|
Опрос
|
реклама
Быстрый переход
Meta✴ использовала почти все ваши публикации с 2007 года для обучения ИИ
13.09.2024 [07:22],
Дмитрий Федоров
Компания Meta✴, владеющая Facebook✴ и Instagram✴, подтвердила, что использует публичные посты пользователей, опубликованные с 2007 года, для обучения ИИ-моделей. Это заявление прозвучало во время правительственного расследования в Австралии. При этом миллиарды пользователей за пределами Европейского союза (ЕС) и Бразилии, сохраняющие публичность своих постов, не имеют возможности отказаться от участия в обучении ИИ. 
Источник изображения: VEPN / Pixabay Во время расследования, проводимого австралийским правительством относительно внедрения ИИ, Мелинда Клейбо (Melinda Claybaugh), глобальный директор по вопросам конфиденциальности компании Meta✴, признала, что компания использует все публичные текстовые и фотоматериалы, опубликованные совершеннолетними пользователями Facebook✴ и Instagram✴ с 2007 года. Признание прозвучало после настойчивых вопросов сенатора от партии «Зелёных» Дэвида Шубриджа (David Shoebridge). При этом Meta✴ не предоставляет возможности удаления уже собранных данных, даже в случае, если пользователь изменит настройки приватности. Meta✴ в своих материалах по конфиденциальности и блогах упоминает об использовании публичных постов и комментариев для обучения моделей генеративного ИИ. Однако детали этого процесса остаются неясными. В июне 2023 года, отвечая на запрос The New York Times о сроках начала и масштабах сбора данных, Meta✴ не предоставила конкретного ответа, отметив лишь, что изменение настроек приватности предотвратит будущий сбор. Особенно тревожит факт использования данных пользователей, которые в 2007 году могли быть несовершеннолетними. Клейбо заявила, что Meta✴ не использует данные пользователей младше 18 лет, однако не смогла дать чёткого ответа на вопрос о том, как обрабатываются аккаунты взрослых, созданные ими в детском возрасте. Сенатор Тони Шелдон (Tony Sheldon) задал вопрос о сканировании публичных фотографий детей на аккаунтах взрослых пользователей. Клейбо подтвердила, что такие данные тоже используются. В отличие от пользователей из ЕС, имеющих право отказаться от участия в обучении ИИ благодаря местным законам о конфиденциальности, и пользователей из Бразилии, где недавно запретили Meta✴ использовать персональные данные для обучения ИИ, большинство из миллиардов пользователей Facebook✴ и Instagram✴ лишены такой возможности. Клейбо не смогла уточнить, будет ли предоставлена возможность отказа австралийским пользователям или кому-либо ещё в будущем, ссылаясь на неопределённость нынешнего регуляторного ландшафта. Отсутствие возможности отказа от использования данных вызывает критику со стороны правозащитников и политиков. Сенатор Шубридж отметил, что неспособность правительства Австралии принять адекватные законы о конфиденциальности позволяет таким компаниям, как Meta✴, продолжать монетизировать и эксплуатировать даже фотографии и видео детей на Facebook✴. Данное заявление указывает на глобальную проблему: законодательство не поспевает за темпами развития технологий ИИ и методами сбора данных. Пользователи WhatsApp смогут отправлять сообщения в другие приложения
07.09.2024 [12:36],
Владимир Фетисов
Компания Meta✴ Platforms рассказала больше о своих планах касательно реализации поддержи обмена сообщениями со сторонними сервисами в WhatsApp и Messenger. После вступления в силу новых европейских законов, касающихся регулирования работы интернет-сервисов, Meta✴ вынуждена обеспечить для пользователей в регионе возможность взаимодействия через мессенджеры WhatsApp и Messenger со сторонними сервисами. 
Источник изображения: Dima Solomin / unsplash.com Функция хранения чатов из разных приложений в одном месте будет развёртываться постепенно. Meta✴ будет информировать европейцев с помощью уведомлений в приложениях о том, когда у них появится возможность объединить чаты в поддерживаемых сервисах. В компании также заявили, что разработчики «вышли за рамки» базовых функций, необходимых для реализации обмена сообщениями со сторонними сервисами. Они готовятся предложить пользователям больше возможностей, включая функции отправки реакций, прямых ответов на сообщения, индикации при наборе текста, уведомлений о прочтении и др. 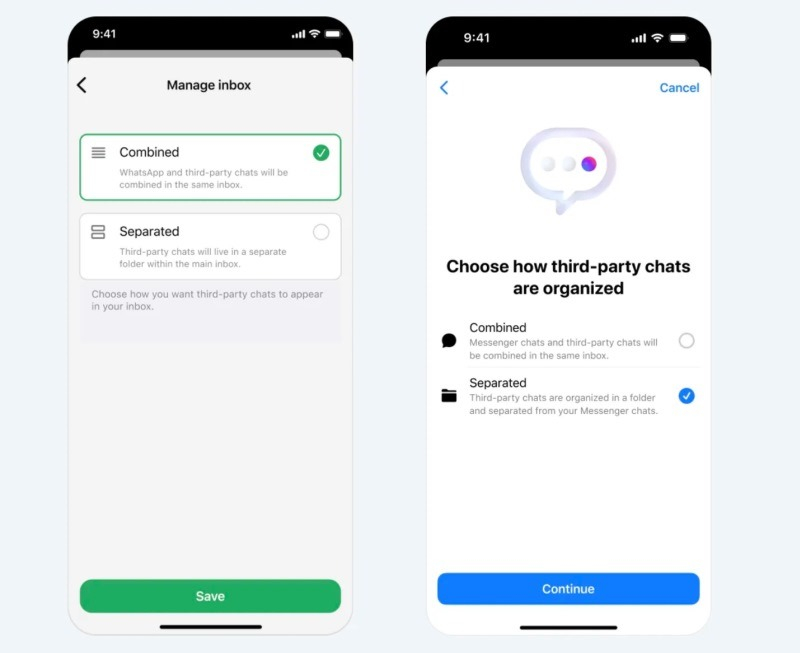
Источник изображения: Meta✴ В следующем году Meta✴ добавит возможность создания групповых чатов с пользователями сторонних сервисов. Более того, в 2027 году компания намерена интегрировать поддержку аудио- и видеозвонков из сторонних приложений. Более подробные детали пока не раскрываются, но очевидно, что Meta✴ прикладывает немало усилий, чтобы соответствовать новым законам в Евросоюзе. Google, Amazon и другие тайно прослушивают пользователей для показа целевой рекламы
03.09.2024 [13:44],
Павел Котов
Медиаконгломерат Cox Media Group предложил технологическим компаниям новый инструмент для формирования целевой рекламы — он анализирует собранные с домашних устройств аудиозаписи. О существовании этой программы стало известно в прошлом году, и теперь ресурсу 404 Media удалось раздобыть презентацию Cox и подтвердить, что ИТ-гиганты подслушивают разговоры пользователей. 
Источник изображения: 404media.co Инструмент получил название Active Listening («Активное прослушивание»), и он работает, получая данные от умных устройств, которые «фиксируют данные о намерениях в реальном времени, слушая наши разговоры». Собрав информацию, рекламодатели получают возможность «объединять эти голосовые данные с поведенческими, чтобы таргетировать потребителей на рынке». Для сбора данных о поведении потребителей в Сети используется искусственный интеллект — при этом потребители «оставляют след данных, основанный на их разговорах и поведении в Сети». ИИ собирает и анализирует «поведенческие и голосовые данные из более чем 470 источников». Эти инструменты предлагаются рекламодателям в США, где в большинстве штатов действуют законы о прослушивании телефонных разговоров — записывать человека без его ведома преимущественно запрещено. В презентации говорится, что Cox сотрудничает с крупнейшими технологическими платформами, включая Google, Amazon и Facebook✴, но в этих компаниях от такого сотрудничества открестились. В Google сообщили, что исключили Cox из программы рекламных партнёров, и отметили, что «все рекламодатели должны соблюдать все действующие законы и правила, а также нашу политику Google Ads, и когда мы обнаруживаем рекламу или рекламодателей, которые нарушают эту политику, мы принимаем соответствующие меры». В Amazon заявили, что платформа «Amazon Ads никогда не сотрудничала с CMG по этой программе и делать этого не планирует». В Meta✴ указали, что компания в презентации указана как «генеральный маркетинговый партнёр, а не партнёр „в этой программе“», а также сослались на запись в корпоративном блоге о политике Facebook✴ в отношении применения микрофонов для целевой рекламы. ИИ-функции в приложениях Meta✴ ежемесячно используют 400 млн человек
01.09.2024 [17:32],
Владимир Фетисов
Инструменты на основе искусственного интеллекта компании Meta✴ Platforms, доступные в Facebook✴, Instagram✴, WhatsApp и Threads, используют не менее 400 млн человек в месяц и 40 млн человек ежедневно. Об этом пишет издание The Information со ссылкой на данные, полученные от двух осведомлённых сотрудников Meta✴. 
Источник изображения: Growtika/unsplash.com Информация о количестве пользователей ИИ-функций Meta✴ появилась вскоре после того, как стало известно, что с ИИ-ботом ChatGPT компании OpenAI еженедельно взаимодействуют более 200 млн человек. В OpenAI позднее подтвердили эту информацию. Это означает, что поддерживаемая Microsoft компания нарастила пользовательскую базу на 100 млн человек менее чем за год. Несмотря на это, данные по количеству пользователей указывают, что Meta✴ остаётся полноценным конкурентом OpenAI в сфере предоставления услуг на основе генеративных нейросетей. Что касается Meta✴, то компания Марка Цукерберга (Mark Zuckerberg) выбрала подход, отличный от того, как работает OpenAI. Разработчики из Meta✴ выпустили на рынок несколько больших языковых моделей Llama с открытым исходным кодом, которые разработчики могут настраивать в соответствии с собственными потребностями. Напомним, ИИ-алгоритмы Meta✴ можно задействовать для помощи в написании и редактировании текстов, а также генерации изображений по текстовому описанию. Они доступны во многих пользовательских приложениях Meta✴, включая Facebook✴ и Instagram✴. Meta✴ похвасталась ростом спроса на языковые модели Llama в 10 раз — всё благодаря их открытости
29.08.2024 [22:42],
Николай Хижняк
Компания Meta✴ сообщила, что количество загрузок её больших языковых моделей ИИ (LLM) Llama приближается к 350 млн. Это в 10 раз больше показателя загрузок за аналогичный период прошлого года. Примерно 20 млн из этих загрузок были сделаны только за последний месяц, после того как компания выпустила языковую модель Llama 3.1, которая, по заявлению Meta✴, позволит ей напрямую конкурировать с решениями компаний OpenAI и Anthropic. 
Источник изображения: Gerd Altmann / pixabay.com У некоторых крупнейших поставщиков облачных услуг, сотрудничающих с Meta✴, ежемесячное использование языковых моделей Llama выросло в десять раз с января по июль этого года. Также отмечается, что с мая по июль использование Llama на серверах её партнёров среди провайдеров облачных услуг выросло более чем вдвое по количеству токенов. Помимо Amazon Web Services (AWS) и Microsoft Azure, компания сотрудничает с Databricks, Dell, Google Cloud, Groq, Nvidia, IBM watsonx, Scale AI и Snowflake и другими, чтобы сделать свои LLM более доступными для разработчиков. Meta✴ считает, что успех её языковых моделей связан с тем, что они распространяются по открытой лицензии. По словам компании, открытое распространение её LLM позволило «расширить и разнообразить экосистему ИИ и предоставить разработчикам больше выбора». Когда Meta✴ выпустила Llama 3.1, глава компании Марк Цукерберг (Mark Zuckerberg) превозносил достоинства ИИ с открытым исходным кодом, назвав его «движением вперёд». Он также рассказал, что компания предпринимает шаги, чтобы сделать ИИ с открытым исходным кодом отраслевым стандартом. В своём последнем отчёте Meta✴ также рассказала, как её партнёры используют большие языковые модели. Например, оператор связи AT&T использует Llama для более точного пользовательского поиска. Один из крупнейших американских доставщиков еды DoorDash использует LLM, чтобы упростить работу своих инженеров по программному обеспечению. Языковая модель также используется для генерации живых реакций и цифровых существ в игре Peridot от компании Niantic. В свою очередь Zoom использует Llama, а также другие языковые модели, для работы ИИ-ассистента, который может подводить итоги встреч и делать умные заметки. Meta✴ разрабатывает компактные очки смешанной реальности Puffin — они выглядят почти как обычные очки
29.08.2024 [10:14],
Владимир Мироненко
Meta✴ работает над созданием очков смешанной реальности, предназначенных для тех, кому не по душе использование тяжёлой гарнитуры в течение длительного времени, сообщил ресурс The Information. Новое носимое устройство под кодовым названием Puffin, которое выглядит как обычные, немного громоздкие очки, появится на рынке не раньше 2027 года если, конечно, компания и дальше будет заниматься его разработкой. 
Источник изображения: Ray-Ban По данным источников, очки весят около 110 граммов, что больше веса умных очков Ray-Ban от Meta✴, но значительно меньше веса более громоздкой гарнитуры Quest 3. В связи с меньшим формфактором очки могут иметь внешний блок с аккумулятором и процессором — аналогично проводному аккумулятору, поставляемому с гарнитурой Apple Vision Pro. Также сообщается, что новые очки будут оснащены блинчатыми линзами, что обеспечит новинке более тонкий профиль. Устройство будет поддерживать сквозную передачу видео, чтобы владелец мог видеть окружающие объекты за пределами дисплеев, а также использование отслеживания рук и глаз для управления. На прошлой неделе The Information сообщил, что Meta✴ решила закрыть проект по дальнейшей разработке гарнитуры виртуальной реальности La Jolla в связи с высокой конечной ценой, что ставило под сомнение перспективы её продаж. Как ожидается, в сентябре на мероприятии Meta✴ Connect компания представит новые очки дополненной реальности Orion, разработка которых ведётся несколько лет. Meta✴ разрабатывала процессор для AR-очков, но отказалась от него для оптимизации расходов
28.08.2024 [17:12],
Павел Котов
В прошлом году, который глава Meta✴ Марк Цукерберг (Mark Zuckerberg) назвал «годом эффективности», в компании был закрыт проект по разработке фирменных чипов для очков дополненной реальности. На фоне массовых увольнений и усилий по сокращению расходов во всей компании работа над этими процессорами была признана слишком дорогой, а потребность в них — слишком далёкой от текущих бизнес-приоритетов компании, сообщает Fortune со ссылкой на собственные источники. 
Источник изображения: ray-ban.com Отказавшись от собственных чипов, Meta✴ в разработке прототипов очков дополненной реальности стала использовать процессоры производства других компаний, в том числе Qualcomm. Сейчас гигант соцсетей продолжает работу над собственными чипами в других сегментах, включая специализированные процессоры для обработки рабочих нагрузок искусственного интеллекта в центрах обработки данных. Свои чипы для носимых устройств Meta✴ пыталась разработать с 2019 года — процессор должен был появиться в линейке очков дополненной реальности, которые проходят под кодовым названием Orion. Не исключено, что экспериментальный прототип таких очков компания представит на мероприятии Meta✴ Connect в сентябре. Сейчас Meta✴ продаёт очки, выпускаемые совместно с компанией EssilorLuxottica под маркой Ray-Ban. Устройство имеет встроенную камеру и чип для подключения к телефону, но не располагает функциями дополненной реальности — подачи изображения непосредственно на линзу. Когда работа над проектом Orion только начиналась, появилось понимание, что для достижения уровня производительности, к которому стремился Марк Цукерберг, потребуются специальные чипы. Их предполагали устанавливать не только на устройства линейки Orion, но и на очки следующего поколения Apollo. В какой-то момент обсуждался вопрос и о разработке процессора для гарнитуры виртуальной реальности Quest, но от этой идеи отказались, как и от идеи выпустить собственный чип для умных часов. Разработкой чипов для носимых устройств занималось подразделение Silicon. Инженеры занимались созданием трёх отдельных типов процессоров: один для «шайбы», то есть внешнего вычислительного блока очков; второй для установки непосредственно в корпус очков для выполнения функции распознавания изображений; и третий также для установки в корпус очков. Эти проекты носили названия соответственно Armstrong, Avogadro и Acropolis. Планировалась также разработка чипов управления питанием, но в компании отказались и от этого. Не исключено, что наработки проекта будут использоваться в перспективе, хотя известно, что несколько десятков сотрудников подразделения Silicon с минувшего октября были уволены — его реорганизация продолжается по сей день, и, вероятно, в отделе останутся лишь «несколько ключевых людей». Некоторые сложности в разработке собственных процессоров Meta✴ для систем генеративного ИИ сохраняются и по сей день, сообщает Reuters. Google Meet запускает ИИ-функцию автоматического конспектирования совещаний и онлайн-встреч
28.08.2024 [07:45],
Анжелла Марина
В приложении Google Meet появилась новая функция, основанная на искусственном интеллекте, которая автоматизирует процесс ведения заметок во время онлайн-встреч. Функция «Take Notes for Me» (Записывай заметки за меня) уже доступна для пользователей Google Workspace. 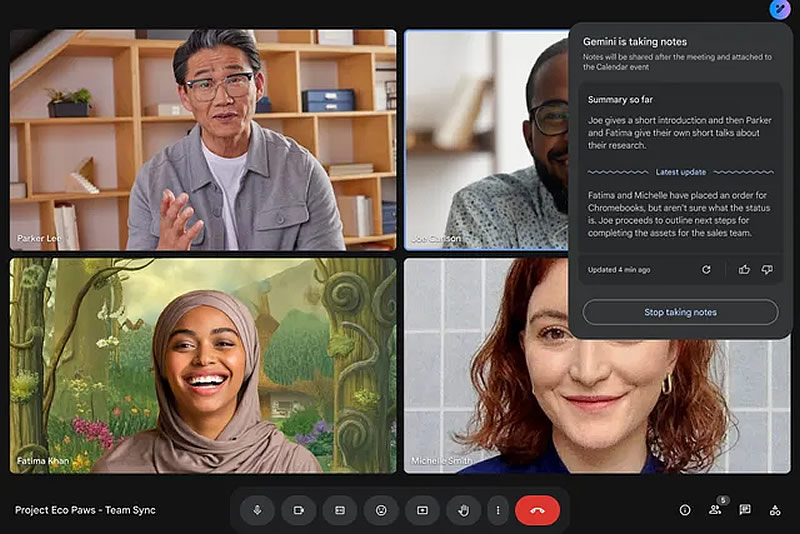
Источник изображения: Google Впервые анонсированная в 2023 году функция Take Notes for Me — это не просто транскрипция речи, подобная инструменту Google Meet, а функция, основанная искусственном интеллекте, которая анализирует разговор, выделяет ключевые моменты и создаёт краткое изложение всего, что было сказано на встрече. Как отмечает The Verge, это обещает значительно упростить жизнь тем, кто пропустил важную встречу или испытывает трудности с одновременным восприятием информации и ведением конспектов. Take Notes for Me автоматически создаёт заметки в Google Docs и прикрепляет их к событию в календаре после завершения встречи, что позволит легко ознакомиться с ключевыми моментами. Кроме того, отправляется файл Google Docs организатору встречи и всем участникам, которые включили эту функцию. «Даже если вы опоздали на совещание, Take Notes for Me предоставит краткое резюме того, что вы пропустили, чтобы можно было быстро войти в курс дела», — подчеркнули в Google. Функция также будет включать ссылки на записи и транскрипции встречи, если опция была включена. Для людей, испытывающих трудности с одновременным восприятием устной речи и ведением заметок, новая функция может стать настоящим спасением. Она позволит сконцентрироваться на обсуждении и быть более вовлечёнными в процесс, не отвлекаясь на конспектирование. Например, для людей с нарушениями слуха или трудностями обработки информации, Take Notes for Me может значительно повысить доступность и эффективность участия в видеоконференциях, так как вместо постоянного напряжения и попыток уловить детали, люди смогут сосредоточиться на содержании обсуждения, полагаясь на автоматически сгенерированные заметки. Функция уже доступна для пользователей Google Workspace с подпиской Gemini Enterprise, Gemini Education Premium или AI Meetings & Messaging, однако к 10 сентября 2024 года Take Notes for Me будет доступен для всех пользователей Google Workspace, правда пока только на английском языке. Threads тестирует исчезающие публикации — они будут жить всего 24 часа
25.08.2024 [13:43],
Владимир Фетисов
Принадлежащий Meta✴ Platforms сервис микроблогов Threads продолжает развиваться и получать новые функции. На этот раз стало известно о скором запуске функции, позволяющей пользователям размещать посты, которые вместе с ответами на них будут исчезать спустя 24 часа с момента публикации. В компании подтвердили, что в настоящее время упомянутая функция тестируется с привлечением ограниченного числа пользователей Threads. 
Источник изображения: Threads Информация об интеграции поддержки исчезающих сообщений появилась через несколько месяцев после того, как глава Instagram✴ Адам Моссери (Adam Mosseri) сообщил, что разработчики Threads экспериментируют с функцией автоматического архивирования. Эта опция позволяет пользователям указать дату, начиная с которой их сообщения будут автоматически скрыты из ленты. Однако пользователи сервиса в основном отзывались об этом нововведении отрицательно, из-за чего автоматическое архивирование до сих пор не получило широкого распространения. Вероятно, в компании посчитали, что исчезающие сообщения аудитория встретит лучше. Напомним, в начале этого месяца пользовательская база Threads превысила отметку в 200 млн человек по всему миру. Не так давно разработчики платформы представили инструмент аналитики под названием Insights, который будет особенно полезен людям с большим количеством подписчиков. Вместе с этим Meta✴ анонсировала функцию отложенных публикаций, которая позволит пользователям создавать посты заранее и устанавливать дату и время, когда они должны стать видимы другим пользователям. Meta✴ прикрыла разработку конкурента Apple Vision Pro — VR-гарнитура получалась слишком дорогой
23.08.2024 [22:00],
Николай Хижняк
Компания Meta✴ отказалась от разработки передовой гарнитуры виртуальной реальности, которая должна была составить конкуренцию AR-гарнитуре Apple Vision Pro. Об этом сообщает издание The Information со ссылкой на осведомлённые источники. Причиной отказа от разработки называется потенциальная стоимость подобной гарнитуры — она была бы слишком высокой, чтобы устройство хорошо продавалось. 
Источник изображения: Meta✴ «По словам двух сотрудников Meta✴ Platforms, компания отказалась от планов разработки премиальной гарнитуры смешанной реальности, которая должна была составить конкуренцию Apple Vision Pro. Компания Meta✴ на этой неделе после встречи топ-менеджеров, на которой присутствовали глава компании Марк Цукерберг (Mark Zuckerberg), технический директор Эндрю Босворт (Andrew Bosworth), а также другие исполнительные лица, поручила сотрудникам её отдела Reality Labs (занимается разработками технологий дополненной и виртуальной реальности, — прим. ред.) прекратить разработку нового устройства. Премиальная гарнитура носила кодовое имя La Jolla. Её разработка началась в ноябре прошлого года. Согласно информации одного из сотрудников компании, устройство планировалось выпустить в 2027 году. Гаджет должен был оснащаться высококлассными дисплеями micro-OLED сверхвысокого разрешения. Та же технология экранов используется в гарнитуре Apple Vision Pro», — пишет The Information. Очень высокая стоимость дисплеев micro-OLED стала одной из причин высокой стоимости всей гарнитуры в целом. Meta✴ хотела сохранить цену на премиальное устройство ниже $1000, однако это оказалось невозможным из-за высокой стоимости использующихся в ней компонентов. По мнению компании, ценовой диапазон «до $1000» является важным условием для того, чтобы обеспечить хорошие продажи такого устройства. В публикации The Information не уточняется, относится ли сумма $1000 к стоимости компонентов или же к целевой цене продажи гарнитуры. В любом случае гарнитура Meta✴ всё равно оказалась бы намного дешевле Vision Pro от Apple, которая продаётся за $3499. Apple не делится цифрами продаж Vision Pro, но, похоже, дела у их гарнитуры идут не лучшим образом. Как пишет портал 9to5Mac, ранее стали ходить разговоры, что Apple отказалась от разработки Vision Pro 2 и вместо этого решила создать более дешёвую версию первого поколения Vision. Также сообщается, что Meta✴ по-прежнему ведёт разработку VR-гарнитуры Quest 4 и планирует её выпустить в 2026 году. Цена этого устройства должна составить $500, то есть остаться такой же, как у актуальной модели Quest 3. В коде Threads нашли следы механизма размещения рекламы, но монетизации на платформе пока не будет
23.08.2024 [17:20],
Павел Котов
Несколько разработчиков и специалистов по обратному проектированию обнаружили в коде приложения Threads ссылки на рекламные продукты, включая упоминание самого слова «реклама» (ads), а также ссылки на спонсируемые публикации и настройку рекламы. В администрации ответственной за службу микроблогов платформы Instagram✴ заявили, что тестирование рекламы в Threads пока не проводится, и запуск монетизации не планируется. 
Источник изображения: Julio Lopez / unsplash.com Несколько разработчиков обнаружили в пакете приложения Threads ссылки на рекламные механизмы на платформе. В частности, Крис Мессина (Chris Messina), нашёл файл JSON с именем «bcn_single_image_ad» и ссылкой на образец рекламного блока. Исследователь приложений Алессандро Палуцци (Alessandro Paluzzi) даже смог сделать так, что одна из его публикаций стала отображаться как спонсируемая — соответствующая пометка появилась рядом с именем пользователя в Threads. 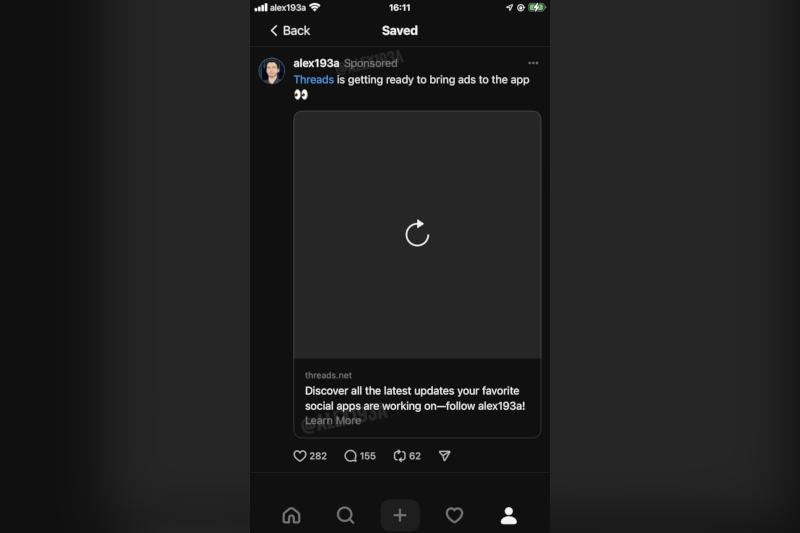
Источник изображения: x.com/alex193a Это указывает, что инженеры Threads исследуют рекламные технологии, но не значит, что реклама на платформе появится уже в ближайшее время. «В настоящее время мы не тестируем рекламу в Threads, и конкретные сроки [запуска] монетизации не установлены», — заявил ресурсу TechCrunch представитель Instagram✴ Алек Букер (Alec Booker). Это согласуется с заявлением инвесторам, которое ранее сделал глава Meta✴ Марк Цукерберг (Mark Zuckerberg): сначала платформе необходимо улучшить основы функций для пользователей, предпринять усилия по удержанию людей и максимально расширить аудиторию, после чего начать работу над монетизацией. Threads постепенно обрастает новыми возможностями: кросспостинг из Instagram✴, аналитика аудитории и многое другое. Представлено 800-долларовое VR-кресло Roto VR Explorer для гарнитуры Meta✴ Quest
15.08.2024 [11:34],
Павел Котов
Лондонская фирма Roto VR предложила решение для эмуляции движения в виртуальном пространстве — вращающееся кресло Explorer за $799. Это первый продукт подобного рода, получивший маркировку «Сделано для Meta✴» (Made for Meta✴). 
Источник изображений: rotovr.com Установка разработана для приложений и игр, требующих 360-градусного обзора в виртуальном пространстве — производитель уверяет, что ему удалось решить проблему укачивания. Вероятно, дело в том, что движения кресла синхронизированы с тем, что видят глаза пользователя, и вероятность получить неприятные ощущения невелика — они могут возникать из-за разрыва связи между мозгом и телом.  Выглядит Roto VR Explorer как стандартное вращающееся кресло на колёсиках, но отличается многоуровневой спинкой и отдалённо напоминающим компас массивным основанием. Для дополнительного ощущения погружения система оборудована тактильной обратной связью, кроме того, Roto пообещала выпустить модульные аксессуары для некоторых из более чем четырёхсот игр, с которыми совместима установка. Компания была основана в 2015 году британским предпринимателем Эллиоттом Майерсом (Elliott Myers) — в её руководстве состоят опытные специалисты в области игр, технологий и инженерного дела. Предварительные заказы на кресло Roto VR Explorer принимаются уже сейчас, а поставки начнутся, как ожидается, в октябре 2024 года. Цукерберг рассказал, как Meta✴ планирует зарабатывать с помощью ИИ
01.08.2024 [19:22],
Павел Котов
Финансовые результаты Meta✴ за II квартал подтверждают тренд, установленный кварталом ранее: технологии генеративного искусственного интеллекта уже начали работать, но потребуется много времени, чтобы они стали приносить деньги. 
Источник изображения: Mark Zuckerberg Meta✴ выгодно отличается от большинства игроков в области ИИ тем, что уже зарабатывает много денег. По итогам минувшего квартала её доход составил $39 млрд (годовой рост на 22 %), а прибыль — $13,5 млрд (+73 %); 3,27 млрд человек пользуются хотя бы одним из приложений Meta✴ каждый день. При этом финансовая отдача от вложений компании в ИИ ожидается «в течение более длительного периода времени», призналась финансовый директор компании Сьюзан Ли (Susan Li) на брифинге по случаю квартального отчёта. «Непросто предсказать, как это станет выглядеть через несколько поколений в будущем, но на данный момент я бы предпочёл рискнуть и нарастить мощности до того, как они понадобится, а не когда будет поздно», — пояснил на том же мероприятии гендиректор Meta✴ Марк Цукерберг (Mark Zuckerberg). Он снова выразил уверенность, что ИИ-помощник Meta✴ AI уже до конца года сможет стать самым используемым в мире — генеративный ИИ, по его мнению, повысит вовлечённость пользователей в продукты компании, но деньги будут поступать от бизнес-кейсов: от создания рекламы с нуля и ИИ-агентов для обслуживания клиентов в WhatsApp. Meta✴ уже готовится к обучению большой языковой модели Llama 4 — она выйдет в следующем году, и Цукерберг хочет сделать её «самой продвинутой» в отрасли. Но и вычислительных мощностей для неё потребуется почти в десять раз больше, чем для последней Llama 3.1. Глава Meta✴ ничего не сказал о намерении инвестировать в EssilorLuxottica, но успех очков Meta✴ Ray-Ban второго поколения его вдохновил, и компания продолжает работать над «будущими поколениями очков с ИИ». Вопрос метавселенной по сравнению с ИИ отошёл на второй план, но Цукерберг упомянул, что продажи Quest 3 превосходят ожидания компании. И, как сообщают неофициальные источники, на мероприятии Connect будет анонсирована более дешёвая версия гарнитуры. В начале июля стало известно, что аудитория платформы микроблогов Threads достигла 175 млн пользователей — сейчас этот показатель приближается к 200 млн, заявил глава компании. Стал также отмечаться рост аудитории Facebook✴, причём теперь обеспечивает его, вопреки стереотипам, молодёжь. Отчёт Meta✴ дал надежду, что гигантские траты бигтехов на ИИ оправдаются
01.08.2024 [16:29],
Павел Котов
Meta✴ опубликовала отчёт, согласно которому её финансовые показатели по итогам II квартала 2024 года превзошли оценки аналитиков. Выше ожидаемых оказались выручка, доходы и прогноз компании на наступивший квартал. 
Источник изображения: Mark Zuckerberg Выручка Meta✴ во II квартале 2024 года составила $39,07 млрд против ожидаемых аналитиками $38,31 млрд, что соответствует росту на 22 % в годовом выражении — уже четвёртый квартал подряд компания демонстрирует рост дохода более чем на 20 %. Прибыль компании составила $13,47 млрд или $5,16 на акцию, в то время как аналитики предсказывали $4,73 на акцию — это соответствует росту на 73 %: во II квартале прошлого года прибыль Meta✴ была $7,79 млрд или $2,98 на акцию. Согласно собственному прогнозу компании, выручка в III квартале окажется в диапазоне от $38,5 млрд до $41 млрд (в среднем $39,75) — аналитики ожидали прогноза в районе $39,1 млрд. Положительные результаты Meta✴ указывают, что она продолжает наращивать долю на рынке цифровой рекламы, составляющем основной бизнес компании. Рекламная выручка, которая поступает преимущественно от платформ Facebook✴ и Instagram✴, показала годовой рост на 22 %. На минувшей неделе Alphabet отчиталась о росте рекламных продаж Google на 11 %, тогда как YouTube ожиданий аналитиков не оправдал. Издержки Meta✴ во II квартале составили $24,2 млрд — сюда же вошло урегулирование техасского дела о несанкционированном использовании данных алгоритмом распознавания лиц, которое обошлось компании в $1,4 млрд. Капитальные затраты за II квартал составили $8,47 млрд, что ниже ожидаемых аналитиками $9,51 млрд. Meta✴ оставила в силе прогноз по величине издержек на 2024 год на уровне $96–99 млрд; прогноз капитальных затрат в $35 млрд был повышен до диапазона $37–40 млрд. Число ежедневно активных людей (Daily Active People — DAP), то есть пользователей, открывших хотя бы одно из приложений компании, достигло 3,27 млрд, что соответствует оценкам аналитиков. 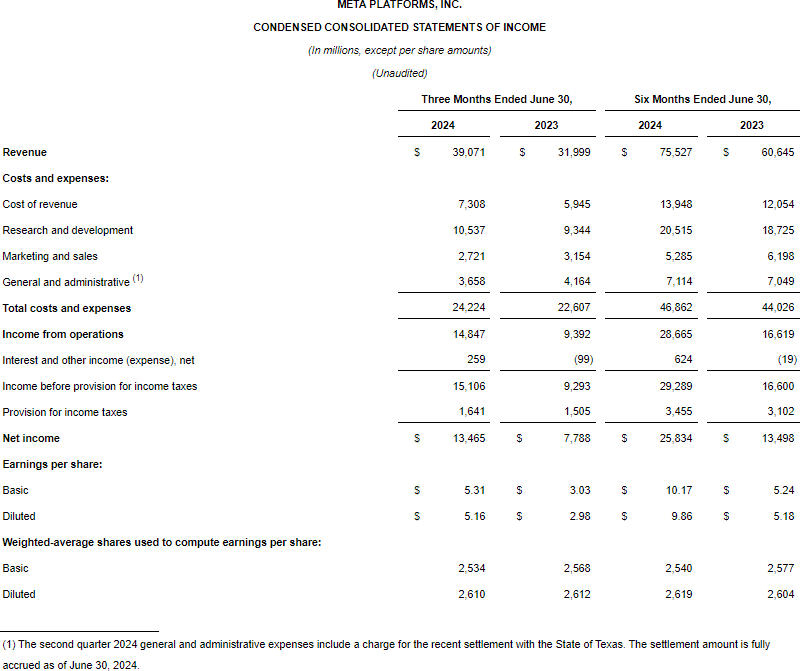
Источник изображения: Meta✴ Гигант соцсетей продолжает реализовывать программу по сокращению расходов, о которой объявил ещё в конце 2022 года. В ходе нескольких раундов увольнений были ликвидированы в общей сложности около 21 000 рабочих мест. Операционный доход вырос на 58 % год к году и достиг $14,9 млрд; операционная маржа за тот же период выросла с 29 % до 38 %. Численность персонала в годовом исчислении сократилась на 1 % и по состоянию на 30 июня составила 70 799 человек. При этом Meta✴ продолжает вкладывать значительные средства в передовые технологии, такие как искусственный интеллект и виртуальная реальность — они необходимы для построения метавселенной. Компания инвестирует в центры обработки данных и вычислительные ресурсы для противостояния конкурентам. В 2025 году ожидается значительный рост капитальных затрат из-за вложений в поддержку исследований и разработку продукции. К концу года в распоряжении Meta✴, по словам её гендиректора Марка Цукерберга (Mark Zuckerberg), будут 350 000 передовых ускорителей систем искусственного интеллекта Nvidia H100 или 600 000, если считать по аналогии оборудование других моделей и производителей. Недавно компания представила крупное обновление больших языковых моделей Llama 3.1 — самая мощная имеет 405 млрд параметров. С начала года акции Meta✴ демонстрировали рост на 34 %; после публикации отчёта они дополнительно прибавили на 6,9 %. Meta✴ продолжает терять деньги на виртуальной реальности: квартальный убыток Reality Labs — $4,48 млрд
01.08.2024 [14:31],
Николай Хижняк
Амбициозные планы Meta✴ по развитию метавселенной по-прежнему обходятся компании в миллиарды долларов. В последнем финансовом отчёте за второй квартал подразделение Reality Labs компании Meta✴, занимающееся разработками технологий дополненной и виртуальной реальности, сообщило об операционных убытках в размере $4,48 млрд. Аналитики отрасли прогнозировали, что убытки этого подразделения составят $4,55 млрд. 
Источник изображения: Meta✴ Как сообщает издание CNBC, с конца 2020 года совокупные убытки подразделения Reality Labs превысили $50 млрд, что подчеркивает огромные инвестиции генерального директора Марка Цукерберга (Mark Zuckerberg) в разработку нового аппаратного и программного обеспечения, которые, по его словам, лягут в основу следующей эры персональных компьютеров. Выручка Reality Labs во втором квартале, в основном полученная от продаж семейства VR-гарнитур Quest и умных очков Ray-Ban Meta✴, составила $353 млн, что на 28 % больше, чем годом ранее ($276 млн) за тот же отчётный период. Аналитики ожидали, что подразделение принесет прибыль в размере $371 млн. В сентябре Meta✴ представила VR-гарнитуру Quest 3 стоимостью $499. Несколько месяцев спустя Apple выпустила премиальную гарнитуру смешанной реальности Vision Pro стоимостью $3500. В июне Apple начала поставки Vision Pro в Китай, где её розничная цена начинается от 29 999 юаней или $4141. Поскольку рынок VR-устройств ещё только зарождается, Meta✴ всё активнее продвигает умные очки, которые она разрабатывает совместно с компанией Ray-Ban. Марк Цукерберг считает, что последние достижения в области искусственного интеллекта и связанных с ним больших языковых моделей являются основной для улучшения возможностей умных очков. В июле генеральный директор материнской компании Ray-Ban EssilorLuxottica Франческо Миллери (Francesco Milleri) сообщил, что Meta✴ планирует стать акционером европейского производителя очков и расширить партнёрство между двумя компаниями, начавшееся в 2020 году. Второе поколение умных очков Meta✴ стоимостью $299 поступило в продажу в октябре прошлого года. В апреле текущего года Цукерберг в разговоре с аналитиками заявил о возможности появления рынка «для модных очков с искусственным интеллектом, не оснащающихся цифровым дисплеем». |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2025 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться