|
Опрос
|
реклама
Быстрый переход
Мощнейшая ИИ-модель OpenAI o3 тратит до $30 000 на решение одной задачи
03.04.2025 [13:07],
Павел Котов
В декабре OpenAI представила рассуждающую модель искусственного интеллекта o3 и продемонстрировала результаты бенчмарка ARC-AGI — самого сложного теста для оценки возможностей ИИ. Теперь результаты теста пришлось пересмотреть, и выглядят они менее впечатляющими: модель оказалась слишком дорогой в обслуживании. 
Источник изображения: Mariia Shalabaieva / unsplash.com На минувшей неделе организация Arc Prize Foundation, ответственная за ARC-AGI, обновила свою оценку затрат на вычисления для OpenAI o3. Первоначально считалось, что её наиболее мощная конфигурация o3 high требует расходов в размере около $3000 на решение одной задачи ARC-AGI. Теперь же было установлено, что стоимость обслуживания намного выше — она, возможно, достигает $30 000 за задачу. Это иллюстрирует, насколько дорогими могут оказаться самые сложные современные модели ИИ в определённых задачах, по крайней мере, на начальном этапе. Цену на o3 компания OpenAI ещё не установила, и в общий доступ модель не поступила, но в Arc Prize Foundation предположили, что можно ориентироваться на показатели OpenAI o1-pro. «Считаем, что o1-pro является более близким сравнением [для определения] истинной стоимости o3 <..> из-за объёма используемых во время тестирования вычислений. Но это не точная оценка, и мы оставили для o3 пометку о предварительной версии в нашей таблице лидеров, чтобы отразить неопределённость, пока не объявлена официальная цена», — рассказали в Arc Prize Foundation ресурсу TechCrunch. Известно, что при решении одной задачи o3 high использовала в 172 раза больше вычислительных ресурсов в ARC-AGI, чем o3 low — наиболее слабая модель в линейке. Ранее стало известно, что тарифные планы на передовые системы OpenAI могут оказаться чрезвычайно дорогостоящими — до $20 000 в месяц за работу специализированных агентов ИИ. При этом моделям свойственно ошибаться: той же o3 high потребовалось 1024 попытки для решения каждой задачи теста ARC-AGI, чтобы показать лучший результат. «Яндекс» представил «Нейроэксперта» — ИИ, который соберёт базу знаний по ссылкам и файлам пользователя
03.04.2025 [10:52],
Павел Котов
Компания «Яндекс» представила сервис «Нейроэксперт», который доступен в формате бета-версии. Он позволяет загружать документы, таблицы, презентации, аудио- и видеофайлы, а также отправлять ссылки, из которых составляется база знаний с возможностью найти ответ на любой вопрос. Воспользоваться сервисом может любой желающий. 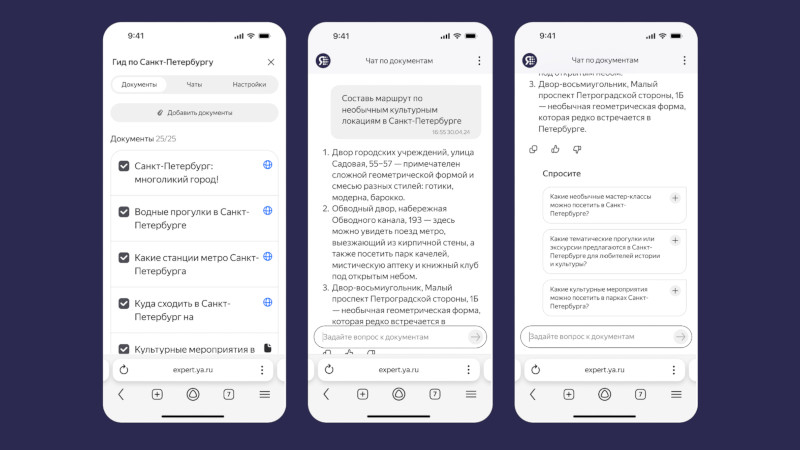
Источник изображений: «Яндекс» База знаний на платформе «Нейроэксперт» похожа на папку в облачном хранилище — ею можно поделиться по ссылке. Пользователь загружает информацию и задаёт о ней вопросы в режиме диалога; ответы система готовит только на основе предоставленных данных. На этапе бета-тестирования загружаются до 25 файлов и ссылок — это могут быть документы, таблицы, аудиосообщения из мессенджера или другие данные. По завершении бета-тестирования можно будет добавлять больше исходных данных. Сервис пригодится тем, кто работает с большими объёмами информации. Преподаватель может загрузить свои лекции и передать базу данных студентам, которые при подготовке к экзаменам найдут в ней ответы на свои вопросы. «Нейроэксперт» окажется полезным, например, если требуется создать отчёт, а необходимые данные размещены в одной из множества презентаций — искать информацию вручную не придётся. Сервис поможет принять решение о покупке, если загрузить в него ссылки с описанием товаров и видеообзоры. Можно, наконец, загрузить «Нейроэксперту» правила настольной игры и задать ему вопрос при возникновении спорного момента. 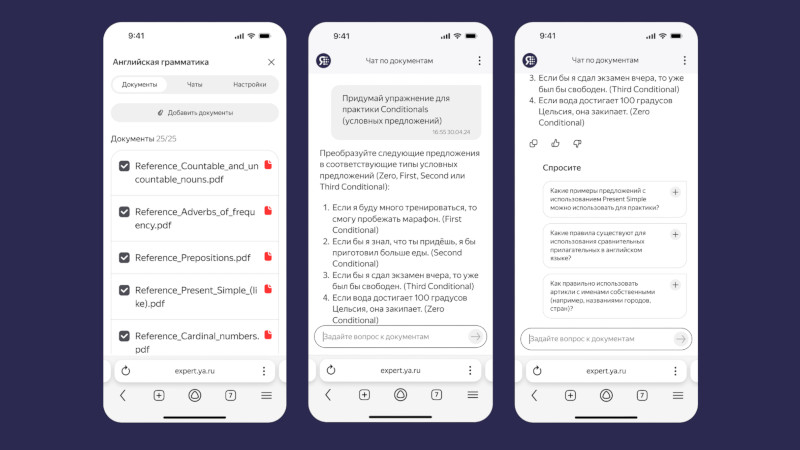 Особенно полезным сервис окажется для бизнес-клиентов — его можно будет подключить к внутренним базам знаний и документации. «Нейроэксперт» поможет систематизировать работу, будет способствовать адаптации и повышению эффективности работников компании. Подключить предварительный вариант корпоративного «Нейроэксперта» можно по заявке. Для работы сервиса использованы несколько созданных «Яндексом» технологий. Для поиска данных по графикам и диаграммам используется визуально-языковая модель (VLM); за обработку аудио и видео отвечает технология распознавания речи (ASR); текст на картинках обрабатывает технология оптического распознавания символов (OCR). Обработку данных от этих систем и подготовку ответа осуществляет большая языковая модель YandexGPT 5 Pro: знания о мироустройстве и правилах языка помогают ей понимать запрос и готовить качественные ответ — при этом фактические данные она берёт из загруженных материалов. Знания модели и сведения из файлов объединяет ещё один компонент — RAG-система (Retrieval Augmented Generation). 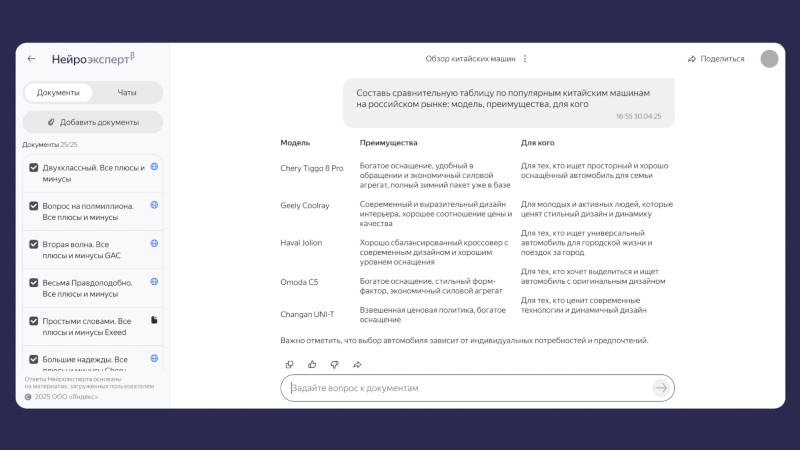 Аналоги «Нейроэксперта» уже есть у зарубежных разработчиков: Google NotebookLM, Perplexity Spaces и ChatGPT Projects. «Яндекс» планирует реализовать две модели монетизации сервиса: расширенные возможности для оформивших подписку пользователей и интеграция «Нейроэксперта» в информационные системы заказчика. Китай увеличил закупки ИИ-чипов Nvidia в четыре раза — до $16 млрд за первый квартал
03.04.2025 [07:45],
Алексей Разин
Китайский рынок для Nvidia сохраняет свою важность даже в условиях усиливающихся правил экспортного контроля США, которые мешают компании поставлять в КНР основную часть ассортимента своих ускорителей вычислений. Тем не менее, даже в этом случае по итогам первого квартала китайские клиенты нарастили заказы у Nvidia в почти в четыре раза, как минимум до $16 млрд. 
Источник изображения: Nvidia Об этом накануне сообщило издание The Information со ссылкой на осведомлённые источники. Среди основных заказчиков подобной продукции оказались ByteDance, Alibaba Group и Tencent Holdings. Ещё в феврале, как сообщало Reuters, наблюдался всплеск спроса на ускорители вычислений H20, которые пока легально можно поставлять в Китай. Китайский производитель серверных систем H3C в прошлом месяце также предупреждал об угрозе дефицита ускорителей H20 в Китае после апреля на фоне роста спроса на них. В прошлом году Nvidia выручила на территории Китая, включая Гонконг, более $17 млрд. Конечно, на фоне растущей семимильными шагами совокупной выручки компании, это не такая большая доля, но в абсолютном выражении она достаточно велика, чтобы Nvidia дорожила китайским рынком. Получается, что только за первый квартал текущего года компания получила почти столько же заказов из Китая, как за весь прошлый фискальный год. «Наш контент бесплатный, а инфраструктура — нет»: ИИ-боты разоряют «Википедию»
02.04.2025 [19:54],
Сергей Сурабекянц
«Википедия» расплачивается за бум искусственного интеллекта — онлайн-энциклопедия сталкивается с растущими расходами из-за ботов, которые копируют её статьи для обучения моделей искусственного интеллекта, что впустую расходует ресурсы и в разы увеличивает трафик и нагрузку на сайт. Только за последние три месяца трафик, генерируемый ИИ-краулерами, вырос на 50 %. 
Источник изображения: «Википедия» Фонд Wikimedia (некоммерческая организация, управляющая «Википедией») заявил, что «автоматизированные запросы на наш контент выросли в геометрической прогрессии». По данным фонда, с января 2024 года пропускная способность, используемая для загрузки мультимедийного контента, выросла на 50 %. Однако трафик исходит не от людей, а от автоматизированных программ, которые постоянно загружают изображения с открытой лицензией для передачи их моделям ИИ. «Наша инфраструктура создана для того, чтобы выдерживать внезапные всплески трафика от людей во время мероприятий с высоким интересом, но объем трафика, генерируемого ботами-скрейперами, беспрецедентен и представляет растущие риски и расходы», — сообщила «Википедия». Боты часто собирают данные из менее популярных статей «Википедии». Специалисты «Википедии» утверждают, что по крайней мере 65 % подобного трафика, поступает от ботов, что является непропорционально большим объёмом, учитывая, что общее количество просмотров страниц ботами составляет около 35 %. Также боты проявляют интерес к «ключевым системам в инфраструктуре разработчиков, таким как наша платформа проверки кода или наш баг-трекер», что ещё больше нагружает ресурсы сайта. «Википедия» была вынуждена ввести индивидуальные ограничения скорости для ИИ-ботов или вообще запретить доступ некоторым из них. Но для решения проблемы в долгосрочной перспективе фонд разрабатывает план «Ответственного использования инфраструктуры». План предусматривает сбор отзывов от сообщества «Википедии» о способах определения трафика от ИИ-ботов и фильтрации их доступа. Социальная платформа Reddit столкнулась с похожей проблемой в 2023 году. Например, Microsoft без уведомления Reddit использовала данные платформы для обучения моделей ИИ, что вынудило Reddit заблокировать ботов Microsoft. После этого инцидента Reddit решила взимать плату со сторонних разработчиков за доступ к своему API. Это привело к массовым протестам разработчиков и закрытию некоторых популярных форумов Reddit. Meta✴ лишилась главы фундаментальных ИИ-исследований
02.04.2025 [11:25],
Дмитрий Федоров
Вице-президент Meta✴ по исследованиям в области ИИ Джоэль Пино (Joelle Pineau) объявила о своём уходе из компании. Её последний рабочий день в Meta✴ назначен на 30 мая 2025 года. Отставка происходит на фоне активной инвестиционной стратегии компании в сфере ИИ, направленной на опережение OpenAI и Google. 
Источник изображения: Farhat Altaf / Unsplash О своём уходе Пино сообщила в публикации на LinkedIn, где подтвердила, что покинет Meta✴. Она занимала должность вице-президента компании по исследованиям в области ИИ и с 2023 года возглавляла подразделение Fundamental AI Research (FAIR). FAIR занимается фундаментальными разработками в области ИИ, часть которых впоследствии внедряется в ключевые цифровые продукты Meta✴. Уход Пино совпал с этапом технологического переосмысления внутри компании. Генеральный директор Meta✴ Марк Цукерберг (Mark Zuckerberg) обозначил ИИ как приоритетное направление и инвестировал в него многомиллиардные ресурсы. Согласно его заявлениям, Meta✴ стремится к созданию ИИ-ассистента, которым будут пользоваться более одного миллиарда человек, а также к разработке так называемого сильного ИИ (Artificial General Intelligence — AGI), то есть ИИ-систем, способных мыслить и действовать на уровне человека. В своём заявлении Пино указала, что на фоне глобальных изменений и ускоряющейся гонки в сфере ИИ она считает целесообразным «освободить пространство для других». Она добавила, что будет наблюдать за дальнейшим развитием событий «со стороны», зная, что у команды Meta✴ есть всё необходимое для построения эффективных и этически устойчивых ИИ-систем, способных интегрироваться в повседневную жизнь миллиардов людей. Пино присоединилась к Meta✴ в 2017 году для руководства лабораторией по исследованиям в области ИИ в Монреале. Она также занимает должность профессора информатики в Университете Макгилла (McGill University), где является содиректором лаборатории по обучению и логическому выводу. Среди проектов, курируемых Пино, — семейство открытых языковых моделей LLaMA, а также PyTorch — фреймворк машинного обучения для языка Python для разработчиков ИИ. Разработки под её руководством охватывали передовые направления в области компьютерных наук и впоследствии использовались в технологических решениях Meta✴. Объявление Пино прозвучало за несколько недель до проведения ежегодной конференции LlamaCon, которая состоится 29 апреля. Ожидается, что на мероприятии Meta✴ представит очередную версию большой языковой модели LLaMA. Главный директор по продуктам компании Крис Кокс (Chris Cox) заявил, что LLaMA 4 станет основой для ИИ-агентов нового поколения. По информации издания CNBC, компания также планирует выпустить отдельное приложение для чат-бота Meta✴ AI. На фоне этих разработок отставка Пино приобретает особое значение, учитывая её ключевую роль в формировании научного направления FAIR. ChatGPT остаётся самым популярным чат-ботом с ИИ, но у конкурентов аудитория тоже растёт
01.04.2025 [17:57],
Павел Котов
Чат-бот с искусственным интеллектом OpenAI ChatGPT остаётся самым популярным сервисом этого типа в мире. Но активно наращивают аудиторию и конкурирующие платформы, гласит статистика аналитических компаний SimilarWeb и Sensor Tower. 
Источник изображения: Levart_Photographer / unsplash.com SimilarWeb специализируется на оценке трафика веб-сайтов, включая веб-версии чат-ботов, и, как утверждают в компании, по итогам марта сервис Google Gemini нарастил аудиторию на 7,4 % в сравнении с февралём — показатель достиг 10,9 млн посетителей в день; Microsoft Copilot за месяц нарастил аудиторию на 2,1 млн до 2,4 млн; Anthropic Claude достиг в марте посещаемости в 3,3 млн человек; чат-бот китайской DeepSeek преодолел отметку 16,5 млн пользователей в день — такой же результат показал xAI Grok. У ChatGPT по состоянию на конец марта были 500 млн посетителей в день. Платформа OpenAI остаётся впереди с колоссальным отрывом, но за второе место развернулась нешуточная битва. Занявший по итогам марта второе место DeepSeek растерял 25 % февральской аудитории, xAI Grok по сравнению с предшествующим месяцем показал рост почти на 800 %, и это крупнейшая положительная динамика в рейтинге, говорят в SimilarWeb. Динамика посещаемости мобильных приложений чат-ботов связывается с выпуском новых моделей ИИ. В течение недели, начавшейся 24 февраля, когда Anthropic выпустила Claude 3.7 Sonnet, аудитория приложения Claude выросла на 21 %, гласит статистика Sensor Tower. Двумя неделями ранее, вскоре после выхода Google Gemini 2.0 Flash аудитория приложения Gemini показала недельный рост на 42 %. Помимо выхода обновлённых моделей, пользователей интересуют и новые возможности сервисов: функция Canvas в Gemini, которая позволяет запускать программный код; или новые функции Claude, которые Anthropic добавляет постоянно. Но и здесь поводов для паники у OpenAI пока не отмечается. По состоянию на март число активных пользователей мобильного приложения ChatGPT десятикратно превзошло аудиторию Gemini и Claude вместе взятых. OpenAI пообещала выпустить открытую рассуждающую ИИ-модель в ближайшие месяцы
01.04.2025 [16:34],
Павел Котов
«В ближайшие месяцы» OpenAI намерена выпустить открытую большую языковую модель искусственного интеллекта — она станет первой со времён GPT-2. Об этом говорится на специальной странице на сайте компании; здесь же размещена форма, которую предлагается заполнить «разработчикам, исследователям и всему сообществу». 
Источник изображения: Growtika / unsplash.com «Мы рады сотрудничеству с разработчиками, исследователями и сообществом, чтобы собрать мнения и сделать эту модель максимально полезной. Если вы заинтересованы дать обратную связь команде OpenAI, сообщите нам об этом [через форму] ниже», — говорится на сайте OpenAI. Дополнительно собрать отзывы и показать прототипы модели компания хочет на мероприятиях, которые проведёт сама. Первое через несколько недель пройдёт в Сан-Франциско, за ним последуют встречи в Европе и Азиатско-Тихоокеанском регионе. OpenAI приходится всё активнее отбивать атаки конкурентов, в том числе китайской DeepSeek, которые выпускают открытые модели ИИ. Конкуренты позволяют сообществу использовать эти системы как для экспериментов, так и в коммерческих целях. Значительные средства в разработку моделей семейства Llama вложила Meta✴ — в марте эти модели набрали более 1 млрд загрузок. Большую базу пользователей быстро собрала DeepSeek. «[Лично я считаю,] нам нужно выработать другую стратегию в отношении открытого исходного кода. Эту точку зрения в OpenAI разделяют не все, и сейчас это нашим приоритетом не является. [В будущем] мы станем выпускать лучшие модели, но наше лидерство станет меньшим, чем в предыдущие годы», — рассказал ранее глава OpenAI Сэм Альтман (Sam Altman). Новая открытая модель будет поддерживать функцию рассуждений, добавил он накануне в соцсети X. Компания проведёт все стандартные проверки, как перед выпуском коммерческих моделей, и ряд дополнительных, учитывая, что после выпуска пользователи начнут её дорабатывать самостоятельно. Развёртывать её будут крупные компании и правительственные учреждения, считает господин Альтман. Copilot+PC на чипах Intel и AMD наконец получили новые ИИ-функции для Paint, «Фото» и не только
01.04.2025 [11:46],
Павел Котов
Microsoft сделала доступными новые функции искусственного интеллекта на устройствах класса Copilot+PC с процессорами Intel и AMD. Одной из наиболее заметных обещает стать Live Captions — осуществляемый в реальном времени перевод аудио с десятков разных языков на английский и вывод субтитров. 
Источник изображения: blogs.windows.com Тестирование Live Captions на компьютерах нового поколения с чипами Intel и AMD стартовало в декабре минувшего года; с выходом очередного обновления Windows 11 функция стала общедоступной. Обновление также включает в себя функцию Cocreator — инструмент ИИ в Paint, генерирующий картинки по текстовому описанию или на основе простых эскизов. 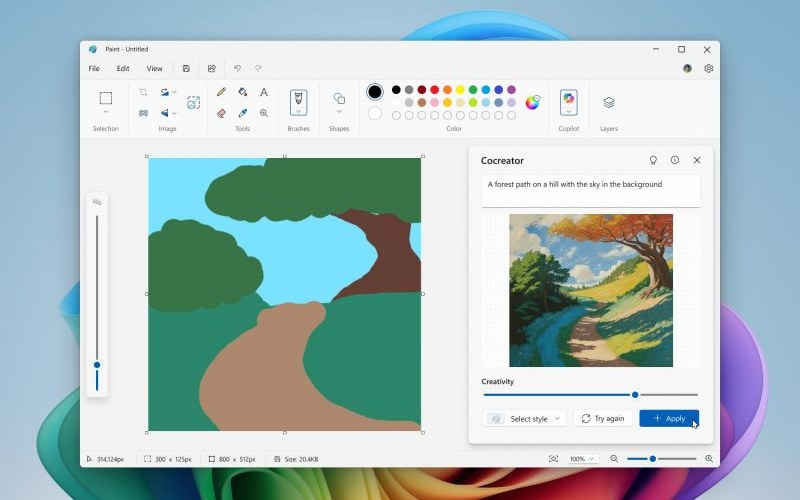 Расширен доступ к редактору и генератору изображений (Restyle Image и Image Creator) в приложении «Фотографии». Ранее эти функции работали только на компьютерах Copilot+PC с чипами Qualcomm. 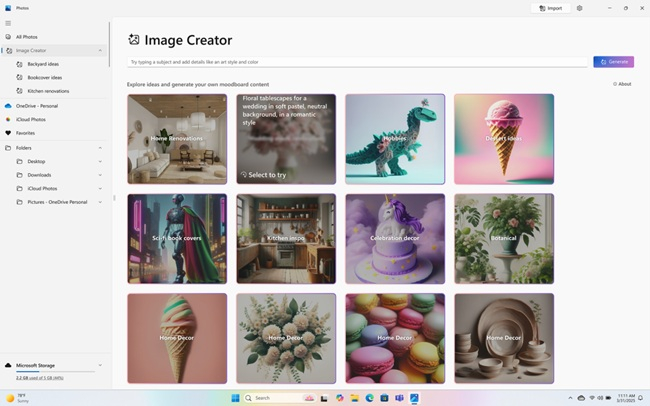 В прошлом году Microsoft начала тестировать на ПК с процессорами нового поколения Intel и AMD ИИ-функцию Recall, которая предусматривает регулярное сохранение снимков экрана на компьютере и поиск по ним; сроки её выхода в общедоступном варианте пока неизвестны. Для компьютеров на процессорах Qualcomm обновилась функция Voice Access из набора специальных возможностей, позволяющая управлять ПК голосовыми командами, — теперь она понимает «более описательный и гибкий язык». Добавлена возможность перевода с 27 языков на упрощённый китайский. В перспективе обе эти функции появятся на устройствах с процессорами Intel и AMD. OpenAI привлекла $40 млрд инвестиций от «синдиката инвесторов» — деньги пойдут на создание AGI
01.04.2025 [11:07],
Павел Котов
В ходе очередного раунда финансирования OpenAI привлекла $40 млрд от группы инвесторов во главе с SoftBank — разработчика ИИ при этом оценили в $300 млрд. Это крупнейший в истории раунд финансирования частной технологической компании, сообщает CNBC. 
Источник изображения: Mariia Shalabaieva / unsplash.com OpenAI получит авансом $10 млрд, $7,5 млрд из которых поступят от SoftBank и $2,5 млрд — от «синдиката инвесторов». Остальные $30 млрд будут переведены к концу года при условии, что к тому времени OpenAI проведёт реорганизацию и станет коммерческой компаний. В противном случае объём сделки сократится на четверть. В январе OpenAI объявила о проекте Stargate — совместное предприятие с бюджетом $500 млрд при поддержке SoftBank, Oracle и фонда MGX из Абу-Даби в ближайшие четыре года намеревается построить сеть гигантских центров обработки данных для систем искусственного интеллекта. Сейчас компания в ударе: накануне её гендиректор Сэм Альтман (Sam Altman) сообщил, что всего за час платформа привлекла 1 млн пользователей благодаря функции Images в ChatGPT, ставшей вирусной из-за возможности генерировать изображения в стиле аниме Studio Ghibli. В ближайшие месяцы OpenAI намеревается выпустить мощную большую языковую модель с открытыми весами. Еженедельная аудитория сервисов OpenAI составляет 500 млн пользователей, сообщалось в ходе раунда финансирования. Несмотря на бурный рост из-за ChatGPT, у компании сохраняются колоссальные издержки. По итогам текущего года она намеревается получить $12,7 млрд дохода — в прошлом году этот показатель был $3,7 млрд. На положительный денежный поток компания намеревается выйти в 2029 году, когда её выручка достигнет $125 млрд. В ходе раунда финансирования OpenAI в очередной раз озвучила цель своей работы — «создание сильного ИИ (AGI), который принесёт пользу всему человечеству». Для достижения этой цели компании потребуются значительные вычислительные и энергетические ресурсы, глобальная инфраструктура и очень большие деньги, дал понять Сэм Альтман. «Он смотрит в прошлое»: глава Take-Two объяснил, почему ИИ никогда не создаст собственную GTA VI
01.04.2025 [10:37],
Дмитрий Рудь
Генеральный исполнительный директор Take-Two Interactive Штраус Зельник (Strauss Zelnick) прокомментировал потенциальное влияние генеративного искусственного интеллекта на игровую индустрию. 
Источник изображения: Kotaku В последнее время генеративный ИИ приобретает всё большее значение в области интерактивных развлечений, однако, по мнению Зельника, игровых хитов на базе этой технологии ждать не стоит. В интервью Кэролин Дейли (Carolyn Dailey) для её книги The Creative Entrepreneur руководитель Take-Two заявил, что «не волнуется насчёт создания искусственным интеллектом хитов». «Потому что [ИИ] основывается на уже существующих данных. Он смотрит в прошлое. Большие хиты обращены в будущее и должны быть созданы из ничего», — поделился Зельник. 
Источник изображения: Rockstar Games Глава Take-Two считает, что для создания чего-то по-настоящему успешного в игровой индустрии нужно «нанимать лучших творцов, наставлять их следовать за своими увлечениями, пробовать что-то новое и держаться подальше от подражания». «В Голливуде принято презентовать свой продукт как смесь "Человека-паука", "Бэтмена" и "Назад в будущее"... Мы таким не занимаемся. Мы стремимся к чему-то, что вы никогда не видели», — заверил Зельник. В настоящее время Take-Two готовит к выпуску криминальный боевик GTA VI от Rockstar Games, который считается одной из самых ожидаемых видеоигр в истории индустрии. Релиз планируется осенью текущего года на PS5, Xbox Series X и S. Amazon представила ИИ-агента Nova Act, который заменит человека в интернет-серфинге
31.03.2025 [18:03],
Сергей Сурабекянц
Amazon представила универсального ИИ-агента Nova Act, который может управлять веб-браузером и самостоятельно выполнять некоторые простые действия. В будущем Nova Act будет поддерживать все функции Alexa+ — обновлённого голосового помощника Amazon. Одновременно с агентом компания выпустила набор инструментов Nova Act SDK, который позволяет разработчикам создавать собственные прототипы агентов. 
Источник изображения: Pixabay Nova Act разработан недавно открытой в Сан-Франциско лабораторией AGI Amazon, возглавляемой бывшими исследователями OpenAI Дэвидом Луаном (David Luan) и Питером Аббелем (Pieter Abbeel). Amazon называет выпуск ИИ-агента «исследовательским предварительным просмотром». Разработчики уже сейчас могут получить доступ к набору инструментов Nova Act на специализированном ресурсе nova.amazon.com, который также служит «витриной» для различных моделей Nova Foundation от Amazon. Nova Act — это попытка Amazon составить конкуренцию OpenAI Operator и Anthropic Computer Use с помощью технологии агентов ИИ общего назначения. Многие лидеры рынка искусственного интеллекта считают, что агенты ИИ, которые могут исследовать интернет по заданию пользователей, сделают чат-ботов ИИ значительно более полезными. Amazon рассчитывает, что распространённость Alexa+ обеспечит новому агенту широкий охват. Разработчики, использующие Nova Act SDK, смогут автоматизировать базовые действия от имени пользователей, такие как заказ продуктов или бронирование столика в ресторане. С помощью Nova Act разработчики могут объединить инструменты, которые позволят ИИ-агенту перемещаться по веб-страницам, заполнять формы или выбирать даты в календаре. По данным Amazon, Nova Act превосходит агентов от OpenAI и Anthropic в нескольких внутренних тестах компании. Например, в ScreenSpot Web Text, который измеряет, как агент ИИ взаимодействует с текстом на экране. Nova Act набрал 94 %, превзойдя CUA OpenAI (88 %) и Claude 3.7 Sonnet от Anthropic (90 %). По мнению экспертов, основная проблема с недавно выпущенными ИИ-агентами от OpenAI, Google и Anthropic заключается в их низкой надёжности. Во многих тестах они работают медленно, с трудом принимают самостоятельные решения и склонны к ошибкам, которые человек бы не допустил. В скором времени станет ясно, удалось ли Amazon избавить свой продукт от этих недостатков. Голливудские студии перенаправили монетизацию фейковых трейлеров на YouTube себе в карман
31.03.2025 [16:59],
Дмитрий Федоров
Крупные голливудские студии, включая Warner Bros. Discovery, Paramount и Sony Pictures, приняли решение не пресекать распространение видеороликов, созданных с помощью генеративного ИИ и опубликованных на YouTube, несмотря на наличие признаков нарушения авторских прав. Вместо подачи жалоб на удаление такого контента студии потребовали от видеохостинга перенаправить рекламную выручку с этих видео в свою пользу, фактически узаконив присутствие несанкционированного контента на площадке. 
Источник изображения: Allison Saeng / Unsplash Гильдия киноактеров и Американская федерация артистов телевидения и радио (SAG-AFTRA) осудила действия студий, подчеркнув, что видео используют цифровые образы актёров без их согласия. Это происходит на фоне усилий гильдии, добивающейся включения положений об использовании ИИ в договоры. Видео представляют собой пример эксплуатации внешности и голоса актёров без правового основания, что нарушает как этические нормы, так и интересы членов объединения. Контент YouTube-каналов Screen Culture и KH Studio включает фальшивые трейлеры, которые имитируют анонсы новых фильмов или продолжений популярных франшиз. Screen Culture насчитывает 1,4 млн подписчиков и около 1,4 млрд просмотров. KH Studio имеет 683 тысячи подписчиков и более 560 млн просмотров. Видеоролики строятся по типовой схеме: монтаж реальных фрагментов из существующих фильмов и сериалов дополняется кадрами, сгенерированными ИИ. Некоторые видео создаются на основе реальных фильмов, чьи официальные трейлеры уже доступны, например «Супермен» (Superman) и «Мир Юрского периода: Возрождение» (Jurassic World: Rebirth), тогда как другие полностью вымышлены. 
Источник изображения: YouTube / Screen Culture Через два дня после публикации расследования изданием Deadline, YouTube прекратил монетизацию обоих каналов. Согласно официальной позиции платформы, упомянутые YouTube-каналы были удалены из партнёрской программы за нарушение политики монетизации. Правила YouTube запрещают создавать дублирующий или повторяющийся контент, а также видео, сделанные исключительно ради получения просмотров. Авторы обязаны вносить значительные изменения в заимствованные материалы и избегать публикации контента, способного ввести зрителя в заблуждение. Согласно политике YouTube в отношении дезинформации, авторам запрещено публиковать видео, которые могут быть восприняты как официальные, если они таковыми не являются. В случае с этими YouTube-каналами, поддельные трейлеры были оформлены таким образом, что зрители могли принять их за реальную продукцию киностудий. Оба канала могут обжаловать приостановку рекламных отчислений. После блокировки партнёрской программы KH Studio изменил заголовки последних трёх видео, указав в них термин «concept trailer» вместо ранее использовавшегося «first trailer». В своём заявлении SAG-AFTRA сообщила, что рассчитывает на активные действия со стороны студий по защите прав своих участников. Организация подчеркнула, что монетизация несанкционированного, нежелательного и низкокачественного использования интеллектуальной собственности подрывает индустрию. По мнению гильдии, подобная практика стимулирует краткосрочные интересы технологических компаний в ущерб системной защите результатов человеческого труда. Arm собралась руками Nvidia захватить половину рынка процессоров для дата-центров
31.03.2025 [16:24],
Дмитрий Федоров
Arm Holdings ожидает, что к концу 2025 года ей будет принадлежать до 50 % мирового рынка центральных процессоров (CPU), используемых в центрах обработки данных. По словам представителя компании, в 2024 году доля Arm составляла около 15 %. Предпосылкой для значительного прироста назван резкий рост популярности вычислительных систем, предназначенных для задач ИИ, где активно применяются CPU на базе архитектуры Arm. 
Источник изображения: arm.com Процессоры Arm используются в качестве хост-компонентов в инфраструктуре ИИ-систем. Их роль заключается в управлении потоками данных между высокопроизводительными графическими ускорителями (GPU). В качестве примера Мохамед Авад (Mohamed Awad), возглавляющий направление инфраструктурных решений Arm, привёл серверные системы компании Nvidia, в которых применяется разработанный ею процессор Grace на архитектуре Arm. В отдельных системах Grace работает совместно с двумя GPU нового поколения Blackwell, также созданными Nvidia. Авад подчеркнул, что архитектура Arm демонстрирует преимущество по показателю энергопотребления по сравнению с решениями конкурентов, включая процессоры Intel и AMD. Поскольку ИИ-системы требуют значительных энергетических ресурсов, потребность в энергоэффективных архитектурах способствует увеличению спроса на продукты Arm среди поставщиков облачных вычислений. По словам Авада, Arm получает более высокий совокупный размер роялти с CPU, предназначенных для центров обработки данных, поскольку такие чипы используют больше компонентов интеллектуальной собственности компании. Это отличает их от менее сложных вычислительных решений, применяемых, например, в потребительских устройствах. Arm не производит микропроцессоры самостоятельно — компания лицензирует архитектуру и предоставляет интеллектуальные компоненты другим компаниям, включая облачных провайдеров и производителей, таких как Apple и Nvidia, для разработки CPU для серверов, ноутбуков и смартфонов. Выручка Arm формируется за счёт лицензионных отчислений за использование технологий и роялти за каждый произведённый чип. В течение почти двадцати лет Arm не удавалось занять значимую долю в сегменте серверных CPU из-за доминирования архитектуры x86, разработанной Intel и AMD. Переход на платформу Arm требовал от клиентов адаптации программного обеспечения (ПО) и изменения аппаратных компонентов. Однако, по утверждению Авада, ситуация изменилась: теперь разработка ПО всё чаще ведётся сразу под архитектуру Arm. Amazon сообщила в декабре 2024 года, что в течение последних двух лет более половины вычислительной мощности новых серверов компании обеспечивалось за счёт CPU, разработанных Amazon на базе архитектуры Arm. По данным издания Reuters, компании Alphabet (владеющая Google) и Microsoft также начали разработку собственных серверных CPU с использованием технологий Arm. Их проекты появились позже по сравнению с инициативами Amazon. Китайская Zhipu AI ворвалась в ИИ-гонку с бесплатным ИИ-агентом AutoGLM Rumination
31.03.2025 [11:49],
Дмитрий Федоров
Китайская компания Zhipu AI, специализирующаяся на разработке систем искусственного интеллекта, представила ИИ-агента под названием AutoGLM Rumination. Новинка стала частью волны аналогичных проектов на фоне нарастающей конкуренции на китайском рынке ИИ. AutoGLM Rumination способен выполнять углублённые исследования, а также справляться с прикладными задачами, включая поиск информации в интернете, планирование путешествий и составление исследовательских отчётов. 
Источник изображения: zhipuai.cn Агент основан на моделях собственной разработки Zhipu AI. В их число входят рассуждающая ИИ-модель GLM-Z1-Air и базовая языковая модель GLM-4-Air-0414. Компания утверждает, что GLM-Z1-Air демонстрирует производительность, сопоставимую с моделью R1 компании DeepSeek, но работает в восемь раз быстрее и требует лишь одну тридцатую вычислительных ресурсов. Такие характеристики указывают на потенциальное снижение затрат на развёртывание и эксплуатацию ИИ-систем, что особенно важно на фоне масштабной интеграции нейросетей в экономику и государственное управление. ИИ-агенты представляют собой автономные программные системы, способные принимать решения и выполнять широкий спектр задач без постоянного вмешательства пользователя. В начале 2025 года компания DeepSeek представила ИИ-модель, работающую при значительно меньших издержках, чем американские аналоги, что вызвало значительный интерес на рынке. На этом фоне китайские разработчики ускорили вывод отечественных решений в области ИИ. Презентация Zhipu AI состоялась спустя несколько недель после заявления конкурирующей компании Manus, представившей своего ИИ-агента как первого в мире универсального ИИ-агента. В отличие от Manus, предлагающей продукт по подписке стоимостью до $199 в месяц, AutoGLM Rumination будет доступен бесплатно. Компания заявляет, что пользователи смогут получить доступ к ИИ-агенту через официальный сайт модели GLM и мобильное приложение. Компания Zhipu AI была основана в 2019 году как самостоятельная организация, выделившаяся из исследовательской лаборатории при Университете Цинхуа (Tsinghua University) с целью коммерциализации разработок в области ИИ. За последние годы она заняла одно из ведущих мест среди китайских ИИ-стартапов. Zhipu AI известна разработкой серии моделей GLM, последняя из которых — GLM4 — по заявлению компании превосходит GPT-4 по ряду бенчмарков. Подробные данные о метриках и условиях тестирования не раскрываются. Ранее в марте Zhipu AI провела три раунда финансирования при участии китайских государственных структур. Последние инвестиции поступили от администрации города Чэнду, которая вложила в компанию 300 млн юаней (около $41,5 млн). Участие региональных властей отражает стратегическую заинтересованность китайских городов в развитии ИИ-решений, особенно в условиях усиливающегося соперничества с иностранными разработками. Apple добавит ИИ-врача в приложение «Здоровье» для iPhone
31.03.2025 [09:05],
Дмитрий Федоров
Apple готовит к запуску полностью переработанную версию приложения «Здоровье», которая выйдет в составе обновления iOS 19.4. Проект, получивший кодовое название Mulberry, предусматривает создание нового цифрового консультанта по здоровью на основе ИИ. 
Источник изображения: Curated Lifestyle / Unsplash По данным журналиста Bloomberg Марка Гурмана (Mark Gurman), запуск ИИ-агента ожидается весной или летом 2026 года. Разработка ведётся при участии подразделения Apple по ИИ. Как отмечает Гурман, новый ИИ-консультант будет воспроизводить функции реального врача, используя информацию, собираемую устройствами Apple — преимущественно Apple Watch. Пользователь сможет получать персонализированные рекомендации, основанные на анализе физиологических данных. Это соответствует долгосрочной стратегии Тима Кука (Tim Cook), согласно которой основной вклад Apple в благополучие общества должен быть связан с развитием здравоохранения. ИИ-агент обучается на данных, предоставленных врачами, нанятыми компанией Apple. Также планируется привлечение сторонних специалистов для записи видеоматериалов, которые будут интегрированы в приложение. В числе экспертов, с которыми предполагается сотрудничество, — кардиологи, диетологи, сомнологи, физиотерапевты и специалисты по психическому здоровью. Согласно информации Гурмана, видеоконтент будет использоваться для объяснения пользователям возможных неблагоприятных изменений в состоянии их здоровья. Эти материалы будут записываться в новой студии Apple, расположенной в Окленде, штат Калифорния. Кроме того, Apple намерена привлечь известного врача, который станет ведущим нового сервиса и будет сопровождать образовательные видеоролики. Внутри компании эта инициатива получила неофициальное название Health+. Как сообщает Гурман, значительное внимание в обновлённом приложении будет уделено отслеживанию питания. Пользователи смогут фиксировать потребляемые продукты, а ИИ будет предоставлять рекомендации по рациону и корректировке пищевых привычек в зависимости от индивидуальных физиологических показателей. Также ведётся работа над функцией, использующей заднюю камеру iPhone для анализа тренировок. ИИ будет отслеживать движения пользователя и предлагать рекомендации по улучшению техники выполнения упражнений. Предполагается, что впоследствии эта функция будет интегрирована в экосистему Apple Fitness+. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться