|
Опрос
|
реклама
Быстрый переход
Ещё не выпущенные ИИ-гаджеты Rabbit R1 уже перепродают на eBay с двукратной наценкой
13.01.2024 [13:36],
Владимир Фетисов
Неожиданным хитом выставки CES 2024 стал ИИ-гаджет Rabbit R1, который позволяет взаимодействовать с мобильными приложениями с помощью алгоритмов на основе нейросетей. Всего через сутки после презентации разработчики объявили, что им удалось продать 10 тыс. устройств R1. Хотя поставки начнутся лишь через пару месяцев, некоторые из первых покупателей уже выставили на eBay ИИ-гаджеты от Rabbit, рассчитывая перепродать их по более выгодной цене. 
Источник изображения: Rabbit Гаджет R1 оснащён 2,88-дюймовым дисплеем, вращающейся камерой для съёмки фото и видео, а также колесом прокрутки, которое помогает в навигации и взаимодействии со встроенным ИИ-помощником. Аппаратной основой устройства стал микропроцессор MediaTek с рабочей частотой 2,4 ГГц, 4 Гбайт оперативной памяти и накопитель ёмкостью 128 Гбайт. В качестве операционной системы задействована собственная разработка Rabbit OS с интегрированными ИИ-алгоритмами. Гаджет позволяет использовать единый интерфейс для управления разнообразными приложениями и сервисами разных разработчиков: музыкой, оформлением заказов на доставку еды, отправкой сообщений и др. Авторы R1 считают, что в будущем этот гаджет может стать потенциальной заменой смартфонов. Что касается стоимости ИИ-гаджета, то его можно предзаказать на официальном сайте Rabbit за $199. Проблема в том, что ввиду неожиданно высокой популярности за первые двое суток с момента презентации были распроданы две партии R1 по 10 тыс. единиц каждая. Согласно имеющимся данным, покупатели устройств из первой партии начнут получать R1 в марте, а из второй — в апреле-мае 2024 года. Гаджет всё еще можно заказать на сайте Rabbit, но получить его удастся не раньше мая-июня. 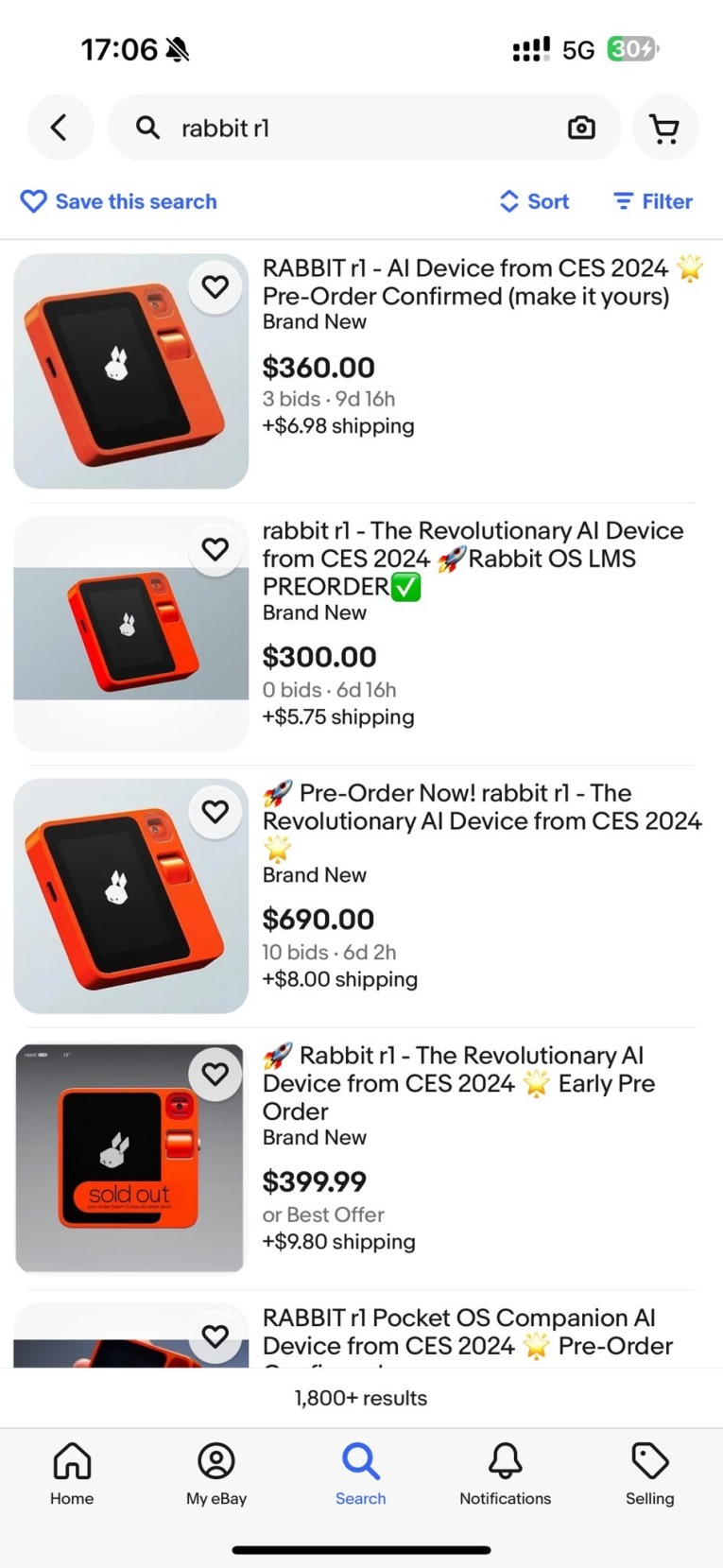
Источник изображения: Jesse Lyu / X Этим и решили воспользоваться некоторые люди, успевшие заказать устройства из первых партий. Они предлагают купить R1 на платформе eBay по значительно более высокой цене от $300 до $690. Авторы таких лотов обещают отправить устройство покупателям сразу же после того, как получат свои предзаказанные R1. Такая предприимчивость некоторых покупателей не понравилась разработчикам. Основатель и генеральный директор Rabbit Джесси Лю (Jesse Lyu) опубликовал в своём аккаунте в соцсети X снимок экрана с несколькими лотами R1 на eBay. «Чёрт возьми, нет. Не делайте этого», — на писал Лю в комментарии к фото. Очевидно, компания не ожидала, что спрос на R1 будет настолько высоким, из-за чего в данный момент она не в состоянии удовлетворить спрос в полной мере. Rabbit за сутки продала 10 тыс. ИИ-гаджетов R1 — в 20 раз больше, чем ожидалось
11.01.2024 [13:40],
Владимир Фетисов
ИИ-стартап Rabbit представил на выставке CES 2024 устройство R1, предназначенное для взаимодействия с мобильными приложениями при помощи алгоритмов на основе нейросетей. Теперь стартап объявил, что всего за сутки с момент презентации было продано более 10 тыс. устройств R1 стоимостью $199. Соответствующее сообщение появилось в аккаунте Rabbit в соцсети X (бывшая Twitter). 
Источник изображений: Rabbit «Когда мы создавали R1, мы сказали себе, что будем рады, если в день запуска продадим 500 устройств. За 24 часа мы уже превзошли этот показатель в 20 раз!», — говорится в сообщении Rabbit. Что касается самого гаджета R1, то в его конструкции предусмотрен 2,88-дюймовый дисплей, вращающаяся камера для съёмки фото и видео, а также колесо прокрутки, помогающее в навигации и взаимодействии со встроенным ИИ-помощником. Согласно имеющимся данным, аппаратной основой R1 стал микропроцессор MediaTek с рабочей частотой 2,4 ГГц, 4 Гбайт оперативной памяти и накопитель на 128 Гбайт. Роль программной платформы исполняет Rabbit OS с интегрированными ИИ-алгоритмами. Платформа позволяет через единый интерфейс управлять музыкой, заказывать доставку и такси, отправлять сообщения и др. Хотя первая партия устройств Rabbit R1 полностью распродана, желающие стать обладателем необычного гаджета могут оформить предзаказ на официальном сайте стартапа. По данным производителя, поставки новинки начнутся в апреле-мае этого года. Тем же кто успел заказать R1 из первой партии, устройство будет доставлено в марте. Microsoft добавит ИИ даже в «Блокнот» — функция Cowriter поможет с обработкой текста
11.01.2024 [01:46],
Владимир Фетисов
Похоже, что в этом году Microsoft планирует также активно интегрировать функции на основе искусственного интеллекта в свои продукты, как это было в году минувшем. На этой неделе стало известно о планах софтверного гиганта добавить в «Блокнот» для Windows 11 функцию под названием Cowriter, которая будет задействовать нейросети для корректировки текста. 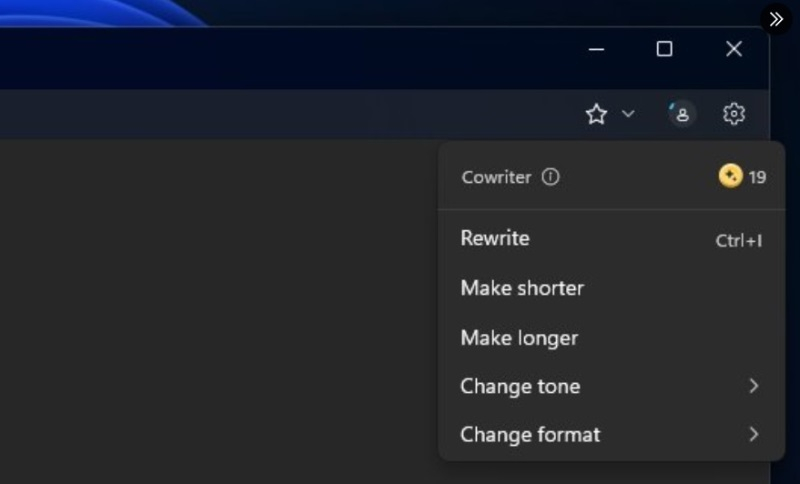
Источник изображения: @PhantomOcean3 / X Инсайдеры @PhantomOcean3 и @teroalhonen поделились скриншотами новой версии «Блокнота» и файлов, связанных с текстовым редактором. Речь идёт о версии «Блокнота» 11.2312.17.0, в которой и были обнаружены упоминания функции Cowriter. Хотя на данный момент инструмент не работает, не трудно догадаться, для чего именно он предназначен. 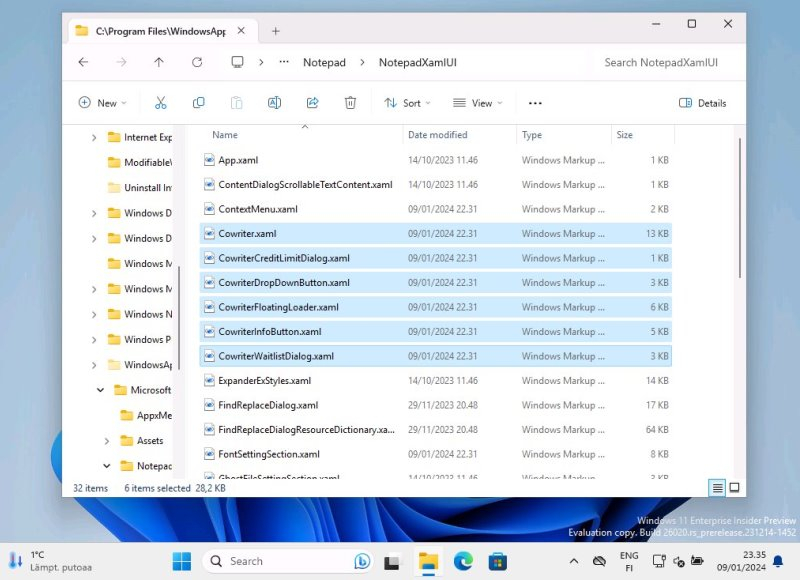
Источник изображения: @teroalhonen / X Предполагается, что инструмент Cowriter будет задействовать нейросети для корректировки набираемого текста, изменения его длины, фона или даже форматирования. Вероятно, в скором времени Microsoft анонсирует новую функцию, после чего она станет доступна участникам программы предварительной оценки Windows Insider. Когда разработчики планируют добавить Cowriter в стабильные версии «Блокнота», пока неизвестно. ИИ больно ударит по сотрудникам Google — грядут сокращения в отделе продаж
25.12.2023 [16:37],
Владимир Фетисов
По сообщениям сетевых источников, компания Google рассматривает возможность смены направления деятельности или увольнения части сотрудников отдела продаж, чья работа была автоматизирована за счёт запуска инструментов на основе искусственного интеллекта. Ранее в этом году поисковый гигант запустил «новую эру рекламы на основе ИИ» как способ улучшения взаимодействия рекламодателей с компанией. 
Источник изображения: JHVEPhoto / Shutterstock Согласно имеющимся данным, в настоящее время рекламное подразделение Google насчитывает около 30 тыс. сотрудников, причём почти половина из них занимается продажей рекламы для определённых рекламных сервисов Google. Необходимость в этих сотрудниках фактически отпала после запуска ряда ИИ-инструментов. Ожидается, что в долгосрочной перспективе замена сотрудников на ИИ поможет Google нарастить прибыль. Стоит отметить, что не только в рекламном бизнесе большое количество людей может лишиться своих мест из-за технологий на основе искусственного интеллекта. По мере того, как нейросети становятся всё более продвинутыми, на некоторые должности, традиционно занимаемые людьми, потенциально может претендовать ИИ. По данным исследования хостинговой компании Hostinger, искусственный интеллект может заменить людей некоторых профессий в сферах здравоохранения, транспорта и финансовых услуг, среди прочего. Ожидается, что в сфере здравоохранения, особенно в таких областях, как выполнение административных задач в больницах, искусственный интеллект придёт на смену человеку быстрее всего. Будущее соучредителя OpenAI Ильи Суцкевера в компании остаётся под вопросом
09.12.2023 [13:20],
Владимир Фетисов
После возвращения Сэма Альтмана (Sam Altman) на должность генерального директора OpenAI произошло немало событий, одним из которых стал роспуск совета директоров. Однако неясной остаётся судьба главного научного сотрудника компании Ильи Суцкевера (Ilya Sutskever), который, как сообщалось, сыграл важную роль в смещении Альтмана с должности. 
Источник изображения: Viralyft / unsplash.com По данным издания Business Insider, ссылающегося на собственные источники в OpenAI, на этой неделе Суцкевер не появлялся в офисе компании в Сан-Франциско, хотя его имя продолжает фигурировать в системах компании, таких как Slack, а картины Ильи продолжают дополнять интерьер офиса. Один из источников отметил, что будущее Суцкевера в компании ещё не обсуждалось руководством официально. «Илья всегда будет играть важную роль. Но, вы знаете, есть много других людей, готовых взять на себя ответственность, которую исторически нёс Илья», — добавил представитель компании, пожелавший сохранить конфиденциальность. Другой источник сообщил, что в настоящее время обсуждается возможность выделения Суцкеверу новой должности, и что есть желание «найти для него роль». При этом он отметил, что определённости относительно будущего главного научного сотрудника OpenAI в компании пока нет. Это не выглядит удивительным, учитывая, что Суцкевер сыграл важную роль в увольнении Альтмана с поста гендиректора, вслед за которым ушёл соучредитель OpenAI Грег Брокман (Greg Brockman), а многие сотрудники компании пригрозили последовать их примеру. Суцкевер входил в совет директоров, который принял решение об увольнении Альтмана. Однако его значение и влияние в компании, а также статус соучредителя делают Суцкевера более значимой фигурой по сравнению с любым другим членом совета директоров. Продолжающийся кризис в OpenAI подтверждает недавний пост Суцкевера в соцсети X, где он написал: «За последний месяц я усвоил много уроков. Одним из таких уроков является то, что фраза «избиения будут продолжаться до тех пор, пока не улучшится моральный дух» применяется чаще, чем имеет на то право». Эта фраза часто используется в мемах для ироничного обозначения цикла, когда низкая мораль порождает наказание, делающее её ещё более низкой. Также известно, что Суцкевер нанял адвоката, которым стал Алекс Вайнгартен (Alex Weingarten) из Willkie & Gallagher. Адвокат отказался комментировать вопросы сотрудничества с Суцкевером, сообщив лишь, что его клиент желает лучшего для компании. Официальные представители OpenAI также воздерживаются от комментариев по данному вопросу. Google представила ИИ-модель Gemini — она должна стать главным конкурентом GPT-4
06.12.2023 [22:11],
Владимир Фетисов
Google объявила о запуске модели искусственного интеллекта Gemini, которая станет основой ИИ-функций компании и бросит вызов конкурентам, включая ChatGPT от OpenAI. По словам гендиректора Google Сундара Пичаи (Sundar Pichai), появление нового алгоритма знаменует начало новой эры искусственного интеллекта в компании. 
Источник изображений: Google «Одна из самых важных особенностей этого момента в том, что вы можете работать над одной базовой технологией и улучшать её, и это сразу будет распространяться на все наши продукты», — сказал господин Пичаи. Гендиректор Google отметил, что запуск языковой модели Gemini является огромным шагом вперёд и в конечном счёте это окажет влияние практически на все продукты компании. Gemini представляет собой нечто большее, чем одна языковая модель. Существует более лёгкая версия ИИ-модели Gemini Nano, которая предназначена для автономной работы на устройствах с Android. Кроме того, существует более мощная версия Gemini Pro, которая в будущем станет основой многих сервисов Google, а с сегодняшнего дня является основой чат-бота Bard. В дополнение к этому Google создала ИИ-модель Gemini Ultra, которая является самой мощной языковой моделью компании и в основном предназначена для использования в центрах обработки данных и интеграции с корпоративными приложениями. 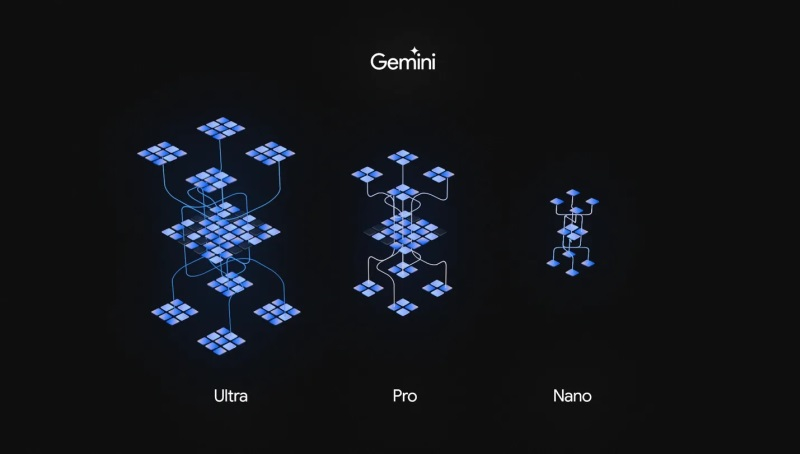 На потребительский рынок компания выводит свою ИИ-модель сразу несколькими способами. Чат-бот Bard теперь работает на основе Gemini Pro, а пользователи Pixel 8 Pro получат доступ к нескольким новым функциям благодаря интеграции с Gemini Nano. Возможность использования Gemini Ultra появится в следующем году. Разработчики и корпоративные клиенты смогут получить доступ к Gemini Pro через Google Generative AI Studio или Vertex AI в Google Cloud, начиная с 13 декабря. На данный момент Gemini может обрабатывать запросы на английском языке, но, очевидно, что в дальнейшем, появится поддержка других языков. По словам Сундара Пичаи, эта ИИ-модель в конечном счёте будет интегрирована в поисковую систему Google, рекламные продукты компании, браузер Chrome и другие сервисы. Похоже, что Google, являющаяся создателем большей части основополагающих технологий, способствовавших нынешнему буму в сфере ИИ, и уже около десяти лет называвшая себя компанией, ориентированной на искусственный интеллект, готова дать отпор запущенному год назад ChatGPT, который оказался настолько хорош, что явно заставил нервничать IT-гиганта. В рамках презентации Gemini гендиректор Google DeepMind Демис Хассабис (Demis Hassabis) рассказал, что Google провела тщательное сравнение своей языковой модели с GPT-4, наиболее актуальной версией нейросети, лежащей в основе ChatGPT. «Мы провели очень тщательный сравнительный анализ систем. Я думаю, что мы существенно опережаем конкурента по 30 из 32 показателей», — сказал Хассабис, указывая на 32 хорошо себя зарекомендовавших теста сравнения больших языковых моделей. Он также отметил, что в некоторых тестах превосходство Gemini над GPT-4 минимально, тогда как в других оно более ощутимо. В этих тестах наиболее явным преимуществом Gemini стала способность понимать видео и аудио, а также взаимодействовать с ними. По большому счёту, Google так и задумывала, поскольку компания не создавала отдельные ИИ-модели для обработки изображений и аудио, как сделала OpenAI, создав DALL-E и Whisper. С самого начала Google работала над созданием единой модели, способной распознавать изображения и звуки. На данный момент базовые версии Gemini поддерживают ввод и вывод текста, но более мощные версии алгоритма, такие как Gemini Ultra, могут работать с изображениями, видео и аудио. Конечно, эти модели всё ещё галлюцинируют, они не лишены предубеждений и других проблем, но со временем Google планирует улучшить их понимание окружающего мира. Несмотря на проведённые разработчиками тесты, главную проверку Gemini проведут рядовые пользователи, которые захотят использовать алгоритм для поиска информации, создания контента, написания программного кода и многого другого. В плане генерации кода алгоритм Google использует новую систему AlphaCode 2, которая, по словам представителей компании, работает лучше по сравнению с 85 % аналогами конкурентов и на 50 % лучше по сравнению с оригинальным алгоритмом AlphaCode. Не менее важно для Google и то, что Gemini, вероятно, является максимально эффективной моделью. Она обучалась с использованием тензорных процессоров Google, благодаря чему может работать быстрее и эффективнее, чем предыдущие алгоритмы компании, такие как PaLM. Наряду с новой языковой моделью Google представила ускорители TPU v5p, которые предназначены для использования в центрах обработки данных для обучения и запуска больших языковых моделей. Презентация Gemini даёт понять, что Google рассматривает новый алгоритм как масштабный проект и одновременно большой шаг вперёд для всей компании. Gemini — это ИИ-модель, к которой Google шла годами, возможно, даже та, которую ей следовало выпустить до того, как мир захватил ChatGPT. Google приложили массу усилий, чтобы обеспечить безопасность и надёжность Gemini, проведя внутреннее и внешнее тестирование алгоритма, но и это, по словам руководителей компании, не гарантирует, что нейросеть будет работать безошибочно. В течение многих лет Сундар Пичаи и другие руководители Google поэтически рассуждали о потенциале искусственного интеллекта. Сам Пичаи не раз говорил, что ИИ окажет на человечество более сильное влияние, чем огонь или электричество. Первое поколение модели Gemini, скорее всего, не изменит мир. В лучшем случае она поможет компании догнать ChatGPT, но руководство Google, уверено, что это начало чего-то большего. «Яндекс» запустил сервис «Нейростат» для отслеживания популярности искусственного интеллекта в России
05.12.2023 [14:04],
Владимир Фетисов
Компания «Яндекс» объявила о запуске сервиса «Нейростат», который представляет собой инструмент для оценки уровня осведомлённости и использования генеративных нейросетей на территории России. Решение предоставляет статистические данные и позволяет следить за тем, как ИИ-алгоритмы всё глубже проникают в повседневную жизнь людей. 
Источник изображений: «Яндекс» Статистические данные «Яндекса» указывают на то, что в настоящее время 58 % россиян в возрасте от 18 до 45 летзнают о существовании алгоритмов для генерации текстов по короткому описанию. В ноябре этого года 31 % пользователей применяли такие нейросети для создания текстов, что существенно больше 23 % пользователей, которые взаимодействовали с генераторами текста в мае. О существовании генеративных алгоритмов, способных создавать изображения и видео по текстовому описанию, осведомлены 75 % пользователей в возрасте от 18 до 45 лет. В ноябре 31 % пользователей использовали такие алгоритмы для создания изображений. 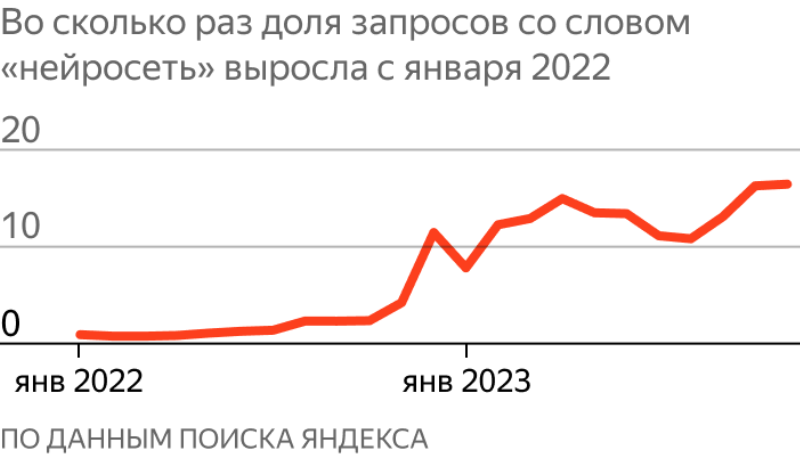
Источник изображения: «Яндекс» По данным поисковой системы «Яндекса», с начала 2022 года интерес к ИИ-алгоритмам со стороны пользователей вырос более чем в 15 раз. В настоящее время слово «нейросеть» встречается в запросах так же часто, как «фитнес», «психолог» или «пиво». Для взаимодействия с нейросетями используются «промты» или «промпты» — текстовое описание задания или инструкция. Этот термин менее распространён, сейчас о нём знают 13 % пользователей текстовых нейросетей, из которых 18 % уже ими пользуются. Apple вкладывает «достаточно много» средств в ИИ, заявил Тим Кук
03.11.2023 [15:36],
Владимир Фетисов
Сегодня Apple озвучила финансовые результаты по итогам прошедшего квартала. Вместе с этим руководство компании ответило на вопросы аналитиков и инвесторов. Так, главу Apple Тима Кука (Tim Cook) спросили, каким образом компания планирует монетизировать возможности генеративных нейросетей. Он, конечно, не дал прямого ответа на этот вопрос, но отметил, что компания инвестирует «достаточно много» в искусственный интеллект. 
Источник изображения: Apple «Если вы посмотрите масштабнее на то, что мы сделали с помощью технологий искусственного интеллекта и машинного обучения, и как мы их использовали, вы увидите, что это фундаментальные вещи, являющиеся неотъемлемыми для каждого нашего продукта. Когда мы выпустили iOS 17, в ней появились такие функции, как Personal Voice и Live Voicemail, в основе которых лежит ИИ. Можно дойти до функций, спасающих жизнь, на часах и смартфоне, таких как обнаружение падения, обнаружение аварий и ЭКГ на часах. Они были бы невозможны без ИИ. Мы не называем их как таковыми, поскольку мы определили их потребительскую выгоду, но основополагающими технологиями, лежащими в их основе, являются ИИ и машинное обучение <…> Что касается генеративного ИИ, то здесь у нас, безусловно, есть над чем работать. Я не буду вдаваться в подробности, потому что мы этим не занимаемся, но вы можете быть уверены, что мы инвестируем. Мы инвестируем достаточно много. Мы собираемся делать это ответственно. Со временем вы увидите новые продукты, в основе которых будут лежать эти технологии», — рассказал Тим Кук. Глава Apple заявил, что компания намерена ответственно подойти к внедрению генеративных нейросетей в свои продукты, отметив, что этот процесс будет проходить постепенно. По слухам, Apple планирует в следующем году продолжить интеграцию технологий на базе ИИ в свои продукты. Возможно, речь, в том числе, идёт об использовании генеративных нейросетей. По данным источника, Apple тратит миллиарды долларов на исследования и разработки в сфере генеративных нейросетей. Российские власти рассматривают возможность создания платформы для разработки ПО на базе нейросетей
18.10.2023 [08:08],
Владимир Фетисов
Совет Федерации предложил Минцифры создать за счёт бюджета государственную платформу развития искусственного интеллекта для предоставления разработчикам доступа к вычислительной инфраструктуре и данным для развития программного обеспечения на базе нейросетей. Об этом пишет «Коммерсантъ» со ссылкой на решение Совета по развитию цифровой экономики при Совете Федерации. 
Источник изображения: Pixabay Из документа следует, что Минцифры в рамках обновления Национальной стратегии развития искусственного интеллекта до 2030 года рекомендуется сформировать государственную платформу развития ИИ для разработчиков. Соответствующие рекомендации в адрес регулятора 17 октября направил зампред Совета по развитию цифровой экономики при Совете Федерации Артём Шейкин. О результатах рассмотрения данной инициативы сенатор попросит сообщить не позднее 13 ноября. «Российские разработчики, не имеющие достаточных ресурсов, должны иметь доступ к государственным данным для создания технологий искусственного интеллекта», — считает господин Шейкин. Он также добавил, что на платформе должны размещаться дата-сеты, пригодные для обучения ИИ-алгоритмов. Кроме того, разработчики получат доступ к вычислительной инфраструктуре. Он считает, что этот проект должен быть профинансирован из бюджета. По данным источника, после обострения ситуации на Украине и ухода с российского рынка иностранных вендоров вычислительной техники и IT-сервисов стоимость разработки ИИ-алгоритмов в стране выросла на 30-40 %. Раньше небольшие отечественные компании могли задействовать для этого ресурсы Amazon, Google и других поставщиков, но сейчас такая возможность отсутствует. Создание государственной платформы может поспособствовать развитию ИИ-алгоритмов небольшими компаниями, которые в сложившихся условиях не могут позволить себе создание собственной инфраструктуры, необходимой для обучения нейросетей. YouTube наполнится генеративным ИИ — он будет выполнять дубляж, создавать фоны для видео и помогать с идеями
21.09.2023 [23:02],
Владимир Фетисов
В рамках мероприятия Made on YouTube видеосервис анонсировал ряд любопытных новинок, предназначенных для создателей контента. Как и следовало ожидать, в скором времени всё больше роликов на платформе будет создаваться с использованием генеративных нейросетей. На данном этапе наиболее заметными нововведениями станут возможность генерации фото- и видеофона, идей и схем для новых роликов, а также функция дубляжа контента на другие языки. 
Источник изобраежний: YouTube Новая функция Dream Screen позволит генерировать с помощью нейросети видео и изображения, которые в дальнейшем авторы контента смогут использовать в качестве фона для своих коротких видеороликов в Shorts. На начальном этапе генерация таких видео и фото будет осуществляться на основе подсказок пользователя. В дальнейшем, по словам представителей YouTube, авторы контента получат возможность создавать ремиксы и редактировать существующие ролики с помощью набора ИИ-инструментов, чтобы получить что-то новое. Во время демонстрации возможностей функции Dream Screen в ходе презентации фоновые изображения на основе подсказок генерировались в течение считанных секунд. Новая функция на основе ИИ в YouTube Studio будет генерировать идеи и схемы для потенциальных роликов. Согласно имеющимся данным, авторы контента будут получать персонализированные рекомендации, основанные на том, какой контент популярен среди их аудитории. В дополнение к этому алгоритм сможет на основе текстового запроса подбирать музыку для видео по его описанию. 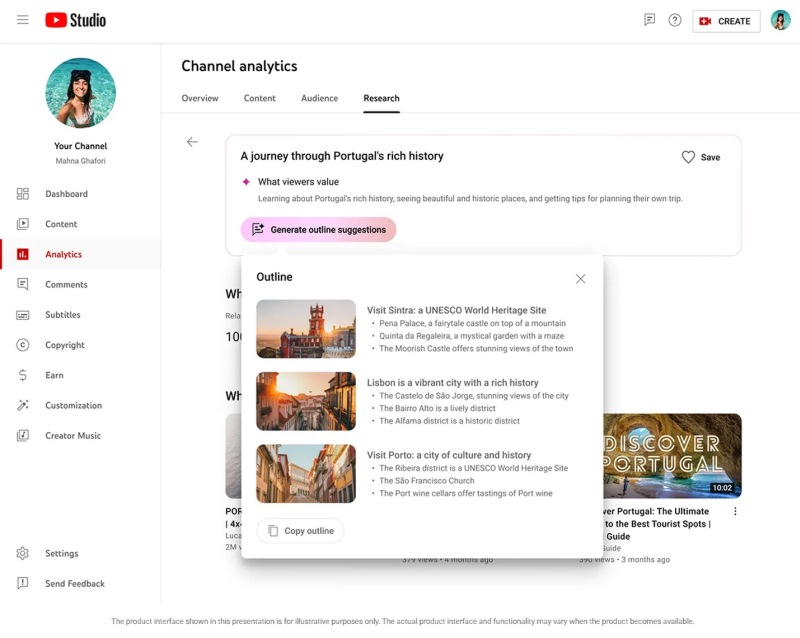 Ещё YouTube анонсировал функцию дубляжа на базе искусственного интеллекта. С её помощью авторы контента смогут дублировать свои ролики на разные языки. Этот инструмент разрабатывался специалистами команды Aloud, входящей в инкубатор стартапов Area 120. Появление новых ИИ-функций на YouTube может ознаменовать сдвиг в том, как авторы планируют, создают и структурируют свой контент. Постепенно созданный с использованием генеративных нейросетей контент станет более распространённым. На фоне роста количества сгенерированного контента другие популярные платформы, такие как TikTok, уже используют специальные метки, которыми помечается контент, созданный ИИ. Владелец ТНТ и Rutube создаст студию по производству контента с помощью ИИ
11.09.2023 [15:29],
Владимир Фетисов
Холдинг «Газпром-Медиа» (владеет каналами НТВ, ТНТ и ТВ-3, кинокомпанией «Централ Партнершип», хостингом Rutube и др.) запустит экспериментальную студию производства контента с помощью нейросетей. Об этом в беседе с журналистами на Восточном экономическом форуме рассказал глава принадлежащей холдингу цифровой лаборатории D. Lab Эдуард Маас. 
Источник изображения: steve_a_johnson / Pixabay Согласно имеющимся данным, в студии будут использоваться около 20 моделей искусственного интеллекта, включая проекты Open Source (например, генератор изображений Stable Diffusion и языковая модель LLaMA) и собственные разработки «Газпром-Медиа». Студия займётся производством анимации с использованием генеративных алгоритмов, а также будет создавать виртуальных ведущих, перерабатывать архивный контент, работать над рекламными спецпроектами. Объём инвестиций, которые будут направлены для развития проекта, озвучен не был. Господин Масс считает, что технологии создания контента с помощью генеративных нейросетей будут полезны продакшен-студиям, рекламным агентствам и блогерам, в первую очередь использующим видеохостинг Rutube и социальную сеть Yappy. В дополнение к этому холдинг будет предлагать свои технологии внешним заказчикам, включая представителей банковского сектора и госкорпорации. В настоящее время компания ведёт переговоры с одним из крупнейших банков с точки зрения маркетинга и крупным издательством, где генеративные алгоритмы могут использоваться для иллюстрации книг. Сам же холдинг может использовать эти технологии для создания промо в соцсетях, генерации анимации из аудио, создания виртуальных ведущих и др. Для производства «сериального хита или топового шоу» предложенные технологии использоваться не будут, уточнил господин Маас. При этом искусственный интеллект может существенно снизить затраты на отдельные производственные процессы. К примеру, такие технологии можно задействовать для отрисовки фонов, персонажей и деталей видеоряда. Нейросети также могут быть полезными для дорисовки вертикальных видео, чтобы делать их горизонтальными, озвучивания произведений реалистично синтезированными голосами и др. Беспилотные автомобили с трудом распознают детей и темнокожих пешеходов
27.08.2023 [13:55],
Владимир Фетисов
Разработчики систем автономного вождения утверждают, что их программное обеспечение одинаково хорошо распознаёт взрослых светлокожих людей, детей и темнокожих пешеходов. Однако исследование учёных из Королевского колледжа в Лондоне показало, что это не совсем так. 
Источник изображения: metamorworks / Shutterstock Исследователи проверили восемь систем обнаружения пешеходов, построенных на базе нейросетей. В ходе тестирования использовалось более 8 тыс. изображений пешеходов. Оказалось, что системы обнаружения пешеходов на 20 % лучше распознают взрослых людей, чем детей. Кроме того, программное обеспечение на 7,5 % точнее определяет светлокожих людей, чем темнокожих пешеходов. По мнению исследователей, проблема распознавания темнокожих людей заключается в том, что системы автономного вождения преимущественно обучаются на изображениях людей со светлой кожей. «Хотя влияние несправедливых систем искусственного интеллекта хорошо задокументировано, начиная с того, что ИИ-алгоритмы при приёме на работу предпочитают кандидатов-мужчин и заканчивая тем, что алгоритмы распознавания лиц менее точно определяют темнокожих женщин, чем белых мужчин, опасность, которую могут представлять беспилотные автомобили, очень велика. Раньше представителям меньшинств могли отказать в жизненно важных услугах, а теперь они могут столкнуться с серьёзными травмами», — считает доктор Цзе Чжан (Jie Zhang), один из авторов исследования. Учёные также установили, что точность распознавания темнокожих людей сильно снижается в условиях недостаточной освещённости и низкой контрастности. Это может приводить к возникновению опасных ситуаций при использовании систем обнаружения пешеходов на основе ИИ в тёмное время суток. Автопроизводители не раскрывают подробностей о программном обеспечении, используемом для распознавания пешеходов. Однако исследователи утверждают, что эти алгоритмы, как правило, построены на основе тех же систем с открытым исходным кодом, которые были проверены в ходе исследования. Alibaba выпустила ИИ-модели, которые могут распознавать изображения и вести диалог
26.08.2023 [20:31],
Владимир Фетисов
Китайский технологический гигант Alibaba представил две языковые модели — Qwen Large Vision Language Model (Qwen-VL) и Qwen-VL-Chat — демонстрирующие расширенные возможности интерпретации изображений и ведения диалогов на естественном языке. Учитывая растущий спрос на доступ к продвинутым ИИ-алгоритмам, появление языковых моделей Alibaba может оказаться весьма своевременным. 
Источник изображения: maginative.com Представленные языковые модели не ограничиваются понимаем текстовых сообщений. Qwen-VL способен воспринимать и понимать изображения, текст и соблюдать ограничения. Алгоритм может обрабатывать запросы, связанные с разными изображениями, и генерировать ответы на них. Qwen-VL-Chat предназначен для более сложного взаимодействия. Например, он может сравнивать несколько изображений, отвечать на серии вопросов, писать истории на основе предоставленных пользователем картинок. К примеру, пользователь может спросить ИИ о местоположении больницы по фото её вывески и получить точный ответ на этот вопрос. Одно из преимуществ представленных языковых моделей состоит в том, что они работают с высокой точностью. По данным Alibaba, Qwen-VL значительно превосходит существующие схожие языковые модели с открытым исходным кодом по нескольким критериям оценки английского языка. Алгоритм также поддерживает новую функцию «общение с чередованием нескольких изображений», которая предполагает, что пользователь предоставит ИИ несколько изображений, после чего будет задавать связанные с ними вопросы. Используя стандартные эталоны, специалисты Alibaba оценили возможности новых алгоритмов при выполнении разных задач, начиная от генерации комментариев к изображениям и заканчивая ответами на вопросы по загруженным снимкам. Обе модели также тестировались по разработанному в Alibaba эталону, который основан на оценке GPT-4 для определения диалоговых возможностей и соответствия человеческому восприятию. Отмечается, что Qwen-VL и Qwen-VL-Chat достигли наилучших результатов в разных категориях. Alibaba стала одной из первых китайских компаний, представивших конкурентоспособную систему генеративного ИИ, что свидетельствует о быстром прогресс исследований в сфере нейросетей в Поднебесной. Выпуская модели с открытым исходным кодом, Alibaba гарантирует, что исследователи, учёные и компании по всему миру смогут использовать их для создания собственных приложений, не прибегая к трудоёмкому и дорогостоящему процессу обучения нейросетей с нуля. «Это майнинг 2.0»: на оборудовании для добычи криптовалюты теперь обучают ИИ-алгоритмы
04.07.2023 [00:23],
Владимир Фетисов
Стремительный рост популярности генеративных нейросетей, таких как ChatGPT, открыл новые возможности для компаний, занимающихся майнингом криптовалюты. Ярким примером такой деятельности стала испанская компания Satoshi Spain, которая продавала и сдавала в аренду оборудование для майнинга в период бума криптовалют, а в последнее время помогает своим клиентам перепрофилировать оборудование под нужды ИИ. 
Источник изображения: Kanchanara/unsplash.com «Вы всё ещё можете зарабатывать деньги на своём оборудовании для майнинга. Это майнинг 2.0», — считает основатель Satoshi Spain Алехандро Ибаньес де Педро (Alejandro Ibanez de Pedro). В настоящее время оборудование компании используется для обучения ИИ-алгоритмов разных стартапов и университетов в Европе. Satoshi Spain не единственный представитель криптовалютного рынка, обративший внимание на стремительный рост популярности ИИ-алгоритмов, для обучения которых необходимы производительные графические ускорители. Спрос на производительные GPU вырос благодаря успеху чат-бота ChatGPT от OpenAI. На фоне затишья в сегменте майнинга криптовалют некоторые компании перепрофилируют оборудование для добычи цифровых активов под нужды ИИ-алгоритмов. После того, как изменился способ майнинга криптовалюты Ethereum, миллионы графических ускорителей перестали использоваться для добычи цифровых активов. Возможность перепрофилировать оборудование для обучения ИИ-алгоритмов даёт майнинговым компаниям новые перспективы для извлечения выгоды. На создателей ChatGPT подали в суд за незаконное использование данных миллионов интернет-пользователей
29.06.2023 [17:31],
Владимир Фетисов
Юридическая компания Clarkson обратилась в федеральный суд северного округа Калифорнии с коллективным иском против OpenAI, разработчика популярного ИИ-бота ChatGPT. Заявитель считает, что разработчик нарушил права миллионов интернет-пользователей, используя их публично доступные данные для обучения больших языковых моделей, которые являются основой ИИ-алгоритмов. 
Источник изображения: Pixabay По словам управляющего партнёра Clarkson Райана Кларксона (Ryan Clarkson), компания хочет представлять в суде интересы «реальных людей, чьи данные были украдены и незаконно присвоены для создания этой очень мощной технологии». Согласно имеющимся сведениям, речь идёт об общедоступных данных пользователей, таких как комментарии в социальных сетях, сообщения в блогах, статьи в «Википедии» и др. Официальные представители OpenAI пока воздерживаются от комментариев по данному вопросу. Судебный иск Clarkson затрагивает главную нерешённую проблему в сфере генеративных нейросетей, таких как ИИ-боты и генераторы изображений. Такие инструменты обучаются на огромном количестве данных, доступных в интернете. После завершения обучения большие языковые модели могут формировать ответы при общении с человеком, сочинять стихи или рассказы, вести сложные беседы и др. Однако люди, чьи данные используются при обучении нейросетей, не давали согласия на использование этой информации кем-то вроде OpenAI. «Вся эта информация используется масштабно, хотя она никогда не предназначалась для обучения больших языковых моделей», — заявил Кларксон. Он также рассчитывает, что суд установит определённые ограничения в плане того, как могут обучаться ИИ-алгоритмы, и как люди могут получить компенсацию за использование их данных. По данным источника, у компании уже есть группа истцов, и она активно ищет новых клиентов. Иск Clarkson к OpenAI является не первым случаем, когда разработчиков ИИ-алгоритмов обвиняют в незаконном использовании данных. В ноябре прошлого года был подан иск против OpenAI и Microsoft в связи с тем, что компании использовали программный код на платформе GitHub для обучения ИИ-инструментов. В феврале платформа Getty Images подала в суд на Stability AI, обвинив компанию в незаконном использовании изображений сервиса для обучения своей генеративной нейросети. |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться