|
Опрос
|
реклама
Быстрый переход
ИИ поможет выявлять ухудшение водительских навыков у пожилых людей
23.01.2024 [14:36],
Алексей Разин
Для Японии старение населения давно является серьёзной проблемой. Помимо прочего это снижает безопасность на дорогах. Бороться с этим предлагается не только за счёт внедрения автопилота, но и контроля за способностью престарелых граждан управлять транспортными средствами при помощи систем искусственного интеллекта. 
Источник изображения: Unsplash, Laura Gariglio Во всяком случае, как сообщает Nikkei Asian Review, японская компания NTT Data разрабатывает нейросеть соответствующего назначения. Следя за поведением водителя, она будет оценивать скорость движения, ускорения и замедления, а также обрабатывать другие данные, которые позволят своевременно выявить снижение способности конкретного человека безопасно управлять автомобилем в силу возрастных изменений. В качестве эксперимента NTT Data будет собирать статистику в одном из таксопарков японской столицы среди машин, управляемых водителями старше 65 лет, и накапливаться эта информация будет с января по июнь текущего года. Таксомоторы будут оборудованы соответствующими датчиками и устройствами GPS, а также модемами для передачи телеметрии в облачную систему NTT Data, которая и будет обрабатывать накапливаемую статистику. Особое внимание будет выделяться фактам резкого торможения или ускорения. Аномалии будут выявляться в сравнении с созданным профилем каждого водителя, учитывающим его нормальное поведение за рулём. Через несколько лет NTT Data планирует запустить в коммерческую эксплуатацию соответствующий облачный сервис, его клиентами смогут стать таксопарки и логистические компании, заботящиеся о безопасности перевозок. Со временем подключиться к этому сервису смогут и рядовые автолюбители. Компания собирается сотрудничать со страховщиками, чтобы те могли интегрировать данный сервис в свою экосистему. Предполагается, что для анализа когнитивных функций конкретного водителя будет достаточно статистики, накопленной за несколько дней активной работы. В дополнение к этому, прочими разработчиками для оценки профпригодности пожилых водителей будут использоваться технологии распознавания голоса и анализа выражений лица, а также движения зрачков. Искусственный интеллект скоро сможет правдоподобно имитировать почерк человека
16.01.2024 [10:17],
Алексей Разин
Уже сейчас нейросети способны правдоподобно воссоздавать голос человека и имитировать его мимику в соответствии с якобы произносимым текстом. Как считают учёные, вскоре искусственному интеллекту будут по плечу и задачи правдоподобного воспроизведения почерка человека, для этого нейросетям будет достаточно ознакомиться лишь с несколькими абзацами «исходного материала». 
Источник изображения: Unsplash, Hannah Olinger Команде специалистов Университета искусственного интеллекта имени Мухаммеда бен Заида в ОАЭ, как сообщает Bloomberg, уже удалось создать профильную нейросеть и опробовать её в деле. Эту разработку авторам даже удалось запатентовать в юрисдикции США. Пока использование данной нейросети сторонними клиентами не подразумевается, и авторы разработки уже выражают опасения по поводу способности недобросовестных пользователей применять её во вред обществу. Прежде чем этот инструмент начнёт распространяться, по мнению разработчиков, необходимо создать защитные механизмы, предотвращающие его некорректное с этической точки зрения применение. «Это всё равно что создать антивирус для вируса», — пояснили представители университета. Подобные соображения не мешают создателям нейросети планировать её коммерческое применение в течение ближайших месяцев, они уже ищут партнёров для реализации сопутствующего потенциала данной технологии. Помимо прочего, такая система могла бы распознавать рукописный текст — например, для обработки записей в историях болезни пациентов. На генерируемых нейросетью рукописях можно было бы обучать другие подобные системы. Пока нейросеть способна распознавать и генерировать рукописный текст на английском и французском языках, но в перспективе разработчики хотели бы добавить к ним и арабский. OPPO представила очень быструю нейросеть AndesGPT — она чуть-чуть уступает GPT-4 и поселится в смартфонах Find X7
27.12.2023 [19:03],
Сергей Сурабекянц
Сегодня компания OPPO представила множество новаторских технологий, которые дебютируют вместе со смартфонами серии Find X7. Одной из впечатляющих новаций стала ИИ-модель AndesGPT, представленная в вариантах со 180, 70 и 7 миллиардами параметров. Самая «компактная» версия и появится в грядущих флагманах OPPO. 
Источник изображения: Weibo Непосредственно в смартфонах Find X7 от OPPO будет использоваться нейросеть AndesGPT с 7 миллиардами параметров. Компания обещает, что AndesGPT обеспечит «сдвиг парадигмы возможностей искусственного интеллекта» благодаря таким нововведениям, как сжатие модели с квантованием в 4 бита, оптимизация механизма запуска ИИ Al Boost и совместная глубокая оптимизация модели с производителями чипов.  В практических сценариях AndesGPT должна проявить себя в обеспечении очень быстрого отклика. По утверждению OPPO, при обобщении текстового контента создание первого из 200 слов занимает всего 0,2 секунды, что опережает конкурентов в 20 раз. Для выжимки из 2000 слов AndesGPT демонстрирует быстрый ответ за 2,9 секунды, превосходя отраслевые стандарты в 2,5 раза. Нейросеть умеет генерировать рефераты объёмом до 14 000 слов, демонстрируя возможности моделирования, в 3,5 раза превосходящие его конкурентов. OPPO хвалит свою языковую модель с 7 миллиардами параметров за «улучшенное интеллектуальное понимание», что особенно заметно в функции сводки вызовов. AndesGPT «превосходно выделяет ключевые моменты из содержания звонков, предоставляя точные сводки с темами, ключевыми моментами и практическими элементами». По мнению OPPO, её нейросеть уступает, причём совсем немного, лишь GPT4 от OpenAI. 
Сравнение AndesGPT с другими нейросетями Нейросеть AndesGPT не ограничивается текстовыми приложениями, она также представляет полный спектр возможностей для генерации изображений. Компания заявляет, что AndesGPT «превосходно генерирует большие изображения с естественным светом и тенью, устанавливая новый стандарт локальной генерации изображений с 6-секундным интервалом — на 60 % быстрее, чем конкурирующие модели на той же платформе». Для смартфонов серии Find X7 компания OPPO также анонсировала технологию спутниковой связи «нового уровня» при помощи антенны с изменяемой диаграммой направленности. Теперь пользователи могут совершать спутниковые звонки традиционным способом, приложив телефон к уху, без необходимости поиска определённого угла или положения аппарата. Акции Google подскочили более чем на 5 % после анонса нейросети Gemini
08.12.2023 [13:06],
Владимир Фетисов
На этой неделе Google представила большую языковую модель Gemini, которая в перспективе должна стать главным конкурентом GPT-4 от OpenAI, а продукты на её основе — конкурентами ИИ-сервисов Microsoft. Для ценных бумаг компании 7 декабря, когда стоимость акций выросла более чем на 5 % до $136,93, стало лучшим днём с 29 августа. 
Источник изображений: Google Представитель торгового отдела банковской холдинговой компании Wells Fargo считает, что анонса нейросети Gemini должно быть достаточно, чтобы успокоить скептиков, которые считают, что Google проигрывает Microsoft гонку в сфере искусственного интеллекта. Он также отметил, что большой вопрос заключается в том, как компания видит монетизацию своей нейросети. Аналитики Bank of America отметили, что в этом году Alphabet находится под давлением из-за опасений по поводу возможностей Google в сфере искусственного интеллекта. Поэтому «хорошо раскрученная» конкурентная модель может иметь преимущества для её потребительской поисковой активности и корпоративных продаж облачных технологий. «Мы считаем, что Google обладает мощным потенциалом в сфере искусственного интеллекта, и данные, свидетельствующие о том, что Google обладает лучшими в своём классе собственными возможностями искусственного интеллекта, могут оказать положительное влияние на акции в первом полугодии 2024 года», — считают аналитики. Пока неясно, планирует ли Google монетизировать Gemini через все свои продукты в долгосрочной перспективе, хотя уже в этом месяце компания начнёт лицензировать использование алгоритма клиентами через Google Cloud. Руководство Google заявило, что Gemini превосходит алгоритм GPT-3.5 от OpenAI, но не были озвучены сравнительные данные с моделью GPT-4 Turbo. Тем не менее, Gemini показывает, что существуют возможности для дальнейшей монетизации ИИ. Например, Microsoft недавно запустила ИИ-помощника Copilot на базе ChatGPT, который встроен в Word, Excel и другие приложения офисного пакета компании, стоимостью $30 в месяц на пользователя. В октябре аналитики Piper Sandler заявили, что Copilot может принести Microsoft более $10 млрд ежегодного дохода к 2026 году. Аналитики JPMorgan сообщили, что хотя инвесторы Уолл-стрит в основном не обратили внимания на анонс Google, они воодушевлены, увидев Google в «этом важном технологическом сдвиге». Однако они отмечают, что «неопределённость в отношении путей монетизации в поиске» будет иметь место. Они считают, что запуск Gemini представляет собой значительную инновацию для Google, поскольку вскоре начнётся второй год коммерциализации и широкой доступности генеративных алгоритмов на базе нейросетей. «Сбер» обновил GigaChat — ИИ-чат-бот получил одну из крупнейших нейросетей на русском языке
23.11.2023 [15:48],
Владимир Фетисов
В рамках международной конференции по искусственному интеллекту AI Journey разработчики «Сбера» представили новую версию чат-бота GigaChat, основой которого стала одна из самых продвинутых больших языковых моделей (LLM) для русского языка с 29 млрд параметров. В скором времени доступ к API новой версии алгоритма получат бизнес-клиенты «Сбера», что позволит им создавать собственные решения на базе GigaChat, а также участники академического сообщества для проведения исследований. 
Источник изображения: sber.ru Использование новой LLM позволяет чат-боту лучше следовать инструкциям и выполнять сложные задания. Существенно повысилась качество суммаризации, рерайтинга, редактирования текстов и ответов на различные вопросы. Разработчики сравнили ответы новой и предыдущей моделей и зафиксировали общее повышение качества на 23 %. В дополнение к этому с фактологией новая модель справляется на 25 % лучше предшественницы. Для повышения качества работы LLM было проведено множество экспериментов по наращиванию эффективности её обучения. К примеру, использовался фреймворк для обучения больших языковых моделей с возможностью шардирования весов нейросети по видеокартам, за счёт чего удалось сократить потребление памяти на них. Результат внутренней оценки в бенчмарке Massive Multitask Language Understanding показал, что версия GigaChat с 29 млрд параметров превосходит самый популярный открытый аналог LLaMA 2 34B. «Обучение моделей, лежащих в основе GigaChat, — это масштабный и сложный вычислительный проект, прежде мы не делали ничего подобного. Суммарное количество вычислительных операций почти в 6 раз превысило количество операций при обучении модели ruGPT-3 с 13 млрд параметров в 2021 году. Также специально для GigaChat мы собрали и развиваем уникальный датасет, над которым работают сотни сотрудников «Сбера», помогая развивать и улучшать качество ответов в самых разных доменах. Благодаря этим усилиям пользователи с каждым новым релизом GigaChat получают максимум от сервиса для решения своих задач», — рассказал Андрей Белевцев, старший вице-президент, руководитель блока «Технологии» Сбербанка. Samsung представила ИИ Gauss для генерации картинок, текста и кода — он, вероятно, поселится в Galaxy S24
08.11.2023 [12:55],
Владимир Фетисов
На этой неделе компания Samsung официально представила собственную генеративную нейросеть под названием Gauss. Анонс нейросети состоялся в рамках ежегодного мероприятия Samsung AI Forum, который с 2017 года проходит в Сеуле и посвящён разработкам в сфере искусственного интеллекта. 
Источник изображения: Samsung Южнокорейский технологический гигант назвал свой генеративный ИИ-алгоритм в честь знаменитого математика Карла Фридриха Гаусса, который создал Закон нормального распределения, используемый в машинном обучении. В компании заявили, что название отражает видение Samsung в отношении ИИ-моделей, которое заключается в том, чтобы использовать все знания в мире для улучшения ИИ и повышения качества жизни потребителей по всему миру. Разработкой алгоритма Gauss занимались инженеры исследовательского подразделения Samsung Research. В настоящее время алгоритм задействован для повышения продуктивности работы сотрудников внутри компании, но в будущем его доступность будет расширена, и он появится в приложениях компании для потребителей. В основе Samsung Gauss лежат три модели: Gauss Language для обработки текстовых запросов, Gauss Image для генерации и обработки изображений, а также Gauss Code для помощи при написании программного кода. Gauss Language представляет собой генеративную нейросеть, предназначенную для повышения эффективности работы за счёт помощи при выполнении разных задач, включая написание электронных писем, обобщение содержания документов, перевод текстов и др. В состав алгоритма входит несколько языковых моделей, что позволяет использовать его как в облаке, так и на устройстве. Помощник по написанию программного кода под названием code.i создан для помощи в процессе программирования. В Samsung уверены, что он позволит разработчикам быстрее писать программный код, а интерактивный интерфейс ассистента обеспечит поддержку ряда полезных функций, таких как описание кода или создание тестовых примеров. Что касается Gauss Image, то эта модель предназначена для создания и редактирования изображений. С её помощью можно легко изменять стиль изображения, добавлять новые элементы, а также улучшать качество картинок с низким разрешением. OpenAI представила флагманскую нейросеть GPT-4 Turbo — мощнее и в разы дешевле GPT-4
07.11.2023 [00:40],
Николай Хижняк
Сегодня на своей первой конференции для разработчиков компания OpenAI представила GPT-4 Turbo — улучшенную версию своей флагманской большой языковой модели. Разработчики из OpenAI отмечают, что новая GPT-4 Turbo стала мощнее и в то же время дешевле, чем GPT-4. 
Источник изображения: CNET Языковая модель GPT-4 Turbo будет предлагаться в двух версиях: одна предназначена исключительно для анализа текста, вторая понимает контекст не только текста, но и изображений. Модель анализа текста доступна в виде предварительной версии через API, начиная с сегодняшнего дня. Обе версии нейросети компания пообещала сделать общедоступными «в ближайшие недели». Стоимость использования GPT-4 Turbo составляет 0,01 доллара за 1000 входных токенов (около 750 слов) и 0,03 доллара за 1000 выходных токенов. Под входными токенами понимаются фрагменты необработанного текста. Например, слово «fantastic» разделяется на токены «fan», «tas» и «tic». Выходные токены, в свою очередь, это токены, которые модель генерирует на основе входных токенов. Цена на GPT-4 Turbo для обработки изображений будет зависеть от размера изображения. Например, обработка изображения размером 1080 × 1080 пикселей в GPT-4 Turbo будет стоить 0,00765 доллара. «Мы оптимизировали производительность, поэтому можем предлагать GPT-4 Turbo по цене в три раза дешевле для входных токенов и в два раза дешевле для выходных токенов по сравнению с GPT-4», — сообщила OpenAI в своём блоге. Для GPT-4 Turbo обновили базу знаний, которая используется при ответе на запросы. Языковая модель GPT-4 обучалась на веб-данных до сентября 2021 года. Предел знаний GPT-4 Turbo — апрель 2023 года. Иными словами, на запросы, имеющие отношение к последним событиям (до апреля 2023 года), нейросеть будет давать более точные ответы. На основе множества примеров из интернета GPT-4 Turbo обучилась прогнозировать вероятность появления тех или иных слов на основе шаблонов, включая семантический контекст окружающего текста. Например, если типичное электронное письмо заканчивается фрагментом «С нетерпением жду…», GPT-4 Turbo может завершить его словами «… вашего ответа». Вместе с этим модель GPT-4 Turbo получила расширенное контекстное окно (количество текста, учитываемое в процессе генерации). Увеличение контекстного окна позволяет модели лучше понимать смысл запросов и выдавать более подходящие им ответы, не отклоняясь от темы. Модель GPT-4 Turbo имеет контекстное окно в 128 тыс. токенов, что в четыре раза больше, чем у GPT-4. Это самое большое контекстное окно среди всех коммерчески доступных моделей ИИ. Оно превосходит контекстное окно модели Claude 2 от Anthropic, которая поддерживает до 100 тыс. токенов. Anthropic утверждает, что экспериментирует с контекстным окном на 200 тыс. токенов, но ещё не внесла эти изменения в открытый доступ. Контекстное окно в 128 тыс. токенов соответствует примерно 100 тыс. словам или 300 страницам текста, что равносильно размеру романов «Грозовой перевал» Эмили Бронте, «Путешествия Гулливера» Джонатана Свифта или «Гарри Поттер и узник Азкабана» Джоан Роулинг. Модель GPT-4 Turbo способна генерировать действительный JSON-формат. По словам OpenAI, это удобно для веб-приложений, передающих данные, например для тех, которые отправляют данные с сервера клиенту, чтобы их можно было отобразить на веб-странице. GPT-4 Turbo в целом получила более гибкие настройки, которые окажутся полезными разработчикам. Более подробно об этом можно узнать в блоге OpenAI. «GPT-4 Turbo работает лучше, чем наши предыдущие модели, при выполнении задач, требующих тщательного следования инструкциям, таких как генерация определённых форматов (например, “всегда отвечать в XML”). Кроме того, GPT-4 Turbo с большей вероятностью вернёт правильные параметры функции», — сообщает компания. Также GPT-4 Turbo может быть интегрирован с DALL-E 3, функциями перевода текста в речь и зрительным восприятием, расширяя возможности использования ИИ. OpenAI также объявила, что будет предоставлять гарантии защиты авторских прав для корпоративных пользователей через программу Copyright Shield. «Мы теперь будем защищать наших клиентов и оплачивать понесённые расходы, если они столкнутся с юридическими претензиями о нарушении авторских прав», — заявила компания в своём блоге. Ранее то же самое сделали Microsoft и Google для пользователей их ИИ-моделей. Copyright Shield будет покрывать общедоступные функции ChatGPT Enterprise и платформы для разработчиков OpenAI. Для GPT-4 компания запустила программу тонкой настройки, предоставляя разработчикам еще больше инструментов для кастомизации ИИ под определённые задачи. По словам компании, в отличие от программы тонкой настройки GPT-3.5, предшественника GPT-4, программа тонкой настройки GPT-4 потребует большего контроля и руководства со стороны OpenAI, в основном из-за технических препятствий. Компания также удвоила лимит скорости ввода и вывода токенов в минуту для всех платных пользователей GPT-4. При этом цена осталась прежней: 0,03 доллара за входной токен и 0,06 доллара за выходной токен (для модели GPT-4 с контекстным окном на 8000 токенов) или 0,06 доллара за входной токен и 0,012 доллара за выходной токен (для модели GPT-4 с контекстным окном на 32 000 токенов). На следующей неделе OpenAI проведёт первую конференцию для разработчиков
04.11.2023 [15:57],
Владимир Фетисов
OpenAI, являющаяся разработчиком популярного ИИ-бота ChatGPT, в понедельник проведёт конференцию для разработчиков. Ожидается, что в рамках этого мероприятия будут анонсированы нововведения, которые сделают ИИ-модели компании более функциональными и доступными для разработчиков приложений. 
Источник изображения: Zac Wolff / unsplash.com Однодневное мероприятие, которое пройдёт в Сан-Франциско, свидетельствует о стремлении OpenAI выйти за пределы потребительского рынка, создав надёжную платформу для разработчиков в сфере ИИ. Генеральный директор OpenAI Сэм Альтман (Sam Altman) подогрел интерес к предстоящей конференции, пообещав участникам «много нового». После нескольких лет работы в относительной безвестности OpenAI в ноябре прошлого года выпустила на рынок ИИ-бота ChatGPT, который стал одним из самых быстрорастущих потребительских приложений за всю историю. Благодаря поддержке со стороны Microsoft, которая инвестировала в OpenAI миллиарды долларов, ChatGPT, способный генерировать тексты и изображения на основе небольших подсказок, создавать программный код и выполнять другие действия, быстрыми темпами завоевал популярность среди пользователей по всему миру. Касательно предстоящего мероприятия ожидается, что OpenAI объявит о снижении стоимости использования своих языковых моделей для разработчиков, а также объявит о новых возможностях машинного зрения для своего ИИ-алгоритма. Снижение затрат должно решить главную проблему для партнёров компании, чьи расходы при использовании большой языковой модели OpenAI растут быстрыми темпами. Возможности машинного зрения, которые позволят ИИ-модели анализировать изображения и составлять их описание, позволят разработчикам создавать приложения с новыми функциями и возможностью применения в разных сферах — от развлечений до медицины. Также ожидается, что OpenAI анонсирует новые возможности тонкой настройки GPT-4, наиболее совершенной языковой модели компании, запуск которой должен состояться осенью этого года. Это и другие нововведения призваны побудить сторонних разработчиков использовать технологию OpenAI для создания чат-ботов и разных приложений на базе нейросетей. По данным источника, одна из главных стратегических задач, поставленных Сэмом Альтманом, заключается в том, чтобы сделать OpenAI незаменимой для других разработчиков приложений. ИИ помог дозаписать новую песню The Beatles с вокалом Джона Леннона — она выйдет 2 ноября
27.10.2023 [18:05],
Владимир Фетисов
Стало известно, что 2 ноября состоится релиз последней песни легендарной группы The Beatles с вокалом Джона Леннона под названием Now and Then. В процессе её создания использовался ИИ-алгоритм компании WingNut Films, который применялся для обработки голоса Леннона на демо-записи этой песни, сделанной несколько десятилетий назад. 
Источник изображения: Business Wire Джон Леннон записал демо-версию Now and Then на аудиокассету в 1970-х годах, но она никогда официально не издавалась. В 2021 году режиссёр Питер Джексон снял документальный сериал The Beatles: Get Back, в процессе работы над которым для обработки партий музыкальных инструментов и голосов людей использовалась технология компании WingNut. Теперь же этот алгоритм задействовали для обработки голоса Леннона на демо-записи, благодаря чему удалось сохранить чёткость оригинального вокала, отделив его от играющей на записи музыки. Спустя несколько десятилетий после создания демо трек будет выпущен как официальная спродюсированная песня вместе с 12-минутным документальным фильмом The Last Beatles Song, посвящённым рассказу о создании этой музыкальной композиции. В него вошли комментарии Пола Маккартни, Ринго Стара, Джорджа Харрисона, а также сына Леннона Шона Оно-Леннона и Питера Джексона. В пресс-релизе, посвящённом предстоящей премьере, Пол Маккартни сказал, что был «весьма взволнован», услышав голос Леннона на «настоящей записи The Beatles» в 2023 году, а Ринго Старр описал процесс создания песни как «самый близкий к тому», чтобы вернуть Леннона в комнату. Документальный фильм The Last Beatles Song выйдет 1 ноября, песня Now and Then — 2 ноября, а видеоклип на неё — 3 ноября. Исследователи придумали «отравленные картинки», которыми художники смогут бороться с нейросетями
25.10.2023 [18:06],
Владимир Фетисов
Команда исследователей из Чикагского университета создала инструмент под названием Nightshade, с помощью которого художники смогут защитить свои работы от генеративных нейросетей, использующих для обучения изображения в интернете. Он позволяет добавить к изображениям невидимые глазу человека пиксели, которые эффективно искажают данные для обучения ИИ-алгоритмов. 
Источник изображения: petapixel.com Стремительный рост популярности генеративных нейросетей, способных создавать изображения по текстовому описанию, также привёл к многочисленным судебным искам со стороны современных художников в адрес компаний, занимающихся разработкой ИИ-алгоритмов. Дело в том, что для обучения генеративных нейросетей обычно используются изображения, опубликованные на разных веб-ресурсах. За счёт этого генеративные нейросети способны рисовать изображения не хуже человека и даже копировать стили известных художников. Алгоритм Nightshade призван помочь художникам защитить свои работы от сканирования нейросетями. Он особым образом обрабатывает изображения, и, если в дальнейшем они используются для обучения нейросетей, то последние теряют способность должным образом обрабатывать пользовательский запрос и выдают неверный результат. Фактически такая доработка картинок заставляет нейросети неправильно распознавать изображённые на них предметы. Например, там, где нарисованы шляпы, алгоритм распознаёт торты, а сумки — распознаются как тостеры. Повреждённые таким образом данные очень сложно удалить, поскольку разработчикам генеративных алгоритмов придётся кропотливо находить каждый такой фрагмент вручную.  Художники, которые хотят поделиться своими работами в интернете, но при этом также намерены защитить их, могут задействовать Nightshade в сочетании с другим инструментом под названием Glaze (разработан той же группой исследователей и предназначен для модификации изображений таким образом, что нейросеть не сможет эффективно обучаться с их помощью). Согласно имеющимся данным, Nightshade и Glaze будут доступны для бесплатного использования, а первый из них будет иметь открытый исходный код, благодаря чему другие разработчики смогут улучшать его. YouTube разрабатывает ИИ-инструмент для создания музыкальных треков с голосами известных вокалистов
19.10.2023 [20:00],
Сергей Сурабекянц
Согласно сообщению Bloomberg, YouTube в настоящее время разрабатывает инструмент на базе ИИ, который позволит пользователям имитировать голоса известных музыкантов при записи звука. В настоящее время сервис пытается получить у музыкальных компаний права на обучение своей нейросети на песнях из их музыкальных каталогов. Ни один крупный звукозаписывающий лейбл пока не дал согласия, но источники утверждают, что переговоры между сторонами продолжаются. 
Источник изображения: Pixabay В прошлом месяце YouTube представил несколько новых инструментов на базе ИИ для авторов, в том числе созданные с помощью нейросети фоновые изображения и видео. Компания планировала включить в эти объявления и новый инструмент для клонирования голосов известных музыкантов, но не смогла вовремя получить разрешения от правообладателей. Музыка, сгенерированная ИИ, в настоящее время находится в юридической «серой» зоне из-за трудностей с установлением прав собственности на песни, которые воспроизводят уникальный голос исполнителя, но не используют напрямую защищённых текстов или аудиозаписей. В настоящее время с точки зрения существующего законодательства неясно, является ли обучение генеративного ИИ клонированию голоса на музыкальном каталоге звукозаписывающей компании нарушением авторских прав. Тем не менее, это не подорвало интерес к разработке и обучению «музыкальных» нейросетей — в этом году Meta✴, Google и Stability AI выпустили ИИ-инструменты для создания музыки. YouTube позиционирует себя в качестве партнёра, который поможет отрасли двигаться вперёд с помощью технологии генеративного ИИ, которую, по данным Bloomberg, приветствуют музыкальные компании. Хотя Alphabet в течение последнего года активно продвигала свои разработки в области генеративного ИИ, далеко не факт, что ей удастся на законных основаниях предоставить создателям YouTube инструменты клонирования голоса на базе ИИ, не вызвав многочисленных исков о нарушении авторских прав. В настоящее время неясно, помогут ли дискуссии об ИИ-инструменте клонирования голоса YouTube решить возникающие претензии о нарушении авторских прав от звукозаписывающих компаний на фоне увеличения количества треков, созданных с помощью ИИ и подражающих популярным музыкантам. Широкое внимание к этой проблеме было привлечено в начале года, когда созданная ИИ песня Drake стала вирусной в интернете. В то время как некоторые музыканты, такие как Граймс (Grimes), поддерживают музыку, генерируемую ИИ, многие другие, в том числе Стинг (Sting), Джон Ледженд (John Legend) и Селена Гомес (Selena Gomez), призывают к введению правил, защищающих их голоса от копирования. «Яндекс» представил YandexART — новую нейросеть для создания изображений
18.10.2023 [12:34],
Андрей Крупин
Команда разработчиков «Яндекса» представила новую диффузионную нейросеть Yandex AI Rendering Technology (YandexART), которая создаёт изображения и анимацию в ответ на текстовые запросы пользователей. 
Примеры созданных YandexART изображений (источник: пресс-служба «Яндекса») YandexART формирует изображения и анимацию методом каскадной диффузии: сначала нейросеть генерирует картинки и кадры в соответствии с запросом пользователя, а затем поэтапно увеличивает их разрешение, насыщая деталями. В качестве обучающего набора данных были задействованы 330 млн изображений с текстовым описанием. Также разработчиками был реализован новый алгоритм распознавания текстов, помогающий нейросети лучше понимать пожелания пользователей. Отличительной особенностью YandexART является понимание российского культурного кода — нейросеть знает известные места и города страны, выдающихся личностей разных эпох и знакомых с детства персонажей мультфильмов и сказок. Например, Чебурашку, богатырей и Бабу-Ягу. Нейросеть уже интегрирована в мобильное приложение «Шедеврум» и помогает иллюстрировать рекламные объявления в «Яндекс Бизнесе». Вскоре YandexART появится в «Яндекс Клавиатуре» и других сервисах компании. «Яндекс Браузер» научился кратко пересказывать видеоролики
06.10.2023 [11:57],
Андрей Крупин
Компания «Яндекс» сообщила об очередных доработках своего фирменного браузера и включении функции краткого пересказа русскоязычных видео. Она позволяет быстро ознакомиться с содержанием ролика и понять, есть ли в нём ответ на нужный вопрос. 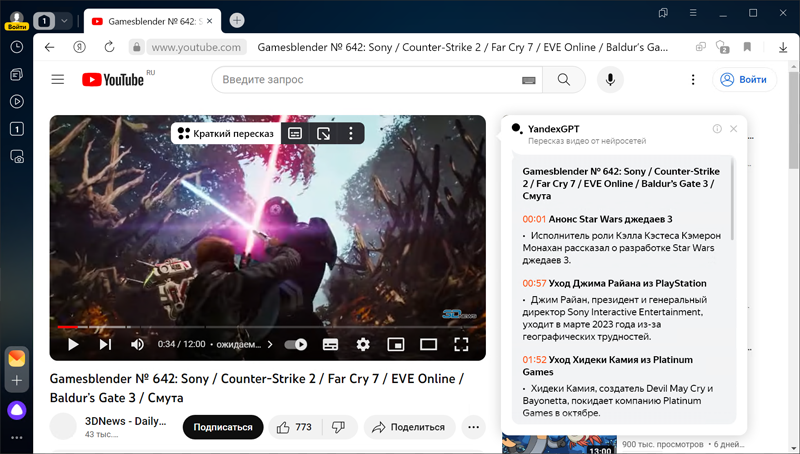 В основу новой функции положены технологии распознавания речи и генеративная нейросеть нового поколения YandexGPT. Сначала алгоритм конвертирует аудиодорожку в текст с помощью системы распознавания речи, а затем YandexGPT разбивает его на смысловые фрагменты. Нейросеть обобщает каждый из них и указывает таймкод начала блоков, кликнув по которому, можно перейти к интересующему фрагменту видео. Чтобы получить пересказ ролика, нужно открыть видео в «Яндекс Браузере» и нажать на кнопку «Краткий пересказ». Функция также доступна в поиске «Яндекса» и сервисе краткого пересказа 300.ya.ru. Согласно данным статистического сервиса LiveInternet.ru, «Яндекс.Браузер» является вторым по популярности веб-обозревателем в Рунете и контролирует 28,3 % рынка. Лидирующую позицию занимает Google Chrome c 51,3 процентами отечественной аудитории (показатели приведены за октябрь 2023 года). В Android 14 появился ИИ-генератор обоев
04.10.2023 [20:10],
Владимир Фетисов
Сегодня состоялась презентация смартфонов Pixel 8 и Pixel 8 Pro, а также других аппаратных и программных новинок компании Google. Вместе с этим состоялся релиз мобильной операционной системы Android 14, которая имеет немало новых функций, включая генератор обоев на базе нейросети. 
Источник изображения: Google Впервые эта функция была анонсирована в рамках мероприятия Google I/O в мае этого года. Взаимодействие с генератором обоев начинается с выбора категории, например, классического искусства, после чего нужно задать требуемые параметры и алгоритм представит несколько вариантов изображений на их основе. В одном из примеров Google выбирается категория Dreamscape, после чего отмечаются варианты структуры, материала и цвета. В конечном итоге формируется запрос «Дом из растений цвета индиго», после обработки которого алгоритм выдаёт несколько изображений покрытых растениями построек с входной дверью и фиолетовым оттенком. Первыми функцию генерации обоев смогут испытать в деле обладатели смартфонов Pixel 8 и Pixel 8 Pro. Когда она может появиться на других смартфонах с Android 14, не уточняется. Однако формулировка Google предполагает, что в конечном счёте это всё же произойдёт. ИИ-генератор обоев — это лишь одна из многих новых функций Android 14. Программная платформа предоставит широкие возможности в плане настройки пользовательского интерфейса, включая экран блокировки, возможность выбора разных шрифтов и цветов, ситуативные виджеты и др. Хотя Android в целом опережает iOS в плане возможностей визуальной настройки, пользователям не всегда легко привести интерфейс к желаемому виду. С выходом Android 14 сделать это будет проще. Созданная с помощью ИИ песня Дрейка и The Weeknd не получит премию «Грэмми»
10.09.2023 [07:31],
Владимир Фетисов
Ранее СМИ писали, что песня Heart on My Sleeve, сгенерированная с помощью нейросети на основе вокала Дрейка и The Weeknd, будет претендовать на получение престижной премии «Грэмми». Теперь же, президент Национальной академии искусства и науки звукозаписи Харви Мейсон (Harvey Mason Jr.) заявил, что трек не будет номинирован. 
Источник изображения: Elice Moore / unsplash.com Господин Мейсон опроверг своё же предыдущее заявление относительно того, что упомянутый трек может получить «Грэмми», поскольку он создавался с участием человека. Ранее на этой неделе Мейсон в беседе с журналистами заявил, что песня Heart on My Steeve «полностью соответствует требованиям, потому что её написал человек». «Позвольте мне быть предельно ясным: несмотря на то, что она была написана человеком, вокал не был получен законным путём, не было получено одобрение на использование вокала от лейбла или исполнителей, песня не является коммерчески доступной, и поэтому она не может быть включена в список», — рассказал Мейсон в беседе с журналистами. Напомним, автором композиции стал человек с ником Ghostwriter, который использовал текст собственного сочинения и сгенерированные нейросетью голоса известных исполнителей. Сообщалось, что трек будет претендовать на получение награды сразу в двух номинациях: «Лучшая рэп-песня» и «Песня года» (обе премии традиционно присуждаются автору композиции, а не её исполнителю). Несмотря на то, что Heart on My Sleeve не получит престижную премию, Мейсон дал понять, что в будущем на получение «Грэмми» могут быть номинированы композиции, созданные с помощью искусственного интеллекта. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться