лет, а глава XPeng убеждён, что в домохозяйствах они освоятся примерно лет через пять. 
Источник изображения: XPeng Как отмечает Reuters, свои заявления основатель Nvidia Дженсен Хуанг (Jensen Huang) сделал с трибуны GTC 2025 в Калифорнии. По его мнению, сроки появления человекоподобных роботов на рынке в достаточных количествах измеряются не пятью годами, а меньшим периодом. Впрочем, при этом пионерами внедрения таких роботов всё же станут предприятия, а не домохозяйства. На производстве в жёстко контролируемой и стандартизованной среде применять роботов гораздо проще и безопаснее, чем в домашней обстановке. О стоимости человекоподобных роботов глава Nvidia рассуждает достаточно свободно: «Стоимость очень, очень просто определить. Средняя ставка аренды человекоподобного робота сейчас достигает $100 000, и я думаю, что это очень хорошая экономика». По всей видимости, в такую сумму обходится годовая аренда передового человекоподобного робота, хотя период и не конкретизируется первоисточником. Напомним, что Илон Маск (Elon Musk) хочет сделать своих человекоподобных роботов Tesla Optimus максимально доступными — по $20 000 за штуку в неограниченное по времени пользование. Один из президентов китайского стартапа XPeng Брайан Гу Хонди (Brian Gu Hongdi) на этой неделе также подчеркнул, что его компания будет в первую очередь внедрять человекоподобных роботов в коммерческом секторе, но уже в ближайшие несколько лет ёмкость рынка таких роботов превысит сегмент автомобильного транспорта. Прежде чем человекоподобные роботы получат распространение в быту, однако, пройдёт не менее пяти лет, по мнению руководства XPeng. К концу следующего года китайская компания наладит массовый выпуск не только человекоподобных роботов, но и летающих электромобилей. В ближайшие 20 лет XPeng намеревается потратить на разработку человекоподобных роботов не менее $6,9 млрд. В августе компания представила процессор Turing AI собственной разработки, который найдёт применение как в системах автопилота, так и в роботах данной марки. Машины с автономностью четвёртого уровня XPeng начнёт выпускать в 2026 году. Nvidia перестала быть геймерской компанией, а стала «фабрикой ИИ»
20.03.2025 [10:50],
Алексей Разин
Бессменный генеральный директор Nvidia, который на протяжении более тридцати лет ведёт компанию к успеху, на разных этапах этого пути провозглашает новый статус своего детища. На GTC 2025, окрылённый успехом Nvidia на рынке компонентов для ИИ, он заявил, что компания является провайдером инфраструктуры для соответствующих систем. 
Источник изображения: Nvidia «Nvidia является компанией, связанной с инфраструктурой ИИ. Мы инфраструктурная компания, а не просто "купи-продай чипы"», — высказался Дженсен Хуанг (Jensen Huang) на пресс-конференции в Калифорнии, которая последовала за его выступлением с докладом на открытии GTC 2025. Необходимость заблаговременно делиться подробностями относительно будущих продуктов глава Nvidia пояснил на примере контраста с другими компаниями. По его словам, никто из производителей смартфонов не анонсирует по четыре последовательно выходящие модели смартфонов за раз. Это просто не имеет смысла, как подчеркнул Хуанг. «Инфраструктура ИИ — это не то, что ты покупаешь сегодня и вводишь в строй завтра. Это то, во что ты вкладываешь средства на протяжении двух лет заранее и имеешь план на весь этот двухлетний период, и надеешься, что сможешь развернуть достаточно быстро», — сообщил глава Nvidia. Именно с учётом таких сроков компания представила накануне вычислительные архитектуры, которые лягут в основу продуктов, выпускаемых в период с 2026 по 2028 годы. «Все должны располагать одинаковой информацией и планировать свои действия сообща, чтобы построить инфраструктуру для всего мира», — добавил Хуанг. Глава компании также назвал Nvidia «фабрикой ИИ», которая помогает клиентам зарабатывать деньги: «Теперь мы — фабрика искусственного интеллекта. Это значит, что фабрика помогает клиентам зарабатывать деньги. Наши фабрики напрямую приносят клиентам доход». «Уровень бизнеса гораздо выше, чем ранее. Конкуренция гораздо выше, чем ранее. Прав на ошибку у всех наших клиентов значительно меньше. Это рассчитанный на несколько лет инвестиционный цикл, поэтому речь идёт о сотнях миллиардов долларов», — пояснил гендиректор Nvidia возросший уровень ответственности компании перед клиентами. Влияние 20-процентной пошлины в США на бизнес Nvidia основателя компании пока не особо пугает. Сеть поставщиков продукции Nvidia достаточно развита, по его словам. Это не только Тайвань, но и Мексика, а также Вьетнам. Они распределены по многим местам. В ближайшее время всё будет зависеть от того, какие из стран подвергнутся повышенным пошлинам. Значительного влияния подобные изменения на финансовые результаты деятельности Nvidia всё равно пока не окажут, как убеждено руководство компании. В долгосрочной же перспективе Nvidia будет развивать производство своей продукции на территории США. «У нас есть возможность многое изготавливать в США. Не всё, но многое», — пояснил Дженсен Хуанг, добавив, что TSMC уже снабжает компанию выпускаемыми в штате Аризона компонентами. Намерения TSMC вложить $165 млрд на развитие шести предприятий на территории США внушают руководству Nvidia уверенность в успехе локализации производства продукции этой марки. В интервью Financial Times Дженсен Хуанг заявил, что Nvidia готова в ближайшие четыре года потратить сотни миллиардов долларов на покупку продукции американского производства для своих нужд. Во всяком случае, на территории США производить необходимые Nvidia изделия могут тайваньские компании Foxconn и TSMC. По состоянию на конец января прошлого года Nvidia располагала обязательствами на закупку продукции сторонних компаний на общую сумму $20 млрд. Соответственно, за несколько лет с учётом роста рынка соответствующие затраты в одних только США легко могут возрасти на порядок. Meta✴ AI добрался до Европы, но с ограничениями и без обучения на данных пользователей
20.03.2025 [10:29],
Дмитрий Федоров
Meta✴ AI появится в Европе спустя почти год после приостановки его развёртывания в регионе из-за регуляторных ограничений. Начиная с этой недели, ИИ-ассистент компании станет доступен в приложениях WhatsApp, Facebook✴, Instagram✴ и Messenger для пользователей 41 европейской страны и 21 зарубежной территории. Однако функциональность ИИ-чат-бота будет ограничена только текстовым общением. 
Источник изображения: Farhat Altaf / Unsplash Meta✴ AI появился в США ещё в 2023 году, однако выход на европейский рынок пришлось приостановить после вмешательства ирландской Комиссии по защите данных (Data Protection Commission, DPC). Тогда регулятор потребовал от компании отложить обучение ИИ-модели на пользовательском контенте, опубликованном в Facebook✴ и Instagram✴. Помимо этого, Meta✴ приостановила запуск своей флагманской большой языковой модели Llama в Европейском союзе (ЕС) из-за нормативных ограничений. Теперь Meta✴ AI выходит на европейский рынок, но с серьёзными ограничениями. ИИ-чат-бот сможет помогать европейским пользователям в генерации идей, планировании поездок и поиске информации, опираясь на данные из интернета. Европейцы также смогут использовать Meta✴ AI для отображения определенных видов контента в своей ленте Instagram✴. Однако они не смогут использовать ИИ для создания или редактирования изображений, а также задавать вопросы о фотографиях. Meta✴ подчёркивает, что для обучения ИИ-модели не использовались данные пользователей из ЕС. «Этот запуск стал результатом почти года интенсивного взаимодействия с различными европейскими регуляторами, и пока мы предлагаем в регионе только текстовую модель, которая не была обучена на данных, полученных от пользователей из ЕС. Мы продолжим сотрудничать с регулирующими органами, чтобы люди в Европе имели доступ к инновациям Meta✴ в области искусственного интеллекта, которые уже доступны для всего остального мира», — заявила представитель Meta✴ Элли Хитрик (Ellie Heatrick). В ноябре прошлого года компания Meta✴ начала внедрять некоторые ИИ-функции в свои смарт-очки Ray-Ban Meta✴ в ЕС, но в настоящее время эти устройства не поддерживают ИИ-функции, которые позволяют европейцам спрашивать смарт-очки о том, что они видят. Тем не менее компания подчёркивает, что продолжит работать над достижением паритета в функциональности между европейской и американской версиями Meta✴ AI, постепенно расширяя его возможности. Исследователи нашли способ масштабирования ИИ без дополнительного обучения, но это не точно
19.03.2025 [23:34],
Анжелла Марина
Группа исследователей из Google и Калифорнийского университета в Беркли предложила новый метод масштабирования искусственного интеллекта (ИИ). Речь идёт о так называемом «поиске во время вывода», который позволяет модели генерировать множество ответов на запрос и выбирать лучший из них. Этот подход может повысить производительность моделей без дополнительного обучения. Однако сторонние эксперты усомнились в правильности идеи. 
Источник изображения: сгенерировано AI Ранее основным способом улучшения ИИ было обучение больших языковых моделей (LLM) на всё большем объёме данных и увеличение вычислительных мощностей при запуске (тестировании) модели. Это стало нормой, а точнее сказать, законом для большинства ведущих ИИ-лабораторий. Новый метод, предложенный исследователями, заключается в том, что модель генерирует множество возможных ответов на запрос пользователя и затем выбирает лучший. Как отмечает TechCrunch, это позволит значительно повысить точность ответов даже у не очень крупных и устаревших моделей. В качестве примера учёные привели модель Gemini 1.5 Pro, выпущенную компанией Google в начале 2024 года. Утверждается, что, используя технику «поиска во время вывода» (inference-time search), эта модель обошла мощную o1-preview от OpenAI по математическим и научным тестам. Один из авторов работы, Эрик Чжао (Eric Zhao), подчеркнул: «Просто случайно выбирая 200 ответов и проверяя их, Gemini 1.5 однозначно обходит o1-preview и даже приближается к o1». Тем не менее, эксперты посчитали эти результаты предсказуемыми и не увидели в методе революционного прорыва. Мэтью Гуздиал (Matthew Guzdial), исследователь ИИ из Университета Альберты, отметил, что метод работает только в тех случаях, когда можно чётко определить правильный ответ, а в большинстве задач это невозможно. С ним согласен и Майк Кук (Mike Cook), исследователь из Королевского колледжа Лондона. По его словам, новый метод не улучшает способность ИИ к рассуждениям, а лишь помогает обходить существующие ограничения. Он пояснил: «Если модель ошибается в 5 % случаев, то, проверяя 200 вариантов, эти ошибки просто станут более заметны». Основная проблема состоит в том, что метод не делает модели умнее, а просто увеличивает количество вычислений для поиска наилучшего ответа. В реальных условиях такой подход может оказаться слишком затратным и малоэффективным. Несмотря на это, поиск новых способов масштабирования ИИ продолжается, поскольку современные модели требуют огромных вычислительных ресурсов, а исследователи стремятся найти методы, которые позволят повысить уровень рассуждений ИИ без чрезмерных затрат. «Это отвратительно, и вам должно быть стыдно»: первое за три года дополнение к Ark: Survival Evolved возмутило игроков трейлером, сгенерированным ИИ
19.03.2025 [15:51],
Дмитрий Рудь
В рамках конференции GDC 2025 состоялся анонс первого за три года нового дополнения к многопользовательскому симулятору выживания с динозаврами Ark: Survival Evolved. Презентация оказалась омрачена необычным скандалом. 
Источник изображений: Snail Games Расширение называется Ark: Aquatica и позиционируется как «амбициозное» приключение, 95 % которого будет происходить под водой. Обещают 17 новых существ, предметы, испытания и «интригующий сюжет» за пределами канона Ark. Анонс сопровождался кинематографическим трейлером, однако вместо ажиотажа он вызвал у фанатов лишь гнев и отторжение: минутный ролик практически целиком создан с помощью ИИ. Видео уже скрыли из поисковой выдачи на YouTube, однако оно всё ещё доступно по ссылке. На момент публикации материала трейлер имеет 165 лайков и в 25 раз больше дизлайков (свыше четырёх тысяч). Пользователи в комментариях осудили использование ИИ для создания ролика (тем более в таком объёме). «Это отвратительно, и вам должно быть стыдно», — считает специализирующийся на Ark блогер Syntac с 1,6 млн подписчиков. Геймплейный трейлер Ark: Aquatica Примечательно, что ещё до публикации скандального трейлера Studio Wildcard (Ark: Survival Ascended, Ark 2) поспешила сообщить о своей непричастности к Ark: Aquatica. Разработкой дополнения занимается Snail Games. Ark: Aquatica выйдет на ПК в июне текущего года. Тем временем Studio Wildcard готовит аддон Ark: Lost Colony для Ark: Survival Ascended (заявлен на ноябрь), который должен стать связующим звеном с Ark 2. Дженсен Хуанг заявил, что рассуждающий ИИ спасёт Nvidia от падения продаж чипов из-за эффекта DeepSeek
19.03.2025 [13:28],
Алексей Разин
Выступление основателя и бессменного руководителя Nvidia Дженсена Хуанга (Jensen Huang) на GTC 2025 длилось более двух с половиной часов, поэтому времени для комментариев с оценкой текущего положения дел в отрасли у него было предостаточно. Глава компании убеждён, что к смене приоритетов в сфере искусственного интеллекта она прекрасно готова. 
Источник изображения: Nvidia Прежде всего, Хуанг потрудился разубедить инвесторов в способности новых игроков рынка типа DeepSeek снизить спрос на компоненты для инфраструктуры искусственного интеллекта, поскольку неплохие по своей эффективности языковые модели удаётся создавать с заметно меньшими затратами на обучение. «Почти весь мир всё понял неправильно», — охарактеризовал глава Nvidia реакцию рынка на прорыв DeepSeek. «Количество вычислительных ресурсов, которое требуется для работы агентского ИИ с функцией рассуждения, как минимум в 100 раз больше, чем мы рассчитывали год назад», — заявил Дженсен Хуанг. По его словам, на данном этапе развития систем ИИ компания ставит перед собой два приоритета: обеспечить их работу с максимальным количеством пользовательских обращений и максимально ускорить предоставление ответов. По словам главы Nvidia, только продукция этой марки способна одновременно решить обе задачи. «Если вы будете слишком долго отвечать на вопрос, клиент просто не вернётся к системе. В сфере поиска информации в сети именно так и происходит», — заверил Хуанг. Nvidia выпустила программный мозг для человекоподобных роботов будущего — Isaac GR00T N1
19.03.2025 [12:40],
Павел Котов
Nvidia сообщила о выходе Isaac GR00T N1 — открытой и настраиваемой модели искусственного интеллекта, которая поможет в создании человекоподобных роботов. «Настала эпоха робототехники общего назначения. С Nvidia Isaac GR00T N1 и новыми фреймворками для генерации данных и обучения роботов создатели робототехники по всему миру откроют новый рубеж в эпоху ИИ», — заявил глава компании Дженсен Хуанг (Jensen Huang). 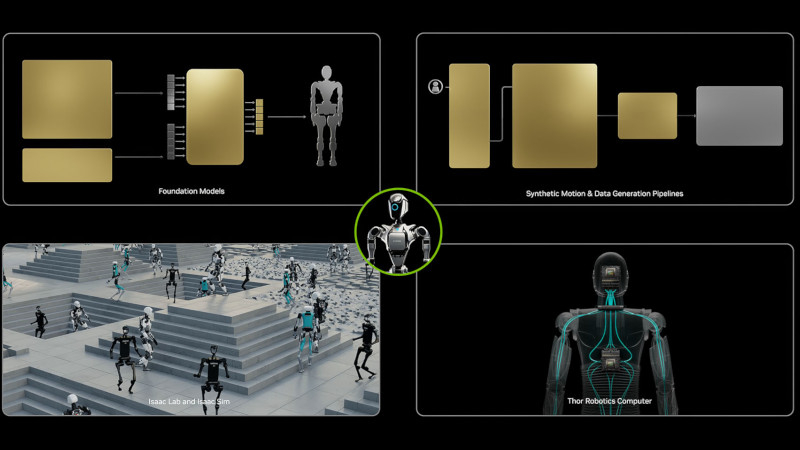
Источник изображения: nvidia.com В ходе выступления на мероприятии GTC 2025 господин Хуанг продемонстрировал человекоподобного робота 1X NEO Gamma, умеющего производить уборку в автономном режиме — в этом ему помогла модель GR00T N1 с постобучением. «Будущее гуманоидов — за адаптивностью и обучением. Модель Nvidia GR00T N1 обеспечила крупный прорыв в области рассуждений и навыков роботов. С минимальным набором данных после обучения мы смогли полностью развернуть её на NEO Gamma, продвинувшись в своей миссии по созданию роботов, которые выступают не инструментами, а компаньонами, способными оказывать людям значимую, безмерную помощь», — прокомментировал проект гендиректор 1X Technologies Бернт Бёрних (Bernt Børnich). Опробовать модель смогли также в Boston Dynamics, Agility Robotics, Mentee Robotics и Neura Robotics. Об этой работе Nvidia впервые рассказала в прошлом году — тогда она носила название Project GR00T (Generalist Robot 00 Technology). Обновлённая GR00T N1 имеет двухсистемную архитектуру по образу человеческого мышления. «Первая система» (System 1), как её называет Nvidia — это «действующая модель с быстрым мышлением» (fast-thinking action model), аналогичная человеческим рефлексам и интуиции. Её обучение проводилось на основе данных, собранных в ходе демонстраций с участием человека, и синтетических данных, смоделированных при помощи платформы Nvidia Omniverse. «Вторая система» (System 2) — визуально-языковая или «медленно думающая» модель. Она «строит рассуждения об окружении и полученных инструкциях, чтобы планировать действия». Составленный план передаётся в «первую систему», которая преобразует его в «точные, непрерывные движения робота». Это могут быть захват или перемещение предметов одной или двумя руками, а также более сложные многоэтапные задачи, для которых необходима комбинация основных навыков. GR00T N1 прошла предварительное обучение и овладела механизмами рассуждений и навыков общего назначения для человекоподобных роботов; разработчикам также предоставляются средства, чтобы провести её дополнительную настройку, скорректировать поведение для конкретных потребностей и провести дополнительное обучение на основе данных, собранных в демонстрациях с участием человека или в моделировании. Nvidia открыла доступ к данным обучения и сценариям оценки задач GR00T N1 на платформах Hugging Face и GitHub. Asus представила настольный мини-суперкомпьютер Ascent GX10 за $2999
19.03.2025 [11:38],
Павел Котов
Asus анонсировала мини-суперкомпьютер Ascent GX10 — собственный вариант Nvidia Project Digits или как он теперь называется Nvidia DGX Spark. Компактная машина на базе Nvidia GB10 Grace Blackwell Superchip предлагает производительность до 1000 TOPS в рабочих нагрузках, связанных с искусственным интеллектом. 
Источник изображения: asus.com Как и эталонный DGX Spark, Asus Ascent GX10 представляет собой мини-ПК, который свободно размещается на столе — для начала работы достаточно подключить к нему монитор, клавиатуру и мышь. Полный список технических характеристик в пресс-релизе производителя не приводится — компания ограничилась лишь основными. Платформа Nvidia GB10 оборудована центральным процессором Nvidia Grace и графикой Blackwell. Центральный процессор выполнен на базе архитектуры Arm — он включает в себя десять ядер Cortex-X925 и десять Cortex-A725; графика подключена к нему через высокоскоростное соединение NVLink-C2C. Asus Ascent GX10 предлагает производительность 1 Пфлопс или 1000 Тфлопс (FP4). Компактный компьютер располагает 128 Гбайт унифицированной памяти, что позволяет запускать на нём ИИ-модели с 200 млрд параметров. Спецификации памяти не раскрываются, но они должны соответствовать эталонному Project Digits, что означает LPDDR5x для ОЗУ, поддержку твердотельных накопителей M.2 NVMe объёмом до 4 Тбайт и аппаратное шифрование. Высокоскоростной сетевой интерфейс Nvidia ConnectX позволяет объединять несколько Asus Ascent GX10 для запуска более крупных моделей, например, Meta✴ Llama 3.1, у которой до 405 млрд параметров. Прочие интерфейсы в пресс-релизе не указываются и на официальном изображении компьютера не просматриваются; в распоряжении DGX Spark значились четыре USB4 Type-C, Wi-Fi, порт Ethernet и один HDMI 2.1a для подключения монитора. Asus предложит Ascent GX10 по цене в $2999 — для сравнения, DGX Spark поступит в продажу в мае за $3999. Nvidia представила Blackwell Ultra с 288 Гбайт HBM3e — ИИ-ускоритель «для эпохи рассуждений»
19.03.2025 [11:20],
Андрей Созинов
Компания Nvidia в рамках открытия конференции GTC 2025 официально анонсировала ускоритель вычислений для центров обработки данных Blackwell Ultra B300, суперчип Grace Blackwell Ultra GB300, а также различные системы на его основе. Новинка «создана для эпохи рассуждений», то есть для новейших, более сложных и требовательных к ресурсам ИИ-моделей (LLM), способных размышлять над задачами. 
Источник изображений: Nvidia Nvidia уже традиционно не стала раскрывать всех деталей о новинке. В компании лишь отметили, что графические процессоры Blackwell Ultra (в составе GB300 и B300) физически отличаются от чипов Blackwell (в GB200 и B200). Отметим, что Blackwell Ultra B300 представляет собой классический ускоритель на GPU, тогда как Grace Blackwell Ultra GB300 — это связка из Arm-процессора Grace с 72 ядрами Neoverse V2 и двух графических процессоров Blackwell Ultra. 
Плата с парой CPU Grace и четырьмя Blackwell Ultra Nvidia отмечает увеличенный на 50 % объём набортной памяти. Blackwell Ultra получил 288 Гбайт HBM3e, что будет как раз кстати при работе с особенно крупными LLM. Объём памяти вырос благодаря использованию новых 12-ярусных стеков HBM3e — в Blackwell B200 применяются восьмиярусные стеки HBM3e, обеспечивающие 192 Гбайт памяти. По словам Nvidia, производительность Blackwell Ultra должна в 1,5 раза превышать производительность Blackwell в запуске уже обученных моделей (FP4 inference). Компания заявляет о производительности в 15 Пфлопс для вычислений FP4, а также о 30 Пфлопс для разреженных FP4. Для оригинального ускорителя Blackwell B200 эти показатели составляли 10 и 20 Пфлопс соответственно. 
GB300 NVL72 Nvidia предложит несколько готовых систем на базе новых ускорителей вычислений, которые начнут поступать в продажу во второй половине 2025 года. GB300 NVL72 — фактически это готовая серверная стойка, объединяющая 72 графических процессора Blackwell Ultra и 36 центральных процессоров Grace. Новинка, как и её предшественница GB200 NVL72, оснащена системой жидкостного охлаждения, использует NVLink пятого поколения, модули Nvidia ConnectX-8 SuperNIC и предлагает 18 Тбайт оперативной памяти LPDDR5X. Производительность достигает 1100 Пфлопс в FP4-вычислениях и до 1400 Пфлопс в разреженных вычислениях. 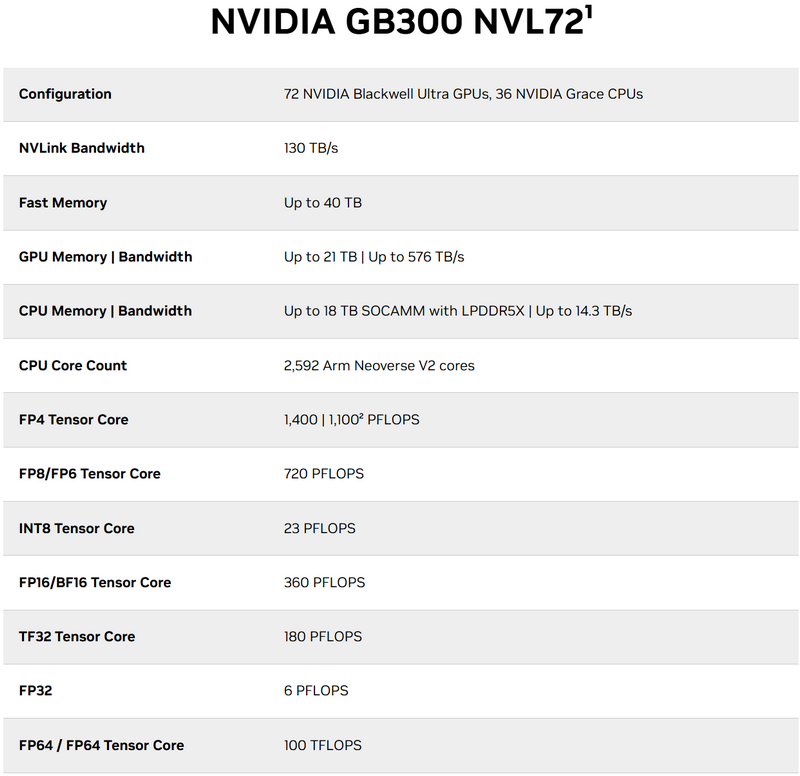 Nvidia особенно отмечает применение интерконнекта NVLink 5-го поколения, который соединяет отдельные чипы для создания «одного большого GPU». Он обладает пропускной способностью 1,8 Тбайт/с на GPU, а общая пропускная способность достигает 130 Тбайт/с. Начиная с Blackwell, NVLink также может использоваться в качестве интерфейса для соединения нескольких стоек, что ранее осуществлялось через InfiniBand со скоростью 100 Гбайт/с. Поэтому Nvidia заявляет о 18-кратном увеличении скорости для этого конкретного сценария. 
Blackwell Ultra DGX SuperPOD В домен NVLink можно подключить до 576 графических процессоров. Собственно, такую систему Nvidia тоже предложит — Blackwell Ultra DGX SuperPOD. Это кластер из восьми стоек NVL72, который включает 288 процессоров Grace, 576 чипов Blackwell Ultra, 300 Тбайт памяти HBM3e и FP4-производительность в 11,5 Экзафлопс. Наконец, Nvidia представила систему HGX B300 NVL16 — решение для тех, кому вместо Arm-процессора Grace нужен чип на x86-совместимой архитектуре. В системе имеется 16 графических процессоров B300A, соединённые через NVLink, и центральные x86-процессоры. Nvidia не уточняет, какие именно CPU применены, но в прошлом использовались чипы как от AMD, так и от Intel.  Ускорители вычислений и системы на базе Blackwell Ultra появятся на рынке во второй половине текущего года. Их предложат все крупные производители серверов, а также новинки будут доступны у основных облачных провайдеров. ИИ-модели Llama скачали более миллиарда раз, похвастался Марк Цукерберг
18.03.2025 [18:40],
Павел Котов
Количество загрузок открытых моделей искусственного интеллекта Llama достигло 1 млрд, сообщил глава компании Meta✴ Марк Цукерберг (Mark Zuckerberg). По состоянию на начало декабря 2024 года этот показатель составлял 650 млн, что соответствует росту более чем на 50 % за квартал. 
Источник изображения: Stefan Cosma / unsplash.com Модели семейства Llama лежат в основе ИИ-помощника Meta✴ AI, который присутствует на различных платформах компании, в том числе в Facebook✴, Instagram✴ и WhatsApp — Meta✴ стремится выстроить обширную систему продуктов в области ИИ. Компания бесплатно по собственной лицензии предоставляет как сами модели, так и инструменты для их тонкой настройки и кастомизации. Эти модели имеют некоторые ограничения для использования в коммерческих целях, но активно применяются в различных продуктах — например, оператором связи AT&T и потоковой службой Spotify. Впрочем, не обходится и без сложностей: сейчас Meta✴ пытается отбиться от судебного иска, в рамках которого её обвиняют в обучении ИИ на защищённых авторским правом материалах; в ЕС компанию заставили отложить, а то и вовсе отменить выпуск некоторых моделей из-за сомнений в отношении конфиденциальности данных. Кроме того, модели DeepSeek оказались по ряду критериев лучше, чем Llama. Meta✴ пытается воспользоваться опытом DeepSeek по снижению расходов на обучение ИИ. В этом году американская компания намеревается потратить на ИИ не меньше $65 млрд, а в ближайшие месяцы она хочет выпустить несколько моделей Llama, включая рассуждающие. Meta✴ также, вероятно, ведёт разработку ИИ-агентов — систем, способных самостоятельно выполнять сложные последовательности действий. Некоторые из продуктов она может представить на LlamaCon — первой проводимой Meta✴ конференции разработчиков генеративного ИИ; она намечена на 29 апреля. Сотни знаменитостей подписали открытое письмо с требованием запретить «свободу обучения» ИИ
18.03.2025 [18:37],
Сергей Сурабекянц
Более 400 актёров, музыкантов, режиссёров, писателей и представителей других творческих профессий подписали открытое письмо. Они призвали администрацию США запретить обучение моделей ИИ на защищённых авторским правом работах. Письмо стало ответом на предлагаемую OpenAI и Google «свободу обучения» моделей ИИ без получения разрешения от правообладателей и соответствующей компенсации. 
Источник изображения: unsplash.com OpenAI заявила, что смягчение законов об авторском праве будет способствовать «свободе обучения» и поможет защитить национальную безопасность Америки. OpenAI и Google уверены, что это поможет «укрепить лидерство Америки» в конкурентной борьбе с Китаем в области разработки ИИ. Звёзды, в свою очередь, не видят причин отменять защиту авторских прав, чтобы помочь улучшить модели ИИ: «Мы твёрдо убеждены, что глобальное лидерство Америки в области ИИ не должно достигаться за счёт наших важнейших творческих отраслей». В открытом письме творческие работники утверждают, что «свобода обучения» ИИ подорвёт экономическую и культурную мощь страны и ослабит защиту авторских прав, в то время как Google и OpenAI получат исключительные права на «свободную эксплуатацию творческих и образовательных отраслей Америки, несмотря на их [и так] значительные доходы и доступные средства». «Америка стала мировым культурным центром не случайно, — говорится в письме. — Наш успех напрямую обусловлен нашим фундаментальным уважением к интеллектуальной собственности и авторским правам, которое вознаграждает творческий риск талантливых и трудолюбивых американцев из каждого штата». В письме отмечается, что индустрия развлечений Америки предоставляет работу 2,3 млн граждан США и ежегодно выплачивает $229 млрд в виде заработной платы, а также обеспечивает «основу для американского демократического влияния и мягкой силы за рубежом». Среди подписавших письмо протеста фигурируют такие знаменитости мирового масштаба, как Бен Стиллер (Ben Stiller), Кейт Бланшетт (Cate Blanchett), Пол Маккартни (Paul McCartney), Гильермо дель Торо (Guillermo del Toro), Джозеф Гордон-Левитт (Joseph Gordon-Levitt) и многие другие, не менее известные представители творческих профессий. 
Источник изображения: techspot.com Знаменитости протестуют против этой проблемы не только в США. Великобритания собирается изменить закон об авторском праве, что позволит обучать модели ИИ без разрешения владельцев авторских прав и оплаты, если создатели заранее не откажутся от этого. В знак протеста группа из 1000 музыкантов выпустила «тихий» альбом «Is this what we want?» («Разве этого мы хотим?»), содержащий лишь записи пустых студий и концертных залов. Помимо этого, на первых полосах национальных СМИ был опубликован лозунг музыкантов «Make it fair» («Давайте сделаем по-справедливому») с призывом к диалогу индустрии с разработчиками ИИ. Tencent выпустила пять открытых ИИ-моделей для генерации 3D-объектов для игр и не только
18.03.2025 [18:06],
Павел Котов
Компания Tencent выпустила новые системы искусственного интеллекта, способные создавать трёхмерные объекты по текстовым запросам. Все они будут доступны бесплатно с открытыми кодами. 
Источник изображения: tencent.com Пять генераторов трёхмерных объектов основаны на модели её собственной разработки Hunyuan3D-2.0 — компания намеревается сделать все их открытыми для пользователей. Новые ИИ-системы смогут использоваться в связке с фирменным 3D-движком Tencent для игр и другого контента. Сегодня крупнейшие технологические компании от OpenAI до Alibaba с поразительной скоростью выпускают новые модели ИИ. Появление стартапа DeepSeek, который добился успехов на уровне мировых лидеров отрасли при существенно сниженных затратах, только подстегнуло этот процесс. Ранее китайский поисковый гигант Baidu выпустил Ernie 4.5 — обновлённый вариант своей флагманской ИИ-модели, а также Ernie X1 – прямого конкурента рассуждающей DeepSeek R1. Tencent также считает, что не имеет права быть в позиции догоняющей. В феврале компания представила модель Hunyuan Turbo S, которая не рассуждает подолгу, как DeepSeek R1, а даёт максимально быстрые ответы. Tencent также похвасталась, что смогла резко снизить стоимость развёртывания ИИ. Генераторы 3D-объектов — область, близкая к основному для компании игровому бизнесу; сейчас студии активно внедряют ИИ на всех этапах разработки, сокращая время вывода новых игр на рынок. Собственными проектами Tencent не ограничивается — она интегрировала DeepSeek R1 в широкий спектр своих продуктов от поиска в WeChat до чат-бота Yuanbao. Последний в марте даже смог ненадолго обогнать саму DeepSeek и стать самым скачиваемым приложением для iPhone в Китае. Провал с внедрением ИИ в Siri грозит Apple большими и затяжными потерями
18.03.2025 [16:46],
Павел Котов
Информация о том, что выход обновлённого варианта голосового помощника Siri задержится ещё на год, может дорого обойтись компании Apple. Рост продаж iPhone замедляется, и отставания в области искусственного интеллекта в период его мирового бума инвесторы компании не простят, пишет The Wall Street Journal.  Самая дорогая компания в мире всё отчётливее сталкивается с новой реальностью: положение в сегменте iPhone оставляет желать лучшего, ведь во второй половине 2024 года его продажи выросли лишь на 1,6 % в годовом исчислении. Бизнес, на который приходится более половины выручки компании, слабеет, но из-за высокого доверия к бренду акции Apple до недавнего времени демонстрировали лучшие результаты, чем у многих других игроков технологической отрасли. Однако этому доверию, похоже, приходит конец — известие о том, что компания решила перенести развёртывание функций генеративного ИИ для голосового помощника Siri, уже оказывает негативное влияние на её акции. Представитель Apple 7 марта признал, что для внедрения этих функций потребуется больше времени, и их дебют состоится лишь в 2026 году. Это означает, что с выходом новых iPhone этой осенью Apple не сможет значительно расширить набор функций ИИ. На минувшей неделе акции компании потеряли 11 %, что стало крупнейшим недельным падением с конца 2022 года. Дело не только в проблемах с Siri — предложенная Дональдом Трампом (Donald Trump) стратегия пошлин подорвала позиции всего технологического сектора, и Apple пострадала сильнее прочих. Панические настроения могут задержаться на рынке: обычно компания немногословна в отношении своих продуктов и программных решений, пока они не готовы к выходу, а крупнейшие анонсы в области ПО приберегает для июньской конференции WWDC. За отсутствием крупных нововведений в сфере ИИ Apple придётся в этом году придумать нечто неожиданное, чтобы стимулировать продажи iPhone. Один из возможных вариантов — смартфон в радикально тонком корпусе, однако до сентябрьской презентации компания подробностей раскрывать не станет. Влияние этих новостей, вероятно, окажется минимальным. В январе аналитик Jefferies Эдисон Ли (Edison Lee) понизил рейтинг акций Apple из-за её отставания в области ИИ. Курирующий Siri топ-менеджер Робби Уокер (Robby Walker) на совещании с подчинёнными назвал ситуацию с задержкой обновлённого голосового помощника некрасивой. Даже если в этом году Apple выпустит ультратонкий, а в следующем — складной iPhone, без дополнительного стимула в виде ИИ нарастить продажи необходимыми темпами будет сложно, отметил эксперт. В настоящий момент рыночная капитализация Apple немногим менее чем в 28 раз превосходит её прогнозируемую годовую прибыль, что примерно соответствует среднему пятилетнему значению и показателям других крупных технологических компаний. Пока серьёзной угрозы для акций нет, но её могут спровоцировать дальнейшие задержки в развитии ИИ и политика Белого дома в отношении пошлин. Сборщики данных для ИИ оказались виновниками массового замедления сайтов по всему интернету
18.03.2025 [13:22],
Павел Котов
Платформа Git-хостинга открытых проектов SourceHut заявила, что работа её сервисов замедлилась из-за веб-сканеров, которые запускают компании — разработчики систем искусственного интеллекта. Похожие жалобы всё чаще поступают и от владельцев других ресурсов. 
Источник изображения: Kai Wenzel / unsplash.com Чтобы ограничить трафик от ИИ-ботов, SourceHut пришлось развернуть Nepenthes — средство защиты от недобросовестно работающих веб-сканеров, собирающих данные для обучения моделей ИИ. Администрация платформы в одностороннем порядке целиком заблокировала диапазоны адресов нескольких облачных провайдеров, в том числе Google Cloud и Microsoft Azure, из-за чрезмерных объёмов трафика от развёрнутых в их сетях ботов. Владельцам добросовестно работающих сервисов на этих инфраструктурах рекомендовали связываться с администрацией SourceHut в индивидуальном порядке, чтобы добавлять их в исключения. В 2022 году SourceHut также пострадала из-за слишком частых обращений к её ресурсам от службы Google Go Module Mirror. В 2023 году OpenAI заверила, что её боты будут выполнять директивы из файлов robots.txt, указывающих правила обработки данных с сайтов веб-сканерами. Аналогичные обязательства взяли на себя и другие разработчики ИИ, но жалобы на злоупотребления продолжают поступать. Летом минувшего года сайт iFixit, в частности, подвергся нашествию со стороны бота Anthropic Claudebot. В декабре хостер Vercel сообщил о значительном присутствии ИИ-сканеров в его инфраструктуре: OpenAI GPTbot отправил в его сеть 569 млн запросов, Anthropic Claude — 370 млн. В совокупности они достигли около 20 % от 4,5 млрд запросов Googlebot, который используется для индексации ресурсов в Google. 
Источник изображения: Kai Wenzel / unsplash.com Тогда же разработчик распределённой соцсети Diaspora Деннис Шуберт (Dennis Schubert) пожаловался, что за предшествующие 60 дней на ИИ-ботов пришлись 70 % трафика на его сервер. Публикация обрела вирусную популярность, и активность ИИ-сканеров резко сократилась; однако сетевые хулиганы устроили на его ресурс массовое нашествие запросов от клиентов со значением строки user-agent, совпадающим с OpenAI GPTbot. Вот только настоящий ИИ-бот OpenAI отправляет запросы из инфраструктуры Microsoft Azure, а в случае с сервером Diaspora они исходили с адресов AWS и даже от американских интернет-провайдеров. Иногда ситуация осложняется тем, что некоторые боты имеют несколько предназначений. Так, Meta✴ AI bot и AppleBot собирают данные исключительно для обучения ИИ, тогда как GoogleBot служит и для ИИ, и для индексации в поиске. Чтобы избежать путаницы, Google в 2023 году добавила отдельное значение Google-Extended для инструментов обучения ИИ. Свои следующие ИИ-чипы Google будет разрабатывать в сотрудничестве с MediaTek
18.03.2025 [07:37],
Алексей Разин
Облачный провайдер масштабов Google способен оправдать разработку собственных компонентов для своей вычислительной инфраструктуры, поэтому компания давно развивает линейку собственных процессоров серверного назначения. До сих пор основным партнёром Google в этой сфере оставалась Broadcom, но в следующем поколении к ней может присоединиться MediaTek. 
Источник изображения: Google Об этом накануне сообщило агентство Reuters со ссылкой на публикацию The Information. Сотрудничество с MediaTek при этом не подразумевает разрыв отношений с Broadcom. Первые плоды взаимодействия с MediaTek корпорация Google представит в следующем году, и одна из преследуемых в рамках этого альянса выгод заключается в экономии расходов на выпуск соответствующих чипов. Как сообщается, MediaTek пользуется более низкими тарифами на производство своих чипов на мощностях TSMC, чем Broadcom, поэтому Google в новом поколении собственных решений надеется добиться пропорциональной экономии. По оценкам экспертов Omdia, в прошлом году Google пришлось потратить на свои процессоры Tensor от $6 до $9 млрд, причём эти расчёты основываются на данных о выручке Broadcom в сфере реализации компонентов для систем ИИ. Даже если Google в результате сотрудничества с MediaTek удастся чуть-чуть сэкономить на каждом выпускаемом чипе, то в общем масштабе экономическая выгода может оказаться весьма существенной. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться