
Опрос
|
реклама
Быстрый переход
Представлен ПК для аудиофилов за €28 000 — оперативная память с «лучшим качеством звука», два Intel Xeon и пассивное охлаждение
10.12.2024 [16:51],
Павел Котов
Нидерландский производитель высококачественного аудиооборудования Taiko Audio представил безвентиляторный музыкальный сервер Extreme, предназначенный для хранения аудиофайлов в форматах без потери качества, а также потоковой трансляции с помощью таких сервисов как Tidal. Его цена начинается от €28 000 за вариант с накопителем на 2 Тбайт. 
Источник изображений: taikoaudio.com Компьютер комплектуется двумя процессорами Intel Xeon Scalable с пассивной системой охлаждения на 240 Вт, которая гарантирует ему бесшумную работу. Два процессора позволяют ему использовать выделенные подсистемы для самостоятельных процессов — один чип отвечает за пользовательский интерфейс на базе Windows 10 Enterprise LTSC 2019, из которой исключили всё кроме необходимого для прослушивания музыки; второй — за работу музыкального менеджера Roon.  Для работы операционной системы используется SSD Intel Optane ёмкостью 280 Гбайт, а для хранения данных предусмотрен накопитель на 2 Тбайт, который за дополнительные €1850 можно расширить до 64 Тбайт. Объем оперативной памяти составляет 48 Гбайт — и это 12 планок по 4 Гбайт, потому что «меньший объём и низкая скорость DIMM лучше для качества звука».  За качество звука здесь отвечает и специальный блок питания мощностью 400 Вт на конденсаторах Mundorf и Duelund, которые, по версии производителя, не оказывают влияния на звучание. Для подключения внешних устройств предусмотрены пять портов USB, два медных порта Ethernet, оптический SFP, разъём VGA, порт S/PDIF, и один порт AES/EBU в двух- или четырёхканальной конфигурации.  Nvidia представила ИИ-модель Fugatto, которая «понимает и генерирует звук, как это делают люди»
25.11.2024 [18:33],
Сергей Сурабекянц
Nvidia представила новую экспериментальную генеративную модель ИИ, которую компания описывает как «швейцарский армейский нож для звука». Модель Fugatto (Foundational Generative Audio Transformer Opus 1) использует текстовые подсказки для генерации новых или изменения существующих музыкальных, голосовых и звуковых файлов. В создании модели принимали участие разработчики со всего мира, что усилило «многоакцентные и многоязычные возможности модели». 
Источник изображения: Nvidia «Мы хотели создать модель, которая понимает и генерирует звук, как это делают люди», — рассказал участник проекта и менеджер по прикладным исследованиям звука в Nvidia Рафаэль Валле (Rafael Valle). Компания предложила несколько сценариев, в которых модель Fugatto может оказаться востребованной:
Исследователи утверждают, что модель при некоторой дополнительной тонкой настройке также может выполнять задачи, не входившие в её предварительное обучение. Модель может объединять отдельные инструкции, например, генерировать речь с определёнными интонациями и акцентом или звук пения птиц во время грозы. Модель также умеет генерировать изменяющиеся со временем звуки, например, шум приближающегося ливня или удаляющегося поезда. Fugatto не является первой технологией генеративного ИИ, которая может создавать звуки из текстовых подсказок. Ранее Meta✴ выпустила аналогичную модель ИИ с открытым исходным кодом. Google предлагает ИИ-инструмент собственной разработки для преобразования текста в музыку MusicLM, доступ к которому можно получить через сайт компании AI Test Kitchen. Nvidia пока не предоставила публичный доступ к Fugatto и воздержалась от комментариев на этот счёт. Adobe показала проект Super Sonic для создания звуковых эффектов для видео при помощи ИИ
15.10.2024 [18:05],
Сергей Сурабекянц
На ежегодной конференции Max компания Adobe продемонстрировала экспериментальный проект Super Sonic — прототип программного обеспечения на основе ИИ, которое может превращать текст в аудио, распознавать объекты и голос автора для быстрого создания звуковых эффектов и фонового аудио для видеопроектов. 
Источник изображения: Adobe «Мы хотели дать нашим пользователям контроль над процессом, […] выйти за рамки первоначального рабочего процесса преобразования текста в звук, и именно поэтому мы работали над таким аудиоприложением, которое действительно даёт вам точный контроль над энергией и синхронизацией и превращает его в выразительный инструмент», — рассказал руководитель отдела ИИ Adobe Джастин Саламон (Justin Salamon). Super Sonic использует ИИ для распознавания объектов в любом месте видеоряда, чтобы создать запрос и сгенерировать нужный звук. В другом режиме инструмент анализирует различные характеристики голоса и спектр звука и использует полученные данные для управления процессом генерации. Пользователю необязательно использовать голос, можно хлопать в ладоши, играть на инструменте или извлекать исходный звук любым другим доступным способом. Стоит отметить, что на конференции Max компания Adobe традиционно представляет ряд экспериментальных функций. В дальнейшем многие из них попадают в Adobe Creative Suite. Super Sonic может стать полезным дополнением, например, к Adobe Premiere, но пока дальнейшие перспективы проекта неясны, и он остаётся в статусе демонстрационной версии. Ранее разработчики Super Sonic участвовали в разработке функции генеративного ИИ Firefly под названием Generative Extend, которая позволяла удлинять короткие видеоклипы на несколько секунд, включая звуковую дорожку. Возможность создавать звуковые эффекты из текстового запроса или голоса — полезная функция, но далеко не новаторская. Многие компании, такие как ElevenLabs, уже предлагают подобные коммерческие инструменты. Представлена технология DTS Clear Dialogue, которая повысит чёткость диалогов в фильмах и сериалах
04.09.2024 [13:49],
Павел Котов
У любителей домашнего просмотра кино и сериалов иногда возникают жалобы на то, что диалоги персонажей звучат слишком тихо — они просто теряются на фоне звуковых эффектов и музыкального сопровождения. Решение проблемы предложила компания DTS, представившая технологию Clear Dialogue. 
Источник изображения: Mohamed Hassan / pixabay.com Функция DTS Clear Dialogue представляет собой «основанное на искусственном интеллекте решение, разработанное для повышения чёткости разговорных диалогов на телевизорах». Предложенный компанией алгоритм ИИ распознаёт и усиливает диалоги в звуковых потоках, избавляя любителей домашнего видео от попыток решить эту проблему изменением настроек звука, положения звуковой панели или даже включением субтитров. Система DTS Clear Dialogue позволяет даже персонализировать настройки звука, потому что идеальное звучание для одного человека не всегда оказывается таковым для другого. DTS Clear Dialogue представляет собой пакет инструментов для конечного устройства, то есть его поддержкой придётся озаботиться производителям телевизоров. Компания пока не сообщила, кто будет пользоваться новым решением, но среди её партнёров числятся такие марки как Sony, Hisense, Philips и LG. Работу системы Clear Dialogue компания DTS намеревается продемонстрировать на выставке IFA в Берлине. YouTube научился удалять из видео защищённую авторским правом музыку с сохранением остального звука
05.07.2024 [16:33],
Павел Котов
Сервис YouTube выпустил обновлённый инструмент удаления музыки, защищённой авторским правом — функция основана на алгоритме искусственного интеллекта, который выполняет задачу, не затрагивая всего остального, в том числе диалогов и звуковых эффектов. 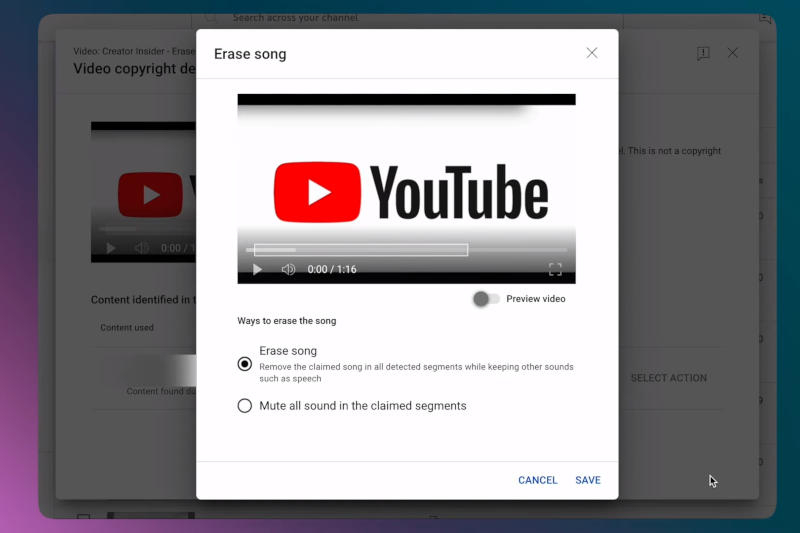
Источник изображения: youtube.com/@creatorinsider Гендиректор YouTube Нил Мохан (Neal Mohan) рассказал о нововведении в соцсети X: «Хорошие новости, авторы: наш обновлённый инструмент „Стереть песню“ (Erase Song) поможет вам легко удалить защищённую авторским правом музыку из вашего видео (оставив остальную часть аудио нетронутой)». Функция работает на основе алгоритма ИИ, который самостоятельно обнаруживает и удаляет композицию, не затрагивая остальной звук на ролике, предупредила администрация YouTube и добавила, что иногда алгоритм всё-таки даёт сбой и удаляет некоторые другие элементы аудио. «Это средство редактирования может не сработать, если песню сложно удалить. Если он не удаляет фрагмент аудио, вы можете попробовать другие варианты редактирования, например, отключить весь звук в указанных сегментах или вырезать эти сегменты», — говорится в анонсе новой функции. После успешного редактирования видео платформа снимает отметку идентификатора контента — системы, которая обнаруживает в загружаемых материалах защищённое авторским правом содержимое. Qualcomm представила чипы Snapdragon S5 Gen 3 и S3 Gen 3 с ИИ для беспроводных наушников
27.03.2024 [00:06],
Николай Хижняк
Компания Qualcomm представила два новых чипа среднего и начального уровня для беспроводных наушников — Qualcomm S5 Gen 3 и Qualcomm S3 Gen 3. Они пришли на замену чипам S5 Gen 2, которые вышли в 2022 году. Обе новинки обладают более высокой вычислительной производительностью. Чип Qualcomm S5 Gen 3 предлагает расширенные ИИ-возможности для улучшения звука. 
Источник изображений: Qualcomm В составе чипа Qualcomm S5 Gen 3 используется процессор с частотой 200 МГц (CPU у Gen 2 работал на частоте 80 МГц), а также новый цифровой сигнальный процессор DSP с частотой 350 МГц (у предшественника был двойной DSP с частотой 240 МГц). Кроме того, новый чип оснащён в 1,5 раза большим объёмом памяти по сравнению с предшественником. Ранее ИИ-вычисления в составе звукового процессора проводились с помощью DSP. И хотя новый DSP в составе Qualcomm S5 Gen 3 быстрее, чем у предшественника, новый чип также получил отдельный ИИ-ускоритель, обеспечивающий прирост вычислительной производительности в 50 раз. На него могут возлагаться такие задачи, как работа активной системы шумоподавления (ANC) и обработка голоса. Дополнительно в составе Qualcomm S5 Gen 3 присутствуют модули для компенсации потери слышимости, работы режима прозрачности, а также фильтр шумов.  Для флагманского сегмента беспроводных наушников Qualcomm рекомендует использовать звуковые чипы S7 и S7 Pro. Они предлагают ещё больше ИИ-функций улучшений звука и работают примерно вдвое быстрее, чем S5 Gen 3. Кроме того, они оснащены более быстрыми CPU и DSP. Для начального сегмента устройств компания представила звуковой чип Qualcomm S3 Gen 3. Он по-прежнему оснащён двуядерным CPU с частотой 80 МГц, однако получил вместо одного двойной DSP с частотой 240 МГц. Здесь также заявляется поддержка технологий Qualcomm AI, но без мощного ускорителя. Несмотря на бюджетность решения чип предлагает поддержку таких функций, как Google Fast Pair, Qualcomm TrueWireless Mirroring, Auracast и других. Qualcomm S5 Gen 3 и S3 Gen 3 очень энергоэффективные. Они могут транслировать музыку с помощью A2DP при энергопотреблении всего 4 мА. Поддержка технологии Snapdragon Sound позволяет им передавать звук в качестве 24 бит/48 кГц. Samsung расширит аудиовозможности смартфонов, планшетов и телевизоров
20.02.2024 [16:49],
Павел Котов
Samsung рассказала о развёртывании новых технологий звука Auracast, 360 Audio и Auto Switch на своих устройствах. В той или иной мере они поддерживались и ранее, но сейчас производитель расширит их присутствие. Компания сообщила, что с конца февраля начнут выходить соответствующие обновления для наушников Samsung Galaxy Buds 2, Buds FE и Buds 2 Pro. 
Источник изображения: samsung.com Основанная на протоколе Bluetooth технология Auracast позволяет одному устройству транслировать звуковой поток на теоретически неограниченное количество приёмников — наушников и динамиков. В прошлом году Samsung объявила о поддержке этой технологии наушниками Galaxy Buds 2 Pro и новейшими моделями телевизоров; она присутствует и на смартфонах серии Galaxy S24. Теперь компания расширила список устройств, которые смогут выступать источниками или приёмниками Auracast. Транслировать звук с Auracast смогут устройства под управлением Samsung One UI 6.1 и выше: смартфоны Galaxy S23, Z Fold 5, Z Flip 5 и планшеты Tab S9. В роли приёмников Auracast смогут также выступать устройства под One UI 5.1.1, то есть к вышеперечисленным добавятся смартфоны Samsung Galaxy Z Fold 4, Z Flip 4, A54 5G, M54 5G, а также планшеты Tab S9 FE и Tab Active 5 5G. Наушники Samsung Galaxy Buds получат поддержку функции ИИ-перевода, дебютировавшей на смартфонах серии Galaxy S24: переведённый телефоном звуковой поток будет транслироваться на наушники, а собеседник сможет услышать перевод через динамик телефона. Расширится присутствие технологии пространственного звука (360 Audio) — её поддержку получат телевизоры Neo QLED и OLED. До настоящего времени она поддерживалась некоторыми смартфонами и планшетами Samsung, а работает она с наушниками Galaxy Buds 2 Pro и Buds 2. Samsung также напомнила о технологии Auto Switch, которая при поступлении входящего вызова переключает Bluetooth-соединение Galaxy Buds 2 Pro от планшета или телевизора на телефон. Теперь функция будет доступна на ноутбуках Galaxy Book с Samsung One UI 6.0. ElevenLabs обучила ИИ создавать звуковые эффекты для видео
20.02.2024 [13:45],
Павел Котов
На минувшей неделе OpenAI представила модель искусственного интеллекта Sora, обученную генерировать реалистичные видеоролики по текстовому описанию. Стартап ElevenLabs предложил собственное решение Sound Effects для наложения звуковых эффектов на такие ролики. 
Источник изображения: youtube.com/@elevenlabsio Компанию ElevenLabs основали в 2022 году бывший инженер Google по машинному обучению Пётр Дабковски (Piotr Dabkowski) и бывший специалист Palantir по стратегии внедрения Мати Станишевски (Mati Staniszewski). Компания выпустила модель по преобразованию текста в речь и дублированного перевода на 20 языков с сохранением оригинального тона и тембра голоса. Новый проект ElevenLabs получил название Sound Effects — он предназначается для создания звуковых эффектов для лишённых звука видеороликов; звук генерируется по текстовому описанию. Работу очередной ИИ-модели компания продемонстрировала на примере роликов, созданных нейросетью OpenAI Sora. Для этого использовались простые описания вроде «шум волн», «звон металла», «чириканье птиц» и «двигатель гоночной машины». ElevenLabs не раскрыла технических подробностей, касающихся работы ИИ-системы, но результаты работы новой модели вполне убедительны — фоновые звуки получились реалистичными: городской шум, шаги на оживлённой улице, сигналы человекоподобного робота и закадровый текст, который как будто читает голливудский актёр. Компании ещё предстоит рассказать, как она планирует защитить свой проект от попыток недобросовестного использования — ElevenLabs Sound Effects может заинтересовать мошенников. Учёные придумали, как воровать отпечатки пальцев по звукам свайпов на смартфоне
20.02.2024 [10:54],
Павел Котов
Группа американских и китайских учёных разработала методику PrintListener, которая позволяет восстанавливать рисунок папиллярных линий, составляющий отпечаток человеческого пальца, посредством анализа звука, который он производит при свайпе, то есть скользящем движении по сенсорному экрану. 
Источник изображения: Lukenn Sabellano / unsplash.com Технология защиты систем при помощи отпечатков пальцев сегодня широко распространена и пользуется большим доверием — если она продолжит расти с теперешними темпами, то к 2032 году рынок решений в области аутентификации по отпечаткам пальцев достигнет почти $100 млрд. При этом растёт осознание, что злоумышленники могут предпринимать попытки кражи отпечатков пальцев, и люди всё реже показывают руки на фотографиях. Как выяснилось, источником утечки данных может оказаться звук скользящего движения пальца по сенсорному дисплею. По итогам испытаний учёные добились успеха с использованием «до 27,9 % частичных и 9,3 % полных отпечатков пальцев с пяти попыток при настройках безопасности AR [False Acceptance Rate] в 0,01 %». Для проведения атаки подобным образом гипотетическому злоумышленнику необходимо получить доступ ко включённому на мобильном устройстве микрофону, а жертве — в штатном режиме поработать с популярными приложениями вроде Discord, Skype, WeChat и FaceTime, где применяются свайпы. Авторам исследования пришлось преодолеть несколько сложностей: проблему слабого звука при трении пальца о сенсорный дисплей решили при помощи методов спектрального анализа; учли физиологические и поведенческие особенности пользователя; применили статистический анализ и разработали эвристический поисковый алгоритм. При помощи технологии звукового анализа PrintListener учёные восстановили синтетические отпечатки PatternMasterPrint, и «в реалистичных сценариях» эта методика помогла успешно восстановить частичные отпечатки пальцев более чем в одном из четырёх случаев, а полные — почти в одном из десяти. Результаты оказались выше, чем атака MasterPrint, предлагающая случайный перебор «универсальных» отпечатков. Samsung выпустит свой аналог Dolby Atmos уже в этом году
23.01.2024 [11:22],
Павел Котов
Компания Samsung сообщила, что разработанная совместно с Google технология пространственного звука IAMF (Immersive Audio Model and Formats) в обозримом будущем станет доступна в её продукции и составит конкуренцию Dolby Atmos. 
Источник изображения: samsung.com Поддержка аудиоформата IAMF появится уже в этом году в продукции Samsung, включая телевизоры и звуковые панели. На существующей продукции она станет доступной с обновлением прошивки, а новые модели будут её поддерживать с начала работы. В отличие от технологии пространственного звука Dolby Atmos, которая предусматривает лицензионные отчисления со всех совместимых устройств, формат IAMF является открытым и не предусматривает никаких выплат Samsung. Корейский производитель пока, однако, не уточнил, какие из его существующих моделей получат поддержку IAMF. Пока неизвестно также, получит ли совместимое оборудование и контент маркировку IAMF — возможно, это было бы оправданное решение, поскольку технология предлагает те же возможности, что и Dolby Atmos. В этом году поддерживающий IAMF контент выйдет также на YouTube, поскольку Google участвовала в разработке технологии совместно с Samsung. Пространственный звук IAMF работает на стандартном оборудовании — при его формировании используются алгоритмы ИИ. Технология поддерживает разделение компонентов звуковой картины: музыки, диалогов и звуковых эффектов; слушателю предоставляется возможность настраивать вывод в соответствии со своими предпочтениями. Bose представила наушники QuietComfort Ultra с виртуальным пространственным звуком
15.09.2023 [21:42],
Сергей Сурабекянц
Bose официально анонсировала наушники QuietComfort Ultra Headphones и QuietComfort Ultra Earbuds, оснащённые продвинутой системой активного шумоподавления (ANC) и новой системой виртуального пространственного звучания Immersive Audio. По утверждению Bose, Immersive Audio делает «пространственный звук доступным для всех», так как не требует специального контента. 
Источник изображений: Engadget Наушники QuietComfort Ultra обеспечивают эффект пространственного звучания при помощи виртуализации и могут работать с любым потоковым сервисом, обеспечивая «акустическую зону наилучшего восприятия» благодаря новому методу цифровой обработки сигнала. Immersive Audio может работать в двух режимах, Still и Motion, названия которых говорят сами за себя и предназначены, соответственно, для прослушивания музыки в кресле или в движении. Эксперты утверждают, что технология Immersive Audio от Bose делает звучание обычного неиммерсивного звукового контента более объёмным и энергичным, добавляя чёткости и детализации, а система шумоподавления довольно эффективно отсекает внешний шум. Immersive Audio можно отключить, вернув классическое звучание от Bose. Дизайн QuietComfort Ultra Headphones совмещает элементы предыдущих моделей линейки QuietComfort и наушников Bose Noise Canceling Headphones 700. Самым большим изменением является оголовье, в котором компания заменила некоторые элементы на металлические, придав им более премиальный вид.  Кардинально изменился регулятор громкости — вместо физических кнопок появилась ёмкостная сенсорная полоса, размещённая на самом краю чашки. Сохранилась физическая многофункциональная кнопка для управления воспроизведением, изменения режимов прослушивания и ответа на звонки. Наушники заряжаются через порт USB Type-C, но прослушивание музыки при проводном подключении возможно лишь через аудиоразъём 3,5 мм. Новая технология Immersive Audio заметно сказывается на времени автономной работы. По данным Bose, при включённом пространственном звуке можно рассчитывать на 18 часов прослушивания и на 24 часа — при отключённом. Данные по автономности компания приводит при использовании ANC. Bose также утверждает, что качество голосового общения через наушники также улучшилось благодаря модернизированным микрофонам и режиму Aware с ActiveSense, определяющему окружающий шумовой фон. Дизайн новых QuietComfort Ultra Earbuds мало изменился: внешняя сенсорная панель стала серебристой. Режим пространственного звучания Immersive Audio заметно влияет на время автономной работы, Earbuds работают до 4 часов при включённом режиме и 6 часов — при отключённом. Bose предлагает дополнительный чехол для беспроводной зарядки новых Earbuds, который обойдётся в $49.  Bose заменила наушники QuietComfort 45 новой моделью QuietComfort с классическим дизайном, активным шумоподавлением и временем автономной работы до 24 часов. Наушники поддерживают многоточечное соединение Bluetooth. Они, как и обе модели Ultra, могут подключаться по протоколу Bose SimpleSync к совместимым звуковым панелям. Все три модели доступны для предварительного заказа уже сегодня и появятся в продаже в начале октября. QuietComfort Ultra Headphones стоят $429, QuietComfort Ultra Earbuds — $299. Наушники QuietComfort поступят в продажу 21 сентября по цене $349. Звук действительно передаётся в вакууме, но совсем не так, как показывают в кино
16.08.2023 [14:29],
Геннадий Детинич
Два финских физика выяснили условия, при которых звук может передаваться через идеальный вакуум. Эффект сродни квантовому туннелированию, но в дело вступает обычная физика и кое-какое оборудование. Открытие может помочь в разработке MEMS-электроники и в системах теплоотвода. 
Источник изображения: Pixabay Жуоран Генг (Zhuoran Geng) и Илари Маасилта (Ilari Maasilta) из Университета Ювяскюля (Финляндия) утверждают, что их работа отражает первое строгое доказательство полного акустического туннелирования в вакууме. Всё, что нужно для эксперимента, — это два пьезоэлектрических датчика, каждый из которых способен превращать звуковые волны в электрическое напряжение (и наоборот). При этом пьезоэлементы должны быть разделены зазором, меньшим, чем длина волны передаваемого звука. В результате звук «перейдёт» от одного элемента к другому с полной силой, если соблюсти необходимые условия. Как мы знаем, для распространения звука необходима среда. Звук передаётся за счёт последовательной передачи колебаний атомов и молекул среды соседним частицам. Непосредственно люди слышат (ощущают) колебания воздуха чувствительной мембраной в ушах. Таких условий, очевидно, нет в чистом вакууме — там нечему колебаться и, следовательно, нечему распространять звуковые волны. Но есть лазейка — в вакууме могут распространяться электромагнитные поля, а это шанс для пьезоэлектрических кристаллов, которые в процессе деформации (под воздействием акустических волн) вырабатывают электричество. А где электричество, там и поля. Учёные использовали в качестве пьезоэлементов оксид цинка. Звуковое колебание создавало механическое напряжение в материале, и это порождало в нём электрическое напряжение и, при определённых условиях, вело к появлению электромагнитного поля. Если в радиусе действия поля первого кристалла находился второй кристалл, то он преобразовывал поле в электрическую энергию и обратно в механическую — фактически в исходный акустический сигнал, который, таким нехитрым (или хитрым) образом преодолевал чистый вакуум. Ширина зазора при этом не должна превышать длины передаваемой звуковой волны. 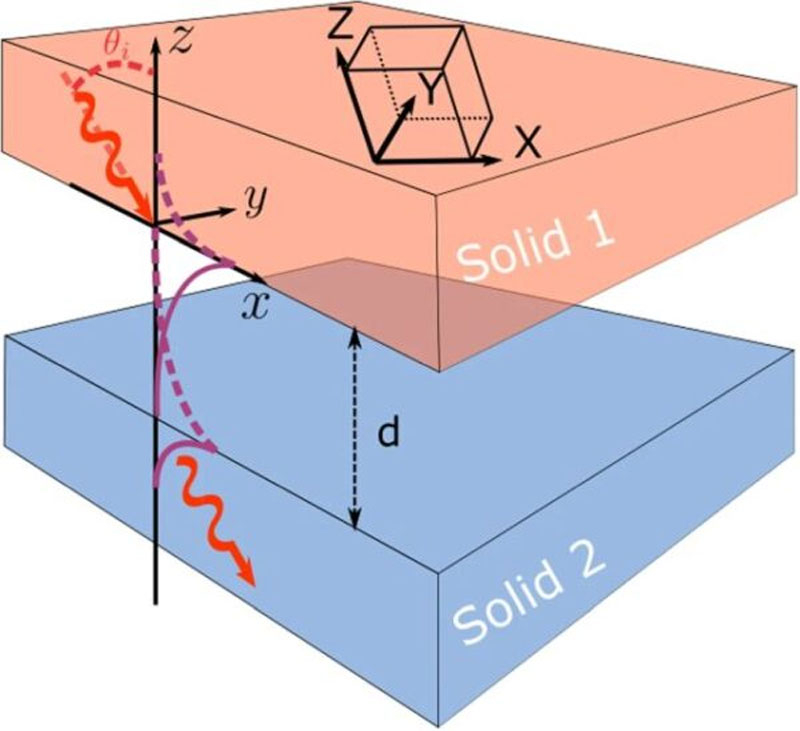
Источник изображения: Geng and Maasilta, Commun. Phys., 2023) Также учёные показали, что эффект не зависит от частоты звука. При соблюдении необходимого зазора он работает и для ультразвука и для сверхзвуковых частот. Обнаруженное явление может использоваться как для практических решений, так и для имитации квантового туннелирования, чтобы помочь в развитии квантовой связи, например. «В большинстве случаев эффект невелик, но мы также обнаружили ситуации, когда полная энергия волны переходит через вакуум со 100 % эффективностью, без каких-либо отражений, — рассказал Маасилта. — Таким образом это явление может найти применение в микроэлектромеханических компонентах (MEMS, технология смартфонов) и в управлении теплом». В последнем случае, очевидно, учёный имеет в виду отвод тепла от приборов, находящихся в вакууме, что может найти применение в космической технике и не только. О самой работе учёные рассказали в статье в журнале Communications Physics. Meta✴ представила AudioCraft — генератор музыки и шума на основе искусственного интеллекта
02.08.2023 [18:29],
Сергей Сурабекянц
Meta✴ представила ИИ-генератор музыки AudioCraft с открытым исходным кодом, который создаёт аудио, полностью основываясь на текстовом запросе пользователя. AudioCraft объединяет три отдельные модели ИИ: MusicGen предназначена для создания музыки и обучена на «20 000 часов музыки, принадлежащей Meta✴ или лицензированной специально для этой цели», AudioGen генерирует звуки и эффекты окружающей среды, а EnCodec обеспечивает качественную обработку звука. 
Источник изображения: Pixabay Музыканты давно экспериментируют с электронным звуком, но компьютерные программы создают музыку на основе существующих звуковых сэмплов. Аудио от AudioCraft генерируется лишь из текстовой подсказки. Meta✴ предоставила журналистам образцы аудио, сгенерированного при помощи AudioCraft. Шумовые эффекты, такие как свист, ветер, вой сирен и автомобильные сигналы звучали весьма достоверно. А вот гитарные партии показались слушателям неестественными. Сейчас музыка, сгенерированная AudioCraft, больше всего напоминает muzak (слегка пренебрежительный термин, применяемый для большинства форм фоновой музыки, независимо от источника, «музыка для лифта») или непритязательный атмосферный эмбиент, и не претендует на роль следующего большого поп-хита. Тем не менее, Meta✴ считает, что AudioCraft может открыть новую волну музыкальной моды, как это когда-то сделали первые синтезаторы. Meta✴ признала сложность создания моделей ИИ для генерации музыки, по утверждению представителя компании эта задача на несколько порядков труднее, чем генерация текста при помощи ИИ, подобного Llama 2. Компания полагает, что открытый исходный код AudioCraft поможет разнообразить данные, используемые для его обучения. «Мы понимаем, что наборы данных, используемые для обучения наших моделей, не отличаются разнообразием: большая часть музыки в западном стиле, пары аудио-текст с текстом и метаданными написаны на английском языке, — пояснил представитель Мета✴. — Поделившись кодом для AudioCraft, мы надеемся, что другим исследователям будет легче тестировать новые подходы к ограничению или устранению потенциальной предвзятости и неправильного использования генеративных моделей». Meta✴ — далеко не пионер в области генерации аудио при помощи ИИ. Большая языковая модель MusicLM от Google вполне успешно генерирует аудио, правда доступна она только исследователям. Сгенерированная ИИ песня с голосовым сходством Drake и The Weeknd мгновенно стала вирусной. Недавно Граймс (Grimes) разрешила использовать имитацию своего голоса в треках ИИ. В свою очередь, звукозаписывающие лейблы и артисты уже забили тревогу, поскольку многие модели ИИ могут использовать для обучения материалы, защищённые авторским правом. Sennheiser начнёт продавать слуховые аппараты — с шумоподавлением, оптимизацией диалогов и Bluetooth
21.06.2023 [13:49],
Руслан Авдеев
Sennheiser известен своей аудиотехникой, в том числе популярными сериями наушников, включая Momentum. Теперь бренд заявил о намерении выйти на рынок безрецептурных медицинских устройств с двумя моделями слуховых аппаратов — All-Day Clear и All-Day Clear Slim. 
Источник изображения: Sennheiser Бренд Sennheiser принадлежит компании Sonova, выпускающей оборудование для помощи слабослышащим. Как и другая медицинская электроника, оборот которой разрешён в соответствии со смягчёнными не так давно правилами американского регулятора FDA (Food and Drug Administration), модели All-Day Clear предназначены для тех, кто имеет лёгкие или умеренные проблемы со слухом. По данным производителя, All-Day Clear и All-Day Clear Slim начнут продавать с середины июля, а стоить они будут около $1400 и $1500 соответственно. Судя по названиям и разнице в ценах можно предположить, что вариант Slim будет несколько компактнее. Как сообщили в Sennheiser, послабления в законах, связанных с оборотом слуховых аппаратов в США, позволили заполнить нишу, для которой производитель предложит готовые к немедленном использованию решения, созданные благодаря опыту компании в разработке акустических технологий. Решения регулятора вполне своевременно. По данным на конец 2022 года, более миллиарда человек рискуют потерять слух из-за наушников. 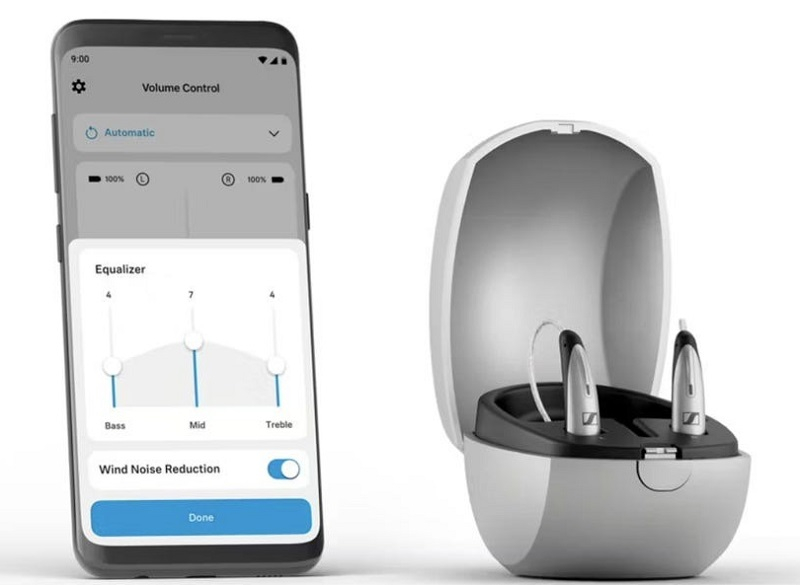
Источник изображения: Sennheiser Известно, что технология подразумевает «распознавание сцен» — проводится постоянный мониторинг окружающей среды для «незаметной оптимизации диалога». Важно, что слуховые аппараты можно дополнительно использовать в качестве беспроводных наушников, поскольку они поддерживают Bluetooth-подключение к другой электронике. Кроме того, при ретрансляции звука устройства подавляют шум ветра. Заряда аккумуляторов хватит на работу до 16 часов, после чего можно воспользоваться зарядным футляром. Настройка аппаратов осуществляется с помощью приложения, делающего подсказки в ходе всего процесса отладки. Устройства совместимы как с iOS, так и с гаджетами на Android. Кроме того, они поставляются в «клинической» комплектации для посещения профессионала, способного провести дополнительную настройку. Послабление правил для некоторых типов слуховых аппаратов в США открыло дорогу для выхода на этот рынок крупных аудиобрендов. Так, Bose (совместно с Lexie Hearing) и Sony (при сотрудничестве с WS Audiology) уже анонсировали выпуск собственных продуктов в течение года. Музыкальный сервис «Звук» получил улучшенный ИИ, который подберёт контент с учётом предпочтений и настроения
13.04.2023 [12:32],
Владимир Мироненко
Музыкальный стриминговый сервис «Звук» обновил приложение, в котором реализовано упрощённое меню с тремя разделами — «Эфир», «Обзор» и «Коллекция», сообщил «Коммерсант». Как отметил сервис, «теперь на благо пользователя трудится ансамбль из разных моделей искусственного интеллекта, угадывающих его музыкальные желания и настроение». 
Источник изображения: «Звук» Усовершенствованный ИИ предлагает пользователю треки в зависимости от его настроения, предпочтений и ситуации. Причём, чем больше пользователь слушает музыку, тем точнее нейросеть сможет распознавать его вкусы и потребности. Сообщается, что приложение будет и дальше постепенно обновляться до середины лета. Раздел «Эфир» содержит различные потоковые «волны» с рекомендациями. Волна «Сила звука» использует несколько моделей ИИ на базе рекомендательных технологий «Сбера» для определения предпочтений и настроений слушателя, предлагая ему соответствующую подборку. «На репите» содержит песни, которые пользователь прослушивает чаще всего. Название волны «Плейлисты от редакторов» говорит само за себя, а в волне «Эксперимент» будут предлагаться новые жанры. Причём, в дальнейшем содержание раздела будет меняться с учётом прослушивания и для каждого пользователя будет уникальным. В «Миксах дня» ИИ предложит плейлист в рамках жанров, которым пользователь отдавал предпочтения в этом месяце. Также есть классический «Топ-100» с подборкой самых популярных и актуальных треков. Раздел «Обзор» содержит навигацию по каталогу «Звука», а также подборки экспертов. В обновлённом «Поиске» можно увидеть запросы других слушателей, что позволит найти близких по духу людей. Отметив их, пользователь сможет в дальнейшем обмениваться с ними музыкой и общаться. Ролики «Сторис» позволят знакомиться с новостями музыкальной индустрии, а также с историями успеха артистов. Раздел «Коллекция» отличается упрощённой навигацией по любимым трекам пользователя, а также усовершенствованным поиском по избранному контенту. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться