
Опрос
|
реклама
Быстрый переход
Telegram снова оштрафован в России за неудаление запрещённого контента — теперь на ₽7 млн
25.11.2024 [19:14],
Сергей Сурабекянц
25 ноября Таганский суд Москвы признал мессенджер Telegram виновным в неудалении запрещённой информации, содержащей призывы к осуществлению экстремистской деятельности или материалы с порнографическими изображениями несовершеннолетних в соответствии с ч. 2 ст. 13.41 КоАП РФ (неудаление владельцем сайта информации в случае, если обязанность по удалению такой информации предусмотрена законодательством РФ). Мессенджер оштрафован на ₽7 млн. 
Источник изображения: unsplash.com Это далеко не первый случай несоблюдения мессенджером требований российского законодательства. 30 октября Таганский суд Москвы оштрафовал Telegram на ₽4 млн за неудаление нескольких каналов, авторы которых размещали запрещённый в РФ контент. Ранее в этом же месяце Telegram уже штрафовали на ₽4 млн в России за административное правонарушение по ч.2 ст. 13.41 КоАП РФ. За аналогичное правонарушение Telegram также был оштрафован на ₽4 млн в августе этого года. В июле Таганский суд Москвы оштрафовал мессенджер на ₽3 млн за отказ удалять запрещённую в РФ информацию. В ноябре 2023 года мессенджер был оштрафован на ₽4 млн за отказ заблокировать запрещённый контент. Кроме того, в 2021 году мессенджер был несколько раз оштрафован за аналогичные нарушения на общую сумму ₽9 млн. В течение последних лет крупнейшие интернет-платформы, такие как Apple, Google, Telegram, Facebook✴, Twitter, TikTok, фонд Wikimedia, неоднократно привлекались в России к ответственности за неудаление запрещённого контента. Нередко это происходит из-за отказа со стороны социальных сетей и мессенджеров удалять недостоверную, по мнению соответствующих ведомств, информацию. Экс-сотрудницу SK hynix осудили за распечатку 4000 страниц — она якобы воровала технологии для Huawei
12.11.2024 [16:48],
Дмитрий Федоров
Бывшая сотрудница компании SK hynix, 36-летняя гражданка Китая, была осуждена на 18 месяцев тюремного заключения и оштрафована на 20 млн вон (около $14 000) за кражу критически важной технологии производства полупроводников перед переходом на работу в Huawei. Суд Южной Кореи признал её виновной в нарушении Закона о защите промышленной технологии (ITA Amendment), отметив, что обвиняемая распечатала около 4000 страниц технической документации с целью повысить свою ценность на новом месте работы. 
Источник изображений: Pixabay Карьера подсудимой в SK hynix началась в 2013 году, где она занималась анализом дефектов в производстве полупроводников. В 2020 году она была назначена на должность руководителя команды, отвечающей за работу с бизнес-клиентами китайского филиала компании, что предполагало доступ к обширному массиву технологических данных и конфиденциальной информации. Этот опыт позволил ей претендовать на более высокооплачиваемую позицию в Huawei, на которую она согласилась в июне 2022 года. Суд отверг доводы подсудимой о том, что распечатка документов — около 4000 страниц за 4 дня — была необходима для учебных целей и передачи дел. Защита настаивала, что эти материалы копировались исключительно для выполнения рабочих задач. Однако суд отметил, что такие действия выглядели необычно: документы были распечатаны в июне 2022 года, всего за несколько дней до её увольнения из компании и последующего трудоустройства в Huawei. При этом кража данных произошла в офисе SK hynix в Шанхае, где меры безопасности были менее строгими. Суд установил, что подсудимая ежедневно выносила примерно по 300 страниц распечатанных документов, пряча их в рюкзаке и сумке для покупок. Этот методичный и систематический подход вызвал подозрение в преднамеренном нарушении конфиденциальности данных, что не ускользнуло от следствия. Обвинение подчеркнуло, что сведения, связанные с технологиями производства полупроводников, могли представлять значительную ценность для нового работодателя подсудимой. Суд также предположил, что переход обвиняемой на работу в Huawei сразу после ухода из SK hynix мог свидетельствовать о её намерении использовать похищенную техническую документацию для подтверждения своей профессиональной значимости. Вскоре после возвращения в Южную Корею в июне 2022 года она приступила к обязанностям в Huawei, что вызвало у следствия серьёзные подозрения. Однако при вынесении приговора суд учёл отсутствие доказательств того, что украденная информация действительно была использована на новом месте работы, а также отсутствие заявленных материальных претензий со стороны SK hynix. Эти обстоятельства стали основанием для сокращения срока заключения и ограничения размера штрафа. Судебное разбирательство также позволило раскрыть меры безопасности, которые SK hynix принимает для защиты конфиденциальных данных. В компании запрещено использование съёмных носителей, таких как USB-накопители, а все печатные материалы подвергаются строгому контролю: фиксируются содержание документа, данные о пользователе принтера и назначение печати. Тем не менее подсудимой удалось обойти эти меры безопасности в шанхайском офисе SK hynix, откуда документы и были ею похищены. Личные данные более 100 млн жителей США оказались в открытом доступе
25.09.2024 [10:43],
Владимир Фетисов
Исследователи в сфере информационной безопасности обнаружили в интернете базу данных, в которой содержится личная информация 106 316 633 граждан США — почти трети населения страны. База включает в себя информацию компании по проверке биографических данных MC2 Data, включая имена людей, их адреса, номера телефонов, копии разных юридических и трудовых документов, а также многое другое. 
Источник изображения: Shutterstock Исследователи считают, что база данных MC2 Data попала в открытый доступ в результате человеческой ошибки, а не направленной хакерской атаки. Это косвенно подтверждается тем, что в базе содержится информация не только о тех, кого проверяли сотрудники компании, но также о более чем 2 млн клиентов, подписавшихся на услуги MC2 Data. Нынешний инцидент стал второй крупной утечкой данных из компаний, занимающихся проверкой биографических данных, за последние несколько месяцев. В августе компания National Public Data подтвердила утечку данных, из-за чего столкнулась с несколькими коллективными исками со стороны американцев, чьи данные оказались в открытом доступе. «Сервисы проверки биографических данных всегда были проблематичными, поскольку киберпреступники могли оплачивать их услуги по сбору данных о потенциальных жертвах. Такая утечка — золотая жила для киберпреступников, поскольку она открывает ряд возможностей и снижет для них риск, позволяя более эффективно использовать эти подробные данные», — прокомментировал данный вопрос исследователь из Cybernews Арас Назаровас (Aras Nazarovas). Хакеры взломали более 10 млн компьютеров на Windows в 2023 году — с каждого в среднем украли по 51 логину и паролю
02.04.2024 [12:06],
Владимир Фетисов
Количество случаев заражения вредоносным программным обеспечением, предназначенным для кражи данных с персональных компьютеров и корпоративных устройств, с 2020 года увеличилось на 643 % и в 2023 году составило около 10 млн по всему миру. Об этом пишут «Ведомости» со ссылкой на данные Kaspersky Digital Footprint Intelligence. 
Источник изображения: Pete Linforth / pixabay.com Чаще всего в 2023 году злоумышленники использовали вредоносное ПО для кражи сведений об устройстве и хранимой в нём информации о логинах и паролях RedLine — на долю вредоноса приходится более 55 % всех краж, подсчитали специалисты «Лаборатории Касперского». В рамках этого исследования специалисты анализировали статистику заражений устройств с Windows. В среднем с одного заражённого устройства злоумышленникам удавалось похитить 50,9 пары логинов и паролей. Учётные данные могут включать логины от социальных сетей, онлайн-банкинга, криптовалютных кошельков и корпоративных онлайн-сервисов. В «Лаборатории Касперского» отметили, что за последние пять лет злоумышленникам удалось скомпрометировать учётные данные на 443 тыс. веб-сайтов по всему миру. Злоумышленники либо использовали похищенные данные для проведения кибератак, либо для продажи и распространения на теневых форумах и Telegram-каналах. Лидером по количеству скомпрометированных данных является домен .com. В прошлом году было взломано около 326 тыс. пар логинов и паролей для веб-сайтов в этом домене. Следом за ним идут доменная зона Бразилии (.br), в которой злоумышленники скомпрометировали 28,9 млн учётных записей, Индии (.in) — 8,2 млн учётных записей, Колумбии (.co) — 6 млн учётных записей и Вьетнам (.vn) — 5,5 млн учётных записей. Доменная зона .ru заняла 21-е место по количеству взломанных аккаунтов в 2023 году (2,5 млн украденных учётных записей). Количество скомпрометированных учётных записей в зонах .org и .net за тот же период составило 11 млн и 20 млн соответственно. Источник отмечает, что экспертные оценки масштабов взлома аккаунтов сильно отличаются. По информации F.A.C.C.T. Threat Intelligence (бывшая Group IB), по итогам прошлого года в России было скомпрометировано около 700 тыс. уникальных аккаунтов. Руководитель направления аналитики киберугроз ГК «Солар» Дарья Кошкина считает, что на Россию едва ли приходится 5 % от общего количества украденных учётных данных. «Мы не исключаем, что некоторые учётные данные, скомпрометированные в 2023 году, окажутся в теневом сегменте только в 2024 году. Поэтому реальное число заражений, по нашим оценкам, может достичь 16 млн», — прокомментировал данный вопрос эксперт по кибербезопасности «Лаборатории Касперского» Сергей Щербель. «Пробив» информации о россиянах подорожал в 2,5 раза
20.03.2024 [12:06],
Павел Котов
К началу 2024 год цена на незаконное получение данных о россиянах выросла в 2,5 раза и составила 44,3 тыс. руб., сообщает «Коммерсант» со ссылкой на информацию от аналитиков DLBI. Получение сведений от операторов связи зависит от компании, но в среднем эта услуга за год подорожала в 3,3 раза. Банковская информация сейчас стоит в 1,5 раза дешевле, чем год назад. 
Источник изображения: methodshop / pixabay.com Изучившие рынок специалисты DLBI учли информацию от 80 посредников, которые предоставляют услуги незаконного получения информации о россиянах через даркнет и Telegram. Аналитики поделили эти услуги на три категории: детализация звонков и SMS через операторов связи; банковская выписка за определённый период; информация из государственных информационных систем. Сильнее всего подорожал сбор информации от мобильных операторов — в среднем в 3,3 раза. У «Вымпелкома» (бренд «Билайн») это стоит около 87 тыс. руб.; у МТС — 68,5 тыс. руб.; у «МегаФона» и Tele2 — до 100 тыс. руб. Незаконное получение банковской информации аналитики оценили как самую нестабильную услугу на чёрном рынке. В среднем за год она подорожала на 51 % до 38–40 тыс. руб., причём данные из крупных банков получить проще, чем из мелких — «пробив» по небольшим банкам либо вообще отсутствует, либо оказывается сложной задачей. Выросла и стоимость получения данных из государственных систем. В частности, это база ГИБДД, база ПТК «Розыск-Магистраль» с информацией о передвижениях человека и база паспортных данных АС «Российский паспорт». Информация в этой категории за год подорожала на 40 %, но осталась самой низкой — 2 тыс. руб. за одну выгрузку. В «Вымпелкоме» отметили, что стоимость такой услуги зависит от числа людей с доступом к информации — в телекоммуникационной отрасли оно снижается. В Tele2 инциденты с кражей данных об абонентах назвали «редкими» и «единичными», а также заверили, что принимают меры для их исключения: это IT-решения с анализом действий пользователей и камеры наблюдения, которые фиксируют фотографирование экрана компьютера мобильным телефоном. Примечательно, что многочисленные утечки данных не влияют на рынок «пробива». За 2023 год число таких инцидентов, по сведениям Роскомнадзора, составило 168 — были похищены 300 млн записей о россиянах. Но едва ли это повлияет на стоимость целевого незаконного получения информации — за этой услугой обращаются, когда необходима «информация из закрытых источников, а не то, что можно достать быстро и дёшево», пояснил опрошенный «Коммерсантом» эксперт. Инженер украл у Google секретные технологии ИИ для передачи в Китай — ему грозит 10 лет тюрьмы
07.03.2024 [11:26],
Павел Котов
Инженеру Google Линьвэю Дину (Linwei Ding), также известному как Леон Дин (Leon Ding), предъявлено обвинение в краже составляющих коммерческую тайну технологий программного и аппаратного обеспечения для систем искусственного интеллекта, принадлежащих Google. Обвинение было предъявлено 5 марта, после чего Дина арестовали. 
Источник изображения: Alex Dudar / unsplash.com Заместитель генерального прокурора Лиза Монако (Lisa Monaco) заявила, что Дин «украл у Google более 500 конфиденциальных файлов, содержащих технологии ИИ, составляющие коммерческую тайну, параллельно работая на китайские компании, стремящиеся получить преимущество в гонке технологий ИИ». Значительная часть похищенных данных предположительно связана с тензорным процессором (TPU) Google. Эти чипы обеспечивают множество рабочих нагрузок и в сочетании с ускорителями NVIDIA могут обучать и запускать модели ИИ, включая Gemini. Доступ к этим чипам есть также через партнёрские платформы, такие как Hugging Face. Дин, по версии правоохранителей, украл проекты ПО для чипов TPU v4 и v6, спецификации программного и аппаратного обеспечения для используемых в центрах обработки данных Google графических процессоров, а также проекты рабочих нагрузок машинного обучения в ЦОД Google. С мая 2022 года по май 2023 года он предположительно скопировал данные компании при помощи приложения Apple Notes на выданном Google компьютере MacBook и экспортировал их в формат PDF, чтобы не попасть в поле зрения системы предотвращения кражи данных. Файлы он разместил в личном аккаунте Google Cloud. Менее чем через месяц после того, как он начал воровать данные, ему предложили должность технического директора в китайской компании Rongshu, занимающейся машинным обучением. Он прилетел в Китай на пять месяцев, чтобы собрать средства, а затем основал и возглавил стартап в области машинного обучения Zhisuan, оставаясь сотрудником Google. Из Google он ушёл в декабре 2023 года и забронировал билет в один конец до Пекина — вылет был намечен на второй день после увольнения, причём в компании уже начали задавать вопросы о загруженных им данных. В декабре 2023 года, по версии Минюста, Дин имитировал своё присутствие в американском офисе Google, попросив отсканировать его бейдж у двери, когда он на самом деле был в Китае. Дину предъявлено обвинение по четырём эпизодам краж информации, составляющей коммерческую тайну, и в случае признания виновным ему грозят до десяти лет тюремного заключения и штраф в размере $250 тыс. по каждому эпизоду. Бывшего сотрудника Samsung обвинили в краже технологий производства памяти в пользу китайской CXMT
04.01.2024 [16:37],
Владимир Мироненко
В минувшую среду в Южной Корее обвинили бывшего сотрудника Samsung Electronics в краже конфиденциальной информации, касающейся ключевых полупроводниковых технологий, с целью передачи их китайской компании за денежное вознаграждение, пишет ресурс Yonhap News Agency. 
Источник изображения: Yonhap News Agency Как стало известно, прокуратура Центрального округа Сеула предъявила обвинение гражданину Киму (Kim), который ранее занимал должность руководителя отдела в Samsung, в нарушении закона о защите промышленных технологий. Ким обвиняется в краже принадлежащей Samsung конфиденциальной информации, касающейся производства микросхем DRAM, и её передаче китайскому производителю чипов памяти ChangXin Memory Technologies (CXMT) для использования в разработке собственных продуктов. Прокуратура подозревает Кима в передаче CXMT данных о семи ключевых технологиях для производства полупроводников и других технологиях Samsung в обмен на десятки миллионов долларов после его перехода в китайскую фирму в 2016 году. Также Ким подозревается в переманивании 20 технических специалистов из Samsung и других фирм в китайскую компанию, которым предлагалось высокое финансовое вознаграждение. Китайская CXMT, которая была новичком на рынке в 2016 году, быстро вышла в лидеры китайской отрасли по производству микросхем оперативной памяти DRAM. По данному делу проходит ещё один экс-сотрудник Samsung, обвиняемый в сговоре с Кимом с целью кражи и передачи информации о ключевых технологиях его бывшей компании китайскому производителю CXMT. Проводящая анализы ДНК компания 23andMe признала утечку данных 6,9 млн клиентов
05.12.2023 [11:44],
Павел Котов
Компания 23andMe, которая проводит анализы ДНК, сообщила, что в результате недавнего взлома произошла утечка данных, принадлежащих 6,9 млн пользователей. Инцидент коснулся 5,5 млн пользователей с активной функцией DNA Relatives (сопоставление людей со схожими ДНК) и 1,4 млн с профилями генеалогического древа. 
Источник изображения: Darwin Laganzon / pixabay.com Компания раскрыла информацию об инциденте в заявлении Комиссии по ценным бумагам и биржам (SEC) США, а также в официальном блоге. Злоумышленники, по версии 23andMe, получили доступ к информации, воспользовавшись методом подстановки данных: люди часто пользуются одинаковыми логинами и паролями на разных сервисах, из-за чего компрометация данных на одном открывает доступ к другим. В результате хакерам удалось войти в 0,1 % (14 000) учётных записей в системе компании. Сделав это, они воспользовались функцией DNA Relatives, предполагающей сопоставление ДНК вероятных родственников, и получили дополнительную информацию нескольких миллионов других профилей. Первые сведения об инциденте были преданы огласке в октябре, когда 23andMe подтвердила, что данные её пользователей выставили на продажу в даркнете. Впоследствии компания заявила, что проверяет сообщения о публикации 4 млн генетических профилей жителей Великобритании, а также «самых богатых людей, проживающих в США и Западной Европе». В базе утечки 5,5 млн пользователей DNA Relatives оказались их отображаемые в системе имена, вероятные связи с другими людьми, число пользователей с совпадениями в ДНК, сведения о происхождении, указанные самими пользователями местоположения, места рождения предков, фамилии, изображения профиля и многое другое. Ещё 1,4 млн пользователей имели доступ к профилям генеалогического древа — из этой базы были похищены их отображаемые имена, родственные связи, годы рождения и указанные этими пользователями местоположения. Во второй базе, однако, не было степеней совпадения ДНК. В 23andMe сообщили, что продолжают уведомлять пострадавших от утечки пользователей. Компания стала предупреждать клиентов о необходимости сменить пароли и принудительно внедрять двухфакторную авторизацию, которая ранее была необязательной. Хакеры могут воровать данные в миллионах сетевых соединений — найден новый метод кражи ключей SSH
14.11.2023 [18:13],
Дмитрий Федоров
Исследователи в области кибербезопасности обнаружили новый метод хищения криптографических ключей в протоколе Secure Shell (SSH), создающий угрозу для конфиденциальности данных в миллионах SSH-соединений, используемых по всему миру. Это исследование является кульминацией 25-летней работы экспертов в этой области. 
Источник изображения: deeznutz1 / Pixabay Открытие, подробно описанное в научной статье, указывает на потенциальные уязвимости в SSH-соединениях, которые злоумышленники могут использовать для перехвата данных между корпоративными серверами и удалёнными клиентами. Ключевой момент уязвимости заключается в использовании мелких вычислительных ошибок, возникающих в процессе установления SSH-соединения, известного как «рукопожатие» (handshake). Эта уязвимость ограничена шифрованием RSA, которое, тем не менее, применяется примерно на трети анализируемых веб-сайтов. Из около 3,5 млрд цифровых подписей, проанализированных на публичных веб-сайтах за последние 7 лет, около миллиарда использовали шифрование RSA. В этой группе примерно одна из миллиона реализаций оказалась уязвимой к раскрытию своих SSH-ключей. «Согласно нашим данным, около одной из миллиона SSH-подписей раскрывает личный ключ хоста SSH. Хотя это и редкое явление, масштабы интернет-трафика показывают, что подобные сбои RSA в SSH происходят регулярно», — отметил Киган Райан (Keegan Ryan), соавтор исследования. Угроза, связанная с новым методом кражи криптографических ключей, не ограничивается только протоколом SSH. Она также распространяется на соединения IPsec, широко используемые в корпоративных и частных сетях, включая VPN-сервисы. Это представляет существенный риск для компаний и индивидуальных пользователей, полагающихся на VPN для защиты своих данных и обеспечения анонимности в интернете. В исследовании под названием Passive SSH Key Compromise via Lattices подробно рассматривается, как методы, основанные на криптографии на решётках (lattice-based cryptography), могут использоваться для пассивного извлечения ключей RSA. Это возможно даже при одиночной ошибочной подписи, созданной с использованием стандарта PKCS#1 v1.5. Такой подход, описанный исследователями, обеспечивает проникновение в протоколы SSH и IPsec, что поднимает вопросы о надёжности этих широко распространённых методов защиты передачи данных. Уязвимость активируется, когда в процессе «рукопожатия» возникает искусственно вызванная или случайно возникшая ошибка. Злоумышленники могут перехватить ошибочную подпись и сравнить её с действительной, используя операцию поиска наибольшего общего делителя для извлечения одного из простых чисел, формирующих ключ. Однако в данной атаке используется метод, основанный на криптографии на основе решёток. Получив ключ, злоумышленники могут организовать атаку типа «человек посередине» (man-in-the-middle или MITM), где сервер, контролируемый хакером, использует похищенный ключ для имитации скомпрометированного сервера. Таким образом, они перехватывают и отвечают на входящие SSH-запросы, что позволяет легко похищать учётные данные пользователей и другую информацию. Та же угроза существует и для IPsec-трафика в случае компрометации ключа. Особенно уязвимыми оказались устройства от четырёх производителей: Cisco, Zyxel, Hillstone Networks и Mocana. Исследователи предупредили производителей о недостатках безопасности до публикации результатов исследования. Cisco и Zyxel отреагировали немедленно, тогда как Hillstone Networks ответила уже после публикации. Недавние улучшения в протоколе защиты транспортного уровня (TLS) повысили его устойчивость к подобным атакам. Райан утверждает, что аналогичные меры должны быть внедрены и в других безопасных протоколах, в частности, в SSH и IPsec, учитывая их широкое распространение. Однако, несмотря на серьёзность угрозы, вероятность подвергнуться таким атакам для каждого отдельного пользователя остаётся относительно мала. Новостные и социальные сайты требуют от OpenAI платить за обучение ChatGPT на их публикациях
20.10.2023 [22:58],
Николай Хижняк
Несколько крупных представителей СМИ и информационных онлайн-платформ ведут переговоры с компанией OpenAI, создавшей популярного ИИ-чат-бота ChatGPT, по поводу доступа к их ресурсам на платной основе. Эти ресурсы представляют собой важнейший источник информации, на основе которой обучаются большие языковые модели. 
Источник изображения: Rolf van Root / unsplash.com Как пишет издание The Washington Post, такие технологические компании как OpenAI годами пользовались на бесплатной основе новостными онлайн-ресурсами и использовали их материалы для обучения своих ИИ-моделей. В последнее время в сфере генеративного ИИ наблюдается значительный рост доходов. По оценкам некоторых экспертов, опрошенных Bloomberg, выручка данного сегмента вырастет к 2032 году до $1,3 триллиона. Информационные издания и платформы претендуют на часть этих денег. С августа текущего года как минимум 535 ведущих изданий, включая York Times, Reuters и The Washington Post, установили на свои онлайн-ресурсы специальные блокираторы, которые не позволяют собирать информацию для обучения ChatGPT. Отмечается, что издатели ведут переговоры с OpenAI по вопросу предоставления чат-боту ChatGPT платного доступа к конкретным отдельным опубликованным материалам. Издатели считают, что такая схема взаимодействия имеет два неоспоримых плюса: информационные платформы будут получать дополнительный доход за каждый отдельный опубликованный материал, а также смогут потенциально увеличить объём трафика на свои веб-сайты. В июле OpenAI заключила сделку с информационным агентством Associated Press. Технологическая компания может использовать публикации ресурса без ограничений для обучения своих ИИ-моделей. По словам источников The Washington Post, такая схема взаимодействия также рассматривается в переговорах между OpenAI и другими изданиями. Однако последние больше склоняются в пользу предоставления доступа только к отдельным материалам, которые могли бы отображаться в ответах на запросы пользователей того же ChatGPT. Источники The Washington Post отмечают, что другие онлайн-платформы, представляющие информационный интерес для обучения чат-ботов, например, Reddit, выросшая из небольшой и простой доски объявлений в огромную социальную платформу, тоже ищет способы дополнительной монетизации за свои публикации. Источники Washington Post утверждают, что представители платформы вели переговоры с ведущими компаниями в разработке генеративного ИИ по вопросам оплаты публикаций, которые могут использоваться для обучения ИИ-моделей. Если такой договорённости достигнуть не получится, то Reddit готова рассмотреть возможность ввода страницы авторизации на свою платформу, без прохождения которой контент не будет отображаться для её посетителей. Переход в разряд закрытой платформы может лишить Reddit поисковой выдачи в Google, сократив количество посетителей сайта по переходам из поиска. Однако по словам анонимного источника The Washington Post, в Reddit считают, что этого того стоит, и платформа «сможет выжить и без поиска». Публично представители Reddit такие заявления отрицают: «Ничего не меняется», — заявила представитель платформы Кортни Гиси-Дорр (Courtney Geesey-Dorr) в разговоре с изданием The Verge, попросившем прокомментировать сообщение The Washington Post. В апреле социальная сеть X (бывший Twitter) начала взимать с исследователей 42 000 долларов за предоставление доступа к подробной статистике и публикациям на платформе. Ранее такой доступ предоставлялся бесплатно, однако по словам владельца соцсети Илона Маска (Elon Musk), компании, занимающиеся разработкой искусственного интеллекта, незаконно использовали данные платформы для обучения своих ИИ-моделей. 
D koi / unsplash.com Учитывая, что генеративный искусственный интеллект способен изменить взаимодействие пользователей с Интернетом, многие издатели и другие компании считают введение оплаты за свою информацию справедливой мерой, рассматривая этот вопрос как экзистенциальную проблему. Например, через месяц после того, как OpenAI запустила продвинутую ИИ-модель GPT-4, трафик сообщества программистов Stack Overflow снизился на 15 %, поскольку люди стали чаще обращаться к ИИ в вопросах, связанных с кодированием, а не к популярной веб-платформе. Об этом в разговоре с The Washington Post сообщил исполнительный директор Stack Overflow Прашант Чандрасекар (Prashanth Chandrasekar). Он также добавил, что чат-бот OpenAI также обучался и на основе их данных. На этой неделе Stack Overflow сократила свой персонал на 28 %. Помимо требований об оплате за используемую для обучения ИИ информацию, ведущие компании, занимающиеся искусственным интеллектом, сталкиваются с множеством исков от отдельных авторов книг, художников и программистов, требующих возмещения ущерба за нарушение их авторских прав, а также, чтобы эти компании поделились с ними долей прибыли. Как сообщает издание Reuters, на этой неделе против Meta✴, Microsoft и Bloomberg был подан коллективный иск. Его инициаторы утверждают, что для обучения своих систем искусственного интеллекта указанные компании использовали пиратские онлайн-библиотеки. По мнению экспертов, готовность OpenAI вести переговоры с издателями может говорить о желании компании заключить сделки для легального использования контента и усилить свою юридическую базу до того, как в дело вступят суды, которые определят есть ли у технологических компаний четкие юридические обязательства лицензировать контент и платить за его использование. В OpenAI подтвердили, что компания ведет переговоры с издателями. Однако предмет разговора не связан с контентом, на базе которого её ИИ-модели уже были обучены. Компания также утверждает, что всю информацию для обучения своих моделей она получила законным путём. «Ни одна наша практика не нарушает закон об авторском праве», — заявил представитель OpenAI. По его словам, в рамках диалога с издателями компания обсуждает вопросы, связанные с новым контентом, доступ к которому был бы невозможен без официальных соглашений. Хакеры слили результаты анализов и другие данные клиентов лабораторий «Ситилаб»
22.05.2023 [17:54],
Сергей Сурабекянц
Telegram-канал «Утечки информации» исследовательской компании DLBI сообщил о появлении в открытом доступе актуальных на 18 мая данных клиентов сети лабораторий «Ситилаб». В обнаруженных файлах содержатся логины, хешированные пароли, ФИО, пол, дата рождения, дата регистрации, 483 тысячи уникальных адресов электронной почты и 435 тысяч уникальных номеров телефонов. 
Источник изображения: pressfoto / freepik.com Адреса электронной почты реальные — исследователи компании DLBI проверили часть из них через форму восстановления аккаунта на сайте «Ситилаб». Утверждается, что хакерам удалось похитить в общей сложности 14 Тбайт данных. В открытый доступ выложена пока только часть украденной информации объёмом 1,7 Тбайт. Кроме непосредственно данных о клиентах сети лабораторий в свободном доступе оказались около 1000 документов в формате PDF с результатами анализов, исследованиями, договорами и чеками. Пока комментариев от «Ситилаб» не поступало. Хакеры не первый раз обращают своё криминальное внимание на медицинские лаборатории — в мае 2022 года в даркнете продавалась информация из 30 млн строк личных данных клиентов «Гемотеста». В июле компанию оштрафовали на 60 тысяч рублей за утечку данных пользователей. Вряд ли такой штраф может серьёзно озаботить компанию с внушительными финансовыми оборотами. Мошенники с помощью расширения для ChatGPT собирали данные пользователей и угоняли аккаунты Facebook✴
14.03.2023 [20:26],
Владимир Фетисов
За последние месяцы продвинутый чат-бот ChatGPT, созданный Open AI при поддержке Microsoft, набрал огромную популярность. Не удивительно, что этим решили воспользоваться мошенники. Как выяснилось, расширение Quick access to ChatGPT для браузера Google Chrome, которое позволяет получить доступ к ИИ-боту в несколько кликов, на деле также собирало данные пользователей и получало доступ к их аккаунтам в Facebook✴. 
Источник изображения: Jonathan Kemper / Unsplash Согласно имеющимся данным, Quick access to ChatGPT было доступно в магазине дополнений для Chrome с 3 по 9 марта. В течение этого короткого периода расширение ежедневно устанавливали более 2 тыс. пользователей браузера Google, которые хотели испытать возможности ИИ-бота. Хотя данный продукт действительно предоставлял возможность быстрого доступа к боту, вместе с этим он похищал пользовательские данные. Специалисты компании Guardio, работающей в сфере информационной безопасности, обнаружили, что Quick access to ChatGPT собирает все хранящиеся в браузере файлы cookie, а также крадёт токены аутентифицированных сессий в Google, YouTube, Facebook✴ и Twitter. За счёт этого мошенники получили доступ к Meta✴ Graph API, который используется для разработки приложений, совместимых с Facebook✴. В результате они могли получить доступ к учётным записям пользователей Facebook✴ и совершать действия от их имени. Когда расширение обнаруживало бизнес-аккаунты Facebook✴, оно собирало данные об активных акциях, остатках на счетах, минимальных порогах выставления счетов и кредитных линиях. 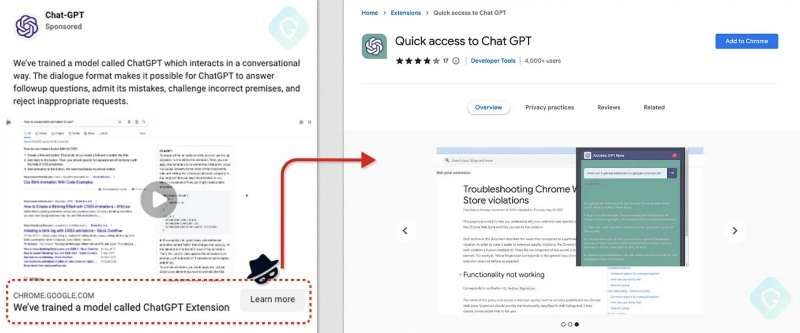
Источник изображения: Guardio Вероятнее всего, собранные таким образом данные будут проданы на одном из хакерских форумов. Также не исключено, что мошенники задействуют взломанные аккаунты Facebook✴ для реализации собственной вредоносной кампании, например, по распространению на платформе мошеннических материалов. Украденные у Activision данные о сотрудниках появились в открытом доступе
01.03.2023 [15:24],
Павел Котов
Данные, украденные у игрового издателя Activision в результате декабрьского инцидента неизвестными киберпреступниками, появились в открытом доступе на одном из популярных форумов в даркнете. Персональная информация пользователей среди них отсутствует. 
Источник изображения: activision.com Факт произведённого в декабре 2022 года взлома Activision подтвердила несколько дней назад, и события стали развиваться по худшему сценарию. Данные, как заявили сами хакеры, были украдены с инстанса Activision в CDN инфраструктуры Azure — они включают в себя 20 тыс. записей о сотрудниках игрового гиганта: полные имена, адреса электронной почты, номера телефонов и адреса офисов. Информация не была выставлена на продажу, а выложена в открытый доступ в формате текстового файла. Взлом был произведён при помощи фишинговой кампании с использованием SMS. Жертвой атаки оказался сотрудник отдела кадров Activision, который, не осознавая последствий своих действий, передал злоумышленникам данные для доступа к ресурсам компании. Представитель Activision подтвердил утечку данных, но заявил, что хакеры не смогли получить доступ к «конфиденциальным данным сотрудников», хотя независимое расследование эту версию опровергло, а опубликованная киберпреступниками информация фактически не оставила на ней камня на камне. В результате взлома была похищена также информация, относящаяся к готовящейся к выходу игровой продукции — в Activision заявили, что она конфиденциальной не является. Компания также заверила, что данные геймеров и клиентов злоумышленникам похитить не удалось. Однако публикация персональной информации сотрудников Activision в открытом доступе способна в значительной мере осложнить их работу — следует ожидать целой волны очередных фишинговых атак. Роскомнадзор запустил систему «Окулус» для автоматического поиска запрещённого контента
13.02.2023 [11:15],
Руслан Авдеев
Запрещённый в Рунете контент начали искать с помощью автоматической системы «Окулус». О начале её работы заявил «Ведомостям» представитель Главного радиочастотного центра (ГРЧЦ), подведомственного Роскомнадзору. Сообщается, что система в полном объёме выполняет возложенные на неё задачи — в числе прочего ведётся поиск запрещённых изображений и видеоматериалов. 
Источник изображения: Glenn Carstens-Peters/unsplash.com Тестирование «Окулуса» стартовало в декабре 2022 года, а уже в январе текущего года была произведена интеграция системы с набором других используемых Роскомнадзором инструментов мониторинга. По словам представителя ГРЧЦ, система распознаёт изображения и символы, противоправные сцены и действия, анализирует текст в фото- и видеоматериалах. Производительность «Окулуса» составляет 200 тысяч изображений в сутки. Планируется дальнейшее совершенствование системы в 2025 году. Она получит поддержку новых типов и классов нарушений, средства распознавания определённых поз людей и их действий, возможность классификации материалов по нескольким кадрам видеоконтента, рукописному тексту, а также рисованному контенту. Необходимость применения подобных механизмов, по словам ГРЧЦ, обоснована ростом количества запрещённых материалов, в том числе политической тематики, в первую очередь разного рода фейков. По имеющимся данным, в 2022 году по требованию Генпрокуратуры были удалены либо заблокированы более 100 тыс. ресурсов с недостоверной информацией. Для сравнения: в 2019 году речь шла о нескольких сотнях таких ресурсов. Первые сведения о создании системы «Окулус» появились в 2021 году. Разработка техзадания была оценена ГРЧЦ в 15 млн рублей, создание всей системы — в 57,7 млн рублей. Разработчиком выступила компания Execution RDC. Сообщается, что выявленная информация обязательно будет перепроверяться вручную во избежание ошибок и не будет отправляться в правоохранительные органы автоматически. ЕС заставил Google стать прозрачнее — компания уточнит важную для пользователей информацию в своих сервисах
27.01.2023 [17:58],
Павел Котов
После серии консультаций с европейскими чиновникам Google согласилась уточнить информацию на своих сервисах, в том числе Google Store, Google Play, Google Hotels и Google Flights. Эти меры помогут потребителям делать осознанный выбор при заказе товаров и услуг. 
Источник изображения: Alex Dudar / unsplash.com На платформах Google Flights и Google Hotels будут чётко различаться услуги, предлагаемые самой Google, и услуги от других компаний, которые Google демонстрирует как посредник. Потребители будут точно знать, где указываются фактические скидки, а где цены указываются для справки и могут не соответствовать действительности. Компания обозначит, что отзывы на Google Hotels не проверяются администрацией, и службе будет обеспечен тот же уровень прозрачности, что и на аналогичных платформах — Booking.com и Expedia. Магазин Google Store предоставит потребителям более подробную информацию о стоимости доставки, возможности оформления возврата, а также доступности вариантов замены или ремонта, если это возможно. Пользователям объяснят, как открывать разделы магазина приложений Google Play для других стран — это особенно актуально для ЕС, чьим жителям будет обеспечен доступ к одному и тому же контенту. Ранее Google заявила, что пользователи смогут менять регион в Google Play раз в год, но в ЕС возразили, что это противоречит законодательству региона. Компания согласилась ограничить своё право в одностороннем порядке отменять заказы или изменять цены в Google Store, а также предоставила европейским чиновникам специальный адрес электронной почты для обращений по вопросам удаления противоправного контента. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться