
Опрос
|
реклама
Быстрый переход
Учёные нашли способ удвоить скорость вычислений компьютеров без замены железа
23.02.2024 [19:53],
Геннадий Детинич
На 56-м ежегодном Международном симпозиуме IEEE/ACM по микроархитектуре исследователи из Калифорнийского университета в Риверсайде (UCR) продемонстрировали подход, при котором любые вычислительные компоненты платформы по-настоящему будут работать одновременно. За счёт этого можно в два раза увеличить скорость вычислений и в два раза сократить потребление энергии. Технология может работать на любых процессорах и ускорителях от смартфонов до серверов ЦОД, но требует доработки. 
Источник изображения: ИИ-генерация DALL-E/newatlas.com «Вам не нужно [для ускорения вычислений] добавлять новые процессоры, потому что они у вас уже есть», — сказал Хунг-Вей Ценг (Hung-Wei Tseng), адъюнкт-профессор факультета электротехники и вычислительной техники Калифорнийского университета и соавтор исследования. Необходимо лишь грамотно распорядиться имеющимися аппаратными ресурсами, а не выстраивать их все в очередь. Разработанная исследователями платформа, которую они назвали одновременной и гетерогенной многопоточностью (SHMT), отходит от традиционных моделей программирования. Вместо того чтобы предоставлять за один промежуток времени данные лишь одному из вычислительных компонентов системы — центральному, графическому, тензорному или другому процессору или ускорителю, технология SHMT распараллеливает исполнение кода сразу по всем компонентам одновременно. 
Тестовая платформа. Источник изображения: Hsu and Tseng SHMT использует политику планирования многопоточности с учетом такого параметра, как quality-aware work-stealing (QAWS), которая не требует больших затрат ресурсов, но зато помогает поддерживать контроль качества и баланс рабочей нагрузки. Система исполнения создаёт и делит набор виртуальных операций (vOPS) на одну или несколько высокоуровневых операций (HLOPs) для одновременного использования нескольких аппаратных ресурсов. Затем система исполнения SHMT распределяет эти HLOPS по очередям задач для запуска на целевом оборудовании. Поскольку HLOPS не зависят от оборудования, система исполнения может перенаправлять задачи по мере необходимости на тот или иной компонент вычислительной платформы. 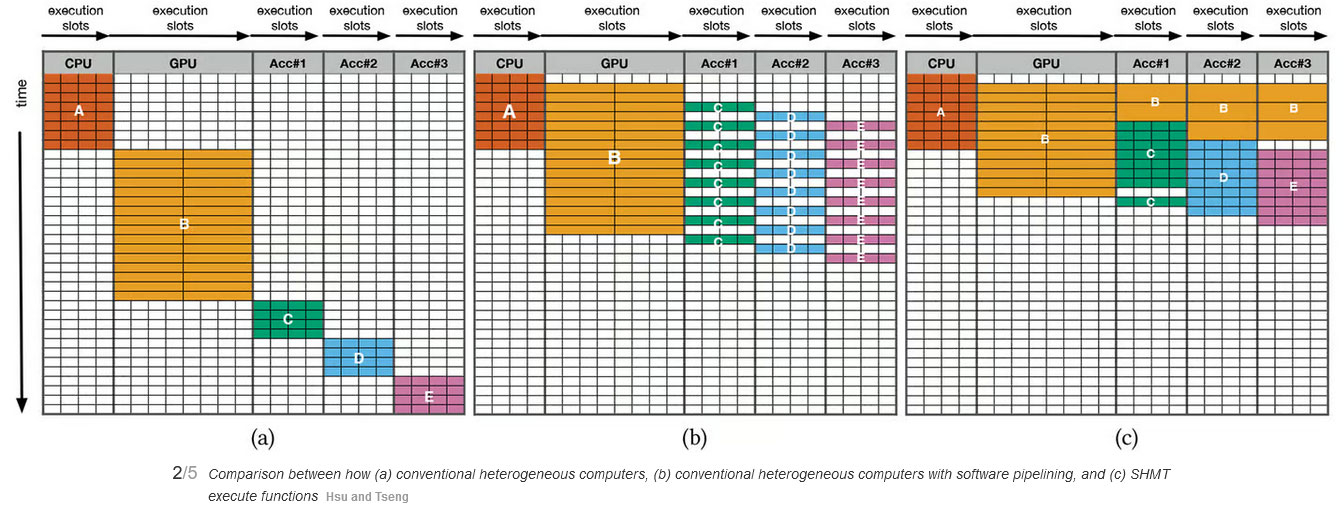
Сравнение методов распараллеливания обычного, современного гетерогенного и SHMT Что особенно ценно, исследователи на примере созданной ими тестовой платформы показали эффективность работы новых программных библиотек. Они создали некий гибрид, который можно считать как смартфоном, так и подобием ПК и даже сервера. На базе объединяющей платы с разъёмом PCIe был создан «компьютер» из комбинации модуля NVIDIA Nano Jetson с четырёхъядерным процессором ARM Cortex-A57 (CPU) и 128 графическими ядрами архитектуры Maxwell (GPU). Через слот M.2 Key E на плате был подключен ускоритель Google Edge (TPU). 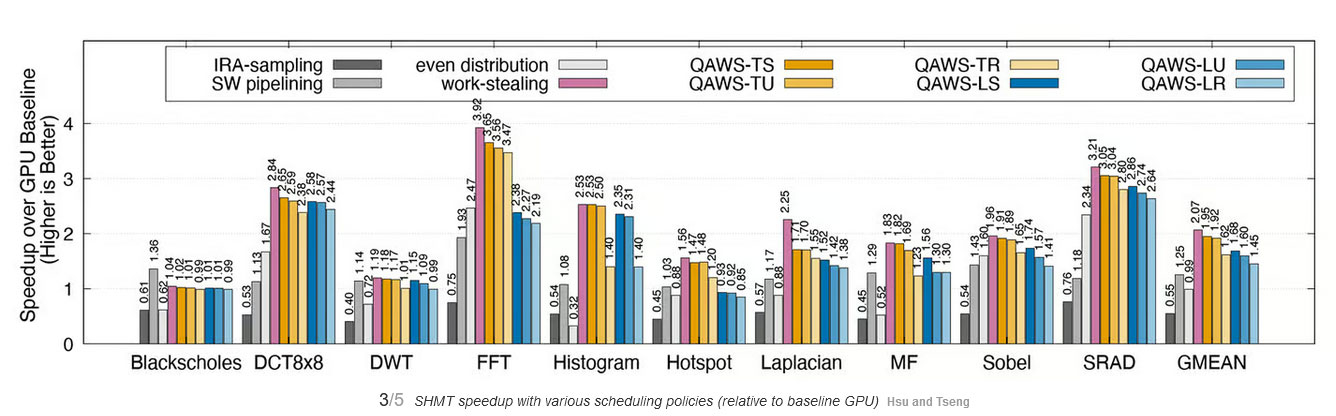
Ускорение вычислений SHMT в зависимости от выбранной политики Основная память представленной системы — это 4 Гбайт LPDDR4 с частотой 1600 МГц и скоростью 25,6 Гбит/с, где хранятся общие данные. Модуль Edge TPU дополнительно содержит 8 Мбайт памяти, а в качестве операционной системы использовался Ubuntu Linux 18.04. 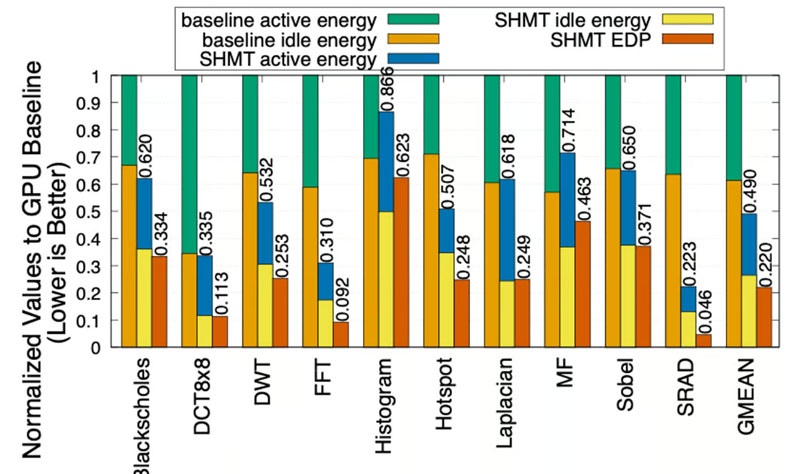
Сравнение потребления в активном режиме и при простое при обычных вычислениях и с использованием SHMT Запуск на импровизированной гетерогенной платформе пакета SHMT с использованием стандартных приложений для тестирования показал, что при наиболее эффективной политике фреймворк QAWS показывает увеличение скорости вычислений в 1,95 раза и значительное сокращение потребления — на 51 % по сравнению с базовым методом распределения вычислений. Если масштабировать этот подход для использования в составе ЦОД, то выигрыш обещает оказаться колоссальным и при этом всё «железо» останется прежним — менять ничего не придётся. Предложенное решение пока не готово к внедрению, но наверняка без труда найдёт заинтересованных в этом лиц. Apple представила фреймворк MLX для разработки ИИ под компьютеры Mac
07.12.2023 [17:51],
Павел Котов
Apple объявила о выходе платформы MLX (ML Explore), предназначенной для разработки систем искусственного интеллекта, которые будут запускаться на компьютерах с её собственными процессорами Apple Silicon. Все необходимые компоненты доступны на GitHub. 
Источник изображения: apple.com Цель проекта — упростить обучение и развёртывание моделей ИИ для исследователей, работающих на компьютерах Apple. Инструмент ориентирован не на потребителя, а на разработчиков, у которых теперь появилась мощная среда — есть похожие друг на друга API Python и API C++; поддерживается унифицированная память, то есть массивы данных находятся в общей памяти, и операции могут выполняться на центральном или графическом процессоре без копирования. Apple также представила набор примеров того, на что способен фреймворк MLX:
Apple осознала потребность в открытых и простых средах разработки систем машинного обучения — они позволят стимулировать дальнейшую работу в этой области. Важно, что MLX работает на чипах Apple, а они теперь используются во всех её продуктах, включая Mac, iPhone и iPad. Фреймворк задействует ресурсы центрального и графического процессоров, помогая добиться достаточно высокой производительности — возможно, в перспективе можно будет подключать ИИ-ускоритель Neural Engine, который также есть на этих чипах. |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться