
Опрос
|
реклама
Быстрый переход
Google добавит в поисковик ИИ-режим в ответ на запуск ChatGPT Search
21.12.2024 [11:03],
Павел Котов
Google намеревается добавить на поисковую страницу новую опцию — режим искусственного интеллекта, который вместо традиционной выдачи предлагает диалог с чат-ботом, способным отвечать на вопросы. Схожим образом работает ИИ-помощник Gemini. 
Источник изображения: sarah b / unsplash.com Режим ИИ будет включаться в меню верхней части страницы — там, где расположены привычные пункты «Все», «Картинки», «Новости», «Видео», «Покупки» и т. д., сообщило издание The Information со ссылкой на собственный источник. Как и чат-бот Gemini, поиск с ИИ будет сопровождать ответы ссылками на сайты и вторым полем ввода, где можно будет задавать дополнительные вопросы. «Сейчас наши современные модели продолжают развиваться, и есть грандиозная возможность внедрить эти новые функции в поиск, помогая людям находить в интернете ещё больше», — рассказали в Google. В октябре российский «Яндекс» представила аналогичную функцию «Поиск с Нейро». Perplexity AI, которая специализируется на технологиях поиска с ИИ, сообщила, что её система сегодня обрабатывает 100 млн запросов в неделю — компания намеревается повысить этот показатель до 100 млн запросов в день. Поиск с ИИ появился на платформе Reddit — отвечая на запросы, система Reddit Answers предлагает ссылки на посты и сообщества. Доступ к веб-поиску есть у OpenAI ChatGPT. Поиск Google научился анализировать любые файлы и отвечать на вопросы по содержимому
17.12.2024 [17:57],
Павел Котов
Поисковая машина Google готова предложить пользователям новый сервис — поиск по документу, который можно будет загрузить с локальной машины. Соответствующая функция обнаружена прямо в поисковой строке. 
Источник изображения: BoliviaInteligente / unsplash.com Механизм работы новой функции продемонстрировал пользователь соцсети X Хушал Бхервани (Khushal Bherwani). В поисковой строке Google появилась кнопка с изображением скрепки — рядом с кнопками голосового поиска и «Объектива». Нажатием на кнопку с изображением скрепки пользователь загружает в Google файл со своего компьютера, после чего поисковая система предлагает «спросить о файле что угодно» прямо в поисковой строке. 
Источник изображения: x.com/b4k_khushal Схожим образом работает поиск по документам в ChatGPT — здесь пользователи также могут загружать файлы и задавать о них вопросы; аналогичная возможность есть у чат-бота Google Gemini, но чтобы ей воспользоваться, потребуется платная подписка Gemini Advanced. Появление этой функции в бесплатной поисковой машине, с одной стороны, повысит её ценность в глаза пользователей; с другой, может вызвать некоторые сомнения по поводу защиты данных — при загрузке файлов с конфиденциальной информацией действительно лучше быть осмотрительнее. Пока нет ясности, каков масштаб данного эксперимента, и есть ли у этой функции шанс на широкое развёртывание. Неизвестно также, ограничится ли Google веб-интерфейсом или добавит возможность анализа локальных файлов в мобильное приложение. «Нам нужно генерировать прибыль»: Google нарастит присутствие ИИ в поиске
11.12.2024 [15:48],
Павел Котов
Холдинг Alphabet, в который входит Google, активно развивается в самых разных областях, в том числе на направлении беспилотного транспорта и квантовых вычислений, но приоритетным направлением для него остаётся веб-поиск. Здесь компания намерена увеличивать присутствие искусственного интеллекта. 
Источник изображения: BoliviaInteligente / unsplash.com Применение ИИ в поиске, который сделал бренд Google именем нарицательным, остаётся самой крупной ставкой для компании, заявила на конференции Reuters NEXT президент и главный инвестиционный директор Alphabet Рут Порат (Ruth Porat). «Мы встретим людей там, где они хотят оказаться», — рассказала топ-менеджер. Годовая выручка Alphabet составляет более $300 млрд, и бо́льшая часть этой суммы поступает от связанной с поиском рекламы. Прока что в поиск компания внедрила создаваемые генеративным ИИ сводки для запросов без очевидного ответа. Google была вынуждена пойти на этот шаг из-за конкуренции со стороны OpenAI ChatGPT. Но компании пришлось столкнуться с «галлюцинациями» ИИ, когда он даёт явно неправильные ответы. Google намерена продолжать развитие поиска с ИИ. Ещё одной ключевой инвестицией являются облачные услуги. Alphabet достигла значительных результатов в области здравоохранения; входящее в холдинг подразделение Isomorphic Labs разрабатывает медицинские препараты, используя ИИ AlphaFold, который предсказывает структуры белковых молекул. ИИ, по мнению Порат, поможет сохранить зрение людям, которые рискуют его потерять; а медицинским работникам не придётся больше подолгу работать у экранов в ущерб времени, которое они могут потратить на лечение пациентов. В 2024 году компания потратит $50 млрд на чипы, центры обработки данных и другие капитальные расходы; но и о результативности она забывать не намерена. «Нам нужно генерировать прибыль», — отметила президент Alphabet. Google упростил отключение персонализированных результатов поиска
06.12.2024 [12:14],
Павел Котов
В поиске Google появилась маркировка персонализированной выдачи — если результаты поиска подстраиваются под пользователя, это теперь легко можно отключить. Функция присутствовала и раньше, но управлять ей было сложнее. 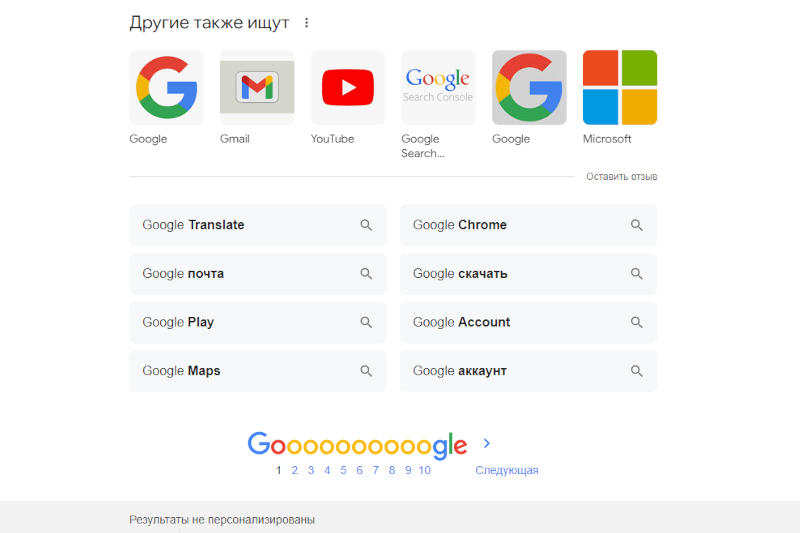
Источник изображения: google.com В нижней части страницы с поисковой выдачей Google появилась пометка о персонализации результатов — если выдача не подвергалась подстройке под пользователя, система выводит сообщение: «Результаты не персонализированы»; в противном случае рядом появляется ссылка на результаты без персонализации. «Это изменение помогает людям точнее понять, были ли их результаты персонализированы, а также предоставляет им возможность изучить неперсонализированные результаты. Мы также упростили для людей возможность изменять настройки персонализации в любое время», — прокомментировал нововведение представитель Google Нед Адрианс (Ned Adriance). Ранее соответствующая информация показывалась индивидуально для каждого пункта в выдаче — новый вариант, по мнению компании, представляется более доступным и понятным. Ссылка на общую поисковую выдачу «даёт людям возможность временно просматривать результаты, которые не были персонализированы», пояснили в Google — это значит, что при переходе по этой ссылке настройки в профиле не меняются. Отключить персонализацию в поиске можно как минимум с 2007 года — для этого необходимо добавить выражение «&pws=0» в конец адреса страницы с выдачей. Полностью отключить персонализацию поиска можно в настройках учётной записи Google. Гуглить — это для стариков. Бизнесу Google угрожает деградация поиска и новые привычки молодёжи
30.11.2024 [16:03],
Павел Котов
Традиционный веб-поиск всё больше становится прерогативой представителей старшего поколения, что создаёт ощутимую угрозу для основного бизнеса Google. Компания рискует утратить доминирующее положение в области веб-поиска, а с ним и в сегменте цифровой рекламы, пишет The Wall Street Journal. 
Источник изображений: BoliviaInteligente / unsplash.com Угрожающие благополучию Google негативные факторы настолько многочисленны и взаимосвязаны, что требование Минюста США о принудительном разделении компании может оказаться меньшей из её проблем. Над поисковым бизнесом Google, который она рассматривает как основной, нависла ощутимая угроза: для поиска информации люди всё чаще обращаются к системам искусственного интеллекта. При этом качество поисковой выдачи постоянно ухудшается из-за того, что активно растёт присутствие сайтов, которые наполняются материалами, созданными тем же ИИ. Эта тенденция может привести к долгосрочному сокращению поискового трафика Google и сопутствующей ему колоссальной прибыли, благодаря которой поддерживаются многочисленные убыточные проекты владеющего компанией холдинга Alphabet, в том числе подразделение беспилотного транспорта Waymo. Первая опасность, с которой столкнулась Google, очевидна и реальна: когда люди хотят что-то купить или найти информацию о товарах в интернете, они сразу идут к конкурентам, а вслед за ними уходят и средства от рекламы. Уже в 2025 году доля Google на рынке поисковой рекламы США впервые за всю историю наблюдений может упасть ниже 50 %, гласит прогноз eMarketer. На эту угрозу сослалась и сама компания, которую привлекли к суду по антимонопольному делу. К примеру, для поиска товаров на Amazon люди больше не открывают Google. Доля TikTok на рынке цифровой рекламы США составляет всего 4 %, но у службы коротких видео есть значительный потенциал для роста: по данным самой платформы, в первые 30 секунд после запуска приложения 23 % пользователей открывают поиск, и по всему миру она обрабатывает 3 млрд запросов в день. Вторая непосредственная угроза — рост популярности систем, которые просто дают ответы на вопросы, а не выступают в качестве традиционных поисковых служб. OpenAI добавила функцию поиска в ChatGPT, о собственном поисковике нового поколения задумались в Meta✴. Чат-боты с ИИ становятся всё более доступными практически: Microsoft и Apple интегрируют их в свои операционные системы. Эту ситуацию аналитики сравнивают с вытеснением традиционных гипермаркетов представителями сектора электронной коммерции или с тем, как Microsoft недооценила потенциал смартфонов с выходом iPhone. Google начала показывать в выдаче подготовленные генеративным ИИ сводки, но этот шаг, по её собственному признанию, стал ответом на действия конкурентов — стартапов и технологических гигантов.  Третья неблагоприятная для Google тенденция, с которой компания едва ли может что-то сделать — деградация экосистемы веб-сайтов, которую она сама сформировала, и от которой она зависит. Из-за распространения созданных ИИ материалов снижается качество поисковых результатов, а Google ответила на это ИИ-сводками в выдаче без необходимости открывать ссылки на сайты, и это лишь ускоряет упадок интернета в его привычном виде. Интернет представляет собой экосистему, в которой Google является одним из ведущих поставщиков трафика, а значит, и дохода. Без трафика с Google будут снижаться стимулы и ресурсы для дальнейшего запуска сайтов, привлекательных для поискового алгоритма Google. Этот процесс уже начался. Google продолжает докладывать о росте доходов по итогам квартала, но скорость, с которой пользователи нажимали на рекламу в поисковой выдаче, сократилась на 8 % за год — возможно, дело как раз в ИИ-сводках, которые избавляют пользователей от необходимости не только переходить на сайты в результатах поиска, но и даже прокручивать страницу до конца. Когда этот механизм развернётся в полной мере, изменения в поиске Google обойдутся владельцам сайтов в $2 млрд потерянной выручки, подсчитали в компании Raptive. Впрочем, и быстрого развития событий ожидать не стоит, уверены эксперты: люди склонны придерживаться определённых привычек, и пока ИИ не покажет значительного качественного превосходства над поиском Google, большинство так и будет пользоваться привычной системой. Минюст США потребовал, чтобы Google отказалась от соглашений о выборе поисковой системы по умолчанию на платформах, устройствах и других продуктах партнёров, а также чтобы компания продала проекты браузера Chrome и ОС Android. Есть мнение, что Google сумеет договориться с администрацией избранного президента США Дональда Трампа (Donald Trump), который придерживается консервативных взглядов, и до столь радикальных мер не дойдёт. Но конкуренция в области, которая является для компании основным бизнесом, может оказаться более ощутимой угрозой её благополучию. Google уберёт из выдачи вторую поисковую строку
22.10.2024 [10:12],
Павел Котов
Google много лет показывает в выдаче по некоторым запросам дополнительную поисковую строку, которая позволяет пользователю продолжить изучение интересующего вопроса, осуществляя поиск только по определённому сайту. Но со временем востребованность этой функции снизилась, и в компании приняли решение от неё отказаться. 
Источник изображения: Adarsh Chauhan / unsplash.com «Прошло больше десяти лет с тех пор, как мы впервые представили поисковое поле среди дополнительных ссылок в „Google Поиске“, и со временем мы заметили, что им стали меньше пользоваться. Учитывая это, и для упрощения поисковой выдачи мы удалим этот визуальный элемент с 21 ноября 2024 года», — рассказали в Google. 
Источник изображения: google.com На эту функцию действительно можно не обратить внимания, но, например, при появлении в выдаче крупного ресурса масштаба New York Times система действительно может показать под ссылкой на сайт и его описанием дополнительную поисковую строку, в которую можно вписать дополнительный запрос для поиска только на этом сайте. И с 21 ноября Google перестанет показывать это поле. Многие пользователи, возможно, и не заметили бы этого изменения, если бы Google о нём не рассказала. В остальном это лишь небольшое изменение поисковой машины, которая всё больше обогащается функциями искусственного интеллекта. Ранее стало известно, что глава поискового подразделения Google Прабхакар Рагхаван (Prabhakar Raghavan) оставит свою должность, на которой его сменит ответственный за разработку ИИ-продуктов Ник Фокс (Nick Fox). Google начал показывать полные рецепты блюд прямо в результатах поиска
11.10.2024 [13:44],
Павел Котов
Компания Google начала тестировать очередную функцию, призванную удержать пользователей на страницах поисковой выдачи — на этот раз за счёт популярных блогов с рецептами блюд. Теперь рецепты показываются целиком прямо в результатах поиска, и пользователю не нужно открывать сайт. 
Источник изображения: ayumi kubo / unsplash.com Функция получила название «Быстрый просмотр» (Quick View) — некоторые пользователи начали видеть соответствующую кнопку рядом с отдельными кулинарными рецептами. Например, при поиске по запросу «рецепт печенья с шоколадной крошкой» эта кнопка демонстрируется рядом со ссылкой на страницу популярного блога Preppy Kitchen. По нажатии на кнопку выводится полный рецепт с ингредиентами, фотографиями и пошаговыми инструкциями — без закрытия поисковой страницы Google. 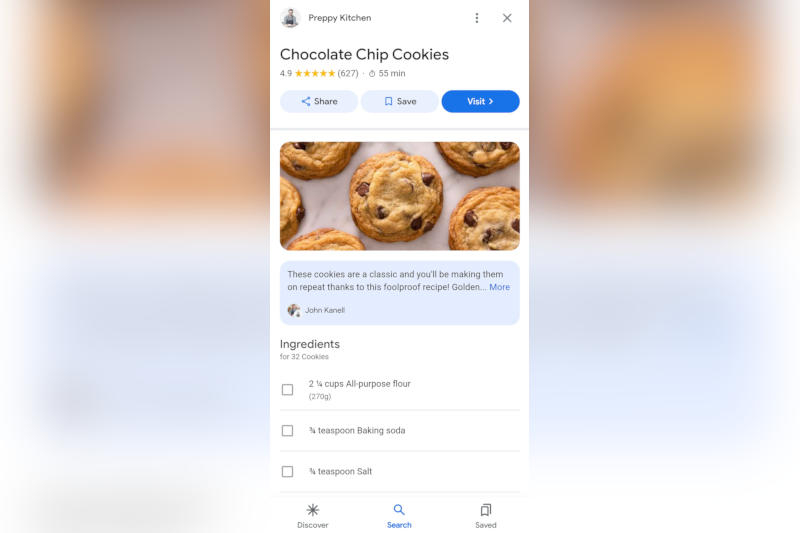
Источник изображения: Google «Мы всегда экспериментируем с разными способами предоставить нашим пользователям высококачественную и полезную информацию. Мы сотрудничаем с некоторым числом авторов на предмет новых возможностей рецептов в „Поиске“, которые помогут пользователям и повысят ценность веб-экосистеме. Анонсировать нам сейчас нечего», — пояснила ресурсу The Verge представитель Google Брианна Дафф (Brianna Duff). Она также сообщила, что функция запущена на ранней стадии эксперимента для ограниченной аудитории, и у компании есть соглашения с авторами блогов с рецептами. Инициатива согласуется со стратегией, в рамках которой эволюционирует поиск: Google стремится оставлять пользователя на своих сервисах и платформах, когда это возможно. Подготовленные ИИ сводки информации, которые позволяют сразу находить ответы на вопросы, не открывая сайтов из выдачи, также преследуют эту цель — даже если эти ответы далеки от идеальных. Вот и в случае с рецептами пользователь получит готовый ответ в Google и может отказаться переходить на другие сайты. Google тестирует в поисковой выдаче синие галочки, которые означают, что «этот сайт — это именно тот сайт»
04.10.2024 [15:18],
Николай Хижняк
Компания Google экспериментирует с новой функцией проверки в поиске, которая должна помочь пользователям избежать перехода по поддельным или мошенническим веб-ссылкам. Как пишет The Verge, некоторые пользователи видят в результатах поиска рядом с ссылками на сайты синие галочки верификации, которые указывают на то, что компания, например, Meta✴ или Apple, является подлинной, а не каким-то подражателем, пытающийся извлечь выгоду из узнаваемого бренда. 
Источник изображений: The Verge «Мы регулярно экспериментируем с функциями, которые помогают потребителям определять надёжные компании в интернете. В настоящее время мы проводим небольшой эксперимент, показывающий галочки рядом с определёнными организациями в поиске Google», — сказала The Verge представитель Google по связям с общественностью Молли Шахин (Molly Shaheen). Как пишет издание, синие галочки верификации можно обнаружить у Microsoft, Meta✴, Epic Games, Apple, Amazon и HP, однако отображаться они могут не для всех пользователей. Это говорит о том, что эксперимент не имеет широкого развёртывания. 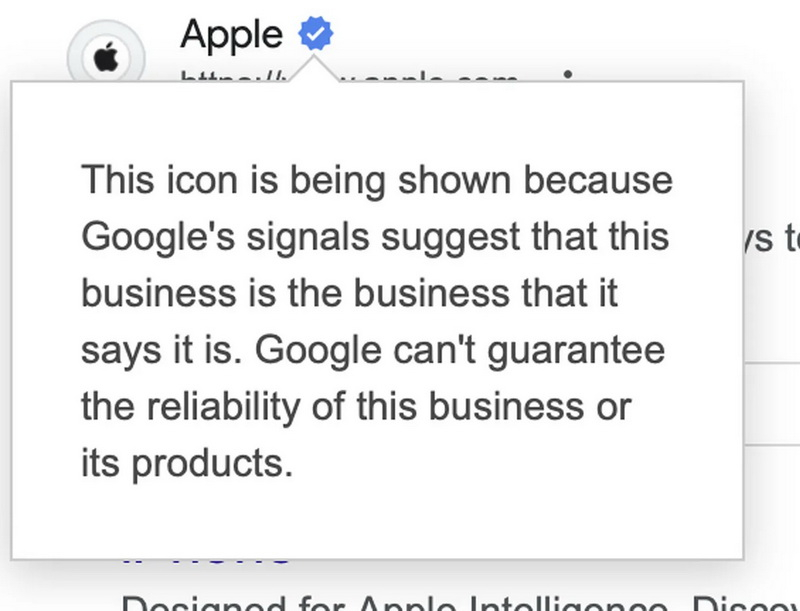 При наведении курсора на галочку верификации отображается сообщение, в котором объясняется, что это действительно ссылка на ресурс того или иного бренда, а не на сайт мошенника, выдающего себя за кого-то другого. Для верификации ссылок используются автоматическая и ручная проверки, а также данные платформы Merchant Center, пояснила в разговоре с The Verge представитель Google. Судя по всему, новый эксперимент с поиском Google является расширением функции Brand Indicators for Message Identification (BIMI), ранее появившейся в почте Gmail. Последняя позволяет почтовому сервису от Google отображать синюю галочку верификации рядом с именем отправителя письма, подтвердившего личность. Google пока официально не анонсировала планы по интеграции галочек верификации для поиска и не сообщила, когда больше пользователей смогут увидеть эту функцию. ИИ-ответы в поисковой выдаче Google обрушили посещаемость множества сайтов
15.08.2024 [19:17],
Сергей Сурабекянц
Удобные «Обзоры ИИ» (AI Overviews), которые Google теперь размещает в верхней части результатов поиска, лишают трафика сайты, на которые пользователи могли бы перейти из поисковой системы. Попытки владельцев интернет-ресурсов блокировать ИИ Google приводят к пропаданию сайта из результатов поиска и ещё более резкому снижению посещаемости, так как генератор ИИ-ответов и поисковый бот Google объединены в единую систему, и раздельно контролировать доступ для них невозможно. 
Источник изображений: unsplash.com Доминирование Google в поиске, которое федеральный суд на прошлой неделе определил как «незаконную монополию», даёт компании решающее преимущество — издателям приходится выбирать между предоставлением своего контента для использования моделями ИИ и исчезновением из поиска Google, являющегося главным источником трафика. Многие из них не готовы идти на подобный риск. Google утверждает, что AI Overviews — сводки, отображаемые в верхней части поисковой выдачи, — являются результатом её давней приверженности предоставлению более качественной информации и расширению возможностей для издателей. «Каждый день Google отправляет миллиарды пользователей на сайты по всему интернету, и мы намерены продолжать этот давно устоявшийся обмен ценностями, — заявил представитель Google. — Благодаря обзорам ИИ люди находят “Поиск Google” более полезным и возвращаются, чтобы искать больше, создавая новые возможности для обнаружения контента». Google использует отдельных краулеров для некоторых продуктов, таких как чат-бот Gemini. Но Googlebot, основной краулер компании, обслуживает как AI Overviews, так и «Поиск Google», так как, по словам представителя компании, «они тесно переплетены». Google сообщила, что издатели могут блокировать появление определённых страниц или их фрагментов в AI Overviews, но это также, вероятно, запретит их появление во всех других функциях поиска Google. Генеральный директор iFixit Кайл Винс (Kyle Wiens) сообщил, что отношения сайта iFixit с Google «гораздо более слабые», чем с другими компаниями, занимающимися ИИ. «Я могу запретить ClaudeBot индексировать нас, не навредив нашему бизнесу, — заявил он, имея в виду стартап Anthropic, занимающийся генеративным ИИ. — Но, если я заблокирую Googlebot, мы потеряем трафик и клиентов». «Это выглядит как экзистенциальный кризис [для владельцев интернет-ресурсов], — говорит издатель новостного сайта Talking Points Memo Джо Рагаццо (Joe Ragazzo). — Есть два плохих варианта. Вы уходите и немедленно умираете, или вы сотрудничаете с ними и, вероятно, просто медленно умираете, потому что в конечном итоге они тоже не будут нуждаться в вас». Рост генеративного ИИ породил волну стартапов, предлагающих поисковые продукты на основе ИИ. Растущая популярность чат-ботов может стать серьёзной угрозой для поискового бизнеса Google. Но, чтобы составить конкуренцию поисковому гиганту, требуется максимально полное сканирование и индексирование интернет-ресурсов, что представляет собой непростую задачу. Для этого требуются деньги, вычислительные мощности и ёмкие хранилища информации. Многие издатели, борясь с нелицензированным использованием контента для индексирования, ограничивают сканирование своих ресурсов для сторонних компаний, предоставляя наибольшую свободу действий лишь крупным поисковым системам, таким как Google или Bing, которые служат для них источниками трафика.  Поисковые стартапы не могут обеспечить трафик, сопоставимый с ведущими игроками в сфере интернет-поиска, поэтому они вынуждены платить издателям за лицензирование контента. На фоне волны сделок между медиакомпаниями и стартапами в области ИИ отказ Google от попыток лицензирования контента особенно заметен, а у издателей практически отсутствуют рычаги влияния на компанию. Если не считать единственной сделки на $60 млн с Reddit, которая привела к скачкообразному росту трафика на сайт социальной сети, Google дала понять издателям, что не заинтересована в подобных переговорах. По свидетельствам осведомлённых источников, попытки поискового стартапа Perplexity заключить с Reddit подобную сделку не увенчались успехом из-за слишком высокой планки, установленной Google. Другие поисковые стартапы также не имеют возможности получить доступ к контенту ресурсов, подобных Reddit. «Нам понадобится 20 лет наших текущих доходов только для того, чтобы заплатить Reddit, — сказал Владимир Преловац, основатель поискового стартапа Kagi. — Я даже не рассматриваю такую возможность». Трудности с индексированием контента испытывают не только небольшие стартапы. Крупные популярные сайты, включая Amazon, Goodreads и Uniqlo, заблокировали поисковый робот SearchGPT от OpenAI, что потенциально создаёт проблемы для амбиций компании в интернет-поиске. OpenAI настаивает, что сайты могут появляться в результатах поиска, даже если запретят индексирование. Дело в том, что файлы robots.txt, которые устанавливают правила сканирования, не были признаны юридически значимыми, поэтому публичные данные можно индексировать, если не требуется вход в систему или ввод учётных данных. После знаменательного судебного решения, установившего, что Google монополизировала рынок онлайн-поиска, Министерство юстиции США рассматривает разные варианты правовой защиты, от предоставления конкурентам доступа к поисковому индексу Google до разделения компании. Закон ЕC «О цифровых рынках» уже требует от Google делиться некоторыми данными поисковых запросов. Винс считает, что «отделение поиска Google от их работы в области ИИ позволит устранить конфликты». Вице-президент по связям с общественностью поисковой системы DuckDuckGo Камил Базбаз (Kamyl Bazbaz) отметил важность поисковых индексов в эпоху ИИ, он уверен, что «технологические сдвиги, происходящие в поиске, делают индекс Google, связанный с антимонопольными проблемами, ещё более проблематичным». Независимо от исхода антимонопольного дела против Google, изменения, происходящие в поисковой среде, лишний раз доказывают, что издателям нельзя становиться чрезмерно зависимыми от какой-либо одной технологической платформы, включая Google. «Мы убеждены, что вам нужно формировать настоящие отношения с читателями, — считает Рагаццо, — и именно так вы создаёте издание, которое может выдержать разные эпохи». Google начала масштабную зачистку поисковой выдачи от откровенных фейковых изображений
31.07.2024 [17:56],
Сергей Сурабекянц
Google внедрила новые функции онлайн-безопасности, которые упрощают масштабное удаление откровенных дипфейковых изображений из поискового индекса и предотвращают их появление на первых позициях результатов поиска. При удалении поддельного контента по запросам пользователей будут также удалены все возможные дубликаты и отфильтрованы результаты по похожим запросам. 
Источник изображения: Pixabay «Эти меры защиты уже доказали свою эффективность в борьбе с другими типами изображений, полученных без согласия правообладателей, и теперь мы создали те же возможности и для поддельных откровенных изображений, — заявила менеджер по продуктам Google Эмма Хайэм (Emma Higham). — Эти усилия призваны дать людям дополнительное спокойствие, особенно если они опасаются появления подобного контента в будущем». Позиции сайтов в индексе Google будут скорректированы, чтобы противодействовать поиску явного фейкового контента. Например, на поисковые запросы, которые намеренно запрашивают поддельные изображения реального человека, поисковая система будет выдавать «высококачественный, корректный контент», например, соответствующие новостные статьи. Сайты со значительным количеством фейковых изображений откровенного характера будут понижены в рейтинге поиска Google. Google утверждает, что предыдущие обновления в этом году более чем на 70 процентов снизили появление в поисковой выдаче откровенных изображений по запросам дипфейкового контента. Перед компанией стоит задача научить поисковую систему отличать реальный откровенный контент, например, изображения обнажённого тела, сделанные по обоюдному согласию, от фейков, чтобы сохранить возможность демонстрации законных изображений. Ранее Google уже предпринимала усилия для решения проблемы появления опасного или откровенного контента в интернете. В 2022 году компания расширила перечень персональной или конфиденциальной информации, которую пользователь может удалить из поиска. В августе 2023 года Google начала по умолчанию размывать откровенно сексуальные изображения. В мае этого года компания запретила рекламодателям продвигать услуги по созданию контента откровенно сексуального характера. Google обвинила в странных ответах поискового ИИ самих пользователей и недостаток обучающих данных
31.05.2024 [16:27],
Павел Котов
На минувшей неделе Google добавила в поисковую систему блок сводок, которые готовит генеративный ИИ. Компания стремилась повысить качество работы поисковой системы, но ИИ начал давать пользователям странные ответы, например, советовал есть камни и клеить сыр к пицце. Компания быстро удалила наиболее скандальные результаты, но они уже успели уйти в мемы. Теперь с комментариями выступила глава поискового подразделения компании. 
Источник изображения: Kai Wenzel / unsplash.com Глава отдела поиска Google Лиз Рид (Liz Reid) обвинила в неточных результатах ответов поискового генеративного ИИ «пустоты данных» и самих пользователей, которые придумывали странные вопросы. По её мнению, блоки с обзорами, которые создаёт генеративный ИИ, дают пользователям «большее удовлетворение» работой поисковой службы. Генерируемые ИИ ответы, как правило, не являются галлюцинациями — просто система иногда неверно интерпретирует то, что есть в Сети. «Нет лучшего аргумента, чем миллионы людей, использующих эту функцию со множеством новых запросов. Мы также отметили новые бессмысленные запросы, по-видимому, направленные на получение ошибочных результатов», — сообщила Рид. Компания, однако, продолжает работать над функцией, ограничивая появление ИИ-обзоров в выдаче по «бессмысленным» запросам и при работе с сатирическими материалами. Это важно, потому что первоначально система могла процитировать сатирический ресурс или сослаться на пользователя соцсети с неприличным ником. Рид также сравнила ИИ-обзоры с поисковой функцией «Выделенные описания» — это блоки с фрагментами текста релевантных веб-страниц, которые приводятся без участия генеративного ИИ. По словам топ-менеджера, «уровни точности» двух функций примерно совпадают. Google признала подлинность слитых секретных документов о работе поисковика
30.05.2024 [15:26],
Павел Котов
Недавно ставший достоянием общественности пакет из 2500 внутренних документов Google с подробной информацией о работе поисковой системы является подлинным, подтвердили в компании. До настоящего момента IT-гигант отказывался комментировать эти материалы. 
Источник изображения: Alex Dudar / unsplash.com В документах подробно описано, какие данные отслеживает Google, и указывается, что некоторые из них компания может использовать в работе тщательно охраняемого алгоритма поискового ранжирования. Материалы позволяют, хотя и частично, ознакомиться с механизмами работы одной из наиболее важных систем, формирующих интернет. «Предостерегаем от неверных допущений о „Поиске“ на основе вырванной из контекста, устаревшей или неполной информации. Мы поделились обширными сведениями о том, как работает „Поиск“ и типах факторов, которые учитываются в наших системах, [мы] также работаем над защитой целостности наших результатов от манипуляций», — заявил ресурсу The Verge представитель Google Дэвис Томпсон (Davis Thompson). Об утечке материалов Google сообщили эксперты по поисковой оптимизации Рэнд Фишкин (Rand Fishkin) и Майк Кинг (Mike King), которые опубликовали аналитические работы на основе этих документов. Согласно этим материалам, Google собирает и может использовать данные, которые, как утверждают представители компании, не влияют на ранжирование страниц в поиске: это клики по ссылкам, данные пользователей Chrome и многое другое. Эти документы располагаются в базе для сотрудников Google, и всё ещё нет ясности, какие именно данные используются при ранжировании — информация может быть устаревшей, использоваться исключительно в учебных целях или собираться, но не применяться при поиске. В материалах также не говорится, какой вес в поиске имеют различные факторы, если они вообще учитываются. Обнародованная информация, вероятно, вызовет волнения в сфере поисковой оптимизации (SEO), маркетинге и издательском деле. Факторы, которыми Google руководствуется при ранжировании сайтов в поисковой выдаче, оказывает большое влияние на компании и предпринимателей, которые делают ставку на интернет: от небольших независимых издателей до ресторанов и интернет-магазинов. Возникла целая отрасль специалистов, которые надеются разгадать, а то и перехитрить поисковые алгоритмы. И утечка внутренних документов Google поможет им понять, о чем думает доминирующая в Сети компания. Секретная документация Google о принципах работы поискового алгоритма стала достоянием общественности
29.05.2024 [06:12],
Анжелла Марина
Предполагаемая утечка 2500 страниц внутренней документации Google проливает свет на то, как работает Поиск, самый могущественный алгоритм интернета. Обнародованные документы показывают, что компания скрывала правду о некоторых аспектах поискового алгоритма. Эксперты обнаружили противоречия с публичными заявлениями компании. 
Источник изображения: Daniel Romero/Unsplash Несколько дней назад произошла масштабная утечка внутренних документов Google, связанных с работой поискового алгоритма компании. По словам эксперта по поисковой оптимизации (SEO) Рэнда Фишкина (Rand Fishkin), который первым сообщил об утечке, речь идёт о 2500 страницах конфиденциальной документации. Эти документы, как утверждается, содержат беспрецедентные подробности о том, как Google анализирует и ранжирует веб-страницы в результатах поиска. Однако в них также есть информация, которая, похоже, противоречит некоторым публичным заявлениям, сделанным представителями Google о работе их поискового алгоритма. В частности, в документах упоминается использование данных из браузера Google Chrome для анализа и ранжирования веб-страниц. Однако ранее представители Google неоднократно отрицали, что данные Chrome каким-либо образом влияют на рейтинг сайтов в поиске. Ещё один потенциальный пример расхождения «слов с делом» касается показателя EEAT (Expertise, Authoritativeness, Trustworthiness), который Google использует для оценки надёжности источников информации. Согласно утечке, Google активно отслеживает атрибуты авторства контента на страницах, что может влиять на рейтинг EEAT. Однако ранее представители компании заявляли, что EEAT не является фактором ранжирования. Помимо этого, в документах содержатся технические детали о том, какие именно данные с веб-страниц и сайтов собирает Google, как обрабатываются запросы по политически чувствительным темам, какие сигналы используются для анализа небольших малопосещаемых сайтов и многое другое. Рэнд Фишкин и другие эксперты по SEO, ознакомившиеся с информацией, утверждают, что она показывает — Google не была полностью честна и прозрачна в вопросах о том, как работает её поисковый алгоритм. По их мнению, компания намеренно скрывала некоторые аспекты с целью ввести в заблуждение конкурирующие друг c другом сайты. Многие эксперты сходятся во мнении, что скрытность Google в вопросах работы поискового алгоритма способствовала разрастанию индустрии SEO, основанной на догадках и теориях. Фишкин призывает журналистов и экспертов более критично относиться к публичным заявлениям Google и не принимать всё на веру. По его мнению, данная утечка должна стать поводом для более пристального анализа реальной работы поискового алгоритма Google в противовес официальной позиции компании. Представители Google пока не прокомментировали подлинность обнародованных документов и обвинений в лукавстве. Ожидается, что в ближайшее время компания сделает официальное заявление по этому поводу. Найден способ навсегда избавить поисковую выдачу Google от советов ИИ
25.05.2024 [13:01],
Павел Котов
Для тех, кто в штыки воспринял появление генерируемых искусственных интеллектом сводок информации в поисковой выдаче Google, найден способ принудительно вернуть поисковик к показу традиционных «десяти синих ссылок» по умолчанию — без советов есть клей и бегать с ножницами, а также без необходимости каждый раз вручную включать опцию «Веб-версия». 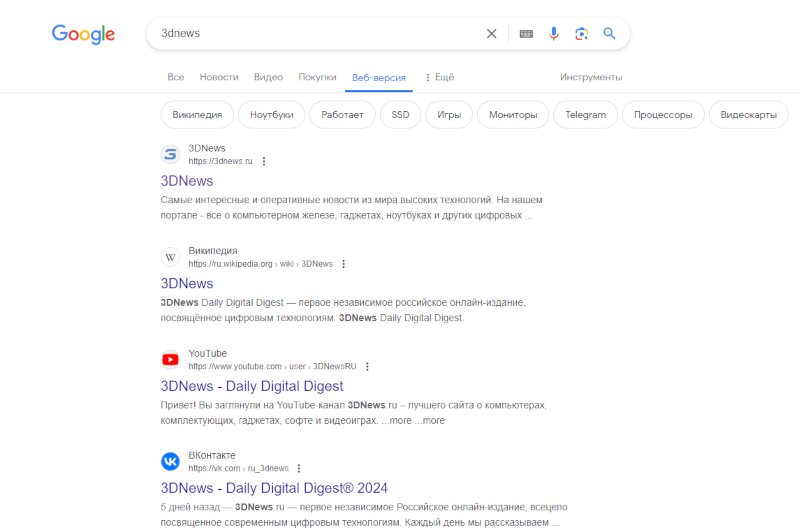 Вариант с «чистой» поисковой выдачей Google предложила на минувшей неделе — он стал альтернативой странице с результатами, которую формирует ИИ. Единственное неудобство при этом — необходимость каждый раз выбирать опцию «Веб-версия» в выпадающем подменю под поисковой строкой. Выяснилось, что есть способ включить её по умолчанию, и этот способ был обнаружен при изучении URL-адреса поисковой выдачи Google по произвольному запросу. Этот адрес содержит множество параметров, и за показ обычных «десяти синих ссылок» отвечает выражение «&udm=14» — им и следует воспользоваться при настройке браузера. Тем, кто привык начинать поиск прямо из адресной строки браузера, потребуется открыть настройки поисковых систем: в Google Chrome и Mozilla Firefox они не очень отличаются, а в производных от них браузерах механизм настройки будет схожим. В случае Chrome достаточно щёлкнуть правой кнопкой мыши в адресной строке и выбрать пункт «Управление поисковыми системами и поиском по сайту». В Firefox придётся приложить дополнительные усилия: ввести в адресную строку выражение «about:config», нажать клавишу Enter, найти раздел «browser.urlbar.update2.engineAliasRefresh» и щёлкнуть мышью кнопку с изображением знака «плюс» справа; после этого перейти в раздел «Настройки» и подраздел «Поиск», прокрутить до блока «Значки поисковых систем» и под ним щёлкнуть кнопку «Добавить». 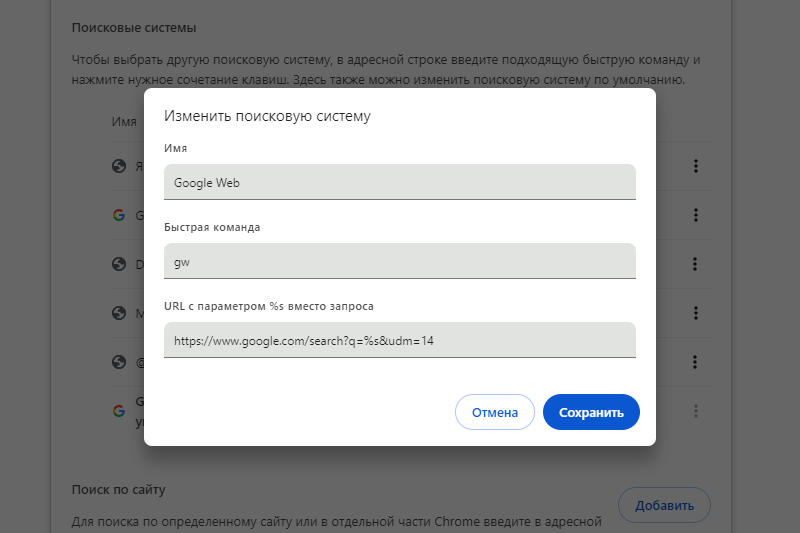 В обоих браузерах возможности редактировать существующий пункт Google не будет, поэтому потребуется создать новый ярлык поисковой системы, назвать его, например, Google Web и в качестве основного адреса добавить выражение «https://www.google.com/search?q=%s&udm=14». Оставшееся поле, которое расположено посередине, может называться «Быстрая команда» или «Краткое имя» — его значение пригодится, если новая поисковая система не будет установлена по умолчанию. Так, если внести в это поле сочетание «gw», то впоследствии можно будет использовать новую поисковую систему, вводя запросы вида «gw куда сходить вечером». При желании можно дополнить адрес параметром «&tbs=li:1», с которым Google производит поиск только по точному совпадению, без замены слова в запросе синонимами. Можно также пользоваться прокси-сайтами, например, udm14.com, поисковое поле которого ведёт напрямую в выдачу Google с активной опцией «Веб-версия» — но владельцы таких ресурсов имеют техническую возможность перехватывать поисковые запросы пользователей. Поисковая выдача в чистом виде: в Google появился традиционный веб-поиск
16.05.2024 [11:48],
Павел Котов
В поисковой выдаче Google появилась вкладка «Веб-версия» (Web), которая показывает только традиционные текстовые результаты поиска без добавленных компанией многочисленных надстроек, загромождающих стандартные «десять синих ссылок». 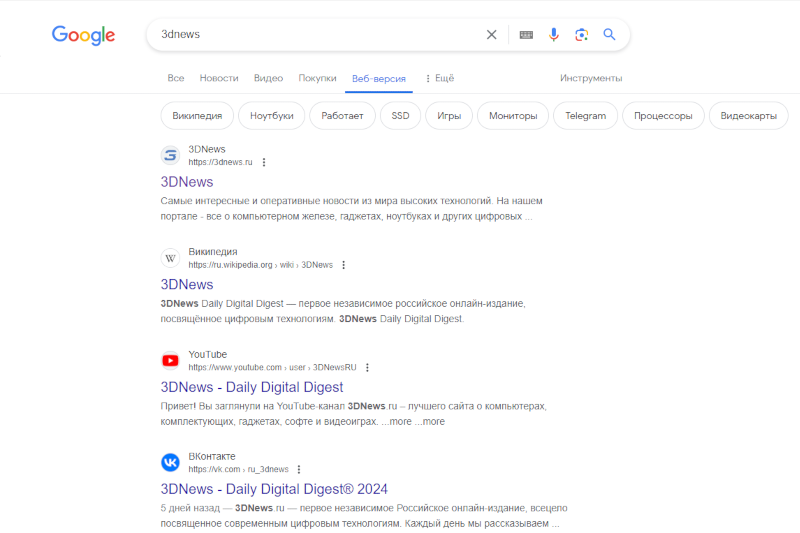 Google добавила к вариантам поисковой выдачи опцию «Веб-версия», которая доступна наряду с привычными вариантами «Новости», «Изображения» и «Покупки». Потребность в этой опции возникла после многочисленных нововведений, которыми компания обогатила результаты поиска в последние годы — в новой вкладке показывается только текстовая выдача без изображений, предложений купить товары, карт и прочих элементов, которые Google считает полезными. Чтобы вернуть актуальный вид выдачи, придётся выбрать вкладку «Все» — она ведёт на страницу с дополнительными элементами, которые компания добавила как для удобства пользователей, так и для своей выгоды. Разница станет ещё заметнее после того, как Google доверит формирование страницы с результатами поиска искусственному интеллекту Gemini. На все эти дополнения жалуются и пользователи, которым не всегда удаётся пробраться сквозь дополнительные элементы к органическим результатам поиска, и владельцы сайтов, которые по той же причине получают меньше трафика. Ситуация осложняется проблемой поискового мусора: бесполезных ресурсов с чрезмерной поисковой оптимизацией, сайтов в большим объёмом сгенерированных ИИ текстов и поддельных интернет-магазинов, которые выманивают личные данные посетителей. Новый вариант с «чистым» веб-поиском станет доступен для пользователей по всему миру в ближайшие два дня. Он позволит людям изучать органическую выдачу и избавит от потребности открывать другие поисковые системы, чтобы свериться с их результатами. Правда, в Google пока не уверены в собственном нововведении: пункт «Веб-версия» скрыт в выпадающем меню «Ещё». |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться