|
Опрос
|
реклама
Быстрый переход
В платформе «VK Звонки» добавили автоматические субтитры и текстовую расшифровку созвонов
31.08.2023 [10:16],
Владимир Мироненко
Социальная сеть «ВКонтакте» представила новые функции платформы «VK Звонки», которые будут полезны для тех, кто использует сервис для делового общения или в условиях, когда важно соблюдать тишину. Речь идёт о текстовой расшифровке встреч, которая автоматически переводит звуковую дорожку встречи в текст с сохранением в чате звонка, а также об автосубтитрах, которые дублируют речь участников чата. 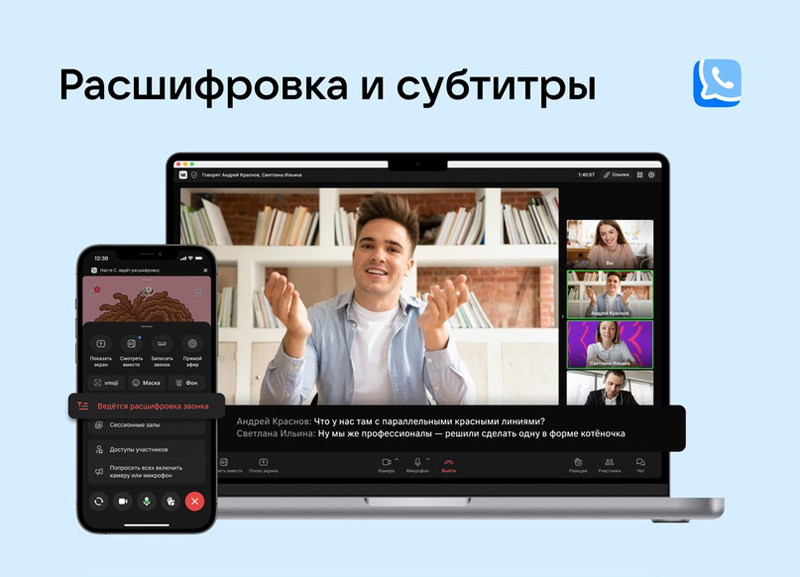
Источник изображения: «ВКонтакте» Функцию текстовой расшифровку может включить любой из участников группового звонка, при этом остальные собеседники получат об этом уведомление. После завершения общения файл с текстом поступит в чат звонка и будет сохранён в специальном разделе в профиле пользователя, включившего текстовую расшифровку. В файле автоматически расставляются тайм-коды и имена говорящих. Что касается автоматических субтитров, то они будут показываться в реальном времени только у тех пользователей, которые включили эту опцию. Текстовая расшифровка может выполняться одновременно с субтитрами и записью звонка. Для перевода речи в текст «ВКонтакте» использует собственные нейросетевые разработки, которые соцсеть применяет для расшифровки голосовых сообщений и создания автосубтитров в видео. Для обеспечения высокого качества расшифровки аудиопоток обрабатывается в несколько этапов. Сначала запись очищается от фоновых звуков с использованием интеллектуального шумоподавления, после чего нейросеть распознаёт слова, формируя текст, который потом делит на предложения в соответствии с конкретным спикером. Нейросети постоянно совершенствуются, проходя обучение, в том числе, на актуальной разговорной речи и сленге. Новыми функциями можно также воспользоваться в сессионных залах и в звонках от имени сообщества. В настоящее время функции доступны только для русского языка, но в дальнейшем будут добавлены и другие языки. Также в ближайшее время планируется запуск новых функций в звонках один на один и возможность настройки администратором того, кто из участников встречи сможет запускать расшифровку. Как отметила «ВКонтакте», новые функции будут особенно полезны тем, кто использует «VK Звонки» для делового общения, позволяя быстро расшифровать интервью, отправить ключевые тезисы после встречи или рассказать об итогах звонка коллегам, которые не были на встрече. Субтитры будут полезны в ситуации, когда важно соблюдать тишину и у пользователя не оказалось наушников. «Кроме того, это шаг к формированию доступной цифровой среды для слабослышащих пользователей: они смогут участвовать во встречах без ограничений», — подчеркнула пресс-служба соцсети. Долой формулы и макросы: российская нейросеть SheetsGPT облегчит работу с таблицами в Excel
25.08.2023 [19:10],
Владимир Мироненко
В России создана нейросеть SheetsGPT, призванная упростить работу с электронными таблицами для всех, кто использует их в своей работе — бухгалтеров, операторов персональных данных, сотрудников маркетплейсов и других специалистов, пишет РИА Новости со ссылкой на информацию пресс-службы платформы Национальной технологической инициативы (НТИ). Нейросеть «понимает» текстовые запросы, поэтому специалистам больше не потребуется прибегать к формулам и писать макросы в Excel. 
Источник изображения: Pixabay «Российская команда разработчиков создала систему SheetsGPT на базе собственной нейросети, которая упростит работу бухгалтера, оператора персональных данных, сотрудника маркетплейсов и всех, кто работает с электронными таблицами — персональные данные, отчёты, заказы и продажи и многое другое. В будущем пользователь также сможет вносить изменения в таблицы. Такое решение избавит клиентов от заучивания формул и написания макросов», — рассказали в пресс-службе. По словам руководителя проекта Антона Аверьянова, пользователю будет достаточно направить нейросети текстовый запрос, который будет обработан серверной частью, после чего человек получит ответ, преобразованный нейросетью в удобный для него вид. Чтобы получить необходимые данные из электронной таблицы, пользователю необходимо загрузить документ на сайт SheetsGPT и написать запрос, на подготовку ответа на который нейросети потребуется 8–15 секунд. Нейросеть также обладает способностью сопоставлять и создавать срез сразу по нескольким таблицам, получать выборки в виде таблицы. В дальнейшем разработчики намерены добавить опцию редактирования данных в таблицах с помощью SheetsGPT. «Мы предлагаем принципиально новый подход к работе с данными. Теперь не нужно знать формулы, писать макросы для того, чтобы с ними работать, — вам нужно только написать текстом то, что вы хотите получить», — рассказал Аверьянов. На данный момент проект находится на стадии прототипа. В ближайшем будущем после проведения тестов разработчики планируют начать продажи продукта конечным потребителям, а также клиентам B2B и B2G-сегментов. NVIDIA наделила эмоциями неигровых персонажей в играх с помощью ИИ
23.08.2023 [00:21],
Николай Хижняк
На выставке Computex 2023 компания NVIDIA представила платформу Avatar Cloud Engine (ACE) for Games, которая позволит сделать умнее неигровых персонажей (NPC) в играх. Представленный инструмент даёт возможность разработчикам создавать собственные ИИ-модели, которые позволят генерировать для NPC естественную речь, диалоги, а также движения. За минувшие месяцы с момента анонса платформы NVIDIA её усовершенствовала, научив создавать эмоциональных персонажей. 
Источник изображения: NVIDIA В рамках изначальной демонстрации работы технологии ACE компания показала интерактивную демо-сцену Kairos с неигровым персонажем Джином, владельцем лапшичной, созданную на движке Unreal Engine 5 с технологией трассировки лучей. Сегодня NVIDIA отчиталась, что интегрировала в платформу ACE ИИ-модель NVIDIA NeMo SteerLM. Она позволяет разработчикам игр изменять характер неигровых персонажей, делая их более эмоциональными и реалистичными, что позволяет человеку сильнее погрузиться в мир игры. Большинство языковых моделей (LLM) разработаны с целью давать только нейтральные ответы. Они лишены возможности эмоциональных имитаций и личностных поведенческих особенностей. Типичным примером таких LLM являются ИИ-чат-боты. В свою очередь с помощью SteerLM языковые модели обучаются давать ответы, соответствующие определённым атрибутам характера, от юмора до креативности и токсичности. При этом все особенности характера NPC можно настроить всего лишь движением нескольких ползунков в интерфейсе SteerLM. С примером использования SteerLM и результатами работы можно ознакомиться на видео ниже, в рамках всё той же интерактивной демо-сцены NVIDIA Kairos. Как можно заметить, ответы NPC значительно отличаются, в зависимости от выбранных атрибутов характера и уровня интенсивности. Неигровой персонаж может обидеться на реплику игрока, попытаться более подробно объяснить ситуацию, а также сделать это с юмором и креативностью. При использовании NVIDIA NeMo SteerLM можно изменять существующие черты характера, а также добавлять новые, создавая по-настоящему уникальных неигровых интерактивных персонажей под определённую сцену в игре или локацию. Эмоциональный отклик — не единственный вариант использования SteerLM в играх. С помощью этой технологии разработчики могут создавать сразу несколько персонажей, используя одну LLM. Кроме того, разработчики могут создавать так называемые атрибуты фракций, чтобы согласовать реакции тех или иных NPC с развитием внутриигровой истории, позволяя неигровым персонажам динамически изменяться в характере с учётом изменяющихся событий в игре. В приведенной выше демо-сцене для озвучивания неигрового персонажа Джина использовался синтезатор текста в речь ElevenLabs. С помощью ACE разработчики могут добавлять свои собственные компоненты в конвейер ACE, расширяя его возможности. Эффект от внедрения ИИ в России превысит 1 трлн рублей к 2025 году, уверены в правительстве
18.08.2023 [19:06],
Сергей Сурабекянц
Вице-премьер России Дмитрий Чернышенко заявил на пленарной сессии по ИИ в рамках международного военно-технического форума «Армия-2023», что только от снижения операционных расходов российских организаций благодаря внедрению ИИ экономический эффект по итогам года составит ₽400 млрд, а к 2025 г. превысит ₽1 трлн. Он также отметил рост рынка ИИ на 18 % до ₽650 млрд по итогам 2022 г. 
Источник изображения: rusarmyexpo.ru Чернышенко сообщил, что сейчас «на фоне вызовов, стоящих перед отраслью, и высокого потенциала применения технологий ведётся работа по актуализации национальной стратегии развития искусственного интеллекта на период до 2030 года». Проект обновлённого документа должен в сентябре рассмотреть премьер Михаил Мишустин, а в ноябре проект оценит президент России Владимир Путин. Дмитрий Чернышенко также проинформировал участников сессии, что «по поручению президента разрабатывается нацпроект “Экономика данных” – в рамках него будет обеспечена реализация обновлённой стратегии». В рамках научно-технологической кооперации в военной сфере Чернышенко поручил включить представителей Минобороны в состав штаба по ИИ, обеспечить информирование экспертов военного ведомства о существующих в России разработках в области ИИ, а также назначить дополнительную экспертизу решениям в области информационных технологий. По данным Чернышенко, правительство с 2021 года осуществляет финансирование и поддержку шести ведущих исследовательских центров в области ИИ, которые тесно сотрудничают с 26 индустриальными партнёрами. Власти планируют отобрать ещё шесть ИИ-лабораторий, которые получат господдержку в 2024–2026 годах. В следующем году планируется запуск реестра типовых ИИ-решений. Также вице-премьер проинформировал участников форума о начавшемся переходе государственных информационных систем на платформу «Гостех», в которой будут храниться обезличенные наборы данных корпоративных и государственных структур. Нейросеть YandexGPT научилась выделять главное из отзывов на товары
14.08.2023 [18:06],
Владимир Фетисов
Поисковая система «Яндекса» подскажет пользователям, на что именно обратить внимание при выборе того или иного товара, а также за что именно заинтересовавшие их продукты хвалят и ругают чаще всего. Для этого нейросеть YandexGPT обобщит данные из отзывов покупателей и сформирует краткий список плюсов и минусов. Сформированные нейросетью обобщённые отзывы также будут доступны в «Яндекс.Маркете». 
Источник изображений: «Яндекс» Пользователи смогут оценить подобранные нейросетью данные, а также сообщить о случаях, когда алгоритм предоставляет некорректную информацию. В поисковике компании такой список плюсов и минусов отображается, если пользователь вводит запрос с указанием конкретной модели. Кликнув на каждое преимущество или недостаток товара можно увидеть конкретный пользовательский отзыв, где упоминается эта особенность. 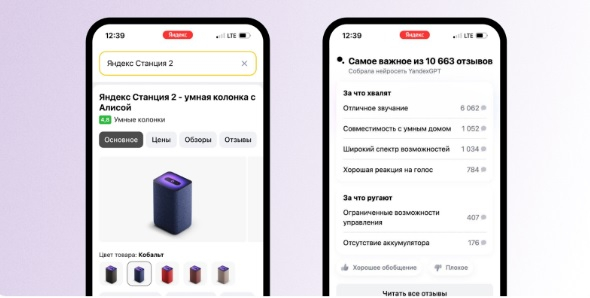
Нейросеть YandexGPT осуществляет анализ отзывов, которые покупатели оставляют в «Яндекс.Маркете» и в разделе «Мои отзывы» в самом поисковике. Алгоритм отбирает наиболее качественные и подробные отзывы, соответствующие многочисленным критериям. После этого нейросеть отмечает особенности товара, которые по мнению пользователей являются важными и о которых заходит речь чаще всего. Для создания списка достоинств и недостатков товара нейросеть использует не менее 10 качественных отзывов. В дальнейшем YandexGPT придёт на смену запущенной в 2021 году технологии создания отзывов в «Яндекс.Маркете». 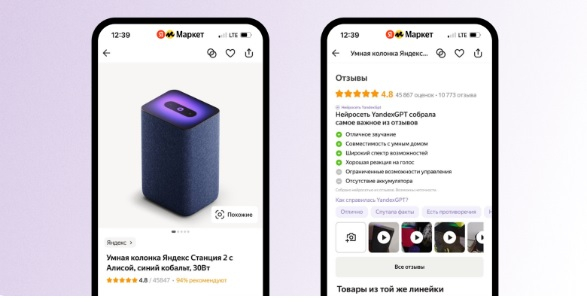
Напомним, «Яндекс.Маркет» представляет собой сервис для покупок, на котором пользователи могут найти свыше 53 млн товаров, начиная от смартфонов и заканчивая детскими игрушками. Для реализации своих товаров сервис используют около 62 тыс. магазинов-партнёров. Помимо веб-версии сервиса пользователи могут использовать мобильные приложения для Android и iOS для взаимодействия с «Яндекс.Маркетом». В Tinkoff Research придумали, как ускорить обучение искусственного интеллекта в 20 раз
04.08.2023 [21:51],
Сергей Сурабекянц
Учёные из лаборатории исследований искусственного интеллекта Tinkoff Research разработали SAC-RND — новый алгоритм для обучения ИИ. На робототехнических симуляторах было достигнуто повышение скорости обучения в 20 раз по сравнению со всеми существующими аналогами при возросшем на 10 % качестве. Оптимизация крайне ресурсоёмкого процесса обучения ИИ ускорит развитие многих сфер, где применяется ИИ. 
Источник изображения: Tinkoff Разработчики утверждают, что SAC-RND может «повысить безопасность беспилотных автомобилей, упростить логистические цепочки, ускорить доставку и работу складов, оптимизировать процессы горения на энергетических объектах и сократить выбросы вредных веществ в окружающую среду. Открытие не только улучшает работу узкоспециализированных роботов, но и приближает нас к созданию универсального робота, способного в одиночку выполнять любые задачи». Результаты исследования были представлены в конце июня на 40-й Международной конференции по машинному обучению (ICML) в Гонолулу, Гавайи. Эта конференция является одной из трёх крупнейших в мире в сфере машинного обучения и искусственного интеллекта. Одним из наиболее перспективных видов обучения ИИ является обучение с подкреплением (RL), позволяющее ИИ учиться методом проб и ошибок, адаптироваться в сложных средах и изменять поведение на ходу. Обучение с подкреплением может использоваться во всех сферах: от регулирования пробок на дорогах до рекомендаций в социальных сетях. При этом ранее считалось, что использование случайных нейросетей (RND) не применимо для офлайн-обучения с подкреплением. В методе RND используются две нейросети — случайная и основная, которая пытается предсказать поведение первой. Свойство нейросети определяются её глубиной — количеством слоёв, из которых она состоит. Основная сеть должна содержать больше слоёв, чем случайная, иначе моделирование и обучение становится нестабильным или даже невозможным. Использование неправильных размеров сетей привело к ошибочному выводу, что метод RND не умеет дискриминировать данные — отличать действия из датасета от прочих. Исследователи из Tinkoff Research обнаружили, что при использовании эквивалентной глубины сетей, метод RND начинает качественно различать данные. Затем исследователи приступили к оптимизации ввода и научили роботов приходить к эффективным решениям при помощи механизма слияния, основанного на модуляции сигналов и их линейном отображении. До этого при использовании метода RND поступающие сигналы не подвергались дополнительной обработке. На визуализации ниже в верхнем ряду показаны предыдущие попытки применения метода RND, в нижнем — метод SAC-RND. Стрелки на изображении должны вести робота в одну точку — они указывают направление к правильному действию. Метод Tinkoff Research во всех случаях стабильно приводит робота в нужную точку 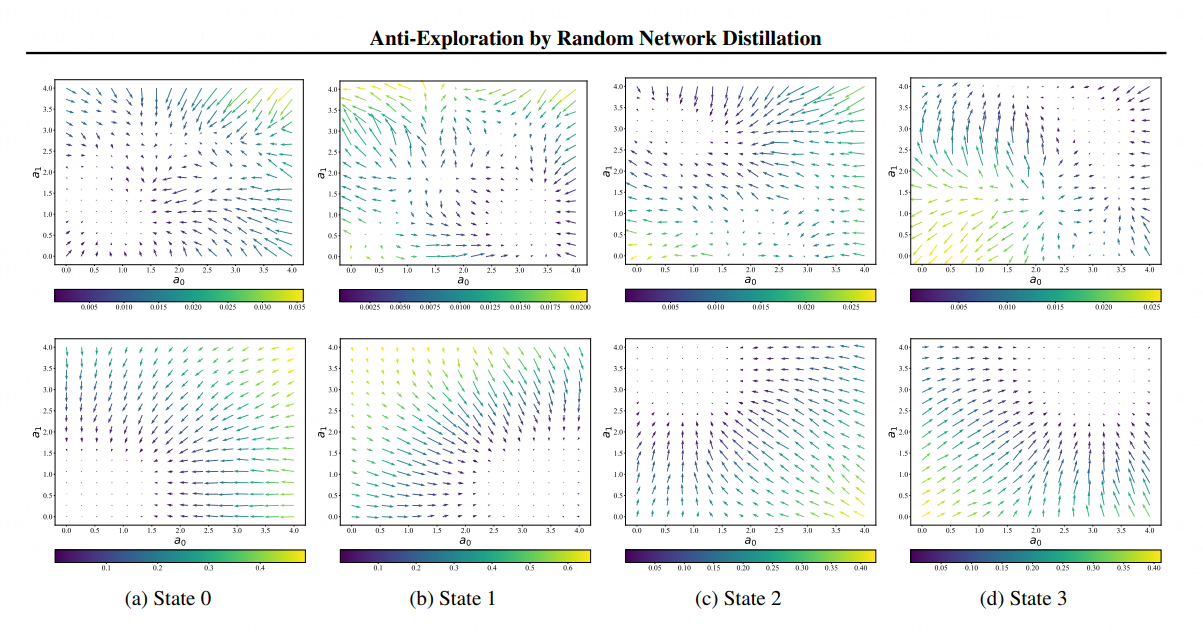
Визуализация принятия решения роботами, обученными с помощью разных алгоритмов. Источник изображения: Tinkoff Research Метод SAC-RND был протестирован на робототехнических симуляторах и показал лучшие результаты при меньшем количестве потребляемых ресурсов и времени. Открытие поможет ускорить исследования в области робототехники и обучения с подкреплением, поскольку оно снижает время получения устойчивого результата в 20 раз и является важным шагом на пути к созданию универсального робота. Tinkoff Research — российская исследовательская некоммерческая группа. Учёные из Tinkoff Research исследуют наиболее перспективные области ИИ: обработку естественного языка (NLP), компьютерное зрение (CV), обучение с подкреплением (RL) и рекомендательные системы (RecSys). Команда курирует исследовательскую лабораторию «Тинькофф» на базе МФТИ и помогает талантливым студентам совершать научные открытия. Stability AI выпустил ИИ-генератор изображений Stable Diffusion XL 1.0, который может работать на более «простом» вычислительном оборудовании
27.07.2023 [05:55],
Владимир Мироненко
ИИ-стартап Stability AI выпустил новую версию своей флагманской модели преобразования текста в изображение Stable Diffusion XL 1.0 (SDXL 1.0) с открытым исходным кодом, которую он позиционирует как свою «самую продвинутую» модель на сегодняшний день. 
Источник изображения: Pixabay По словам Stability, SDXL 1.0, доступная на GitHub в дополнение к API Stability и потребительским приложениям Clipdrop и DreamStudio, обеспечивает «более яркие» и «точные» цвета и лучшую контрастность, тени и освещение по сравнению с предыдущей версией. Джо Пенна (Joe Penna), руководитель отдела прикладного машинного обучения Stability AI, сообщил в интервью TechCrunch, что SDXL 1.0, содержащая 3,5 млрд параметров, может выдавать изображения с разрешением 1 мегапиксель «за секунды» с различными соотношениями сторон. Модель предыдущего поколения Stable Diffusion XL 0.9 также могла создавать изображения с высоким разрешением, но для её запуска требовалось больше вычислительной мощности. Как отметил ресурс SiliconANGLE, открытый исходный код наряду с возможностью работать на относительно простом оборудовании делают SDXL 1.0 гораздо более доступной, чем конкурирующие модели создания изображений. «SDXL 1.0 — кастомизируемая и готова к тонкой настройке в соответствии с концепциями и стилями, — рассказал Пенна. — Она также проста в использовании, обладает способностью создавать сложные проекты с базовыми запросами на обработку естественного языка». Кроме того, SDXL 1.0 получила улучшения в области генерации текста. В то время как даже у многих лучших моделей преобразования текста в изображение наблюдаются проблемы с генерацией изображения с разборчивыми логотипами, не говоря уже о каллиграфии или шрифтах, SDXL 1.0 способна на «продвинутое» генерирование текста и обеспечение его разборчивости, говорит Пенна. SDXL 1.0 имеет функции inpainting, позволяющую восстанавливать недостающие части изображения, outpainting (расширение существующих изображений) и подсказки «изображение-к-изображению», позволяющую после ввода изображения добавлять несколько текстовых подсказок для создания более подробных вариантов этого изображения. Кроме того, модель «понимает» сложные инструкции, состоящие из нескольких частей, которые даются в коротких подсказках, тогда как в предыдущих моделях Stable Diffusion требовались более длинные текстовые подсказки. Тренировочный набор SDXL 1.0 также включает в себя работы художников, протестовавших против использования компаниями, включая Stability AI, их работ в качестве обучающих данных для генеративных моделей ИИ. Stability AI утверждает, что она защищена от юридической ответственности доктриной добросовестного использования, по крайней мере, в США. Хотя это не помешало Getty Images подать в суд на Stability AI с обвинением в незаконном использовании изображений сервиса для обучения своей генеративной нейросети. «Сбер» выложил в открытый доступ русскоязычную ИИ-модель ruGPT-3.5
20.07.2023 [16:16],
Павел Котов
Инженеры «Сбера» выложили в открытый доступ нейросетевую модель ruGPT-3.5, лежащую в основе сервиса GigaChat, который до сих пор проходит стадию закрытого тестирования. Лицензия MIT позволяет использовать материалы проекта в коммерческих целях. 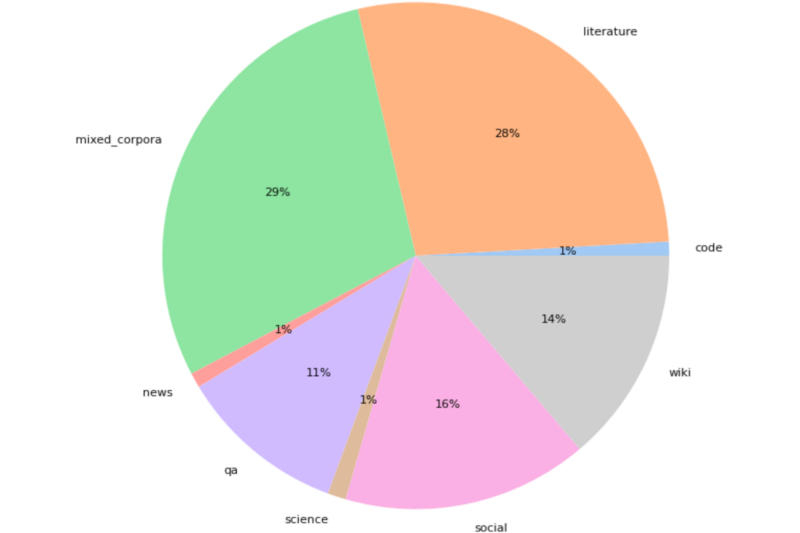
Структура датасета ruGPT-3.5. Источник изображения: habr.com Важнейшим недостатком открытых больших языковых моделей вроде Meta✴ LlaMA является ограниченная поддержка русского языка — обычно это русский раздел «Википедии» и некоторое количество общедоступных текстов. Это оказывает негативное влияние на понимание моделью языка и качество её ответов. Модель ruGPT-3.5, основанная на архитектуре OpenAI GPT-3, создана в первую очередь для работы в русскоязычной среде, поэтому она более качественно обрабатывает такие запросы. Обучение модели производилось в два этапа. Первый этап продлился 1,5 месяца — за это время платформа обработала 300 Гбайт данных: книги, энциклопедийные и научные статьи, социальные ресурсы и другие источники. Потребовались ресурсы 512 ускорителей NVIDIA V100. На втором этапе проводилось дообучение на 110 Гбайт данных из датасета The Stack, юридических документов и обновлённых текстов «Википедии» — это заняло три недели и потребовало 200 ускорителей NVIDIA A100. В результате у ruGPT-3.5 13 млрд параметров при длине контекста 2048 токенов — для сравнения, привели пример разработчики, рассказ А. П. Чехова «Хамелеон» разбивается на 1650 токенов при его длине в 901 слово. Google разрабатывает ИИ-алгоритм Genesis для написания новостных статей, но о замене журналистов речи не идёт
20.07.2023 [12:51],
Владимир Фетисов
По сообщениям сетевых источников, компания Google работает над созданием ИИ-алгоритма для написания новостных статей. Он разрабатывается под кодовым названием Genesis и уже был продемонстрирован руководству некоторых крупных изданий, таких как The New York Times, The Washington Post и The Wall Street Journal. 
Источник изображения: StartupStockPhotos / Pixabay По данным источников, Genesis может генерировать новостные статьи на основе данных о тех или иных событиях. В компании считают, что алгоритм может стать своеобразным помощником для журналистов. С его помощью можно не только генерировать готовые статьи, но и, например, подобрать оптимальный заголовок или изменить стиль материала. «В партнёрстве с издателями новостей, особенно с небольшими издательствами, мы находимся на ранней стадии изучения идей, которые потенциально могут привести к созданию ИИ-инструментов для помощи в работе журналистов. Например, инструменты на базе ИИ могут помочь журналистам с выбором заголовка или стилем написания», — рассказал представитель Google. Он также добавил, что цель компании заключается в том, чтобы предоставить журналистам ИИ-инструменты для повышения эффективности их работы. Особо отмечается, что Google не стремится заменить журналистов ИИ-алгоритмами. На данный момент трудно судить, насколько хорошо Genesis справляется с поставленными задачами. Очевидно, больше информации об этом алгоритме станет известно по мере развития проекта. «Сбер» научил нейросеть Kandinsky генерировать стикеры и фотореалистичные изображения и портреты
12.07.2023 [19:43],
Владимир Мироненко
«Сбер» представил новую версию своей нейросети для генерации изображений по текстовому описанию — Kandinsky 2.2, которая позволит создавать фотореалистичные изображения с более высоким разрешением и изменять соотношение сторон при генерации, а также обеспечит значительный прирост качества при создании портретов. 
Генерация Kandinsky 2.2. Источник изображений: «Сбер» Для дообучения Kandinsky 2.2 использовался набор данных из 1,5 млрд пар «текст — изображение», что на 300 млн больше, чем для предыдущей версии — Kandinsky 2.1, вышедшей в апреле этого года и набравшей всего за 6 дней 2 млн пользователей. Новую версию модели научили создавать стикеры, из которых можно собирать полноценные стикерпаки в Telegram. Также благодаря внедрению специального структурного блока управляемых изменений ControlNetона она получила способность изменять по текстовому описанию отдельные объекты или элементы на изображениях, сохраняя при этом композицию исходной иллюстрации. 
Генерация Kandinsky 2.2 Согласно пресс-релизу, Kandinsky 2.2 понимает запросы на русском и английском языках, обладает способностью рисовать более чем в 20 стилях, смешивать несколько рисунков, стилизовать изображение по текстовому описанию, генерировать изображения, похожие на заданные, а также дорисовывать недостающие части картинки (inpainting) и создавать картины в режиме бесконечного полотна (outpainting). 
Стикерпак от Kandinsky 2.2 «Нейросеть уже не просто пытается подражать творчеству человека, а способна создавать новые художественные смыслы и интерпретации», — сообщил первый зампред правления Сбербанка Александр Ведяхин, добавив, что, как и предыдущая версия, Kandinsky 2.2 находится в открытом доступе, и протестировать её можно совершенно бесплатно. Сообщается, что ознакомиться с возможностями Kandinsky 2.2 можно на промостранице модели, на платформе FusionBrain.AI, в Telegram-боте и боте соцсети «ВКонтакте», а также при помощи команды «Запусти художника» на умных устройствах Sber, в мобильном приложении Салют. Модель доступна на платформе ML Space в хабе предобученных моделей и датасетов DataHub. Разработкой и обучением нейросети занимались исследователи Sber AI при партнёрской поддержке учёных из Института искусственного интеллекта AIRI на объединённом датасете Sber AI и компании SberDevices. Anthropic запустила Claude 2 — дружелюбного ИИ-бота с безобидными ответами и своей конституцией
11.07.2023 [20:13],
Сергей Сурабекянц
Anthropic выпустила в свободный доступ вторую версию своего чат-бота Claude. Компания советует воспринимать «Claude 2 как дружелюбного, увлечённого коллегу или личного помощника, которого можно проинструктировать на естественном языке». Контекстное окно Claude 2 вмещает почти 75 000 слов, что радикально больше 3000 слов у общедоступной версии ChatGPT. К тому же, по словам Anthropic, её чат-бот обладает чувством юмора. ИИ-бот уже доступен для жителей США или Великобритании на сайте Anthropic, а через VPN можно получить к нему доступ и из других стран. 
Источник изображения: Anthropic Бот Claude 2, которого Anthropic описывает как «полезного, безобидного и честного», может приводить краткие содержания текстов, писать код, переводить тексты и выполнять массу других семантических задач. По описанию его функциональность схожа с Google Bard или Microsoft Bing, но Anthropic утверждает, что он построен иначе. Его стиль общения более разговорный и человечный, чем у его «собратьев», кроме того он, предположительно, наделён чувством юмора. Claude 2 руководствуется набором принципов, называемых его создателями «конституцией», которые он использует для проверки своих ответов, не привлекая модераторов-людей. Claude 2 значительно расширил свои возможности по сравнению с предшественником. В дополнение к способности создавать более длинные ответы, чат-бот теперь немного лучше разбирается в математике, кодировании и рассуждениях по сравнению с предыдущей моделью. Так, Claude 2 набрал 76,5 % при сдаче экзамена на адвоката, в то время как предшественник получил только 73 %. Согласно Anthropic, Claude 2 намного лучше «даёт безобидные ответы», не содержащие вредоносного контента, хотя Anthropic не исключает возможности, что чат-бот может быть спровоцирован. 
Источник изображения: Pixabay В отличие от Bard и Bing, Claude 2 не подключён к интернету и обучается на данных до декабря 2022 года. Хотя он не может отображать самую последнюю информацию о текущих событиях, его набор данных все же более свежий, чем тот, который использует бесплатная версия ChatGPT, ограниченная концом 2021 года. Anthropic расширила контекстное окно Claude 2 примерно до 75 000 слов. Пользователь сможет загрузить в чат-бота десятки страниц или даже целый роман для анализа. Благодаря такому размеру контекстного окна, Claude 2 может создать краткое изложение сложной и очень длинной исследовательской работы. Его «собратья» накладывают гораздо более строгие ограничения: максимум ChatGPT составляет около 3000 слов, а контекстное окно Bing было недавно увеличено до 4000 слов. Anthropic, поддерживаемая Google, первоначально запустила первую версию Claude в марте. Тогда этот чат-бот был доступен для предприятий только по запросу или в виде приложения в Slack. Теперь, когда Claude 2 стал общедоступным, множество пользователей постараются выяснить, достаточно ли более длинного контекстного окна, чтобы сбить этого «безобидного» бота с толку, как это уже было с другими чат-ботами. На OpenAI подали в суд за незаконное использование литературных произведений для обучения нейросетей
30.06.2023 [15:35],
Дмитрий Федоров
На OpenAI снова подали в суд за использование произведений для обучения ИИ. Два известных писателя подали иск против компании, которая стоит за ChatGPT и Bing Chat, в нарушении авторских прав. По их мнению, OpenAI использовала их произведения в качестве обучающих данных. Это, по всей видимости, первый поданный иск об использовании текста (в отличие от изображений или кода) в качестве обучающих данных.  В поданном в окружной суд Северного округа Калифорнии иске истцы Пол Тремблей (Paul Tremblay) и Мона Авад (Mona Awad) утверждают, что OpenAI и её дочерние компании нарушили авторские права, нарушили Закон об авторском праве в цифровую эпоху (DMCA), а также нарушили калифорнийские и общие законодательные ограничения на недобросовестную конкуренцию. Писатели представлены юридической фирмой Джозефа Савери (Joseph Saveri) и Мэттью Баттерика (Matthew Butterick), той же командой, которая стоит за недавними исками, поданными против Stable Diffusion AI и GitHub. В жалобе утверждается, что роман Тремблея «Хижина на краю света» и два романа Авад: «13 способов посмотреть на толстую девушку» и «Зайка» использовались в качестве обучающих данных для GPT-3.5 и GPT-4. Хотя OpenAI не раскрывала, что эти романы находятся в её обучающих данных (которые держатся в секрете), истцы делают вывод, что они должны быть там, поскольку ChatGPT смог предоставить подробные резюме сюжетов и ответить на вопросы о книгах, что потребовало бы доступа к их текстам. «Поскольку языковые модели OpenAI не могут функционировать без выразительной информации, извлечённой из произведений истцов (и других лиц) и сохранённой в них, языковые модели OpenAI сами являются нарушающими авторские права производными произведениями, созданными без разрешения истцов и в нарушение их исключительных прав по Закону об авторском праве», — говорится в жалобе. Все три книги содержат информацию о защите авторских прав (CMI), такую как ISBN и номера регистрации авторских прав. Закон об авторском праве в цифровую эпоху (DMCA) утверждает, что удаление или фальсификация CMI является незаконной, и поскольку ответы ChatGPT не содержат этой информации, истцы утверждают, что OpenAI виновна в нарушении этого закона, помимо факта нарушения авторских прав. Хотя в настоящее время в иске участвуют только два истца, адвокаты намерены сделать иск коллективным, что позволило бы другим авторам, чьи авторские произведения использовались OpenAI, также получить компенсацию. Адвокаты требуют денежных возмещений, судебных издержек и судебного запрета, принуждающего OpenAI изменить своё программное обеспечение и деловые практики в отношении авторских материалов. На сайте юридической фирмы LLM Litigation подробно изложена позиция истцов и причины подачи иска. «Мы подали коллективный иск против OpenAI, обвиняя ChatGPT и его базовые большие языковые модели, GPT-3.5 и GPT-4, в том, что они перерабатывают авторские произведения тысяч писателей — и многих других — без согласия, компенсации или признания», — сообщают адвокаты. Они также критикуют концепцию генеративного ИИ, утверждая: «Генеративный искусственный интеллект — это просто человеческий интеллект, переупакованный и проданный как новый продукт. Это не новый вид интеллекта. Это просто новый способ использования чужого интеллекта без разрешения или компенсации». Они отмечают, что, хотя OpenAI заявляет, что не знает, какие именно книги использовались для обучения ИИ, это не имеет значения, поскольку: «OpenAI знает, что она использовала множество книг, и она знает, что она не получила разрешения от их авторов». Это не первый случай, когда OpenAI сталкивается с подобными обвинениями. Однако новый иск, станет первым, затрагивающим использование текстовых данных, и он может создать прецедент для будущих судебных дел о нарушении авторских прав в области ИИ. Нейросеть YandexGPT научилась тезисно пересказывать тексты на русском языке
27.06.2023 [13:28],
Андрей Крупин
Команда разработчиков «Яндекса» сообщила о расширении функциональных возможностей языковой ИИ-модели нового поколения YandexGPT (YaLM 2.0) — теперь генеративная нейросеть умеет выделять из статей на русском языке основные тезисы и излагать их в кратком пересказе. Это позволяет быстрее узнать содержание объёмного материала и сэкономить время. 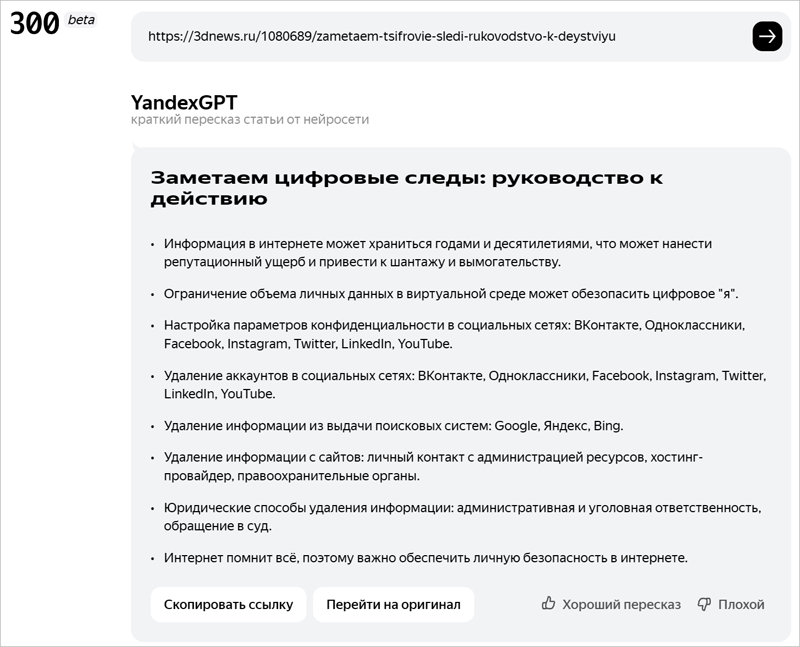 Оценить в деле новую функцию YandexGPT можно на сайте 300.ya.ru. Нейросеть умеет конспектировать русскоязычные тексты длиной до 30 тысяч знаков и сокращать их до небольшого конспекта от 300 до 1000 знаков. В среднем на чтение статьи такого большого объёма требуется 15 минут, а благодаря ИИ-сервису узнать её содержание можно менее чем за минуту. Это удобно, когда требуется проанализировать множество источников информации, написать к ним тезисы или найти ответ, не читая текст целиком. Помимо краткого пересказа текста ИИ-сервис также предоставляет API для разработчиков. С его помощью они могут получить ссылку на сокращённую версию статьи, не пользуясь веб-интерфейсом. Это может быть полезно владельцам сайтов или новостных каналов. Сам сервис и API доступны широкой аудитории и работают в режиме бета-тестирования. YandexGPT была представлена широкой публике 17 мая 2023 года. Языковая ИИ-модель нового поколения доступна в «Яндекс.Браузере», мобильном приложении «Яндекса», программе «Шедеврум», голосовом помощнике «Алиса», в линейке умных колонок и телевизоров компании, а также на главной странице «Яндекса» (ya.ru) и в API для клиентов Yandex Cloud. В планах разработчика — обучение нейросети новым знаниям и её внедрение в другие сервисы и продукты компании, прежде всего в поиск. Глава DeepMind AI похвастался разработкой ИИ-алгоритма, который превзойдёт ChatGPT
26.06.2023 [22:10],
Владимир Фетисов
В 2016 году разработчики из дочерней компании Google под названием DeepMind AI создали алгоритм AlphaGo, который вошёл в историю, победив чемпиона в настольной игре Го. Теперь же Демис Хассабис (Demis Hassabis), соучредитель и генеральный директора DeepMind, заявил о разработке нейросети, которая станет более совершенной по сравнению той, что стоит за популярным ИИ-ботом ChatGPT от компании Open AI. 
Источник изображения: Placidplace/pixabay.com Нейросеть Gemini представляет собой большую языковую модель, которая схожа с лежащей в основе ChatGPT моделью GPT-4. Разработчики из DeepMind намерены объединить возможности нейросети с технологиями, которые использовались в AlphaGo, чтобы расширить возможности алгоритма. «На высоком уровне можно думать о Gemini как о сочетании некоторых сильных сторон систем вроде AlphaGo с удивительными возможностями больших языковых моделей. У нас также есть несколько инноваций, которые будут довольно интересными», — приводит источник слова Демиса Хассабиса. Напомним, о разработке нейросети Gemini впервые стало известно в прошлом месяце. Что касается AlphaGo, то этот алгоритм обучался решать сложные задачи методом, требующим от алгоритма определённого действия. Кроме того, для изучения и прогнозирования возможных ходов на доске для игры в Го использовался алгоритм, называемый древовидным поиском. По словам Хассабиса, алгоритм Gemini всё ещё находится на этапе разработки, который займёт ещё несколько месяцев и для реализации которого могут потребоваться десятки или даже сотни миллионов долларов. Согласно имеющимся данным, разработка GPT-4 обошлось в более чем $100 млн. Знаменитости начали продавать цифровых клонов для рекламы и участия в шоу
20.06.2023 [15:59],
Руслан Авдеев
С развитием систем генеративного ИИ цифровые двойники знаменитостей стали появляться в Сети без разрешения самих «оригиналов». Как сообщает The Wall Street Journal, звёзды решили взять этот процесс под контроль — теперь они сами продают цифровых двойников, которые будут трудиться вместо них в рекламе и не только. В перспективе цифровые копии знаменитостей будут даже общаться с поклонниками — нечто подобное происходит уже сейчас. 
Цифровой двойник Евы Герциговой. Источник изображения: WSJ По словам Тома Грэма (Tom Graham), главы стартапа Metaphysic, занимающегося созданием цифровых двойников, звёздам просто необходимо прийти на несколько минут в студию с 3D-сканером, в будущем это позволит создавать бесчисленное множество часов контента. Например, ещё в прошлом году в ходе Нью-Йоркской недели моды к виртуальным презентациям компания Puma привлекла цифрового двойника футболиста Неймара (Neymar), которого создали с помощью приложения MetaHuman, входящего в пакет Unreal Engine компании Epic Games. Участие знаменитостей в мероприятиях и рекламе — огромный по объёмам бизнес. Только Nike потратила в минувшем фискальном году на привлечение звёзд и спортивных команд $1,3 млрд. Развитие индустрии цифровых двойников может полностью изменить правила игры, поскольку виртуальные звёзды способны на такое, чего никогда не смогли бы проделать люди в реальной жизни. Например, легенда гольфа Джек Никлаус (Jack Nicklaus) согласился, чтобы ИИ-компания Soul Machines создала версию его 38-летнего аватара (сейчас ему уже 83). 
Джек Никлаус общается со своей виртуальной версией. Источник изображения: WSJ Голливудское агентство CAA уже уловило намечающийся тренд и начало консультировать звёзд о возможностях, которые перед ними открывает продажа ИИ-двойников. По некоторым данным, определённые сделки уже заключаются, например, Metaphysic уже заключила контракт на выполнение неких услуг, связанных с применением ИИ-технологий для фильма Роберта Земекиса (Robert Zemeckis) с Томом Хэнксом (Tom Hanks), а также участвует и в других проектах. Как сообщает издание, в фэшн-индустрии, где модели обычно не владеют правами на свои изображения, ИИ тоже открывает новые перспективы. Так, супермодель Ева Герцигова (Eva Herzigova) в апреле представила собственную виртуальную версию, созданную на решениях Epic Games — клон может участвовать в виртуальных онлайн-шоу, а вскоре двойник появится на виртуальных торговых площадках — в будущем модели смогут даже разговаривать с помощью чат-ботов. При этом растут и репутационные риски, поскольку боты вполне способны на грубые или некорректные высказывания. В случае с Джеком Никлаусом, например, пришлось создавать отдельную языковую модель вместо использования инструментов вроде ChatGPT. Ещё одна проблема — пока существующие пробелы в законодательстве. Например, достоверно неизвестно, кому именно должны принадлежать цифровые двойники и каким образом можно организовать их «верификацию» и сделать так, чтобы люди не путали дипфейки с реальными собеседниками. Впрочем, работы в этом направлении уже ведутся, компании пытаются разработать системы идентификаторов для цифровых клонов — как сообщают в Metaphysic, уже в ближайшие пару лет даже обычные люди смогут создавать фотореалистичных двойников не только себя, но и других людей. Общие стандарты позволят звёздам, например, требовать удаления нелегального контента из Сети и контролировать распространение своих копий в целом. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться